







第1关:基本SELECT查询
任务描述
本关任务:
用 SELECT 语句检索数据表中指定字段的数据;
用 SELECT 语句检索数据表中所有字段的数据。
相关知识
为了完成本关任务,你需要掌握:1.如何获取数据表中指定字段的数据,2.如何获取数据表中的所有数据。
若想使用 SELECT 语句来检索数据表中的数据,你至少得弄清楚两个重要的信息:(1) 你想检索的是什么?(2) 你想检索的内容它在什么地方?
检索数据表中一个字段的内容
我们将从最简单的 SELECT 语句开始学习。
语法规则为:
SELECT 字段名 FROM 表名
编程要求
我们已经为你建好了数据库与数据表,并添加了相应的数据内容。
你只需根据右侧提示,完成以下任务:
补全右侧代码片段中 retrieving multiple column 下 Begin-End 区间的代码,检索表 Products 中字段 prod_name 和 prod_price 的所有内容;
补全右侧代码片段中 retrieving all column 下 Begin-End 区间的代码,检索表 Products 中所有字段的内容。
其中表 Products 的结构如下图所示;
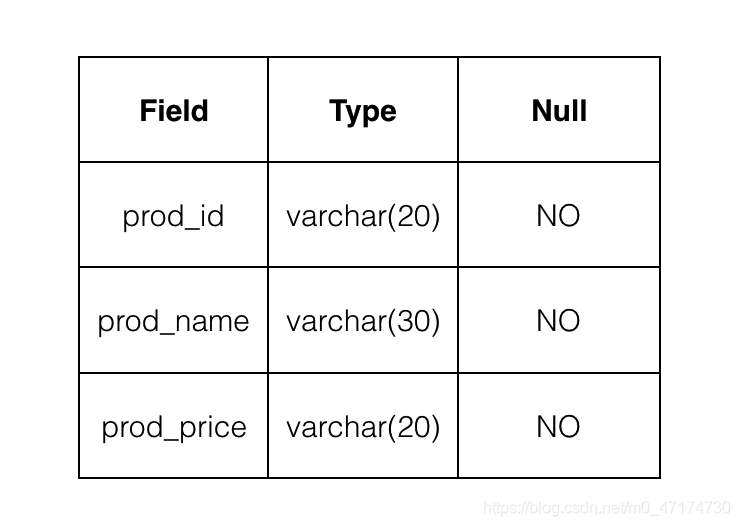
测试说明
测试过程:
本关涉及到的测试文件是 step1_test.sh ,平台将运行用户补全的 step1.sql 文件,得到数据;
将得到的数据与答案比较,判断代码是否正确。
如果操作正确,你将得到如下的结果:

参考代码:
USE Mall
GO
SET NOCOUNT ON
---------- retrieving multiple column ----------
-- ********** Begin ********** --
select prod_name,prod_price from Products
-- ********** End ********** --
GO
---------- retrieving all column ----------
-- ********** Begin ********** --
SELECT * FROM Products
-- ********** End ********** --
GO
第2关:带限制条件的查询和表达式查询
任务描述
本关任务:
查询数据表中的指定字段的数据;
查询数据表中指定字段运算后的数据。
相关知识
为了完成本关任务,你需要掌握:1.使用限制关键字查询数据表中的指定字段的内容,2.使用运算符查询数据表中指定字段运算后的内容。
带限制条件的查询
SELECT 语句可以帮你返回所有匹配的内容,甚至整张表的内容。但是如果你仅仅是想要第一行的数据或者前几行的数据怎么办呢?好消息是我们可以通过限制条件来查询,不过限制条件的语法在各个数据库中的语法是不同的。在 SQL Server 中:
语法规则为:
SELECT TOP 行数 字段名 FROM 表名
编程要求
我们已经为你建好了数据库与数据表,并添加了相应的数据内容。
你只需:
补全右侧代码片段中 retrieving with limited 下 Begin-End 区间的代码,检索表 Products 中字段 prod_name 的前两项内容;
补全右侧代码片段中 retrieving with expression 下 Begin-End 区间的代码,检索表 Products 中字段 prod_price 的内容,并检索到字段 prod_price 打8折后的价钱,命名该打折后的价格为 discount_price 。
其中表 Products 的结构如下图所示:
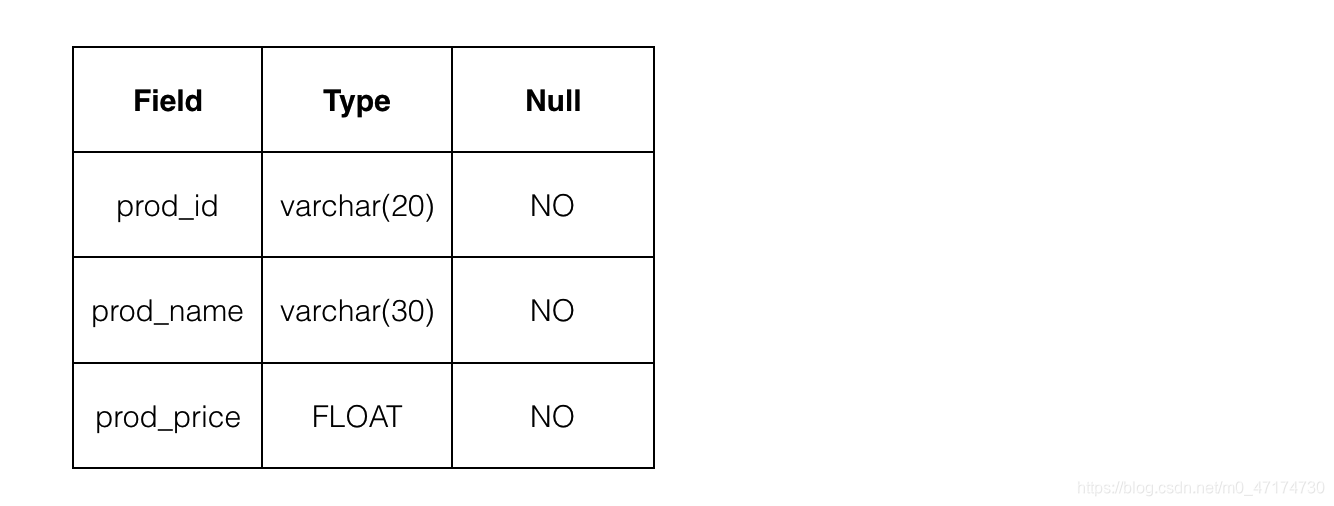
测试说明
测试过程:
本关涉及到的测试文件是 step2_test.sh ,平台将运行用户补全的 step2.sql 文件,得到数据;
将得到的数据与答案比较,判断代码是否正确。
如果操作正确,你将得到如下的结果:
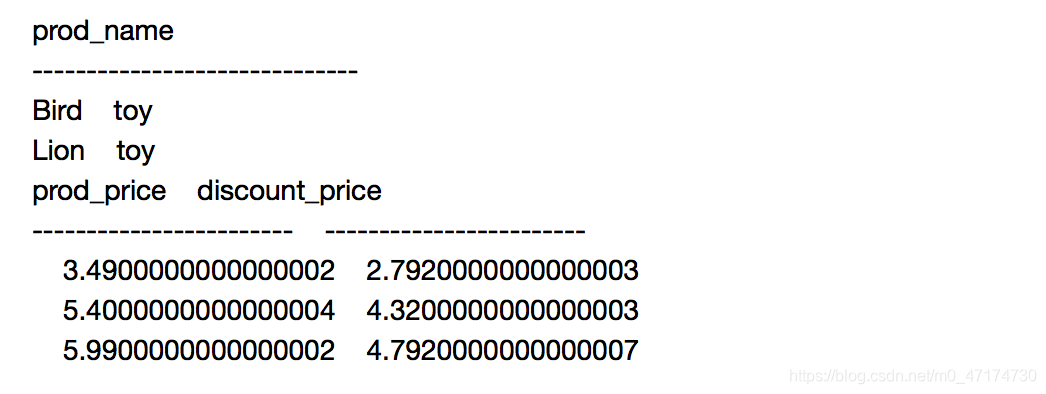
参考代码:
USE Mall
Go
SET NOCOUNT ON
---------- retrieving with limited ----------
-- ********** Begin ********** --
select top 2 prod_name from Products
-- ********** End ********** --
GO
---------- retrieving with expression ----------
-- ********** Begin ********** --
select prod_price,prod_price*0.8 discount_price from Products
-- ********** End ********** --
GO
第3关:使用WHERE语句进行检索
任务描述
本关任务:使用 WHERE 语句和逻辑表达式,检索数据表中指定字段的符合条件的数据。
相关知识
为了完成本关任务,你需要掌握:如何使用 WHERE 语句和操作符来选择符合条件的数据。
在实际情况中,我们不仅需要对某字段的全部数据进行检索,更多的是需要对符合我们需求的数据进行检索。SQL 语言的发明者当然想到了这些,为我们提供了更多的方法来检索你想要的数据。
WHERE 语句就是这样一种存在,只要把你的需求正确地放在 WHERE 后边,它就能帮你检索到你想要的内容。
编程要求
我们已经为你建好了数据库与数据表,并添加了相应的数据内容。
你只需:
补全右侧代码片段中 retrieving with range 下 Begin-End 区间的代码,检索表 Products 中字段 prod_price 价钱介于 3 和 5 的内容,要求显示出商品名称和价钱;
补全右侧代码片段中 retrieving with nomatches 下 Begin-End 区间的代码,检索表 Products 中除了 Lion toy 的商品名称和价钱。
其中表 Products 的内容如下图所示:

测试说明
测试过程:
本关涉及到的测试文件是 step3_test.sh ,平台将运行用户补全的 step3.sql 文件,得到数据;
将得到的数据与答案比较,判断代码是否正确。
如果操作正确,你将得到如下的结果:

参考代码:
USE Mall
Go
SET NOCOUNT ON
---------- retrieving with range ----------
-- ********** Begin ********** --
select prod_name,prod_price
from Products
where prod_price between 3 and 5
-- ********** End ********** --
GO
---------- retrieving with nomatches ----------
-- ********** Begin ********** --
select prod_name,prod_price
from Products
where prod_name!='Lion toy'
-- ********** End ********** --
GO














 5778
5778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









