






爬虫系统面试题
1、为什么做这个项目?
当时刚学完springboot框架,一直以来也对爬虫非常感兴趣非常好奇,爬虫是在学习python的过程中接触的,后来得知sprigboot也可以写爬虫框架的时候,就选择了这个内容来去巩固所学的springboot的知识,而且这个知识在实际中也有很大的作用,因为我爬的是实习僧网站,分别爬取了公司名称、网申url、薪资等属性,使得在用户去找公司时更加的方便,可以更加直观的看到每个公司的特点。
2、项目介绍
爬虫项目是通过spring boot框架和webmagic框架完成的,其本质就是不断向招聘网站发起HTTP请求,在响应中筛选出自己感兴趣的内容并加以分析。springboot框架对于ssm框架做了很多配置上的简化,再加上webmagic这样一个开源的Java爬虫框架,它的目标是简化爬虫的开发流程,让开发者我更专注于逻辑的开发,所以整个项目都非常简洁,配置也都不算复杂。
3、细节怎么实现?
1、爬的PC端还是移动端?
PC端
2、如何跳过平台账号校验?
手动设置cookie,就是先在网站上面登录,复制登陆后的cookies,在爬虫程序中手动设置HTTP请求中的cookie属性,就是将cookie放到headers中进行请求,这种方式适用于采集频次不高、采集周期短,因为cookie会失效,如果长期采集的话就需要频繁的设置cookie。
还有什么更好的方法吗?
使用程序模拟登录,通过模拟登录获取到cookies,这种方式适用于长期采集该网站,因为每次采集都会先登录,这样就不需要担心cookie过期的问题。
3、反爬虫策略怎么应对?
爬虫的速度并不是越快越好,速度过快的话就越容易被发现,也就越容易被封IP,从而丢失大量有效数据,甚至需要重新抓取。可以对每个页面抓取之间的延迟设置为最大来控制频率,这样不会给服务器造成负担,也不会因访问频繁被封,但这种方法会导致抓取的速度较慢,如果有大量抓取任务,会严重影响效率。
解决方法?
可以使用PID控制算法,当爬虫速度过快的时候就会增加延时的时间,当速度过慢时,也会自动减小延时的时间。
PID控制算法怎么实现?
首先给定一些初始化的值,
1)初始化:设定初始延时时间T0和比例系数Kp(典型值-0.05)
2)目标设定:设定爬虫速度S,比如40页/分钟。
3)测量:统计每分钟内爬虫抓取网页的数量n,可能是32,也可能是100等.
4)比较:比较n和S的大小
5)执行:n如果比S大,说明太快了,于是增加延时时间;n如果比S小,说明太慢了,于是减小延时时间。
该方案的公式化表示如下,
Tk=Tk-1+Kp*(S-n)
其中k=1, 2, 3 … ,Tk是第k次设定的延时时间。不要被表达式吓住了,它所传达的意思其实就是5)所描述的执行过程:速度太快 (S-n小于0, Kp*(S-n)为正),增加延时 (Tk大于Tk-1);速度太慢 (S-n大于0, Kp*(S-n)为负),减小延时 (Tk小于Tk-1)。
4、怎样爬出自己想要的指定信息?
Selectable相关的抽取元素链式API是WebMagic的一个核心功能。使用Selectable接口,可以直接完成页面元素的链式抽取,也无需去关心抽取的细节。
在刚才的例子中可以看到,page.getHtml()返回的是一个Html对象,它实现了Selectable接口。这个接口包含的方法分为两类:抽取部分和获取结果部分。
所以使用page.getHtml().xpath()按照某个规则对结果进行抽取,这里抽取支持链式调用。将结果放入到了一个Selectable类型的List中,然后遍历这个List的每一个节点,获取到想要的数据。
关于获取指定数据的方式,WebMagic里主要使用了三种抽取技术:XPath、正则表达式和CSS选择器。
我使用的是Xpath来获取指定内容。
这个方法是定义在pageProcessor的实现类中的,在WebMagic里,实现一个基本的爬虫只需要编写一个类去实现PageProcessor接口即可。 这个类基本上包含了抓取一个网站,你需要写的所有代码。PageProcessor的定制分为几个部分,分别是
爬虫的配置,在Site中配置抓取网站的相关配置,包括编码、抓取间隔、重试次数等。
页面元素的抽取,用Xpath抽取出指定元素。
URL的获取、跳转。
XPath本来是用于XML中获取元素的一种查询语言,但是用于Html也是比较方便的。例如:
page.getHtml().xpath(“//h1[@class=‘entry-title public’]/strong/a/text()”)
这段代码使用了XPath,参数为你所要爬取的html指定数据的路径,它的意思是“查找所有class属性为’entry-title public’的h1元素,并找到他的strong子节点的a子节点,并提取a节点的文本信息”。
5、爬全部信息有什么样的问题
不指定数据而是爬取所有数据的话,大量的数据会严重影响爬取的效率,而且大量的数据爬取也会更容易触发网站的反爬虫策略。
4、项目中的邮件发送是怎么实现的?
项目中的邮件是借助MimeMessageHelper发送的,首先发送人的邮箱必须开通了SMTP/POP3服务,并把授权码记下,然后在yml配置文件中配置服务器地址、发送人、授权码、编码格式。然后在service层进行数据的填充和发送,有两个service,一个是SxsService,SxsService中制定了html页面,并且将数据填充进页面,通过@value注解获取到发送方,在去指定接收方,用迭代器遍历接收方的集合,逐个去填充接收方、内容、标题信息,然后通过EmailService.sendHtmlMail()进行发送。EmailService.sendHtmlMail()方法是借助MimeMessageHelper类进行邮件的发送的,将SxsService传输过来的信息封装到MimeMessageHelper的对象中,调用send方法进行发送。
5、邮件的定时发送是怎么实现的?
这里我用了java的定时器Timer来实现这个功能。这里我编写了两个类,DataListener类和DataTask类。前者是该定时器的监听类,用来设置定时任务执行的具体时间以及开启该定时任务;后者是执行定时任务的具体操作。
首先是DataListener,该类继承了HttpServlet,主要是通过web项目启动时,启动该servlet定时任务。init()方法是HttpServlet启动时需要初始化的方法,所以定时器初始化的配置就写在该方法里。在web.xml文件中还需要配置该servlet启动信息,如下所示。
DataTask类继承了TimerTask,在run()方法中需要补充该定时任务的具体操作内容。我在该任务里边主要编写了访问数据库的service类,将数据推送出去。
6、这个系统中都有哪些组件?作用是什么?
WebMagic的结构分为Downloader、PageProcessor、Scheduler、Pipeline四大组件,并由Spider将它们彼此组织起来。这四大组件对应爬虫生命周期中的下载、处理、管理和持久化等功能。
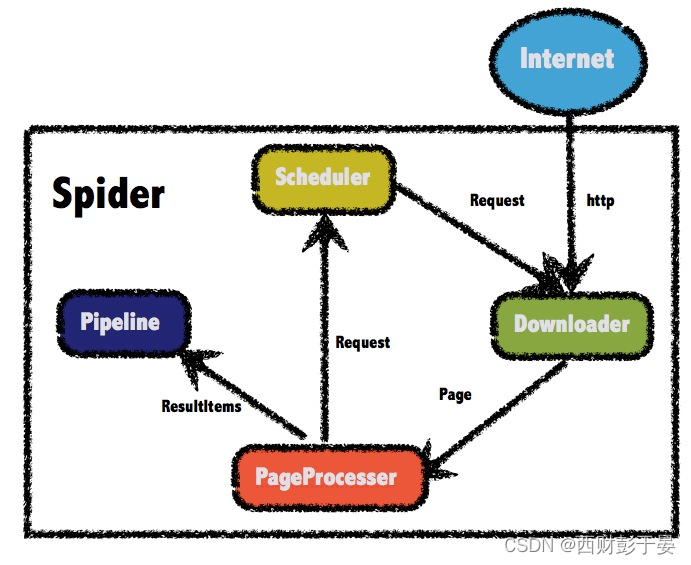
1.2.1 WebMagic的四个组件
1.Downloader
Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。
2.PageProcessor
PageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。
在这四个组件中,PageProcessor对于每个站点每个页面都不一样,是需要使用者定制的部分。
3.Scheduler
Scheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。
除非项目有一些特殊的分布式需求,否则无需自己定制Scheduler。
4.Pipeline
Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。
Pipeline定义了结果保存的方式,如果你要保存到指定数据库,则需要编写对应的Pipeline。对于一类需求一般只需编写一个Pipeline。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









