









目录
注:本笔记主要根据谭浩强教授主编的《C语言程设计(第五版)》、浙大翁凯老师MOOC教程和菜鸟教程整理而成,其中也包含自己学习过程中的一些随记。
第一章——基础
程序
程序,就是一组计算机能够识别和执行的指令。
程序设计是指从确定任务到得到结果、写出文档的全过程,一般经历一下几个阶段:
1.问题分析
2.设计算法
3.编写程序
4.对源程序进行编辑、编译和连接
5.运行程序,分析结果
计算机语言
1.计算机语言就是计算机能够识别并执行的语言
2.计算机能够直接识别和接受的二进制代码称为机器指令,机器指令的集合就是该计算机的机器语言。
3.计算机语言分为低级语言和高级语言,低级语言包括汇编语言和机器语言。
4.用高级语言编写的程序称为源程序,源程序通过编译/解释成为目标程序(机器指令,计算机能够直接执行)。
5.高级语言的发展阶段:
(1)非结构化程序设计,例BASIC(2)结构化程序设计,例Visual Fox Pro、C(3)面向对象的语言,例Java、C++
C语言的特点
C语言是面向过程的程序设计语言,属于计算机高级语言,即可编写应用软件又可编写系统软件。
特点:
1.语言简洁、紧凑,使用方便、灵活
2.运算符丰富
3.数据类型丰富
4.具有结构化的控制语句
5.语法限制不太严格,程序设计自由度大
C语言中的变量与常量
在计算机高级语言中,数据中有两种表现形式:常量与变量
1.常量:指在程序运行过程中,其值始终保持不变的量
常用的常量:整型常量、实型常量、字符常量(普通字符、转义字符)、字符串常量、符号常量
2.变量:指在计算机运行时,其值可以发生变化的量
变量特点:先定义,后使用
常变量
C99允许使用常变量,使用关键字“const”定义
常变量与常量的异同:常变量具有变量的基本属性:有类型,占存储单元,只是不允许改变其值
标识符
在计算机高级语言中,用来对变量、符号常量名、函数、数组、类型等命名的幼小字符序列统称为标识符
标识符只能由字母、数组、下划线三种字符组成,且第一个字符不能以数字开头
数据类型
1.C语言中数据类型分为基本类型、枚举类型、空类型、派生类型
2.基本类型和枚举类型变量的值都是数值,统称为算数类型。算数类型和指针类型统称为纯量类型。数组类型和结构体类型统称为组合类型。函数类型用来定义函数,描述一个函数的结构,包括函数返回值的数据类型和函数的类型
整型数据(int)
1.基本整形(int型):编译系统分配给int型数据2个字节或4个字节。
2.整形数据的存储储方式为:用整数的补码形式存放
3.正数的补码是其本身,负数的补码是其原码按位取反后再加一。
4.短整型(short int):系统分配2字节,即16位。
5.长整型(long int):类型名为long int或long,4字节,即32位。
6.双长整型(long long int):类型名为long long int或long long,一般分配8字节。(此为C99新增类型)
注:C标准没有具体规定各种类型数据所占用存储单元的长度,这是由各编译系统自行决定的。
字符型数据(char)
字符型数据是按其代码(整数)形式存储的,因此C99中将字符型数据作为整数类型的一种。
1.ASCII码(美国国家信息标准交换码):一共有128个字符,用7位二进制数表示,每个字符占据1字节存储单位。ASCII128个字符中包含数字0~9、大写字母、小写字母、以及32个控制符。
2.字符虽然以整数形式存储,但是和整数大不相同。例如,字符'1'的ASCII码值为49,在计算机中占据1个字节,而整数1以整数存储时占据2个字节。
3.字符变量:字符变量是用类型符char(character的缩写)定义字符变量。一个字符变量只能赋予一个字符。
浮点型数据(float、double)
浮点型数据是用来表示具有小数点的实数的
浮点数由两部分组成:阶码和尾数
1.浮点数类型包括float(单精度浮点型)、double(双精度浮点型)、long double(长双精度浮点数)
2.float型(单精度浮点数):编译系统为每一个float型变量分配4个字节。
3.double(双精度浮点数):为了扩大能表示的数值范围,用8个字节存储一个double型数据,可以得到15位有效数字。为了提高运算精度,在C语言中进行浮点数的算数运算时,将float型数据都自动转换为double型,然后进行计算。
4.long double型(长双精度型):Turbo C对该类型分配16个字节,而Visual C++则对其与double型一样处理,分配8字节。
表示常量的类型
1.在一个整数的末尾加大写字母L或小写字母l,表示它是长整型(long int)
2.在一个浮点数的末尾加大写字母F或小写字母f,表示float型常量,分配4字节
运算符
C语言中提供的运算符种类有:
算数运算符、关系运算符、逻辑运算符、位运算符、赋值运算符、条件运算符、都好运算符、指针运算符、求字节数运算符、强制类型转换运算符、成员运算符、下标运算符等
(1)基本的算数运算符有(优先级由高到底):正、负、*、/、%、+、-
(2)自增自减运算符:“++”、“--”
其中该类运算符在表达式中的位置不同,其代表的意义也不相同,即在变量前表示先自增在参与运算,在变量后表示先参与运算运算结束后在进行自增。
(3)算数运算符的结合性:算数运算符是自左至右(左结合性),赋值运算符是自右至左(右结合性)
(4)强制类型转换格式:(类型名)(表达式),例:如x为float型,若转换为int型,需用"(int)x".
(5)逻辑运算符:!、&&、||
C语句
1.C语句作用和分类
1)一个函数包含声明部分和执行部分
2)一个C程序由若干个源程序文件组成,一个源文件可以由若干个函数和预处理指令以及全局变量生命不分组成。
3)控制语句:if()...else...,for()...,while()...,do...while(),continue,break,switch,return,goto
4)函数调用语句:函数调用语句由一个函数调用加一个分号组成
5)表达式语句:由一个表达式加一个分号构成,最典型的是由赋值表达式构成一个赋值语句
6)空语句:一行中存在一个字符且为分号
7)复合语句:用{}把一些语句和声明括起来构成复合语句(又称语句块)
8)赋值语句:给变量赋予内容的语句称为赋值语句,赋值符号为“==”
9)符合赋值运算符:+=、-=、/=、*=、%=
10)赋值表达式:由赋值运算符将一个变量和一个表达式连接起来的式子称为“赋值表达式”,它的一般形式为: <变量><赋值运算符><表达式>
数据的输入输出
1.输入输出是以计算机主机为主题而言的
2.C语言本身不提供输入输出语句
3.要在程序文件的开头用预处理指令“#include”把有关头文件放在本程序中
4.stdio.h头文件存放了调用标准输入输出函数时所需要的信息,包括与标准I/O库有关的变量定义和宏定义以及对函数的声明
5.编译预处理时,系统会把在该头文件中存放的内容调出来,取代本行的#include指令。这些内容就成为了程序的一部分
6.printf函数输出语句:
1)格式:printf(格式控制,输出列表)。
2)“格式控制”是用双撇号括起来的一个字符串,称为格式控制字符串,简称格式字符串。它包括两个信息:格式声明(由“%”和格式字符组成,如%d、%f等)和普通字符(即需要原样输出的字符)
3)“输出列表”是程序需要输出的一些数据,可以是常量、变量或表达式
7.格式字符:
1)d格式符:用来输出一个有符号的十进制整数。在输出时,按十进制整型数据的实际长度输出,正数的符号不输出。格式声明中可以设置输出数据的域宽(例,"%5d"表示指定输出数据占5列右对齐,如左对齐则需"%d-5")
2)c格式符:用来输出一个字符。如果是一个在0~127的整数,则可以输出其对应的ASCII字符,该格式也可以指定域宽
3)s格式符:用来输出一个字符串,如“printf("%s","asdfasdfa");”
4)f格式符:用来输出实数(包括单、双精度、长双精度),以小数形式输出,有以下几种方法:
4.1基本型:用%f,输出时整数部分全部输出,小数部分默认六位
4.2指定数据宽度和小数位数,用%m.nf,表示输出的数据占m列,且包含n位小数。注:一个双精度数只能保证15位有效数字的精确度,在用%f输出时要注意数据本身能提供的有效数字,如float型数据的存储单元只能保证6位有效数字,double型15位
4.3输出的数据左对齐,用“%-m.nf”
5)e/E格式符:用格式声明%e指定以指数形式输出实数
6)i格式符:作用与d葛师傅相同,按十进制数据的长度输出,一般习惯用d而少用i、
7)o格式符:以八进制整数形式输出,注:如果数据为负数,在计算机先将其转换为补码然后再以八进制输出
8)x/X格式符:以十六进制整数形式输出,其他功能与o类似
9)u格式符:用来输出无符号型数据,以十进制整数形式输出
10)g/G格式符:用来输出浮点数,系统自动选f格式或e格式输出,选择其中疮毒较短格式,不输出无意义的0
7.用scanf(格式化输出函数)函数输入数据:
1)格式:scanf(格式控制,地址列表)
2)其格式声明与printf类似
3)应注意的问题:scanf函数中的格式控制后面应当是变量地址,而不是变量名。“&<变量名>”表示该变量的地址信息
8.字符输入输出函数
1)putchar(c),可输出一个字符或字符型变量的值
2)getchar(c),读取用户输入的一个字符或字符型变量的值
6.C语言允许直接访问物理地址(即指针操作),能进行伟位操作,能实现汇编语言的大部分功能,可以直接对硬件进行操作
7.用C语言编写的程序可移植性好
8.生成目标代码质量高,程序执行效率高
C语言程序结构特点
第一个C程序:
#include<stdio.h>
int main(){
printf("HelloWorld!\n");
return 0;
}
C语言程序的结构特点:
1.一个程序有一个或多个源文件组成
2.预处理指令(如:#include<stdio.h>)
3.全局声明
4.函数定义
运行C程序的过程
1.上机输入和编辑源程序
2.对源程序进行编译
3.进行连接处理
4.运行可执行程序,得到运行结果
第二章——算法
程序的组成
1.程序主要包括两方面信息,即对数据的描述(数据结构)和对操作的描述(算法)
2.数据结构是指,在程序中要制定用到那些数据,以及这些数据的类型和数据的组织形式。
3.算法是指要求计算机进行操作的步骤。
算法
1.计算机算法分为两大类别:数值运算算法和非数值运算算法
2.算法的特点:有穷性、确定型、有零个或多个输入、有效性
3.表示算法的方式:自然语言、传统流程图、结构化流程图、伪代码
流程图
1.流程图分为传统流程图和NS流程图
2.传统流程图的组成:
起止框(圆角矩形)、输入输出框(平行四边形)、判断框(菱形)、运算处理框(矩形)、流程线(实心单项箭头线)、连接点(圆圈)、注释框
3.传统流程图的利弊:传统的流程图用流程线指出各框的执行顺序,对流程线的使用没有严格限制。因此,使用者可以不受限制地使流程随意的转来转去,使流程图变得毫无规律,阅读时要花费很大精力去准总流程,使人难以理解算法的逻辑。
4.三种基本结构:顺序结构、选择结构、循环结构(又分当型循环结构和直到型循环结构)
结构化程序设计方法
1.结构化程序就是用计算机语言表示的结构化算法
2.结构化程序设计方法的基本思路:把一个复杂问题的求解过程分阶段进行,每个阶段处理的问题都控制在人们绒里理解和处理的范围内。
3.结构化程序设计的特点(自顶向下,逐步求精):
自顶向下、逐步细化、模块化设计、结构化编码
第三章——程序结构
顺序结构
顺序结构是最简单的程序结构,也是最常用的程序结构,只要按照解决问题的顺序写出相应的语句就行,它的执行顺序是自上而下,依次执行。
分支结构——if语句
1.结构:
if(表达式){
执行代码块;
}2.语义:如果表达式的值为真,则执行其后的语句,否则不执行该语句。其流程图为:
3.注:if()后面没有分号,直接写{}
分支结构——if……else
1.格式:
if(表达式){
代码块1;
}else{
代码块2;
}2.语义:如果表达式为真,则执行代码块1,否则执行代码块2。流程图为:
3.注:if()后面没有分号,直接写{},else后面也没有分号,直接写{}
分支结构——多重if……else语句
1.格式:
if(表达式1){
代码块1;
}
……
else if(表达式m){
代码块m;
}
……
else{
代码块n;
}2.语义:一次判断表达式的值,当出现某个值为真时,则执行对应代码块,否则执行代码块n,流程图为:
3.注:当某一条件为真的时候,则不会向下执行该分支结构的其他语句
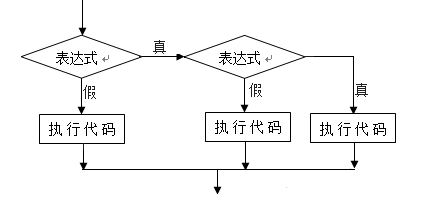
分支结构——嵌套if……else语句
1.格式:
2.流程图:
循环结构——while循环
1.循环就是反复不停的执行某个动作
2.格式:

3.其中表达式表示循环条件,执行代码块为循环体。while语句的语义是:计算表达式的值,当值为真(非0)时,执行循环体代码块。流程图为:
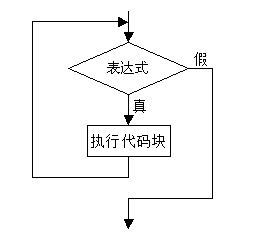
4.while语句中的表达式一般是关系表达式或逻辑表达式,当表达式的值为假时不执行循环体,反之则循环体一直执行。
5.在循环体中一定要改变循环变量的值,否则会出现死循环。
6.循环体如果包括一个以上的语句,则必须用{}括起来,组成复合语句。
循环结构——do……while循环
1.格式:

2.语义:它先执行循环中的执行代码块,然后再判断while中表达式是否为真,如果为真则继续循环;如果为假,则终止循环。因此do……while循环至少执行一次循环体语句。流程图为:
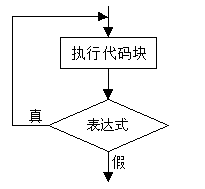
3.注:使用do……while结构语句时,while括号后必须有分号。
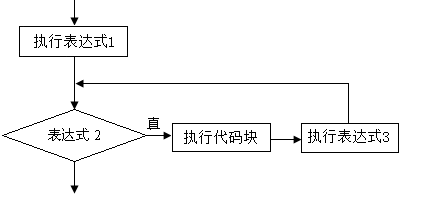
循环结构——for循环
1.for循环相对while和do…while而言更加灵活、直接、简单,其格式为:

2.执行过程为:
1)执行表达式1,对循环变量做初始化
2)判断表达式2,如其值为真(非0),则执行for循环体中执行代码块,然后向下执行;若其值为假(0),则结束循环
3)执行表达式3
4)执行for循环中执行代码块后执行第二步
5)循环结束,程序继续向下执行
3.流程图为:
4.for语句应注意的事项:
1)for循环中的“表达式1、2、3”均可省略,但分号(;)不能省略
2)省略“表达式1(循环变量赋初值)”,表示不对循环变量赋初始值
3)省略“表达式2(循环条件)”,不做其它处理,循环一直执行(死循环)
4)省略“表达式3(循环变量增量)”,不做其他处理,循环一直执行(死循环)
5)表达式1可以使设置循环变量的初值的赋值表达式,也可以是其他表达式
6)表达式1 和 表达式3可以使一个简单表达式也额可以是多个表达式以逗号分割
7)表达式2一般是关系表达式或逻辑表达式,但也可以是数值表达式或字符表达式,只要其值非零,就执行循环体
8)各表达式中的变量一定要在for循环之前定义
三种循环结构之间的比较
1.在知道循环次数的情况下更适合使用for循环
2.在不知道循环次数的情况下适合使用while或者do…while,如果有可能一次都不循环应考虑使用while循环,如果至少循环一次应考虑使用do…while循环,从本质上讲while和do…while和for循环之间是可以相互转换的
循环结构——多重循环
1.多重循环就是在循环体中又出现循环结构
2.一般最多用到三层,因为循环层数越多,运行时间越长,程序越复杂,所以一般用2-3层多重循环即可
3.多重循环在执行的过程中,外层循环为父循环,内层循环为子循环,父循环一次,子循环需要全部执行完,知道跳出循环。父循环再进入一次,子循环继续执行。
循环结构——break语句和continue语句
1.break语句的作用是结束本次循环并跳出当前循环体
2.使用break语句时应注意:在没有循环结构的情况下,break不能用在单独的if-else语句中。在多层循环中,一个break语句只跳出当前循环
3.continue语句的作用是结束本次循环开始下次循环
4.break语句与continue语句的区别是:break是跳出当前整个循环,continue是结束本次循环开始下一次循环
分支结构——switch语句
1.switch语句结构:

2.流程图为:
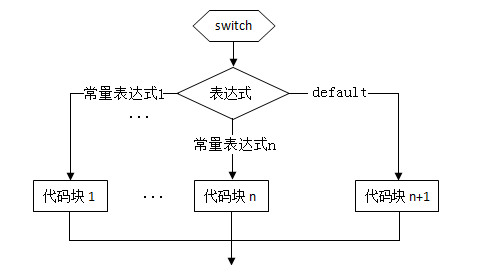
3.switch应注意点:在case后的各常量表达式的值不能相同,否则会出现错误;在case子句如果没有break,会一直往后执行一直到遇到break,才会跳出switch语句。
4.switch后面的表达式语句只能是整形或字符类型
5.在case后,允许有多个语句,可以不用{}括起来
6.各case和default子句的先后顺序可以变动,而不会影响程序执行结果
7.default自居可以省略不用
goto语句
1.格式:goto 语句标号;-----其中语句标号是一个标识符,该标识符一般用英文大写并遵守标识符命名规则,这个标识符加上一个':'一起出现在函数内某处,执行goto语句后,程序将跳转到该标识号处并执行其后的语句。
2.goto语句通常不用,主要因为它将使程序层次不清,且不易牍,但在特定情况下,可以使用goto语句来提高程序的执行速度。
第四章——数组
数组简介
1.在C语言中,需要指代一个东西时,我们可以使用白能量。当需要指代多个东西时,我们就需要用到数据。
2.数组可以存储一个固定大小的相同类型元素的顺序集合。
数组声明
1.数组的声明并不是一个个单独的变量,比如number0、number1……number9,而是声明一个数组变量,比如number,然后使用形如numberp[1]的形式来表示每一个单独的变量。数组中的特定元素可以通过索引访问。
2.所有数组都是由连续的内存位置组成。最低的地址对应第一个元素,最高的地址对应最后一个元素。第一个元素索引为0.
3.C语言中要声明一个数组,需要制定元素的类型和元素的数量,如:
type arrayName[array_size]
这样叫做一维数组,type为数组中存放内容的数据类型,和变量的数据类型一致,arrayName为数组名,arraySize是一个大于零的整数常数。
例:
int length[3]
数组中包含三个元素,都是int类型,若我们需要使用其中的元素时,可以通过length[0]、length[1]、length[2]的方式进行调用。
数组初始化
1.C语言中,数组可以逐个初始化,也可以使用如下的初始化语句:
double length[5] = {1.23,2.23,12.2,45.2,44.266};
注意:当初始化数组有长度时,花括号内数字个数不可以超过长度,否则会发生越界产生错误
2.数组声明时也可以省略数组大小,此时大小为初始化时元素的个数。
例:double length[]={1.23,0.225,4.98,9.21,0.66,123.654}; //数组大小为6
length[2]=2.222; //为数组中单个元素赋值
访问数组元素
数组元素可以通过数组名称加索引进行访问。元素的索引是存放在括号内,跟在数组名称的后边。
double max=length[4]; //将数组中第五个元素赋值给max
多维数组
C语言支持多维数组,其声明一般形式为:
type name[size1][size2][size3]……[sizeN]
1.二维数组
1)二维数组声明
二维数组是最简单的多维数组,也是最常用的多维数组,二维数组本质上是一个一维数组的列表,也就是表示多个一维数组。
例:int a[2][3]; //可以看作是一个两行三列的表格
2)二维数组初始化
多维数组可以通过在括号内为每行指定值来进行初始化
例:int[2][3]={
{2,3,5}, //初始化索引为0的行
{323,256,565}, //初始化索引为1的行
};
初始化时也可以不用内部嵌套:
int a[2][3]={2,3,5,5,8,8}; //与上一个初始化等价
3)二维数组元素访问
二维数组的元素时通过下标(即行索引和列索引)进行访问,例:
int a=a[1][1]; //将数组中的第二行第二列的元素赋值给a
第五章——函数
函数的概念及意义
1.函数也叫做模块化编程,是用于完成特定任务的程序代码单元,就是把一个小功能封装成一个独立的代码段。封装前与封装后的执行结果是完全一样的。
2.使用注意点:通常会把一个功能封装成一个函数,是专门某一功能的。
3.函数的封装无关代码的量。
4.在程序的执行过程中,从main开始,顺序向下执行,如果遇到了函数,则先执行完函数内的所有内容,借着返回,继续在主函数内向下执行。经过这两步跳转,会降低一点效率(微乎其微)
函数的作用
1.增加了代码的复用性(可被重复使用)。
2.增加了代码的可读性,便于其他人读懂,也便于快速找到问题所在,便于修改维护。
函数的类型
简单分为四类:无参数无返回值,无参数有返回值,有参数无返回值,有参数有返回值
无参数无返回值的函数
例:
1.这样的程序就可以展示出无参数无返回值的具体作用了,但是要注意,第二行后面一定不要有分号,像主函数后面不带分号一样,其次,调用时要加上小括号,不过无须写入任何其他的数据。
2.函数的定义包括了函数头和函数体,**返回值 函数名(参数列表)**的写法,但是如果在返回值的地方写上了void,表示函数没有返回值,或者我们不使用返回值,但是如果我们最后加上了return,编译器就会报错。返回值在C中可以不写,默认是int但是C++会报错,C++不支持默认的int。
函数头
函数名:名字就是标识符,相当于int a;中的a,这是个变量名。其实函数的本质也是个变量,只不过是比我们基本数据类型的变量复杂一点。函数名注意点:
1、起始必须是英文字母或者下划线,后面的是以数字,字母或者下划线任意组成,但是不能以数字开头。
2、不要用与系统重名的函数,比如printf,会报错“printf重定义”
3、函数的名字尽量把函数的功能体现出来,原则是将函数功能描述的越详细越好,可以使用尽量多的关键词。长度没有限制,但是描述的清晰程度直接影响了代码的可读性,尽量不要简写,让别人也能读懂。
4、规范写法,其实就是为了增加可读性。函数的参数列表:标准规定,如果函数没有参数,一定要加上void,跟主函数一样。如果不写表示参数个数不确定,写上表示不接受任何参数。但是C++没有这层意思,C++中不写==void。
函数体
1.函数实体,也就是代码部分,跟主函数一样,没有特殊的,但是要记得花括号
2.自定义函数与主函数:主函数是函数,自定义函数也是函数,没有区别,但是主函数是由操作系统调用的。
3.自定义函数与系统函数:printf、scanf等函数都叫系统函数,是微软提前定义好了的,我们可以直接使用,所以就起了个系统函数的名字,这些函数本质上和我们自定义的函数是一样的。
函数的调用
调用形式:函数名+(),小括号内是装参数的,所以没有参数就不用写,返回值的void也不要加(加上了之后是函数声明)。
函数调用的本质是函数地址+(参数列表),函数名字就是函数地址,对函数名字&即&fun也是函数地址,但是其实fun==&fun这一点非常重要(可以在编译器上写上这一行代码,如果级别不一样编译器就会报错),而且还要分辨fun是函数地址,fun()和(&fun)()都是函数调用。注意不要自己调用自己
return
1.return 数据:用于有返回值的函数,终止所在函数的执行,并返回指定数据。也就是说,当函数进行到return时,函数就结束了,不再执行下面的代码,直接跳到花括号。可以有多个2.return,但是只执行代码逻辑顺序中的第一个,比如说用到了if,goto等等,要根据逻辑来判断。而且所有逻辑都一定要有返回值。
3.return:用于无返回值的函数中,终止函数的执行。
4.返回多个值:首先明确概念:return一个只能返回一个值,可以返回一段连续空间的首地址,这段空间里装着多个值,也就是返回一个数组的首地址。
第六章——指针
什么是指针
指针是一个变量,其值为另一个变量的地址,即,内存位置的直接地址。就像其他变量或常量一样,您必须在使用指针存储其他变量地址之前,对其进行声明。指针变量声明的一般形式为:
type *var-name;在这里,type 是指针的基类型,它必须是一个有效的 C 数据类型,var-name 是指针变量的名称。用来声明指针的星号 * 与乘法中使用的星号是相同的。但是,在这个语句中,星号是用来指定一个变量是指针。以下是有效的指针声明:
int *ip; //一个整型的指针
double *dp; //一个double型的指针
float *fp; //一个浮点型的指针
char *ch; //一个字符型的指针
所有实际数据类型,不管是整型、浮点型、字符型,还是其他的数据类型,对应指针的值的类型都是一样的,都是一个代表内存地址的长的十六进制数。
不同数据类型的指针之间唯一的不同是,指针所指向的变量或常量的数据类型不同。
如何使用指针
使用指针时会频繁进行以下几个操作:定义一个指针变量、把变量地址赋值给指针、访问指针变量中可用地址的值。这些是通过使用一元运算符 * 来返回位于操作数所指定地址的变量的值。下面的实例涉及到了这些操作:
#include <stdio.h>
int main () {
int var = 20; // 实际变量的声明
int *ip; // 指针变量的声明
ip = &var; // 在指针变量中存储
var 的地址 printf("var 变量的地址: %p\n", &var ); // 在指针变量中存储的地址
printf("ip 变量存储的地址: %p\n", ip ); //使用指针访问值
printf("*ip 变量的值: %d\n", *ip );
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
var 变量的地址: 0x7ffeeef168d8
ip 变量存储的地址: 0x7ffeeef168d8
*ip 变量的值: 20C中的NULL指针
在变量声明的时候,如果没有确切的地址可以赋值,为指针变量赋一个 NULL 值是一个良好的编程习惯。赋为 NULL 值的指针被称为空指针。
NULL 指针是一个定义在标准库中的值为零的常量。请看下面的程序:
#include <stdio.h>
int main ()
{
int *ptr = NULL;
printf("ptr 的地址是 %p\n", ptr );
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
ptr 的地址是 0x0在大多数的操作系统上,程序不允许访问地址为 0 的内存,因为该内存是操作系统保留的。然而,内存地址 0 有特别重要的意义,它表明该指针不指向一个可访问的内存位置。但按照惯例,如果指针包含空值(零值),则假定它不指向任何东西。
如需检查一个空指针,您可以使用 if 语句,如下所示:
if(ptr) /* 如果 p 非空,则完成 */
if(!ptr) /* 如果 p 为空,则完成 */
指针算数运算——递增、递减
1、递增
我们喜欢在程序中使用指针代替数组,因为变量指针可以递增,而数组不能递增,数组可以看成一个指针常量。下面的程序递增变量指针,以便顺序访问数组中的每一个元素:
#include <stdio.h>
const int MAX = 3;
int main ()
{
int var[] = {10, 100, 200};
int i, *ptr;
/* 指针中的数组地址 */
ptr = var;
for ( i = 0; i < MAX; i++)
{
printf("存储地址:var[%d] = %p\n", i, ptr );
printf("存储值:var[%d] = %d\n", i, *ptr );
/* 指向下一个位置 */
ptr++;
}
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
存储地址:var[0] = e4a298cc
存储值:var[0] = 10
存储地址:var[1] = e4a298d0
存储值:var[1] = 100
存储地址:var[2] = e4a298d4
存储值:var[2] = 2002、递减
同样地,对指针进行递减运算,即把值减去其数据类型的字节数,如下所示:
#include <stdio.h>
const int MAX = 3;
int main ()
{
int var[] = {10, 100, 200};
int i, *ptr;
/* 指针中最后一个元素的地址 */
ptr = &var[MAX-1];
for ( i = MAX; i > 0; i--)
{
printf("存储地址:var[%d] = %p\n", i-1, ptr );
printf("存储值:var[%d] = %d\n", i-1, *ptr );
/* 指向下一个位置 */
ptr--;
}
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
存储地址:var[2] = 518a0ae4
存储值:var[2] = 200
存储地址:var[1] = 518a0ae0
存储值:var[1] = 100
存储地址:var[0] = 518a0adc
存储值:var[0] = 10指针的比较
指针可以用关系运算符进行比较,如 ==、< 和 >。如果 p1 和 p2 指向两个相关的变量,比如同一个数组中的不同元素,则可对 p1 和 p2 进行大小比较。
下面的程序修改了上面的实例,只要变量指针所指向的地址小于或等于数组的最后一个元素的地址 &var[MAX - 1],则把变量指针进行递增:
#include <stdio.h>
const int MAX = 3;
int main ()
{
int var[] = {10, 100, 200};
int i, *ptr;
/* 指针中第一个元素的地址 */
ptr = var;
i = 0;
while ( ptr <= &var[MAX - 1] )
{
printf("存储地址:var[%d] = %p\n", i, ptr );
printf("存储值:var[%d] = %d\n", i, *ptr );
/* 指向上一个位置 */
ptr++;
i++;
}
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
存储地址:var[0] = 0x7ffeee2368cc
存储值:var[0] = 10
存储地址:var[1] = 0x7ffeee2368d0
存储值:var[1] = 100
存储地址:var[2] = 0x7ffeee2368d4
存储值:var[2] = 200第七章——结构类型(枚举、结构、联合)
枚举的定义
1、枚举是一种用户定义的数据类型,它用关键字enum以如下语法来声明:
enum 枚举类型名字{名字0,……,名字n};
2、枚举类型名字通常并不真的使用,要用的是在大括号里的名字,因为他们就是常量符号,他们的类型是int,值则一次从0到n。如:
enum colors{red,yellow,green};
3、就创建了三个常量,red的值是0,yellow是1,而green是2。
4、当需要一些可以排列起来的常量值时,定义枚举的意义就是给了这些常量值名字。
枚举的用法
1、枚举量可以作为值
2、枚举类型可以跟上enum作为类型
3、但是实际上是以整数来做内部计算和外部输入输出的
例:
#include<stdio.h>
enum color{red,yellow,green};
void f(enum color c);
int main(void){
enum color t=red;
scanf("%d",&t);
f(t);
return 0;
}
void f(enum color c){
printf("%d\n",c);
}枚举的特点
1、枚举可以自动计数
#include<stdio.h>
enum color {red,yellow,green,numColors};
int main(int argc,char const *argv[]){
int color=-1;
char *colornames[numColors]={"red","yellow","green",}; //直接将numColors作为定义数组的参数
char *colorname=NULL;
printf("输入你喜欢的颜色的代码:");
scanf("%d",&color);
if(color>=0 && color <numColors){
colorname = colornames[color];
}else{
colorname = "unknown";
}
printf("你喜欢的颜色是%s\n",colorname);
return 0;
}2、声明枚举量的时候可以指定值
enum color{red=1,yellow,green=5};
例:
#include<stdio.h>
enum color{red=1, yellow, green=5, NumColors};
int main(){
printf("code for green is %d\n",green);
return 0;
} 3、枚举只能是int值,即使给枚举类型的变量赋不存在的整数值也没有任何warning或error
4、虽然枚举类型可以当做类型使用,但是实际上很(不)少(好)用
5、如果有意义上排比的名字,用枚举比const int方便
6、枚举比宏(macro)好,因为枚举有int类型
声明结构类型
#include<stdio.h>
int main(){
struct date{
int month;
int day;
int year;
}; //分号勿忘
struct date today;
today.month=07;
today.day=31;
today.year=2020;
printf("Today's date is %i-%i-%i.\n",today.year,today.month,today.day);
return 0;
}结构声明位置
1、和本地变量一样,在函数内部声明的结构类型智能在函数内部使用
2、所以通常在函数外部声明结构类型,这样就可以被多个函数所使用了
声明结构的形式
//1
struct point{
int x;
int y;
};
struct point p1,p2;
//2
struct{
int x;
int y;
}p1,p2;
//3
struct point{
int x;
int y;
}p1,p2;对于第一和第三种形式,都声明了结构point。但是第二种形式没有声明point,只是定义了两个变量
结构成员
结构和数组有点像数组用[]运算符和下标访问其成员(a[0]=10;),结构用 . 运算符和名字访问其成员(today.day 、student.firstName)
结构运算
1、要访问整个结构,直接用结构变量的名字
2、对于整个结构,可以做赋值、取地址,也可以传递给函数参数
例: p1=(struct point){5,10}; //相当于p1.x=5,p1.y=10;
p1=p2; //相当于p1.x=p2.x; p1.y=p2.y;
数组无法做这两种运算!
结构指针
和数组不同,结构变量的名字并不是结构变量的地址,必须使用&运算符。例: struct date *pDate=&today;
结构与函数
int numberOfDays(struct date d);
1、整个结构可以作为参数的值传入函数
2、这时候是在函数内新建一个结构变量,并复制调用者的结构的值
3、也可以返回一个结构
4、这与数组完全不同
输入结构
#include<stdio.h>
struct point{
int x;
int y;
};
void getStruct(struct point);
void output(struct point);
int main(){
struct point y={0,0};
getStruct(y);
output(y);
}
void getStruct(struct point p){
scanf("%d",&p.x);
scanf("%d",&p.y);
printf("%d,%d\n",p.x,p.y);
}
void output(struct point p){
printf("%d,%d",p.x,p.y);
}指向结构的指针
struct date{
int month;
int day;
int year;
}myday;
struct date *p=&myday;
(*p).month=12;
p->month=12;用->表示指针所指的结构变量中的成员
结构指针参数
#include<stdio.h>
struct point{
int x;
int y;
};
struct point* inputPoint(struct point *p){
scanf("%d",&(p->x));
scanf("%d",&(p->y));
return p;
}
void output(struct point p){
printf("%d,%d",p.x,p.y);
}
void main(){
struct point y={0,0};
inputPoint(&y);
output(y);
}1、好处是传入传出只是一个指针的大小
2、如果需要保护传入的结构不被函数修改,可使用:const struct point *p
3、返回传入的指针是一种套路
结构数组
struct date dates[100];
struct date dates[]={
{4,5,2021},{2,4,2020}};结构中的结构
struct dateAndTime{
struct date sdate;
struct time stime;
};
struct point{
int x;
int y;};
struct rectangle{
struct point pt1;
struct point pt2;
};
如果有变量 struct rectangle r;
就可以有: r.pt1.x、r.pt1.y,r.pt2.x和r.pt2.y
如果有变量定义: struct rectangle r,*rp;
那么下面的四种形式是等价的: r.pt1.x、rp->pt1.x、(r.pt1).x、(rp->pt1).x
但是没有rp->pt1->x(因为pt1不是指针)
















 231
231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









