







文章目录
一、scrapy五大核心组件
下面这张图我们在python爬虫-scrapy基本使用见到过,下面就稍微介绍一下scrapy的五大核心组件和中间件
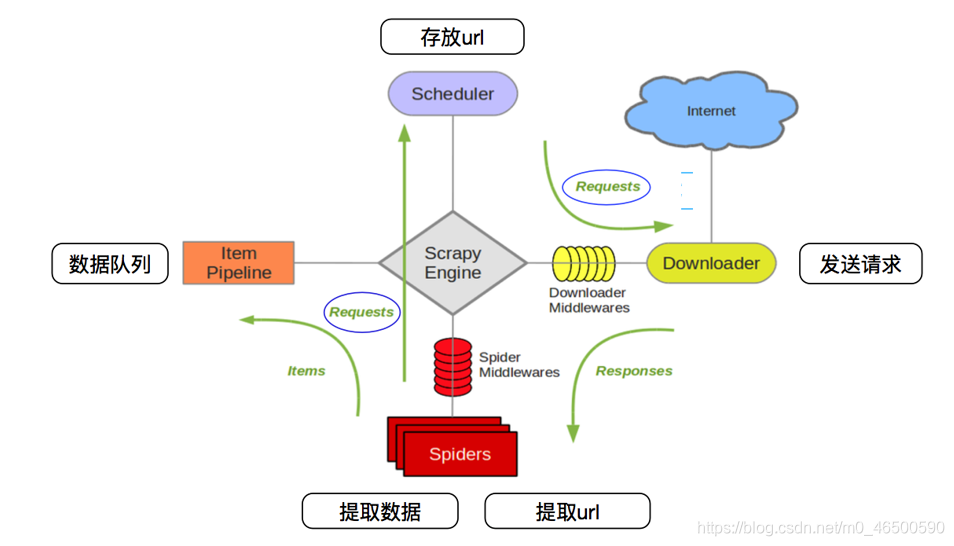
Spiders(爬虫)
Spiders是用户需要编辑的代码的主要部分。用户通过编写spider.py这个类实现爬取指定网站地址、定义网址过滤规则、解析目标数据等。 Spider发出请求,并处理Scrapy引擎返回给它下载器响应数据,把解析到的数据以item的形式传递给ItemPipeline,把解析到的链接传递给Scheduler。
Scrapy Engine(Scrapy引擎)
Scrapy引擎是用来控制整个系统的数据处理流程,并进行不同事务触发,是scrapy框架的核心。
Scheduler(调度器)
调度器包含过滤器和一个url队列,调度器接受引擎发过来的请求,由过滤器过滤重复的url并将其压入url队列中,当引擎再次请求时,从url队列中取出下一个url返回给引擎
Downloader(下载器)
下载器从Scrapy引擎得到需要下载的url,然后向该网址发送请求,将请求到的网页数据传给Spiders。如果需要修改发起的requests请求对象或响应对象,可以通过下载中间件来完成
ItemPipeline(项目管道)
Item对象定义了爬虫要抓取的数据的字段,可以像对待字典一样来存储和提取item对象中存储的数据。Pipeline主要负责处理Spider从网页中抽取的item,对item进行清洗、验证,并且将数据持久化。
二、工作流程
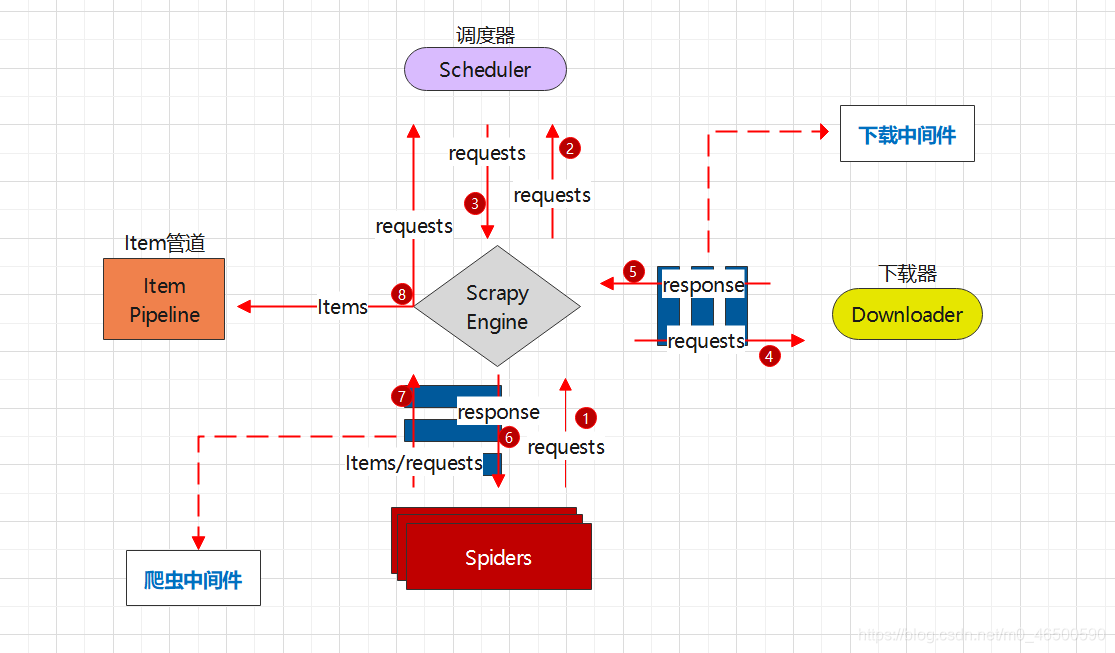
三、中间件
3.1 下载中间件
下载中间件是位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy 引擎与下载器之间的请求及响应。
主要作用
- 在Scrapy将请求发送到网站之前
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 138
138











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









