







《linux内核设计与实现》
内核数据结构
1、链表
1.1 单向链表和双向链表
以下是一个最简单的数据结构表达一个链表
/* an element in a linked list */
struct list_element {
void *data; /* the payload */
struct list_element *next; /* pointer to the next element */
};
下图是一个单项链表

下图表示一个双向链表
/* an element in a linked list */
struct list_element {
void *data; /* the payload */
struct list_element *next; /* pointer to the next element */
struct list_element *prev; /* pointer to the previous element */
};

1.2 环形链表
上述两种链表中,最后一个元素会指向NULL,表示为链表尾,在环形链表中,最后一个元素,指向链表的首元素。
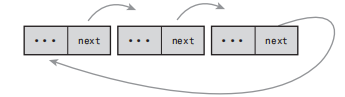
下图是一个环形单向链表
下图为一个环形双向链表
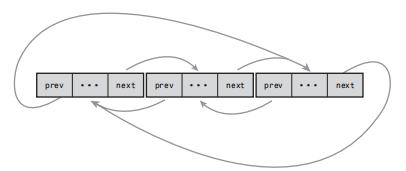
在linux内核中,标准链表采用环形双向链表实现
1.3 沿链表移动
沿链表的移动只能是线性移动,只能通过指针不断往下去访问下一个元素,对于需要随机访问的,一般使用链表。
有的链表采用头指针表示,在环形链表中,向后指向元素的尾元素,遍历一个冤死可以从第一个元素开始也可以从最后一个元素开始,当然还可以从中间的任意一个元素开始遍历访问。
1.4 linux内核中的实现
1、链表数据结构
在普通的链表实现方式中,其采用的是将链表指针嵌入我们的数据结构,如下,其中next指向下一个结构体,prev指向前一个结构体:
struct fox {
unsigned long tail_length; /* length in centimeters of tail */
unsigned long weight; /* weight in kilograms */
bool is_fantastic; /* is this fox fantastic? */
struct fox *next; /* next fox in linked list */
struct fox *prev; /* previous fox in linked list */
};
而在linux中,在2.1内核之后首次引入官方的内核链表实现,其采用的是将链表节点塞入数据结构,如下:
struct list_head {
struct list_head *next
struct list_head *prev;
};
struct fox {
unsigned long tail_length; /* length in centimeters of tail */
unsigned long weight; /* weight in kilograms */
bool is_fantastic; /* is this fox fantastic? */
struct list_head list; /* list of all fox structures */
};
在上述结构中,fox的list.next指向下一个元素的list,list.prev指向前一个元素的list。
2、定义一个链表
链表需要在使用前初始化,因为多数的元素都是动态创建的,因此最常见的方法就是在运行的初始化链表。
struct fox *red_fox; //创建一个结构体对象指针
red_fox = kmalloc(sizeof(*red_fox), GFP_KERNEL); //开辟一个空间
red_fox->tail_length = 40;
red_fox->weight = 6;
red_fox->is_fantastic = false;
INIT_LIST_HEAD(&red_fox->list); //将red_fox->list对象初始化为一个链表头
如果想要编译器静态创建,可以用以下方式:
struct fox red_fox = {
.tail_length = 40,
.weight = 6,
.list = LIST_HEAD_INIT(red_fox.list),
};
为了方便从链表指针找到父结构中包含的任何变量,可以通过container_of()宏定义获得,
/******************************************
* 该函数获得ptr指向的对象所存储的地址
* ptr : 成员变量mem的地址
* type : 包含成员变量mem的宿主结构体的类型
* member: 在宿主结构中的mem成员变量的名称
******************************************/
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );})
其中offsetof函数如下:
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
再通过一个函数即可获得包含list_head的父类型结构体:
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
以下对container_of的解释引用了该文章
假设定义结构体struct my_task_list:
#ptr : &first_task.mylist
#type : struct my_task_list
#member : mylist
struct my_task_list {
int val ;
struct list_head mylist;
}
struct my_task_list first_task =
{ .val = 1,
.mylist = LIST_HEAD_INIT(first_task.mylist)
};
而container_of宏的功能就是根据 first_task.mylist字段的地址得出first_task结构的其实地址。
把上面offsetof的宏定义代入container_of宏中,可得到下面定义:
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - ((size_t) &((type *)0)->member) );})
再把宏中对应的参数替换成实参:
const typeof( ((struct my_task_list *)0)->mylist ) *__mptr = (&first_task.mylist); \
(struct my_task_list *)( (char *)__mptr - ((size_t) &((struct my_task_list *)0)->mylist) );})
typeof 是 GNU对C新增的一个扩展关键字,用于获取一个对象的类型 ,比如这里((struct my_task_list *)0)->mylist 是把0地址强制转换成struct my_task_list 指针类型,然后取出mylist元素。 然后再对mylist元素做typeof操作,其实就是获取 my_task_list结构中mylist字段的数据类型struct list_head,所以这行语句最后转化为:
const struct list_head *__mptr = (&first_task.mylist);
第二条语句中在用 __mptr这个指针 减去 mylist字段在 my_task_list中的偏移(把0地址强制转换成struct my_task_list指针类型,然后取出mylist的地址,此时mylist的地址也是相对于0地址的偏移,所以就是mylist字段相对于宿主结构类型struct my_task_list的偏移) 正好就是宿主结构的起始地址。
3、链表头
上诉代码中,表示了如何从一个现有的数据结构改造成链表。但是我们一般需要一个标准索引指针指向整个链表,即头指针。
下述历程初始化了一个名为fox_list的链表历程。
static LIST_HEAD(fox_list);
1.5 操作链表
链表创建后,就需要有增删改查等功能,linux内核提供了一组函数来实现,存放在<linux/list.h>中,且该函数复杂度都为O(1)。
1、向链表添加一个节点
/*** 该函数是像head节点后插入new节点 ***/
list_add(struct list_head *new,struct list_head *head);
/*** 把节点增加到链表尾 ***/
/*** 该函数是向指定链表的head节点前插入new节点 ***/
list_add_tail(struct list_head *new,struct list_head *head);
2、从链表中删除一个节点
/*** 从链表中删除entry元素 ***/
list_del(struct list_head *entry);
该函数从链表中删除一个entry节点,但是并没有释放所占用的内存空间,且更加有趣的是其只传入entry,而没有传入head,其实现代码如下:
static inline void __list_del(struct list_head *prev, struct list_head *next)
{
next->prev = prev;
prev->next = next;
}
static inline void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
}
从list_del实现代码可以看出其只是改变了指针的指向,释放空间还得通过用户自行释放。
下面的的list_del_init除了再次初始化entry以外,其他和list_del类似,因为虽然链表不再需要entry项,但是还可以再次使用包含entry的数据结构体。
/*** 删除一个节点并对其重新初始化 ***/
list_del_init();
3、移动和合并链表节点
/*** 从一个链表移除list项,然后将其加入到另外一个链表的head节点的后面 ***/
list_move(struct list_head *list,struct list_head *head);
/*** 只是将list插入到head项之前,其余与list_move一样 ***/
list_move_tail(struct list_head *list,struct list_head *head);
/*** 检查列表是否为空,空返回非0 ***/
list_empty(struct list_head *head);
/*** 将List指向的链表插入到指定链表的head元素后面 ***/
list_splice(struct list_head *list,struct list_head *head);
/*** 合并两个链表,并初始化list指向的链表 ***/
list_splice_init(struct list_head *list,struct list_head *head);
1.6 遍历链表
linux对于遍历链表的复杂度为O(n),n代表的是链表元素的个数。
1、基本方法
通过list_for_each宏,但该方法实际上是不可用的,原因是我们需要的是一个指向包含list_head结构体对象的指针,如fox,而非一个简单的list_head。
/*** p是指向当前项,即要得到的对象,fox_list是需要遍历的链表的头结点 ***/
struct list_head *p;
list_for_each(p, fox_list) {
/* p points to an entry in the list */
}
2、可用方法
/******************************************************************
* list_for_each_entry是一个宏
* pos是一个指向包含list_head的对象的指针,可以认为是list_entry宏的返回值
* head是指向头节点的指针
* member是pos中list_head结构的变量名
********************************************************************/
list_for_each_entry(pos, head, member); //其内部采用的也是list_entry宏
/*** 使用方法如下 ***/
struct fox *f;
list_for_each_entry(f, &fox_list, list) {
/* on each iteration, ‘f’ points to the next fox structure ... */
}
在内核中有这么一个遍历的使用案例:
static struct inotify_watch *inode_find_handle(struct inode *inode, struct inotify_handle *ih)
{
struct inotify_watch *watch;
//注意list_for_each_entry是一个宏,其定义了一个for循环去遍历
//其中watch接受其搜索查到的对象,然后再通过watch中的ih变量来判断是否是我们要的数据
//inode->inotify_watches头结点
//i_list代表的是在list_head在inode结构中的命名
/** 实现了在inode结构串联起来的inotify_watches链表中
搜索其inotify_handle与所提供的举办相匹配的inotify_watch项 **/
list_for_each_entry(watch, &inode->inotify_watches, i_list) {
if (watch->ih == ih)
return watch; //
}
return NULL;
}
3、反向遍历链表
list_for_each_entry_reverse(pos,head,member);
4、遍历同时删除
在标准的链表中,想要遍历同时删除是不可能的,因为如果我们遍历之后删除一个节点,就无法获得该节点的next,即无法获得删除的节点的下一个节点,而linux提供了这么一个方法,其给我们返回了一个pos也返回了一个next即对下个节点进行了缓存。
/*************************************************
* pos其返回值
* next是接收返回值的下一个节点
* head是头结点
* member是pos中list_head结构的变量名
*************************************************/
list_for_each_entry_safe(pos,next,head,member);
/*** 宏定义 ***/
#define list_for_each_entry_safe(pos, n, head, member) \
for (pos = list_first_entry(head, typeof(*pos), member), \
n = list_next_entry(pos, member); \
&pos->member != (head); \
pos = n, n = list_next_entry(n, member))
以下是linux内核中的对于该函数的使用案例:
注意这里获得节点后,需要对该链表上锁,否则可能会出现多个进程并发删除而导致出错。
void inotify_inode_is_dead(struct inode *inode)
{
struct inotify_watch *watch, *next;
mutex_lock(&inode->inotify_mutex);
list_for_each_entry_safe(watch, next, &inode->inotify_watches, i_list) {
struct inotify_handle *ih = watch->ih;
mutex_lock(&ih->mutex);
inotify_remove_watch_locked(ih, watch); /* deletes watch */
mutex_unlock(&ih->mutex);
}
mutex_unlock(&inode->inotify_mutex);
}
程序历程
#include <linux/types.h>
#include <linux/kernel.h>
#include <linux/delay.h>
#include <linux/ide.h>
#include <linux/init.h>
#include <linux/module.h>
#include <linux/errno.h>
#include <linux/gpio.h>
#include <linux/cdev.h>
#include <linux/device.h>
#include <linux/of_gpio.h>
#include <linux/semaphore.h>
#include <linux/timer.h>
#include <linux/i2c.h>
#include <asm/mach/map.h>
#include <asm/uaccess.h>
#include <asm/io.h>
#include <linux/list.h>
#include "ap3216creg.h"
#include <linux/mutex.h>
#define N 10
struct numlist{
int num;
struct list_head list;
};
struct mutex list_lock;
struct numlist numhead;
static int __init ap3216c_init(void)
{
struct numlist *listnode;
struct list_head *pos;
struct numlist *p;
int i;
printk("doublelist is starting...\r\n");
INIT_LIST_HEAD(&numhead.list);//初始化队列头
mutex_init(&list_lock);
for(i = 0;i < N;i++)
{
listnode = (struct numlist *)kmalloc(sizeof(struct numlist),GFP_KERNEL);
listnode->num = i+1;
//注意在操作队列的时候最好需要上锁,避免多线程操作出现问题
mutex_lock(&list_lock);
list_add_tail(&listnode->list,&numhead.list); //注意传入的是list_head对象
printk("node %d has added to the doublelist\r\n",i);
mutex_unlock(&list_lock);
}
//打印便利列表
i = 1;
list_for_each(pos,&numhead.list){
//在得到pos之后需要通过list_entry来获取其所在的地址,才能够打印其元素
p = list_entry(pos,struct numlist,list);
printk("node %d data is %d\r\n",i,p->num);
i++;
}
return 0;
}
static void __exit ap3216c_exit(void)
{
struct list_head *pos,*n;
struct numlist *p;
//依次删除节点
list_for_each_safe(pos,n,&numhead.list)
{
list_del(pos);
mutex_lock(&list_lock);
p = list_entry(pos,struct numlist,list);
printk("node %d has been del\r\n",p->num);
kfree(p);
mutex_unlock(&list_lock);
}
printk("exit ok \r\n");
}
module_init(ap3216c_init);
module_exit(ap3216c_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("mrchen");
运行结果:

2、队列
队列实现了生产者和消费者的模型,也称为FIFO,即先进先出,队列API存储在<kfifo.h>。

2.1 kfifo
对于队列而言需要有enqueue(入队列)和dequeue(出队列)。kfifo有两个偏移量:入口偏移和出口偏移,前者是下次入队的位置,后者是下次出队的位置,出口便宜总是小于或等于入口便宜,当队列出口等于入口偏移则表示没有数据了,除非有新的入队否则不会再出队。
2.2 创建队列
使用kfifo前,需要对队列进行初始化,一般采用动态分配的方式:
/*********************************************
* 动态创建并且初始化一个大小为size的kfifo
* gfp_mask标识分配队列,在十二章会有
* 成功则返回0,失败返回错误码
*********************************************/
int kfifo_alloc(struct kfifo *fifo,unsigned int size,gfp_t gfp_mask);
//以下是一个例子
struct kfifo fifo;
int ret;
ret = kfifo_alloc(&kifo, PAGE_SIZE, GFP_KERNEL);
if (ret)
return ret;
/*********************************************
* 创建并初始化一个kfifo对象
* 他将使用由buffer指向的size字节大小的内存
* 该函数的内存空间是用户自己分配的
*********************************************/
int kfifo_init(struct kfifo *fifo,void *buffer,unsigned int size);
对于kfifo_alloc和kfifo_init而言,size必须是2的幂
以下是静态分配的方法,并不常用:
//创建一个名称为name,大小为kfifo的对象。
DECLARE_KFIFO(name,size);
INIT_KFIFO(name);
2.3 推入队列数据
/**************************************************
* 把from指针所指向的len字节数据拷贝到fifo所指的队列中
* 成功返回推入字节的大小
* 若剩下队列的空间小于len,则可能返回0或者小于len的值
**************************************************/
unsigned int kfifo_in(struct kfifo *fifo,const void *from,unsigned int len);
2.4 摘取队列数据
//从fifo所指向的队列中拷贝出长度为len字节的数据到to所指向的缓冲中,成功则返回函数拷贝的数据长度
//并且摘除后,数据就会被删除
unsigned int kfifo_out(struct kfifo *fifo, void *to, unsigned int len);
//若不想摘除后数据则采用kfifo_out_peek,与kfifo_out,但是这次摘除的数据也可以下次摘取
//offset参数指向对了中索引的位置,默认为0则读取队列头
unsigned int kfifo_out_peek(struct kfifo *fifo, void *to, unsigned int len, unsigned offset);
2.5 获取队列长度
//获取队列空间总体的大小
static inline unsigned int kfifo_size(struct kfifo *fifo);
//获取队列中已推入的数据大小
static inline unsigned int kfifo_len(struct kfifo *fifo);
//获取队列中还有多少空间
static inline unsigned int kfifo_avail(struct kfifo *fifo);
//判断是否为满/空,若分别是满和空则返回非0,反之则返回0
static inline int kfifo_is_empty(struct kfifo *fifo);
static inline int kfifo_is_full(struct kfifo *fifo);
2.6 重置和撤销队列
//重置队列:意味着抛弃所有队列中的内容
static inline void kfifo_reset(struct kfifo *fifo);
//撤销一个用kfifo_alloc分配的队列
void kfifo_free(struct kfifo *fifo);
2.7 代码历程
#include <linux/types.h>
#include <linux/kernel.h>
#include <linux/delay.h>
#include <linux/ide.h>
#include <linux/init.h>
#include <linux/module.h>
#include <linux/errno.h>
#include <linux/gpio.h>
#include <linux/cdev.h>
#include <linux/device.h>
#include <linux/of_gpio.h>
#include <linux/semaphore.h>
#include <linux/timer.h>
#include <linux/i2c.h>
#include <asm/mach/map.h>
#include <asm/uaccess.h>
#include <asm/io.h>
#include <linux/list.h>
#include "ap3216creg.h"
#include <linux/kfifo.h>
#define N 10*sizeof(int)
struct kfifo kfifo_tmp;
static int __init ap3216c_init(void)
{
int i;
int val;
int ret;
printk("fifo is starting...\r\n");
ret = kfifo_alloc(&kfifo_tmp,N,GFP_KERNEL);
if(ret < 0)
{
printk("alloc fail");
return ret;
}
//推入队列
for(i = 0;i < 10;i++)
{
ret = kfifo_in(&kfifo_tmp,&i,sizeof(i));
if(ret > 0)
{
printk("data %d put in ok\r\n",i);
}
else
{
printk("put data %d error\r\n",i);
return ret;
}
}
//摘取队列但不删除
for(i = 0;i < 10;i++)
{
ret = kfifo_out_peek(&kfifo_tmp,&val,sizeof(val));
if(ret > 0)
{
printk("peek %d ok\r\n",val);
}
else
{
printk("peek data %d error\r\n",i);
return ret;
}
}
return 0;
}
static void __exit ap3216c_exit(void)
{
int i,ret,val;
//摘取队列并且释放队列
for(i = 0;i < 10;i++)
{
ret = kfifo_out(&kfifo_tmp,&val,sizeof(val));
if(ret > 0)
{
printk("peek %d ok\r\n",val);
}
else
{
printk("peek data %d error\r\n",i);
}
}
//释放队列
kfifo_free(&kfifo_tmp);
}
module_init(ap3216c_init);
module_exit(ap3216c_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("mrchen");
运行结果

3、映射
映射也成为关联数组,即一个由唯一键组成的集合,每个键必须关联一个特定的值,至少要支持一下三种操作:
Add (key, value)
n Remove (key)
n value = Lookup (key)
在实现中,虽然散列就是一种映射,但并不是所有的映射都需要通过散列表实现,采用二叉搜索树有着更优的性能:
1、在最坏的情况下有更好的表现
2、能够满足顺序保证
3、不需要散列函数,只需要定义<=操作算子即可
在linux中提供了一种映射数据结构,并不通用,因为其主要是映射一个唯一的标示数(UID)到一个指针,并且除了三种标准的映射操作外,还提供了allocate方法,不仅可以向Map插入键值对,而且可以产生UID
3.1 初始化一个idr
void idr_init(struct idr *idp);
3.2 分配一个新的UID
建立了idr之后,就可以分配新的UID,分配新的UID需要有两个步骤:
1、告诉idr我们需要分配新的UID了,通知其必要时调整后备树的大小
2、像idr请求我们所需要的新的UID
/*****************************************************
* 调整后备树大小
* idp指向idr,gfp_mask在十二章
* 成功返回1,失败返回0
*****************************************************/
int idr_pre_get(struct idr *idp,gfp_t gfp_mask);
/**********************************************************
* 实际执行获取新的UID
* idp所指向的idr去分配一个新的UID,并且将其关联到ptr上
* 将新的UID存放于id中,失败则返回-EAGAIN,若idr满了,则是-ENOSPC
* 成功返回0
***********************************************************/
int idr_get_new(struct idr *idp,void *ptr,int *id);
/**********************************************************
* 该函数与idr_get_new作用相同,但他确保新的UID大于或等于starting_id
* 使用这个方法允许idr的使用者确保UID不会被重用
* 成功返回0
***********************************************************/
int idr_get_new_above(struct idr *idp, void *ptr, int starting_id, int *id);
以下实例若成功则将获得一个新的UID,并且存储在遍历id中:
int id;
do {
if (!idr_pre_get(&idr_huh, GFP_KERNEL))
return -ENOSPC;
ret = idr_get_new(&idr_huh, ptr, &id);
//ret = idr_get_new_above(&idr_huh,prt,next_id,&id);
} while (ret == -EAGAIN);
3.3 查找UID
//成功则返回id关联的指针,出错则返回NULL
void *idr_find(struct idr *idp,int id);
//案例
struct my_struct *ptr = idr_find(&idr_huh, id);
if (!ptr)
return -EINVAL; /* error */
3.4 删除UID
void idr_remove(struct idr *idp,int id);
3.5 撤销idr
void idr_remove_all(struct idr *idp);
4、二叉树
树结构是一个能够提供分层的树形数据结构,是一种无环连接的有向图。
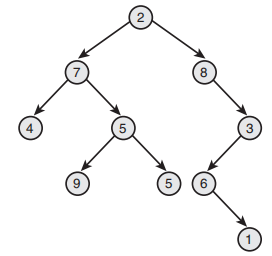
二叉搜索树:
1、根的左分支节点值小于根节点值
2、右分支节点值大于根节点值
3、所有子树都为二叉树
4.1 自平衡二叉树
节点深度:从根节点开始到达他所需要经过的父节点数目
叶子节点:没有子节点的节点
数的高度:指的是处于最底层节点的深度
平衡二叉树是所有叶子节点深度不超过1的二叉树,自平衡二叉搜索树是指操作都试图未出(半)平衡的二叉搜索树。
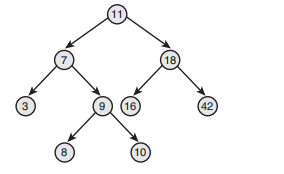
1、红黑树
在linux中实现的平衡二叉数采用的为二叉树去实现,红黑树的特性:
1、所有节点不为红色就为黑色
2、叶子节点都为黑色
3、叶子节点不包含数据
4、所有非叶子节点都有两个节点
5、如果一个节点是红色,则子节点都是黑色
6、在一个节点到叶子节点的路径中,如果总是包含同样数目的黑色节点,则该路径相比其他路径是最短的。
上述的条件保证了最深的叶子节点的深度不会大于两倍的最浅叶子节点的深度,因此红黑树总是半平衡的。
2、rbtree
在linux中红黑树被称为rbtree,定义在lib/tree.c中,声明在<linux/rbtree.h>中,linux的rbtree类似于经典红黑树,既保持了平衡性又以插入效率和书中节点数目呈对数关系。
//根节点需要初始化为特殊值RB_BOOT,树里的其他节点由结构rb_node描述
struct rb_root root = RB_ROOT;
搜索rbtree,该函数遍历了整个rbtree,offset决定向右还是向左搜索。
struct page * rb_search_page_cache(struct inode *inode, unsigned long offset)
{
struct rb_node *n = inode->i_rb_page_cache.rb_node;
while (n) {
//通过n节点找到page属性所在的地址,从而索引到offset值去判断搜索
struct page *page = rb_entry(n, struct page, rb_page_cache);
if (offset < page->offset)
n = n->rb_left;
else if (offset > page->offset)
n = n->rb_right;
else
return page;
}
return NULL;
}
插入rbtree,在插入rbtree之前,也需要遍历rbtree,看看是否已经存在offset这个节点,如果不存在且会遍历到叶子节点,就会调用rb_link_node在给定的叶子节点插入新的节点,在通过rb_insert_color执行平衡操作。
struct page * rb_insert_page_cache(struct inode *inode, unsigned long offset, struct rb_node *node)
{
struct rb_node **p = &inode->i_rb_page_cache.rb_node;
struct rb_node *parent = NULL;
struct page *page;
while (*p) {
parent = *p;
page = rb_entry(parent, struct page, rb_page_cache);
if (offset < page->offset)
p = &(*p)->rb_left;
else if (offset > page->offset)
p = &(*p)->rb_right;
else
return page;
}
rb_link_node(node, parent, p);
rb_insert_color(node, &inode->i_rb_page_cache);
return NULL;
}
5、数据结构以及选择
1、1️⃣如果是主要的操作是遍历则选择,2️⃣当性能不是首要考虑的,3️⃣储存较少数据时,4️⃣需要和内核中其他使用链表的代码交互时,5️⃣存储一个大小不定的数据集合,都可选择链表
2、1️⃣使用的代码符合生产者消费者模式时,2️⃣要一个一定长缓存,可以使用队列
3、1️⃣需要映射一个UID到一个对象,2️⃣处理发给用户空间的描述符,可以使用映射
4、1️⃣需要存储大量数据且要检索速度可以选择红黑树
6、算法复杂度
在计算机科学相关领域中,存在各种伸缩发描述算法复杂度,但最常用的是研究算法的渐近行为,渐进行为是指当算法输入变的非常大或者接近无限大的实话算法的行为。
6.1 算法
算法即一系列的指令,可能有一个或多个输入最后产生一个结果或输出,在数学角度上将,一个算法好比一个函数,可以写成y = f(x)
6.2 大O符号
一种很有用的渐进表示法就是上限–他是一个函数,其值从一个起点之后总是超过我们所研究的函数的值,即上限增长等于或者快于我们研究的函数,O符号来表示增长率。
如f(x)=O(g(x)),读为f是g的大o。数学上表示为f(x)=o(g(x))则存在c,x’满足f(x) <= c*g(x),对任意的x>x’。即完成f(x)的时间总是短于或者等于gx的时间和任意常量的乘积。
从根本上讲,就是要寻找一个函数,其行为和我们的算法一样差或者更差,这样子我们通过给该函数输入非常大的输入,然后观察该函数的结果,从而查看我们的上限。
6.3 大θ符号
如果fx是gx的大θ,那么gx既是fx的上限也是fx的下限。
6.4 时间复杂度
假如我们一秒数一个人房间里有7个人我们需要数7秒则时间复杂度为o(n),而如果我们只需要知道每个人都在干啥,如所有人都在跳舞则只需要1秒而不管我们输入多少个人了,这个时候时间复杂度就为o(1)。
我们在设计算法的实话应该尽量避免n!和2^n,当然在g(x)前还需要乘以一个c,如果这个C过于庞大,如我们稳定时间都为3小时,这样子也是不行的。
















 120
120











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









