






模板转换jinjia2包链接:https://pan.baidu.com/s/1ycb_zf8oS88HF0FvpXrYFg?pwd=ym9n
提取码:ym9n
import os
from jinja2 import Environment, PackageLoader
class xml_fill:
def __init__(self, path, width, height, depth=3, database='Unknown', segmented=0):
environment = Environment(loader=PackageLoader('source', 'XML_template'), keep_trailing_newline=True)
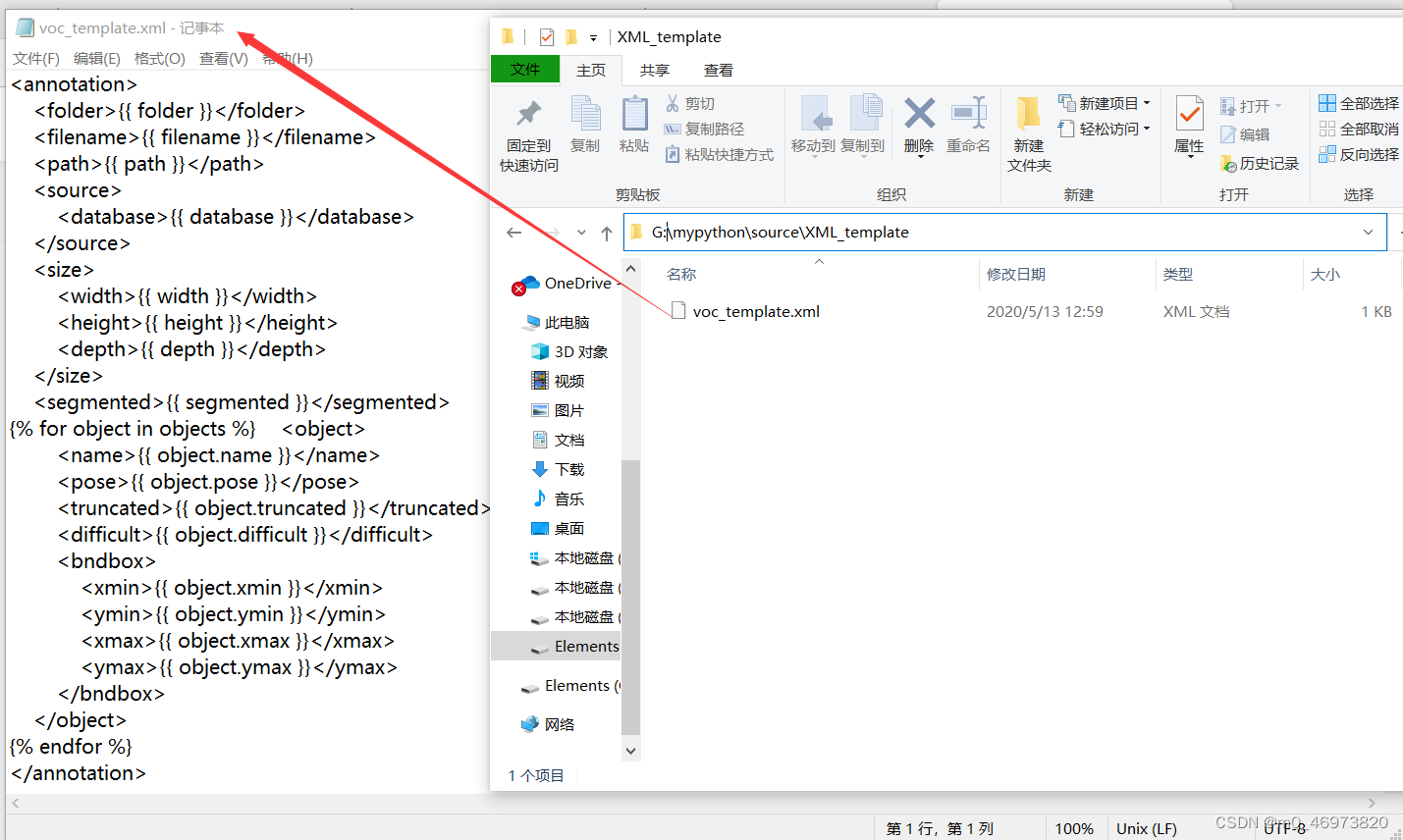
self.annotation_template = environment.get_template('voc_template.xml')
abspath = os.path.abspath(path)
self.template_parameters = {
'path': abspath,
'filename': os.path.basename(abspath),
'folder': os.path.basename(os.path.dirname(abspath)),
'width': width,
'height': height,
'depth': depth,
'database': database,
'segmented': segmented,
'objects': []
}
def add_obj_box(self, name, xmin, ymin, xmax, ymax, pose='Unspecified', truncated=0, difficult=0):
self.template_parameters['objects'].append({
'name': name,
'xmin': xmin,
'ymin': ymin,
'xmax': xmax,
'ymax': ymax,
'pose': pose,
'truncated': truncated,
'difficult': difficult,
})
def save_xml(self, annotation_path):
with open(annotation_path, 'w') as file:
content = self.annotation_template.render(**self.template_parameters)
file.write(content)
import json
import os
from PIL import Image
from voc_xml_generator import xml_fill
tt100k_parent_dir = "G:\\"
def find_image_size(filename):
with Image.open(filename) as img:
img_weight = img.size[0]
img_height = img.size[1]
img_depth = 3
return img_weight, img_height, img_depth
def load_mask(annos, datadir, imgid, filler):
img = annos["imgs"][imgid]
path = img['path']
for obj in img['objects']:
name = obj['category']
box = obj['bbox']
xmin = int(box['xmin'])
ymin = int(box['ymin'])
xmax = int(box['xmax'])
ymax = int(box['ymax'])
filler.add_obj_box(name, xmin, ymin, xmax, ymax)
work_sapce_dir = os.path.join(tt100k_parent_dir, "TT100K\\VOCdevkit\\")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
work_sapce_dir = os.path.join(work_sapce_dir, "VOC20230102\\")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
jpeg_images_path = os.path.join(work_sapce_dir, 'JPEGImages')
annotations_path = os.path.join(work_sapce_dir, 'Annotations')
if not os.path.isdir(jpeg_images_path):
os.mkdir(jpeg_images_path)
if not os.path.isdir(annotations_path):
os.mkdir(annotations_path)
datadir = tt100k_parent_dir + "TT100K\\data"
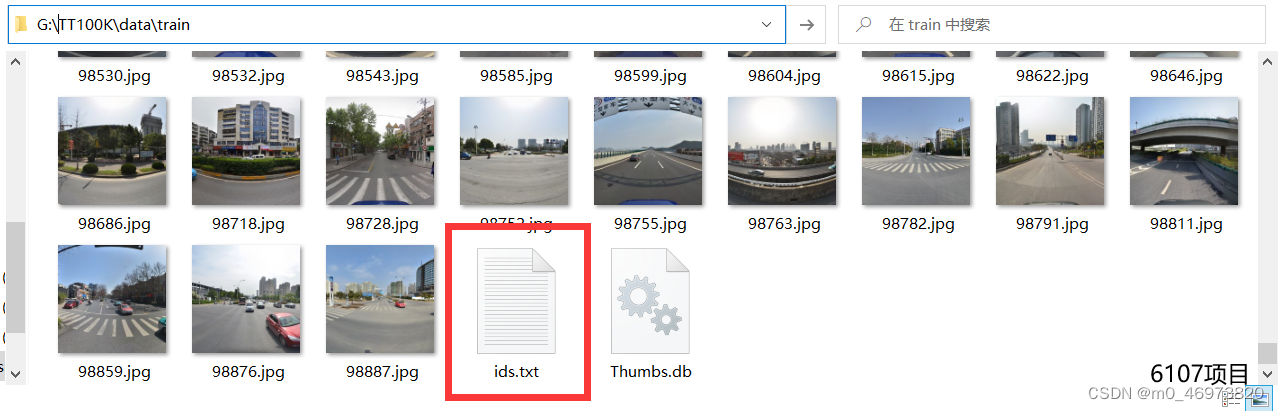
filedir = datadir + "\\annotations.json"
ids = open(datadir + "\\train\\ids.txt").read().splitlines()
annos = json.loads(open(filedir).read())
for i, value in enumerate(ids):
imgid = value
filename = datadir + "\\train\\" + imgid + ".jpg"
width,height,depth = find_image_size(filename)
filler = xml_fill(filename, width, height, depth)
load_mask(annos, datadir, imgid, filler)
filler.save_xml(annotations_path + '\\' + imgid + '.xml')
print("%s.xml saved\n"%imgid)
import xml.etree.ElementTree as ET
import os
import random
from shutil import move
type45="i2,i4,i5,il100,il60,il80,io,ip,p10,p11,p12,p19,p23,p26,p27,p3,p5,p6,pg,ph4,ph4.5,ph5,pl100,pl120,pl20,pl30,pl40,pl5,pl50,pl60,pl70,pl80,pm20,pm30,pm55,pn,pne,po,pr40,w13,w32,w55,w57,w59,wo"
type45 = type45.split(',')
classes = type45
TRAIN_RATIO = 80
def clear_hidden_files(path):
dir_list = os.listdir(path)
for i in dir_list:
abspath = os.path.join(os.path.abspath(path), i)
if os.path.isfile(abspath):
if i.startswith("._"):
os.remove(abspath)
else:
clear_hidden_files(abspath)
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
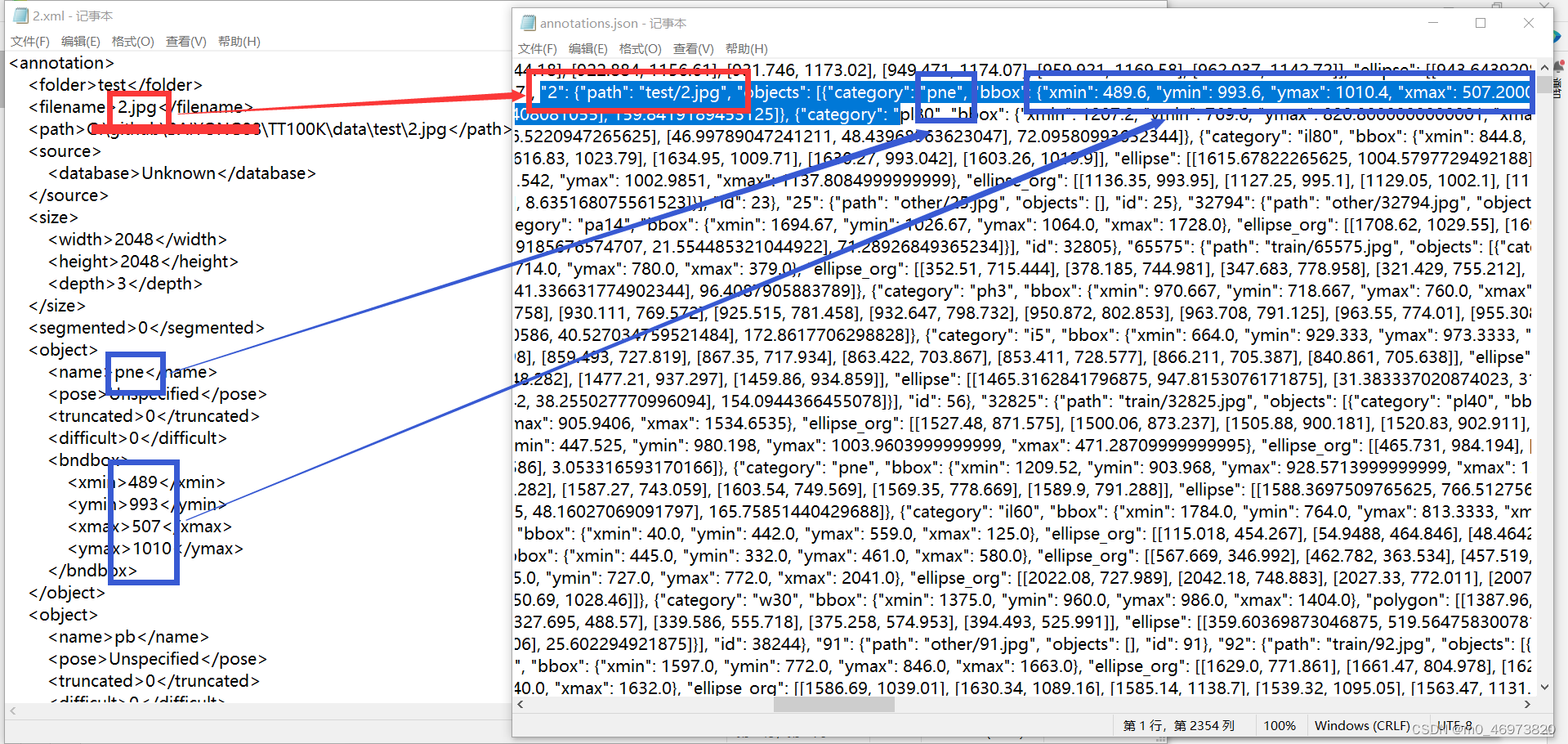
def convert_annotation(image_id):
in_file = open('VOC/2022/ANNOTATIONS/%s.xml' %image_id)
out_file = open('VOC/2022/YOLOLabels/%s.txt' %image_id, 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
wd = os.getcwd()
wd = os.getcwd()
data_base_dir = os.path.join(wd, "VOC/")
if not os.path.isdir(data_base_dir):
os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, "2022/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "ANNOTATIONS/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "IMAGE/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/")
if not os.path.isdir(yolo_labels_dir):
os.mkdir(yolo_labels_dir)
clear_hidden_files(yolo_labels_dir)
yolov5_images_dir = os.path.join(data_base_dir, "images/")
if not os.path.isdir(yolov5_images_dir):
os.mkdir(yolov5_images_dir)
clear_hidden_files(yolov5_images_dir)
yolov5_labels_dir = os.path.join(data_base_dir, "labels/")
if not os.path.isdir(yolov5_labels_dir):
os.mkdir(yolov5_labels_dir)
clear_hidden_files(yolov5_labels_dir)
yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")
if not os.path.isdir(yolov5_images_train_dir):
os.mkdir(yolov5_images_train_dir)
clear_hidden_files(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")
if not os.path.isdir(yolov5_images_test_dir):
os.mkdir(yolov5_images_test_dir)
clear_hidden_files(yolov5_images_test_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")
if not os.path.isdir(yolov5_labels_train_dir):
os.mkdir(yolov5_labels_train_dir)
clear_hidden_files(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")
if not os.path.isdir(yolov5_labels_test_dir):
os.mkdir(yolov5_labels_test_dir)
clear_hidden_files(yolov5_labels_test_dir)
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'w')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'w')
train_file.close()
test_file.close()
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'a')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'a')
list_imgs = os.listdir(image_dir) # list image files
prob = random.randint(1, 100)
for i in range(0,len(list_imgs)):
path = os.path.join(image_dir,list_imgs[i])
if os.path.isfile(path):
image_path = image_dir + list_imgs[i]
voc_path = list_imgs[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
label_name = nameWithoutExtention + '.txt'
label_path = os.path.join(yolo_labels_dir, label_name)
prob = random.randint(1, 100)
if(prob < TRAIN_RATIO): # train dataset
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
move(image_path, yolov5_images_train_dir + voc_path)
move(label_path, yolov5_labels_train_dir + label_name)
else: # test dataset
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
move(image_path, yolov5_images_test_dir + voc_path)
move(label_path, yolov5_labels_test_dir + label_name)
train_file.close()
test_file.close()



class LoadImgLabels(Dataset):
# root = "YOLO/VOC"
def __init__(self,root,mode):
super(LoadImgLabels, self).__init__()
self.root = root
self.mode = mode
img_path = get_path(os.path.join(root,'images',self.mode))
lab_path = get_path(os.path.join(root,'labels',self.mode))
self.img_files = get_file(img_path)
self.label_files = img2label_paths(self.img_files)
def __len__(self):
return len()
def __getitem__(self, item):
return# 获得(不同操作系统)标准路径
def get_path(path):
p = str(Path(path))
return p# 得到路径下的每个文件
def get_file(path):
file = []
if os.path.isdir(path):
file += glob.iglob(path + os.sep + '*.*')
return file# 由图片的文件得到对应标签的文件
def img2label_paths(img_paths):
sa, sb = os.sep + 'images' + os.sep, os.sep + 'labels' + os.sep
return [x.replace(sa, sb, 1).replace(os.path.splitext(x)[-1], '.txt') for x in img_paths]# 缓存标签
def cache_labels(img_files, label_files, path='labels.cache'):
x = {}
pbar = tqdm(zip(img_files, label_files), desc='Scanning images', total=len(img_files))
for (img, label) in pbar:
print(img,label)
try:
l=[]
im = Image.open(img)
im.verify()
shape = im.size
if os.path.isfile(label):
with open(label,'r') as f:
l = np.array([x.split() for x in f.read().splitlines()], dtype=np.float32)
if len(l) == 0:
l = np.zeros((0, 5), dtype=np.float32)
x[img] = [l,shape]
except:
pass
torch.save(x, path)
return x
class LoadImgLabels(Dataset):
# root = "../VOC"
def __init__(self,root,mode,img_size):
super(LoadImgLabels, self).__init__()
self.root = root
self.mode = mode
self.img_size = img_size # 输入图片分辨率大小
img_path = get_path(os.path.join(root,'images',self.mode))
if os.path.isfile('labels.cache'):
print("读取缓存标签文件'labels.cache'")
cache = torch.load('labels.cache')
else:
print("生成缓存标签文件'labels.cache'")
self.img_files = get_file(img_path)
self.label_files = img2label_paths(self.img_files)
cache = cache_labels(self.img_files, self.label_files)
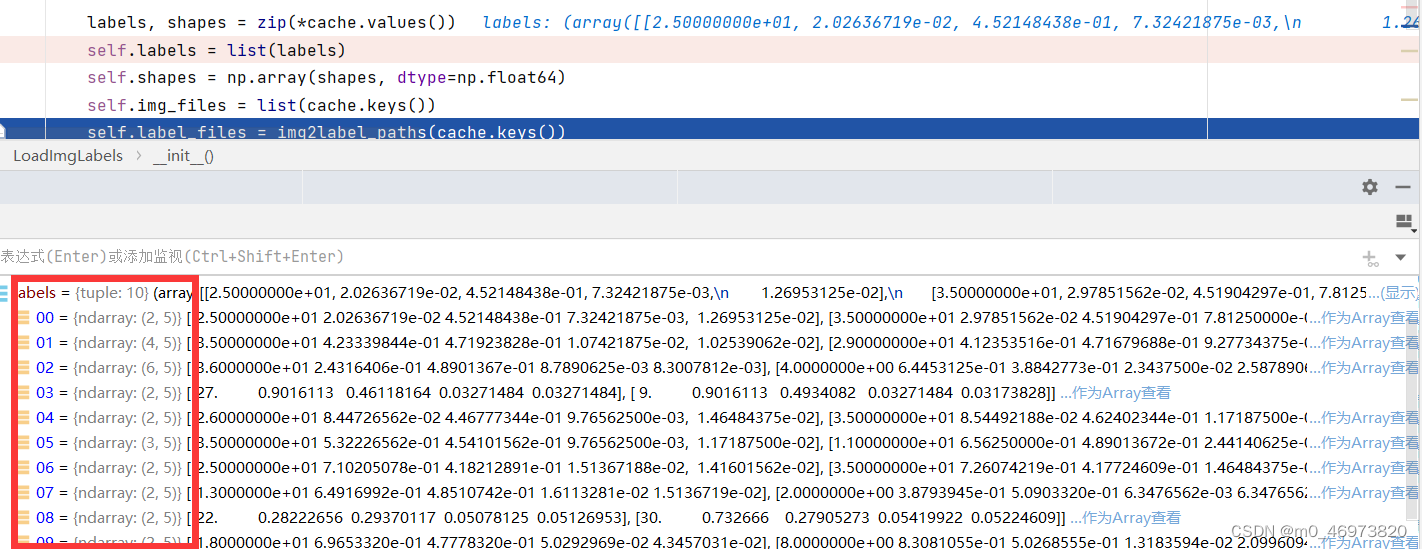
labels, shapes = zip(*cache.values())
self.labels = list(labels)
self.shapes = np.array(shapes, dtype=np.float64)
self.img_files = list(cache.keys())
self.label_files = img2label_paths(cache.keys())
def __len__(self):
return len(self.img_files)
def __getitem__(self, index):
return 0
# 加载图片
并根据设定的输入大小与图片原大小的比例ratio进行resize;
if img_size = 640:(1080, 1920)———>(360, 640)
def load_image(img_files, img_size , index): # img_size = 640
path = img_files[index]
img = cv2.imread(path)
h0 ,w0 = img.shape[:2]
r = img_size / max(h0,w0)
if r != 1:
interp = cv2.INTER_AREA if r < 1 else cv2.INTER_LINEAR
img = cv2.resize(img, (int(w0 * r), int(h0 * r)), interpolation=interp)
return img, (h0, w0), img.shape[:2] # (1080, 1920)———>(360, 640)# 图像缩放: 保持图片的宽高比例,剩下的部分采用灰色填充。
def Make_squqre(img, new_shape=(640, 640), color=(114, 114, 114)):
# Resize image to a 32-pixel-multiple rectangle https://github.com/ultralytics/yolov3/issues/232
shape = img.shape[:2] # 当前图片大小
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# ----------------计算填充大小-----------------------------------------
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])# r = 1.0
ratio = r, r # ratio = (1.0,1.0)
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # 填充宽度,高度
# 计算上下左右填充大小
dw /= 2
dh /= 2
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
# ------------------进行填充-------------------------------------------
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color)
return img, ratio, (dw, dh)对标签的处理
# 1根据pad调整框的标签坐标
# 2调整框的标签,xyxy->xywh
# 3归一化标签0 - 1
labels = []
x = self.labels[index]
if x.size > 0:
# 根据pad调整框的标签坐标:注意label是真实位置,没有归一化的
labels = x.copy()
labels[:, 1] = ratio[0] * w * (x[:, 1] - x[:, 3] / 2) + pad[0]
labels[:, 2] = ratio[1] * h * (x[:, 2] - x[:, 4] / 2) + pad[1]
labels[:, 3] = ratio[0] * w * (x[:, 1] + x[:, 3] / 2) + pad[0]
labels[:, 4] = ratio[1] * h * (x[:, 2] + x[:, 4] / 2) + pad[1]
nL = len(labels)
if nL:
labels[:, 1:5] = xyxy2xywh(labels[:, 1:5])
# 重新归一化标签0 - 1
labels[:, [2, 4]] /= img.shape[0] # normalized height 0~1
labels[:, [1, 3]] /= img.shape[1] # normalized width 0~1
labels_out = torch.zeros((nL, 6))
if nL:
labels_out[:, 1:] = torch.from_numpy(labels)# 左上角右下角坐标格式转换成中心点+宽高坐标格式
def xyxy2xywh(x):
# Convert nx4 boxes from [x1, y1, x2, y2] to [x, y, w, h] where xy1=top-left, xy2=bottom-right
y = torch.zeros_like(x) if isinstance(x, torch.Tensor) else np.zeros_like(x)
y[:, 0] = (x[:, 0] + x[:, 2]) / 2 # x center
y[:, 1] = (x[:, 1] + x[:, 3]) / 2 # y center
y[:, 2] = x[:, 2] - x[:, 0] # width
y[:, 3] = x[:, 3] - x[:, 1] # height
return ydataloader
import torch
from contextlib import contextmanager
from tqdm import tqdm
from YOLO.dataset.dataset import LoadImgLabels
# 定义生成器 _RepeatSampler
class _RepeatSampler(object):
def __init__(self, sampler):
self.sampler = sampler
def __iter__(self):
while True:
yield from iter(self.sampler)
# 定义DataLoader(一个python生成器)
class InfiniteDataLoader(torch.utils.data.dataloader.DataLoader):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
object.__setattr__(self, 'batch_sampler', _RepeatSampler(self.batch_sampler))
self.iterator = super().__iter__()
def __len__(self):
return len(self.batch_sampler.sampler)
def __iter__(self): # 实现了__iter__方法的对象是可迭代的
for i in range(len(self)):
yield next(self.iterator)
@contextmanager
def torch_distributed_zero_first(local_rank: int):""
if local_rank not in [-1, 0]:
torch.distributed.barrier() # Synchronizes all processes
yield
if local_rank == 0:
torch.distributed.barrier()
# 利用自定义的数据集(LoadImagesAndLabels)创建dataloader
def create_dataloader(path, mode , imgsz, batch_size,rank=-1):
with torch_distributed_zero_first(rank):
dataset = LoadImgLabels(path, mode, imgsz)
batch_size = min(batch_size, len(dataset))
dataloader = InfiniteDataLoader(dataset,# torch.utils.data.DataLoader
batch_size=batch_size,
shuffle=True,
collate_fn=LoadImgLabels.collate_fn,
pin_memory=True)
return dataloader, dataset
dataloader, dataset = create_dataloader("G:\VOC", 'train',640, 2)
pbar = enumerate(dataloader)
nb = len(dataloader)
pbar = tqdm(pbar, total=nb)
for i, (imgs, targets, path) in pbar:
ni = i + nb * 1
imgs = imgs / 255.0
print(imgs.size(),targets.size())













 1676
1676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









