






一、案例一:获取影片信息
访问豆瓣电影Top250,网址:https://movie.douban.com/top250?start=0 获取每部电影的中文片名、排名、评分及其对应的链接,按照“排名-中文片名-评分-链接”的格式显示在屏幕上。
以下是案例代码:
import requests
from bs4 import BeautifulSoup
import time
# 请求网页
def page_request(url, ua):
response = requests.get(url=url, headers=ua)
html = response.content.decode('utf-8')
return html
# 解析网页
def page_parse(html):
soup = BeautifulSoup(html, 'lxml')
# 获取每部电影的排名
position = soup.select('#content > div > div.article > ol > li > div > div.pic > em')
# 获取豆瓣电影名称
name = soup.select('#content > div > div.article > ol > li > div > div.info > div.hd > a > span:nth-child(1)')
# 获取电影评分
rating = soup.select('#content > div > div.article > ol > li> div > div.info > div.bd > div > span.rating_num')
# 获取电影链接
href = soup.select('#content > div > div.article > ol > li > div > div.info > div.hd > a')
for i in range(len(name)):
print(position[i].get_text()+'\t'+name[i].get_text()+'\t' + rating[i].get_text() + '\t' + href[i].get('href'))
if __name__ == "__main__":
print('**************开始爬取豆瓣电影**************')
ua = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4421.5 Safari/537.36'}
# 豆瓣电影Top250每页有25部电影,start就是每页电影的开头
for startNum in range(0, 251, 25):
url = "https://movie.douban.com/top250?start=%d" % startNum
html = page_request(url=url, ua=ua)
page_parse(html=html)
print('**************爬取完成**************')本案例中使用CSS选择器来获取标签,如何直接在浏览器获取指定元素的CSS选择器:
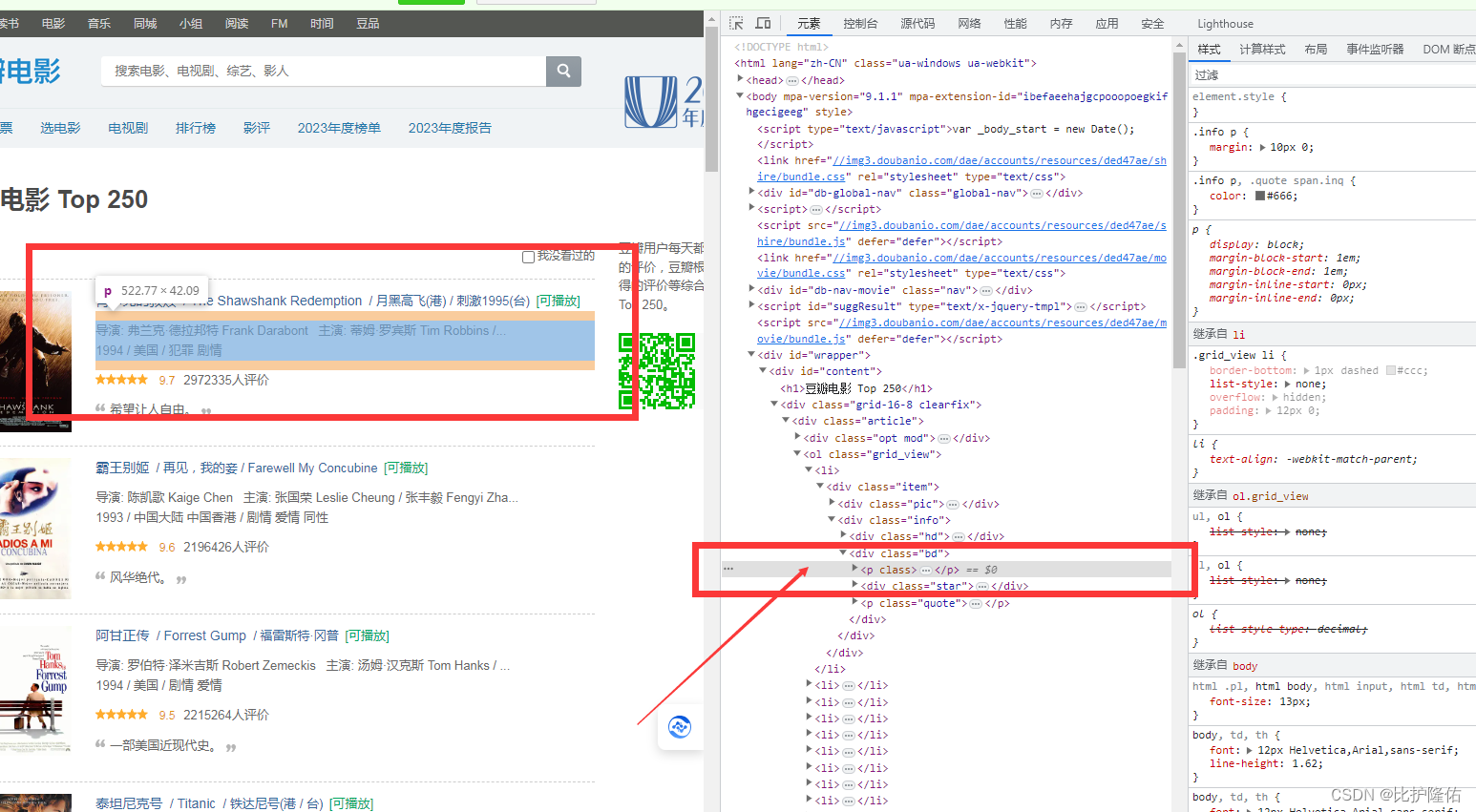
我们打开网页后,例如要获取《肖申克的救赎》电影的导演,把鼠标移动至该电影的导演处,右击,选择审查元素

在右侧的元素区可以定位到该信息在html网页源码的具体位置
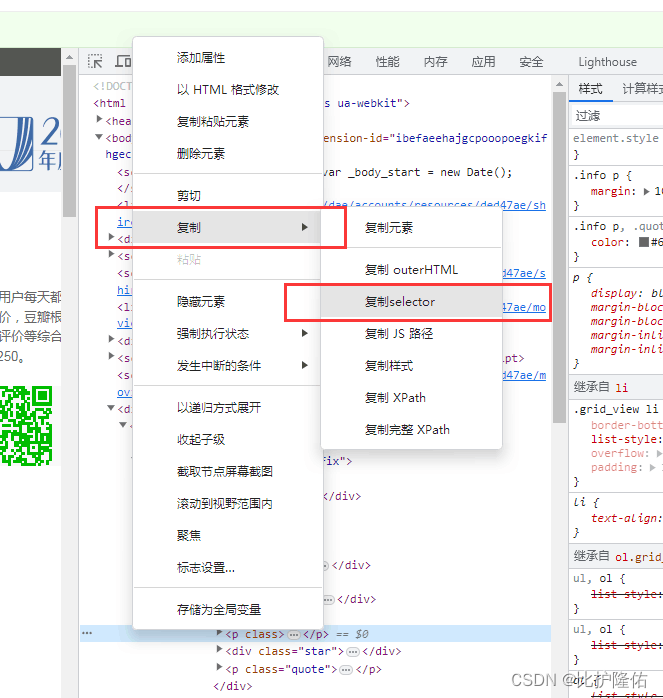
然后在对应标签处右击,选择复制——复制selector
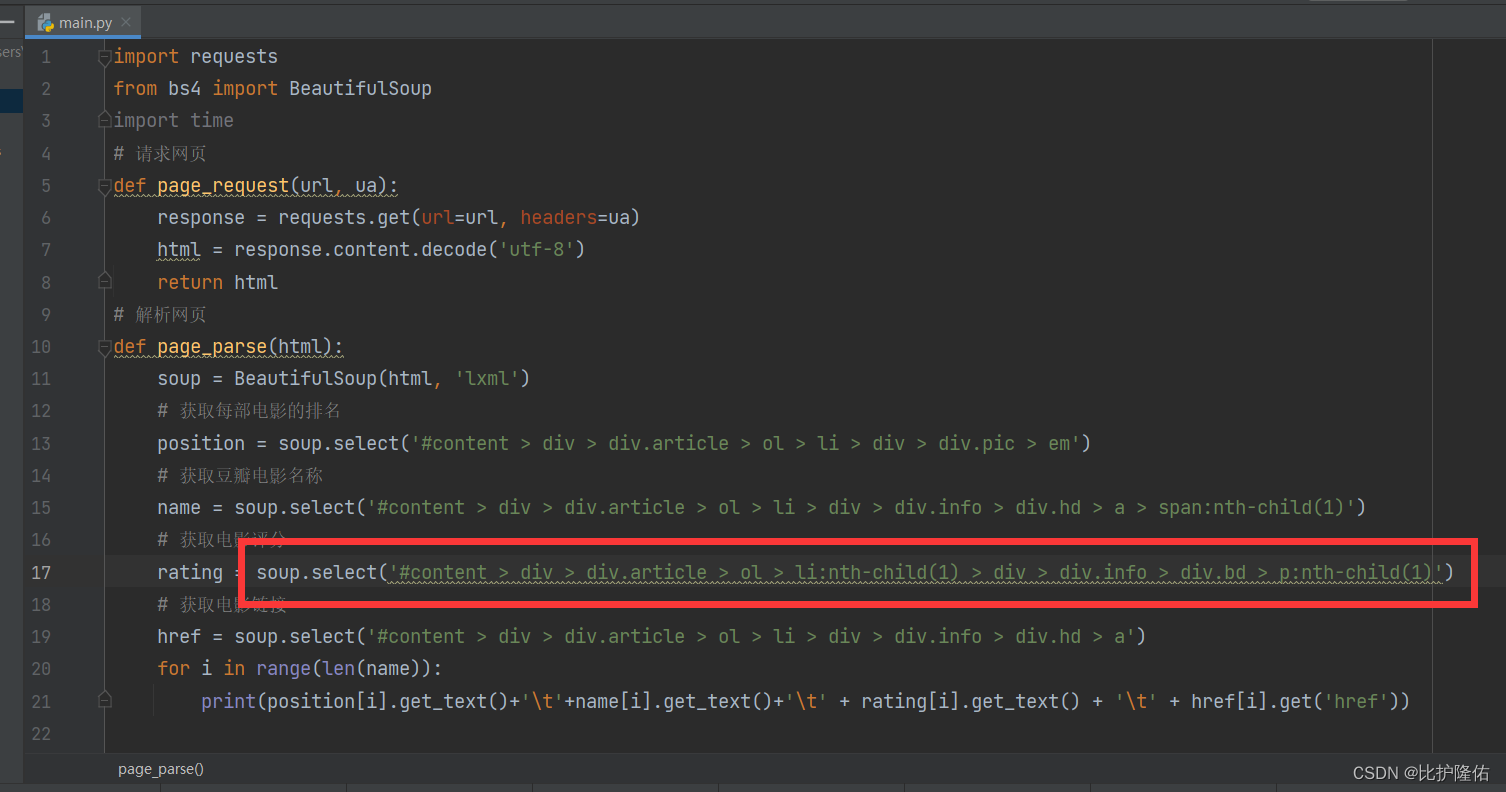
将复制好的selector粘贴到soup.select()中即可。
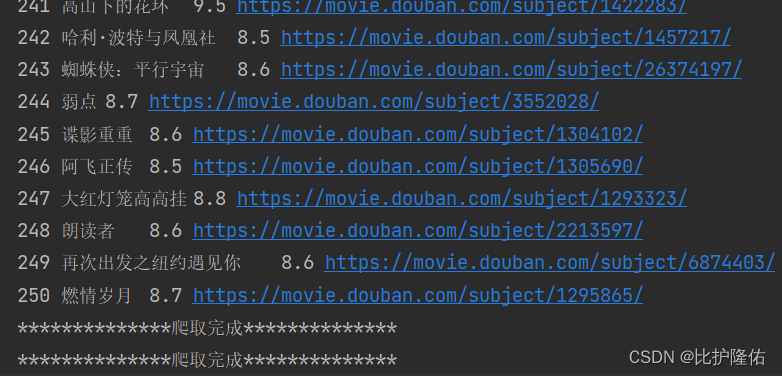
以下为爬取结果:
二、案例二:访问热搜榜并发送邮件
访问微博热搜榜(https://s.weibo.com/top/summary),获取微博热搜榜前50条热搜名称、链接及其实时热度,并将获取到的数据通过邮件的形式,每20秒发送到个人邮箱中。
本案例需要获取User-Agent、Accept、Accept-Language、Accept-Ecoding、Cookie五个字段,前四个字段可能都是相同的,主要是Cookie不同。
具体获取流程如下:
打开目标网页:https://s.weibo.com/top/summary按键盘上面F12进入开发者模式,再按F5刷新页面,会出现网页相关信息:
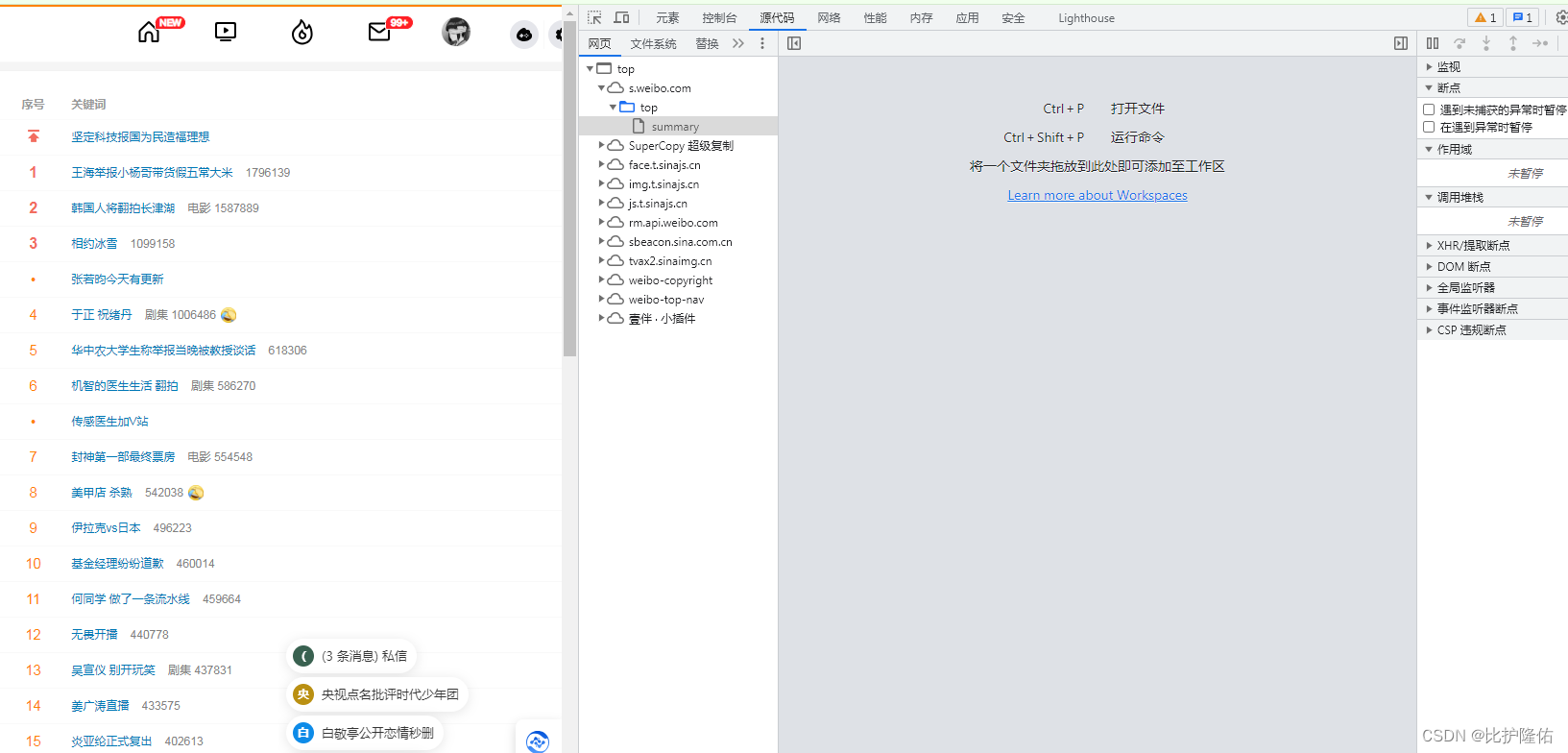
依次点击Network、All、以及summary(即目标链接的地址):
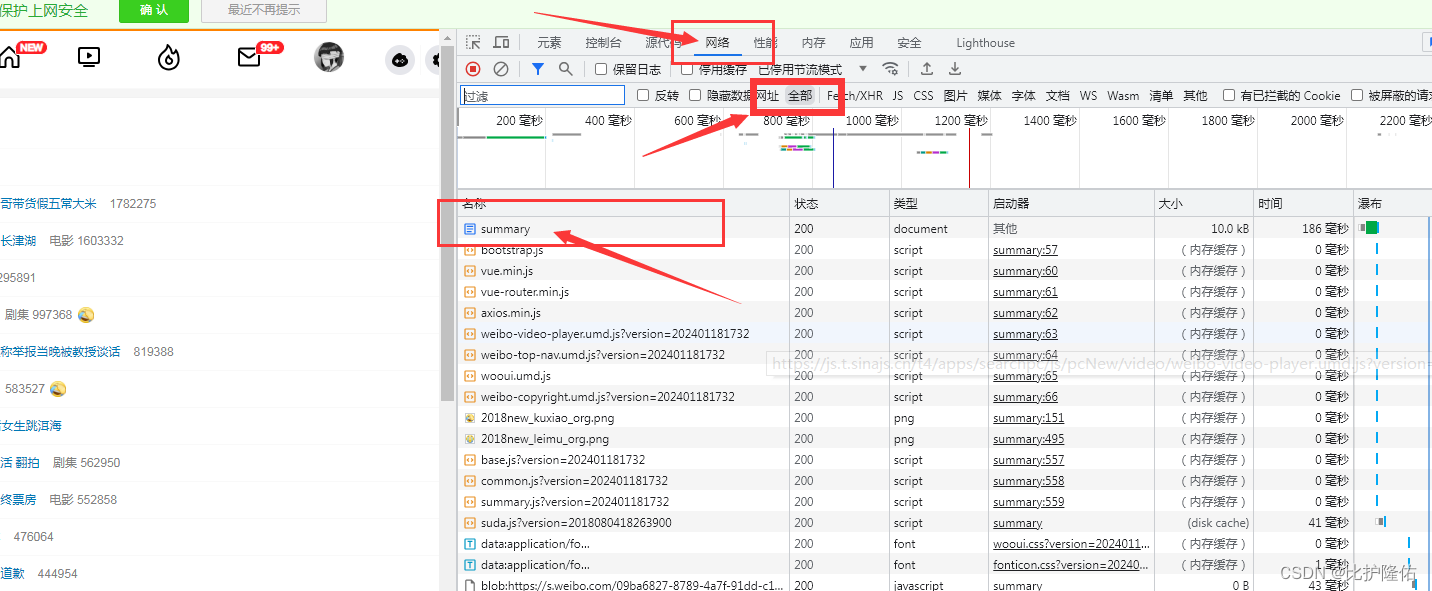
点击summary后出现右侧窗口,点击Header能够得到相关报文字段。
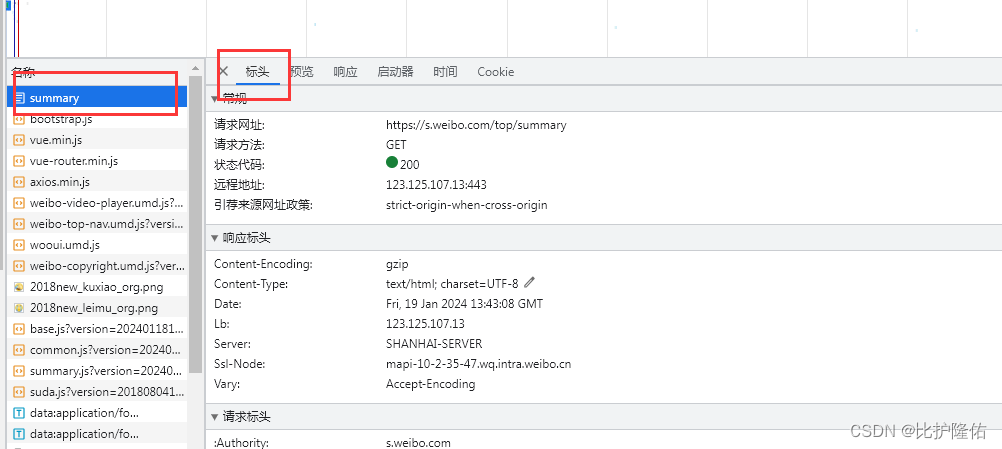
本案例所需的字段均在Request Header中,即下图中标注的字段。具体字段对应的值以各自浏览器为主,无需与图中字段值相同
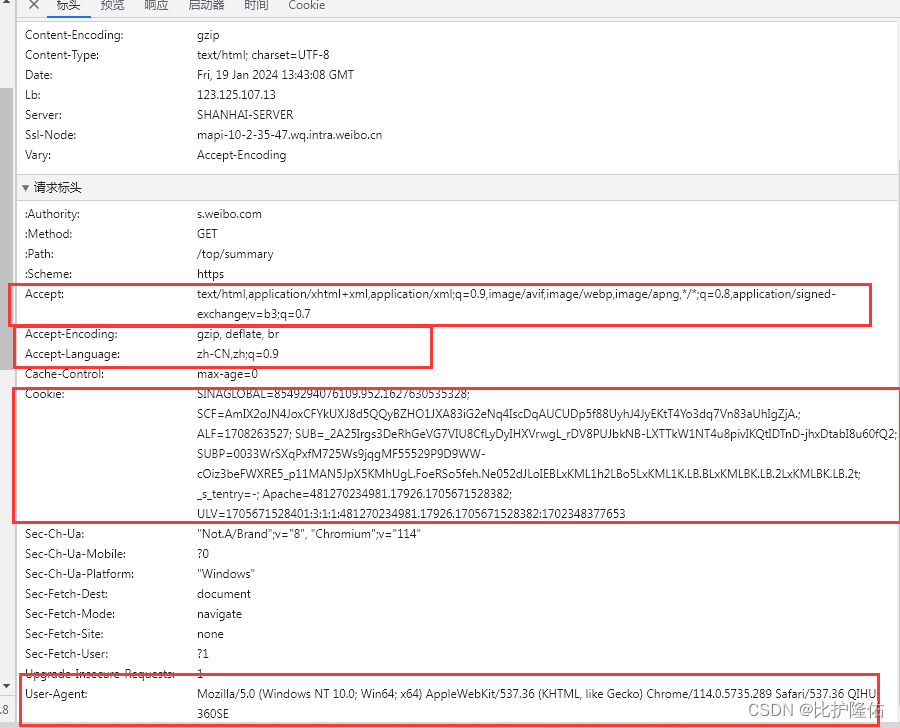
记住User-Agent、Accept、Accept-Language、Accept-Ecoding、Cookie五个字段值,后续在代码中会用到。
然后再去QQ邮箱获取邮箱的smtp授权码就可以进行爬取操作了,本案例还是使用CSS选择器获取指定元素信息。其中,热搜榜置顶没有显示热度,需要特殊处理。另外就是部分热搜的链接会出现别的情况,也需要特殊处理。
获取发送邮箱的smtp授权码:
smtp授权码只需要发送邮箱的,不是接收邮箱的。因为不是我们自己主动发送邮件,通过第三方(python代码)发送的,所以需要获取smtp授权码进行第三方登录。本案例以QQ邮箱为例,获取QQ邮箱的smtp授权码,其他类型邮箱类似或者可以上网查找相关资料。
打开QQ邮箱设置-账户,往下滑找到如图所示的选项:

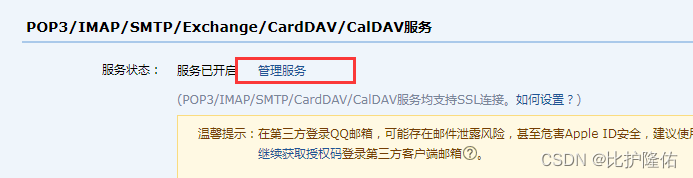
将以上4个服务都开起来,然后点击管理服务,点生成授权码
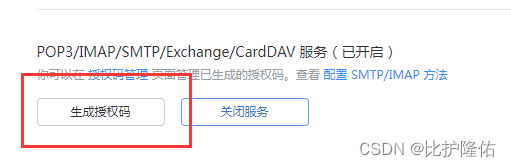
这样授权码就生成了
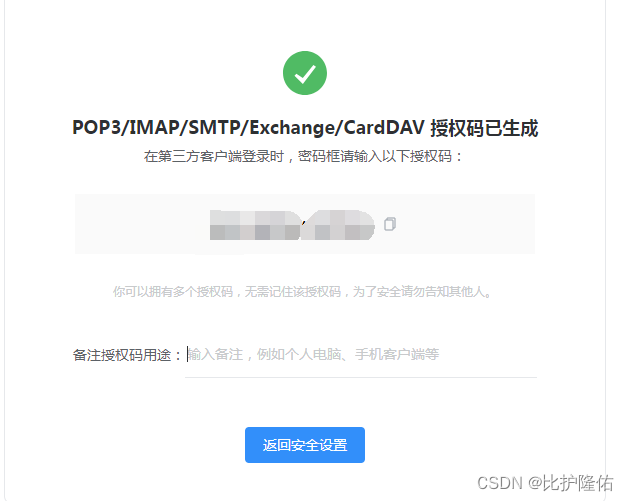
以下是本案例代码,把User-Agent、Accept、Accept-Language、Accept-Ecoding、Cookie五个字段值改成刚刚在网页中查询到的,然后发送邮箱、邮箱授权码、接收邮箱也填写自己对应的信息
# 爬虫相关模块
import requests
from bs4 import BeautifulSoup
# 发送邮箱相关模块
import smtplib
from email.mime.text import MIMEText
from email.header import Header
# 定时模块
import schedule
import time
# 请求网页
def page_request(url, header):
response = requests.get(url=url, headers=header)
html = response.content.decode("UTF-8")
return html
# 解析网页
def page_parse(html):
soup = BeautifulSoup(html, 'lxml')
news = []
# 处理热搜前50
urls_title = soup.select('#pl_top_realtimehot > table > tbody > tr > td.td-02 > a')
hotness = soup.select('#pl_top_realtimehot > table > tbody > tr > td.td-02 > span')
for i in range(len(urls_title)):
new = {}
title = urls_title[i].get_text()
url = urls_title[i].get('href')
# 个别链接会出现异常
if url == 'javascript:void(0);':
url = urls_title[i].get('href_to')
# 热搜top没有显示热度
if i == 0:
hot = 'top'
else:
hot = hotness[i - 1].get_text()
new['title'] = title
new['url'] = "https://s.weibo.com" + url
new['hot'] = hot
news.append(new)
print(len(news))
for element in news:
print(element['title'] + '\t' + element['hot'] + '\t' + element['url'])
# 发送邮件
sendMail(news)
# 将获取到的热搜信息发送到邮箱
def sendMail(news):
# 发送邮箱
from_addr = '123456789@qq.com'
# 发送邮箱授权码,不是邮箱密码,而是smtp授权码
password = 'qwertyuiopasdfghj'
# 接收邮箱
to_addr = '123456789@qq.com' #同发送邮箱一致即可
# qq邮箱的smtp地址
maihost = 'smtp.qq.com'
# 建立SMTP对象
qqmail = smtplib.SMTP()
# 25为SMTP常用端口
qqmail.connect(maihost, 25)
# 登录邮箱
qqmail.login(from_addr, password)
# 设置发送邮件的内容
content = ''
for i in range(len(news)):
content += str(i) + '、\t' + news[i]['title'] + '\t' + '热度:' + news[i]['hot'] + '\t' + '链接:' + news[i][
'url'] + ' \n'
get_time = time.strftime('%Y-%m-%d %X', time.localtime(time.time())) + '\n'
content += '获取事件时间为' + get_time
# 设置邮件的格式以及发送主题
msg = MIMEText(content, 'plain', 'utf-8')
msg['subject'] = Header('微博热搜', 'utf-8')
try:
qqmail.sendmail(from_addr, to_addr, msg.as_string())
print('succeed sending')
except:
print('fail sending')
qqmail.quit()
def job():
print('**************开始爬取微博热搜**************')
header = {
#这里需要把刚刚在网页中查到的5个字段值复制过来
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh-Hans;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Cookie':'SINAGLOBAL=8549294076109.952.1627630535328; SCF=AmIX2oJN4JoxCFYkUXJ8d5QQyBZHO1JXA83iG2eNq4IscDqAUCUDp5f88UyhJ4JyEKtT4Yo3dq7Vn83aUhIgZjA.; ALF=1708263527; SUB=_2A25Irgs3DeRhGeVG7VIU8CfLyDyIHXVrwgL_rDV8PUJbkNB-LXTTkW1NT4u8pivIKQtIDTnD-jhxDtabI8u60fQ2; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WW-cOiz3beFWXRE5_p11MAN5JpX5KMhUgL.FoeRSo5feh.Ne052dJLoIEBLxKML1h2LBo5LxKML1K.LB.BLxKMLBK.LB.2LxKMLBK.LB.2t; _s_tentry=-; Apache=481270234981.17926.1705671528382; ULV=1705671528401:3:1:1:481270234981.17926.1705671528382:1702348377653'
}
url = 'https://s.weibo.com/top/summary'
html = page_request(url=url, header=header)
page_parse(html)
if __name__ == "__main__":
# 定时爬取,每隔20s爬取一次微博热搜榜并将爬取结果发送至个人邮箱
# 可以将20修改成其他时间
schedule.every(20).seconds.do(job)
while True:
schedule.run_pending()运行结果


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









