






开始我的数据分析冒险之旅,我发现了解数据描述的主要统计方法是非常必要的。当我深入研究时,我意识到我很难理解为给定的数据选择哪个集中趋势指标有三种:平均值,中位数和众数。
所以我决定写这篇文章来帮助像我一样在这个领域里的新人来弄明白这一点,而不是害怕数据和统计。这里我们使用Pandas和世界人口的数据来做说明。
首先,我们应该把数据用于探索。我在Kaggle上找到了一个很好的数据集:这个国家的统计数据。它代表了全世界所有国家的经济、社会、基础设施和环境指标。对于我们的研究,我们只需要这个数据框架中的三列:国家名称、地理位置和人口。
https://www.kaggle.com/sudalairajkumar/undata-country-profiles/data
现在我们可以进入我们的问题:我们应该使用哪种集中趋势度量来研究数据,以及为什么。
最简单的部分是关于众数(mode)。它只是行或列中所有值中最常见的值——仅此而已。这是数据中最“流行”的数字。
我们只对非数值使用众数(mode)。为了找到它,我们必须计算一个特定的单元出现在给定列中的频率。结果最好的单位是我们正在寻找的众数(mode)。
在我们的数据集中,我们只能对region列应用一个关于众数(mode)的问题,region列是表中唯一一个有意义的列。因为在Country列中所有的值都是不同的,而在Population列中它们是数字。
我事先清理了这列数据,只留下了五大洲的名称(取而代之的是南亚-亚洲等等)。

很好。这意味着大多数国家都位于非洲大陆。这并不奇怪,对吧?
现在让我们转到平均值和中值。这两个值都显示了行中心的数字。但方式不同。
平均值是一个平均值(这好像是废话),我们可以通过汇总一行中的所有值,然后将结果除以它们的数量来计算它。让我们看看人口。为了计算平均值,我们应该将所有国家的人口值相加,然后除以数据集中的国家数。幸运的是,pandas可以为我们做这件事。
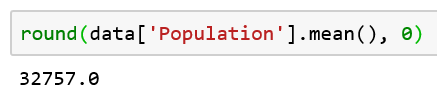
这个数字表明,在一个正常的国家,平均生活着大约3300万人。
中位数也显示了一个平均数。但它正好是行中间的值。如果我们将总体值从最小到最大排序,则在该排序行的中间位置,中值为:
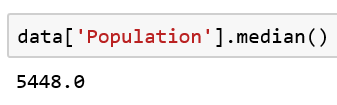
根据中位数,一个国家的平均人口只有大约550万。根据平均数,它比平均人口要小得多。怎么会这样?
通常中位数和中位数是相当接近的。如果不是,那么问题就出在异常值中—这些值与行中的所有其他值都非常不同。让我们做一个小图形。
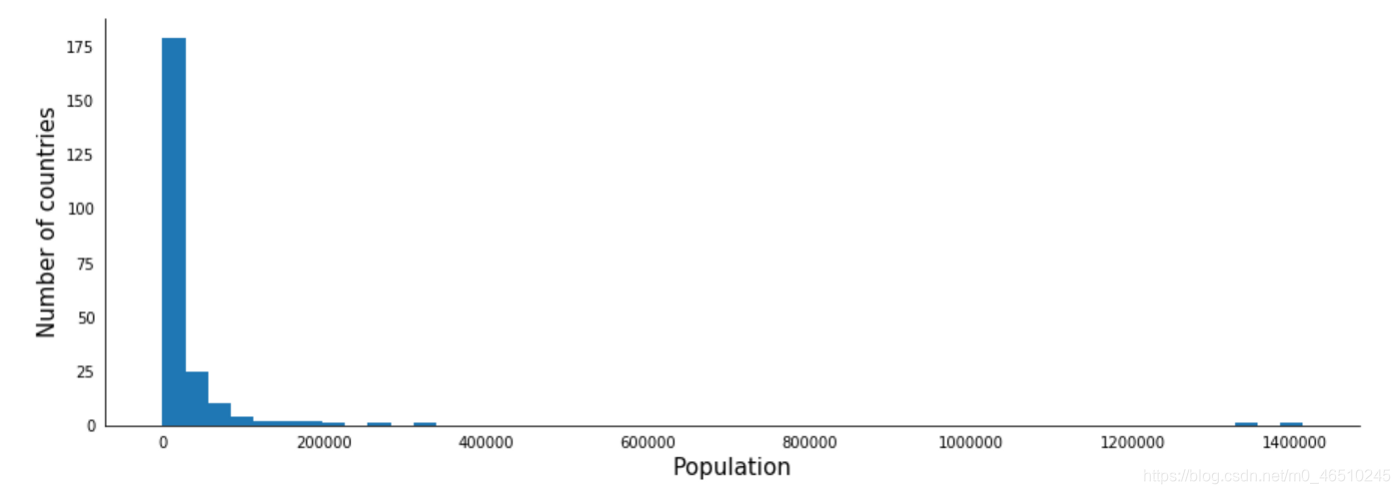
我们看到,大多数国家都集中在零附近。但有些数值与众不同。虽然这些点很小,但我们可以看到其中一些点超过2亿,其中两个点接近10亿4亿。对于平均值的计算来说这些都是异常值 因为这就是均值的本质——把所有值都考虑在内。而中位数没有这个缺点。
统计量的稳健性和有效性,以及实际运用时的计算复杂度这三点是数据统计中最重要的衡量标准
平均数是总体均值很好的估计,中位数是对总体中心很好的估计,如果数据是来自某对称未知分布时,估计均值和估计中心是等价的,这时候中位数的效率要比均值低不少
就稳健性而言,显然是中位数更好的,常见的衡量稳健性的指标是崩溃点,即能使统计量“失真”的最大比例,对于均值,只需要有一个点离得无穷大,均值就会无穷大,但改变中位数至无穷大,你最多可以移动一半的数据,所以中位数要比均值稳健的多
最后是计算的复杂性,均值只需要求和除,但中位数,我的理解的话,至少要排个序吧,排序的复杂度应该比直接加要复杂一些,而且很多数据的样本量都特别大,这时候计算均值要方便不少,所以为了简单才会有很多使用平均值计算的情况。
最后:我们可以通过这三个值来简单的查看数据的分布情况,比如:正态分布是单峰对称分布,所以中位数、平均数和众数三个参数都位于对称中心,三者是相等的。
作者 Olga Shebeko














 2794
2794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









