






去啊 LP;[']
[toc]
0.总起
ViT是encoder only类型,主要用于图像分类;
与传统的nlp不同,nlp领域里一个字符含有的信息非常丰富,而对于图像而言,一个像素点所含有的信息非常稀少,所以往常的处理都是基于一个个图片的小块,每个小块含有很多像素点
0.1 声明
代码大量复制粘贴于大佬rwightman的工作
这里在于加入自己的理解
0.1 token
在自然语言处理(NLP)和计算机科学中,“token” 是指文本的最小单位或基本元素。一个 token 可以是一个单词、一个字符、一个子词或其他更小的文本单元。
在 NLP 中,将文本分解成 token 的过程称为 “分词”(tokenization)或 “词法分析”(lexical analysis)。这个过程的目标是将连续的文本序列划分为有意义的 token,以便进行后续的处理和分析。
例如,考虑以下句子:“I love to play soccer.” 如果我们使用空格作为分隔符,将句子分解为 token,得到的结果可能是:[“I”, “love”, “to”, “play”, “soccer”, “.”],其中每个单词和句点都是一个 token。
0.2 传统的顺序摆放
常见的顺序为: 全连接层(Linear) -> BN层 -> 激活函数 -> Dropout层
1、.整体架构
JNBVCX`1 
反正敲完transformer之后感觉这张图大部分内容都挺熟悉的,除了DropPath和GELU这两
2.原理&原理
声明:参考的王树森的视频讲解,约15min

2.1 图片划分
有些类似于CNN中卷积的移动,但没有卷积核的计算,这一步的作用只是划分原图像
· 其实可以重叠,但原文没有重叠


自然地,需要两个参数:
- patch size: 框的shape,类似于Conv里面的卷积核形状
- stride: 移动的步长,基本等同Conv里面的stride
2.2 .图片向量化
对应于NLP里面的embedding,比如在transformer里面就要使用nn.embedding来实现词嵌入
但在ViT中不需要nn.embedding,而是通过线性变化将这么一个,如shape为 16* 16* 3的 张量变成 768 的一维向量
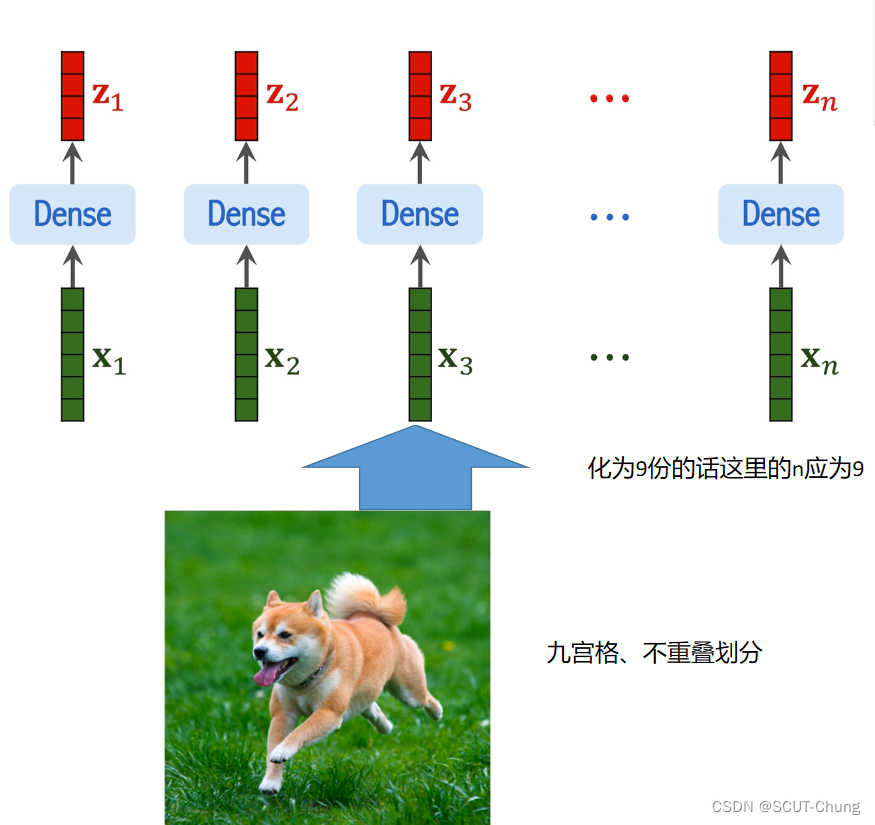
实际上是直接使用Conv来完成这一步的
以 原图片为 3224224 为例,这一步之后shape为 7681414
2.3 positional embedding
在transformer里,positional embedding是因为同一单词在句子里不同的位置上所对应的含义是不一样的,例如
“我跑在狗子前面” 和 “狗子跑在我前面”,有典型的不同。
同样的,在ViT中,为了让模型明白下面的这两张图是截然不同的,加入了positional embedding。实验结果证明加了位置编码后高了三个百分点,而是哪种形式造成的差异并不大。
使用方法还是transformer里面的加法.
但是transformer里的positional embedding是固定的,以此生成后就不变的东西,ViT里面的是可训练的nn.Parameter

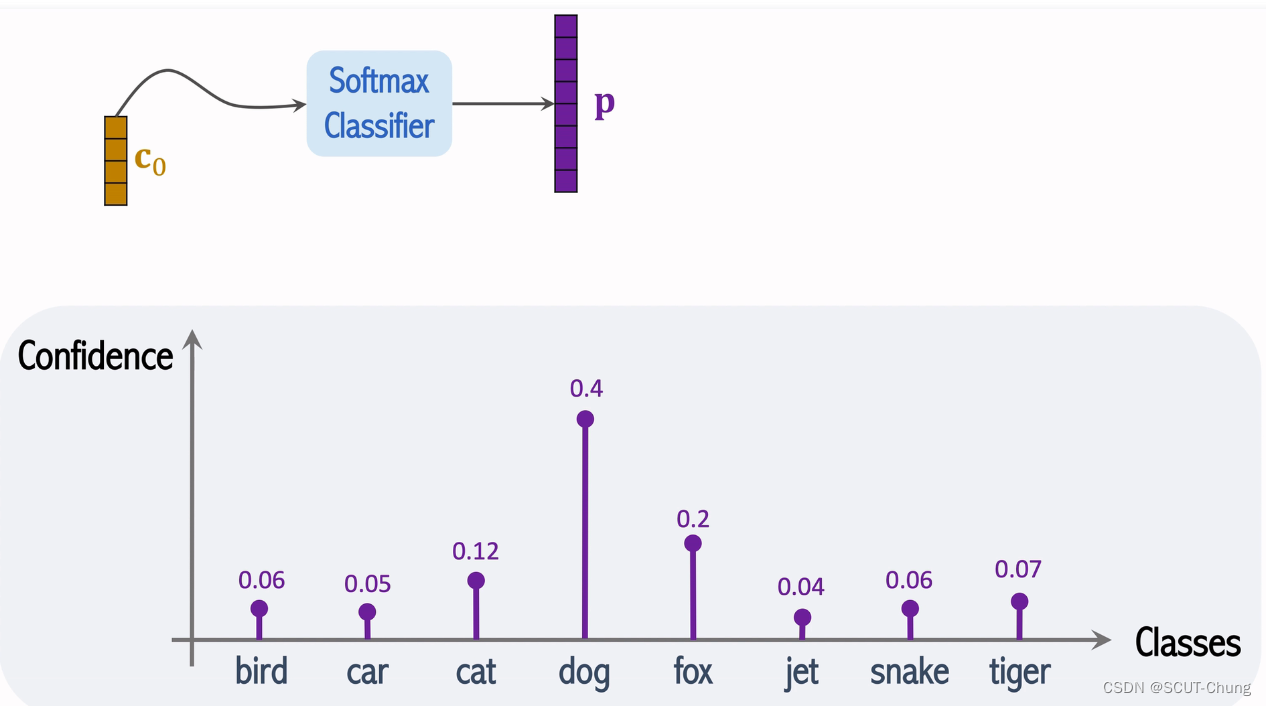
2.4 cls

在图片划分之后,在全部向量之前加入一个[cls],由于attention的机制,[cls]对应的c0会知道x1 到 xn 的全部信息,所以可以凭借c0来完成对图像的分类。
2.5 分类
2.6 使用指导
ViT训练时所用的数据集越大,效果越好,“足够大“指3亿张图片;
ResNet的准确率反而对这种爆炸级增长的训练数据量没有多大变;化
3 Multi-Head Attention
直接复制粘贴transformer里的
#%% 注意力机制
import torch
import torch.nn.functional as F
import torch.nn as nn
import math
def attention(q,k,v,masked=None,dropout=None):
# Q、K、V三者的形状都是[batch_size, sequence_length, d_model](单头时,多头最后一个为d_model/m)
d_model=q.shape[-1]
# shape:batch_size*sequence_length*sequence_length
score=torch.matmul(q,k.transpose(-2,-1))/math.sqrt(d_model)
if masked is not None:
# 将对应的掩码位置转化为1e-9
score=score.masked_filled(0,1e-9)
# 结果是每个sequence_length的sequence_length列个元素的和为1,
# p_attn表示每个key中的每一个词对一个询问语句中的一个单词的相关程度(sequence_length_of_query * sequence_length_of_key)
# shape:batch_size*sequence_length*sequence_length
p_attn=F.softmax(score,dim=-1)
if dropout is not None:
p_attn=nn.Dropout(p_attn,p=dropout)
# query的注意力表示:torch.matmul(p_attn,v), shape:[batch_size, sequence_length, d_model]
# 注意力张量:p_attn, shape:batch_size*sequence_length*sequence_length
return torch.matmul(p_attn,v),p_attn
#%% 多头注意力
# 就是对词向量进行拆分再使用attention
import copy
def clones(module, num):
return nn.ModuleList([copy.deepcopy(module) for _ in range(num)])
class MultiHeadAttention(nn.Module):
def __init__(self,head,d_model,dropout=0.1):
#embedding_dim:就是class PositionalEmbedding里设置的d_model的值
super(MultiHeadAttention,self).__init__()
self.head=head
assert d_model % head == 0
self.d_k=d_model/ head
self.d_model=d_model
self.linears=copy(nn.Linear(self.d_model, self.d_model),4)
self.dropout=dropout
self.attn=None
def forward(self,q,k,v,masked=None):
if masked is not None:
masked=masked.unsqueeze(1)
batch_size=q.size[0]
# http://nlp.seas.harvard.edu/2018/04/03/attention.html
# 原文的图中意思是将q,k,v从d_model(假设512维)映射到不同的子空间(维度都为d_k,假设为64)中
# 但是实际的做法是直接截取d_k维度(8)的词向量做同维度(8)映射
# 最后转换后形状为: 句子数量 * 头的数量(8) * 每个句子单词数 * 截取的词维度数目(64)
q,k,v=[l(x).view(batch_size,-1,self.head,self.d_k).transpose(1,2) for l,x in zip(self.linears,(q,k,v))]
x,self.attn=attention(q,k,v,masked,self.dropout)
# contiguous()的作用在于使得后面的view能用,不然报bug
# 实际上在完成concat,将8个片段合在一起,重新化为512维
x=x.transpose(1,2).contiguous().view(batch_size,-1,self.head * self.d_k)
return self.linears[-1](x)
#%% patch embedding
#原来的设计先将每个patch窗口里的像素点flatten,然后用一个餐宿共享的全连接层做最初的变换,算是做了一步特征提取
#后来发现这一步与CNN里的卷积很像,于是直接用卷积实现
class pathEmbedding(nn.Module):
def __init__(self,img_size=224, patch_size=16,in_channel=3,emb_dim=768,norm_layer=None):
# img_size: 图片的形状
# patch_dim:每次截取的正方形窗口的形状,默认是16
# in_channel:默认是彩图,RGB三通道,所以是3
# emd_dim:类似于NLP里的词向量嵌入,这里的768=14*14*3
# 即将每次截的窗口里的像素,共16*16*3=768个flatten之
super(pathEmbedding, self).__init__()
self.img_size=img_size
self.in_channel=in_channel
self.after_shape=(self.img_size[-2]/patch_size, self.img_size[-1]/patch_size)
self.out_channel=emb_dim
self.patch_size=patch_size
self.conv=nn.Conv2d(self.in_channel, self.out_channel,kernel_size=patch_size,stride=patch_size)
self.norm=norm_layer(emb_dim) if norm_layer else nn.Identity()
def forward(self,x):
B,C,H,W=x.shape
# 如果shape不同就报错
assert H == self.img_size or W == self.img_size, f" input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
# flatten(dim) 从这个dim,包括这个dim开始flatten
# conv: [B,C,H,W] --> [B, C*patch_size*patch_size, H/patch_size, W/patch_size]
# 实际上这个 emb_dim = in_channel * patch_size * patch_size
# flatten: [B, emd_dim, H/patch_size, W/patch_size] --> [B, C*patch_size*patch_size, (H/patch_size)*(W/patch_size)]
# transpose: [B, C*patch_size*patch_size, (H/patch_size)*(W/patch_size)] --> [B, (H/patch_size)*(W/patch_size), C*patch_size*patch_size]
# 这一步的结果类似于transformer里面的embedding 句子数目 * 每句几单词 * 每个单词对应的词向量
# 这里我个人感觉可以理解为 几张图片 * 每张图片几个patch * 每个patch对应像素点
# 这里的patch给我的感觉非常类似于NLP的token
x=self.conv(x).faltten(2).transpose(1,2)
x=self.norm(x)
return x
#%%
# MLP
# 就是两层全连接
# 类似于Transformer里面的FeedForward
class Mlp(nn.Module):
def __init__(self,in_channel,hidden_channel,out_channel, act_layer=nn.GELU,dropout=0.):
super(Mlp, self).__init__()
hidden_channel= hidden_channel or in_channel
out_channel = out_channel or in_channel
self.fc1=nn.Linear(in_channel,hidden_channel)
self.ac1=act_layer()
self.fc2=nn.Linear(hidden_channel,out_channel)
self.drop=nn.Dropout(p=dropout)
def forward(self,x):
x=self.fc1(x)
x=self.ac1(x)
x=self.drop(x)
x=self.fc2(x)
x=self.drop(x)
return x
#%% LayerNorm
# BN是在每个维度上统计所有样本的值,计算均值和方差;
# LN是在每个样本上统计所有维度的值,计算均值和方差(语句里难以区分特征,不如视一句话一个特征)
class LayerNorm(nn.Module):
# d_model:词向量嵌入长度
# eps,一个放在分母的小数,为0
def __init__(self,d_model,eps=1e-6):
super(LayerNorm,self).__init__()
self.eps=eps
self.d_model=d_model
# self.a: 增益参数
# self.b: 偏移项
# 公式见 https://zhuanlan.zhihu.com/p/54530247 中的(4)
self.a=nn.Parameter(torch.ones(self.d_model))
self.b=nn.Parameter(torch.zeros(self.d_model))
def forward(self,x):
mean=torch.mean(x,dim=-1,keepdim=True)
std=torch.std(x,dim=-1,keepdim=True)
result=self.a*(x-mean)/(std+self.eps)+self.b
return result
#%%
class sublayerConnection(nn.Module):
def __init__(self, size, dropout):
# size等同于d_model
super(sublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
# 这里的 sublayer 指转换函数,如在encoder里面第一个sublayer 是MultiHeadAttention,第二个是FeedForward
# 这里归一化的位置是有些奇怪,个人熟悉的应该是 self.norm(x + self.dropout(sublayer(x)))
# 关于上一点会在 Encoder 的正式定义里见到,在正式输出到下个encoder之前会再norm一次
return x + self.dropout(sublayer(self.norm(x)))
#%%
# 相当于在Transformer 里的encoder部分, 差别在于是自注意力机制
# 实际上我这里是从transformer那里改过来的
# 由于droppath不那么常用,这里使用dropout
class Block(nn.Module):
def __init__(self,multi_head_attn,d_model,dropout,mlp_ratio=4):
super(Block,self).__init__()
# multi_head_attn:多头注意力机制的一个实现类
# feedForward:前馈全连接层的一个实现类,在这用的叫Mlp
self.multiHeadAttention=multi_head_attn
self.feedForward=Mlp(in_channel=d_model,hidden_channel=d_model,out_channel=d_model, act_layer=nn.GELU,dropout=dropout)
self.d_model=d_model
self.subPlayerConnect=clones(sublayerConnection(d_model,dropout),2)
def forward(self,x,mask=None):
# 解释一下,由于多头注意力机制需要四个参数,而subPlayerConnect只有一个参数传递的地方,所以其他三个位置的参数需要提前指定
# 在x + self.dropout(sublayer(self.norm(x)))里还是等价于 x+self.self_attn(self.norm(x), self.norm(x), self.norm(x), mask)
# 而feedForward只需要一个参数,所以可以直接使用
# 其实下面地self.multiHeadAttention(x, x, x, mask)即是自注意力机制
# 形象地,其计算了每个单词对其他单词的"注意力",最后结果是所有词向量的加权求和,即将其他位置的信息纳入计算,为每个位置提供了上下文表示
x=self.subPlayerConnect[0](x, lambda x: self.multiHeadAttention(x, x, x, mask))
x=self.subPlayerConnect[1](x,self.feedForward)
return x
#%% 模型的正式搭建
# 它的positional embedding有点奇怪,用的是一个可训练的形状的
#
from functools import partial
class VisionTransformer(nn.Module):
def __init__(self,img_size=224,patch_size=16,in_channel=3,num_classes=1000,
emb_dim=768,depth=12,num_heads=8,embed_layer=pathEmbedding,
pos_dropout=0.,mlh_dropput=0.,mlp_dropout=0.,mlp_ratio=4,norm_layer=None,act_layer=None):
super(VisionTransformer, self).__init__()
self.img_size=img_size
self.patch_size=patch_size
self.in_channel=in_channel
self.num_classes=num_classes
self.emb_dim=emb_dim
self.depth=depth
self.num_heads=num_heads
self.num_tokens = 1
# partial(func, *parameter ) 表示固定func中的参数,以*parameter中的数值固定
norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)
act_layer = act_layer or nn.GELU
self.patch_embed=embed_layer(img_size=self.img_size, patch_size=16,in_channel=3,emb_dim=768,norm_layer=norm_layer)
# 注册为会被更新的参数
self.cls_token=nn.Parameter(torch.zeros(1,1,self.emb_dim))
# //也是除法,只是向下得到整数
# 如果是224*224,patch_size=16的话,这里row=224//16=14
# col=16*16*3=768
row=self.img_size//self.patch_size
col=self.patch_size*self.patch_size*self.in_channel
# 对所有的向量图(shape已变为196*768)进行统一的位置编码,所以是二维是足够的,
self.pos_emb=nn.Parameter(torch.zeros(1,row,col))
self.pos_dropout=nn.Dropout(p=pos_dropout)
# encoder
multihead_attention=MultiHeadAttention(head=self.num_heads,d_model=self.emb_dim,dropout=mlh_dropput)
self.Block=Block(multihead_attention,d_model=self.emb_dim,dropout=mlp_dropout,mlp_ratio=mlp_ratio)
self.net_blocks=nn.Sequential(*[self.Block for i in range(depth)])
self.norm=norm_layer
# classifier
self.head = nn.Linear(self.emb_dim, num_classes) if num_classes > 0 else nn.Identity()
# Weight init
nn.init.trunc_normal_(self.pos_embed, std=0.02)
nn.init.trunc_normal_(self.cls_token, std=0.02)
self.apply(_init_vit_weights)
def forward_features(self,x):
# x.shape: bs*3*224*224
x=self.patch_embed(x)
# pathch_embed: bs*3*224*224 -> bs * 196 * 768
# .expand,,每项对应从0开始的维度,-1表示不处理,其他数字表示复制为几次,只有原维度为1时可用
# .expand: 1*1*emb_dim -> bs * 1 * emb_dim
cls_token=self.cls_token.epand(x.shape[0], -1, -1)
# cat: x: bs*196*768 -> bs*197*768
x = torch.cat((cls_token, x), dim=1)
x=self.pos_dropout(x+self.pos_emb)
x=self.net_blocks(x)
x=self.norm(x)
return x[:, 0], x[:, 1]
def forward(self,x):
x = self.forward_features(x)
x = self.head(x)
return x
def _init_vit_weights(m):
"""
ViT weight initialization
:param m: module
"""
if isinstance(m, nn.Linear):
nn.init.trunc_normal_(m.weight, std=.01)
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out")
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.LayerNorm):
nn.init.zeros_(m.bias)
nn.init.ones_(m.weight)
#%%
def vit_base_patch16_224(num_classes: int = 1000):
"""
ViT-Base model (ViT-B/16) from original paper (https://arxiv.org/abs/2010.11929).
ImageNet-1k weights @ 224x224, source https://github.com/google-research/vision_transformer.
weights ported from official Google JAX impl:
链接: https://pan.baidu.com/s/1zqb08naP0RPqqfSXfkB2EA 密码: eu9f
"""
#img_size=224,patch_size=16,in_channel=3,num_classes=1000,
# emb_dim=768,depth=12,num_heads=8,embed_layer=pathEmbedding,
# pos_dropout=0.,mlh_dropput=0.,mlp_dropout=0.,mlp_ratio=4,norm_layer=None,act_layer=None
model = VisionTransformer(img_size=224,
patch_size=16,
in_channel=3,
emb_dim=768,
depth=12,
num_heads=12,
num_classes=num_classes)
return model















 192
192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









