







 本文详细介绍了PCA(主成分分析)的目的、原理及使用方法,并通过Python实现了PCA对鸢尾花数据集的降维。PCA旨在在降维过程中最大化保留原始信息,通过计算协方差矩阵和特征值来确定降维后的方向。文章讨论了m值选择的依据,以及PCA与LDA在降维和分类目的上的异同。
本文详细介绍了PCA(主成分分析)的目的、原理及使用方法,并通过Python实现了PCA对鸢尾花数据集的降维。PCA旨在在降维过程中最大化保留原始信息,通过计算协方差矩阵和特征值来确定降维后的方向。文章讨论了m值选择的依据,以及PCA与LDA在降维和分类目的上的异同。
PCA公式推导
PCA目的与原理
PCA可以实现在维度较多的时候的降维的功能,并且能在降维的过程中最大的保留原来的变量的所有信息。实现的思路是,对于现存的m维数据,找到k(k<m)维数据来对其进行代替,目标是尽可能减少信息的损失。为了更加直观的认识,我们以二维的数据为例。如下图,存在蓝色的一些数据点,我们希望找到一个比二维维度更低(这里就是这条一维的直线),并且可以用这个维度得到评价指标的相应的值。举例来说,PCA的目的就是,对于一个点,如图中的x1
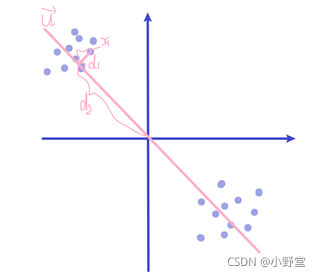
找到一个方向为u的直线,使得x1 到直线的距离 d1尽可能的小,并且可以用d2 来表示x1 的信息。当维度增加的时候,我们不能直观的获取这个 d1,而我们发现这样的直线可以满足在投影之后,样本点的分布尽量的分散,并且在数学中常用方差来衡量样本之间的距离。因此在求解的时候,使用变化后让每个特征内部方差最大化的思想来进行求解。
另外,在实际使用PCA的时候需要注意,要对数据进行标准化,如果维度之间的量纲差异过大,需要对数据进行归一化,这样有利于提升计算的效率。
PCA使用说明
在实际使用PCA的时候,只要这样几个步骤就可以了。
1)先按照数据的特点,对数据进行标准化和归一化的处理。根据数据点计算协方差矩阵。
2)求出协方差矩阵的特征值以及对应的特征向量
3)将特征向量按照对应的特征值大小从上到下按行排列成矩阵,取前k行形成矩阵P
4)Y = PX即为降维到k维后的数据
那么为什么可以这样做呢?我们可以看第三个部分PCA的公式推导来进行理解。
PCA公式推导



关于m值的选择
m值也就是最后降维得到的维数。
一般在现实的问题中,上述降维矩阵中的m值是未知的,因此如何选择降维成为多少的数据呢?
从推导中我们可以发现,虽然m是未知的,但是对应的特征值和特征向量其实是给定的,因此我们利用公式:
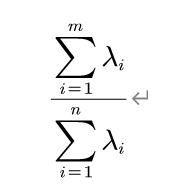
来进行衡量。这个公式代表了降维之后的数据相对于原来信息的保存的信息量的大小的百分比。有多种选择方式来选择合适的k,一般可以选择百分比大于80%的时候,可以认为这个m是可以接受的m。(因为m过小的时候,不能留存足够的信息)
Python实现PCA对于鸢尾花数据进行降维
利用PCA降维,使得鸢尾花数据集只有两个特征&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









