







核心观点:别把推理大模型看成普通大模型的简单升级版!这是两种基于不同工作机制、训练方法和运行机制的AI模型。
普通大模型,如ChatGPT、Qwen这些,工作流程是这样的:先用海量文本数据进行预训练,让它学会语言规律和各种知识;然后通过监督微调(SFT)和人类反馈的强化学习(RLHF)进行对齐。
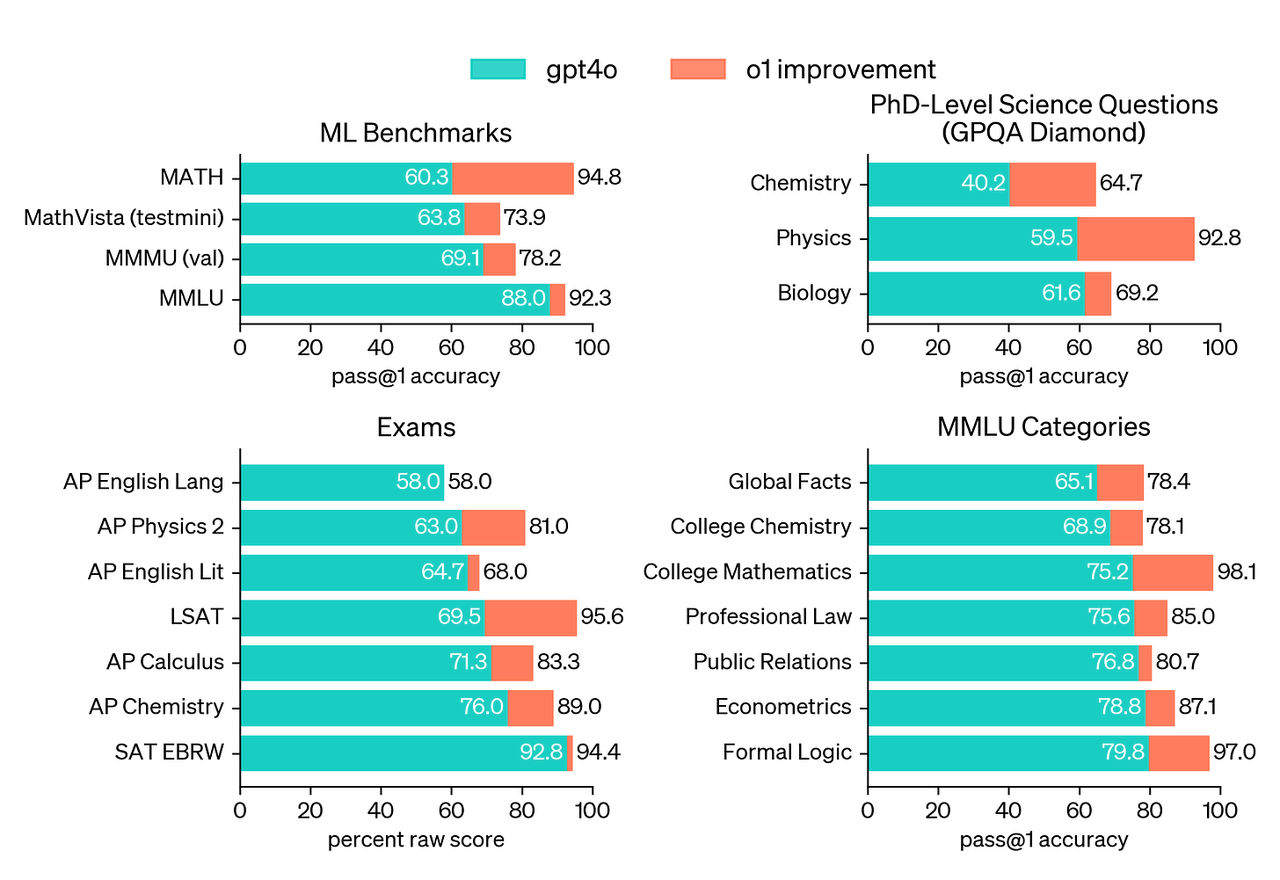
以我自己的使用经验来说,像ChatGPT这类通用模型很会聊天,多轮对话也没问题,但遇到需要一步步推理的任务(比如debug代码),它有时候会给出看起来很对但其实错误的答案。这让我明白,模型的设计目标不同,能干的事也差得远。后来推理大模型出来了,像OpenAI的o系列、DeepSeek的R1、Google的Gemini Flash Thinking,它们在处理数学、编程这种需要多步推导的问题时,会先“想一想”再回答。
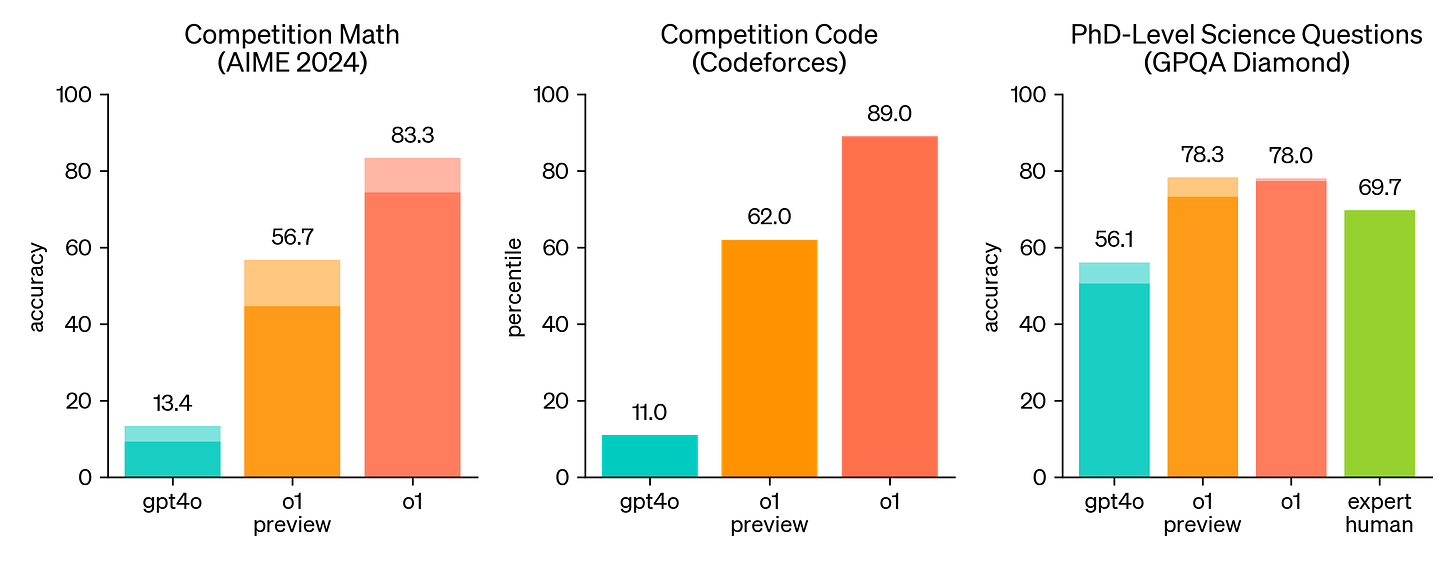
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











