






介绍
哈夫曼编码(Huffman Coding),又称霍夫曼编码。Huffman于1952年提出这种编码方式。主要功能就是缩短编码长度。论文采用哈夫曼编码,目的就是尽可能的缩短位图(bit map)的编码长度,节省存储空间。
构建方法
首先构建哈夫曼树。构建哈夫曼树的原则就是①先合并权值最小,在具体应用中就是出现频率最小的两个节点;②所有节点必须都在树上。
比如我们有5种字符,ABCDE,出现频率如下:
A 0.15
B 0.1
C 0.15
D 0.2
E 0.4
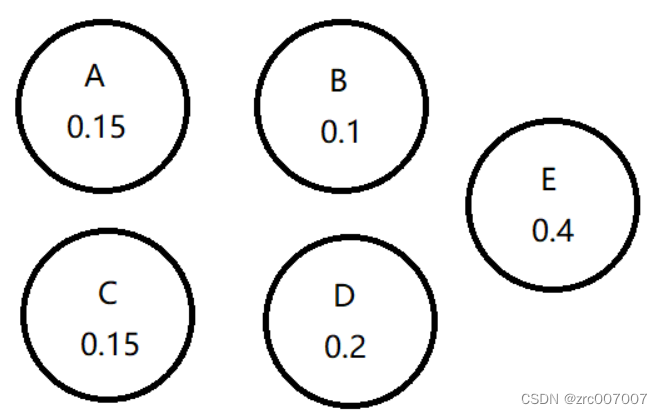
根据首先合并最小两项的原则,选择最小的B,因为它是0.1,然后选择出现频率第二低的0.15的,这里就选择A吧,合并为一项。
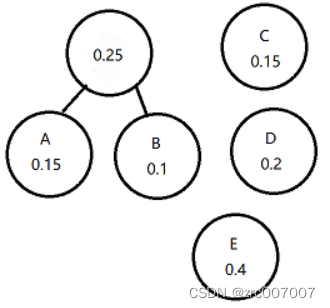
然后再找出现频率最低的两项,我们找到了C和D, 0.15和0.2的。
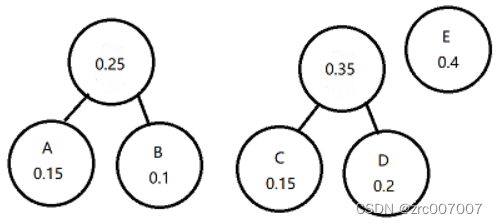
注意,合并后的一项单独算所有子项加起来的权重/概率,所以现在场上剩下 3个节点:0.25节点、0.35节点和E节点(0.4)。于是我们把0.25节点和0.35节点合并。
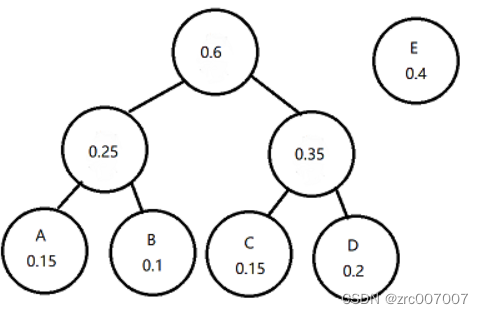
最后自然是合并0.6节点和E节点。
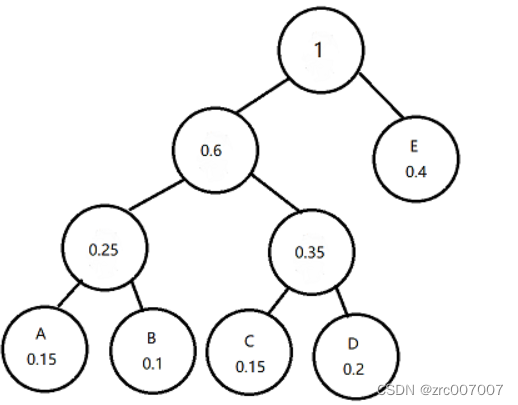
然后根据哈夫曼树进行编码,就可以得到哈夫曼编码了。我们先确认编码规则,很简单,左边标1,右边标0,还是左边标0,右边标1。比如我们这里选左边标1,右边标0,那标出来的结果就是这样的:
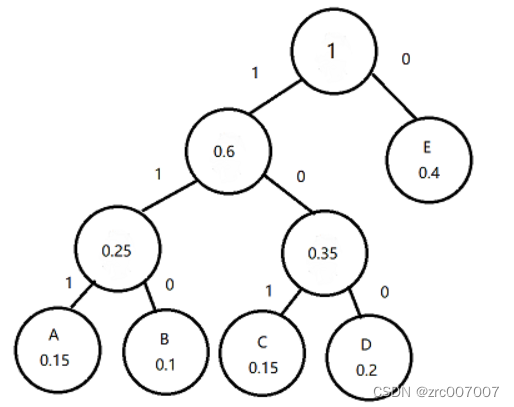
所以编码结果如下:
A 111
B 110
C 101
D 100
E 0
对比
不妨再计算一下,如果按这样编码,比起按数字逐个编码,即:
A 000
B 001
C 010
D 011
E 100
算都不用算了,A到D都是3个字符,E省了俩,肯定是短的。
如果非要计算,那就是这样的:
怎么样,算出来是不是也是少了0.8个单位长度的~
唯一可译性
那你可能会问了,欸,你这按数字来,是每个都编3个长度的,那我数字编短一点,0编0,1编1,2编10不就肯定比那什么哈夫曼的短嘛。
短是短了,但你看看会出什么问题:
假设编码按你所想是这样的:
A 0
B 1
C 10
D 11
E 100
比如我要传EDCBA,按最短的数字大小编,会传什么比特流呢?是这样的:
好的,请问,你一开始传的,前面3个,到底是1、0、0构成BAA呢,还是10、0构成CA呢,还是你要说的100构成E呢。
所以这种编码方式,它存在一个问题就是无法唯一识别比特流中的编码顺序。术语叫没有唯一可译性。
而哈夫曼编码很好的解决了这个问题。比如同样是EDCBA,按照我们上面得到的编码,应该编成什么样呢?
A 111
B 110
C 101
D 100
E 0
EDCBA就是:
其实你从哈夫曼树来看,就知道这种编码是肯定不会编码出歧义的。
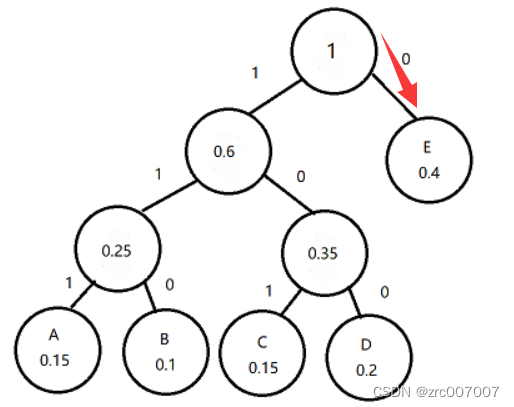
比如一开始的是0,根据哈夫曼树,根节点到0的只有E这个节点,那第一个字符,就是第一1个比特,0,代表E;
好,那第二个字符,从第2个比特开始,第一位为1,从根节点到1,又有分支,那继续看,第3个比特为0,那就是到了右边,还继续,第4个比特位0,又走到右边,这下确定是D了。
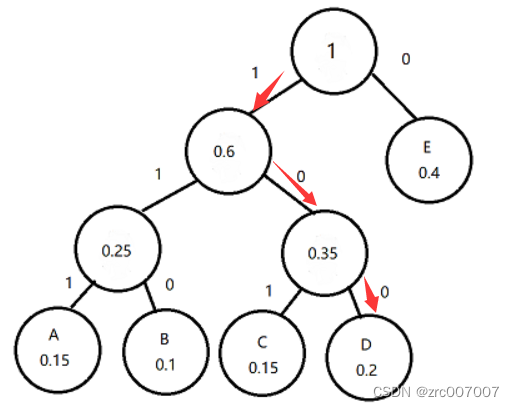
第三个字符,从第5个比特开始,1,0,1,然后第四个字符……
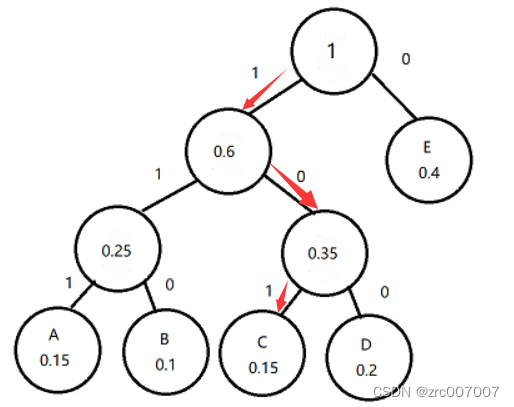
这样,从开始到结束,总能找到唯一的结果与之对应,所以哈夫曼不存在混乱编码的问题。
这个就是所谓的,哈夫曼编码的所有编码都是不同的前缀码,保证了编码的唯一可译性。

















 1896
1896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









