







 本文介绍了一种在处理Excel文件时遇到的重复数据问题及解决方案。通过分析发现,部分数值在不同格式的Excel文件中出现了微小差异,导致pandas库无法正确识别并去除重复项。最终通过转换文件格式为.xlsx解决了该问题。
本文介绍了一种在处理Excel文件时遇到的重复数据问题及解决方案。通过分析发现,部分数值在不同格式的Excel文件中出现了微小差异,导致pandas库无法正确识别并去除重复项。最终通过转换文件格式为.xlsx解决了该问题。
最近在处理一个 1.4 1.4 1.4 万行数据的 E x c e l Excel Excel 文件时,发现总是有 70 70 70 行重复数据,总结下发现的过程和解决办法
e n v env env: → \rightarrow → p a n d a s : pandas: pandas: 1.2.2
解决方法
df.to_excel('output.xlsx')
df = pd.read_excel('output.xlsx')
df.drop_duplicates(subset=column_lis, inplace=True)
df.to_excel('output.xlsx')
发现异常的过程
- 根据客户的需求,我需要使用某几个 c o l u m n column column 去除重复值
- 客户拿到我去重后的 E x c e l Excel Excel,反映还是有重复值
- 我去
D
e
b
u
g
Debug
Debug,确认
P
y
t
h
o
n
Python
Python 确实执行了去重代码,也就是
final_output.drop_duplicates(columns_for_removing_duplicate_value, inplace=True) - 既然客户在
E
x
c
e
l
Excel
Excel 中发现了重复值,那我也先把数据导出到
E
x
c
e
l
Excel
Excel -->
final_output.to_excel(output_file_path, index=False) - 重新读取一次
df = pd.read_excel(output_file_path),记录下这时候len(df) == 14397,然后再次执行去重代码df.drop_duplicates(columns_for_removing_duplicate_value, inplace=True),发现len(df)变成14327了,去重成功
寻找问题根源
既然 P y t h o n Python Python 确实执行了去重代码,那么我觉得可能有两个地方会导致这种现象:①drop_duplicates方法并不完善 ②在对 E x c e l Excel Excel 的读取和写入时,某些数据发生了变化,和我们的预期有差异
但由于第二次去重成功了,所以我暂时不管可能性①,先研究可能性②
通过在to_excel时保留
i
n
d
e
x
index
index,我定位到了其中的两个重复的行,仔细研究后发现,在用于去重的
c
o
l
u
m
n
column
column 中(columns_for_removing_duplicate_value),有一列(将它命名为
c
o
l
_
1
col\_1
col_1 吧)的全是数值型,其余列都是str类型
于是我拿出这一列数值继续查看 --> lis = [(i, type(i)) for i in final_output['col_1'].tolist()]
并通过索引重新定位到重复的那两行,终于发现为什么去重会失效(这里可以排除数值类型引起问题的可能,因为它们类型均为float)

原来是因为在 E x c e l Excel Excel 中应为 − 1239.45 -1239.45 −1239.45 的数字被读成了 − 1239.4499999999998 -1239.4499999999998 −1239.4499999999998,导致这两行被 p a n d a s pandas pandas 视为非重复行
然后我继续追根溯源,找到
−
1239.4499999999998
-1239.4499999999998
−1239.4499999999998 所在的源文件,发现在
E
x
c
e
l
Excel
Excel 中改数值显示为
−
1239.45
-1239.45
−1239.45 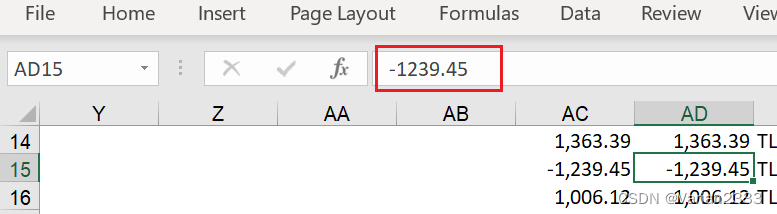

通过上面两张截图,就能判定 --> 问题和pd.read_excel有关,但是为什么to_excel后重新加载又能解决这个问题呢
通过对比源文件以及to_excel生成的
E
x
c
e
l
Excel
Excel 文件,我发现根源问题也与
E
x
c
e
l
Excel
Excel 的类型有关,因为源文件的类型为Microsoft Excel 97-2003 Worksheet (.xls),而我to_excel输出的文件类型为.xlsx
也就是说,对于其中一个重复值,它经历了以下过程才被正确加载,所以才能成功去除所有重复值(相当于利用xlsx给所有被错误加载的数值来一次标准化)

所以针对这种由
E
x
c
e
l
Excel
Excel 类型导致的drop_duplicates失效,可以使用文章开头展示的代码解决

















 770
770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









