






一、工作负载(workloads)
workloads官方文档
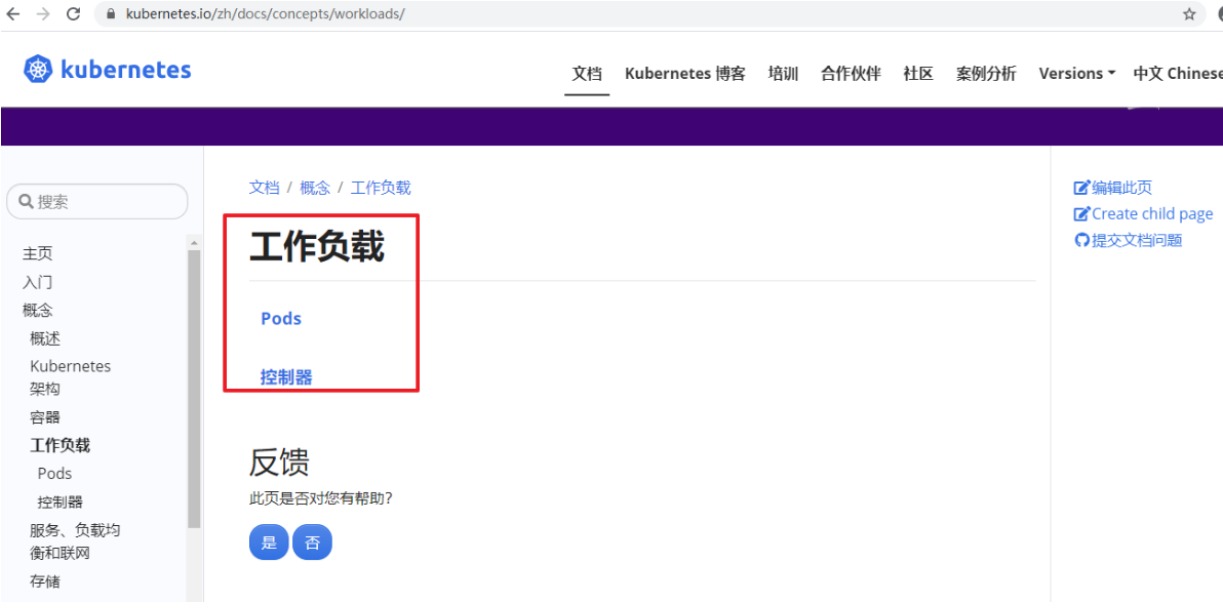
workloads分为pod与controllers
- pod通过控制器实现应用的运行,如何伸缩,升级等
- controllers 在集群中管理pod
- pod与控制器之间通过label-selector相关联,是唯一的关联方式
比如在pod的YAML里指定
labels:
app: nginx
在控制器的YAML里指定
selector:
matchLabels:
app: nginx
二、pod介绍
pod定义与分类
- Pod(豆荚) 是Kubernetes集群管理与调度的最小单元
- 一个Pod可以封装一个容器或多个容器(主容器或sidecar边车容器)
- 一个pod内的多个容器之间共享部分命名空间,例如:Net Namespace,UTS Namespace,IPC Namespace及存储资源、
- 用户pod默认会被调度运行在node节点之上(不运行在master节点上,但也有例外情况)
- pod内的IP不是固定的,集群外不能直接访问pod
pod可分为:
- 无控制器管理的自主式pod 没有副本控制器控制,删除自主式pod后不会重新创建
- 控制器管理的pod 控制器可以控制pod的副本数,扩容与裁剪,版本更新与回滚等
查看pod方法
pod是一种资源,可以通过kubectl get pod来查看
[root@master1 ~]# kubectl get pod # pod或pods都可以,不指定namespace,默认是名为default的namespace
[root@master1 ~]# kubectl get pod -n kube-system
pod的YAML资源清单格式
先看一个yaml格式的pod定义文件解释
# yaml格式的pod定义文件完整内容:
apiVersion: v1 #必选,api版本号,例如v1
kind: Pod #必选,Pod
metadata: #必选,元数据
name: string #必选,Pod名称
namespace: string #Pod所属的命名空间,默认在default的namespace
labels: # 自定义标签
name: string #自定义标签名字
annotations: #自定义注释列表
name: string
spec: #必选,Pod中容器的详细定义(期望)
containers: #必选,Pod中容器列表
- name: string #必选,容器名称
image: string #必选,容器的镜像名称
imagePullPolicy: [Always | Never | IfNotPresent] #获取镜像的策略 Alawys表示下载镜像 IfnotPresent表示优先使用本地镜像,否则下载镜像,Nerver表示仅使用本地镜像
command: [string] #容器的启动命令列表,如不指定,使用打包时使用的启动命令
args: [string] #容器的启动命令参数列表
workingDir: string #容器的工作目录
volumeMounts: #挂载到容器内部的存储卷配置
- name: string #引用pod定义的共享存储卷的名称,需用volumes[]部分定义的的卷名
mountPath: string #存储卷在容器内mount的绝对路径,应少于512字符
readOnly: boolean #是否为只读模式
ports: #需要暴露的端口库号列表
- name: string #端口号名称
containerPort: int #容器需要监听的端口号
hostPort: int #容器所在主机需要监听的端口号,默认与Container相同
protocol: string #端口协议,支持TCP和UDP,默认TCP
env: #容器运行前需设置的环境变量列表
- name: string #环境变量名称
value: string #环境变量的值
resources: #资源限制和请求的设置
limits: #资源限制的设置
cpu: string #Cpu的限制,单位为core数,将用于docker run --cpu-shares参数
memory: string #内存限制,单位可以为Mib/Gib,将用于docker run --memory参数
requests: #资源请求的设置
cpu: string #Cpu请求,容器启动的初始可用数量
memory: string #内存清求,容器启动的初始可用数量
livenessProbe: #对Pod内个容器健康检查的设置,当探测无响应几次后将自动重启该容器,检查方法有exec、httpGet和tcpSocket,对一个容器只需设置其中一种方法即可
exec: #对Pod容器内检查方式设置为exec方式
command: [string] #exec方式需要制定的命令或脚本
httpGet: #对Pod内个容器健康检查方法设置为HttpGet,需要制定Path、port
path: string
port: number
host: string
scheme: string
HttpHeaders:
- name: string
value: string
tcpSocket: #对Pod内个容器健康检查方式设置为tcpSocket方式
port: number
initialDelaySeconds: 0 #容器启动完成后首次探测的时间,单位为秒
timeoutSeconds: 0 #对容器健康检查探测等待响应的超时时间,单位秒,默认1秒
periodSeconds: 0 #对容器监控检查的定期探测时间设置,单位秒,默认10秒一次
successThreshold: 0
failureThreshold: 0
securityContext:
privileged:false
restartPolicy: [Always | Never | OnFailure] # Pod的重启策略,Always表示一旦不管以何种方式终止运行,kubelet都将重启,OnFailure表示只有Pod以非0退出码退出才重启,Nerver表示不再重启该Pod
nodeSelector: obeject # 设置NodeSelector表示将该Pod调度到包含这个label的node上,以key:value的格式指定
imagePullSecrets: #Pull镜像时使用的secret名称,以key:secretkey格式指定
- name: string
hostNetwork:false #是否使用主机网络模式,默认为false,如果设置为true,表示使用宿主机网络
volumes: #在该pod上定义共享存储卷列表
- name: string #共享存储卷名称 (volumes类型有很多种)
emptyDir: {} #类型为emtyDir的存储卷,与Pod同生命周期的一个临时目录。为空值
hostPath: string #类型为hostPath的存储卷,表示挂载Pod所在宿主机的目录
path: string #Pod所在宿主机的目录,将被用于同期中mount的目录
secret: #类型为secret的存储卷,挂载集群与定义的secret对象到容器内部
scretname: string
items:
- key: string
path: string
configMap: #类型为configMap的存储卷,挂载预定义的configMap对象到容器内部
name: string
items:
- key: string
path: string
YAML格式查找帮助方法回顾
[root@master1 ~]# kubectl explain namespace
[root@master1 ~]# kubectl explain pod
[root@master1 ~]# kubectl explain pod.spec
[root@master1 ~]# kubectl explain pod.spec.containers
三、pod创建与验证
命令创建pod(v1.18变化)
- k8s之前版本中, kubectl run命令用于创建deployment控制器
- 在v1.18版本中, kubectl run命令改为创建pod
1, 创建一个名为pod-nginx的pod
[root@master1 ~]# kubectl run nginx1 --image=nginx:1.15-alpine
pod/nginx1 created
2, 验证
[root@master1 ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx1 1/1 Running 0 41s
YAML创建pod
1, 准备yaml文件
[root@master1 ~]# vim pod1.yml
apiVersion: v1 # api版本
kind: Pod # 资源类型为Pod
metadata:
name: pod-stress # 自定义pod的名称
spec:
containers: # 定义pod里包含的容器
- name: c1 # 自定义pod中的容器名
image: polinux/stress # 启动容器的镜像名
command: ["stress"] # 自定义启动容器时要执行的命令(类似dockerfile里的CMD)
args: ["--vm", "1", "--vm-bytes", "150M", "--vm-hang", "1"] # 自定义启动容器执行命令的参数
# polinux/stress这个镜像用于压力测试,在启动容器时传命令与参数就是相当于分配容器运行时需要的压力
2, 通过yaml文件创建pod
[root@master1 ~]# kubectl apply -f pod1.yml
pod/pod-stress created
查看pod信息
查看pod信息
[root@master1 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pod-stress 1/1 Running 0 45s
查看pod详细信息
[root@master ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-stress 1/1 Running 0 71s 10.3.166.146 192.168.122.13 <none> <none>
描述pod详细信息
[root@master1 ~]# kubectl describe pod pod-stress
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled <unknown> default-scheduler Successfully assigned default/pod-stress to 192.168.122.13
Normal Pulling 2m12s kubelet, 192.168.122.13 Pulling image "polinux/stress"
Normal Pulled 2m9s kubelet, 192.168.122.13 Successfully pulled image "polinux/stress"
Normal Created 2m8s kubelet, 192.168.122.13 Created container c1
Normal Started 2m7s kubelet, 192.168.122.13 Started container c1
删除pod
单个pod删除
方法1:
[root@master1 ~]# kubectl delete pod pod-stress
pod "pod-stress" deleted
方法2:
[root@master1 ~]# kubectl delete -f pod1.yml
多个pod删除
方法1: 后接多个pod名
[root@master1 ~]# kubectl delete pod pod名1 pod名2 pod名3 ......
方法2: 通过awk截取要删除的pod名称,然后管道给xargs
[root@master1 ~]# kubectl get pods |awk 'NR>1 {print $1}' |xargs kubectl delete pod
方法2: 如果要删除的pod都在同一个非default的命名空间,则可直接删除命名空间
[root@master1 ~]# kubectl delete ns xxxx
镜像拉取策略
由imagePullPolicy参数控制
- Always : 不管本地有没有镜像,都要从仓库中下载镜像
- Never : 从来不从仓库下载镜像, 只用本地镜像,本地没有就算了
- IfNotPresent: 如果本地存在就直接使用, 不存在才从仓库下载
默认的策略是:
- 当镜像标签版本是latest,默认策略就是Always
- 如果指定特定版本默认拉取策略就是IfNotPresent。
1, 将上面的pod删除再创建,使用下面命令查看信息
[root@master1 ~]# kubectl apply -f pod1.yml
[root@master1 ~]# kubectl delete -f pod1.yml
[root@master1 ~]# kubectl describe pod pod-stress
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled <unknown> default-scheduler Successfully assigned default/pod-stress1 to 192.168.122.14
Normal Pulling 27s kubelet, 192.168.122.14 Pulling image "polinux/stress"
Normal Pulled 12s kubelet, 192.168.122.14 Successfully pulled image "polinux/stress"
Normal Created 10s kubelet, 192.168.122.14 Created container c1
Normal Started 10s kubelet, 192.168.122.14 Started container c1
说明: 可以看到第二行信息还是pulling image下载镜像
2, 修改YAML
[root@master1 ~]# vim pod1.yml
apiVersion: v1
kind: Pod
metadata:
name: pod-stress
namespace: default
spec:
containers:
- name: c1
image: polinux/stress
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "150M", "--vm-hang", "1"]
imagePullPolicy: IfNotPresent # 增加了这一句
3,再次删除再创建
[root@master1 ~]# kubectl describe pod pod-stress
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled <unknown> default-scheduler Successfully assigned default/pod-stress1 to 192.168.122.14
Normal Pulled 3s kubelet, 192.168.122.14 Container image "polinux/stress" already present on machine
Normal Created 2s kubelet, 192.168.122.14 Created container c1
Normal Started 1s kubelet, 192.168.122.14 Started container c1
说明: 第二行信息是说镜像已经存在,直接使用了
pod的标签
- 为pod设置label,用于控制器通过label与pod关联
- 语法与前面学的node标签几乎一致
通过命令管理标签
- 查看pod的标签
[root@master ~]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
pod-stress 1/1 Running 0 7m25s <none>
- 打标签,再查看
[root@master1 ~]# kubectl label pod pod-stress region=huanai zone=A env=test bussiness=game
pod/pod-stress labeled
[root@master1 ~]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
pod-stress 1/1 Running 0 8m54s bussiness=game,env=test,region=huanai,zone=A
- 通过等值关系标签查询
[root@master1 ~]# kubectl get pods -l zone=A
NAME READY STATUS RESTARTS AGE
pod-stress 1/1 Running 0 9m22s
- 通过集合关系标签查询
[root@master1 ~]# kubectl get pods -l "zone in (A,B,C)"
NAME READY STATUS RESTARTS AGE
pod-stress 1/1 Running 0 9m55s
- 删除标签后再验证
[root@master1 ~]# kubectl label pod pod-stress region- zone- env- bussiness-
pod/pod-stress labeled
[root@master ~]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
pod-stress 1/1 Running 0 16m <none>
小结:
- pod的label与node的label操作方式几乎相同
- node的label用于pod调度到指定label的node节点
- pod的label用于controller关联控制的pod
通过YAML创建标签
1, 修改yaml
[root@master1 ~]# vim pod1.yml
apiVersion: v1
kind: Pod
metadata:
name: pod-stress
namespace: default
labels:
env: dev
app: nginx # 直接在原来的yaml里加上多个标签
spec:
containers:
- name: c1
image: polinux/stress
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "150M", "--vm-hang", "1"]
imagePullPolicy: IfNotPresent
2, 直接apply应用
[root@master1 ~]# kubectl apply -f pod1.yaml
pod/pod-stress1 configured # 这里是configured,表示修改了
3, 验证
[root@master1 ~]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
pod-stress 1/1 Running 0 3m5s app=nginx,env=dev # 标签有了
pod资源限制
准备2个不同限制方式的创建pod的yaml文件
[root@master1 ~]# vim pod2.yml
apiVersion: v1
kind: Namespace
metadata:
name: namespace1
---
apiVersion: v1
kind: Pod
metadata:
name: pod-stress2
namespace: namespace1
spec:
containers:
- name: c1
image: polinux/stress
imagePullPolicy: IfNotPresent
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
command: ["stress"] # 启动容器时执行的命令
args: ["--vm", "1", "--vm-bytes", "150M", "--vm-hang", "1"] # 产生1个进程分配150M内存1秒后释放
[root@master1 ~]# vim pod3.yml
apiVersion: v1
kind: Namespace
metadata:
name: namespace1
---
apiVersion: v1
kind: Pod
metadata:
name: pod-stress3
namespace: namespace1
spec:
containers:
- name: c1
image: polinux/stress
imagePullPolicy: IfNotPresent
resources:
limits:
memory: "200Mi"
requests:
memory: "150Mi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "250M", "--vm-hang", "1"]
[root@master1 ~]# kubectl apply -f pod2.yml
namespace/namespace1 created
pod/pod-stress2 created
[root@master1 ~]# kubectl apply -f pod3.yml
namespace/namespace1 unchanged
pod/pod-stress3 created
[root@master1 ~]# kubectl get namespace |grep namespace1
namespace1 Active 1m28s
[root@master1 ~]# kubectl get pod -n namespace1
NAME READY STATUS RESTARTS AGE
pod-stress2 1/1 Running 0 2m2s
pod-stress3 0/1 OOMKilled 4 115s
查看会发现pod-stress3这个pod状态变为OOMKilled,因为它是内存不足所以显示Container被杀死
说明: 一旦pod中的容器挂了,容器会有重启策略, 如下:
-
Always:表示容器挂了总是重启,这是默认策略
-
OnFailures:表容器状态为错误时才重启,也就是容器正常终止时才重启
-
Never:表示容器挂了不予重启
-
对于Always这种策略,容器只要挂了,就会立即重启,这样是很耗费资源的。所以Always重启策略是这么做的:第一次容器挂了立即重启,如果再挂了就要延时10s重启,第三次挂了就等20s重启… 依次类推
测试完后删除
[root@master1 ~]# kubectl delete ns namespace1
pod包含多个容器
1, 准备yml文件
[root@master1 ~]# vim pod4.yml
apiVersion: v1
kind: Pod
metadata:
name: pod-stress4
spec:
containers:
- name: c1
image: polinux/stress
imagePullPolicy: IfNotPresent
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "150M", "--vm-hang", "1"]
- name: c2
image: polinux/stress
imagePullPolicy: IfNotPresent
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "150M", "--vm-hang", "1"]
2, 应用yml文件创建pod
[root@master1 ~]# kubectl apply -f pod4.yml
pod/pod-stress4 created
3, 查看pod在哪个节点
[root@master1 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-stress4 2/2 Running 0 115m 10.3.166.149 192.168.122.13 <none> <none>
可以看到有2个容器,运行在192.168.122.13(node1)节点
4,在node2上验证,确实产生了2个容器
[root@node1 ~]# docker ps -a |grep stress
d7827a963f9d df58d15b053d "stress --vm 1 --vm-…" 2 hours ago Up 2 hours k8s_c2_pod-stress4_default_a534bce1-3ffe-45f5-8128-34657e289b44_0
ae8e8f8d095b df58d15b053d "stress --vm 1 --vm-…" 2 hours ago Up 2 hours k8s_c1_pod-stress4_default_a534bce1-3ffe-45f5-8128-34657e289b44_0
e66461900426 easzlab/pause-amd64:3.2 "/pause" 2 hours ago Up 2 hours k8s_POD_pod-stress4_default_a534bce1-3ffe-45f5-8128-34657e289b44_0
对pod里的容器进行操作
命令帮助
[root@master1 ~]# kubectl exec -h
不用交互直接执行命令
格式为: kubectl exec pod名 -c 容器名 -- 命令
注意:
- -c 容器名为可选项,如果是1个pod中1个容器,则不用指定;
- 如果是1个pod中多个容器,不指定默认为第1个。
[root@master1 ~]# kubectl exec pod-stress4 -c c2 -- touch /111
[root@master1 ~]# kubectl exec pod-stress4 -c c2 -- ls /111
/111
不指定容器名,则默认为pod里的第1个容器
[root@master1 ~]# kubectl exec pod-stress4 -- touch /222
Defaulting container name to c1.
Use 'kubectl describe pod/pod-stress4 -n default' to see all of the containers in this pod.
和容器交互操作
和docker exec几乎一样
[root@master1 ~]# kubectl exec -it pod-stress4 -c c1 -- /bin/bash
bash-5.0# touch /333
bash-5.0# ls
222 bin etc lib mnt proc run srv tmp var
333 dev home media opt root sbin sys usr
bash-5.0# exit
exit
验证pod中多个容器网络共享
1, 编写YAML
[root@master1 ~]# vim pod-nginx.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx2
spec:
containers:
- name: c1
image: nginx:1.15-alpine
- name: c2
image: nginx:1.15-alpine
2, 应用YAML
[root@master1 ~]# kubectl apply -f pod-nginx.yaml
pod/nginx2 created
3, 查看pod信息与状态
[root@master1 ~]# kubectl describe pod nginx2
......
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled <unknown> default-scheduler Successfully assigned default/nginx2 to 192.168.122.13
Normal Pulling 108s kubelet, 192.168.122.13 Pulling image "nginx:1.15-alpine"
Normal Pulled 75s kubelet, 192.168.122.13 Successfully pulled image "nginx:1.15-alpine"
Normal Created 74s kubelet, 192.168.122.13 Created container c1
Normal Started 72s kubelet, 192.168.122.13 Started container c1
Normal Pulled 12s (x4 over 72s) kubelet, 192.168.122.13 Container image "nginx:1.15-alpine" already present on machine
Normal Created 11s (x4 over 71s) kubelet, 192.168.122.13 Created container c2
Normal Started 10s (x4 over 69s) kubelet, 192.168.122.13 Started container c2
Warning BackOff 6s (x4 over 60s) kubelet, 192.168.122.13 Back-off restarting failed container
[root@master1 ~]# kubectl get pods |grep nginx2
nginx2 1/2 CrashLoopBackOff 3 2m40s
有一个启不来,因为一个容器中两个pod是共用网络的,所以不能两个都占用80端口
有一个启不来,因为一个容器中两个pod是共用网络的,所以不能两个都占用80端口
通过查找192.168.122.13(node1)上面的容器,然后docker logs查看,得到如下的报错,说明是端口被占用
[root@node1 ~]# docker logs k8s_c2_nginx2_default_51fd8e81-1c4b-4557-9498-9b25ed8a4c99_4
2020/11/21 04:29:12 [emerg] 1#1: bind() to 0.0.0.0:80 failed (98: Address in use)
nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address in use)
2020/11/21 04:29:12 [emerg] 1#1: bind() to 0.0.0.0:80 failed (98: Address in use)
nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address in use)
2020/11/21 04:29:12 [emerg] 1#1: bind() to 0.0.0.0:80 failed (98: Address in use)
nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address in use)
2020/11/21 04:29:12 [emerg] 1#1: bind() to 0.0.0.0:80 failed (98: Address in use)
nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address in use)
2020/11/21 04:29:12 [emerg] 1#1: bind() to 0.0.0.0:80 failed (98: Address in use)
nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address in use)
2020/11/21 04:29:12 [emerg] 1#1: still could not bind()
nginx: [emerg] still could not bind()
四、pod调度
kubernetes会通过算法将pod调度到node节点上运行
pod调度流程
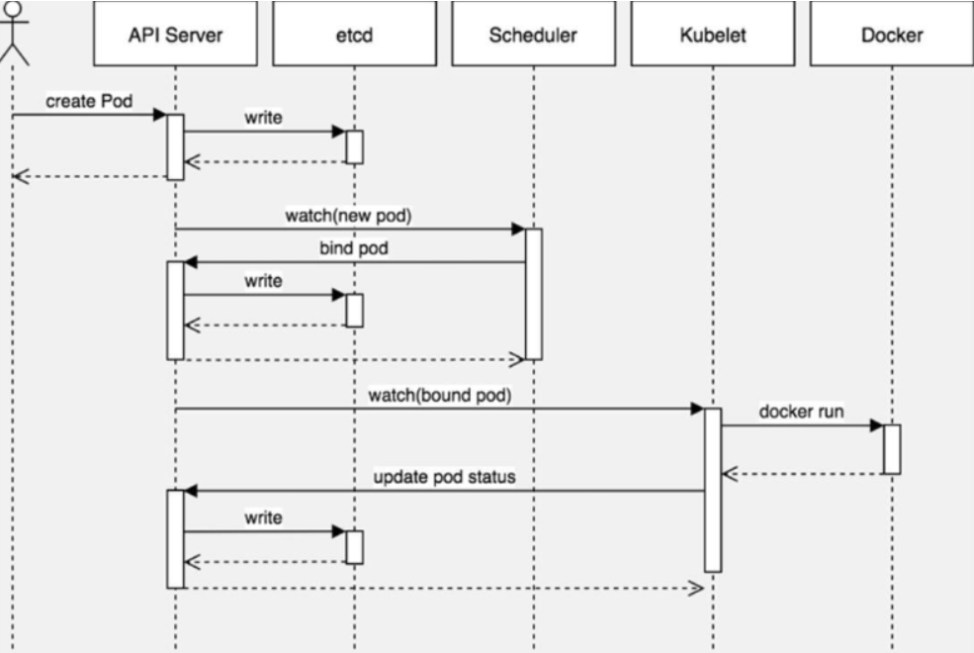
调度约束方法
我们为了实现容器主机资源平衡使用, 可以使用约束把pod调度到指定的node节点
- nodeName 用于将pod调度到指定的node名称上
- nodeSelector 用于将pod调度到匹配Label的node上
案例1: nodeName
1, 编写YAML文件
[root@master1 ~]# vim pod-nodename.yml
apiVersion: v1
kind: Pod
metadata:
name: pod-nodename
spec:
nodeName: 192.168.122.13 # 通过nodeName调度到192.168.122.13(node1)节点
containers:
- name: nginx
image: nginx:1.15-alpine
2, 应用YAML文件创建pod
[root@master1 ~]# kubectl apply -f pod-nodename.yml
pod/pod-nodename created
3, 验证
[root@master1 ~]# kubectl describe pod pod-nodename |tail -6
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Pulled 14s kubelet, 192.168.122.13 Container image "nginx:1.15-alpine" already present on machine
Normal Created 13s kubelet, 192.168.122.13 Created container nginx
Normal Started 13s kubelet, 192.168.122.13 Started container nginx
倒数第3行没有使用scheduler,而是直接给node1了,说明nodeName约束生效
案例2: nodeSelector
1, 为192.168.122.14(node2)打标签
[root@master1 ~]# kubectl label nodes 192.168.122.14 bussiness=game
node/192.168.122.14 labeled
2, 编写YAML文件
[root@master ~]# vim pod-nodeselector.yml
apiVersion: v1
kind: Pod
metadata:
name: pod-nodeselect
spec:
nodeSelector: # nodeSelector节点选择器
bussiness: game # 指定调度到标签为bussiness=game的节点
containers:
- name: nginx
image: nginx:1.15-alpine
3, 应用YAML文件创建pod
[root@master ~]# kubectl apply -f pod-nodeselector.yml
pod/pod-nodeselect created
4, 验证
[root@master1 ~]# kubectl describe pod pod-nodeselect |tail -6
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled <unknown> default-scheduler Successfully assigned default/pod-nodeselect to 192.168.122.14
Normal Pulled 10s kubelet, 192.168.122.14 Container image "nginx:1.15-alpine" already present on machine
Normal Created 10s kubelet, 192.168.122.14 Created container nginx
Normal Started 9s kubelet, 192.168.122.14 Started container nginx
仍然经过了scheduler,但确实分配到了node2上
有兴趣可以再删除后再创建,重复几次验证
五、pod的生命周期
参考: https://kubernetes.io/zh/docs/concepts/workloads/pods/pod-lifecycle/
- 有些pod(比如跑httpd服务),正常情况下会一直运行中,但如果手动删除它,此pod会终止
- 也有些pod(比如执行计算任务),任务计算完后就会自动终止
上面两种场景中,pod从创建到终止的过程就是pod的生命周期。
容器启动
-
pod中的容器在创建前,有初始化容器(init container)来进行初始化环境
-
初化完后,主容器(main container)开始启动
-
主容器启动后,有一个post start的操作(启动后的触发型操作,或者叫启动后钩子)
-
post start后,就开始做健康检查
-
第一个健康检查叫存活状态检查(liveness probe ),用来检查主容器存活状态的
-
第二个健康检查叫准备就绪检查(readiness probe),用来检查主容器是否启动就绪
-
容器终止
- 可以在容器终止前设置pre stop操作(终止前的触发型操作,或者叫终止前钩子)
- 当出现特殊情况不能正常销毁pod时,大概等待30秒会强制终止
- 终止容器后还可能会重启容器(视容器重启策略而定)。
回顾容器重启策略
-
Always:表示容器挂了总是重启,这是默认策略
-
OnFailures:表容器状态为错误时才重启,也就是容器正常终止时不重启
-
Never:表示容器挂了不予重启
-
对于Always这种策略,容器只要挂了,就会立即重启,这样是很耗费资源的。所以Always重启策略是这么做的:第一次容器挂了立即重启,如果再挂了就要延时10s重启,第三次挂了就等20s重启… 依次类推
HealthCheck健康检查
当Pod启动时,容器可能会因为某种错误(服务未启动或端口不正确)而无法访问等。
Health Check方式
kubelet拥有两个检测器,它们分别对应不同的触发器(根据触发器的结构执行进一步的动作)
| 方式 | 说明 |
|---|---|
| Liveness Probe(存活状态探测) | 检查后不健康,重启pod(参照容器重启策略) |
| readiness Probe(就绪型探测) | 检查后不健康,将容器设置为Notready;如果使用service来访问,流量不会转发给此种状态的pod |
Probe探测方式
| 方式 | 说明 |
|---|---|
| Exec | 执行命令 |
| HTTPGet | http请求某一个URL路径 |
| TCP | tcp连接某一个端口 |
案例1: liveness-exec
参考: https://kubernetes.io/zh/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/
1, 准备YAML文件
[root@master ~]# vim pod-liveness-exec.yml
apiVersion: v1
kind: Pod
metadata:
name: liveness-exec
namespace: default
spec:
containers:
- name: liveness
image: busybox
imagePullPolicy: IfNotPresent
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5 # pod启动延迟5秒后探测
periodSeconds: 5 # 每5秒探测1次
2, 应用YAML文件
[root@master1 ~]# kubectl apply -f pod-liveness-exec.yml
3, 通过下面的命令观察
[root@master1 ~]# kubectl describe pod liveness-exec
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 40s default-scheduler Successfully assigned default/liveness-exec to node1
Normal Pulled 38s kubelet, 192.168.122.13 Container image "busybox" already present on machine
Normal Created 37s kubelet, 192.168.122.13 Created container liveness
Normal Started 37s kubelet, 192.168.122.13 Started container liveness
Warning Unhealthy 3s kubelet, 192.168.122.13 Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory
看到40s前被调度以node1节点,3s前健康检查出问题
4, 过几分钟再观察
[root@master1 ~]# kubectl describe pod liveness-exec
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 3m42s default-scheduler Successfully assigned default/liveness-exec to node1
Normal Pulled 70s (x3 over 3m40s) kubelet, node1 Container image "busybox" already present on machine
Normal Created 70s (x3 over 3m39s) kubelet, node1 Created container liveness
Normal Started 69s (x3 over 3m39s) kubelet, node1 Started container liveness
Warning Unhealthy 26s (x9 over 3m5s) kubelet, node1 Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory
Normal Killing 26s (x3 over 2m55s) kubelet, node1 Container liveness failed liveness probe, will be restarted
[root@master1 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
liveness-exec 1/1 Running 3 4m12s
看到重启3次,慢慢地重启间隔时间会越来越长
拓展: 容器重启策略验证
apiVersion: v1
kind: Pod
metadata:
name: liveness-exec
namespace: default
spec:
restartPolicy: Never # 把容器重启策略由默认的always改为Never
containers:
- name: liveness
image: busybox
imagePullPolicy: IfNotPresent
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
请自行验证
验证结果为:
- 容器健康检查出现问题后,不再重启,也不会继续sleep 600秒,而是直接关闭了
案例2: liveness-httpget
1, 编写YMAL文件
[root@master1 ~]# vim pod-liveness-httpget.yml
apiVersion: v1
kind: Pod
metadata:
name: liveness-httpget
namespace: default
spec:
containers:
- name: liveness
image: nginx:1.15-alpine
imagePullPolicy: IfNotPresent
ports: # 指定容器端口,这一段不写也行,端口由镜像决定
- name: http # 自定义名称,不需要与下面的port: http对应
containerPort: 80 # 类似dockerfile里的expose 80
livenessProbe:
httpGet: # 使用httpGet方式
port: http # http协议,也可以直接写80端口
path: /index.html # 探测家目录下的index.html
initialDelaySeconds: 3 # 延迟3秒开始探测
periodSeconds: 5 # 每隔5s钟探测一次
2, 应用YAML文件
[root@master1 ~]# kubectl apply -f pod-liveness-httpget.yml
3, 验证查看
[root@master1 ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
liveness-httpget 1/1 Running 0 9s
4, 交互删除nginx里的主页文件
[root@master1 ~]# kubectl exec -it liveness-httpget -- rm -rf /usr/share/nginx/html/index.html
5, 验证查看会发现
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fQ5bT9II-1643868580771)(http://note.youdao.com/yws/res/12218/WEBRESOURCE08dec2fa3015c7c438b3ea36ead6541c)]
[root@master1 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
liveness-httpget 1/1 Running 1 11m
只restart一次
案例3: liveness-tcp
1, 编写YAML文件
[root@master1 ~]# vim pod-liveness-tcp.yml
apiVersion: v1
kind: Pod
metadata:
name: liveness-tcp
namespace: default
spec:
containers:
- name: liveness
image: nginx:1.15-alpine
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
livenessProbe:
tcpSocket: # 使用tcp连接方式
port: 80 # 连接80端口进行探测
initialDelaySeconds: 3
periodSeconds: 5
2, 应用YAML文件创建pod
[root@master1 ~]# kubectl apply -f pod-liveness-tcp.yml
pod/liveness-tcp created
3, 查看验证
[root@master1 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
liveness-tcp 1/1 Running 0 14s
4, 交互关闭nginx
[root@master1 ~]# kubectl exec -it liveness-tcp -- /usr/sbin/nginx -s stop
5, 再次验证查看
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Q0Dl2fLC-1643868580772)(http://note.youdao.com/yws/res/12220/WEBRESOURCEc057c1d858cb2759ee8dbf3239eeac62)]
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
liveness-tcp 1/1 Running 1 5m13s
也只重启1次,重启后重新初始化了
案例4: readiness
1, 编写YAML文件
[root@master1 ~]# vim pod-readiness-httpget.yml
apiVersion: v1
kind: Pod
metadata:
name: readiness-httpget
namespace: default
spec:
containers:
- name: readiness
image: nginx:1.15-alpine
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
readinessProbe: # 这里由liveness换成了readiness
httpGet:
port: http
path: /index.html
initialDelaySeconds: 3
periodSeconds: 5
2, 应用YAML文件
[root@master1 ~]# kubectl apply -f pod-readiness-httpget.yml
pod/readiness-httpget created
3, 验证查看
[root@master1 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
readiness-httpget 1/1 Running 0 10s
4, 交互删除nginx主页
[root@master1 ~]# kubectl exec -it readiness-httpget -- rm -rf /usr/share/nginx/html/index.html
5, 再次验证

[root@master1 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
readiness-httpget 0/1 Running 0 2m49s
READY状态为0/1
6, 交互创建nginx主页文件再验证
[root@master1 ~]# kubectl exec -it readiness-httpget -- touch /usr/share/nginx/html/index.html
[root@master1 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
readiness-httpget 1/1 Running 0 3m10s
READY状态又为1/1了
案例5: readiness+liveness综合
1, 编写YAML文件
[root@master1 ~]# vim pod-readiness-liveiness.yml
apiVersion: v1
kind: Pod
metadata:
name: readiness-liveness-httpget
namespace: default
spec:
containers:
- name: readiness-liveness
image: nginx:1.15-alpine
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
livenessProbe:
httpGet:
port: http
path: /index.html
initialDelaySeconds: 1
periodSeconds: 3
readinessProbe:
httpGet:
port: http
path: /index.html
initialDelaySeconds: 5
periodSeconds: 5
2, 应用YAML文件
[root@master1 ~]# kubectl apply -f pod-readiness-liveiness.yml
pod/readiness-liveness-httpget created
3, 验证
[root@master1 ~]# kubectl get pod |grep readiness-liveness-httpget
NAME READY STATUS RESTARTS AGE
readiness-liveness-httpget 0/1 Running 0 6s
post-start
1, 编写YAML文件
[root@master1 ~]# vim pod-poststart.yml
apiVersion: v1
kind: Pod
metadata:
name: poststart
namespace: default
spec:
containers:
- name: poststart
image: nginx:1.15-alpine
imagePullPolicy: IfNotPresent
lifecycle: # 生命周期事件
postStart:
exec:
command: ["mkdir","-p","/usr/share/nginx/html/haha"]
2, 应用YMAL文件
[root@master1 ~]# kubectl apply -f pod-poststart.yml
3, 验证
[root@master1 ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
poststart 1/1 Running 0 25s
[root@master1 ~]# kubectl exec -it poststart -- ls /usr/share/nginx/html -l
total 8
-rw-r--r-- 1 root root 494 Apr 16 13:08 50x.html
drwxr-xr-x 2 root root 6 Aug 5 05:33 haha 有创建此目录
-rw-r--r-- 1 root root 612 Apr 16 13:08 index.html
pre-stop
容器终止前执行的命令
1, 编写YAML文件
[root@master1 ~]# vim prestop.yml
apiVersion: v1
kind: Pod
metadata:
name: prestop
namespace: default
spec:
containers:
- name: prestop
image: nginx:1.15-alpine
imagePullPolicy: IfNotPresent
lifecycle: # 生命周期事件
preStop: # preStop
exec:
command: ["/bin/sh","-c","sleep 60000000"] # 容器终止前sleep 60000000秒
2, 应用YAML文件创建pod
[root@master1 ~]# kubectl apply -f prestop.yml
pod/prestop created
3, 删除pod验证
[root@master1 ~]# kubectl delete -f prestop.yml
pod "prestop" deleted 会在这一步等待一定的时间(大概30s-60s左右)才能删除,说明验证成功
结论: 当出现特殊情况不能正常销毁pod时,大概等待30秒会强制终止
pod故障排除
| 状态 | 描述 |
|---|---|
| Pending | pod创建已经提交到Kubernetes。但是,因为某种原因而不能顺利创建。例如下载镜像慢,调度不成功。 |
| Running | pod已经绑定到一个节点,并且已经创建了所有容器。至少有一个容器正在运行中,或正在启动或重新启动。 |
| completed | Pod中的所有容器都已成功终止,不会重新启动。 |
| Failed | Pod的所有容器均已终止,且至少有一个容器已在故障中终止。也就是说,容器要么以非零状态退出,要么被系统终止。 |
| Unknown | 由于某种原因apiserver无法获得Pod的状态,通常是由于Master与Pod所在主机kubelet通信时出错。 |
| CrashLoopBackOff | 多见于CMD语句错误或者找不到container入口语句导致了快速退出,可以用kubectl logs 查看日志进行排错 |
- kubectl describe pod pod名
- kubectl logs pod [-c CONTAINER]
- kubectl exec POD [-c CONTAINER] --COMMAND [args…]
下一篇:Controller















 2028
2028











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









