








一、结构介绍
- 为啥是 5 层而不是 4 层或者 6 层,emmm,这应该去问作者本人,可能对于当时作者拿到的数据集来说,这个层数的表现更好,但不代表所有的数据集这个结构都适合。我们该多关注这种 Encoder-Decoder 的设计思想,具体实现则应该因数据集而异。
- 网络体系结构如图1所示。它包括一条收缩路径(左侧)和一条扩张路径(右侧)。收缩路径遵循卷积网络的典型架构。它由两个3x3卷积(未填充卷积)的重复应用组成,每个卷积后面都有一个整流线性单元(ReLU)和一个2x2 max池化操作,步幅为2,用于下采样。在每个降采样步骤中,我们将特征通道的数量加倍。扩展路径中的每一步都包括特征映射的上采样,然后是一个将特征通道数量减半的2x2卷积(\up-convolution”),一个与收缩路径中相应裁剪的特征映射的连接,以及两个3x3卷积,每个卷积后面都有一个ReLU。由于在每次卷积中边界像素的损失,裁剪是必要的。在最后一层,使用1x1卷积将每个64个组件的特征向量映射到所需的类数量。这个网络总共有23个卷积层。
二、创新点与疑惑问题
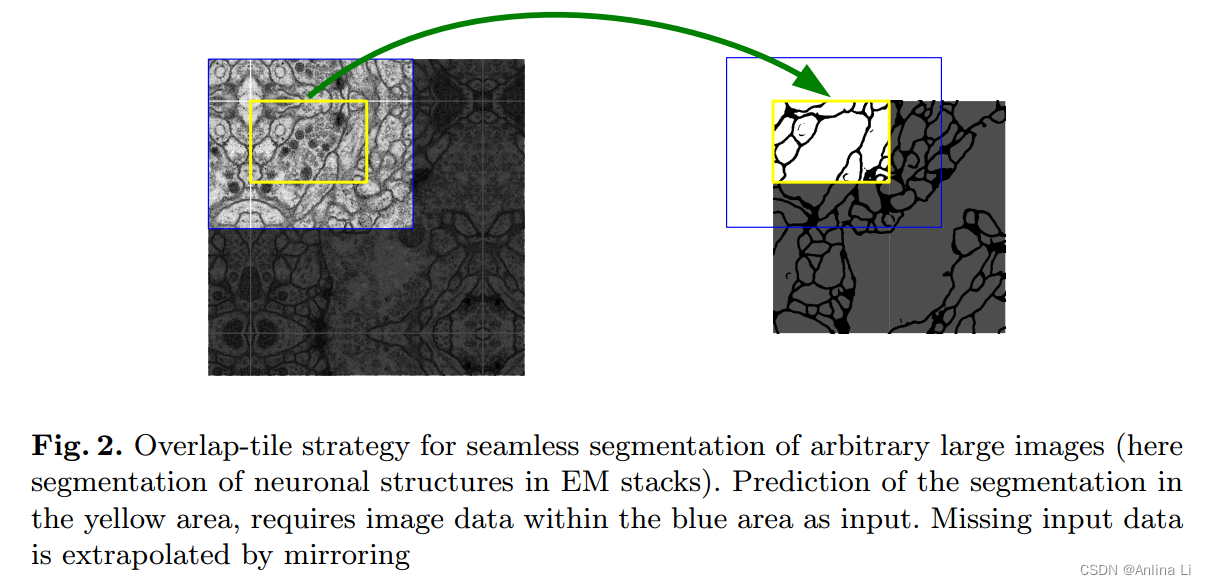
1.overlap-tile strategy
- 可以看到最开始输入的图像尺寸是(572,572),channel=1的灰度图像, 经过第一波卷积二连,尺寸已经变成(568,568),channel=64的feature map了。
- 经过一顿疯狂的不带padding的卷积操作,最后的输出已经(388,388)了,channel=2,两个channel分别为foreground和background的mask,及白色的细胞区域和黑色的背景区域,也就是完成了segmentation。
- 显然,如果生生把原始图像喂进来,最后输出的结果,会比原始图像小好多。我们希望输入跟输出尺寸一样,即不能强行scale up最后的输出,又不想给每层卷积加padding(我的理解,连续对feature map加padding卷积,会使得padding进来的feature误差越来越大,因为越卷积,feature的抽象程度越高,就更容易受到padding的影响)
- 于是就简单粗暴的在最开始直接通过padding扩大输入图像,使得最后输出的结果正好是原始图像的尺寸。在这篇论文中,用的mirror padding, 视场景可以使用别的padding方法
- 最开始接触 U-Net 的时候并不知道原作使用了 Overlap-tile 这种策略,因此当时不太理解为何网络结构要设计成非对称形式,即上采样得到的特征图尺寸与对应层在下采样时的尺寸不一致。
- 另外发现,这种策略可用于许多场景,特别是当 数据量较少 或者 不适合对原图进行缩放时尤其适用(缩放通常使用插值算法,主流的插值算法如双线性插值具有低通滤波的性质,会使得图像的高频分量受损,从而造成图像轮廓和边缘等细节损失,可能对模型学习有一定影响),同时它还能起到为目标区域提供上下文信息的作用。
- 在输入网络前对图像进行padding,使得最终的输出尺寸与原图一致。特别的是,这个padding是镜像padding,这样,在预测边界区域的时候就提供了上下文信息。
- 上图左边是对原图进行镜像padding后的效果,黄框是原图的左上角部分,padding后其四周也获得了上下文信息,与图像内部的其它区域有类似效果。
- Overlap-tile策略可搭配patch(图像分块)一起使用。当内存资源有限从而无法对整张大图进行预测时,可以对图像先进行镜像padding,然后按序将padding后的图像分割成固定大小的patch。这样,能够实现对任意大的图像进行无缝分割,同时每个图像块也获得了相应的上下文信息。另外,在数据量较少的情况下,每张图像都被分割成多个patch,相当于起到了扩充数据量的作用。更重要的是,这种策略不需要对原图进行缩放,每个位置的像素值与原图保持一致,不会因为缩放而带来误差。
- patch可以通俗地理解为图像块,当需要处理的图像分辨率太大而资源受限(比如显存、算力等)时,就可以将图像划分成一个个小块,这些小的图像块就是patch。
- 基于上述另外补充一点:为何要划分patch而不使用resize缩小分辨率呢?
- 通常情况下,resize没有太大问题。但在处理图像分割问题时,由于是dense prediction,属于像素级的预测,因此会尽量要求精确。
- 而resize操作大多是对图像进行插值处理,本质上一种滤波,在像素级别上会造成损失(对传统图像处理有了解的应该知道某些滤波效果会使图像变得模糊),即:某些位置上的像素值是通过多个位置加权计算出来的,从而限制了模型预测结果的上限。因为你给的源图像本来就是不精确的,基于这不精确的源信号作为监督,训练出来的模型性能自然就局限在那里了。
- 相对地,划分patch只是把原来的大图分成一个个小图,而这些小图依然是原图的部分,像素值没有改动,因而在理论上,训练出来模型的上限能够比基于resize得到的图像训练来的高。
2.弹性变形–数据增强
tips:在针对线分割的问题,经常都会出现中间断裂的情况。后期经过不断工程验证,发现弹性变形这种数据增强有助于解决该问题
-
对于我们的任务,可用的训练数据很少,我们通过对可用的训练图像应用弹性变形来使用过度的数据增强。这允许网络学习这种变形的不变性,而不需要在注释的图像语料库中看到这些转换。这在生物医学分割中尤其重要,因为变形曾经是组织中最常见的变化,并且可以有效地模拟真实的变形。Dosovitskiy等[2]在无监督特征学习的范围内证明了数据增强对学习不变性的价值。
-
弹性变形的具体理论步骤如下:
-
step1:对图像imageA进行仿射变换(三点法),得到imageB,关于仿射变换可以看: 马同学;
-
step2:对imageB图像中的每个像素点随机生成一个在x和y方向的位移,△x和△y。其位移范围在(-1, 1)之间,得到一个随机位移场(random displacement fields);
-
step3:用服从高斯分布的N(0, δ)对step2中生成的随机位移场进行卷积操作(和CNN中的卷积操作一样,说白了就是滤波操作)。我们知道δ越大,产生的图像越平滑。下图是论文中的不同δ值对随机位移场的影响,下图左上角为原图,右上角为δ较小的情况(可以发现,位移方向非常随机),左下角和右下角为较大的不同δ值。

-
step4:用一个控制因子α与随机位移场相乘,用以控制其变形强度;
-
step5:将随机位移场施加到原图上,具体是怎么施加的呢?首先,生成一个和imageB大小一样的meshgrid网格meshB,网格中的每个值就是像素的坐标,比如说meshgrid网格大小为512x512,则meshgrid中的值为(0, 0), (0, 1), …, (511, 0), (511, 511),然后将随机位移场和meshB网格相加,这就模拟了imageB中的每个像素点在经过随机位移场的作用后,被偏移的位置,meshB与随机位移场相加后的结果记做imageC。
-
step6:弹性变形最终输出的imageC中每个位置的灰度值大小,组成一副变形图像,现在imageC中每个像素点存储的是(x+△x, y+△y),如下图中的A’,那怎么转化成灰度值呢,依据论文,作者是根据imageB中的B位置的双线性插值灰度值作为A’点的像素灰度值大小,最终将imageC输出得到变形图像。

-
3.copy and crop什么操作?灰色箭头
这一关键步骤融合了底层信息的位置信息与深层特征的语义信息,并且它采用的是拼接的方式,具体来说,当网络完成反卷积之后,就会将反卷积的结果与Encoder中对应步骤的特征图拼接起来,需要注意的是,Encoder特征图尺寸稍大,将其修剪过后进行拼接。拼接会保留了更多的维度/位置 信息,这使得后面的 layer 可以在浅层特征与深层特征自由选择,这对语义分割任务来说更有优势
4.将相互接触的细胞分割开来,即将同类别相互接触的目标分开
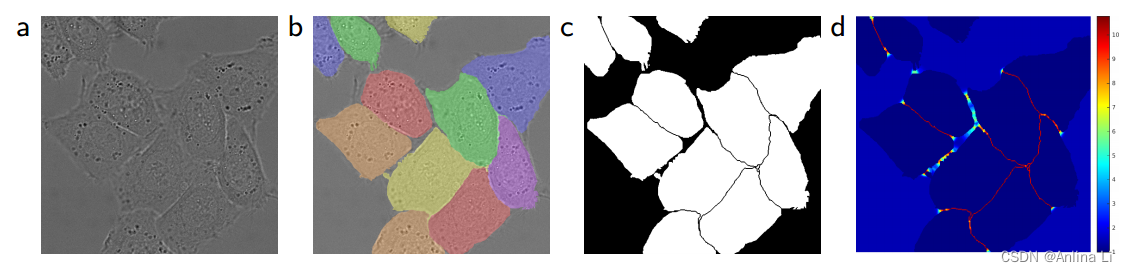
- 在细胞分割任务中的另一个挑战是,如何将同类别的相互接触的目标分开,如上图
- 我们提出了使用一种带权重的损失(weighted loss)。
- 在损失函数中,分割相互接触的细胞会获得更大的权重。
三、论文实验与论文结论
当只有很少的训练样本可用时,数据增强对于教会网络所需的不变性和鲁棒性是必不可少的。 对于微观图像,我们主要需要平移和旋转不变性以及对变形和灰度值变化的鲁棒性。特别是训练样本的随机弹性变形似乎是训练具有很少注释图像的分割网络的关键概念。我们在粗糙的3 × 3网格上使用随机位移向量生成平滑变形。位移从具有10个像素标准差的高斯分布中采样。然后使用双三次插值计算逐像素位移。收缩路径末端的退出层执行进一步的隐式数据扩充。
u-net架构在不同的生物医学分割应用中取得了很好的性能。 由于弹性变形的数据增强,它只需要很少的注释图像,并且在NVidia Titan GPU (6 GB)上只有10小时的训练时间。我们提供了完整的基于Caffe[6]的实现和经过训练的网络。我们确信,u-net架构可以很容易地应用于更多的任务。
感兴趣的目标尺寸非常小,对于尺寸极小的目标,U-Net分割性能可能会不好,分割效果也不好。















 1042
1042











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









