







大数据-hadoop HA
大数据-hadoop HA
HA
- 主从集群:结构相对简单,主与从协作
- 主:单点,数据一致好掌握
问题:
- 单点故障,集群整体不可用
- 压力过大,内存受限
HDFS解决方案:
单点故障:
- 高可用方案:HA(High Available)
- 多个NN,主备切换,主
压力过大,内存受限:
- 联帮机制: Federation(元数据分片)
- 多个NN,管理不同的元数据
- HADOOP 2.x 只支持HA的一主一备
Namenode元数据:
1.cli交互操作mkdir /a
2.dn提交的block
HA:数据同步(cli的操作)
分布式:强一致性破坏可用性
CAP原则
Consistency:一致性
Availability:可用性
Partition tolerance:分区容忍性

Paxos 算法
Paxos算法是莱斯利·兰伯特于1990年提出的一种基于消息传递的一致性算法。
这个算法被认为是类似算法中最有效的。
该算法覆盖全部场景的一致性。
每种技术会根据自己技术的特征选择简化算法实现。
传递:NN之间通过一个可靠的传输技术,最终数据能同步就可以
*我们一般假设网络等因素是稳定的
*类似一种带存储能力的消息队列
简化思路:
分布式节点是否明确
节点权重是否明确
强一致性破坏可用性
过半通过可以中和一致性和可用性
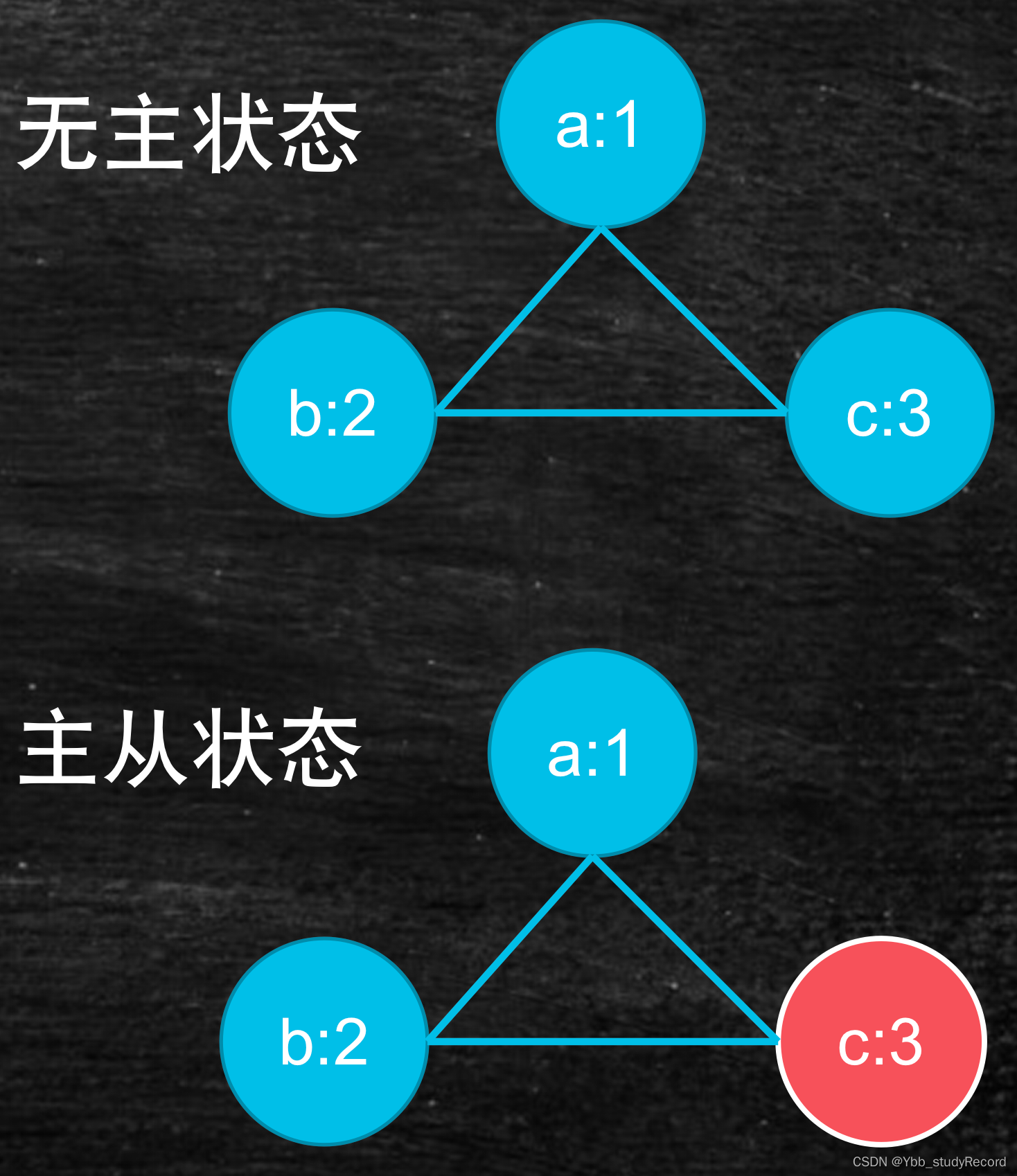
最简单的自我协调实现:主从
主的选举:明确节点数量和权重
主从的职能:
主:增删改查
从:查询,增删改传递给主
主与从:过半数同步数据
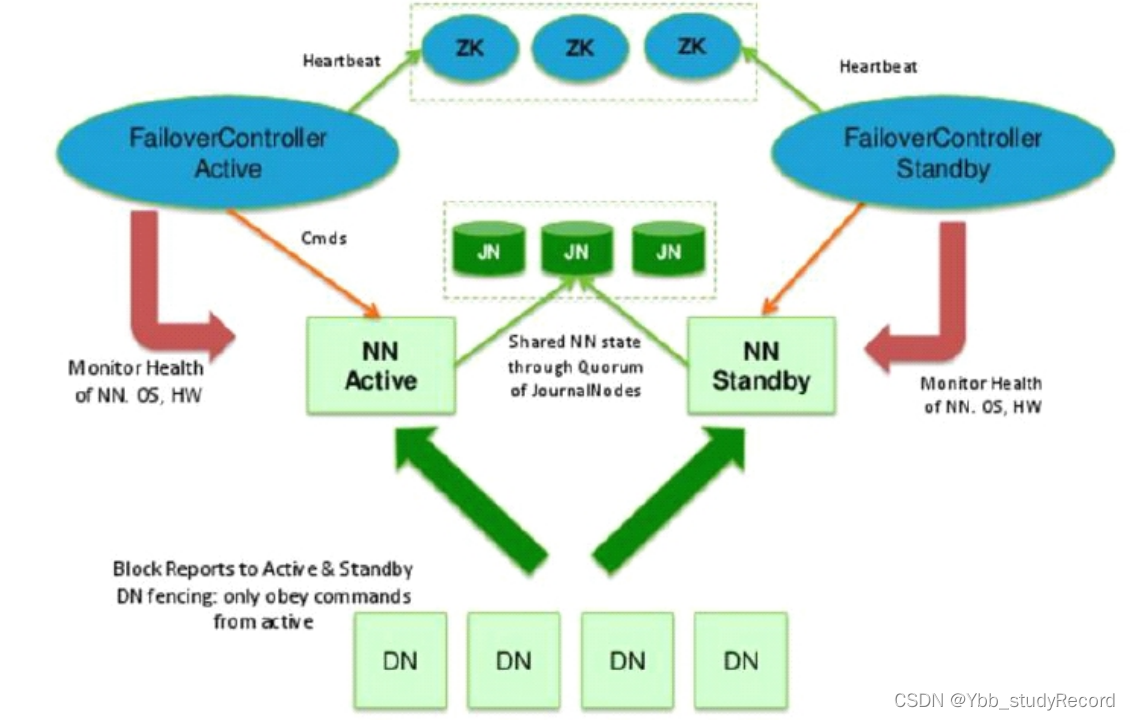
HA方案:
多台NN主备模式,Active和Standby状态
Active对外提供服务
增加journalnode角色(>3台),负责同步NN的editlog
最终一致性
增加zkfc角色(与NN同台),通过zookeeper集群协调NN的主从选举和切换
事件回调机制
DN同时向NNs汇报block清单
Federation
NN的压力过大,内存受限问题:
元数据分治,复用DN存储
元数据访问隔离性
DN目录隔离block
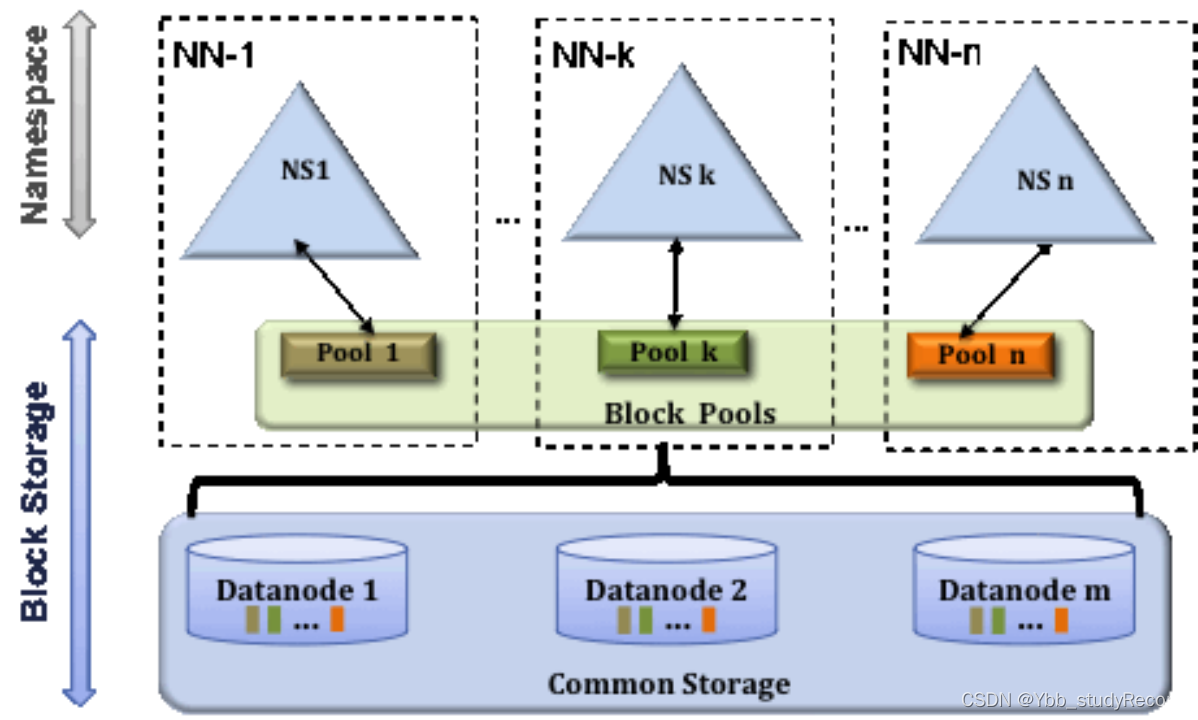
HDFS Federation是解决namenode内存瓶颈问题的水平横向扩展方案。
Federation意味着在集群中将会有多个namenode和namespace。这些namenode之间是联合的,也就是说,他们之间相互独立且不需要互相协调,各自分工,管理自己的区域。分布式的datanode被用作通用的数据块存储存储设备。每个datanode要向集群中所有的namenode注册,且周期性地向所有namenode发送心跳和块报告,并执行来自所有namenode的命令。
Federation一个典型的例子就是上面提到的NameNode内存过高问题,我们完全可以将上面部分大的文件目录移到另外一个NameNode上做管理.更重要的一点在于,这些NameNode是共享集群中所有的DataNode的,它们还是在同一个集群内的。
这时候在DataNode上就不仅仅存储一个Block Pool下的数据了,而是多个 。
概括起来:
- 多个NN共用一个集群里的存储资源,每个NN都可以单独对外提供服务。
- 每个NN都会定义一个存储池(block pool),有单独的id,每个DN都为所有存储池提供存储。
- DN会按照存储池id向其对应的NN汇报块信息,同时,DN会向所有NN汇报本地存储可用资源情况。
实操
FULL -> HA:
HA模式下:有一个问题,你的NN是2台?在某一时刻,谁是Active呢?client是只能连接Active
core-site.xml
fs.defaultFs -> hdfs://node01:9000
配置:
core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node02:2181,node03:2181,node04:2181</value>
</property>
hdfs-site.xml
#以下是 一对多,逻辑到物理节点的映射
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node02:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node02:50070</value>
</property>
#以下是JN在哪里启动,数据存那个磁盘
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node01:8485;node02:8485;node03:8485/mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/var/bigdata/hadoop/ha/dfs/jn</value>
</property>
#HA角色切换的代理类和实现方法,我们用的ssh免密
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
#开启自动化: 启动zkfc
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
流程:
基础设施
ssh免密:
1)启动start-dfs.sh脚本的机器需要将公钥分发给别的节点
2)在HA模式下,每一个NN身边会启动ZKFC,
ZKFC会用免密的方式控制自己和其他NN节点的NN状态
应用搭建
HA 依赖 ZK 搭建ZK集群
修改hadoop的配置文件,并集群同步
初始化启动
1)先启动JN hadoop-daemon.sh start journalnode
2)选择一个NN 做格式化:hdfs namenode -format <只有第一次搭建做,以后不用做>
3)启动这个格式化的NN ,以备另外一台同步 hadoop-daemon.sh start namenode
4)在另外一台机器中: hdfs namenode -bootstrapStandby
5)格式化zk: hdfs zkfc -formatZK <只有第一次搭建做,以后不用做>
6) start-dfs.sh
使用
1)停止之前的集群
2)免密:node01,node02
node02:
cd ~/.ssh
ssh-keygen -t dsa -P '' -f ./id_dsa
cat id_dsa.pub >> authorized_keys
scp ./id_dsa.pub node01:`pwd`/node02.pub
node01:
cd ~/.ssh
cat node02.pub >> authorized_keys
3)zookeeper 集群搭建 java语言开发 需要jdk 部署在2,3,4
node02:
tar xf zook....tar.gz
mv zoo... /opt/bigdata
cd /opt/bigdata/zoo....
cd conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
datadir=/var/bigdata/hadoop/zk
server.1=node02:2888:3888
server.2=node03:2888:3888
server.3=node04:2888:3888
mkdir /var/bigdata/hadoop/zk
echo 1 > /var/bigdata/hadoop/zk/myid
vi /etc/profile
export ZOOKEEPER_HOME=/opt/bigdata/zookeeper-3.4.6
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin
. /etc/profile
cd /opt/bigdata
scp -r ./zookeeper-3.4.6 node03:`pwd`
scp -r ./zookeeper-3.4.6 node04:`pwd`
node03:
mkdir /var/bigdata/hadoop/zk
echo 2 > /var/bigdata/hadoop/zk/myid
*环境变量
. /etc/profile
node04:
mkdir /var/bigdata/hadoop/zk
echo 3 > /var/bigdata/hadoop/zk/myid
*环境变量
. /etc/profile
node02~node04:
zkServer.sh start
4)配置hadoop的core和hdfs
5)分发配置
给每一台都分发
6)初始化:
1)先启动JN hadoop-daemon.sh start journalnode
2)选择一个NN 做格式化:hdfs namenode -format <只有第一次搭建做,以后不用做>
3)启动这个格式化的NN ,以备另外一台同步 hadoop-daemon.sh start namenode
4)在另外一台机器中: hdfs namenode -bootstrapStandby
5)格式化zk: hdfs zkfc -formatZK <只有第一次搭建做,以后不用做>
6) start-dfs.sh
使用验证:
1)去看jn的日志和目录变化:
2)node04
zkCli.sh
ls /
启动之后可以看到锁:
get /hadoop-ha/mycluster/ActiveStandbyElectorLock
3)杀死namenode 杀死zkfc
kill -9 xxx
a)杀死active NN
b)杀死active NN身边的zkfc
c)shutdown activeNN 主机的网卡 : ifconfig eth0 down
2节点一直阻塞降级
如果恢复1上的网卡 ifconfig eth0 up
最终 2编程active














 352
352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









