







SpringMVC介绍
- SringMVC介绍
- SpringMVC运行原理
- 1.SpringMVC是什么? 请说出你对它的理解?
- 2.SpringMVC的加载流程是什么?
- 3.SpringMVC的执行流程是什么?
- 4.SpringMVC的核心组件有哪些?作用是什么?
- 5.SpringMVC常用注解有哪些?
- 6.SpringMVC如何设置转发和重定向?
- 7.SpringMVC中拦截器编写方式?
- 8.SpringMvc的处理器是不是单例模式?如果是,有什么问题?怎么解决?
- 9.Springmvc的优点
- 10.SpringMvc里面拦截器是怎么写的
- 11.传统mvc模式存在什么问题?或者说为何要使用框架?
- 12.mybatis与Hibernate有什么不同?
- 13.解释下MyBatis 中的动态SQL的理解?
- 14.JDBC编程有哪些不足之处,MyBatis是如何解决这些问题的?
- 15.使用MyBatis的mapper接口调用时有哪些要求?
- 16.简单的说一下MyBatis的一级缓存和二级缓存?
- 17.mybatis中${value}与#{} 的区别是什么?
- 18.谈谈对mybatis中的sqlSession、sqlSessionFactoryBuild和sqlSessionFactory的理解。
- 19.通常一个xml映射文件,都会写一个Dao接口与之对应,请问这个Dao接口的工作原理是什么?Dao接口里的方法,参数不同时,方法可以重载吗?为啥?
- 20.mybatis是如何进行分页的?分页插件的原理是什么?
- 21.Mybatis是否支持延迟加载?如果支持,它的实现原理是什么?
- 22.Mybatis映射文件中,如果A标签通过include引用了B标签的内容,请问,B标签能否定义在A标签的后面,还是说必须定义在A标签的前面?
- 23.简述Mybatis的Xml映射文件和Mybatis内部数据结构之间的映射关系?
SringMVC介绍
JavaEE开发中,项目从上到下分层为应用层,web层,业务层,持久层层
SpringMVC属于web层框架,spring主要是业务层,mybatis框架是持久层使用
SPringMVC是一个基于Java,实现了web MVC设计模式来设计的框架,基于请求/响应的事件驱动模型的思想实现(B/S模型)
Web服务演进过程
在早期 Java Web 的开发中,统一把显示层、控制层、数据层的操作全部交给 JSP 或者 JavaBean 来进行处理,如下图所示:
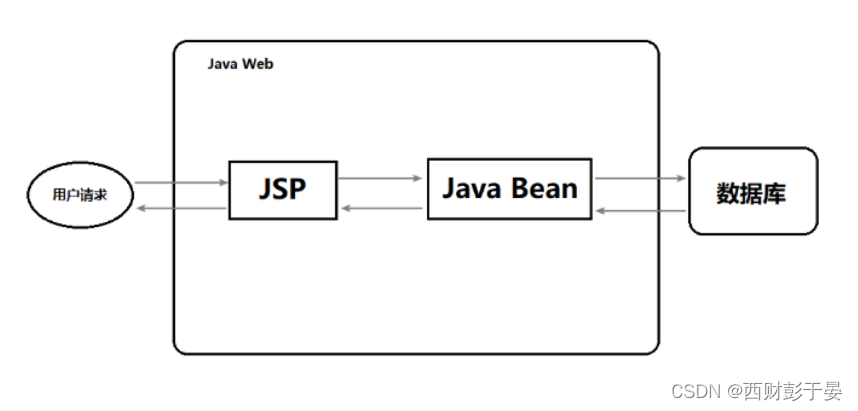
以上便是早期的web开发交互图,但存在以下弊端:
JSP 和 Java Bean 之间严重耦合,Java 代码和 HTML 代码也耦合
要求开发者不仅要掌握 Java ,还要掌握前端技术
前端和后端相互依赖,前端需要等待后端完成,后端也依赖前端完成,才能进行有效的测试
代码难以复用
很快这种方式被Servlet + JSP + Java Bean 所替代,早期的 MVC 模型就如下图这样:
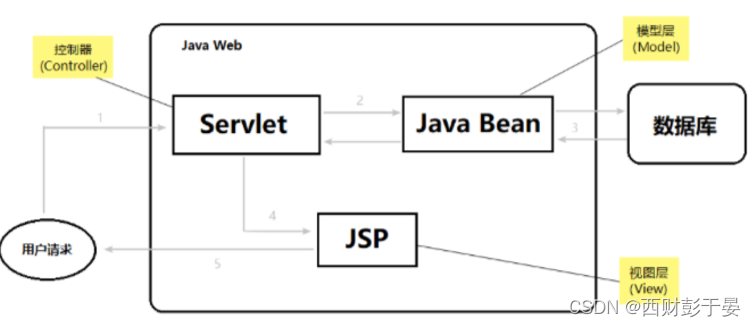
首先用户的请求会到达 Servlet,然后根据请求调用相应的 Java Bean,并把所有的显示结果交给 JSP 去完成,这样的模式我们就称为 MVC 模式。
M 代表模型(Model)
模型是什么呢?模型就是数据,就是 dao,bean
V 代表视图(View)
视图是什么呢?就是网页, JSP,用来展示模型中的数据
C 代表控制器(controller)
控制器是什么?控制器的作用就是把不同的数据(Model),显示在不同的视图(View)上,Servlet 扮演的就是这样的角色。
在Spring中给出的MVC的方案如下所示:
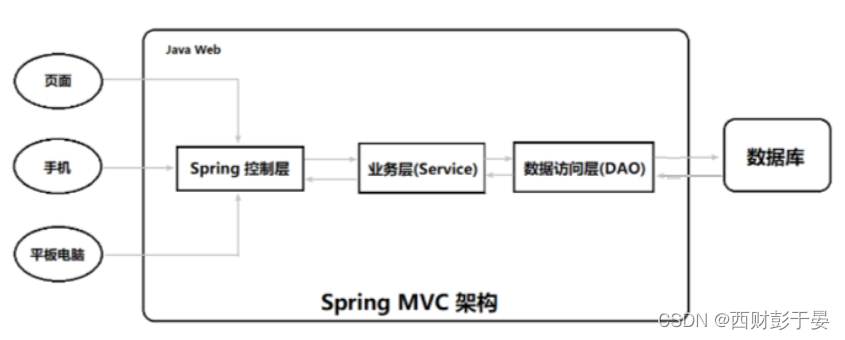
传统的模型层被拆分为了业务层(Service)和数据访问层(DAO,Data Access Object)。在 Service 下可以通过Spring 的声明式事务操作数据访问层。
特点:
结构松散,几乎可以在 Spring MVC中使用各类视图
松耦合,各个模块分离
与 Spring 无缝集成
Spring MVC的架构
SpringMVC是属于Spring的一个模块
SpringMVC和Spring无需通过中间整合进行整合
Spring是一个基于MVC的web框架
SpringMVC运行原理
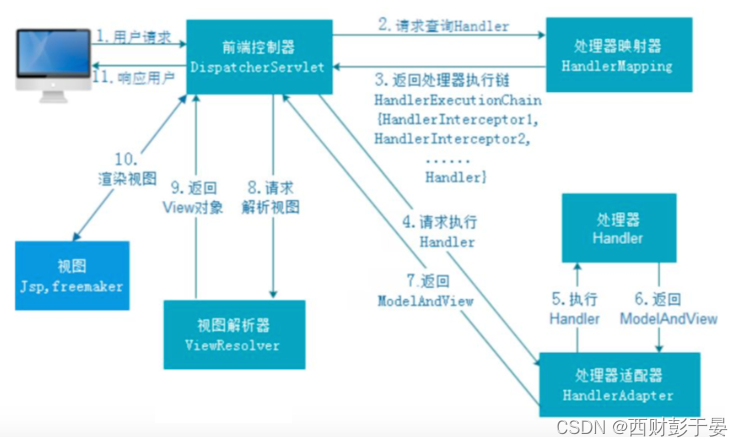
具体流程:
第一步:用户发起请求request到前端控制器DispatcherServlet
第二步:前端控制器请求处理映射器HandlerMapping查找Handler,可以根据注解、XML进行查找
第三步:处理映射器向前端控制器返回映射结果处理器映射链HandlerExecutionChain对象,包含一个Handler处理器对象、多个HandlerInterceptor拦截器的对象
第四步:前端控制器请求处理器适配器HandlerAdapter请求执行Handler
第五步:处理器适配器执行Handler
第六步:处理器执行完返回给适配器ModelAndView对象,ModelAndView是SpringMVC一个底层的对象,包含View和Model,Model部分是业务对象返回的模型数据,View部分为逻辑视图名
第七步:处理器适配器返回给前端控制器ModelAndView对象(包含模型数据、逻辑视图名)
第八步:前端控制器请求视图解析器ViewResolver解析视图,视图解析器将把逻辑视图名解析为具体的View(jsp…)
第九步:视图解析器向前端控制器返回view
第十步:前端控制器进行视图渲染,视图渲染将模型数据(ModelAndView对象)填充到request域
第十一步:前端控制器向用户响应结果
1.SpringMVC是什么? 请说出你对它的理解?
SpringMVC是Spring将Web层基于MVC封装后的框架.
在没有SpringMVC之前,Web层的Servlet负责的事情很多,很杂.
例如:接收请求,调用service层处理请求,封装返回结果,响应信息给浏览器.
SpringMVC将Servlet负责的事情分门别类,进行具体的划分.
M-model: 封装数据
V-View: 封装视图
C-Controller: 处理器方法,用于接收请求
2.SpringMVC的加载流程是什么?
加载流程,即服务器启动时,加载SpringMVC的环境:
1.服务器启动时从web.xml文件开始加载
2.初始总控制器 DispatcherServlet
3.在总控制器的初始化方法中(initStrategies:初始化策略),完成核心组件的加载
处理器映射器:HandlerMapping,建立绑定路径与方法全限定名的对应关系
处理器适配器:HandlerAdapter,适配处理器的实现方式,调用指定的类反射执行处理器方法
视图解析器:ViewResolver,根据逻辑视图生成对应的物理视图,并将物理视图返回
3.SpringMVC的执行流程是什么?
执行流程,即浏览器发起请求后,框架内部的执行链路:
1.浏览器发起请求给服务器
2.DispatcherServlet拦截来自浏览器的请求
3.总控制器调用处理器映射器,根据请求路径找到对应的方法全限定名,并返回给总控制器
4.总控制器调用处理器适配器,找到对应的方法适配实现方式,调用指定的实现类反射执行方法
5.总控制器调用视图解析器,根据逻辑视图找到对应的物理视图
6.生成响应
4.SpringMVC的核心组件有哪些?作用是什么?
DispatcherServlet: 总控制器/前端控制器,接收请求,调度
HandlerMapping: 处理器映射器。
SpringMVC框架加载时,存放请求路径与处理器方法之间的映射关系。
HandlerAdapter: 处理器适配器,适配处理器的实现方式,实现方式不同调用的适配器类不同。不同的适配器类,可以处理不同的处理器方法。
ViewResolver: 视图解析器,根据逻辑视图,生成对应的物理视图,并将物理视图返回给总控制器
Handler: 处理器,我们自己编写的用于处理器业务的方法
5.SpringMVC常用注解有哪些?
@RequestMapping
为处理器绑定浏览器访问的路径
@RequestBody
解析请求携带的json数据,封装到对应的javaBean中
@ResponseBody
将响应结果装换成json并响应给浏览器
@Controller
用于创建Controller层类对象,并将类对象存放到SpringMVC的IOC容器中
@ControllerAdvice
全局异常处理
全局数据绑定
全局数据预处理
6.SpringMVC如何设置转发和重定向?
请求转发:
逻辑视图字符串 + 视图解析器
响应标记 + 物理视图字符串
重定向:
响应标记 + 物理视图字符
7.SpringMVC中拦截器编写方式?
SpringMVC中的拦截器实现方式有两种:
1.编写一个类实现HandlerInterceptor接口,重写抽象方法
2.编写一个类继承HandlerInterceptorAdapter,选择性的重写方法
以上两种方式需要在核心配置文件中配置拦截的路径
8.SpringMvc的处理器是不是单例模式?如果是,有什么问题?怎么解决?
是单例模式,在多线程访问的时候有线程安全问题。
解决方案: 在控制器里面不能写可变状态量,如果需要使用这些可变的量,可以使用ThreadLocal解决,为每个线程单独生成一个变量,独立操作,互不影响。
9.Springmvc的优点
1.可以支持各种视图技术,而不仅仅局限于JSP.
2.与Spring框架集成(如IoC容器、AOP等)
3.清晰的角色分配:总控制器(dispatcherServlet),请求到处理器映射(handlerMapping),处理器适配器(HandlerAdapter),视图解析器(ViewResolver)。
4.支持各种请求资源的映射策略。
10.SpringMvc里面拦截器是怎么写的
有两种写法,一种是实现接口,另外一种是继承适配器类,然后在SpringMvc的配置文件中配置拦截器即可:
<!-- 只针对部分请求拦截 -->
<mvc:interceptor>
<mvc:mapping path="/modelMap.do" />
<bean class="com.et.action.MyHandlerInterceptorAdapter" />
</mvc:interceptor>
11.传统mvc模式存在什么问题?或者说为何要使用框架?
传统MVC模式存在问题
(1)所有的Servlet和Servlet映射都要配置在web.xml中,如果项目太大,web.xml就太庞大,并且不能实现模块化管理。
(2)Servlet的主要功能就是接受参数、调用逻辑、跳转页面,比如像其他字符编码、文件上传等功能也要写在Servlet中,不能让Servlet主要功能而需要做处理一下特例。
(3)接受参数比较麻烦(String name = request.getParameter(“name”),User user=new User user.setName(name)),不能通过model接收,只能单个接收,接收完成后转换封装model.
(4)跳转页面方式比较单一(forword,redirect),并且当我的页面名称发生改变时需要修改Servlet源代码.
12.mybatis与Hibernate有什么不同?
相同点:都是java中orm框架、屏蔽jdbc api的底层访问细节,使用我们不用与jdbc api打交道,就可以完成对数据库的持久化操作。jdbc api编程流程固定,还将sql语句与java代码混杂在了一起,经常需要拼凑sql语句,细节很繁琐。
ibatis的好处:屏蔽jdbc api的底层访问细节;将sql语句与java代码进行分离;提供了将结果集自动封装称为实体对象和对象的集合的功能.queryForList返回对象集合,用queryForObject返回单个对象;提供了自动将实体对象的属性传递给sql语句的参数。
Hibername的好处:Hibernate是一个全自动的orm映射工具,它可以自动生成sql语句,并执行并返回java结果。
不同点:
1、hibernate要比ibatis功能强大很多。因为hibernate自动生成sql语句。
2、ibatis需要我们自己在xml配置文件中写sql语句,hibernate我们无法直接控制该语句,我们就无法去写特定的高效率的sql。对于一些不太复杂的sql查询,hibernate可以很好帮我们完成,但是,对于特别复杂的查询,hibernate就很难适应了,这时候用ibatis就是不错的选择,因为ibatis还是由我们自己写sql语句。
ibatis可以出来复杂语句,而hibernate不能。
3、ibatis要比hibernate简单的多。ibatis是面向sql的,不同考虑对象间一些复杂的映射关系。
13.解释下MyBatis 中的动态SQL的理解?
对于一些复杂的查询,我们可能会指定多个查询条件,但是这些条件可能存在也可能不存在,例如在58同城上面找房子,我们可能会指定面积、楼层和所在位置来查找房源,也可能会指定面积、价格、户型和所在位置来查找房源,此时就需要根据用户指定的条件动态生成 SQL 语句。如果不使用持久层框架我们可能需要自己拼装 SQL 语句,还好 MyBatis 提供了动态 SQL 的功能来解决这个问题。 MyBatis 中用于实现动态 SQL 的元素主要有:
if
choose / when / otherwise
trim
where
set
foreach
其中
If标签: 多个条件查询时候用到
Where标签:可以自动处理第一个and
Foreach:应用场景 在多个ID查询时 传递的是集合或者是数组时候
Foreach的属性:
Collection: Java对象的属性名
Open:sql拼接开始的语句
Close: 结束时的SQL语句
Item:查询SQL中的字段名
Separator:语句拼接时候用什么进行分割
14.JDBC编程有哪些不足之处,MyBatis是如何解决这些问题的?
① 数据库链接创建、释放频繁造成系统资源浪费从而影响系统性能,如果使用数据库链接池可解决此问题。
解决:在SqlMapConfig.xml中配置数据链接池,使用连接池管理数据库链接。
② Sql语句写在代码中造成代码不易维护,实际应用sql变化的可能较大,sql变动需要改变java代码。
解决:将Sql语句配置在XXXXmapper.xml文件中与java代码分离。
③ 向sql语句传参数麻烦,因为sql语句的where条件不一定,可能多也可能少,占位符需要和参数一一对应。
解决: Mybatis自动将java对象映射至sql语句。
④ 对结果集解析麻烦,sql变化导致解析代码变化,且解析前需要遍历,如果能将数据库记录封装成pojo对象解析比较方便。
解决:Mybatis自动将sql执行结果映射至java对象。
另外的参考回答
频繁的创建数据连接,关闭资源,造成性能的下降,使用数据文库连接池 解决这个问题用数据库连接池.在SqlMapConfig.xml 配置数据库连接池 c3p0 DBCP
Jdbc 编程sql 的可维护性不高. Mybatis采用配置文件的方式解决sql可维护的问题
在mapper.xml中配置 ,是sql与代码分离 可维护行变高
Jdbc 传入参数比较麻烦. 参数有时候多,参数要和占位符一一对应.
Mybatis 使用statement 的 paremterType 定义输入的参数类型
对结果解析比较麻烦. Mybatis 使用resultType 自动映射到pojo中解决了jdbc解析结果的麻烦
15.使用MyBatis的mapper接口调用时有哪些要求?
① Mapper接口方法名和mapper.xml中定义的每个sql的id相同
② Mapper接口方法的输入参数类型和mapper.xml中定义的每个sql 的parameterType的类型相同
③ Mapper接口方法的输出参数类型和mapper.xml中定义的每个sql的resultType的类型相同
④ Mapper.xml文件中的namespace即是mapper接口的类路径。
16.简单的说一下MyBatis的一级缓存和二级缓存?
Mybatis首先去缓存中查询结果集,如果没有则查询数据库,如果有则从缓存取出返回结果集就不走数据库。Mybatis内部存储缓存使用一个HashMap,key为hashCode+sqlId+Sql语句。value为从查询出来映射生成的java对象
Mybatis的二级缓存即查询缓存,它的作用域是一个mapper的namespace,即在同一个namespace中查询sql可以从缓存中获取数据。二级缓存是可以跨SqlSession的。
17.mybatis中${value}与#{} 的区别是什么?
#{} 表示占位符.可以实现preparedStatement 向占位符中设置值,#{}可以接受简单类型,pojo属性值, #{}可以防止sql注入.如果preparedStatement 中传入简单类型 #{value} 可以随意写但是不可以不写
v a l u e S Q L 语 句 的 拼 接 . 可 以 接 收 p o j o 属 性 值 和 简 单 数 类 型 , 如 果 p r e p a r e d S t a t e m e t 传 入 简 单 数 据 类 型 , {value} SQL 语句的拼接.可以接收pojo属性值和简单数类型,如果preparedStatemet 传入简单数据类型,valueSQL语句的拼接.可以接收pojo属性值和简单数类型,如果preparedStatemet传入简单数据类型,{value} 只能是value 不能改变
另外一种参考答案:
#{}是预编译处理,KaTeX parse error: Expected ‘EOF’, got ‘#’ at position 21: …串替换。 Mybatis在处理#̲{}时,会将sql中的#{}替…{}时,就是把${}替换成变量的值。
使用#{}可以有效的防止SQL注入,提高系统安全性。
18.谈谈对mybatis中的sqlSession、sqlSessionFactoryBuild和sqlSessionFactory的理解。
sqlSession:封装了对数据 增删改查的方法。
sqlSession是通过sqlSessionFactory创建的。
.sqlSessionFactory是通过sqlSessionFactoryBuild创建的。
sqlSessionFactoryBuild 是创建sqlSessionFactory时使用的.一旦创建成功后就不需要sqlSessionFactoryBuild的,因为sqlSession是通过sqlSessionFactory创建的,可以可以当做工具类使用。
sqlSessionFactory是一个接口, 类里重载了opensession的不同的方法使用范围是在整个运行范围内,一旦创建可以重复使用.可以当做单实例对象来管理。
sqlSession是面向用户的一个操作数据库的接口 每个线程都应该有自己的sqlSession 并且sqlSession不可以共享. 线程是不安全的,打开一个sqlSession用完之后就要关闭。
19.通常一个xml映射文件,都会写一个Dao接口与之对应,请问这个Dao接口的工作原理是什么?Dao接口里的方法,参数不同时,方法可以重载吗?为啥?
Dao接口,就是人们常说的Mapper接口,接口的全限名,就是映射文件中的namespace的值,接口的方法名,就是映射文件中MappedStatement的id值,接口方法内的参数,就是传递给sql的参数。Mapper接口是没有实现类的,当调用接口方法时,接口全限名+方法名拼接字符串作为key值,可唯一定位一个MappedStatement,举例:com.mybatis3.mappers.StudentDao.findStudentById,可以唯一找到namespace为com.mybatis3.mappers.StudentDao下面id = findStudentById的MappedStatement。在Mybatis中,每一个、、、标签,都会被解析为一个MappedStatement对象。
Dao接口里的方法,是不能重载的,因为是全限名+方法名的保存和寻找策略。
Dao接口的工作原理是JDK动态代理,Mybatis运行时会使用JDK动态代理为Dao接口生成代理proxy对象,代理对象proxy会拦截接口方法,转而执行MappedStatement所代表的sql,然后将sql执行结果返回。
20.mybatis是如何进行分页的?分页插件的原理是什么?
Mybatis使用RowBounds对象进行分页,它是针对ResultSet结果集执行的内存分页,而非物理分页,可以在sql内直接书写带有物理分页的参数来完成物理分页功能,也可以使用分页插件来完成物理分页。
分页插件的基本原理是使用Mybatis提供的插件接口,实现自定义插件,在插件的拦截方法内拦截待执行的sql,然后重写sql,根据dialect方言,添加对应的物理分页语句和物理分页参数。
21.Mybatis是否支持延迟加载?如果支持,它的实现原理是什么?
Mybatis仅支持association关联对象和collection关联集合对象的延迟加载,association指的就是一对一,collection指的就是一对多查询。在Mybatis配置文件中,可以配置是否启用延迟加载lazyLoadingEnabled=true|false。
它的原理是,使用CGLIB创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,比如调用a.getB().getName(),拦截器invoke()方法发现a.getB()是null值,那么就会单独发送事先保存好的查询关联B对象的sql,把B查询上来,然后调用a.setB(b),于是a的对象b属性就有值了,接着完成a.getB().getName()方法的调用。这就是延迟加载的基本原理。
举个例子:如果查询订单并且关联查询用户信息。如果先查询订单信息即可满足要求,当我们需要查询用户信息时再查询用户信息。把对用户信息的按需去查询就是延迟加载。 所以延迟加载即先从单表查询、需要时再从关联表去关联查询,大大提高数据库性能,因为查询单表要比关联查询多张表速度要快。
22.Mybatis映射文件中,如果A标签通过include引用了B标签的内容,请问,B标签能否定义在A标签的后面,还是说必须定义在A标签的前面?
虽然Mybatis解析Xml映射文件是按照顺序解析的,但是,被引用的B标签依然可以定义在任何地方,Mybatis都可以正确识别。
原理是,Mybatis解析A标签,发现A标签引用了B标签,但是B标签尚未解析到,尚不存在,此时,Mybatis会将A标签标记为未解析状态,然后继续解析余下的标签,包含B标签,待所有标签解析完毕,Mybatis会重新解析那些被标记为未解析的标签,此时再解析A标签时,B标签已经存在,A标签也就可以正常解析完成了。
23.简述Mybatis的Xml映射文件和Mybatis内部数据结构之间的映射关系?
Mybatis将所有Xml配置信息都封装到All-In-One重量级对象Configuration内部。在Xml映射文件中,标签会被解析为ParameterMap对象,其每个子元素会被解析为ParameterMapping对象。标签会被解析为ResultMap对象,其每个子元素会被解析为ResultMapping对象。每一个标签均会被解析为MappedStatement对象,标签内的sql会被解析为BoundSql对象。














 3070
3070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









