










关于:
程序是借助API的(废话), 所以在无网络时, 没办法使用. 成品下载地址在文章末.
准备工作:
导入库, request(发送请求) 和 json(解析返回数据).
开搞:
首先, 是找到我们所需要的API, 瞧瞧这个链接: 有道翻译体验
虽说是体验, 但是我都用了巨长一段时间却没有任何问题, 看来这个API至少短时间内不会有任何变更了~
然后就是破解API的请求内容了. 打开浏览器调试, 转到网络选项卡, 然后重新翻译一下, 好的, 结果很明显, 芜湖 😄
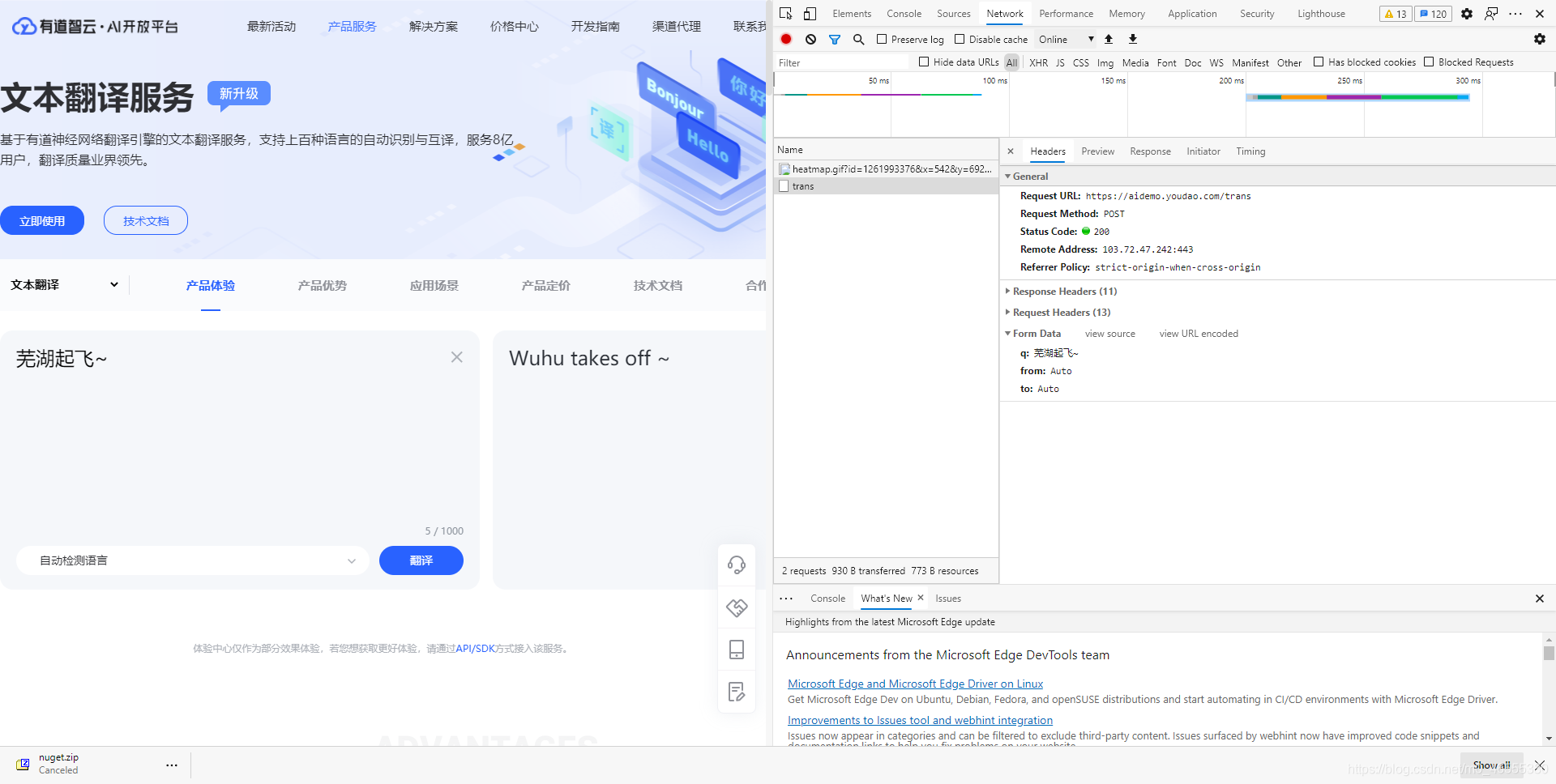
post请求, 3个参数, q是翻译内容, from和to表示翻译的语言, 那么, 试着换一下语言吧.
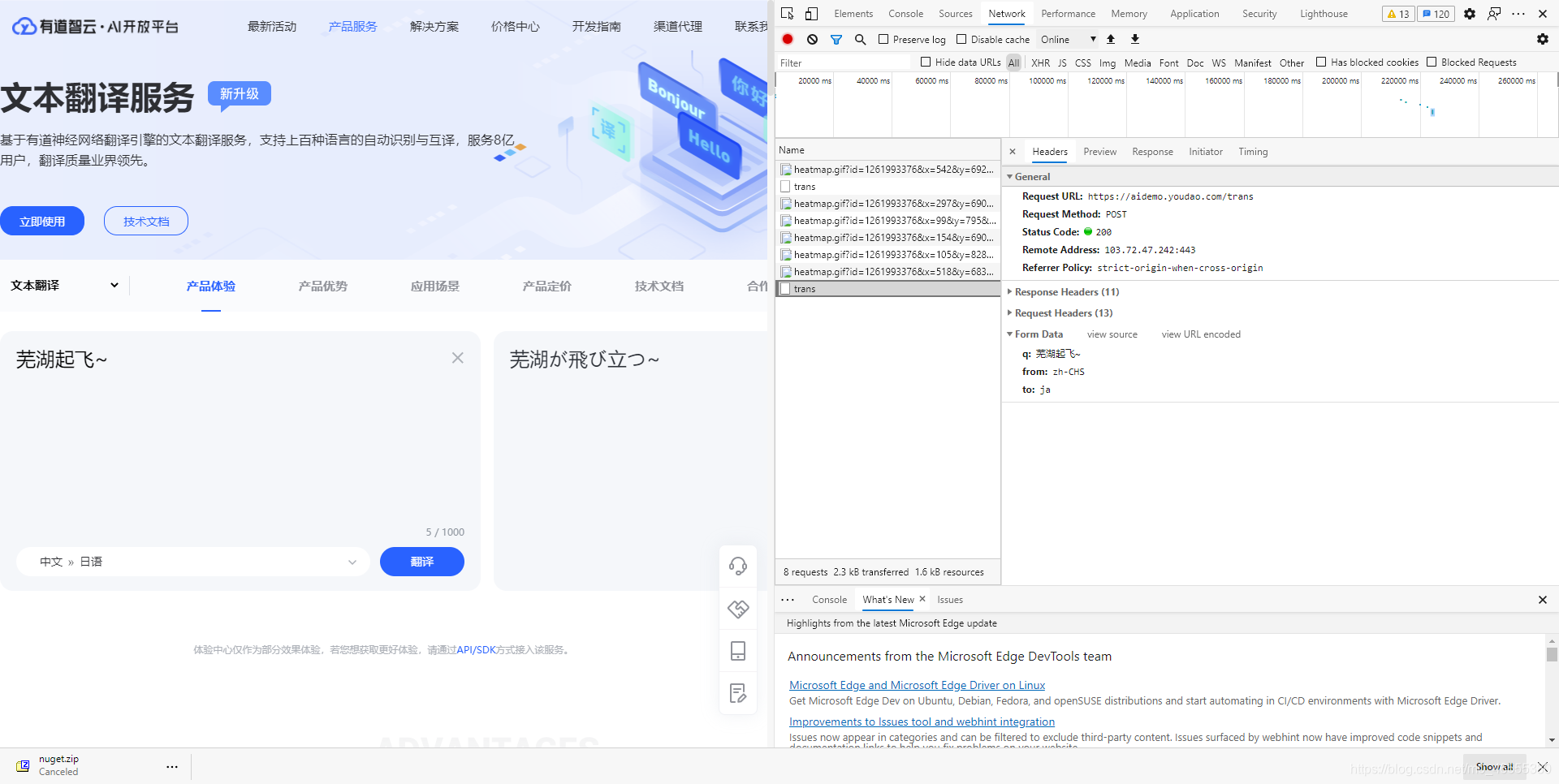
哦, 我们得到了中文与日文的对应数据, zh-CHS 和 ja, 还有更多语言呢, 看看HTML节点吧
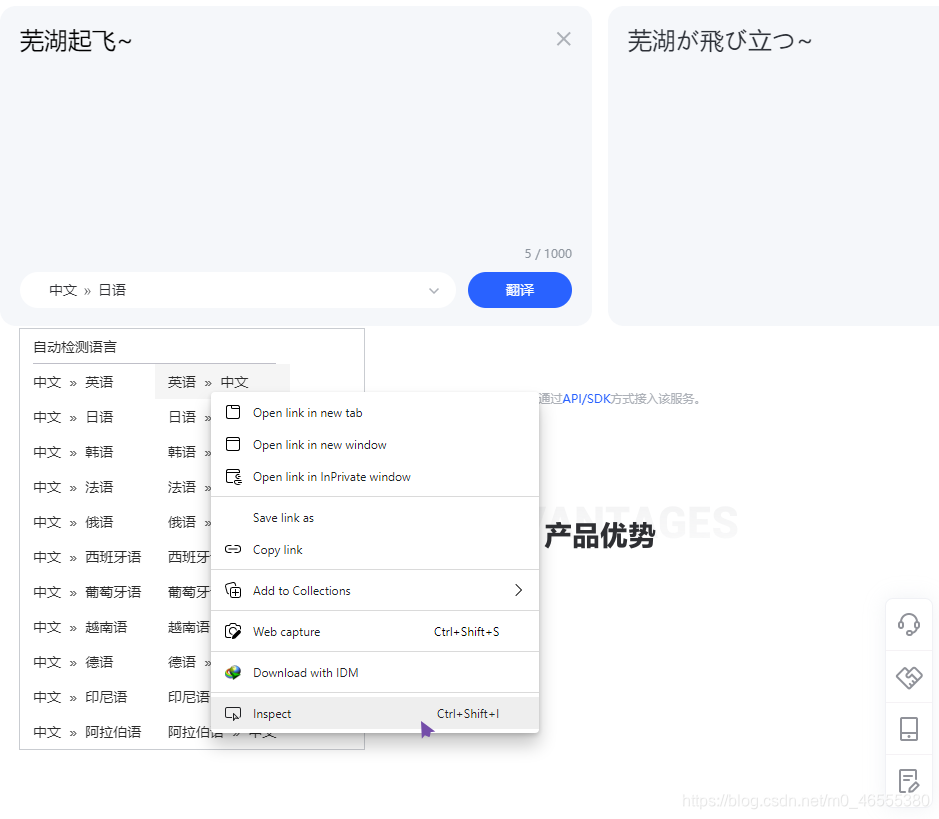
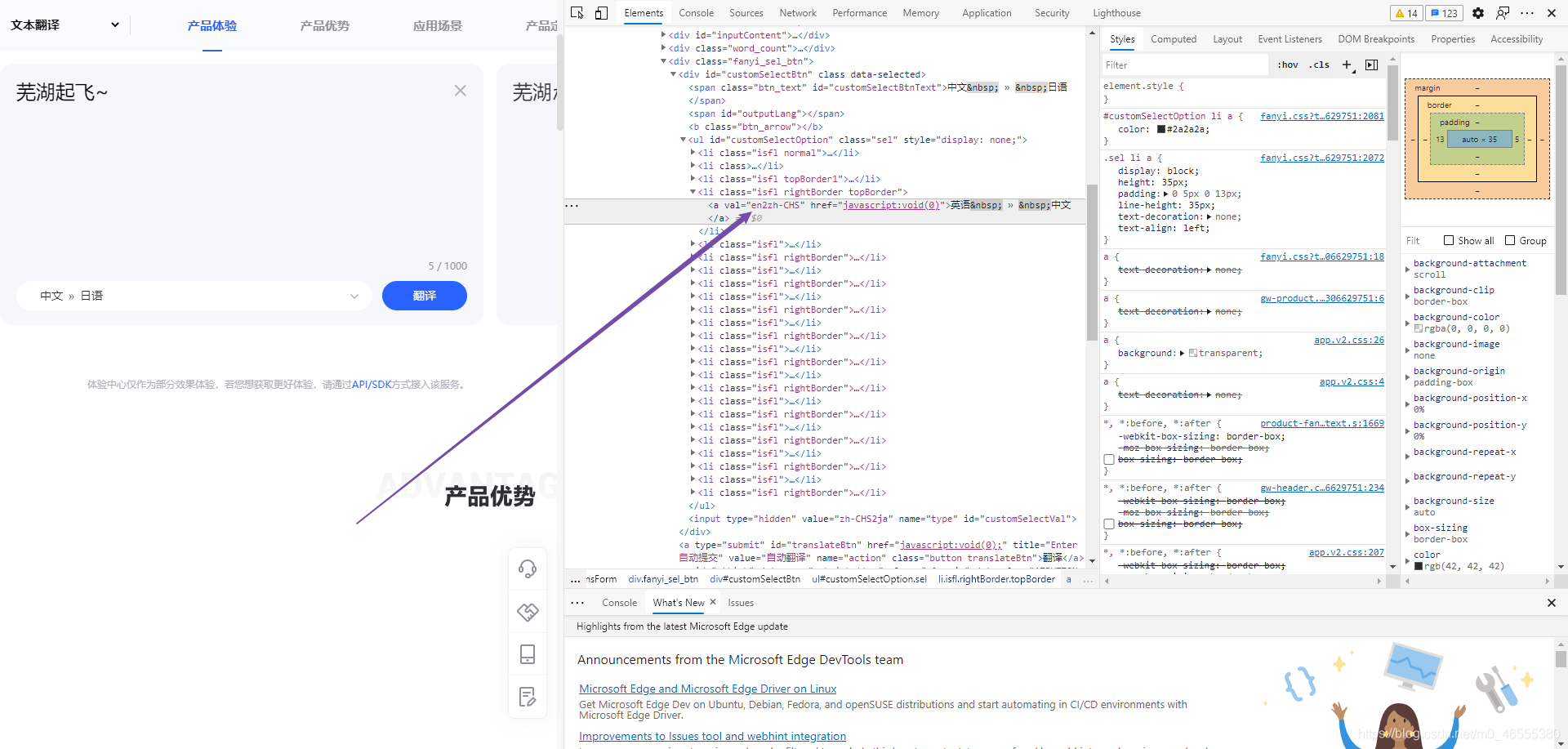
哦豁, 比想象中的要简单! 2就是to的意思, 那么, 我们能得到所有的语言对应参数值了!

记录下来吧~
参数: q:翻译文本 from:从语言 to:至语言
语言支持的值: 中文:zh-CHS, 英语:en, 日语:ja, 韩语:ko, 法语:fr, 俄语:ru,
西班牙语:es, 葡萄牙语:pt, 越南语:vi, 德语:de, 印尼语:id
阿拉伯语:ar
接下来, 就是对网页中, 源代码的进一步分析了, 检查"翻译"按钮的节点, 然后查看click事件监听代码.
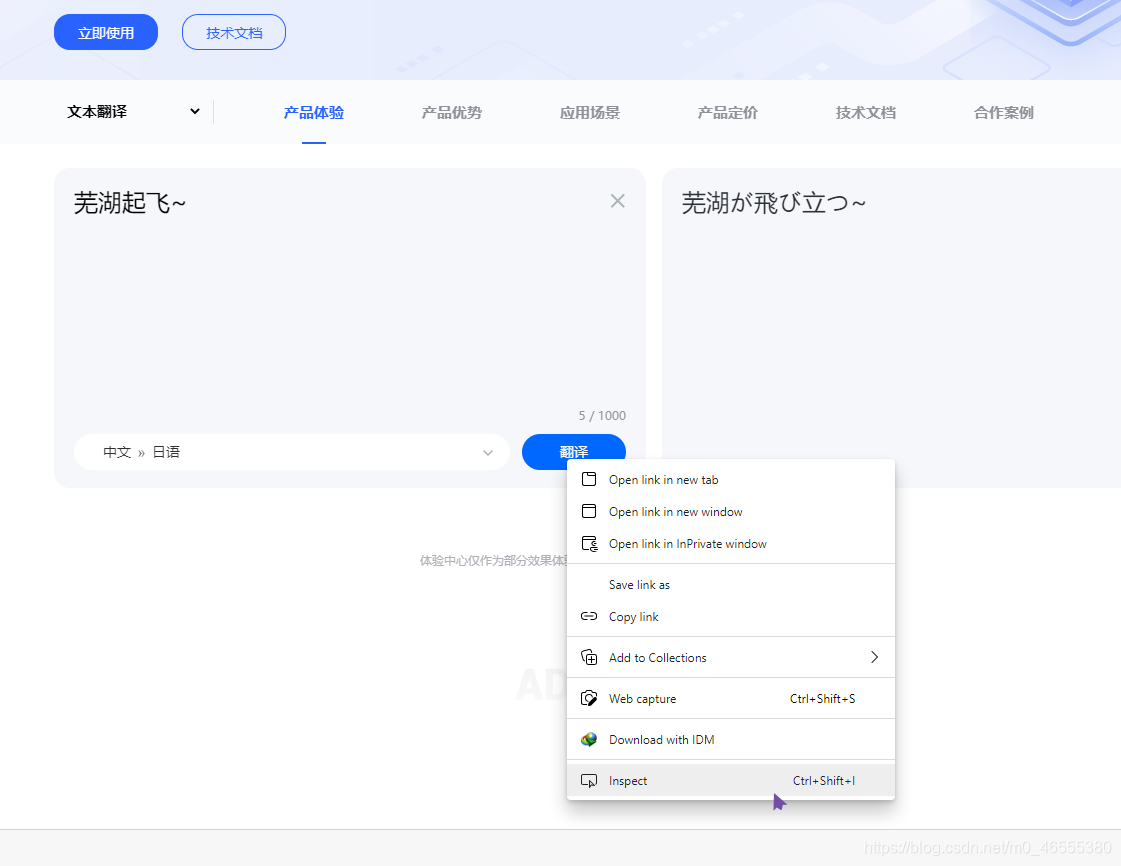
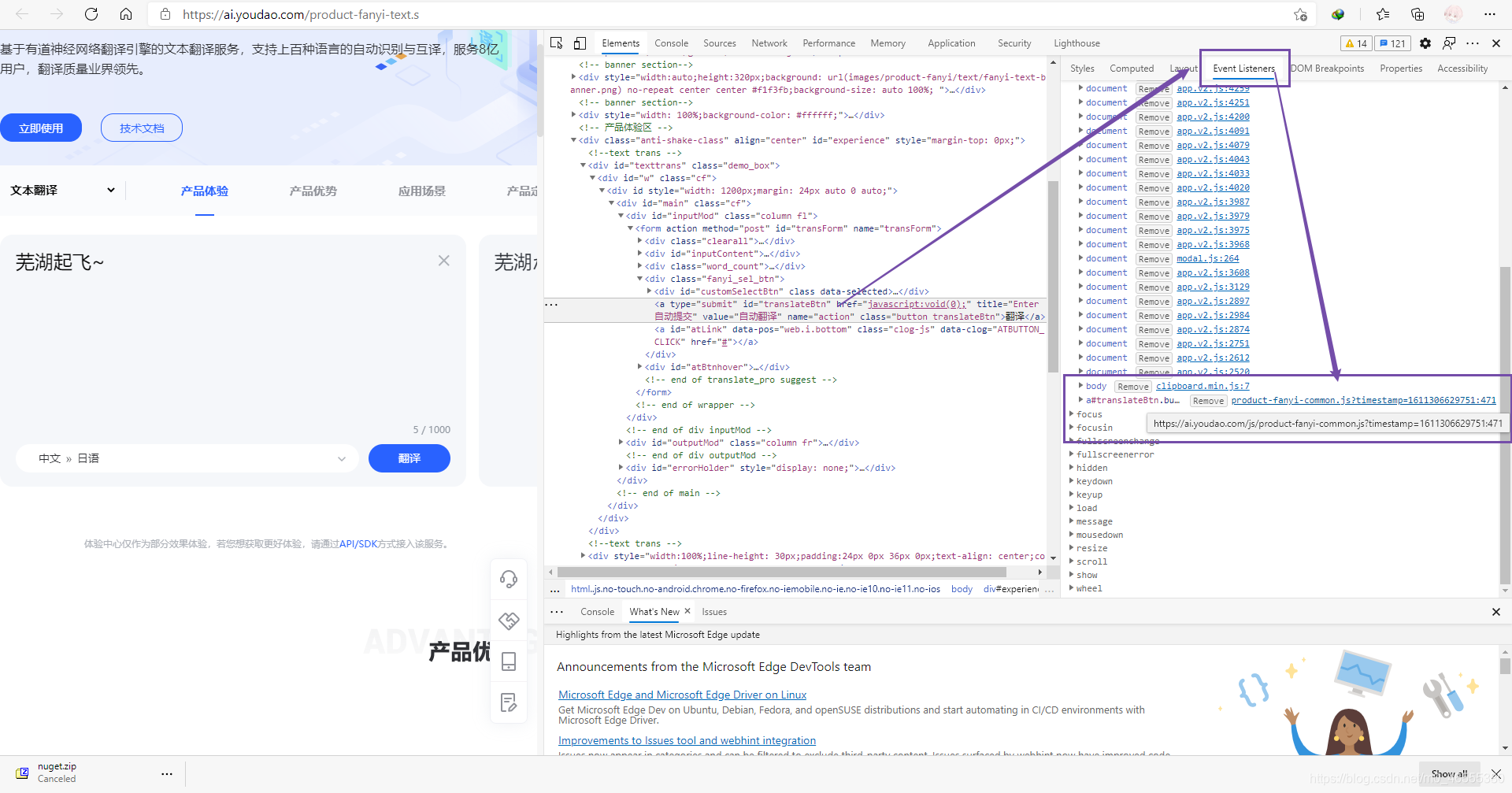
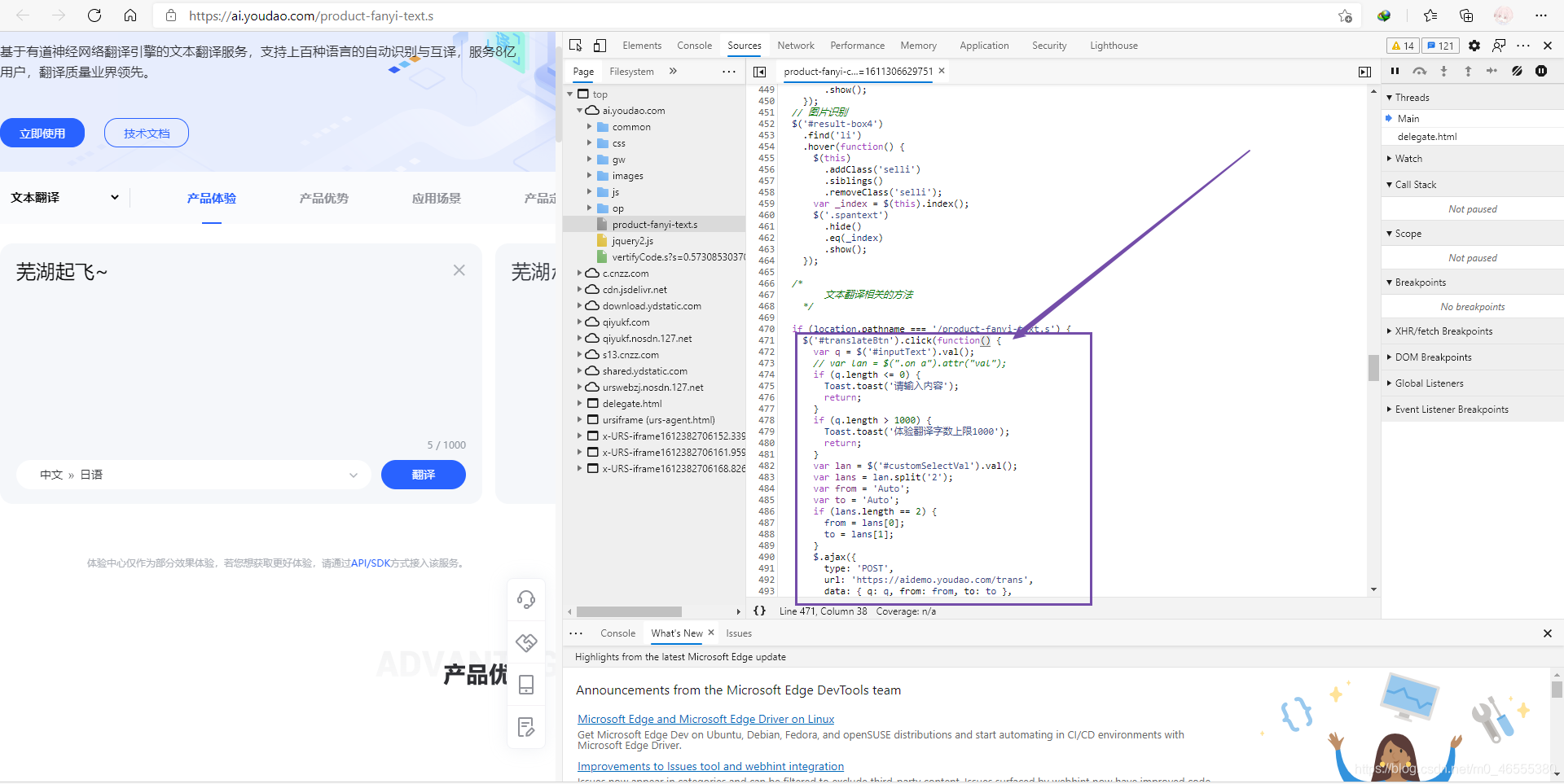
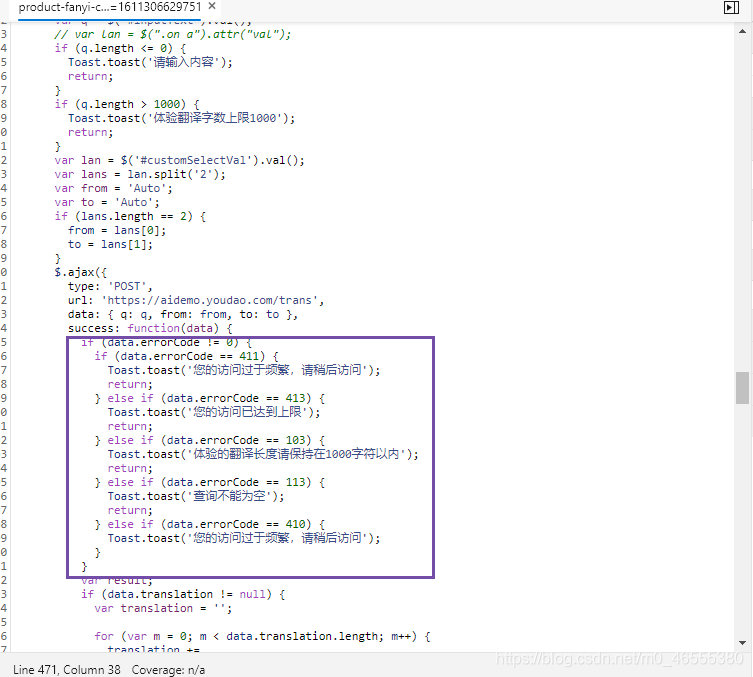
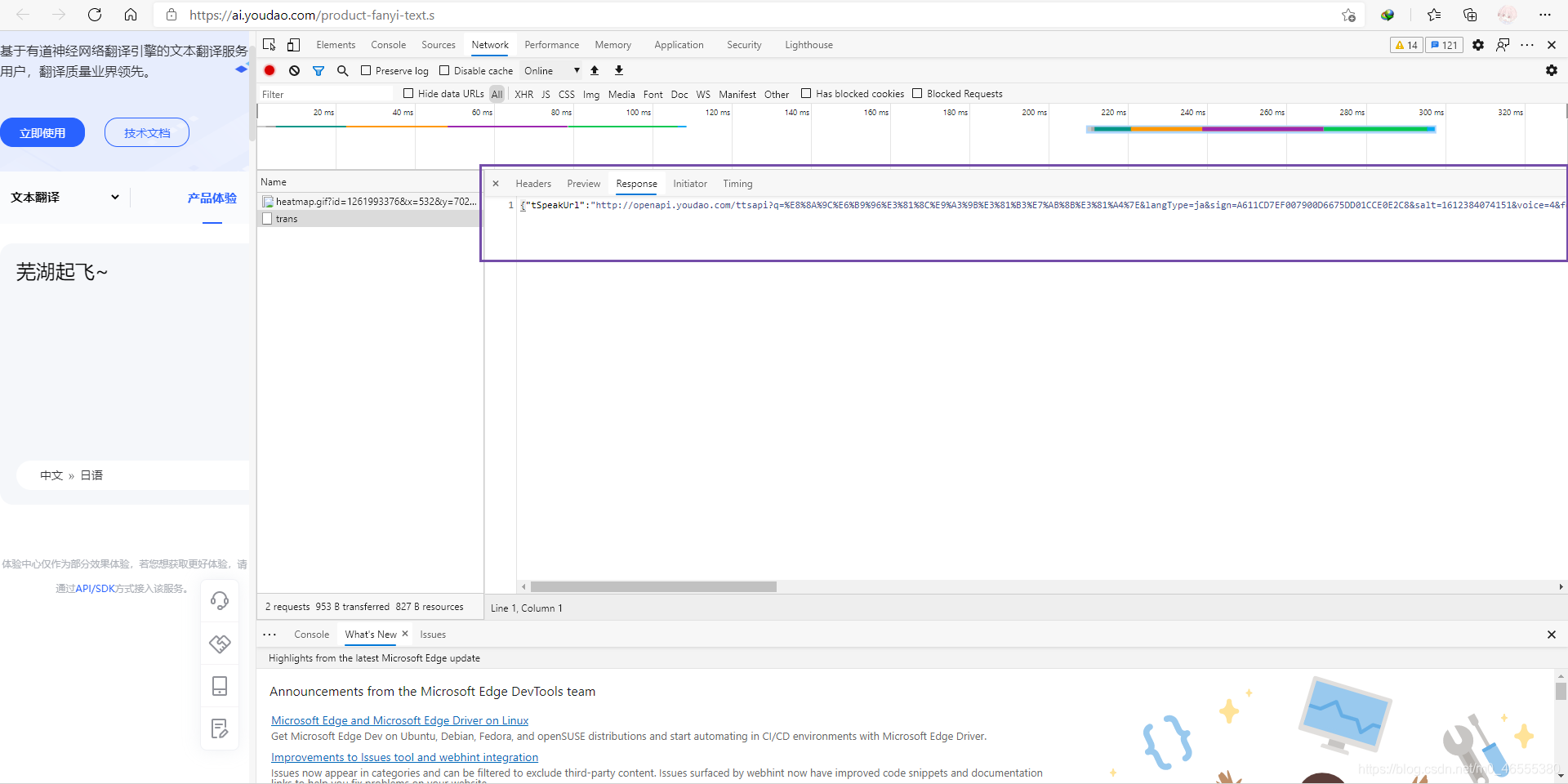
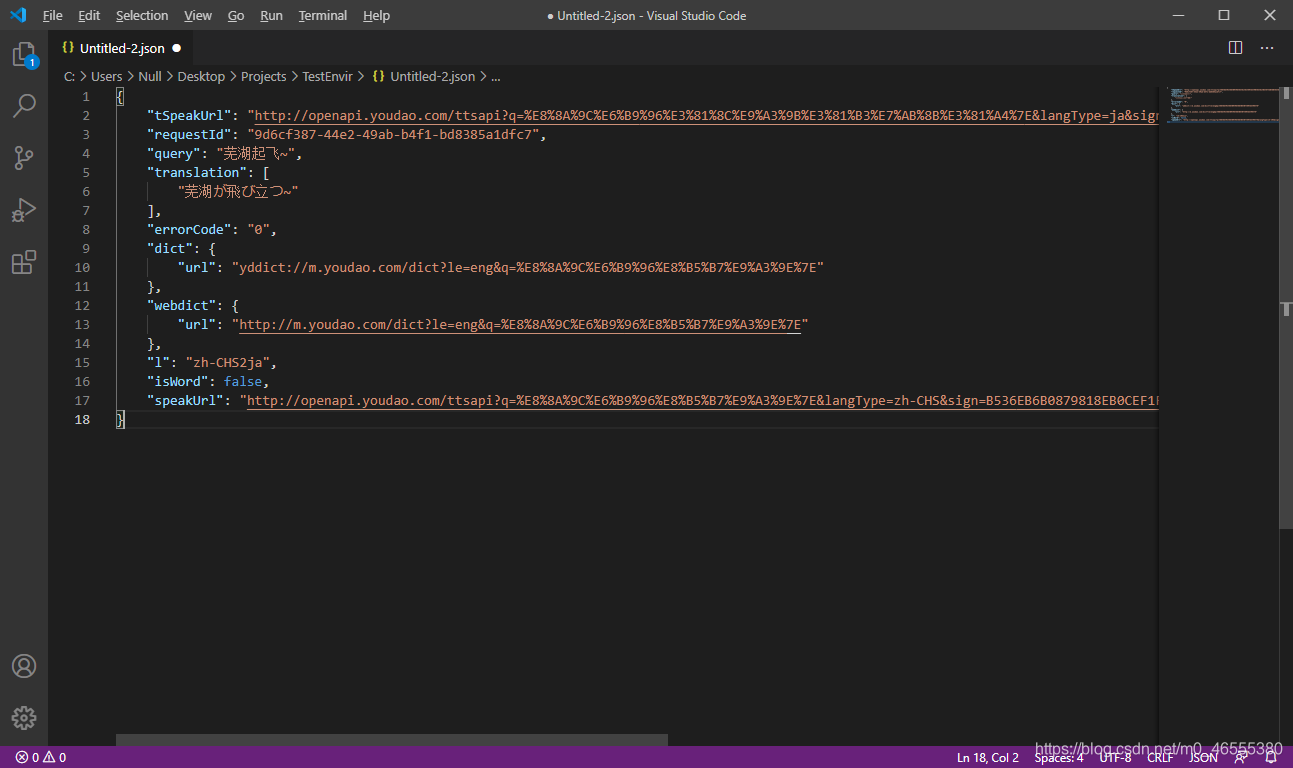
然后, 回到刚刚的网络选项卡, 然后重新翻译一下, 查看返回值.
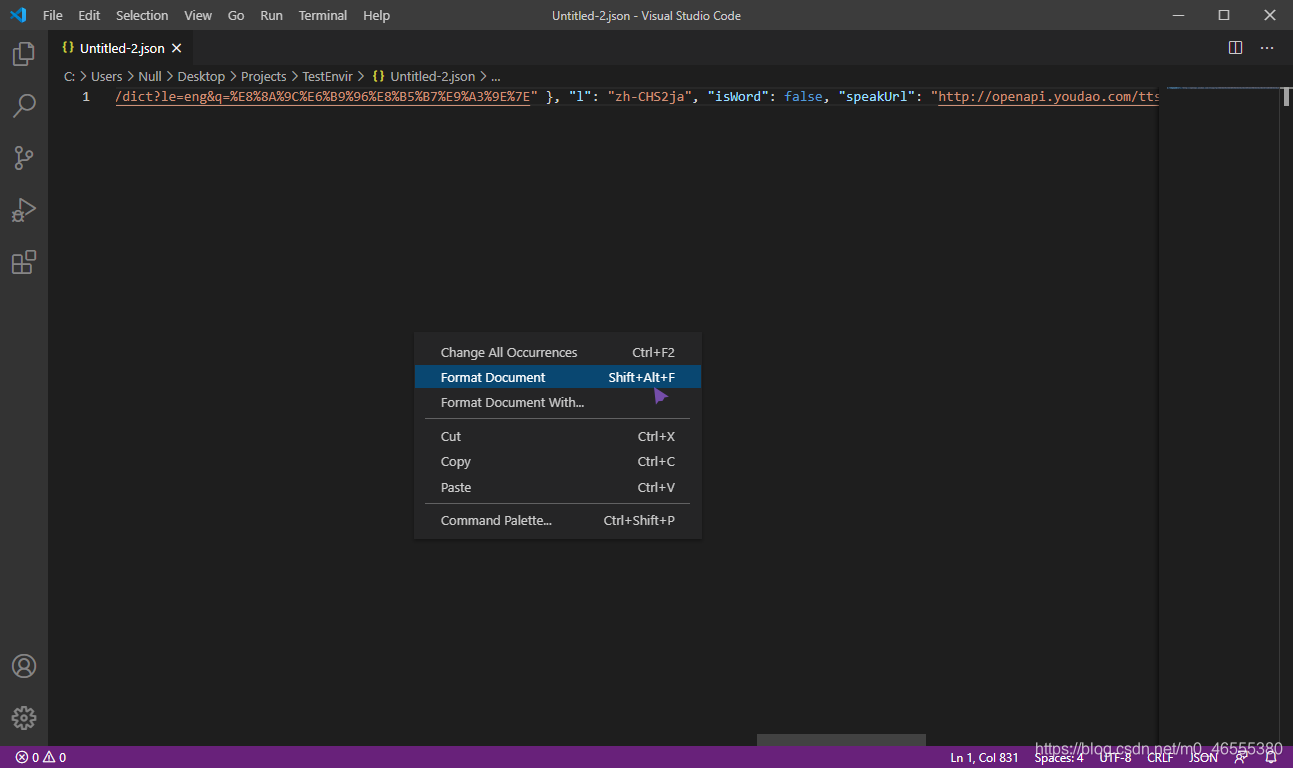
弄到 Visual Studio Code里面, 保存为json文件, 然后格式化文档.
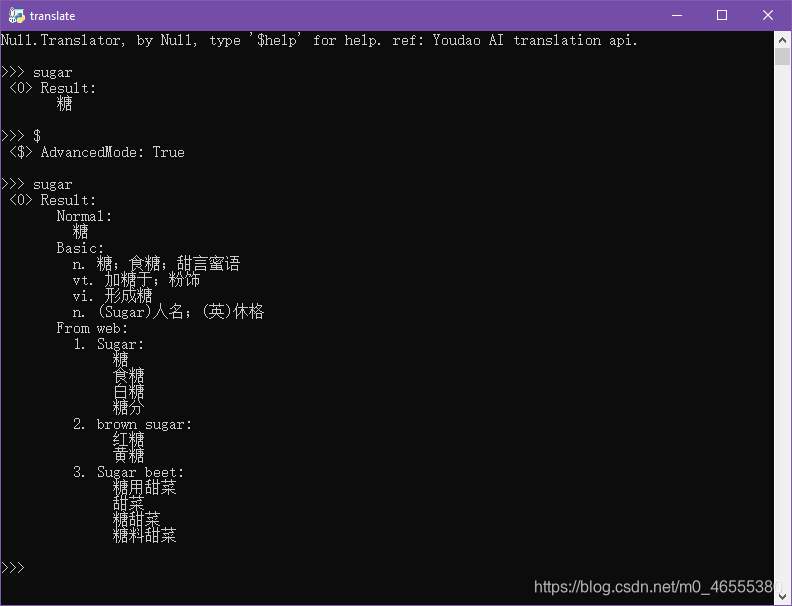
但是, 不止如此, 我们再尝试翻译一些, 词, 例如 sugar, 然后看看返回值, 不出所料, 果然!
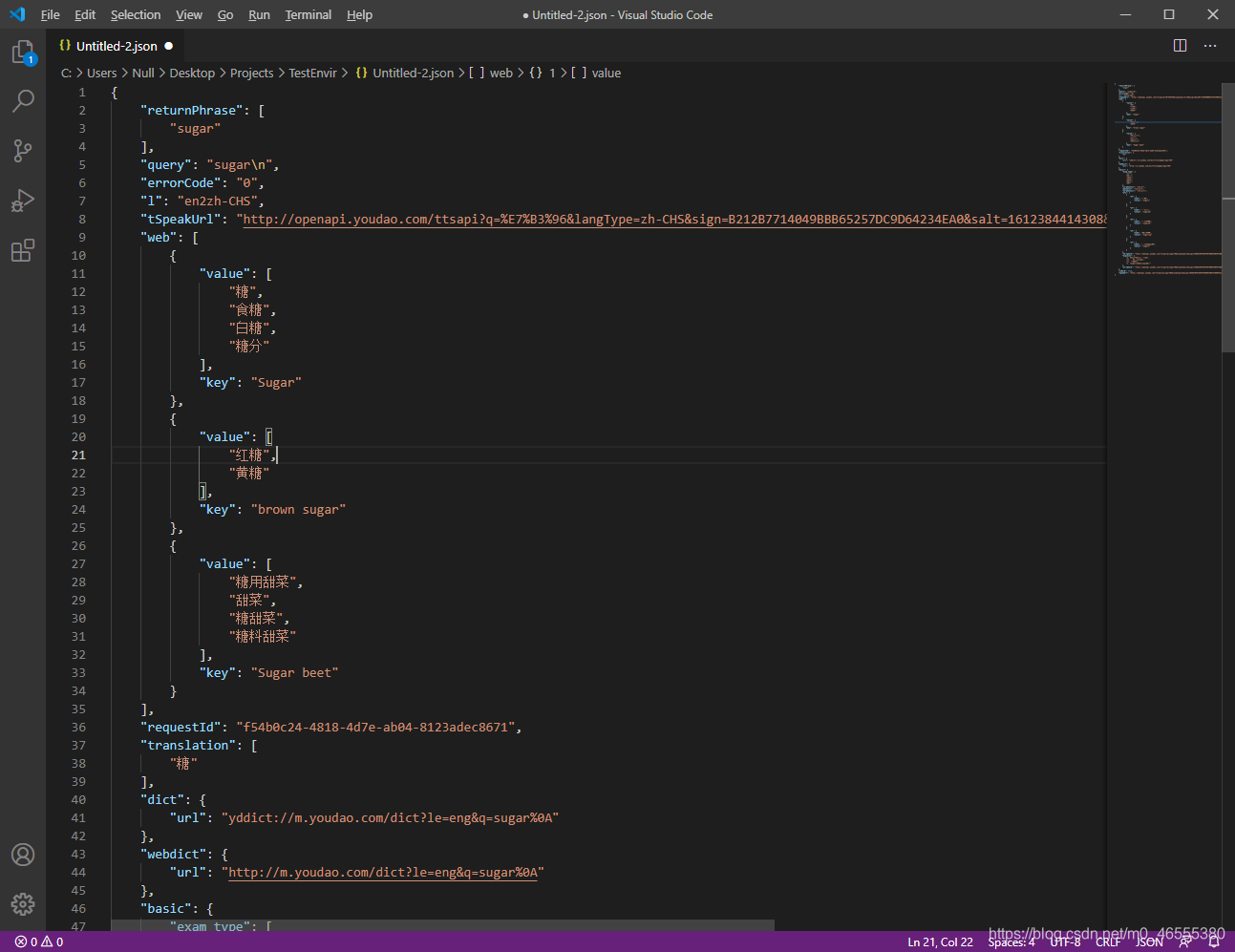
返回值里面包含的内容不是一般的多啊, 甚至还有音标, hhh
{
"returnPhrase": [
"sugar"
],
"query": "sugar\n",
"errorCode": "0",
"l": "en2zh-CHS",
"tSpeakUrl": "http://openapi.youdao.com/ttsapi?q=%E7%B3%96&langType=zh-CHS&sign=B212B7714049BBB65257DC9D64234EA0&salt=1612384414308&voice=4&format=mp3&appKey=2423360539ba5632&ttsVoiceStrict=false",
"web": [
{
"value": [
"糖",
"食糖",
"白糖",
"糖分"
],
"key": "Sugar"
},
{
"value": [
"红糖",
"黄糖"
],
"key": "brown sugar"
},
{
"value": [
"糖用甜菜",
"甜菜",
"糖甜菜",
"糖料甜菜"
],
"key": "Sugar beet"
}
],
"requestId": "f54b0c24-4818-4d7e-ab04-8123adec8671",
"translation": [
"糖"
],
"dict": {
"url": "yddict://m.youdao.com/dict?le=eng&q=sugar%0A"
},
"webdict": {
"url": "http://m.youdao.com/dict?le=eng&q=sugar%0A"
},
"basic": {
"exam_type": [
"初中",
"高中",
"CET4",
"CET6",
"考研",
"SAT"
],
"us-phonetic": "ˈʃʊɡər",
"phonetic": "ˈʃʊɡə(r)",
"uk-phonetic": "ˈʃʊɡə(r)",
"wfs": [
{
"wf": {
"name": "复数",
"value": "sugars"
}
},
{
"wf": {
"name": "过去式",
"value": "sugared"
}
},
{
"wf": {
"name": "过去分词",
"value": "sugared"
}
},
{
"wf": {
"name": "现在分词",
"value": "sugaring"
}
},
{
"wf": {
"name": "第三人称单数",
"value": "sugars"
}
}
],
"uk-speech": "http://openapi.youdao.com/ttsapi?q=sugar%0A&langType=en&sign=C668ACDF9C58F3D76BADC5B54F1BDEE7&salt=1612384414308&voice=5&format=mp3&appKey=2423360539ba5632&ttsVoiceStrict=false",
"explains": [
"n. 糖;食糖;甜言蜜语",
"vt. 加糖于;粉饰",
"vi. 形成糖",
"n. (Sugar)人名;(英)休格"
],
"us-speech": "http://openapi.youdao.com/ttsapi?q=sugar%0A&langType=en&sign=C668ACDF9C58F3D76BADC5B54F1BDEE7&salt=1612384414308&voice=6&format=mp3&appKey=2423360539ba5632&ttsVoiceStrict=false"
},
"isWord": true,
"speakUrl": "http://openapi.youdao.com/ttsapi?q=sugar%0A&langType=en&sign=C668ACDF9C58F3D76BADC5B54F1BDEE7&salt=1612384414308&voice=4&format=mp3&appKey=2423360539ba5632&ttsVoiceStrict=false"
}
是不是已经有些感到兴奋了呢? 现在, 开始正式Coding吧!
先是以自动识别语言开始吧. 那么, 首先是最基本的导库与定义:
import requests
import json
url = 'https://aidemo.youdao.com/trans'
'''
有道翻译API, 支持get与post
参数: q:翻译文本 from:从语言 to:至语言
语言支持的值: 中文:zh-CHS, 英语:en, 日语:ja, 韩语:ko, 法语:fr, 俄语:ru,
西班牙语:es, 葡萄牙语:pt, 越南语:vi, 德语:de, 印尼语:id
阿拉伯语:ar
错误码: 411:过于频繁 413:访问上限 103:字符太长 410:过于频繁
'''
然后是请求
def translate(text):
try:
data = {"q": text, "from": "auto", "to": "auto"}
resp = requests.post(url, data)
except:
return None
return resp
然后是打印翻译结果:
advancedmode = False # 默认状态下, 不展示所有信息, 当advancedMode为True时, 展示更多内容
def listPrint(obj, iden, ps = ''):
print("\n".join(' ' * iden + ps + str(i) for i in obj))
def printrst(resp):
if resp is not None and resp.status_code == 200:
respJson = json.loads(resp.text)
if advancedmode:
print(" <0> Result:")
if "translation" in respJson:
print(" Normal:")
listPrint(respJson["translation"], 9)
if "basic" in respJson and "explains" in respJson["basic"]:
print(" Basic:")
listPrint(respJson["basic"]["explains"], 9)
if "web" in respJson:
print(" From web:")
index = 1
for i in respJson["web"]:
print(" %d. %s:" % (index, i["key"]))
listPrint(i["value"], 14)
index += 1
# print
else:
print(" <0> Result:")
listPrint(respJson["translation"], 7)
else:
print("Request error, status code: %s" % (resp.status_code if resp != None else "???"))
既然都有advancedMode了, 所以得让用户有办法打开关闭它, 模拟简单的命令行吧, 如果输入的内容是以 $ 开头的, 则判定为命令, 并运行这个命令
def runcmd(cmd):
cmdline = cmd.split(' ')
cmdname = cmdline[0].lower()
if cmdname == '$':
global advancedmode
advancedmode = not advancedmode
print(" <$> AdvancedMode: %s" % advancedmode)
elif cmdname == '$help':
if len(cmdline) == 1:
print(" <$> Help document, type '$help command' for more information.")
listPrint((
"$ : Switch Advanced Mode.",
"$help : Display help document."
""
), 7)
elif len(cmdline) == 2:
if cmdline[1] == '$':
print(" <$> Switch Advanced Mode.")
listPrint((
"Advanced Mode: %s" % advancedmode,
"If advanced mode is enabled, more information will be shown. default value is disabled."
), 7)
else:
print(" <$> Help document: unknown command.")
else:
print(" <$> Help document: unknown usage.")
else:
print(" <$> Unknown command.") # 更多指令, 你来添加吧, 例如切换语言
最后是主程序
if __name__ == "__main__":
print("Null.Translator, by Null, type '$help' for help. ref: Youdao AI translation api.")
while True:
text = input("\n>>> ") # 模拟像Python那样的提示符, 很酷炫的有木有
if text != '':
if text.startswith('$'):
runcmd(text)
else:
resp = translate(text)
printrst(resp)
else:
exit() # 如果输入为空, 则退出, 方便退出程序. (表示懒得挪鼠标 滑稽)
(最后, 上面所有的代码片, 拼在一起, 就能运行, 懒得拼的话, 就点击下面的下载链接下载吧)
再多说一句, 那个API返回的数据辣么多, 想实现什么功能自己随便实现啦~
下载链接:
CSDN站内下载: Null.Translator
预告:
这可不就是一个文本转语音API嘛! 薅有道羊毛真不戳















 271
271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









