







 本文详细分析了YOLOv2相较于YOLOv1的改进,包括批量归一化加速收敛、去除dropout、高分辨率处理、网络结构调整、候选框优化、偏移量方法改进、特征融合和多尺度训练。YOLO9000通过联合训练扩展了检测类别并引入了WordTree结构来处理多类别的分类问题。
本文详细分析了YOLOv2相较于YOLOv1的改进,包括批量归一化加速收敛、去除dropout、高分辨率处理、网络结构调整、候选框优化、偏移量方法改进、特征融合和多尺度训练。YOLO9000通过联合训练扩展了检测类别并引入了WordTree结构来处理多类别的分类问题。
YOLOv2的改进之处

-
Batch Normalization
加入了批量归一化(现在已经是必然的处理了,相当于开家长会,使得收敛更加的容易,上面是比喻,真实是:这样网络就不需要每层都去学数据的分布,收敛会更快)。舍弃了dropout,因为dropout一般用在全连接层上,而v2基本上将全连接层取消了。所以使用卷积后加批量归一化。

-
High Resolution Classifier
更大的分辨率:原来v1训练用的是224 * 224,测试用的448 * 448.会导致模型水土不服,于是v2版本额外进行了10次448 * 448的微调。为什么v1不用呢,因为当时的计算机计算能力跟不上。224 * 224到448 * 448并不是简单的2倍,而是数量级级别的参数量提升。

-
网络结构变化:原来的v1版本的
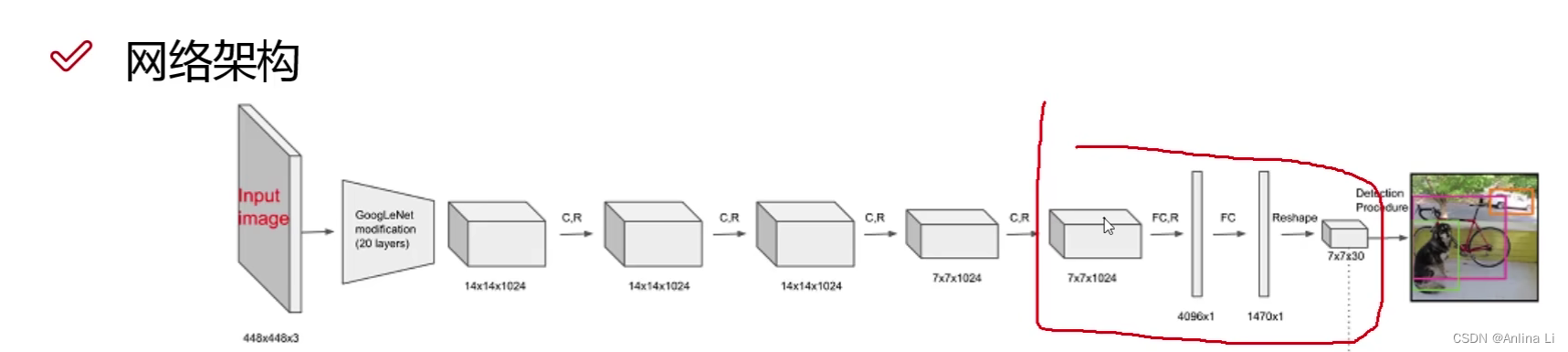
这个位置很奇怪,为什么不直接卷积到7 * 7 * 30呢,于是v2版本就直接卷积了,同时也删除了全连接层。在DarkNet19结构的内部可以看到1 * 1卷积,这就是为了减少参数量。

5次降采样使得特征图大小缩了32倍,而最后得到的希望是奇数,因为这样就有中心点了。所以要用416 * 416
-
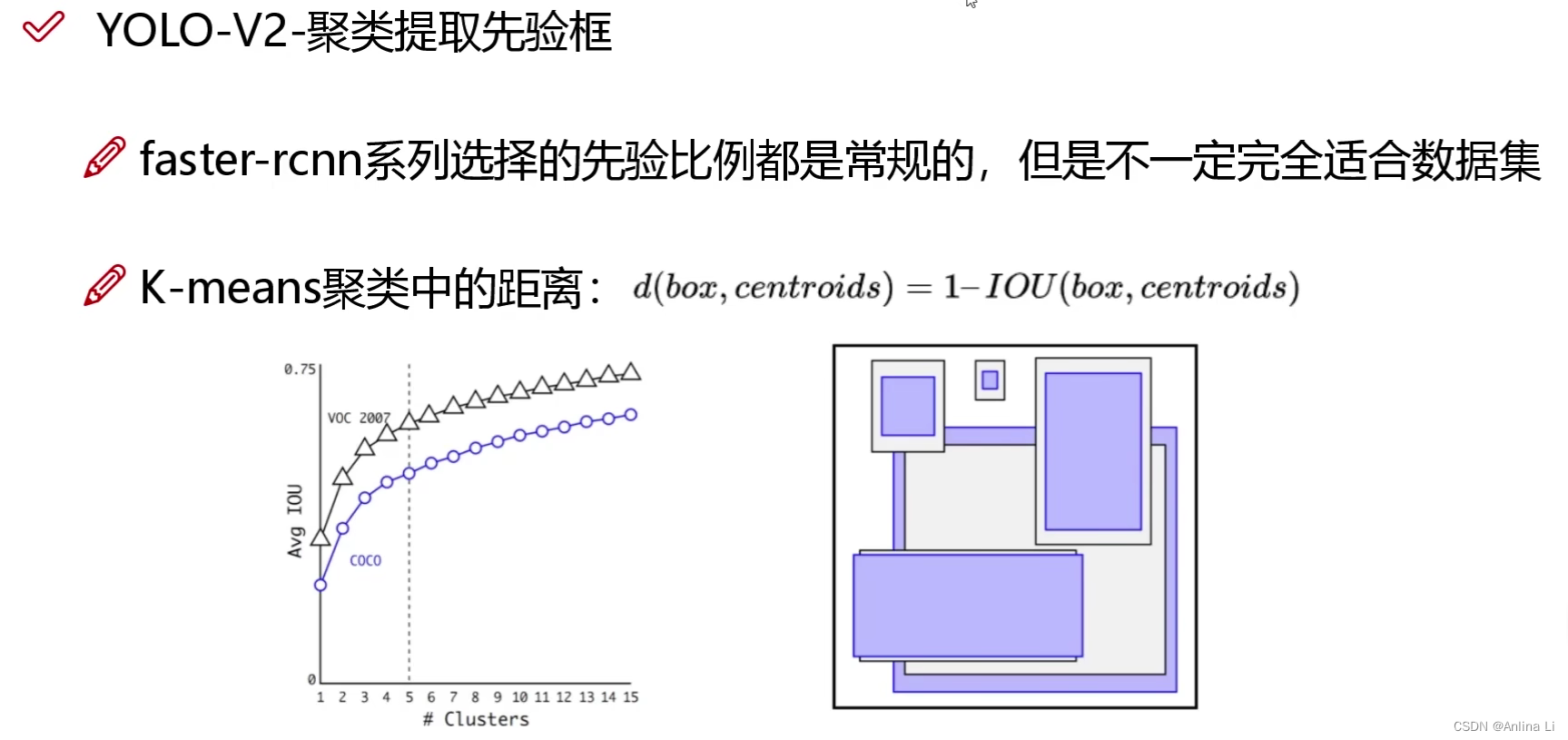
v1版本的候选框只选了2个,且是随机选的,受Faster R-CNN(9个候选框:3种不同大小 * 3种不同比例)启发,同时升级,选择了K-means聚类(对coco和voc数据集中的框聚类)的方法选取了5个(实验得来的数据)候选框。聚类中的距离用的是1-框和框的iou。最后得到的5类选取这五类的中心位置的样本(h和w)作为候选框尺寸。
-
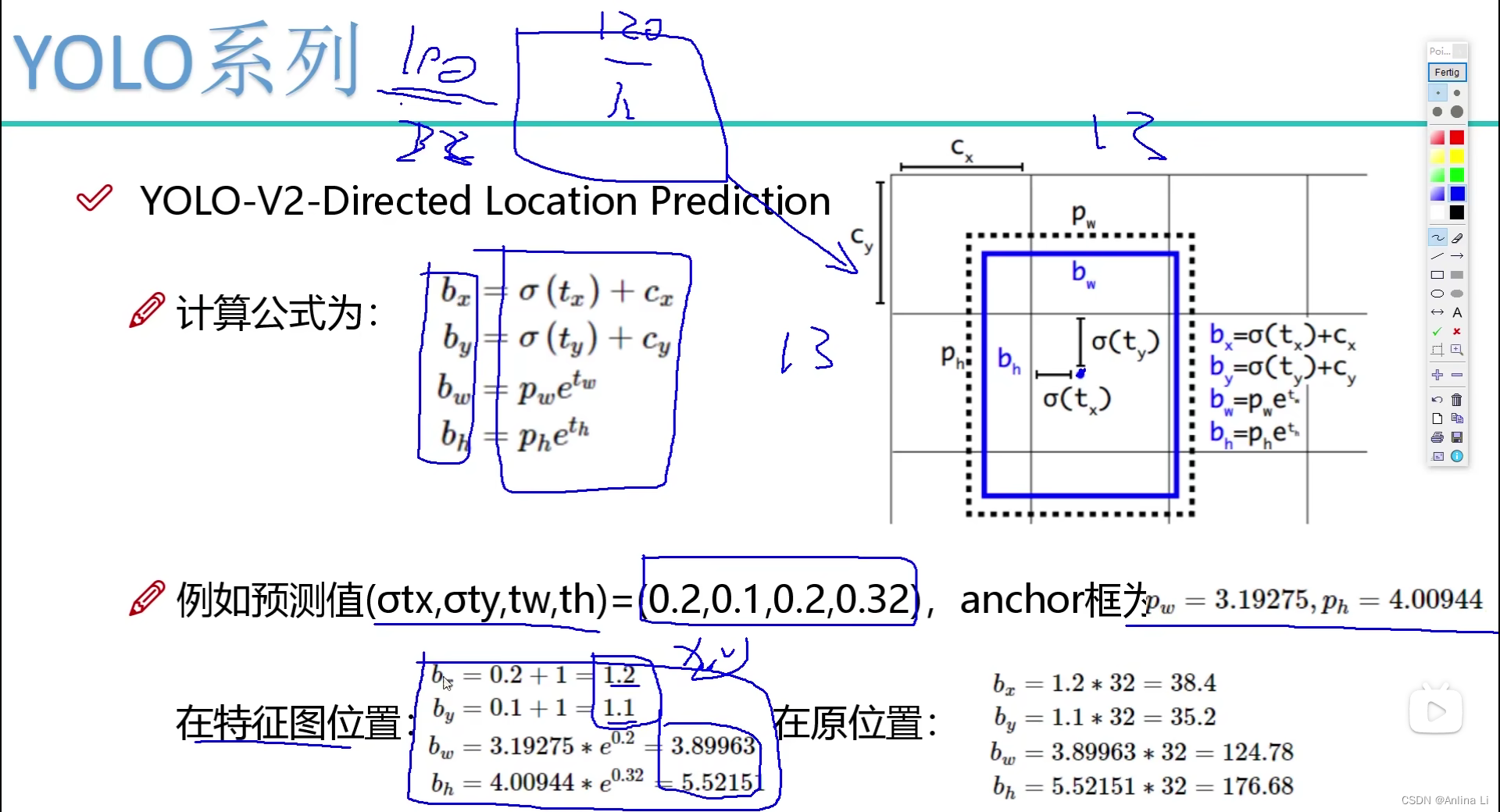
偏移量的方法改进:v1就是简单的预测边界框的坐标。受Faster R-CNN启发,预测偏移量而不是坐标可以简化问题,使网络更容易学习。而预测偏移量就是简单的在原始候选框的基础上加上预测出来的偏移量,这就会导致偏移过头,候选框的中心点飘的不知道哪里去了,会导致收敛问题,模型不稳定。于是v2版本选择了相对单元格的偏移量,总的来说就是再怎么偏移,最后候选框的中心点都是在单元格内部的。

具体的方法就是:对偏移量进行一个函数再加上单元格在单元格特征图中的相对位置cx,h和w也做相对偏移,最后得到了相对特征图位置的四个值,将其映射到原图位置的话就是乘以32,因为一共进行了5次下采样,使得特征图缩小了32倍。
-
特征融合
感受野:越往后的卷积的感受野越大。一个7 * 7的卷积操作和3个3 * 3的卷积操作的感受野一样,但一般选择3 个 3 * 3 的卷积,这是由于后者参数更少,且的多次开家长会(批量归一化)会使收敛效果更好。
论文中常出现浅层特征图一般是纹理特征,深层特征图一般是全局特征,原因就是深层特征图的感受野更大。
v1版本最后一层时感受野太大了,小目标就可能丢失了(v1版本的缺点),于是v2版本融合了之前特征图的特征。
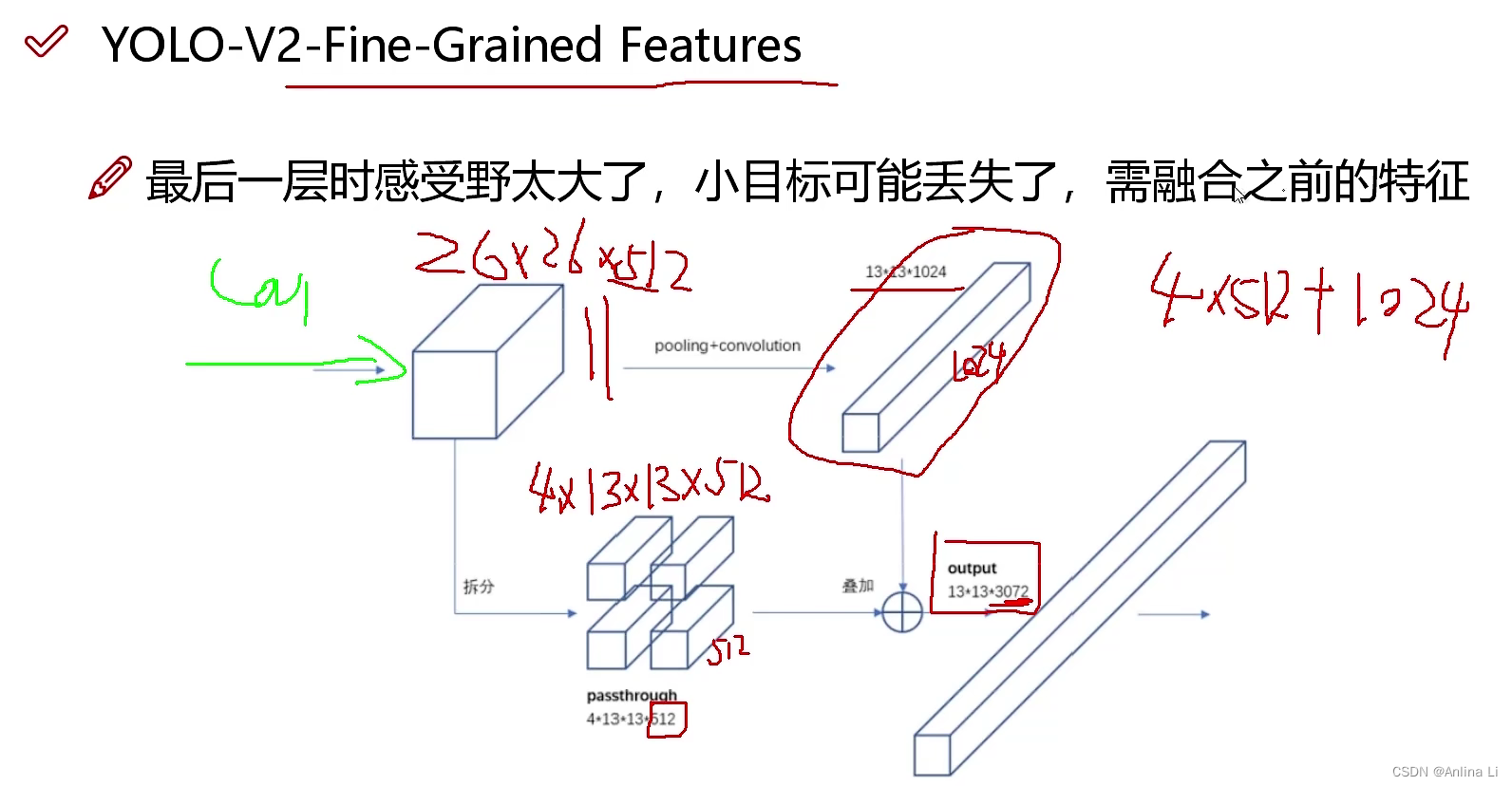
即简单叠加,叠加到通道数上。最后的通道数就变成了3072.
-
多尺度信息:因为变成了全卷积,于是输入数据可以全是320 * 320,也可以全是608 * 608.只需要保证一次迭代一致就好。为什么要多尺度呢?因为v1是简单的将图像进行了resize,导致图像检测效果并不好,同时因为有全连接层在内,所以只能接受固定的输入大小。将多尺度联结在一起之后,效果会更好,适应能力会更强。

充分证明,v1版本的错误分析很好。以后自己也可以试着学习用上。
YOLO9000
YOLOv2是在YOLOv1上进行改进得到的,主要改进方式是上述的几种:批量归一化、更大的分辨率、网络结构的变化(DarkNet)、候选框选择方式变化、偏移量改进、特征融合(加入了直通层)、多尺度信息训练
YOLO9000的主要检测网络是YOLOv2,主要增加了联合训练,通过联合分类的数据和检测的数据使得网络能够检测的分类数更多。
联合训练
输入的图像如果是目标检测标签的,就在模型中反向传播目标检测的损失函数。输入的图像如果是分类标签,那么久反向传播分类的损失函数。
由于COCO中的分类比较粗,ImageNet中的分类细,就会产生一张图是狗,也是金毛,而网络会选择概率最大的进行分类,就会导致“金毛”的分类失效,这是一个问题,作者用了一种方式 来解决这个问题。
WordTree方式
- 背景:由于ImageNet的分类标签是从WordNet中获取的,这是一个语言库,是有向图。而有向图复杂所以作者将图用一种方式重制作了树状结构WordTree(9418个类)。在WordTree结构上进行操作,需要预测的是每一个节点相对于父节点的条件概率,要计算某个几点的绝对概率 或者说联合概率,就直接从他乘到根节点。
YOLO9000是怎样进行联合训练的?
YOLO9000采用 YOLO v2的结构,Anchorbox由原来的5调整到3,对每个Anchorbox预测其对应的边界框的位置信息x , y , w , h和置信度以及所包含的物体分别属于9418类的概率,所以每个Anchorbox需要预测4+1+9418=9423个值。每个网格需要预测3×9423=28269个值。在训练的过程中,当网络遇到来自检测数据集的图片时,用完整的 YOLO v2 loss进行反向传播计算,当网络遇到来自分类数据集的图片时,只用分类部分的loss进行反向传播。
YOLO 9000是怎么预测的?
WordTree中每个节点的子节点都属于同一个子类,分层次的对每个子类中的节点进行一次softmax处理,以得到同义词集合中的每个词的下义词的概率。当需要预测属于某个类别的概率时,需要预测该类别节点的条件概率。即在WordTree上找到该类别名词到根节点的路径,计算路径上每个节点的概率之积。预测时, YOLO v2得到置信度,同时会给出边界框位置以及一个树状概率图,沿着根节点向下,沿着置信度最高的分支向下,直到达到某个阈值,最后到达的节点类别即为预测物体的类别。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









