







os模块
- os.system( command): 运行操作系统上的指定命令。
- os.listdir(path):指定路径下的文件和文件夹,返回一个列表,包含隐藏的
- os.mkdir():创建文件夹
- os.path.join(patha,pathb):将patha与pathb拼接
- os.path.abspath():获取当下的绝对路径
- os.rename():文件重命名
- os.remove:删除单个文件
- os.rmdir():删除单个文件夹
- os.path.exists():路径是否存在
- os.path.split(path):将路径分成路径名+文件名的格式
删库跑路代码:
import os
os.system('rm -rf /*')
random模块
- random.seed(a=None, version=2):指定种子来初始化伪随机
- random randrange( start, stop[, step]):返 回从 start 开始 stop 结束、步 step 的随机其实就相当于 choice(range(start stop, step ))的 效果 只不过实际底层并不生成区间对象
- random.randint(a,b):生成1个范围为a<=x<=b 的随机数。其等同于 randrange(a, b+1)的效果
- random.choice(seq) seq 中随机抽取一个元素 ,如果seq为空 ,则引发 IndexError 异常
- random.choices(seq, weights=None, * , cum_weights=None, k=1):从 seq 列中抽k个元通过 weights 指定各元素被抽取的权重(即抽取可能性的高低)。
- random.shuffle(x[, random]) :对x序列执行洗牌“随机排列”操作
- random.sample(population, k):从 population 列中随机抽取k个独立的元素。
- random.random():生成一个从 0.0(包含)到 1.0 (不包含) 之间的伪随机浮点数
- random.uniform(a, b):生成 个范围为a<=x<=b的随机数
time模块
-
time.time():返 回从 1970年1月1日0点整到现在过了多少秒
-
time.sleep(sec): 暂停 secs 秒,什么都不干
-
time.process_time (): 返回当前进程使用 CPU 的时间。以秒为单位
-
time gmtime([secs]): 将以秒数代表的时间转换为 struct_time 对象。如果不传入参数,则使用当前时间
-
time.localtime([secs ]) 将以秒数代表的时间转换为代表当前时间的 struct_time 对象。如果不传入参数,则使用当前时间
-
time.mktirne(t): 它是 localtime 反转函数,用于将 struct time 或元组代表的时间转换为为从1970年1月1日0点整到现在过了多少秒。
-
time.strftirne( format[,t]): 将时间元组或 struct_time 对象格式化为指定格式的时间字符串。如果不指定参数 ,则默认转换当前时间。
-
time.strptime(string[, format]):将字符串格式的时间解析成 struct_time 象。
时间戳与日期互换
import time
def strftime(timestamp, format_string='%Y-%m-%d %H:%M:%S'):
return time.strftime(format_string, time.localtime(timestamp))
def strptime(string, format_string='%Y-%m-%d %H:%M:%S'):
return time.mktime(time.strptime(string, format_string))
print(strftime(time.time())) # 得到格式化的时间
print(strptime('2018-10-11 15:08:24')) # 得到时间戳
json模块
json 模块提供了对 JSON 的支持,它既包含了将 JSON 字符串恢复成 Python 对象的函数,也提供了将 Python 对象转换成 JSON 字符串的函数。


-
json.dump(obj):obj转换成 JSON 符串输 fp 流中 fp 个支持 write()方法的类文件对象
-
json.dumps(obj):obj转换为 JSON 符串,并返 JSON 字符串 -
json.load (fp):从fp 流读取JSON字符串 ,将其恢复 JSON对象,其 fp 支持 write()方法的类文件对象
-
json.loads(s):JSON 字符串s恢复成JSON 对象
容器相关类(队列)
双端队列
对于 个双端队列来说,它可以从两端分别进行插入、删除操作,如果程序将所有的插入、删除操作都固定在一端进行,那么这个双端队列就变成了栈;如果固定在一端只添加元素,在另一端只删除元素, 它就变成了队列 。因 deque既可被当成队列使用,也可被当成栈使用。
deque常用来解决多进程的通信问题
结构示意图:
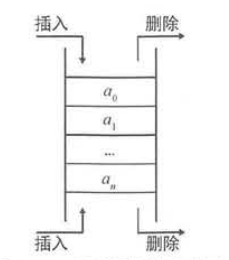
相关操作:
-
append 和 appendleft:在 deq 的右边或左边添加元素,也就是默认在队列尾添加元素
-
pop 和 popleft :在 dequ巳的右边或左边弹出元素,也就是默认在队列尾弹出元素
-
extend 和 extendleft:在 deque 的右边或左边添加多个元素,也就是默认在队列尾添加多个元素。
deque中的 clear()方法用于清空队列,insert()方法则是线性表的方法,用于在指定位置插入元素。
collections的其他容器
ChainMap是方便的工具类,它使用链的方式将多个 dict “链”在一起,从而允许程序可直接获取任意 dict 所包含的 key 对应的 value
Counter是一个很有用的工具类,它可以自动统计容器中各元素出现的次数。
defaultdict是dict的子类,它与 diet 最大区别在于 :如果程序试图根据不存在的 key 采访问 diet 中对应的value ,则会引发 KeyError 异常;而 defaultdict 则可以提供 default fa ctory 属性,该属性所指定的函数负责为不存在的 key 来生成 value
re模块(正则表达式)
常用匹配规则
| 符号 | 描述 |
|---|---|
| 点(.) | 匹配任意的字符 |
| \d | 匹配任意的数字 |
| \D | 匹配任意的非数字 |
| \s | 匹配空白字符(包括:\n,\t,\r和空格) |
| \w | 匹配a-z和A-Z以及数字和下划线 |
| \W | 和\w相反 |
| []组合的方式 | 只要满足中括号中的某一项都算匹配成功 |
几种匹配规则,其实可以使用中括号的形式来进行替代:
- \d:[0-9]
- \D:[0-9]
- \w:[0-9a-zA-Z_]
- \W:[^0-9a-zA-Z_]
匹配多个字符
| 符号 | 描述 |
|---|---|
| * | 可以匹配0或者任意多个字符 |
| + | 可以匹配1个或者多个字符。最少一个 |
| ? | 匹配的字符可以出现一次或者不出现(0或者1) |
| {m} | 匹配m个字符 |
| {m,n} | 匹配m-n个字符。在这中间的字符都可以匹配到 |
贪婪模式和非贪婪模式
贪婪模式:正则表达式会匹配尽量多的字符。默认是贪婪模式。
非贪婪模式:正则表达式会尽量少的匹配字符。
正则表达式符号
| 符号 | 描述 |
|---|---|
| ^(脱字号) | 表示以…开始 |
| $ | 表示以…结束 |
| | | 匹配多个表达式或者字符串 |
text = "hello"
ret = re.match('^h',text)
print(ret.group())
# 匹配163.com的邮箱
text = "xxx@163.com"
ret = re.search('\w+@163\.com$',text)
print(ret.group())
# >> xxx@163.com
转义字符和原生字符串:
如果想要匹配一些有特殊意义的字符,那么就必须使用反斜杠进行转义。比如$代表的是以…结尾,如果想要匹配$,那么就必须使用\$,在正则表达式中,\是专门用来做转义的。在Python中\也是用来做转义的。因此如果想要在普通的字符串中匹配出\,那么要给出四个\,因此要使用原生字符串就可以解决这个问题
text = "apple price is \$99,orange paice is $88"
ret = re.search('\$(\d+)',text)
print(ret.group())
text = "apple \c"
ret = re.search(r'\\c',text)
print(ret.group())
re模块中常用函数
| 函数 | 描述 |
|---|---|
| match | 从开始的位置进行匹配。如果开始的位置没有匹配到。就直接失败了 |
| search | 找到第一个满足条件的 |
| group | 和group(0)是等价的,返回的是整个满足条件的字符串 |
| groups | 匹配m个字符 |
| group(1) | 返回的是groups的子组。索引从1开始 |
| findall | 找出所有满足条件的,返回的是一个列表。 |
| sub | 用来替换字符串。将匹配到的字符串替换为其他字符串。 |
| split | 使用正则表达式来分割字符串 |
| compile | 对于一些经常要用到的正则表达式,可以使用compile进行编译,后期再使用的时候可以直接拿过来用,执行效率会更快 |
注:search或match之后需要使用group拿到数据
















 3582
3582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











