







1.聚合函数
| 函数 | 说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
–统计班级共有多少同学SELECT COUNT(*) FROM students;
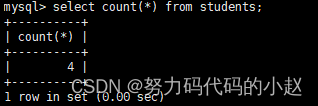
–统计本次考试的数学成绩分数个数select count(math) from exam_result;
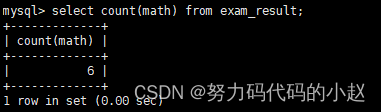
–统计数学成绩总分:select sum(math) from exam_result;
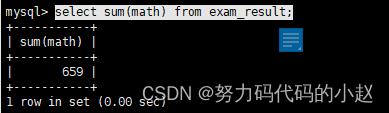
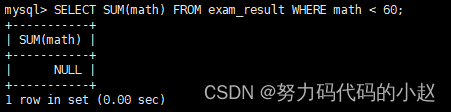
– 不及格 < 60 的总分,没有结果,返回 NULL:SELECT SUM(math) FROM exam_result WHERE math < 60;
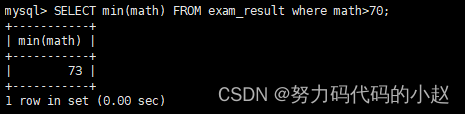
–统计平均总分:SELECT avg(math+chinese+english) FROM exam_result;
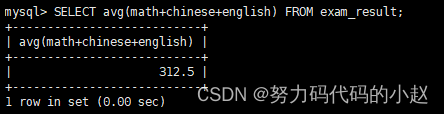
–返回英语最高分:SELECT max(english) FROM exam_result;
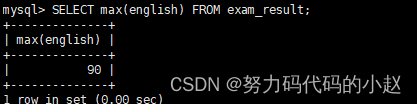
–返回 > 70 分以上的数学最低分:SELECT min(math) FROM exam_result where math>70;
2.group by子句
在select中使用group by 子句可以对指定列进行分组查询
库中有三张表,表结构如下
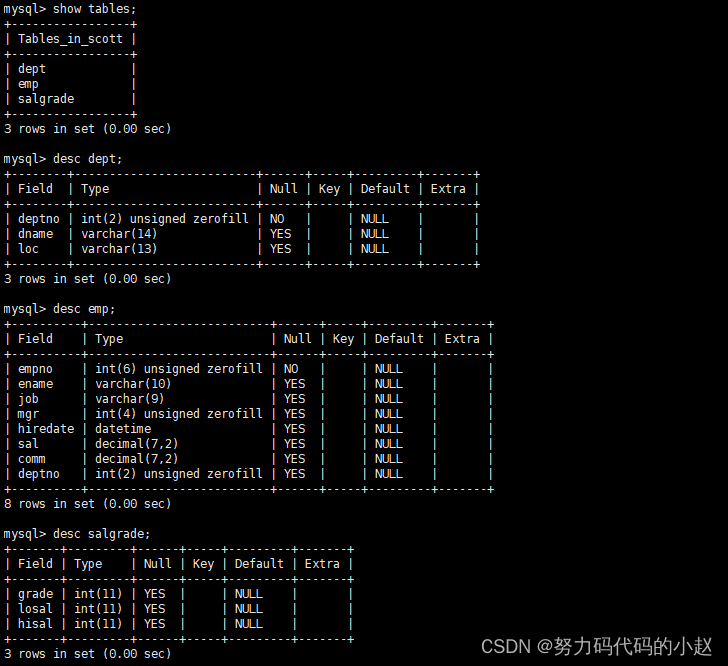
–显示每个部门的平均工资和最高工资:select avg(sal),max(sal) from emp group by deptno;
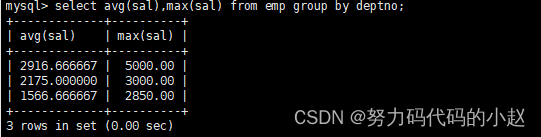
–显示每个部门的每种岗位的平均工资和最低工资:select avg(sal),min(sal),deptno,job from emp group by deptno,job;
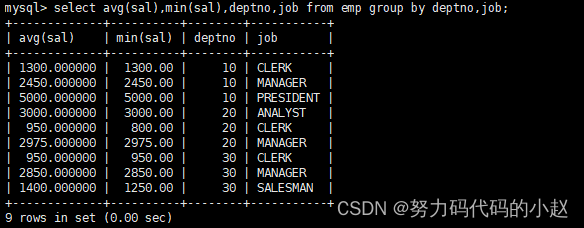
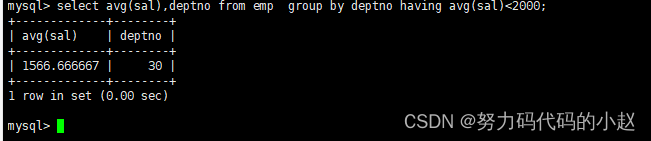
–显示平均工资低于2000的部门和它的平均工资:select avg(sal),deptno from emp group by deptno having avg(sal)<2000;
聚合函数只能使用having进行筛选,因为聚合函数是得先有数据才能聚合统计,而where是必须先有条件才能筛出数据,这两者是冲突的。


















 2964
2964











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











