







1. 摘要
论文:《Generative Adversarial Nets》
论文链接:https://arxiv.org/abs/1406.2661
自2014年Ian Goodfellow提出了GAN(Generative Adversarial
Network)以来,对GAN的研究可谓如火如荼。各种GAN的变体不断涌现,GAN全称对抗生成网络,顾名思义是生成模型的一种,而他的训练则是处于一种对抗博弈状态中的。
GAN的基本原理其实非常简单,这里以生成图片为例进行说明。假设我们有两个网络,G(Generator)和D(Discriminator)。正如它的名字所暗示的那样,它们的功能分别是:
- G是一个生成图片的网络,它接收一个随机的噪声z(可以是任意的简单分布,如高斯分布),通过这个噪声生成图片,记做G(z)。
- D是一个判别网络,判别一张图片是由Generator生成的还是来自真实数据的。它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。
在训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量把G生成的图片和真实的图片分别开来。这样,G和D构成了一个动态的“博弈过程”。最后博弈的结果是什么?在最理想的状态下,G可以生成足以“以假乱真”的图片G(z)。对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z)) = 0.5
2. GAN的原理
GAN主要的应用就是是集中在生成,对一个分布进行建模使其生成另一种分布,将网络当作一个Gennertor来用,特别的是我们在输入的时候加入一个随机噪声z,它是不固定的,是从一个distribution中sample出来的,这个分布足够简单,以至于我们知道他长什么样子,那么这样一来输入一个分布进入Generator就会输出另一个分布。
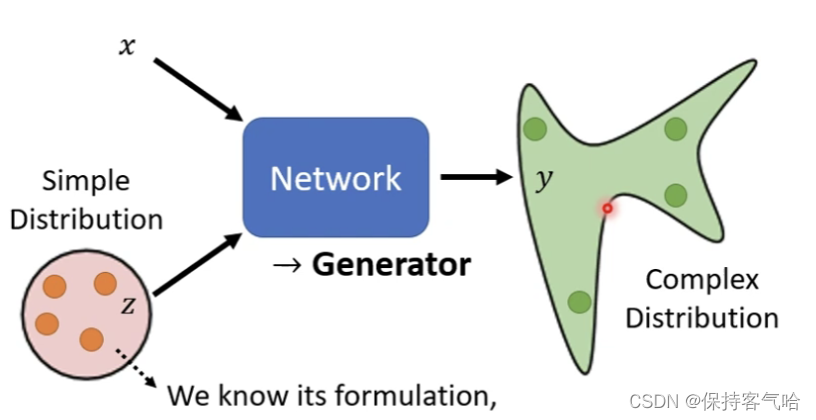
上述任务其实本质上就是在做一个极大似然估计的事情,我们希望可以用某一种具体的分布形式 ,尽可能逼真地表达另一个分布 ,这样我们就相当于是得到了最终想要的结果。
eg:
- 给定一个数据分布 P d a t a ( x ) P_{data}(x) Pdata(x)
- 给定一个由参数 θ \theta θ定义的数据分布 P G ( x ; θ ) P_{G}(x;\theta) PG(x;θ)
- 我们希望求得参数 θ \theta θ使得 P G ( x ; θ ) P_{G}(x;\theta) PG(x;θ) 尽可能接近 P d a t a ( x ) P_{data}(x) Pdata(x)
可以理解成: P G ( x ; θ ) P_{G}(x;\theta) PG(x;θ) 是某一具体的分布(比如简单的高斯分布),而 P d a t a ( x ) P_{data}(x) Pdata(x)是未知的(或者及其复杂,我们很难找到一个方式表示它),我们希望通过极大似然估计的方法来确定 θ \theta θ ,让 P G ( x ; θ ) P_{G}(x;\theta) PG(x;θ)能够大体表达 P d a t a ( x ) P_{data}(x) Pdata(x) 。然而问题在于 P G ( x ; θ ) P_{G}(x;\theta) PG(x;θ)的计算非常复杂,使用极大似然估计根本无从下手。那么这时候GAN就出现了,GAN由生成器 G G G和判别器 D D D组成。为了解决上述问题我们引入判别器 D D D。
- 我们先选取论文中的先验分布 P p i r o r P_{piror} Ppiror( 就是上述的随机分布),从该先验分布中采样z作为输入入到 G G G中,得到 G
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









