







目录
什么是正则表达式,为什么要用正则表达式?
正则表达式,又称规则表达式,(Regular Expression,在代码中常简写为regex、regexp或RE),是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符"),是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串,通常被用来检索、替换那些符合某个模式(规则)的文本。
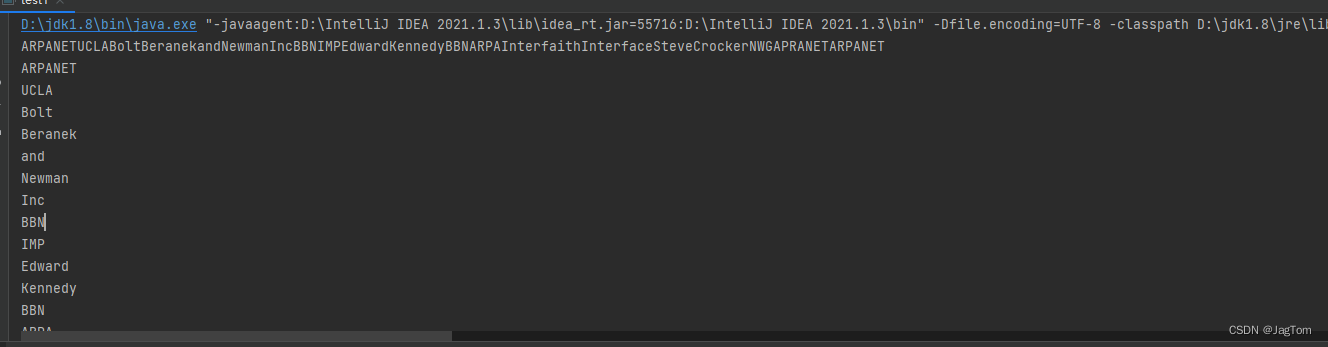
public static void main(String[] args) {
String reg="8月递交有关ARPANET的建议书,9月受到回应。\n" +
"10月,加州大学洛杉矶分校(UCLA)获得建立网络测量中心的合同。\n" +
"Bolt Beranek and Newman、Inc.公司(BBN)获得建立接口消息处理机(IMP)中的包交换部分的合同。\n" +
"美国参议员Edward Kennedy向BBN公司发出祝贺电报,祝贺他们从ARPA处获得百万美圆的合同来建造 Interfaith(他的笔误,应为Interface接口)消息处理机,并感谢他们的努力。\n" +
"以Steve Crocker为首的松散组织,网络工作组(NWG),开始开发用于APRANET通信的主机一级的协议。\n" +
"1969 美国国防部委托开发ARPANET,进行联网的研究。";
//提取文章中所有的英文单词
//(1).传统方法。使用遍历方式,代码量大,效率不高
char[] chars = reg.toCharArray();
StringBuilder stringBuilder=new StringBuilder();
for (char aChar : chars) {
if ((aChar >= 65) && (aChar <= 122)) {
stringBuilder.append(aChar);
}
}
System.out.println(stringBuilder.toString());
//(2).正则表达式技术
//1.先创建一个Pattern对象﹐模式对象,可以理解成就是一个正则表达式对象
Pattern pattern = Pattern.compile("[a-zA-Z]+");
Pattern pattern1 = Pattern.compile("[0-9]+"); //找到数字
Pattern pattern2 = Pattern.compile("([0-9]+)|[a-zA-Z]+"); //找到数字和英文字母
//2.创建一个匹配器对象
Matcher matcher = pattern.matcher(reg);
char a='b';
//3.可以开始循环匹配
//理解:就是 matcher 匹配器按照 pattern(模式/样式),到文本中去匹配
// 找到就返回true,否则就返回false
while(matcher.find()){
System.out.println(matcher.group(0));
}
//正则表达式是处理文本的利器
}
正则表达式使用到的地方特别多,无论是单独做文本处理,还是结合用来做数据校验等等场景都非常常见!!!在开发中,看懂并且记得一些常用的正则表达式是非常必要的。
正则表达式在通用方面也十分广泛
正则表达式的底层实现
public class test2 {
public static void main(String[] args) {
String reg="8月递交有关ARPANET的建议书,9月受到回应1234。\n" +
"10月,加州大学洛杉矶分校(UCLA)获得建立网络测量中心的合同。\n" +
"Bolt Beranek and Newman、Inc.公司(BBN)获得建立接口消息处理机(IMP)中的包交换部分的合同。\n" +
"美国参议员Edward Kennedy向BBN公司发出祝贺电报,祝贺他们从ARPA处获得百万美圆的合同来建造 Interfaith(他的笔误,应为Interface接口)消息处理机,并感谢他们的努力。\n" +
"以Steve Crocker为首的松散组织,网络工作组(NWG),开始开发用于APRANET通信的主机一级的协议。\n" +
"1969 美国国防部委托开发ARPANET,进行联网的研究。";
//目标:匹配所有四个数字
// 说明
//1. \d表示一个任意的数字 java中 \需要转义, 所以\\d 就是第一个\符号是转义字符,后面的\d代表数字
String regStr = "\\d\\d\\d\\d";
String regStrGroup = "(\\d\\d)(\\d\\d)"; //分组情况
//2.创建模式对象[即正则表达式对象]
Pattern pattern = Pattern.compile(regStr);
//3.创建匹配器
//说明:创建匹配器matcher,按照正则表达式的规则去匹配 reg字符串
Matcher matcher = pattern.matcher(reg);
/*、
*matcher.find()完成的任务
*1.根据指定的规则,定位满足规则的子字符串(比如1234)
*2.找到后,将子字符串的开始的索引记录到 matcher对象的属性int[] groups;* groups[0] = 24,把该子字符串的结束的索引+1的值记录到 groups[1]= 28
*3,同时记录oldLast 的值为子字符串的结束的索引+1的值即28,即下次执行find时,就从28开始匹配
*
* 源码:
public String group(int group) {
if (first < 0)
throw new IllegalStateException("No match found");
if (group < 0 || group > groupCount())
throw new IndexOutOfBoundsException("No group " + group);
if ((groups[group*2] == -1) || (groups[group*2+1] == -1))
return null;
return getSubSequence(groups[group * 2], groups[group * 2 + 1]).toString();
*1.根据 groups[0]=24和 groups[1]=28的记录的位置,从content开始截取子字符串返回
就是[24,28) String截取字符串是前闭后开
}
*/
while (matcher.find()){
//小结
//1.如果正则表达式有()即分组
//2.取出匹配的字符串规则如下
//3.group(0)表示匹配到的子字符串
//4.group(1)表示匹配到的子字符串的第一组字串
//5.group(2)表示匹配到的子字符串的第2组字串
//6.但是分组的数不能越界.
System.out.println(matcher.group(0));
System.out.println("第一组:"+matcher.group(1)); //看源码group(1)其实就是记录groups[2]-groups[3],以此类推
System.out.println("第二组:"+matcher.group(2));
}
}
}

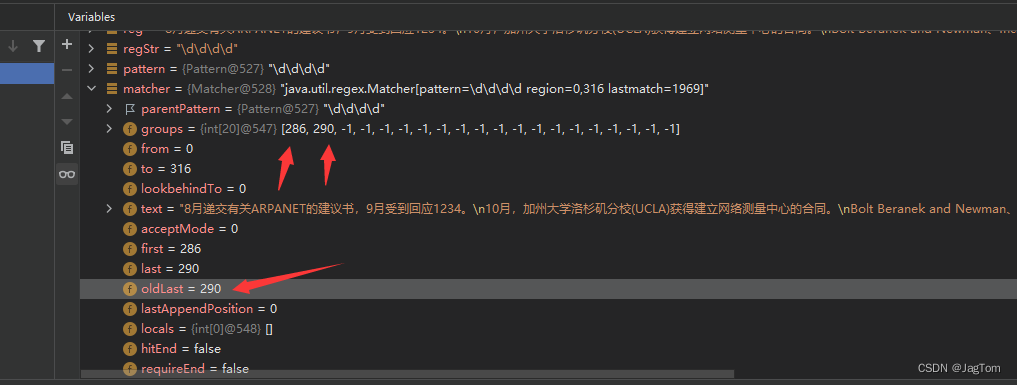
值得注意的是,matcher比较器比较的对象应该是charSequence的实现类
charSequence是一个接口,表示char值的一个可读序列。此接口对许多不同种类的char序列提供统一的自读访问。此接口不修改该equals和hashCode方法的常规协定,因此,通常未定义比较实现 CharSequence 的两个对象的结果。他有几个实现类:CharBuffer、String、StringBuffer、StringBuilder。
正则表达式语法
元字符-转义符\\
符号说明:在我们使用正则表达式去检索某些特殊字符的时候,需要用到转义符号,否则检索不到结果,甚至会报错的。
在Java的正则表达式中,两个代表 \\ 其他语言中的一个 \
元字符-字符匹配符
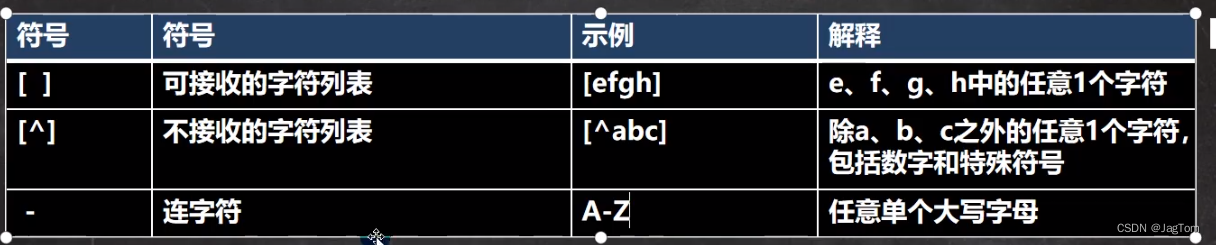
提示:连字符只能用在[]内,用在中括号外会被当作普通字符
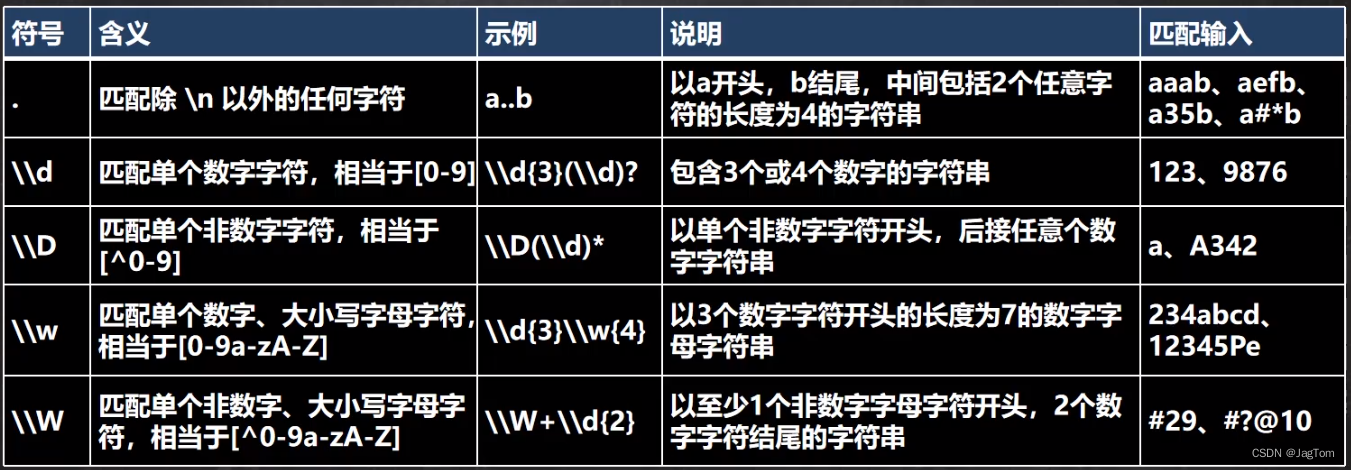
+表示1个或多个,?表示0个或1个,*表示0或多个
public class test3 {
public static void main(String[] args) {
//[A-Z]表示可以匹配A-Z中任意一个字符。
//[0-9]表示可以匹配0-9中任意一个字符。
String str="abc1231ABC";
// String reg="[a-z]";
// String reg="abc"; //java正则表达式默认是区分字母大小写的,如何实现不区分大小写
// String reg="(?i)abc"; //(?i)abc表示abc都不区分大小写
// String reg=a(?i)bc; //a(?i)bc表示bc不区分大小写 a((?i)b)c表示只有b不区分大小写
// Pattern pat = Pattern.compile(regEx,Pattern.CASE_INSENSITIVE); 也可以设定不区分大小写
// String reg="[^a-z]"; //[^a-z]表示可以匹配不是a-z中的任意一个字符
Pattern pattern=Pattern.compile(reg);
Matcher matcher = pattern.matcher(str);
while(matcher.find()){
System.out.println(matcher.group(0));
}
}
}
元字符-选择匹配符

元字符-限定符
用于指定其前面的字符和组合项连续出现多少次
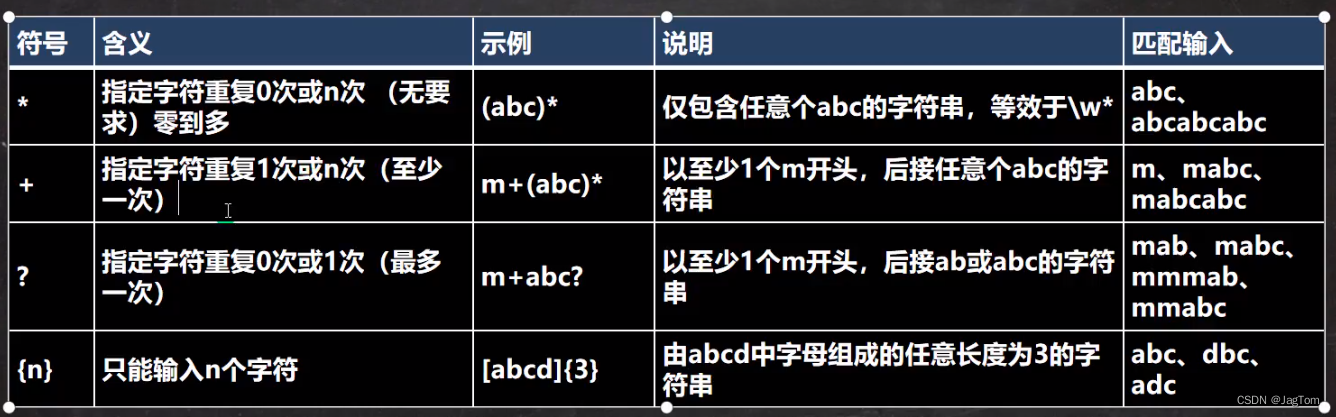

java匹配默认贪婪匹配,即尽可能匹配多的,后面能匹配多少就匹配多少
元字符-定位符
定位符,规定要匹配的字符串出现的位置,比如在字符串的开始还是在结束的位置,这个也是相当有用的,必须掌握、
 分组
分组

非捕获分组

public class test4 {
public static void main(String[] args) {
String content="2小红帽 233小苹果 133小辣椒";
// 这个非捕获分组是为了取消分组效果,以提高匹配效率。
String reg="小(?:红帽|苹果|辣椒)";
//这个会截取小红帽中的小,不会显示红帽。不显示后面的字符
String reg1="小(?=红帽|苹果|辣椒)";
//取反,找排除小红帽,小苹果中的小,所以只能找到小辣椒中的小
String reg2="小(?!红帽|苹果)";
Pattern compile = Pattern.compile(reg);
Matcher matcher = compile.matcher(content);
while (matcher.find()){
System.out.println(matcher.group(0));
// System.out.println(matcher.group(1)); 非捕获分组,不能写这个,会报错
}
}
}如果取消默认的贪婪匹配

其他更多的正则表达式元字符可以去官网查看正则表达式 – 元字符 | 菜鸟教程
反向引用


public class test5 {
public static void main(String[] args) {
String content="我....我我我我我...要要要学学学...java";
//1.去掉所以的.
String str="\\.";
Pattern compile = Pattern.compile(str);
Matcher matcher = compile.matcher(content);
content = matcher.replaceAll("");
System.out.println(content); //我我我我我我要要要学学学java
//2.去掉重复的字
//思路
//(1)使用(.)\\1+
// 注意:因为正则表达式变化,所以需要重置matcher
compile = Pattern.compile("(.)\\1+");
matcher = compile.matcher(content);
//使用反向引用$1 来替换匹配到的内容
content = matcher.replaceAll("$1");
System.out.println(content); //我要学java
//或者,一句话解决 链式编程
String contentNew = Pattern.compile("(.)\\1+").matcher(content).replaceAll("$1");
}
}String类中使用正则表达式


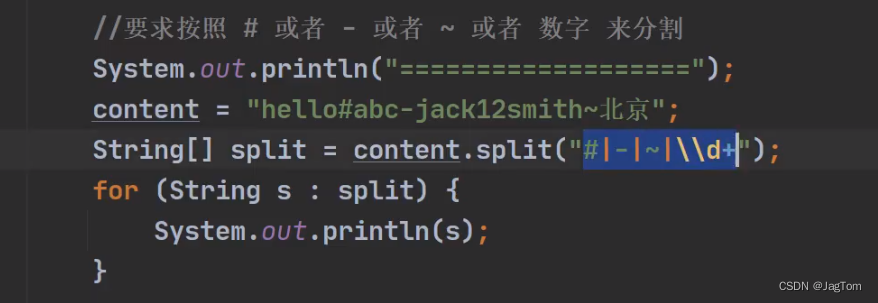
















 2514
2514











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











