







1.摘要
红外和可见光图像融合在计算机视觉领域中起着重要作用。先前的方法努力在损失函数中设计各种融合规则。然而,这些实验设计的融合规则使方法变得越来越复杂。此外,它们大多只关注提升视觉效果,因此在后续的高级视觉任务中表现不尽如人意。为了解决这些挑战,在本文中,我们开发了一个语义级融合网络,充分利用语义引导,摆脱了实验设计的融合规则。此外,为了更好地理解特征融合过程的语义,我们以多尺度方式提出了一个基于Transformer的融合块。此外,我们设计了一个正则化损失函数,结合训练策略,充分利用高级视觉任务中的语义引导。与最先进的方法相比,我们的方法不依赖于手工设计的融合损失函数。尽管如此,在视觉质量以及后续的高级视觉任务方面,它仍然取得了卓越的性能。
2.引言
在本文中,我们提出了一个通用的语义驱动学习范式,用于研究特定任务的图像融合,而不是为IVIF显式构建融合规则。
我们可以粗略地将当前的学习方案分为两类:基于融合规则的方法和端到端的学习方案
具体而言,第一类融合方法依赖于手动设计的规则来近似地聚合模态特征。这些方法首先利用自动编码器机制提取和重构多模态特征,以充分学习显著的特征提取。然后,它们开发各种特征融合的融合规则,例如加权平均、求和、最大选择和L1范数。例如,Li等人首次将密集块作为可学习的自动编码器,并采用加权平均策略来融合模态特征。此后,Li等人3还提供了空间/通道注意机制作为融合策略,以嵌套连接融合特征。随后,Liu等人引入边缘注意引导的自动编码器来提取特征并采用简单的融合规则。
我们可以明显地观察到,当前的方法依赖于适当的融合策略来指导特征融合。然而,这些融合策略对不同数据分布不敏感,容易引发视觉伪影和模糊。更重要的是,融合策略的手动设计过于脆弱,无法保留适合支持后续高级视觉任务的合适模态特性。
与手动设计的融合规则不同,端到端的学习方法旨在直接建立源图像与融合图像之间的连接。具体而言,架构和损失函数是这些方法的两个具有挑战性的障碍。现有方法侧重于基于当前有效实践设计架构,而不考虑融合任务的特定属性。 虽然获得了可以获得显著统计指标的视觉吸引力结果。这些损失函数结合训练策略使方法变得更加复杂。此外,这些架构不能有效地提取模态特性,受卷积网络的局部感知能力限制。我们认为,这两种类别的方法都是为了提高融合的视觉质量,而忽略了后续语义任务的需求。
为了部分缓解这些问题,在本文中,我们提出了一种语义驱动的融合方法。我们不仅将图像融合视为一个独立的任务,还充分利用高级语义任务的引导,以保留有益信息并减少冲突。这样,我们的融合结果不仅突出了全面的信息,还有助于后续的语义任务。具体而言,我们首先提出了一个带有自注意机制的多尺度融合网络,以充分聚合模态特征。多尺度提取可以有效地从场景结构到上下文细节以粗到细的方式组合特征。自注意机制是建立多模态特征的长程依赖性,更好地描绘显著目标的全局表示。然后,我们引入相关的正则化来描述源图像与融合图像之间的关系。基于此,我们仅利用高级视觉任务的标准来训练融合和高级网络。
因此,这种策略解放了实验设计的融合规则,摒弃了模态统计指标的限制,并显著提高了高级视觉任务的性能。我们总结核心贡献如下:
- 提出了基于多尺度自注意机制的图像融合网络,以粗到细的方式有效地表示全局结构。
- 引入相关正则化,提出了一个完全语义驱动的训练策略,摆脱了手工设计的融合规则。
3.方法
3.1 网络架构
我们采用了来自下图的多尺度机制,分别处理纹理细节和语义信息。如图1所示,我们使用下采样(即最大池化)操作获取不同分辨率的特征图。其中,浅层特征图包含更多的纹理信息,而深层特征图则包含更多的语义信息。
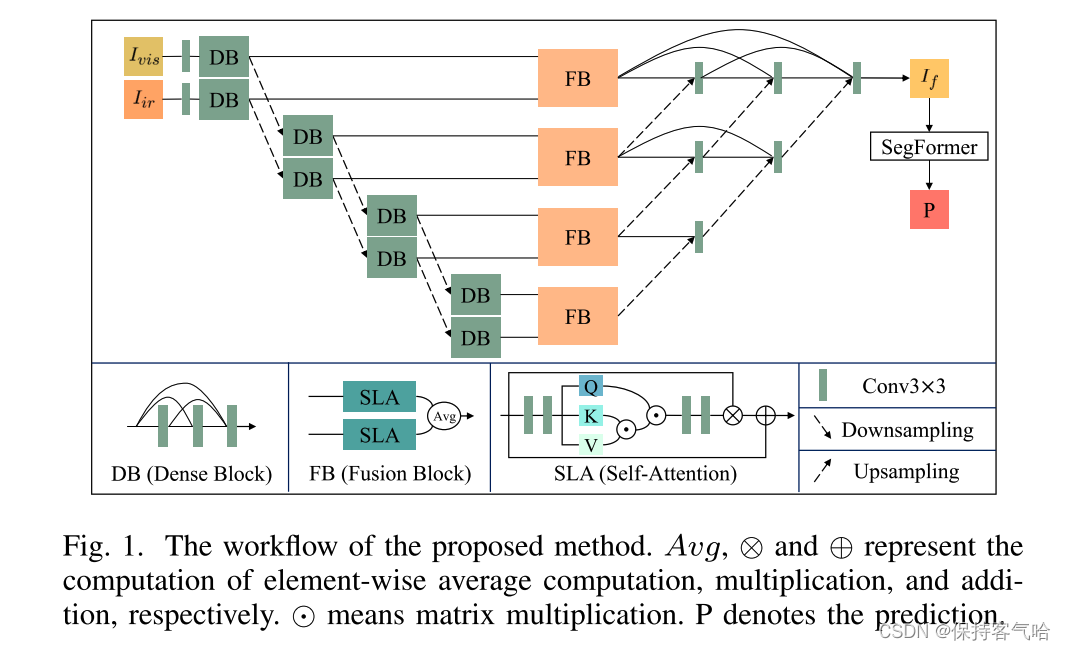
另一方面,为了融合提取的跨模态特征图,我们设计了一个基于高效自注意力的通用融合块。如图1底部所示,融合块由两个自注意模块组成,可以捕捉和强化全局感受野中的有用组件。在自注意模块中,我们将 R H × W × C R^{H×W×C} RH×W×C的特征图重塑为 R N × C R^{N×C} RN×C的向量,其中N = H×W。然后,我们使用线性层将向量编码为查询Q、键K和值V。我们通过矩阵乘法 K T V K^TV KTV得到注意力图,然后通过 Q S o f t m a x ( K T V ) QSoftmax(K^TV) QSoftmax(KTV)获得最终的注意力结果。强化的组件是通过逐元素相乘注意力结果和输入特征图获得的。为保留细节信息,我们进一步引入了残差连接。
3.2 训练策略
现有的端到端深度学习方法专注于设计融合规则以获得视觉上令人满意的结果。然而,手工设计的融合规则在场景方面存在严重限制,无法满足后续语义任务的基本要求。为了解决这个问题,我们开发了一种以语义为驱动的训练策略,以摆脱手动设计的限制。
1)热启动阶段:同时训练融合和分割网络是一种直观的策略。然而,在训练开始时,融合模型的参数是随机初始化的,因此无法为分割网络提供有意义的融合图像进行处理。因此,训练过程偏离了我们的预期。
为了解决这个问题,我们使用了一种平均策略来预训练融合模型,以获得可塑性的初始化。这个学习过程可以表示为:
m i n θ L W S ( N F ( I v i s , I i r ; θ ) ) , ( 1 ) \underset{θ}{min}L_{WS} (N_F (I_{vis}, I_{ir}; θ)),\quad (1) θminLWS(N
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 118
118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









