






中文命名实体识别的研究
Chinese NER Using Lattice LSTM
动机
对于中文分词而言,基于字符的方法优于基于词的方法。基于字符的方法的缺点是显式的word和word sequence信息没有充分利用。如何更好地利用中文NER的单词信息已得到持续关注,其中分割信息已被用作NER的软特征,联合分割和NER已经使用对偶分解、多任务学习等进行了研究。然而,上述方法可能会受到分割训练数据和分割错误的影响,但本文中的方法不需要分词器,并且由于不考虑多任务设置,该模型在概念上更简单。
疑问
Chinese NER is correlated with word segmentation. In particular, named entity boundaries are also word boundaries. One intuitive way of performing Chinese NER is to perform word segmentation first, before applying word sequence labeling.The segmentation ->NER pipeline, however,can suffer the potential issue of error propagation, since NEs are an important source of OOV in segmentation, and incorrectly segmented entity boundaries lead to NER errors.
方法
本文通过使用格结构LSTM表示句子中的词典词,将潜在词信息集成到基于字符的LSTM-CRF中。由于在格中具有指数数量的单词字符路径,文章中利用格LSTM结构来自动控制从句子开头到结尾的信息流。门结构被用于动态路由从不同路径到每个字符的信息。
Model
使用LSTM-CRF作为主要的网络框架,将字符级输入序列表示为 s = c 1 , c 2 , . . . , c m s=c_1,c_2,...,c_m s=c1,c2,...,cm,其中 c j c_j cj表示第 j j j个字符, s s s还可以进一步被看作词序列 s = w 1 , w 2 , . . . , w n s=w_1,w_2,...,w_n s=w1,w2,...,wn, w j w_j wj表示第 j j j个单词,使用 t ( i , k ) t(i,k) t(i,k)表示在第 i i i个单词中的第 k k k个字符的实际索引值。例如,如果语义是“南京市 长江大桥”,则 t ( 2 , 1 ) = 4 , t ( 2 , 2 ) = 5 t(2,1)=4,t(2,2)=5 t(2,1)=4,t(2,2)=5,本文使用BIOES模式对基于词和基于字符的NER进行标记。
Character-Based Model
最基本的character-based model很简单,如下图所示:
x
j
C
=
e
C
(
c
j
)
x^C_j=e^C(c_j)
xjC=eC(cj),其中
c
j
c_j
cj是第
j
j
j个字符。
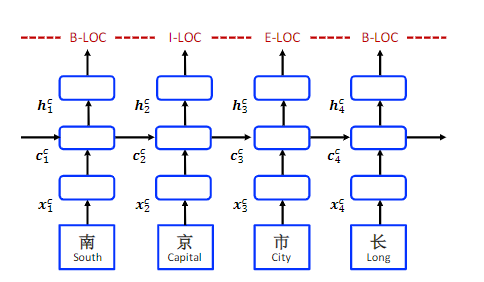
- Char + bichar
在词分割中,字符二元组对于表示字符已经被证明是有用的,通过将二元嵌入与字符嵌入连接起来,用二元信息增强基于字符的表示。
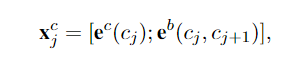
- Char + softword
已经表明,使用分割作为基于字符的NER模型的软特征可以提高性能。通过将分割标签连接到字符嵌入来使用分割信息来增强字符表示。 e S e_S eS为分割标签嵌入查找表, s e g ( c j ) seg(c_j) seg(cj)表示给定一个单词分割器在字符c j c_j cj上的分割标签。
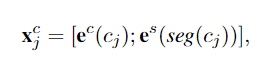
Word-Based Model
e
w
(
w
i
)
e^w(w_i)
ew(wi)表示每个词的嵌入表示。这种也太容易出错了:想象一下,如果“南京市长江大桥”是“南京市长”+“江大桥”,则“江大桥”可能不在词典中,这就会造成分割错误。

Integrating character representations
字符CNN和LSTM都已经被用于表示一个词中的字符序列。将词
w
i
w_i
wi中的字符序列表示为
X
i
C
X^C_i
XiC,一个新的词表示被获得通过连接
e
w
(
w
i
)
和
X
i
C
e^w(w_i)和X^C_i
ew(wi)和XiC。
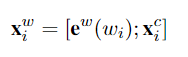
词中的字符序列表示
X
i
C
X^C_i
XiC有以下三种方法。
- Word + char LSTM
假设每个输入字符 j j j的嵌入为 e C ( c j ) e^C(c_j) eC(cj),使用一个双向的LSTM去学习词 w i w_i wi包含的字符 c t ( i , 1 ) , . . . , c t ( i , l e n ( i ) ) c_{t(i,1)},...,c_{t(i,len(i))} ct(i,1),...,ct(i,len(i))的隐藏状态 h ⃗ t ( i , 1 ) c , . . . , h ⃗ t ( i , l e n ( i ) ) c \vec{h}^c_{t(i,1)},...,\vec{h}^c_{t(i,len(i))} ht(i,1)c,...,ht(i,len(i))c和 h ⃗ t ( i , 1 ) c , . . . , h ⃗ t ( i , l e n ( i ) ) c \vec{h}^c_{t(i,1)},...,\vec{h}^c_{t(i,len(i))} ht(i,1)c,...,ht(i,len(i))c - Word + char LSTM’
- Word + char CNN
CNN-Based Chinese NER with Lexicon Rethinking
动机
应用长短期记忆整合词典的字符级命名实体识别取得了巨大成功,但是这种方法无法利用GPU的并行性,并且候选词典可能会发生冲突。
研究现状
- 已经有比较基于词和基于字符的方法的明确讨论,这表明由于当前中文分词的性能有限,基于字符的名称标注器可以胜过基于词的标注器。
- Zhang and Yang[2018]利用基于RNN的格结构同时对字符和词典中的相应单词进行建模,从而防止分割错误。然而,格结构的LSTM存在效率低下和单词冲突的问题。
疑问
Compared with English NER, Chinese named entities are more difficult to identify due to their uncertain boundaries, complex compositions, and NE definitions within the nest.
方法
使用基于再思考机制的卷积神经网络来整合词典,将卷积操作的窗口大小设置为2,所有可能的词都可以轻松融合到相应位置,具有特定长度的单词对应于特定层中的不同位置,所提出的方法可以并行建模与句子匹配的所有字符和潜在方法。大多数现有的中文NER模型仅使用前馈结构来学习特征,他们在看到整个句子后没有机会修改冲突的词典信息,重新思考机制可以通过反馈高级特征来细化网路进而解决单词冲突。
Lexicon-Based CNNs
假设
C
=
{
c
1
,
c
2
,
.
.
.
,
c
M
}
C= \lbrace c_1,c_2,...,c_M\rbrace
C={c1,c2,...,cM},
ν
\nu
ν是字符词汇表(所有字符的嵌入表示),
c
m
c_m
cm是第m个字符的嵌入表示,
C
∈
R
d
∗
M
C\in R^{d*M}
C∈Rd∗M是整个句子的嵌入表示,词典lexicon中的潜在词word匹配一部分的字符序列,
w
m
l
=
{
c
m
,
.
.
.
,
c
m
+
l
−
1
}
w^l_m=\lbrace c_m,...,c_{m+l-1} \rbrace
wml={cm,...,cm+l−1}表示一个词,这个词的开头字符为
c
m
c_m
cm,这个词的长度为
l
l
l。
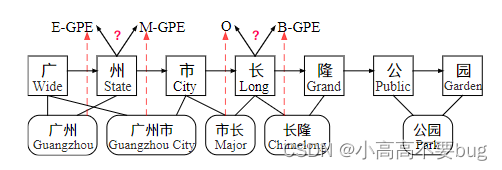
对于上面这句话来说,广州市可以表示为
w
1
3
w^3_1
w13,长隆公园可以表示为
w
4
4
w^4_4
w44。然后采用字符级的CNN去编码字符特征和注意力模块去整合词信息。在CNN中,采用大量大小为
H
∈
R
d
∗
2
H\in R^{d*2}
H∈Rd∗2的卷积核,并且采用的步长也是2,在第一次进行卷积操作的时候得到的是二元词(含两个字符)的信息,在第二次进行卷积操作的时候得到的是三元词(含三个字符)的信息,在第
l
l
l次进行卷积操作的时候得到的是
l
l
l元词(含
l
l
l个字符)的信息,所以说具有特定长度的词对应于特定层中的不同位置。卷积计算公式如下:
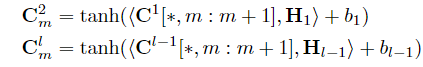
C
[
∗
,
m
:
m
+
1
]
C[*,m:m+1]
C[∗,m:m+1]对应于
C
C
C中的第
m
m
m列到第
m
+
1
m+1
m+1列,上述表达式说明的就是在一个窗口内卷积的计算公式,
<
A
,
B
>
=
T
r
(
A
B
T
)
<A,B>=Tr(AB^T)
<A,B>=Tr(ABT)其实就是卷积操作,对应元素相乘再求和。其中,
c
m
l
c^l_m
cml代表第
l
l
l层中
l
l
l元组的特征。每一层都能进行这样的卷积运算,个人猜测每一层卷积核应该是
d
∗
(
d
∗
2
)
d*(d*2)
d∗(d∗2)的,即有
d
d
d个卷积核。并且在每一层中都有填充,填充到序列长度为M,不然序列会越来越短,不方便后面的运算。
接下来就是整合注意力机制,得到
X
m
1
,
X
m
2
,
.
.
.
,
X
m
L
X^{1}_m,X^{2}_m,...,X^{L}_m
Xm1,Xm2,...,XmL(这其中有一些信息是冗余的,有一些字符的组合没有意义),如下:
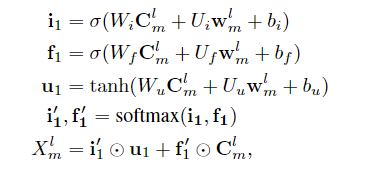
Refining Networks with Lexicon
尽管注意力机制有效的整合词典信息,但是处理潜在词之间的矛盾仍然有困难。在模型中,较低层中包含潜在词的模型不能引用较高层中的词,因此有效地使用高级特征来解决潜在词之间的歧义仍是一个关键问题。
定义CNN顶层特征
X
m
L
X^L_m
XmL作为最高级特征。高级特征参与词向量和CNN特征的重新加权:通过增加一个反馈层给每个CNN层,论文中使用这些特征去重新调整词典注意力模块中的权重:
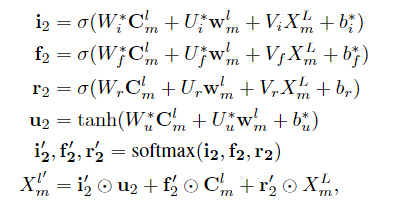
于是更新生成了一堆新的
X
m
1
′
,
X
m
2
′
,
.
.
.
,
X
m
L
′
∈
R
d
∗
1
X^{1'}_m,X^{2'}_m,...,X^{L'}_m\in R^{d*1}
Xm1′,Xm2′,...,XmL′∈Rd∗1。
接下来就是一些信息整合:

最终的输出:
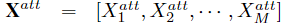
其中,
X
∈
R
M
X\in R^M
X∈RM。
Predicting NER with CRF
假设序列
C
C
C的标签为
y
=
{
y
1
,
.
.
.
,
y
M
}
y=\lbrace y_1,...,y_M \rbrace
y={y1,...,yM},
Υ
(
C
)
\Upsilon (C)
Υ(C)表示关于C的所有标签的组合,标签序列
y
y
y的概率分布为:
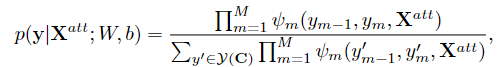
其中,(最后是用了一个CRF层),
W
m
W_m
Wm和
b
m
b_m
bm是分别对应于标签对
(
y
m
−
1
,
y
m
)
(y_{m-1},y_m)
(ym−1,ym)的权重和偏置向量。

在训练阶段,优化模型以最大化下面的条件似然函数:
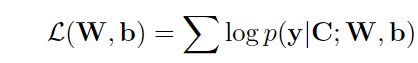
在测试阶段,通过以下方式求得标签:
















 740
740











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









