






 这是一份全面的Java技术面试题集,涵盖了Java基础、容器、多线程、反射、对象拷贝、Java Web、异常处理、网络、设计模式、Spring/Spring MVC、Spring Boot/Spring Cloud、ORM框架(Hibernate、Mybatis)、消息队列(RabbitMQ、Kafka)、分布式协调(Zookeeper)、数据库(MySQL)、缓存(Redis)、JVM、数据结构与算法等多个模块。面试题包括JDK与JRE的区别、多线程同步机制、数据库的ACID特性、Spring框架的工作原理、JVM调优、设计模式的运用、网络协议解析、数据结构在实际问题中的应用等内容,旨在考察和提升开发者在Java全栈开发中的综合能力。
这是一份全面的Java技术面试题集,涵盖了Java基础、容器、多线程、反射、对象拷贝、Java Web、异常处理、网络、设计模式、Spring/Spring MVC、Spring Boot/Spring Cloud、ORM框架(Hibernate、Mybatis)、消息队列(RabbitMQ、Kafka)、分布式协调(Zookeeper)、数据库(MySQL)、缓存(Redis)、JVM、数据结构与算法等多个模块。面试题包括JDK与JRE的区别、多线程同步机制、数据库的ACID特性、Spring框架的工作原理、JVM调优、设计模式的运用、网络协议解析、数据结构在实际问题中的应用等内容,旨在考察和提升开发者在Java全栈开发中的综合能力。
面试题模块汇总
面试题包括以下十九个模块:Java 基础、容器、多线程、反射、对象拷贝、Java Web 模块、异常、网络、设计模式、Spring/Spring MVC、Spring Boot/Spring Cloud、Hibernate、Mybatis、RabbitMQ、Kafka、Zookeeper、MySql、Redis、JVM,数据结构与算法 。如下图所示:
*

JAVA面试题
- Java 基础(1001)
- 1.JDK 和 JRE 有什么区别?
- 2.== 和 equals 的区别是什么?(esqb ==dc)
- 3.两个对象的 hashCode()相同,则 equals()也一定为 true,对吗?
- 4.为什么要重写hashCode()和equals()(cxhe)
- 5.final 在 java 中有什么作用?(fldc)
- 6.java 中的 Math.round(-1.5) 等于多少?
- 7.String 属于基础的数据类型吗?
- 8.java 中操作字符串都有哪些类?它们之间有什么区别?(sss)
- String为什么要设计成不可变的?(sgbkb)
- 在使用 HashMap 的时候,用 String 做 key 有什么好处?(sgzk hpsg)
- 9.两个字符串相加的底层是如何实现的?(字符串相加zfcxj)
- 8.String str="i"与 String str=new String(“i”)一样吗?(字符串创建zfccj)
- 10.String 类的常用方法都有那些?(sgff)
- 12.普通类和抽象类有哪些区别?
- 14.接口和抽象类有什么区别?(jcqb)
- 15.java 中 IO 流分为几种?(iol)
- 字节流如何转为字符流?
- 16.BIO、NIO、AIO 有什么区别?(biodc)
- IO 和 NIO 有什么区别(inqb)
- 17.File的常用方法都有哪些?(feff)
- 18、List、Map、Set 三个接口,存取元素时,各有什么特点?(lsmdc)
- 19、List 和 Map 区别
- 20、HashMap 和 Hashtable 的区别(hhqb)
- 21.HashMap为什么线程不安全(hahsmap线程不安全)(hpxc)
- 32.如何得到一个线程安全的Map(hashmap线程安全 hpxcaq)
- 22.TreeMap底层怎么实现的?(tpdc)
- 23.LinkedHashMap底层实现原理(lpdc)
- 24.介绍一下ConcurrentHashMap是怎么实现的?(cpdc)
- 25.HashMap与LinkedHashMap的区别(hlqb)
- 26.HashMap与ConcurrentHashMap有什么区别?(hcqb)
- 28. Integer i=100; Integer j=100;true还是false
- 30.char能不能存储汉字?
- 34. 线程方法常用的是什么?(xcff)
- 35.Servlet中forward()和redirct()的区别?
- 36.Servlet的生命周期 (stsmzq)
- 37.存储过程和函数的区别?(chqb hcqb)
- 38.Java8新特性(xtx)
- 39.说一说你对Java访问权限的了解(lfwqx)
- 40.介绍一下Java的数据类型(jasjlx)
- 41.请介绍全局变量(成员)和局部变量的区别(cjqb)
- 42.说一说自动装箱、自动拆箱的应用场景(czxjz)
- 44.int和Integer有什么区别(iiqb)
- 45.面向对象的三大特征是什么(面向对象特征)(mxdxtz)
- 29.重写和重载的区别?(ccqb)
- 46.Java为什么是单继承,为什么不能多继承(java单继承)(jadjc)
- 48.构造方法能不能重写
- 49.介绍一下Object类中的方法(otdc)
- 50.说一说你对static关键字的理解(scdc)
- 51.static和final有什么区别?(sfqb)
- 52.说一说你对泛型的理解(fxdc)
- 53.List<? super T>和List<? extends T>有什么区别?(通配符tpfdc)
- Lambda表达式和匿名内部类的区别(lnqb)
- Java 对象的生命周期(jadxsmzq)
- 容器(101)
- Collection 和 Collections 有什么区别?(ccqb)
- List、Set、Map 之间的区别是什么?(lsmqb)
- 27、常见的list,set接口的特点及实现类(lsmdc)
- 如何决定使用 HashMap 还是 TreeMap?
- 说一下 HashMap的实现原理?(hpdc)
- 介绍一下HashMap扩容机制(hpkr)
- 31.描述一下HashMapput的过程(hpput)
- 为什么HashMap线程不安全(hpxcbaq)
- HashMap中的循环链表是如何产生的?(hpxhlb)
- 说一下 HashSet 的实现原理?(htdc)
- ArrayList 和 LinkedList 的区别是什么?(alqb)
- 如何实现数组和 List 之间的转换?
- ArrayList 和 Vector 的区别是什么?(avqb)
- Array 和 ArrayList 有何区别?(aaqb)
- 在队列中 poll()和 remove()有什么区别?(prqb)
- 哪些集合类是线程安全的?(jhlxcaq)
- 迭代器 Iterator 是什么?(irdc)
- Iterator 怎么使用?有什么特点?(irjs)
- Iterator 和 ListIterator 有什么区别?(ilqb)
- SimpleDataFormat 是非线程安全的,如何更好的使用而避免风险呢(stxcaq)
- 多线程(102)
- 并行和并发有什么区别?(bbqb)
- 线程和进程的区别?(jxqb)
- 进程与线程的切换流程?(jxqh)
- 进程的用户态和内核态(ynqb)(xclx)
- PCB包括哪些内容(pcbdc)
- 进程间通信方式以及各自的优缺点(jctx)
- 线程间通信与同步(xctx)
- 线程的调度方式(xcdd)
- 守护线程是什么?(shxc)
- 创建线程有哪几种方式?(xccj)
- 有三个线程T1,T2,T3,如何保证顺序执行?(xcsxzx)
- 说一下 runnable 和 callable 有什么区别?(rcqb)
- 什么是Callable和Future?(cfqb)
- 线程有哪些状态?(xczt)
- sleep() 和 wait() 有什么区别?(swqb)
- notify()和 notifyAll()有什么区别?(nnqb)
- sleep()和wait() 有什么区别?(slqb)
- 线程的 run()和 start()有什么区别?(srqb)
- Java线程的生命周期和状态(xcsmzq)
- 线程池工作原理(xccdc)
- 线程池的拒绝策略有哪些?(xccjjcl)
- 线程池核心线程数怎么设置呢?(xcchxxcs)
- 线程池参数?(xcccs)
- 创建线程池有哪几种方式?(xcccj)
- 线程池都有哪些状态?(xcczt)
- 什么是阻塞队列?阻塞队列的实现原理是什么?如何使用阻
- 塞队列来实现生产者-消费者模型?(zsdl)
- execute方法与submit方法(esqb)
- 线程池如何知道一个线程的任务已经执行完成(xcczxwc)
- 多线程的好处,多线程应用场景:(dxcsycj)
- 在 java 程序中怎么保证多线程的运行安全?(dxcaq)
- 什么是多线程中的上下文切换?(dxcsxwqh)
- 什么是Daemon线程?它有什么意义?(shxc htxc dnxc)
- 多线程锁的升级原理是什么?(dxcs)
- 多线程同步和互斥有几种实现方法,都是什么?(dxctbhc)
- 线程同步的方式有哪些?(xctbfs)
- fail-safe 机制与 fail-fast 机制分别有什么作用(ffqb)
- 什么是死锁?(ssdc)
- 怎么防止死锁?(fzss)
- ThreadLocal 是什么?有哪些使用场景?(tldc)
- synchronized 和 volatile 的区别是什么?(svqb)
- synchronized 和 Lock 有什么区别?(slqb)
- synchronized 和 ReentrantLock 区别是什么?(srqb)
- SynchronizedMap 和 ConcurrentHashMap 有什么区别?(scqb)
- 读写锁ReadWriteLock 是什么?(rkdc)
- 说一下 atomic 的原理?(acdc)
- 说一下volatile关键字(vedc)
- 说一下 synchronized 底层实现原理?(sddc)
- 说说自己是怎么使用 synchronized 关键字?(sdsy)
- synchronized的优化(sdyh)
- wait 和 notify 这个为什么要在synchronized 代码块中?(wnqb)
- 什么是AQS
- 能谈一下 CAS 机制吗(casdc)
- CAS有什么缺点吗?(casqd)
- 反射(103)
- 对象拷贝(104)
- Java Web(105)
- jsp 和 servlet 有什么区别?
- jsp 有哪些内置对象?作用分别是什么?
- 说一下 jsp 的 4 种作用域?(jspzyy)
- session 和 cookie 有什么区别?(scqb)
- session与token区别(stqb)
- 会话cookie和持久cookie有什么区别?(ccqb)
- 说一下 session 的工作原理,session如何共享 ?(sndc)
- 什么是Token(tndc)
- 说一下 cookie 的工作原理?(cedc)
- Cookie的传输流程(cecslc)
- 如果客户端禁止 cookie 能实现 session 还能用吗?
- spring mvc 和 struts 的区别是什么?(ssqb)
- 如何避免 sql注入?
- 什么是 XSS攻击,如何避免?
- 什么是 CSRF攻击,如何避免?
- 异常(106)
- 网络(107)
- http 响应码 301 和 302 代表的是什么?有什么区别?
- forward 和 redirect 的区别?(frqb)
- 简述 tcp 和 udp的区别?(tuqb)
- 浏览器输入一个url到整个页面显示出来经历了哪些过程?(urldc)
- tcp 为什么要三次握手,两次不行吗?为什么?(scws)
- TCP三次握手、四次挥手(scws)
- TIME_WAIT和CLOSE_WAIT的区别(tcqb)
- 说一下 tcp粘包是怎么产生的?
- IP协议的首部结构 (ipsb)
- OSI 的七层模型都有哪些?(qcmx)
- TCP/IP 四层模型(scmx)
- get 和 post 请求有哪些区别?(gpqb)
- IP数据报文结构解析(ipbw)
- 什么是对称加密与非对称加密(jmdc)
- 如何实现跨域?(kydc)
- 说一下 JSONP 实现原理?
- http和https的区别(hhqb)
- ARP协议工作原理?ARP攻击?如何解决(arpdc)
- DNS的解析过程(dnsjx)
- 如何用HTTP实现长连接?(hpclj)
- 中间人攻击知道吗?怎么做https的抓包?https怎么篡改?(zjrgj)
- 设计模式(sjms)(108)
- Spring/Spring MVC(109)
- 为什么要使用 spring?
- 解释一下什么是 aop?(aopdc)(jdqb)
- 在Spring AOP 中,关注点和横切关注的区别是什么?(aopgzd)
- Spring AOP和AspectJ AOP有什么区别?(aaqb)
- 解释一下什么是 ioc?(iocdc)
- 说一说你对Spring容器的了解(sgrq baqb abqb)
- Spring 中 BeanFactory 和FactoryBean 的区别(bfqb fbqb)
- Spring Boot怎么更换bean组件(stthbn stghbn)
- 请描述Spring Boot自动装配的过程(stzdzp)
- spring 中的 bean 是线程安全的吗?(snxcaq)
- spring 支持几种 bean 的作用域?(snzyy)
- spring 自动装配bean有哪些方式?(Spring创建bean的方式)(zdzpbn)(sgzrbn)
- Spring MVC的controller是线程安全的吗?怎么去保证线程安全呢?(mvcxcaq)
- spring 事务实现方式有哪些,事务特性?(sgswdc)
- 事务三要素是什么?(swsys)
- 说一下 spring 的事务隔离级别,事务传播行为?(sgswgl sgswcb sjkswgljb)
- 说一下 spring mvc 运行流程?(scyxlc scdc dtdc)
- spring中都用了哪些设计模式(sgsjms)
- Spring 是如何解决循环依赖问题的?(sgxhyl sgsjhc)
- Spring 中哪些情况下,不能解决循环依赖问题?(sgxhyl)
- Spring三级缓存的作用是什么?(sgsjhczy)
- 代理设计中的正向代理和反向代理?(zfqb)
- springbean的生命周期(snsmzq)
- Spring是如何管理Bean的?(sgglbn)
- 如何自己去定义注解(zdyzj)
- @Autowired和@Resource注解有什么区别?(arqb)
- Spring如何管理事务(sgglsw)
- Spring的事务如何配置,常用注解有哪些?(sgswpz)
- 说一说你知道的Spring MVC注解 (zjdc)
- 依赖注入的方式有几种,各是什么?(ylzr zrdc)
- Spring应用上下文的生命周期(sgsxw)
- Spring Boot/Spring Cloud(110)
- 什么是 spring boot?
- Spring Boot Starter有什么用(stsr)
- spring boot 配置文件有哪几种类型?它们有什么区别?
- spring boot 有哪些方式可以实现热部署?
- SpringBoot启动过程(stqdgc)
- jpa 和 hibernate 有什么区别?
- 什么是 spring cloud?什么是微服务?
- 服务治理的基础角色
- spring cloud 断路器的作用是什么?Hystrix
- 什么是自我保护机制?
- spring cloud 的核心组件有哪些?
- Eureka和ZooKeeper都可以提供服务注册与发现的功能,请说说两个的区别(ezqb)
- Ribbon和Feign的区别?
- Ribbon负载均衡策略有哪些?@LoadBalanced(rndc)
- REST 和RPC对比(rrqb)
- Spring Cloud 和dubbo区别(scqb)
- 服务注册和发现是什么意思?Spring Cloud 如何实现?
- 什么是 Hystrix?它如何实现容错?
- Zuul有几种过滤器类型?分别是?
- 什么是Sleuth
- 熔断器如何设计?(rdqsj)
- Spring Boot 常用注解汇总(stzj)
- Dubbo
- Hibernate(111)
- Mybatis(112)
- mybatis 中 #{}和 ${}的区别是什么?
- MyBatis 使用了哪些设计模式 (mssjms)
- mybatis 有几种分页方式?(msfy)
- mybatis 逻辑分页和物理分页的区别是什么?
- mybatis 是否支持延迟加载?延迟加载的原理是什么?(msycjz)
- 说一下 mybatis 的一级缓存和二级缓存?(mshcjz)
- mybatis 和 hibernate 的区别有哪些?(mhqb)
- mybatis 有哪些执行器(Executor)?(mszxq)
- mybatis 如何编写一个自定义插件?(mszdycj)
- 页面报400错误是什么意思?
- 请求数据出现乱码该怎么处理?(lmdc)
- 了解Spring Boot JPA吗?
- RabbitMQ(113)
- 消息丢列的使用场景有哪些?(xxdlds)
- rabbitmq 有哪些重要的角色?
- rabbitmq 有哪些重要的组件?
- rabbitmq 中 vhost 的作用是什么?
- rabbitmq 的消息是怎么发送的?
- rabbitmq 怎么保证消息的稳定性?
- rabbitmq 怎么避免消息丢失?
- 要保证消息持久化成功的条件有哪些?
- rabbitmq 持久化有什么缺点?
- rabbitmq 有几种广播类型?
- rabbitmq 怎么实现延迟消息队列?
- .rabbitmq 集群有什么用?
- rabbitmq 节点类型有哪些?
- rabbitmq 集群搭建需要注意哪些问题?
- rabbitmq 每个节点是其他节点的完整拷贝吗?为什么?
- rabbitmq 集群中唯一一个磁盘节点崩溃了会发生什么情况?
- rabbitmq 对集群节点停止顺序有要求吗?
- Kafka(114)
- Kafka底层(kadc)
- Kafka使用场景?为什么用?为什么吞吐量高?(kasycj)
- Kafka 消息数据积压,消费能力不足怎么处理?(kaxxjy)
- Kafka 有哪些情形会造成重复消费?
- 那些情景会造成消息漏消费?
- Kafka中的ISR、AR又代表什么?☆☆☆☆☆
- Kafka中的HW、LEO等分别代表什么? ☆☆☆☆☆
- Kafka中的分区器、序列化器、拦截器是否了解?它们之间的处理顺序是什么?☆☆☆
- 当你使用kafka-topics.sh创建(删除)了一个topic之后,Kafka背后会执行什么逻辑? ☆☆☆
- topic的分区数可不可以增加?如果可以怎么增加?如果不可以,那又是为什么?☆☆☆☆☆
- Kafka有内部的topic吗?如果有是什么?有什么所用? ☆☆☆☆
- Kafka分区分配的概念? ☆☆☆☆☆
- Kafka中有那些地方需要选举?这些地方的选举策略又有哪些?☆☆☆☆☆
- Kafka怎么保证高吞吐量的?(kagttl)
- **kafka零拷贝原理**(kalkb)
- kafka 可以脱离 zookeeper 单独使用吗?为什么?
- kafka 有几种数据保留的策略?
- kafka 同时设置了 7 天和 10G 清除数据,到第五天的时候消息达到了 10G,这个时候 kafka 将如何处理?
- 什么情况会导致 kafka 运行变慢?
- 使用 kafka 集群需要注意什么?
- 消息队列如何保证顺序消费(xxdlsxxf)
- 消息队列避免消息丢失?(xxdlbmxxds)
- 消息队列如何保证避免重复消费(xxdlbmcfxf)
- 什么是幂等?如何解决幂等性问题?
- Zookeeper(115)
- zookeeper 是什么?
- zookeeper 都有哪些功能?(zkgn)
- 四种类型的znode
- Zookeeper通知机制
- zookeeper 有几种部署模式?
- zookeeper 怎么保证主从节点的状态同步?(zkzctb)
- 集群中为什么要有主节点?
- 集群中有 3 台服务器,其中一个节点宕机,这个时候 zookeeper 还可以使用吗?
- 说一下 zookeeper 的通知机制?(zktzjz)
- zookeeper是如何选取主leader的(zkxz)
- Zookeeper同步流程(zktb)
- zk节点宕机如何处理?(zkdj)
- zookeeper负载均衡和nginx负载均衡区别(znqb)
- zookeeper watch机制(zkwhjz)
- zookeeper是如何保证事务的顺序一致性的?(zkswyzx)
- Zookeeper工作原理(zkgzyl)
- Zookeeper数据复制(zksjfz)
- Zookeeper队列管理(文件系统、通知机制)(zkdlgl)
- zookeeper获取分布式锁的流程(zkhqfbss)
- Zookeeper分布式锁(zkfbss)
- zookeeper分布式锁有什么缺陷(zkfbssqx)
- 请说一下你对分布式锁的理解,以及分布式锁的实现(fbssdc)
- MySql(116)
- 数据库的三范式是什么?(sjksfs)
- 一张自增表里面总共有 7 条数据,删除了最后 2 条数据,重启 mysql 数据库,又插入了一条数据,此时 id 是几?
- 如何获取当前数据库版本?
- char 和 varchar 的区别是什么?(cvqb)
- float 和 double 的区别是什么?(fdqb)
- mysql 的内连接、左连接、右连接有什么区别?(nzyqb)
- mysql 数据库索引是怎么实现的?(数据库索引sjksy)
- 什么情况下不推荐使用索引?
- 哪些情况下需要创建使用索引:
- 怎么验证 mysql 的索引是否满足需求?
- 最左匹配的原理(zzqz)(zzpp)
- 为什么要使用联合索引(lhsy)
- 说一下数据库事务 ACID 是什么?(acid)
- 数据库事务有哪几种类型,它们之间有什么区别?(sjkswlx)
- MySQL事务如何回滚?(sjkswhg)
- 说一下 mysql 常用的引擎?(sjkyq)
- 说一下 mysql 的行锁和表锁?(hbqb)
- 说一下乐观锁和悲观锁?(lbqb)
- mysql 问题排查都有哪些手段?(sjkwtpc)
- 什么叫视图?游标是什么?
- MySQL 中有哪几种锁?(sjks)
- mysql数据库索引都有哪些?如何创建索引?索引的底层实现原理和优化(sjksydc)
- 索引在什么情况下会失效?(sysx)
- 数据库索引优化(sjksyyh)
- 索引的设计原则?(sysjyz)
- 索引的使用场景有哪些?(sysycj)
- 聚簇索引和非聚簇索引有什么区别?(jfqb)
- 谈谈你对SQL注入的理解(sqlzr)
- WHERE和HAVING有什么区别?(whqb)
- 说一说你对数据库优化的理解(sjkyh)
- 该如何优化MySQL的查询?(数据库查询优化sjkcxyh)
- mysql怎样插入数据才能更高效?(数据库插入优化sjkcryh)
- 表中包含几千万条数据该怎么办(大数据量优化dsjyh)
- MySQL的慢查询优化有了解吗?(慢查询优化mcxyh)
- MySQL主从同步是如何实现的(数据库主从同步 sjkzctb)
- mysql日志(sjkrz)
- SQL的执行过程?(sqlzxlc)
- 说一说你对redolog、undolog、binlog的了解(redolog)
- redolog刷盘时机和策略
- 什么是redolog的“两阶段提交” (ljdtj)
- 谈谈你对MVCC的了解(mvccdc)
- MySQL的Hash索引和B树索引有什么区别?索引数据结构(hbqb) (b+dc)
- MySQL采用B+树的优缺点,B树与B+树比较(bbqb)
- 索引的类型有哪些?(sylx)
- 索引的种类有哪些?(syzl)
- MySQL高可用方案整理(sjkgky)
- 秒杀实用方案(msfa)
- 聊聊分库分表,需要停服嘛(fkfb)
- 怎么设计一个短链地址(dldz)
- 布隆过滤器(blglq)
- 采用自增ID和UUID的区别?(iuqb)
- 谈一谈,id全局唯一且自增,如何实现?(idzz xhsfdc)
- 一条 SQL 执行过长的时间,你如何优化,从哪些方面?(sqlyh)
- 垂直权限漏洞与水平权限漏洞(czqxld spqxld)
- Redis(117)
- redis 是什么?都有哪些使用场景?(rssycj)
- Redis为什么快呢?(rsk)
- Redis 线程是否安全 ?(rsxcaq)
- Redis 中是否有事务机制?事务支持回滚吗?(rsswjz)
- Redis 与 mysql 如何保持数据一致性?(mrsjyzx)
- Redis 与 本地缓存 如何保持数据一致性?(rbsjyzx)
- Redis 宕机,数据会丢失吗? ☆☆☆☆☆
- Redis 中如何存放对象 ☆☆☆
- Redis 内存满了怎么办?☆☆☆☆
- Redis 如何实现高可用? 哨兵机制的作用?☆☆☆☆☆(rsgkyjz)
- Redis 集群有哪些方案?(三种方案)☆☆☆(rsjqdc)
- 订单超时自动取消如何实现? ☆☆☆☆☆
- Redis 主从复制如果网络延时怎么办?☆☆☆☆(rszcfz)
- Redis 主从同步效率非常慢怎么解决?☆☆☆☆
- Redis Cluster 集群 ☆☆☆☆**☆**
- 说说你对redis 哨兵机制的理解 ☆☆☆☆☆(rssbjz)
- 为什么 Redis 需要把所有数据放到内存中?☆☆☆☆☆(rsnc)
- redis 和 memecache 有什么区别?(rmqb)
- 说说 Redis 的线程模型(rsxcmx rsdxcmx)
- redis 为什么是单线程的?(rsdxc)
- 什么是缓存穿透,缓存击穿,缓存雪崩,缓存预热,缓存更新?怎么解决?(hcjc)
- redis 支持的数据类型有哪些?(rssjlx)
- 说说Redis底层数据结构?(rsdcsjjg)
- redis 支持的 java 客户端都有哪些?
- jedis 和 redisson 有哪些区别?(jrqb)
- 怎么保证缓存和数据库数据的一致性?(mrsjyzx)
- redis持久化有几种方式?(rscjh)
- Redis 如何实现分布式锁? ☆☆☆☆ (rsfbss)
- redis 分布式锁有什么缺陷?(rsfbssqx)
- redis 如何做内存优化?(rsncyh)
- redis 常见的性能问题有哪些?该如何解决?(rswt)
- redis集群
- Redis 做异步队列(延时队列)(rsybdl)
- Redis 做延时队列(rsysdl)
- Redis 回收进程如何工作(rshsjc)
- Redis和Lua脚本的使用了解吗?(rsluadc)
- Redis 如何做内存优化(rsncyh)
- Redis 事务(rssw)
- Redis的管道了解吗?(rsgd)
- Redis集群的主从复制模型是怎样的(rszcfz)
- redis主从复制过程如果出现数据不一致怎么办(rssjbyz)
- Redis哈希槽(rshxc)
- Redis集群的原理是什么(rsjqyl)
- Redis的主从数据同步机制(rszctb)
- redis 过期键的删除策略?(rssccl)
- redis 淘汰策略有哪些?(rsttcl)
- 怎么处理热key?(rsrdk)
- 大key问题了解吗?(rsdk)
- 无底洞问题吗?如何解决?
- 如果让你设计一个KV数据库,该如何设计(sjksj)
- JVM(118)
- 说一下 jvm 的主要组成部分? JVM 结构原理、GC 工作机制详解(jvmdc)
- 说一下类加载的执行过程?(ljz)
- 常见内存泄露的几种场景(oomdc)
- 说一下堆栈的区别?(dzqb)
- 什么是双亲委派模型?(sqwp)
- 怎么判断对象是否可以被回收?(dxhs)
- 说一说Java的四种引用方式(引用类型)?(yylx )
- 说一下 jvm 有哪些垃圾回收算法?(ljhssf)
- 说一下 jvm 有哪些垃圾回收器?(ljhsq)
- 详细介绍一下CMS垃圾回收器?
- 新生代垃圾回收器和老生代垃圾回收器都有哪些?有什么区别?
- 简述分代垃圾回收器是怎么工作的?(fdljhsq)(fdcl)
- 说一下 jvm 调优的工具?
- 常用的 jvm 调优的参数都有哪些?(jvmty)
- 内存分配方式(内存模型)(ncfpff)(ncmx)
- 创建对象的过程(cjdx)
- 描述一下 JVM 加载 class 文件的原理机制
- int a=10;int a=-10(1234567在内存如何存储,这个方法叫什么(123nccc))
- 数据结构与算法(119)
- Linux常见面试题(125)
- Linux 下系统调用过程以及方法(lxxtdy)
- Linux 常用命令学习
- 1、ls命令:通过 ls 命令不仅可以查看 linux 文件夹包含的文件,而且可以查看文件权限(包括目录、文件夹、文件权限)查看目录信息等等。(lls)
- 2.cat 命令(lcat)
- 3.more 命令:more 会以一页一页的显示方便使用者逐页阅读(lmore)
- 4.less 命令:使用 less 可以随意浏览文件(lless)
- 5.head 命令: 用来显示档案的开头至标准输出中,默认 head 命令打印其相应文件的开头 10 行。(lhead)
- 6.tail 命令:用于显示指定文件末尾内容,不指定文件时,作为输入信息进行处理。常用查看日志文件。(ltail)
- 7.which 命令:在 linux 要查找某个文件,但不知道放在哪里了(lwhich)
- 8.whereis 命令(lwhere)
- 9.locate 命令(llocate)
- 10.find 命令:用于在文件树中查找文件,并作出相应的处理。(lfind)
- 11.chmod 命令:用于改变 linux 系统文件或目录的访问权限(lchmod)
- 12.chown 命令:chown 将指定文件的拥有者改为指定的用户或组(lchown)
- 13.df 命令:显示磁盘空间使用情况。获取硬盘被占用了多少空间(ldf)
- 14.du 命令:du 命令也是查看使用空间的(ldu)
- 15.ln 命令:功能是为文件在另外一个位置建立一个同步的链接(lln)
- 16.date 命令:显示或设定系统的日期与时间(ldate)
- 17.cal 命令:可以用户显示公历(阳历)日历如只有一个参数(lcal)
- 18.grep 命令:强大的文本搜索命令(lgrep)
- 19.wc 命令:wc(word count)功能为统计指定的文件中字节数、字数、行数,并将统计结果输出(lwc)
- 20.ps 命令:用来查看当前运行的进程状态(lps)
- 21.top 命令:显示当前系统正在执行的进程的相关信息,包括进程 ID、内存占用率、CPU 占用率等(ltop)
- 22.kill 命令(lkill)
- 23.free 命令:显示系统内存使用情况,包括物理内存、交互区内存(swap)和内核缓冲区内存(lfree)
- 24.Linux上如何查看某个进程的线程 (lckjcxc)
- 怎么清屏?怎么退出当前命令?怎么执行睡眠?怎么查看当前用户 id?查看指定帮助用什么命令?
- linux中ctrl+c的底层原理是什么?(+cdc)
- 查看文件有哪些命令?
- 列举几个常用的Linux命令。
- 你平时是怎么查看日志的?(lckrz)
- 查看文件内容有哪些命令可以使用?
- 随意写文件命令?怎么向屏幕输出带空格的字符串,比如”hello world”?
- 终端是哪个文件夹下的哪个文件?黑洞文件是哪个文件夹下的哪个命令?
- Linux下命令有哪几种可使用的通配符?分别代表什么含义?
- Linux中进程有哪几种状态?在ps显示出来的信息中分别用什么符号表示的?(lxjczt)
- 怎么使一个命令在后台运行?
- 哪个命令专门用来查看后台任务?
- 把后台任务调到前台执行使用什么命令?把停下的后台任务在后台执行起来用什么命令?(lfg)
- 怎么查看系统支持的所有信号?
- 搜索文件用什么命令? 格式是怎么样的?
- 使用什么命令查看用过的命令列表?
- 使用什么命令查看网络是否连通?
- 查看各类环境变量用什么命令?
- 通过什么命令查找执行命令?
- 怎么对命令进行取别名?
- du和df的定义,以及区别?(ddqb)
- 当你需要给命令绑定一个宏或者按键的时候,应该怎么做呢?
- 当前系统支持的所有命令的列表
- 打印出当前的目录栈(lmlz)
- 你的系统目前有许多正在运行的任务,在不重启机器的条件下,有什么方法可以把所有正在运行的进程移除呢?
- bash shell中的hash命令有什么作用?(lhash)
- 哪一个bash内置命令能够进行数学运算。
- 怎样一页一页地查看一个大文件的内容呢?
- 数据字典属于哪一个用户的?
- 怎样查看一个linux命令的概要与用法?假设你在/bin 目录中偶然看到一个你从没见过的的命令,怎样才能知道它的作用和用法呢?
- 使用哪一个命令可以查看自己文件系统的磁盘空间配额呢?
- Linux下创建进程的三种方式及特点(lxcjjc)
- Linux中进程的组成?(lxjczc)
- 进程调度算法?(jcddsf)
- 什么叫孤儿进程,什么叫僵尸进程?(lxjsjc gejc)
- 进程控制函数(lxjckzhs)
- Linux环境下定位CPU飙高的原因(cpubg)
- 项目(126)
Java 基础(1001)
1.JDK 和 JRE 有什么区别?
JDK:Java Development Kit 的简称,java 开发工具包,提供了 java 的开发环境和运行环境。
JRE:Java Runtime Environment 的简称,java 运行环境,为 java 的运行提供了所需环境。
具体来说 JDK 其实包含了 JRE,同时还包含了编译 java 源码的编译器 javac,还包含了很多 java 程序调试和分析的工具。简单来说:如果你需要运行 java 程序,只需安装 JRE 就可以了,如果你需要编写 java 程序,需要安装 JDK。
2.== 和 equals 的区别是什么?(esqb ==dc)
==运算符:
作用于基本数据类型时,是比较两个数值是否相等;
作用于引用数据类型时,是比较两个对象的内存地址是否相同,即判断它们是否为同一个对象;
equals()方法:
没有重写时,Object默认以 == 来实现,即比较两个对象的内存地址是否相同;
进行重写后,一般会按照对象的内容来进行比较,若两个对象内容相同则认为对象相等,否则认为对象不等.
3.两个对象的 hashCode()相同,则 equals()也一定为 true,对吗?
不对,两个对象的 hashCode()相同,equals()不一定 true。
因为在散列表中,hashCode()相等即两个键值对的哈希值相等,然而哈希值相等,并不一定能得出键值对相等。
4.为什么要重写hashCode()和equals()(cxhe)
Object类提供的equals()方法默认是用==来进行比较的,也就是说只有两个对象是同一个对象时,才能返回相等的结果。而实际的业务中,我们通常的需求是,若两个不同的对象它们的内容是相同的,就认为它们相等。鉴于这种情况,Object类中equals()方法的默认实现是没有实用价值的,所以通常都要重写。
由于hashCode()与equals()具有联动关系(参考“说一说hashCode()和equals()的关系”一题),所以equals()方法重写时,通常也要将hashCode()进行重写,使得这两个方法始终满足相关的约定。
5.final 在 java 中有什么作用?(fldc)
final 修饰的类叫最终类,该类不能被继承。
final 修饰的方法不能被重写。
final 修饰的变量叫常量,常量必须初始化,初始化之后值就不能被修改。
6.java 中的 Math.round(-1.5) 等于多少?
等于 -1。
7.String 属于基础的数据类型吗?
String 不属于基础类型,基础类型有 8 种:byte、boolean、char、short、int、float、long、double,而 String 属于对象。
8.java 中操作字符串都有哪些类?它们之间有什么区别?(sss)
操作字符串的类有:String、StringBuffer、StringBuilder。
String 和 StringBuffer、StringBuilder 的区别在于 String 声明的是不可变的对象,每次操作都会生成新的
String 对象,然后将指针指向新的 String 对象,而 StringBuffer、StringBuilder
可以在原有对象的基础上进行操作,所以在经常改变字符串内容的情况下最好不要使用 String。
String中的对象是不可变的,也就可以理解为常量,显然线程安全。
StringBuffer 和 StringBuilder 最大的区别在于,StringBuffer对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。而StringBuilder 是非线程安全的,但 StringBuilder 的性能却高于
StringBuffer,所以在单线程环境下推荐使用 StringBuilder,多线程环境下推荐使用 StringBuffer。
String为什么要设计成不可变的?(sgbkb)
1.便于实现字符串池(String pool)
在Java中,由于会大量的使用String常量,如果每一次声明一个String都创建一个String对象,那将会造成极大的空间资源的浪费。Java提出了String pool的概念,在堆中开辟一块存储空间String pool,当初始化一个String变量时,如果该字符串已经存在了,就不会去创建一个新的字符串变量,而是会返回已经存在了的字符串的引用。如果字符串是可变的,某一个字符串变量改变了其值,那么其指向的变量的值也会改变,String pool将不能够实现!
2.使多线程安全
在并发场景下,多个线程同时读一个资源,是安全的,不会引发竞争,但对资源进行写操作时是不安全的,不可变对象不能被写,所以保证了多线程的安全。
3.避免安全问题
在网络连接和数据库连接中字符串常常作为参数,例如,网络连接地址URL,文件路径path,反射机制所需要的String参数。其不可变性可以保证连接的安全性。如果字符串是可变的,黑客就有可能改变字符串指向对象的值,那么会引起很严重的安全问题。
4.加快字符串处理速度
由于String是不可变的,保证了hashcode的唯一性,于是在创建对象时其hashcode就可以放心的缓存了,不需要重新计算。这也就是Map喜欢将String作为Key的原因,处理速度要快过其它的键对象。所以HashMap中的键往往都使用String。
总体来说,String不可变的原因要包括 设计考虑,效率优化,以及安全性这三大方面。
在使用 HashMap 的时候,用 String 做 key 有什么好处?(sgzk hpsg)
HashMap 内部实现是通过 key 的 hashcode 来确定 value 的存储位置,因为字符串是不可变的,所以当创建字符串时,它的 hashcode 被缓存下来,不需要再次计算,所以相比于其他对象更快。
9.两个字符串相加的底层是如何实现的?(字符串相加zfcxj)
如果拼接的都是字符串直接量,则在编译时编译器会将其直接优化为一个完整的字符串,和你直接写一个完整的字符串是一样的。
如果拼接的字符串中包含变量,则在编译时编译器采用StringBuilder对其进行优化,即自动创建StringBuilder实例并调用其append()方法,将这些字符串拼接在一起。
8.String str="i"与 String str=new String(“i”)一样吗?(字符串创建zfccj)
不一样,因为内存的分配方式不一样
String str=“i” :JVM会使用常量池来管理字符串直接量。在执行这句话时,JVM会先检查常量池中是否已经存有"abc",若没有则将"abc"存入常量池,否则就复用常量池中已有的"abc",将其引用赋值给变量a。
new String(“abc”) :在执行这句话时,JVM会先使用常量池来管理字符串直接量,即将"abc"存入常量池。然后再创建一个新的String对象,这个对象会被保存在堆内存中。并且,堆中对象的数据会指向常量池中的直接量。
10.String 类的常用方法都有那些?(sgff)
indexOf():返回指定字符的索引。
charAt():返回指定索引处的字符。
replace():字符串替换。
trim():去除字符串两端空白。
split():分割字符串,返回一个分割后的字符串数组。
getBytes():返回字符串的 byte 类型数组。
length():返回字符串长度。
toLowerCase():将字符串转成小写字母。
toUpperCase():将字符串转成大写字符。
substring():截取字符串。
equals():字符串比较。
12.普通类和抽象类有哪些区别?
普通类不能包含抽象方法,抽象类可以包含抽象方法。
抽象类不能直接实例化,普通类可以直接实例化。
14.接口和抽象类有什么区别?(jcqb)
- 接口里只能包含抽象方法、静态方法、默认方法和私有方法,不能为普通方法提供方法实现;抽象类则完全可以包含普通方法。
- 接口里只能定义静态常量,不能定义普通成员变量;抽象类里则既可以定义普通成员变量,也可以定义静态常量。
- 接口里不包含构造器;抽象类里可以包含构造器,抽象类里的构造器并不是用于创建对象,而是让其子类调用这些构造器来完成属于抽象类的初始化操作。
- 接口里不能包含初始化块;但抽象类则完全可以包含初始化块
- 一个类最多只能有一个直接父类,包括抽象类;但一个类可以直接实现多个接口,通过实现多个接口可以弥补Java单继承的不足。
15.java 中 IO 流分为几种?(iol)
(1)按照流的方向:输入流(inputStream)和输出流(outputStream);
(2)按照实现功能分:节点流(可以从或向一个特定的地方(节点)读写数据。如
FileReader)和处理流(是对一个已存在的流的连接和封装,通过所封装的流的功能调用实现数据读写。如 BufferedReader。处理流的构造方法总是要带一个其他的流对象做参数。一个流对象经过其他流的多次包装,称为流的链接);
(3)按照处理数据的单位:字节流和字符流。字节流继承于 InputStream 和 OutputStrea,字符流继承于InputStreamReader 和 OutputStreamWriter 。
字节流如何转为字符流?
字节输入流转字符输入流通过 InputStreamReader 实现,该类的构造函数可以传入 InputStream 对象。
字节输出流转字符输出流通过 OutputStreamWriter 实现,该类的构造函数可以传入 OutputStream 对象。
16.BIO、NIO、AIO 有什么区别?(biodc)
BIO:Block IO 同步阻塞式 IO,就是我们平常使用的传统 IO,它的特点是模式简单使用方便,并发处理能力低。
NIO:New IO 同步非阻塞 IO,是传统 IO 的升级,客户端和服务器端通过 Channel(通道)通讯,实现了多路复用。
AIO:异步非阻塞I/O模型,异步非阻塞无需一个线程去轮询所有IO操作的状态改变,在相应的状态改变后,系统会通知对应的线程来处理。对应到烧开水中就是,为每个水壶上面装了一个开关,水烧开之后,水壶会自动通知我水烧开了。
IO 和 NIO 有什么区别(inqb)
首先,I/O指的是 IO 流,它可以实现数据从磁盘中的读取以及写入。实际上,除了磁盘以外,内存、网络都可以作为 I/O 流的数据来源和目的地。在 Java 里面,提供了字符流和字节流两种方式来实现数据流的操作。其次,当程序是面向网络进行数据的 IO 操作的时候,Java 里面提供了 Socket的方式来实现。通过这种方式可以实现数据的网络传输。基于 Socket 的 IO 通信,它是属于阻塞式 IO,也就是说,在连接以及 IO 事件未就绪的情况下,当前的连接会处于阻塞等待的状态。如果一旦某个连接处于阻塞状态,那么后续的连接都得等待。所以服务端能够处理的连接数量非常有限。
NIO,是 JDK1.4 里面新增的一种 NEW IO 机制,相比于传统的 IO,NIO 在效率上做了很大的优化,并且新增了几个核心组件。Channel、Buffer、Selectors。另外,还提供了非阻塞的特性,所以,对于网络 IO 来说,NIO 通常也称为No-Block IO,非阻塞 IO。也就是说,通过 NIO 进行网络数据传输的时候,如果连接未就绪或者 IO 事件未就绪的情况下,服务端不会阻塞当前连接,而是继续去轮询后续的连接来处理。所以在 NIO 里面,服务端能够并行处理的链接数量更多。总的来说,IO 和 NIO 的区别,站在网络 IO 的视角来说,前者是阻塞 IO,后者是非阻塞 IO。
17.File的常用方法都有哪些?(feff)
Files.exists():检测文件路径是否存在。
Files.createFile():创建文件。
Files.createDirectory():创建文件夹。
Files.delete():删除一个文件或目录。
Files.copy():复制文件。
Files.move():移动文件。
Files.size():查看文件个数。
Files.read():读取文件。
Files.write():写入文件。
18、List、Map、Set 三个接口,存取元素时,各有什么特点?(lsmdc)
首先,List 与 Set 具有相似性,它们都是单列元素的集合,所以,它们有一个共同的父接口Collection。Set里面不允许有重复的元素,所以,Set 集合的add方法有一个 boolean 的返回值,当集合中没有某个元素,此时 add 方法可成功加入该元素时,则返回 true,当集合含有与某个元素 equals 相等的元素时,此时 add 方法无法加入该元素,返回结果为 false。Set 取元素时,只能以 Iterator 接口取得所有的元素,再逐一遍历各个元素。 List 表示有先后顺序的集合, Map与 List 和 Set 不同,它是双列的集合,其每次存储时,要存储一对 key/value,不能存储重复的 key,这个重复的规则也是按equals 比较相等。取则可以根据 key 获得相应的 value。 List以特定次序来持有元素,可有重复元素。Set 无法拥有重复元素,内部排序。Map 保存key-value 值,value 可多值。
19、List 和 Map 区别
一个是存储单列数据的集合,另一个是存储键和值这样的双列数据的集合,List 中存储的数据是有顺序,并且允许重复;Map 中存储的数据是没有顺序的,其键是不能重复的,它的值是可以有重复的。
20、HashMap 和 Hashtable 的区别(hhqb)
相同点:1、二者都是 key-value的双列集合;2、底层都是通过数组+链表方式实现数据的存储;不同点:1、继承的父类不同:Hashtable 继承自 Dictionary 类,而 HashMap 继承自 AbstractMap类。但二者都实现了Map 接口。2、线程安全性不同:Hashtable 中的方法是 Synchronize 的,而 HashMap 中的方法在缺省情况下是非Synchronize 的。在多线程并发的环境下,可以直接使用Hashtable,不需要自己为它的方法实现同步,但使用HashMap时就必须要自己增加同步处理。3、hashMap允许 null 键和 null 值,只能有一个,但是 hashtable不允许。4、HashMap 是 java 开发中常用的类,但是 Hashtable和 vector 一样成为了废弃类,不推荐使用,因为有其他高效的方式可以实现线程安全,比如ConcurrentHashMap。
21.HashMap为什么线程不安全(hahsmap线程不安全)(hpxc)
1.在JDK1.7中,当并发执行扩容操作时会造成环形链和数据丢失的情况。(链表的头插法 造成环形链)
2.在JDK1.8中,在并发执行put操作时会发生数据覆盖的情况。(元素插入时使用的是尾插法) HashMap在put的时候,插入的元素超过了容量(由负载因子决定)的范围就会触发扩容操作,就是rehash,这个会重新将原数组的内容重新hash到新的扩容数组中,在多线程的环境下,存在同时其他的元素也在进行put操作,如果hash值相同,可能出现同时在同一数组下用链表表示,造成闭环,导致在get时会出现死循环,所以HashMap是线程不安全的。
32.如何得到一个线程安全的Map(hashmap线程安全 hpxcaq)
使用Collections工具类,将线程不安全的Map包装成线程安全的Map;
使用java.util.concurrent包下的Map,如ConcurrentHashMap;
不建议使用Hashtable,虽然Hashtable是线程安全的,但是性能较差。
22.TreeMap底层怎么实现的?(tpdc)
TreeMap是桶+红黑树的实现方式.TreeMap的底层结构就是一个数组,数组中每一个元素又是一个红黑树.当添加一个元素(key-value)的时候,根据key的hash值来确定插入到哪一个桶中(确定插入数组中的位置),当桶中有多个元素时,使用红黑树进行保存;当一个桶中存放的数据过多,那么根据key查找的效率就会降低
23.LinkedHashMap底层实现原理(lpdc)
LinkedHashMap 继承自 HashMap,所以它的底层仍然是基于拉链式散列结构。该结构由数组和链表+红黑树 ,在此基础上LinkedHashMap增加了一条双向链表,保持遍历顺序和插入顺序一致的问题。在实现上,LinkedHashMap 很多方法直接继承自 HashMap(比如put remove方法就是直接用的父类的),仅为维护双向链表覆写了部分方法(get()方法是重写的)。LinkedHashMap允许使用null值和null键,线程是不安全的,虽然底层使用了双线链表,但是增删变快了。因为他底层的Entity 保留了hashMap node 的next 属性。
24.介绍一下ConcurrentHashMap是怎么实现的?(cpdc)
JDK 1.7中的实现:
在 jdk 1.7 中,ConcurrentHashMap 是由 Segment 数据结构和 HashEntry数组结构构成,采取分段锁来保证安全性。Segment 是 ReentrantLock 重入锁,在 ConcurrentHashMap中扮演锁的角色,HashEntry 则用于存储键值对数据。一个 ConcurrentHashMap 里包含一个 Segment 数组,一个Segment 里包含一个 HashEntry 数组,Segment 的结构和 HashMap 类似,是一个数组和链表结构。
JDK1.8中的实现:JDK1.8 的实现已经摒弃了 Segment 的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用Synchronized 和 CAS 来操作,整个看起来就像是优化过且线程安全的 HashMap,虽然在 JDK1.8 中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本。当我们初始化一个 ConcurrentHashMap 实例时,默认会初始化一个长度为 16的数组。由于 ConcurrentHashMap 它的核心仍然是 hash 表,所以必然会存在hash 冲突问题。ConcurrentHashMap 采用链式寻址法来解决 hash 冲突。当 hash 冲 突 比 较 多 的 时 候 , 会 造 成 链 表 长 度 较 长 , 这 种 情 况 会 使 得ConcurrentHashMap 中数据元素的查询复杂度变成 O(n)。因此在 JDK1.8 中,引入了红黑树的机制。当数组长度大于 64 并且链表长度大于等于 8 的时候,单项链表就会转换为红黑树。另外,随着 ConcurrentHashMap 的动态扩容,一旦链表长度小于 8,红黑树会退化成单向链表。
25.HashMap与LinkedHashMap的区别(hlqb)
HashMap 它根据键的HashCode 值存储数据,根据键可以直接获取它的值,具有很快的访问速度。遍历时,取得数据的顺序是完全随机的。HashMap最多只允许一条记录的键为Null;允许多条记录的值为
Null。 HashMap不支持线程的同步,可能会导致数据的不一致。如果需要同步,可以用Collections的synchronizedMap方法使HashMap具有同步的能力,或者使用ConcurrentHashMap。
保存插入顺序:LinkedHashMap保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的。也可以在构造时带参数,按照应用次数排序。速度慢:在遍历的时候会比HashMap慢,不过有种情况例外:当HashMap容量很大,实际数据较少时,遍历起来可能会比LinkedHashMap慢。因为LinkedHashMap的遍历速度只和实际数据有关,和容量无关,而HashMap的遍历速度和他的容量有关。
26.HashMap与ConcurrentHashMap有什么区别?(hcqb)
HashMap是非线程安全的,这意味着不应该在多线程中对这些Map进行修改操作,否则会产生数据不一致的问题,甚至还会因为并发插入元素而导致链表成环,这样在查找时就会发生死循环,影响到整个应用程序。
Collections工具类可以将一个Map转换成线程安全的实现,其实也就是通过一个包装类,然后把所有功能都委托给传入的Map,而包装类是基于synchronized关键字来保证线程安全的(Hashtable也是基于synchronized关键字),底层使用的是互斥锁,性能与吞吐量比较低。
ConcurrentHashMap的实现细节远没有这么简单,因此性能也要高上许多。它没有使用一个全局锁来锁住自己,而是采用了减少锁粒度的方法,尽量减少因为竞争锁而导致的阻塞与冲突,而且ConcurrentHashMap的检索操作是不需要锁的。
28. Integer i=100; Integer j=100;true还是false
这个结果为true,根本原因是java的包装类Integer使用了缓存,对包装类的自动装箱、自动拆箱也是一种语法糖, Java的new Integer操作,当参数值在【-128,127】之间时,new操作返回的对象是有缓存的,你使用的5在这个范围内,所以使用的是ab是同一个对象。
30.char能不能存储汉字?
答:java char型变量是能够定义成为一个中文的,因为java中以unicode编码,一个char占16个字节,所以放一个中文是没问题的
34. 线程方法常用的是什么?(xcff)
Thread类的常用方法:
static Thread currentThread()//静态方法,通过这个方法可以获得主线程的引用,从而达到操作主线程的目的。
static int activeCount()//静态方法,获得当前活动线程数量 long getId() //获得当前线程id String
getName() //获得当前线程名字
int getPriority() //获得优先级 boolean isAlive() //当前线程是否处于活动状态。 boolean
isDaemon() //是否为守护线程 void run() //run()方法,我们用线程,主要就是对run()方法的重写 void
start() // 使该线程开始执行;Java 虚拟机调用该线程的run() 方法。
void sleep()//使当前线程休眠,以执行其他线程,如Thread.sleep(1000) 休眠1秒
35.Servlet中forward()和redirct()的区别?
答:前者仅是容器中控制权的转向,在客户端浏览器地址栏中不会显示出转向后的地址;后者则是完全的跳转,浏览器将会得到跳转的地址,并重新发送请求链接。这样,从浏览器的地址栏中可以看到跳转后的链接地址。所以,前者更加高效,在前者可以满足需要时,尽量使用forward()方法,并且,这样也有助于隐藏实际的链接。在有些情况下,比如,需要跳转到一个其它服务器上的资源,则必须使用sendRedirect()方法。
36.Servlet的生命周期 (stsmzq)
servlet的生命周期就是从servlet出现到销毁的全过程。主要分为以下几个阶段: 加载类—>实例化(为对象分配空间)—>初始化(为对象的属性赋值)—>请求处理(服务阶段)—>销毁
服务器启动时(web.xml中配置load-on-startup=1,默认为0)或者第一次请求该servlet时,就会初始化一个Servlet对象,也就是会执行初始化方法init(ServletConfig conf),该servlet对象去处理所有客户端请求,service(ServletRequest req,ServletResponse res)方法中执行,最后服务器关闭时,才会销毁这个servlet对象,执行destroy()方法。其中加载阶段无法观察,但是初始化、服务、销毁阶段是可以观察到的。
37.存储过程和函数的区别?(chqb hcqb)
本质上没区别。只是函数有如:只能返回一个变量的限制。而存储过程可以返回多个。而函数是可以嵌入在sql中使用的,可以在select中调用,而存储过程不行。执行的本质都一样。 函数限制比较多,比如不能用临时表,只能用表变量.还有一些函数都不可用等等.而存储过程的限制相对就比较少
38.Java8新特性(xtx)
1 lambda表达式。
2 注解拓展,注解几乎可以使用在任何元素上:局部变量、接口类型、超类和接口实现类。
3 类型推断的能力更加强大。
4 使用@Repeatable注解定义重复注解,可以在同一个地方多次使用同一个注解。
5 接口的静态方法和默认方法。默认方法可以直接被实现类继承,静态方法可以直接被调用。抽象方法必须被实现类实现。
6 Java8中,当链表中的元素超过了 8 个以后,会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为 O(logN)。
39.说一说你对Java访问权限的了解(lfwqx)
Java语言为我们提供了三种访问修饰符,即private、protected、public,在使用这些修饰符修饰目标时,一共可以形成四种访问权限,即private、default、protected、public,注意在不加任何修饰符时为default访问权限。
在修饰成员变量/成员方法时,该成员的四种访问权限的含义如下 (cybl):private:该成员可以被该类内部成员访问;
default:该成员可以被该类内部成员访问,也可以被同一包下其他的类访问;
protected:该成员可以被该类内部成员访问,也可以被同一包下其他的类访问,还可以被它的子类访问;
public:该成员可以被任意包下,任意类的成员进行访问。
在修饰类时,该类只有两种访问权限,对应的访问权限的含义如下:
default:该类可以被同一包下其他的类访问;
public:该类可以被任意包下,任意的类所访问。
40.介绍一下Java的数据类型(jasjlx)
Java数据类型包括基本数据类型和引用数据类型两大类。
基本数据类型有8个,可以分为4个小类,分别是整数类型(byte/short/int/long)、浮点类型(float/double)、字符类型(char)、布尔类型(boolean)。其中,4个整数类型中,int类型最为常用。2个浮点类型中,double最为常用。
引用类型就是对一个对象的引用,根据引用对象类型的不同,可以将引用类型分为3类,即数组、类、接口类型。引用类型本质上就是通过指针,指向堆中对象所持有的内存空间,只是Java语言不再沿用指针这个说法而已。
byte:1字节(8位),数据范围是 -2^7 ~ 2^7-1。short:2字节(16位),数据范围是 -2^15 ~ 2^15-1。
int:4字节(32位),数据范围是 -2^31 ~ 2^31-1。
long:8字节(64位),数据范围是 -2^63 ~ 2^63-1。
float:4字节(32位),数据范围大约是 -3.410^38 ~ 3.410^38。
double:8字节(64位),数据范围大约是 -1.810^308 ~ 1.810^308。
char:2字节(16位),数据范围是 \u0000 ~ \uffff。
boolean:Java规范没有明确的规定,不同的JVM有不同的实现机制。
41.请介绍全局变量(成员)和局部变量的区别(cjqb)
成员变量:
成员变量是在类的范围里定义的变量;
成员变量有默认初始值;
未被static修饰的成员变量也叫实例变量,它存储于对象所在的堆内存中,生命周期与对象相同;
被static修饰的成员变量也叫类变量,它存储于方法区中,生命周期与当前类相同。
局部变量:
局部变量是在方法里定义的变量;
局部变量没有默认初始值;
局部变量存储于栈内存中,作用的范围结束,变量空间会自动的释放。
42.说一说自动装箱、自动拆箱的应用场景(czxjz)
自动装箱、自动拆箱是JDK1.5提供的功能。
自动装箱:可以把一个基本类型的数据直接赋值给对应的包装类型;
自动拆箱:可以把一个包装类型的对象直接赋值给对应的基本类型;
通过自动装箱、自动拆箱功能,可以大大简化基本类型变量和包装类对象之间的转换过程。比如,某个方法的参数类型为包装类型,调用时我们所持有的数据却是基本类型的值,则可以不做任何特殊的处理,直接将这个基本类型的值传入给方法即可。
44.int和Integer有什么区别(iiqb)
1、Integer是int的包装类,int则是java的一种基本数据类型
2、Integer变量必须实例化后才能使用,而int变量不需要
3、Integer实际是对象的引用,当new一个Integer时,实际上是生成一个指针指向此对象;而int则是直接存储数据值
4、Integer的默认值是null,int的默认值是0
45.面向对象的三大特征是什么(面向对象特征)(mxdxtz)
面向对象的程序设计方法具有三个基本特征:封装、继承、多态。其中,封装指的是将对象的实现细节隐藏起来,然后通过一些公用方法来暴露该对象的功能;继承是面向对象实现软件复用的重要手段,当子类继承父类后,子类作为一种特殊的父类,将直接获得父类的属性和方法;多态指的是子类对象可以直接赋给父类变量,但运行时依然表现出子类的行为特征,这意味着同一个类型的对象在执行同一个方法时,可能表现出多种行为特征。
29.重写和重载的区别?(ccqb)
override(重写) 1、方法名、参数、返回值相同。 2、子类方法不能缩小父类方法的访问权限。3、子类方法不能抛出比父类方法更多的异常(但子类方法可以不抛出异常)。 4、存在于父类和子类之间。 5、方法被定义为final不能被重写。
overload(重载) 1、参数类型、个数、顺序至少有一个不相同。 2、不能重载只有返回值不同的方法名。 3、存在于父类和子类、同类中。
46.Java为什么是单继承,为什么不能多继承(java单继承)(jadjc)
首先,Java是单继承的,指的是Java中一个类只能有一个直接的父类。Java不能多继承,则是说Java中一个类不能直接继承多个父类。
其次,Java在设计时借鉴了C++的语法,而C++是支持多继承的。Java语言之所以摒弃了多继承的这项特征,是因为多继承容易产生混淆。比如,两个父类中包含相同的方法时,子类在调用该方法或重写该方法时就会迷惑。
准确来说,Java是可以实现"多继承"的。因为尽管一个类只能有一个直接父类,但是却可以有任意多个间接的父类。这样的设计方式,避免了多继承时所产生的混淆。
48.构造方法能不能重写
构造方法不能重写。因为构造方法需要和类保持同名,而重写的要求是子类方法要和父类方法保持同名。如果允许重写构造方法的话,那么子类中将会存在与类名不同的构造方法,这与构造方法的要求是矛盾的。
49.介绍一下Object类中的方法(otdc)
一个object对象占用16字节
Class<?> getClass():返回该对象的运行时类。boolean equals(Object obj):判断指定对象与该对象是否相等。
inthashCode():返回该对象的hashCode值。在默认情况下,Object类的hashCode()方法根据该对象的地址来计算。但很多类都重写了Object类的hashCode()方法,不再根据地址来计算其hashCode()方法值。
String
toString():返回该对象的字符串表示,当程序使用System.out.println()方法输出一个对象,或者把某个对象和字符串进行连接运算时,系统会自动调用该对象的toString()方法返回该对象的字符串表示。Object类的toString()方法返回运行时类名@十六进制hashCode值格式的字符串,但很多类都重写了Object类的toString()方法,用于返回可以表述该对象信息的字符串。另外,Object类还提供了wait()、notify()、notifyAll()这几个方法,通过这几个方法可以控制线程的暂停和运行。Object类还提供了一个clone()方法,该方法用于帮助其他对象来实现“自我克隆”,所谓“自我克隆”就是得到一个当前对象的副本,而且二者之间完全隔离。由于该方法使用了protected修饰,因此它只能被子类重写或调用。
50.说一说你对static关键字的理解(scdc)
在Java类里只能包含成员变量、方法、构造器、初始化块、内部类(包括接口、枚举)5种成员,而static可以修饰成员变量、方法、初始化块、内部类(包括接口、枚举),以static修饰的成员就是类成员。类成员属于整个类,而不属于单个对象。
对static关键字而言,有一条非常重要的规则:类成员(包括成员变量、方法、初始化块、内部类和内部枚举)不能访问实例成员(包括成员变量、方法、初始化块、内部类和内部枚举)。因为类成员是属于类的,类成员的作用域比实例成员的作用域更大,完全可能出现类成员已经初始化完成,但实例成员还不曾初始化的情况,如果允许类成员访问实例成员将会引起大量错误。
51.static和final有什么区别?(sfqb)
static关键字可以修饰成员变量、成员方法、初始化块、内部类,被static修饰的成员是类的成员,它属于类、不属于单个对象。以下是static修饰这4种成员时表现出的特征:
1.类变量:被static修饰的成员变量叫类变量(静态变量)。类变量属于类,它随类的信息存储在方法区,并不随对象存储在堆中,类变量可以通过类名来访问,也可以通过对象名来访问,但建议通过类名访问它。
2.类方法:被static修饰的成员方法叫类方法(静态方法)。类方法属于类,可以通过类名访问,也可以通过对象名访问,建议通过类名访问它。
3.静态块:被static修饰的初始化块叫静态初始化块。静态块属于类,它在类加载的时候被隐式调用一次,之后便不会被调用了。
4.静态内部类:被static修饰的内部类叫静态内部类。静态内部类可以包含静态成员,也可以包含非静态成员。静态内部类不能访问外部类的实例成员,只能访问外部类的静态成员。外部类的所有方法、初始化块都能访问其内部定义的静态内部类。
final关键字可以修饰类、方法、变量,以下是final修饰这3种目标时表现出的特征:
final类:final关键字修饰的类不可以被继承。
final方法:final关键字修饰的方法不可以被重写。
final变量:final关键字修饰的变量,一旦获得了初始值,就不可以被修改。
52.说一说你对泛型的理解(fxdc)
Java集合有个缺点—把一个对象“丢进”集合里之后,集合就会“忘记”这个对象的数据类型,当再次取出该对象时,该对象的编译类型就变成了Object类型(其运行时类型没变)。
但这样做带来如下两个问题:
(1) 集合对元素类型没有任何限制,这样可能引发一些问题。例如,想创建一个只能保存Dog对象的集合,但程序也可以轻易地将Cat对象“丢”进去,所以可能引发异常。
(2)由于把对象“丢进”集合时,集合丢失了对象的状态信息,只知道它盛装的是Object,因此取出集合元素后通常还需要进行强制类型转换。这种强制类型转换既增加了编程的复杂度,也可能引发ClassCastException异常。
从Java5开始,Java引入了“参数化类型”的概念,允许程序在创建集合时指定集合元素的类型,Java的参数化类型被称为泛型(Generic)。例如 List,表明该List只能保存字符串类型的对象。
有了泛型以后,程序再也不能“不小心”地把其他对象“丢进”集合中。而且程序更加简洁,集合自动记住所有集合元素的数据类型,从而无须对集合元素进行强制类型转换。
53.List<? super T>和List<? extends T>有什么区别?(通配符tpfdc)
? 是类型通配符,List<?> 可以表示各种泛型List的父类,意思是元素类型未知的List;
List<? super T> 用于设定类型通配符的下限,此处 ? 代表一个未知的类型,但它必须是T的父类型;
List<? extends T> 用于设定类型通配符的上限,此处 ? 代表一个未知的类型,但它必须是T的子类型。
Lambda表达式和匿名内部类的区别(lnqb)
1.所需类型不同:
匿名内部类:可以是接口,也可以是抽象类,还可以是具体类。
Lambda表达式:只能是接口。
2.使用限制不同
如果接口中有且仅有一个抽象方法,可以使用Lambda表达式,也可以使用匿名内部类。
如果接口中多于一个抽象方法,只能使用匿名内部类,而不能使用Lambda表达式。
3.实现原理不同
匿名内部类:编译之后,产生一个单独的.class字节码文件。
Lambda表达式:编译之后,没有一个单独的.class字节码文件。对应的字节码会在运行的时候动态生成。
Java 对象的生命周期(jadxsmzq)
在Java中,对象的生命周期包括以下几个阶段:
创建阶段(Created)
应用阶段(In Use)
不可见阶段(Invisible)
不可达阶段(Unreachable)
收集阶段(Collected)
终结阶段(Finalized)
对象空间重分配阶段(De-allocated)
1.创建阶段(Created)
在创建阶段系统通过下面的几个步骤来完成对象的创建过程
l 为对象分配存储空间
l 开始构造对象
l 从超类到子类对static成员进行初始化
l 超类成员变量按顺序初始化,递归调用超类的构造方法
l 子类成员变量按顺序初始化,子类构造方法调用
一旦对象被创建,并被分派给某些变量赋值,这个对象的状态就切换到了应用阶段
2.应用阶段(In Use)
对象至少被一个强引用持有着。
3.不可见阶段(Invisible)
当一个对象处于不可见阶段时,说明程序本身不再持有该对象的任何强引用,虽然该这些引用仍然是存在着的。
简单说就是程序的执行已经超出了该对象的作用域了。
4.不可达阶段(Unreachable)
对象处于不可达阶段是指该对象不再被任何强引用所持有。
与“不可见阶段”相比,“不可见阶段”是指程序不再持有该对象的任何强引用,这种情况下,该对象仍可能被JVM等系统下的某些已装载的静态变量或线程或JNI等强引用持有着,这些特殊的强引用被称为”GC root”。存在着这些GC root会导致对象的内存泄露情况,无法被回收。
5.收集阶段(Collected)
当垃圾回收器发现该对象已经处于“不可达阶段”并且垃圾回收器已经对该对象的内存空间重新分配做好准备时,则对象进入了“收集阶段”。如果该对象已经重写了finalize()方法,则会去执行该方法的终端操作。
这里要特别说明一下:不要重载finazlie()方法!原因有两点:
l 会影响JVM的对象分配与回收速度
在分配该对象时,JVM需要在垃圾回收器上注册该对象,以便在回收时能够执行该重载方法;在该方法的执行时需要消耗CPU时间且在执行完该方法后才会重新执行回收操作,即至少需要垃圾回收器对该对象执行两次GC。
l 可能造成该对象的再次“复活”
在finalize()方法中,如果有其它的强引用再次持有该对象,则会导致对象的状态由“收集阶段”又重新变为“应用阶段”。这个已经破坏了Java对象的生命周期进程,且“复活”的对象不利用后续的代码管理。
6.终结阶段
当对象执行完finalize()方法后仍然处于不可达状态时,则该对象进入终结阶段。在该阶段是等待垃圾回收器对该对象空间进行回收。
7.对象空间重新分配阶段
垃圾回收器对该对象的所占用的内存空间进行回收或者再分配了,则该对象彻底消失了,称之为“对象空间重新分配阶段”。
容器(101)
Collection 和 Collections 有什么区别?(ccqb)
java.util.Collection是一个集合接口(集合类的一个顶级接口)。它提供了对集合对象进行基本操作的通用接口方法。Collection接口在Java 类库中有很多具体的实现。Collection接口的意义是为各种具体的集合提供了最大化的统一操作方式,其直接继承接口有List与Set。
Collections则是集合类的一个工具类/帮助类,其中提供了一系列静态方法,用于对集合中元素进行排序、搜索以及线程安全等各种操作。
List、Set、Map 之间的区别是什么?(lsmqb)

27、常见的list,set接口的特点及实现类(lsmdc)
List 接口的特点:元素可重复,有序(存取顺序)。 list 接口的实现类如下:
Ø ArrayList:底层实现是数组,查询快,增删慢,线程不安全,效率高;
Ø Vector:底层实现是数组,查询快,增删慢,线程安全,效率低;【废弃】
Ø LinkedList:底层实现是链表,增删快,查询慢,线程不安全,效率高;
Ø Set 接口的特点:元素唯一,不可重复,无序。 Set 接口实现类如下:
Ø HashSet:底层实现 hashMap,数组+链表实现,不允许元素重复,无序。
Ø TreeSet:底层实现红黑二叉树,实现元素排序
Ø Map 接口的特点:key-value 键值对形式存储数据 Map 接口实现类如下:
Ø HashMap:底层数组+链表实现,线程不安全效率高;
Ø TreeMap:底层红黑二叉树实现,可实现元素的排序;
Ø LinkedHashMap:底层hashmap+linkedList 实现,通过 hashmap 实现 key-value 键值对存储,通过链表实现元素有序。
如何决定使用 HashMap 还是 TreeMap?
对于在Map中插入、删除和定位元素这类操作,HashMap是最好的选择。然而,假如你需要对一个有序的key集合进行遍历,TreeMap是更好的选择。基于你的collection的大小,也许向HashMap中添加元素会更快,将map换为TreeMap进行有序key的遍历。
说一下 HashMap的实现原理?(hpdc)
在JDK1.6,JDK1.7中,HashMap采用位桶+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,HashMap采用位桶+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。当链表长度大于或等于阈值(默认为 8)的时候,如果同时还满足容量大于或等于 MIN_TREEIFY_CAPACITY(默认为 64)的要求,就会把链表转换为红黑树。同样,后续如果由于删除或者其他原因调整了大小,当红黑树的节点小于或等于 6 个以后,又会恢复为链表形态。(通常如果 hash 算法正常的话,那么链表的长度也不会很长,那么红黑树也不会带来明显的查询时间上的优势,反而会增加空间负担。所以通常情况下,并没有必要转为红黑树,所以就选择了概率非常小,小于千万分之一概率,也就是长度为 8 的概率,把长度 8 作为转化的默认阈值。在理想情况下,链表长度符合泊松分布,各个长度的命中概率依次递减,当长度为 8 的时候,概率仅为 0.00000006。这是一个小于千万分之一的概率,通常我们的 Map 里面是不会存储这么多的数据的,所以通常情况下,并不会发生从链表向红黑树的转换。链表长度超过 8 就转为红黑树的设计,更多的是为了防止用户自己实现了不好的哈希算法时导致链表过长,从而导致查询效率低, 而此时转为红黑树更多的是一种保底策略,用来保证极端情况下查询的效率。)
hashMap默认初始化容量为 16,也就是说数组索引值为0-15,每个数组中存储一个链表。当 hashmap 空间使用达到 0.75后,会对数组进行扩容,新建数组,然后将元素拷贝到新的数组中,每次扩容翻倍。存储元素时,存储对象为Map.Entry,entry对象包含四个信息,key、value、hash 值、链表地址值,因为存储元素时,会根据hash 值%16 计算,元素存储数组中的索引位置。 但是有可能发生
hash冲突现象(hxct),即两个元素不相同,却有一样的 hash 值,这样的话,就将元素在数组中存入链表中,以链表的形式进行元素的存储,第一个entry存在链表顶端,再有hash 值一致的entry 存入,则链接在第一个元素之后。put()方法存储元素时,根据hash值定位数组,在链表中通过HashCode()和equals()方法,定位元素的key,若没有一致的entry,则在链表中添加entry对象,若找到一样的entry,则将oldValue返回,将新的value 存入到entry 中。为了解决哈希碰撞,数组中的元素是单向链表类型。当链表长度到达一个阈值时,会将链表转换成红黑树提高性能。而当链表长度缩小到另一个阈值时,又会将红黑树转换回单向链表提高性能。
Hashmap触发扩容条件:hashMap默认的负载因子是0.75,即如果hashmap中的元素个数超过了总容量75%,则会触发扩容;如果某个桶中的链表长度大于等于8了,则会判断当前的hashmap的容量是否大于64,如果小于64,则会进行扩容;如果大于64,则将链表转为红黑树。
介绍一下HashMap扩容机制(hpkr)
数组的初始容量为16,而容量是以2的次方扩充的,一是为了提高性能使用足够大的数组,二是为了能使用位运算代替取模预算(据说提升了5~8倍)。
数组是否需要扩充是通过负载因子判断的,如果当前元素个数为数组容量的0.75时,就会扩充数组。这个0.75就是默认的负载因子,可由构造器传入。我们也可以设置大于1的负载因子,这样数组就不会扩充,牺牲性能,节省内存。
对于第三点补充说明,检查链表长度转换成红黑树之前,还会先检测当前数组数组是否到达一个阈值(64),如果没有到达这个容量,会放弃转换,先去扩充数组。所以上面也说了链表长度的阈值是7或8,因为会有一次放弃转换的操作。
为什么需要使用加载因子,为什么需要扩容呢?因为如果填充比很大,说明利用的空间很多,如果一直不进行扩容的话,链表就会越来越长,这样查找的效率很低,因为链表的长度很大,扩容之后,将原来链表数组的每一个链表分成奇偶两个子链表分别挂在新链表数组的散列位置,这样就减少了每个链表的长度,增加查找效率。
31.描述一下HashMapput的过程(hpput)
HashMap是最经典的Map实现,下面以它的视角介绍put的过程:
1.首次扩容:
先判断数组是否为空,若数组为空则进行第一次扩容(resize);
2.计算索引:
通过hash算法,计算键值对在数组中的索引;
3.插入数据:
如果当前位置元素为空,则直接插入数据;
如果当前位置元素非空,且key已存在,则直接覆盖其value;
如果当前位置元素非空,且key不存在,则将数据链到链表末端;
若链表长度达到8,则将链表转换成红黑树,并将数据插入树中;
4.再次扩容
如果数组中元素个数(size)超过threshold,则再次进行扩容操作。
为什么HashMap线程不安全(hpxcbaq)
HashMap会进行resize操作,在resize操作的时候会造成线程不安全。下面将举两个可能出现线程不安全的地方。
1、put的时候导致的多线程数据不一致。
这个问题比较好想象,比如有两个线程A和B,首先A希望插入一个key-value对到HashMap中,首先计算记录所要落到的桶的索引坐标,然后获取到该桶里面的链表头结点,此时线程A的时间片用完了,而此时线程B被调度得以执行,和线程A一样执行,只不过线程B成功将记录插到了桶里面,假设线程A插入的记录计算出来的桶索引和线程B要插入的记录计算出来的桶索引是一样的,那么当线程B成功插入之后,线程A再次被调度运行时,它依然持有过期的链表头但是它对此一无所知,以至于它认为它应该这样做,如此一来就覆盖了线程B插入的记录,这样线程B插入的记录就凭空消失了,造成了数据不一致的行为。
2、另外一个比较明显的线程不安全的问题是HashMap的get操作可能因为resize而引起死循环
多线程HashMap的resize
我们假设有两个线程同时需要执行resize操作,我们原来的桶数量为2,记录数为3,需要resize桶到4,原来的记录分别为:[3,A],[7,B],[5,C],在原来的map里面,我们发现这三个entry都落到了第二个桶里面。
假设线程thread1执行到了transfer方法的Entry next = e.next这一句,然后时间片用完了,此时的e = [3,A], next = [7,B]。线程thread2被调度执行并且顺利完成了resize操作,需要注意的是,此时的[7,B]的next为[3,A]。此时线程thread1重新被调度运行,此时的thread1持有的引用是已经被thread2 resize之后的结果。线程thread1首先将[3,A]迁移到新的数组上,然后再处理[7,B],而[7,B]被链接到了[3,A]的后面,处理完[7,B]之后,就需要处理[7,B]的next了啊,而通过thread2的resize之后,[7,B]的next变为了[3,A],此时,[3,A]和[7,B]形成了环形链表,在get的时候,如果get的key的桶索引和[3,A]和[7,B]一样,那么就会陷入死循环。
HashMap中的循环链表是如何产生的?(hpxhlb)
HashMap在并发执行put操作时,可能会导致形成循环链表,从而引起死循环。在多线程的情况下,当重新调整HashMap大小的时候,就会存在条件竞争,因为如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小。在调整大小的过程中,存储在链表中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在链表的尾部,而是放在头部,这是为了避免尾部遍历。如果条件竞争发生了,那么就会产生死循环了。
说一下 HashSet 的实现原理?(htdc)
HashSet底层由HashMap实现,由于 Map 需要 key 和 value,所以 所有 key 的都有一个默认 value。类似于
HashMap,HashSet 不允许重复的 key,只允许有一个 null key,意思就是 HashSet 中只允许存储一个 null
对象。HashSet的值存放于HashMap的key上
HashMap的value统一为PRESENT
ArrayList 和 LinkedList 的区别是什么?(alqb)
是否保证线程安全: ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
底层数据结构: Arraylist 底层使用的是Object数组;LinkedList 底层使用的是双向循环链表数据结构;
插入和删除是否受元素位置的影响: ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行add(E e)方法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是O(1)。但是如果要在指定位置 i 插入和删除元素的话(add(int index, E element))时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 LinkedList 采用链表存储,所以插入,删除元素时间复杂度不受元素位置的影响,都是近似 O(1)而数组为近似 O(n)。
是否支持快速随机访问: LinkedList 不支持高效的随机元素访问,而ArrayList 实现了RandomAccess 接口,所以有随机访问功能。快速随机访问就是通过元素的序号快速获取元素对象(对应于get(int index)方法)。
内存空间占用: ArrayList的空 间浪费主要体现在在list列表的结尾会预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗比ArrayList更多的空间(因为要存放直接后继和直接前驱以及数据)。
如何实现数组和 List 之间的转换?
List转换成为数组:调用ArrayList的toArray方法。
数组转换成为List:调用Arrays的asList方法。
ArrayList 和 Vector 的区别是什么?(avqb)
Vector是同步的,而ArrayList不是。然而,如果你寻求在迭代的时候对列表进行改变,你应该使用CopyOnWriteArrayList。
ArrayList比Vector快,它因为有同步,不会过载。
ArrayList更加通用,因为我们可以使用Collections工具类轻易地获取同步列表和只读列表。
Array 和 ArrayList 有何区别?(aaqb)
Array可以容纳基本类型和对象,而ArrayList只能容纳对象。
Array是指定大小后不可变的,而ArrayList大小是可变的。
Array没有提供ArrayList那么多功能,比如addAll、removeAll和iterator等。
在队列中 poll()和 remove()有什么区别?(prqb)
poll() 和 remove() 都是从队列中取出一个元素,但是 poll() 在获取元素失败的时候会返回空,但是 remove()
失败的时候会抛出异常。
哪些集合类是线程安全的?(jhlxcaq)
vector:就比arraylist多了个同步化机制(线程安全),因为效率较低,现在已经不太建议使用。在web应用中,特别是前台页面,往往效率(页面响应速度)是优先考虑的。
statck:堆栈类,先进后出。
hashtable:就比hashmap多了个线程安全。
enumeration:枚举,相当于迭代器。
迭代器 Iterator 是什么?(irdc)
迭代器是一种设计模式,它是一个对象,它可以遍历并选择序列中的对象,而开发人员不需要了解该序列的底层结构。迭代器通常被称为“轻量级”对象,因为创建它的代价小。
Iterator 怎么使用?有什么特点?(irjs)
Java中的Iterator功能比较简单,并且只能单向移动:
(1) 使用方法iterator()要求容器返回一个Iterator。第一次调用Iterator的next()方法时,它返回序列的第一个元素。注意:iterator()方法是java.lang.Iterable接口,被Collection继承。
(2) 使用next()获得序列中的下一个元素。
(3) 使用hasNext()检查序列中是否还有元素。
(4) 使用remove()将迭代器新返回的元素删除。
Iterator是Java迭代器最简单的实现,为List设计的ListIterator具有更多的功能,它可以从两个方向遍历List,也可以从List中插入和删除元素。
Iterator 和 ListIterator 有什么区别?(ilqb)
Iterator可用来遍历Set和List集合,但是ListIterator只能用来遍历List。
Iterator对集合只能是前向遍历,ListIterator既可以前向也可以后向。
ListIterator实现了Iterator接口,并包含其他的功能,比如:增加元素,替换元素,获取前一个和后一个元素的索引,等等。
SimpleDataFormat 是非线程安全的,如何更好的使用而避免风险呢(stxcaq)
DateFormat 的所有实现,包括 SimpleDateFormat 都不是线程安全的,因此你不应该在多线程序中使用,除非是在对外线程安全的环境中使用,如 将 SimpleDateFormat 限制在 ThreadLocal 中。如果你不这么做,在解析或者格式化日期的时候,可能会获取到一个不正确的结果。因此,从日期、时间处理的所有实践来说,我强力推荐 joda-time 库。
解决办法:
1.需要的时候创建新实例:在需要用到SimpleDateFormat 的地方新建一个实例,不管什么时候,将有线程安全问题的对象由共享变为局部私有都能避免多线程问题,不过也加重了创建对象的负担。在一般情况下,这样其实对性能影响比不是很明显的。
2.使用同步:同步SimpleDateFormat对象,当线程较多时,当一个线程调用该方法时,其他想要调用此方法的线程就要block,多线程并发量大的时候会对性能有一定的影响。
3.使用ThreadLocal:使用ThreadLocal, 也是将共享变量变为独享,线程独享肯定能比方法独享在并发环境中能减少不少创建对象的开销。如果对性能要求比较高的情况下,一般推荐使用这种方法。
4.抛弃JDK,使用其他类库中的时间格式化类:1.使用Apache commons 里的FastDateFormat,宣称是既快又线程安全的SimpleDateFormat, 可惜它只能对日期进行format, 不能对日期串进行解析。
2.使用Joda-Time类库来处理时间相关问题
多线程(102)
并行和并发有什么区别?(bbqb)
并行是指两个或者多个事件在同一时刻发生;而并发是指两个或多个事件在同一时间间隔发生。
并行是在不同实体上的多个事件,并发是在同一实体上的多个事件。
在一台处理器上“同时”处理多个任务,在多台处理器上同时处理多个任务。如hadoop分布式集群。
线程和进程的区别?(jxqb)
- 进程是一个“执行中的程序”,是系统进行资源分配和调度的一个独立单位。
- 线程是进程的一个实体,一个进程中拥有多个线程,线程之间共享地址空间和其它资源(所以
通信和同步等操作线程比进程更加容易) - 线程上下文的切换比进程上下文切换要快很多。
(1)进程切换时,涉及到当前进程的CPU环境的保存和新被调度运行进程的CPU环境的设置。
(2)线程切换仅需要保存和设置少量的寄存器内容,不涉及存储管理方面的操作。
进程与线程的切换流程?(jxqh)
进程切换分两步:
1、切换页表以使用新的地址空间,一旦去切换上下文,处理器中所有已经缓存的内存地址一瞬间都作废了。
2、切换内核栈和硬件上下文。
对于linux来说,线程和进程的最大区别就在于地址空间,对于线程切换,第1步是不需要做的,第2步是进程和线程切换都要做的。
因为每个进程都有自己的虚拟地址空间,而线程是共享所在进程的虚拟地址空间的,因此同一个进程中的线程进行线程切换时不涉及虚拟地址空间的转换。
进程的用户态和内核态(ynqb)(xclx)
线程类型
内核线程(KLT)
内核线程就是直接由操作系统内核支持的线程,这种线程由内核来完成线程切换,内核通过操纵调度器对线程进行调度,并负责将线程的任务映射到各个处理器上。每个内核线程可以视为内核的一个分身,这样操作系统就有能力同时处理多件事情,支持多线程的内核就叫做多线程内核。
用户线程(UT)
用户线程建立在用户空间的线程库上,系统内核不能感知线程存在的实现。用户线程的建立、同步、销毁和调度完全在用户态中完成,不需要内核的帮助。如果程序实现得当,这种线程不需要切换到内核态,因此操作可以是非常快速且低消耗的,也可以支持规模更大的线程数量,部分高性能数据库中的多线程就是由用户线程实现的。
进程的用户态和内核态
内核态:
当一个任务(进程)执行系统调用而陷入内核代码中执行时,我们就称进程处于内核运行态。此时处理器处于特权级最高的(0级)内核代码中执行。当进程处于内核态时,执行的内核代码会使用当前进程的内核栈。cpu可以访问内存的所有数据,包括外围设备,例如硬盘,网卡,cpu也可以将自己从一个程序切换到另一个程序。
用户态:
每个进程都有自己的内核栈。当进程在执行用户自己的代码时,则称其处于用户运行态。即此时处理器在特权级最低的(3级)用户代码中运行。当正在执行用户程序而突然被中断程序中断时,此时用户程序也可以象征性地称为处于进程的内核态。因为中断处理程序将使用当前进程的内核栈。这与处于内核态的进程的状态有些类似。只能受限的访问内存,且不允许访问外围设备,占用cpu的能力被剥夺,cpu资源可以被其他程序获取。
用户运行一个程序,该程序所创建的进程开始是运 行在用户态的,如果要执行文件操作,网络数据发送等操作,必须通过write,send等系统调用,这些系统调用会调用内核中的代码来完成操作,这时,必 须切换到Ring0,然后进入3GB-4GB中的内核地址空间去执行这些代码完成操作,完成后,切换回Ring3,回到用户态。这样,用户态的程序就不能 随意操作内核地址空间,具有一定的安全保护作用。
用户态程序将一些数据值放在寄存器中, 或者使用参数创建一个堆栈(stack frame), 以此表明需要操作系统提供的服务.用户态程序执行陷阱指令,CPU切换到内核态, 并跳到位于内存指定位置的指令, 这些指令是操作系统的一部分, 他们具有内存保护, 不可被用户态程序访问,这些指令称之为陷阱(trap)或者系统调用处理器(system call handler). 他们会读取程序放入内存的数据参数, 并执行程序请求的服务,系统调用完成后, 操作系统会重置CPU为用户态并返回系统调用的结果
PCB包括哪些内容(pcbdc)
PCB : 进程控制块
系统利用PCB来控制和管理进程,所以PCB是系统感知进程存在的唯一标志。进程与PCB是一一对应的。
通常PCB应包含如下一些信息:
1、进程标识符 name
每个进程都必须有一个唯一的标识符,可以是字符串,也可以是一个数字。
2、进程当前状态 status
说明进程当前所处的状态。为了管理的方便,系统设计时会将相同的状态的 进程组成一个队列,如就绪进程队列,等待进程则要根据等待的事件组成多个等待队列,如等待打印机队列。
3、进程相应的程序和数据地址以便把PCB与其程序和数据联系起来。
4、进程资源清单
列出所拥有的除CPU外的资源记录,如拥有的I/O设备, 打开的文件列表等。
5、进程优先级 priority
进程的优先级反映进程的紧迫程度,通常由用户指定和系统设置。
6、CPU现场保护区 cpustatus
当进程因某种原因不能继续占用CPU时(如等待打印机),释放CPU,这时就要将CPU的各种状态信息保护起来,为将来再次得到处理机恢复CPU的各种状态,继续运行。
7、进程同步与通信机制
用于实现进程间互斥、同步和通信所需的信号量等。
8、进程所在队列PCB的链接字
根据进程所处的现行状态,进程相应的PCB参加到不同队列中。PCB链接字指出该进程所在队列中下一个进程PCB的首地址。
9、与进程有关的其他信息
如进程记账信息,进程占用CPU的时间等。
进程间通信方式以及各自的优缺点(jctx)
1)管道(gddc)
管道分为有名管道和无名管道
无名管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用.进程的亲缘关系一般指的是父子关系。无明管道一般用于两个不同进程之间的通信。当一个进程创建了一个管道,并调用fork创建自己的一个子进程后,父进程关闭读管道端,子进程关闭写管道端,这样提供了两个进程之间数据流动的一种方式。
有名管道也是一种半双工的通信方式,但是它允许无亲缘关系进程间的通信。
无名管道:优点:简单方便;缺点:1)局限于单向通信2)只能创建在它的进程以及其有亲缘关系的进程之间;3)缓冲区有限;
有名管道:优点:可以实现任意关系的进程间的通信;缺点:1)长期存于系统中,使用不当容易出错;2)缓冲区有限
2)信号量(xhldc)
信号量是一个计数器,可以用来控制多个线程对共享资源的访问.,它不是用于交换大批数据,而用于多线程之间的同步.它常作为一种锁机制,防止某进程在访问资源时其它进程也访问该资源.因此,主要作为进程间以及同一个进程内不同线程之间的同步手段.
优点:可以同步进程;缺点:信号量有限
3)信号
信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生.
Linux系统中常用信号:
(1)SIGHUP:用户从终端注销,所有已启动进程都将收到该进程。系统缺省状态下对该信号的处理是终止进程。
(2)SIGINT:程序终止信号。程序运行过程中,按Ctrl+C键将产生该信号。
(3)SIGQUIT:程序退出信号。程序运行过程中,按Ctrl+\\键将产生该信号。
(4)SIGBUS和SIGSEGV:进程访问非法地址。
(5)SIGFPE:运算中出现致命错误,如除零操作、数据溢出等。
(6)SIGKILL:用户终止进程执行信号。shell下执行kill -9发送该信号。
(7)SIGTERM:结束进程信号。shell下执行kill 进程pid发送该信号。
(8)SIGALRM:定时器信号。
(9)SIGCLD:子进程退出信号。如果其父进程没有忽略该信号也没有处理该信号,则子进程退出后将形成僵尸进程。
4)消息队列
消息队列是消息的链表,存放在内核中并由消息队列标识符标识.消息队列克服了信号传递信息少,管道只能承载无格式字节流以及缓冲区大小受限等特点.消息队列是UNIX下不同进程之间可实现共享资源的一种机制,UNIX允许不同进程将格式化的数据流以消息队列形式发送给任意进程.对消息队列具有操作权限的进程都可以使用msget完成对消息队列的操作控制.通过使用消息类型,进程可以按任何顺序读信息,或为消息安排优先级顺序.
优点:可以实现任意进程间的通信,并通过系统调用函数来实现消息发送和接收之间的同步,无需考虑同步问题,方便;缺点:信息的复制需要额外消耗CPU的时间,不适宜于信息量大或操作频繁的场合
5)共享内存
共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问.共享内存是最快的IPC(进程间通信)方式,它是针对其它进程间通信方式运行效率低而专门设计的.它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步与通信.
优点:无须复制,快捷,信息量大;缺点:1)通信是通过将共无法实现享空间缓冲区直接附加到进程的虚拟地址空间中来实现的,因此进程间的读写操作的同步问题;2)利用内存缓冲区直接交换信息,内存的实体存在于计算机中,只能同一个计算机系统中的诸多进程共享,不方便网络通信
6)套接字:可用于不同进程间的进程通信(tjzdc)
优点:1)传输数据为字节级,传输数据可自定义,数据量小效率高;2)传输数据时间短,性能高;3) 适合于客户端和服务器端之间信息实时交互;4) 可以加密,数据安全性强
缺点:1) 需对传输的数据进行解析,转化成应用级的数据
线程间通信与同步(xctx)
共享内存
共享内存的并发模型里线程通过显示的同步即通过互斥实现对公共空间的读写,将需要共享的数据同步到公共的内存中,这样便实现了间接的通信。即共享内存是显示同步,隐式通信。
消息传递
消息传递模型即消息传递,线程间无公共内存,因为消息通信天然具有先后关系所以间接实现类数据的同步。所以消息传递模型是显示通信,隐式同步。
Java的并发采用的是共享内存模型,所以Java线程之间的通信是基于共享内存实现的。
操作系统中线程间的通信有两种情况(lxctx):
不同进程的线程之间进行通信,由于两个线程只能访问自己所属进程的地址空间和资源,故等同于进程间的通信。(上面已经介绍了)
同一个进程中的两个线程进行通信。
由于同一进程中的线程之间有共享内存,因此它们之间的通信是通过共享内存实现的。
线程的调度方式(xcdd)
抢占式调度
每个线程由系统分配CPU时间,线程本身无法控制使用多次CPU时间。好处是线程的执行时间是可控的,不会造成因为一个线程导致进程长时间阻塞问题。
协同式调度
线程自己控制CPU时间。并且当前线程执行完毕后需要通知系统切换另外一个线程。最主要的问题是线程的切换取决于线程本身,若线程存在Bug导致切换线程不成功则会一直阻塞。
守护线程是什么?(shxc)
守护线程(即daemon thread),是个服务线程,准确地来说就是服务其他的线程。
创建线程有哪几种方式?(xccj)
①. 继承Thread类创建线程类
定义Thread类的子类,并重写该类的run方法,该run方法的方法体就代表了线程要完成的任务。因此把run()方法称为执行体。
创建Thread子类的实例,即创建了线程对象。
调用线程对象的start()方法来启动该线程。
②. 通过Runnable接口创建线程类
定义runnable接口的实现类,并重写该接口的run()方法,该run()方法的方法体同样是该线程的线程执行体。
创建 Runnable实现类的实例,并依此实例作为Thread的target来创建Thread对象,该Thread对象才是真正的线程对象。
调用线程对象的start()方法来启动该线程。
③. 通过Callable和Future创建线程
创建Callable接口的实现类,并实现call()方法,该call()方法将作为线程执行体,并且有返回值。
创建Callable实现类的实例,使用FutureTask类来包装Callable对象,该FutureTask对象封装了该Callable对象的call()方法的返回值。
使用FutureTask对象作为Thread对象的target创建并启动新线程。
调用FutureTask对象的get()方法来获得子线程执行结束后的返回值。
有三个线程T1,T2,T3,如何保证顺序执行?(xcsxzx)
在多线程中有多种方法让线程按特定顺序执行,你可以用线程类的join()方法在一个线程中启动另一
个线程,另外一个线程完成该线程继续执行。为了确保三个线程的顺序你应该先启动最后一个(T3调
用T2,T2调用T1),这样T1就会先完成而T3最后完成。
说一下 runnable 和 callable 有什么区别?(rcqb)
Runnable接口中的run()方法的返回值是void,它做的事情只是纯粹地去执行run()方法中的代码而已;
Callable接口中的call()方法是有返回值的,是一个泛型,和Future、FutureTask配合可以用来获取异步执行的结果。
什么是Callable和Future?(cfqb)
Callable接口类似于Runnable,从名字就可以看出来了,但是Runnable不会返回结果,并且无法抛
出返回结果的异常,而Callable功能更强大一些,被线程执行后,可以返回值,这个返回值可以被
Future拿到,也就是说,Future可以拿到异步执行任务的返回值。可以认为是带有回调的
Runnable。
Future接口表示异步任务,是还没有完成的任务给出的未来结果。所以说Callable用于产生结果,
Future用于获取结果。
线程有哪些状态?(xczt)
线程通常都有五种状态,创建、就绪、运行、阻塞和死亡。
创建状态。在生成线程对象,并没有调用该对象的start方法,这是线程处于创建状态。
就绪状态。当调用了线程对象的start方法之后,该线程就进入了就绪状态,但是此时线程调度程序还没有把该线程设置为当前线程,此时处于就绪状态。在线程运行之后,从等待或者睡眠中回来之后,也会处于就绪状态。
运行状态。线程调度程序将处于就绪状态的线程设置为当前线程,此时线程就进入了运行状态,开始运行run函数当中的代码。
阻塞状态。线程正在运行的时候,被暂停,通常是为了等待某个时间的发生(比如说某项资源就绪)之后再继续运行。sleep,suspend,wait等方法都可以导致线程阻塞。
死亡状态。如果一个线程的run方法执行结束或者调用stop方法后,该线程就会死亡。对于已经死亡的线程,无法再使用start方法令其进入就绪
sleep() 和 wait() 有什么区别?(swqb)
sleep():方法是线程类(Thread)的静态方法,让调用线程进入睡眠状态,让出执行机会给其他线程,等到休眠时间结束后,线程进入就绪状态和其他线程一起竞争cpu的执行时间。因为sleep()
是static静态的方法,他不能改变对象的机锁,当一个synchronized块中调用了sleep()
方法,线程虽然进入休眠,但是对象的机锁没有被释放,其他线程依然无法访问这个对象。wait():wait()是Object类的方法,当一个线程执行到wait方法时,它就进入到一个和该对象相关的等待池,同时释放对象的机锁,使得其他线程能够访问,可以通过notify,notifyAll方法来唤醒等待的线程
notify()和 notifyAll()有什么区别?(nnqb)
notify可能会导致死锁,而notifyAll则不会
任何时候只有一个线程可以获得锁,也就是说只有一个线程可以运行synchronized 中的代码
使用notifyall,可以唤醒 所有处于wait状态的线程,使其重新进入锁的争夺队列中,而notify只能唤
醒一个。
wait() 应配合while循环使用,不应使用if,务必在wait()调用前后都检查条件,如果不满足,必须调
用notify()唤醒另外的线程来处理,自己继续wait()直至条件满足再往下执行。
notify() 是对notifyAll()的一个优化,但它有很精确的应用场景,并且要求正确使用。不然可能导致
死锁。正确的场景应该是 WaitSet中等待的是相同的条件,唤醒任一个都能正确处理接下来的事
项,如果唤醒的线程无法正确处理,务必确保继续notify()下一个线程,并且自身需要重新回到
WaitSet中.
sleep()和wait() 有什么区别?(slqb)
对于sleep()方法,我们首先要知道该方法是属于Thread类中的。而wait()方法,则是属于Object类
中的。
sleep()方法导致了程序暂停执行指定的时间,让出cpu给其他线程,但是他的监控状态依然保持
者,当指定的时间到了又会自动恢复运行状态。在调用sleep()方法的过程中,线程不会释放对象
锁。
当调用wait()方法的时候,线程会放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象调用
notify()方法后本线程才进入对象锁定池准备,获取对象锁进入运行状态。
线程的 run()和 start()有什么区别?(srqb)
每个线程都是通过某个特定Thread对象所对应的方法run()来完成其操作的,方法run()称为线程体。通过调用Thread类的start()方法来启动一个线程。
start()方法来启动一个线程,真正实现了多线程运行。这时无需等待run方法体代码执行完毕,可以直接继续执行下面的代码;
这时此线程是处于就绪状态, 并没有运行。 然后通过此Thread类调用方法run()来完成其运行状态,
这里方法run()称为线程体,它包含了要执行的这个线程的内容, Run方法运行结束, 此线程终止。然后CPU再调度其它线程。run()方法是在本线程里的,只是线程里的一个函数,而不是多线程的。
如果直接调用run(),其实就相当于是调用了一个普通函数而已,直接待用run()方法必须等待run()方法执行完毕才能执行下面的代码,所以执行路径还是只有一条,根本就没有线程的特征,所以在多线程执行时要使用start()方法而不是run()方法。
Java线程的生命周期和状态(xcsmzq)
新建状态:使用 new 关键字和 Thread 类或其子类建立一个线程对象后,该线程对象就处于新建状态。它保持这个状态直到程序start() 这个线程。
就绪状态:当线程对象调用了 start()方法之后,该线程就进入就绪状态。就绪状态的线程处于就绪队列中,要等待 JVM 里线程调度器的调度。
运行状态:如果就绪状态的线程获取 CPU 资源,就可以执行run(),此时线程便处于运行状态。处于运行状态的线程最为复杂,它可以变为阻塞状态、就绪状态和死亡状态。
阻塞状态:如果一个线程执行了
sleep(睡眠)、suspend(挂起)等方法,失去所占用资源之后,该线程就从运行状态进入阻塞状态。在睡眠时间已到或获得设备资源后可以重新进入就绪状态。
死亡状态:一个运行状态的线程完成任务或者其他终止条件发生时,该线程就切换到终止状态。
线程池工作原理(xccdc)
首先,线程池本质上是一种池化技术,而池化技术是一种资源复用的思想,比较常见的有连接池、内存池、对象池。而线程池里面复用的是线程资源,它的核心设计目标,我认为有两个:减少线程的频繁创建和销毁带来的性能开销,因为线程创建会涉及到 CPU 上下文切换、内存分配等工作。线程池本身会有参数来控制线程创建的数量,这样就可以避免无休止的创建线程带来的资源利用率过高的问题,起到了资源保护的作用。
其次,我简单说一下线程池里面的线程复用技术。因为线程本身并不是一个受控的技术,也就是说线程的生命周期时由任务运行的状态决定的,无法人为控制。所以为了实现线程的复用,线程池里面用到了阻塞队列,简单来说就是线程池里面的工作线程处于一直运行状态,它会从阻塞队列中去获取待执行的任务,一旦队列空了,那这个工作线程就会被阻塞,直到下次有新的任务进来。也就是说,工作线程是根据任务的情况实现阻塞和唤醒,从而达到线程复用的目的。最后,线程池里面的资源限制,是通过几个关键参数来控制的,分别是核心线程数、最大线程数。核心线程数表示默认长期存在的工作线程,而最大线程数是根据任务的情况动态创建的线程,主要是提高阻塞队列中任务的处理效率
使用线程池有哪些好处:
(1)发挥多核CPU的优势
现在的笔记本、台式机乃至商用的应用服务器至少也都是双核的,4核、8核甚至
16核的也都不少见,如果是单线程的程序,那么在双核CPU上就浪费了50%,在4核CPU上就浪费
了75%。单核CPU上所谓的"多线程"那是假的多线程,同一时间处理器只会处理一段逻辑,只不过
线程之间切换得比较快,看着像多个线程"同时"运行罢了。多核CPU上的多线程才是真正的多线
程,它能让你的多段逻辑同时工作,多线程,可以真正发挥出多核CPU的优势来,达到充分利用
CPU的目的。
(2)防止阻塞
从程序运行效率的角度来看,单核CPU不但不会发挥出多线程的优势,反而会因为在单核CPU上运
行多线程导致线程上下文的切换,而降低程序整体的效率。但是单核CPU我们还是要应用多线程,
就是为了防止阻塞。试想,如果单核CPU使用单线程,那么只要这个线程阻塞了,比方说远程读取
某个数据吧,对端迟迟未返回又没有设置超时时间,那么你的整个程序在数据返回回来之前就停止
运行了。多线程可以防止这个问题,多条线程同时运行,哪怕一条线程的代码执行读取数据阻塞,
也不会影响其它任务的执行。
(3)便于建模
这是另外一个没有这么明显的优点了。假设有一个大的任务A,单线程编程,那么就要考虑很多,
建立整个程序模型比较麻烦。但是如果把这个大的任务A分解成几个小任务,任务B、任务C、任务
D,分别建立程序模型,并通过多线程分别运行这几个任务,那就简单很多了。
当提交一个新任务到线程池时,具体的执行流程如下:(xcczxlc)
- 当我们提交任务,线程池会根据corePoolSize大小创建若干任务数量线程执行任务
- 当任务的数量超过corePoolSize数量,后续的任务将会进入阻塞队列阻塞排队
- 当阻塞队列也满了之后,那么将会继续创建(maximumPoolSize-corePoolSize)个数量的线程来
执行任务,如果任务处理完成,maximumPoolSize-corePoolSize额外创建的线程等待
keepAliveTime之后被自动销毁 - 如果达到maximumPoolSize,阻塞队列还是满的状态,那么将根据不同的拒绝策略对应处理
线程池的拒绝策略有哪些?(xccjjcl)
主要有4种拒绝策略:
- AbortPolicy:直接丢弃任务,抛出异常,这是默认策略
- CallerRunsPolicy:只用调用者所在的线程来处理任务
- DiscardOldestPolicy:丢弃等待队列中最旧的任务,并执行当前任务
- DiscardPolicy:直接丢弃任务,也不抛出异常
线程池核心线程数怎么设置呢?(xcchxxcs)
分为CPU密集型和IO密集型
CPU
这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1,比 CPU 核心数多出
来的一个线程是为了防止线程偶发的缺页中断,或者其它原因导致的任务暂停而带来的影响。一旦
任务暂停,CPU 就会处于空闲状态,而在这种情况下多出来的一个线程就可以充分利用 CPU 的空
闲时间。
IO密集型
这种任务应用起来,系统会用大部分的时间来处理 I/O 交互,而线程在处理 I/O 的时间段内不会占
用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用。因此在 I/O 密集型任务的应用中,我们
可以多配置一些线程,具体的计算方法是 : 核心线程数=CPU核心数量*2。
线程池参数?(xcccs)
一、corePoolSize 线程池核心线程大小
线程池中会维护一个最小的线程数量,即使这些线程处理空闲状态,他们也不会被销毁,除非设置了allowCoreThreadTimeOut。这里的最小线程数量即是corePoolSize。任务提交到线程池后,首先会检查当前线程数是否达到了corePoolSize,如果没有达到的话,则会创建一个新线程来处理这个任务。
二、maximumPoolSize 线程池最大线程数量
当前线程数达到corePoolSize后,如果继续有任务被提交到线程池,会将任务缓存到工作队列(后面会介绍)中。如果队列也已满,则会去创建一个新线程来出来这个处理。线程池不会无限制的去创建新线程,它会有一个最大线程数量的限制,这个数量即由maximunPoolSize指定。
三、keepAliveTime 空闲线程存活时间
一个线程如果处于空闲状态,并且当前的线程数量大于corePoolSize,那么在指定时间后,这个空闲线程会被销毁,这里的指定时间由keepAliveTime来设定
四、unit 空闲线程存活时间单位
keepAliveTime的计量单位
五、workQueue 工作队列(xccdl)
新任务被提交后,会先进入到此工作队列中,任务调度时再从队列中取出任务。jdk中提供了四种工作队列:
①ArrayBlockingQueue
基于数组的有界阻塞队列,按FIFO排序。新任务进来后,会放到该队列的队尾,有界的数组可以防止资源耗尽问题。当线程池中线程数量达到corePoolSize后,再有新任务进来,则会将任务放入该队列的队尾,等待被调度。如果队列已经是满的,则创建一个新线程,如果线程数量已经达到maxPoolSize,则会执行拒绝策略。
②LinkedBlockingQuene
基于链表的无界阻塞队列(其实最大容量为Interger.MAX),按照FIFO排序。由于该队列的近似无界性,当线程池中线程数量达到corePoolSize后,再有新任务进来,会一直存入该队列,而基本不会去创建新线程直到maxPoolSize(很难达到Interger.MAX这个数),因此使用该工作队列时,参数maxPoolSize其实是不起作用的。
③SynchronousQuene
一个不缓存任务的阻塞队列,生产者放入一个任务必须等到消费者取出这个任务。也就是说新任务进来时,不会缓存,而是直接被调度执行该任务,如果没有可用线程,则创建新线程,如果线程数量达到maxPoolSize,则执行拒绝策略。
④PriorityBlockingQueue
具有优先级的无界阻塞队列,优先级通过参数Comparator实现。
六、threadFactory 线程工厂
创建一个新线程时使用的工厂,可以用来设定线程名、是否为daemon线程等等
七、handler 拒绝策略
当工作队列中的任务已到达最大限制,并且线程池中的线程数量也达到最大限制,这时如果有新任务提交进来,该如何处理呢。这里的拒绝策略,就是解决这个问题的,jdk中提供了4中拒绝策略:
①CallerRunsPolicy
该策略下,在调用者线程中直接执行被拒绝任务的run方法,除非线程池已经shutdown,则直接抛弃任务。
②AbortPolicy
该策略下,直接丢弃任务,并抛出RejectedExecutionException异常。
③DiscardPolicy
该策略下,直接丢弃任务,什么都不做。
④DiscardOldestPolicy
该策略下,抛弃进入队列最早的那个任务,然后尝试把这次拒绝的任务放入队列
创建线程池有哪几种方式?(xcccj)
①. newFixedThreadPool(int nThreads)
创建一个固定长度的线程池,每当提交一个任务就创建一个线程,直到达到线程池的最大数量,这时线程规模将不再变化,当线程发生未预期的错误而结束时,线程池会补充一个新的线程。
②. newCachedThreadPool()
创建一个可缓存的线程池,如果线程池的规模超过了处理需求,将自动回收空闲线程,而当需求增加时,则可以自动添加新线程,线程池的规模不存在任何限制。
③. newSingleThreadExecutor()
这是一个单线程的Executor,它创建单个工作线程来执行任务,如果这个线程异常结束,会创建一个新的来替代它;它的特点是能确保依照任务在队列中的顺序来串行执行。
④. newScheduledThreadPool(int corePoolSize)
创建了一个固定长度的线程池,而且以延迟或定时的方式来执行任务,类似于Timer。
使用场景:
fixedThreadPool核心线程池等于最大线程池,当前的线程数能够比较稳定保证一个数。能够避免频繁回收线程和创建线程。故适用于处理cpu密集型的任务,确保cpu在长期被工作线程使用的情况下,尽可能少的分配线程,即适用长期的任务。
此方法的弊端是:
到了线程池最大容量后,如果有任务完成让出占用线程,那么此线程就会一直处于等待状态,而不会消亡,直到下一个任务再次占用该线程。这就可能会使用无界队列来存放排队任务,当大量任务超过线程池最大容量需要处理时,队列无线增大,使服务器资源迅速耗尽。
newCacehedThreadPool 的最大特点就是,线程数量不固定。只要有空闲线程空闲时间超过keepAliveTime,就会被回收。有新的任务,查看是否有线程处于空闲状态,如果不是就直接创建新的任务。故适用用于并发不固定的短期小任务。
此方法的弊端是:
线程池没有最大线程数量限制,如果大量的任务同时提交,可能导致创线程过多会而导致资源耗尽。
使用场景:
newSingleThreadExecutor 适用串行化任务,一个任务接着一个一个任务的执行。
ScheduledThreadPoolExecutor 适用于定时操作一些任务
虽然Executors为我们提供了构造线程池的便捷方法,对于服务器程序我们应该杜绝使用这些便捷方法,而是直接使用线程池ThreadPoolExecutor的构造方法,避免无界队列可能导致的OOM以及线程个数限制不当导致的线程数耗尽等问题。ExecutorCompletionService提供了等待所有任务执行结束的有效方式,如果要设置等待的超时时间,则可以通过CountDownLatch完成。
线程池都有哪些状态?(xcczt)
Running
会接受新任务,处理阻塞队列的任务
调用 Shutdown() 切换为Shutdown 状态
调用 shutdownNow() 切换到STOP状态
Shutdown
不接受新任务,会处理阻塞队列的任务
阻塞队列的任务为空,线程池中的线程执行的任务也为空,变为TIDYING
Stop
不接受新任务,不会处理阻塞队列的任务,而且中断正在执行的任务。
线程池中正在执行的任务为空,则变为TIDYING
TIDYING
表明所有任务执行完毕,记录任务的数量为0
Terminated() 执行完毕,进入TERMINATED状态
TERMINATED
线程池彻底终止
什么是阻塞队列?阻塞队列的实现原理是什么?如何使用阻
塞队列来实现生产者-消费者模型?(zsdl)
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。
这两个附加的操作是:在队列为空时,获取元素的线程会等待队列变为非空。当队列满时,存储元
素的线程会等待队列可用。
阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿
元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。
JDK7提供了7个阻塞队列。分别是:
ArrayBlockingQueue :一个由数组结构组成的有界阻塞队列。
LinkedBlockingQueue :一个由链表结构组成的有界阻塞队列。
PriorityBlockingQueue :一个支持优先级排序的无界阻塞队列。
DelayQueue:一个使用优先级队列实现的无界阻塞队列。
SynchronousQueue:一个不存储元素的阻塞队列。
LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。
LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
Java 5之前实现同步存取时,可以使用普通的一个集合,然后在使用线程的协作和线程同步可以实
现生产者,消费者模式,主要的技术就是用好,wait ,notify,notifyAll,sychronized这些关键字。而
在java 5之后,可以使用阻塞队列来实现,此方式大大简少了代码量,使得多线程编程更加容易,
安全方面也有保障。
BlockingQueue接口是Queue的子接口,它的主要用途并不是作为容器,而是作为线程同步的的工
具,因此他具有一个很明显的特性,当生产者线程试图向BlockingQueue放入元素时,如果队列已
满,则线程被阻塞,当消费者线程试图从中取出一个元素时,如果队列为空,则该线程会被阻塞,
正是因为它所具有这个特性,所以在程序中多个线程交替向BlockingQueue中放入元素,取出元
素,它可以很好的控制线程之间的通信。
阻塞队列使用最经典的场景就是socket客户端数据的读取和解析,读取数据的线程不断将数据放入
队列,然后解析线程不断从队列取数据解析。
execute方法与submit方法(esqb)
(1)execute没有返回值;而submit有返回值,方便返回执行结果。
(2)submit方便进行Exception处理,由于返回参数是future,如果执行期间抛出了异常,可以使用future.get()进行捕获。
线程池如何知道一个线程的任务已经执行完成(xcczxwc)
在线程池内部,当我们把一个任务丢给线程池去执行,线程池会调度工作线程来执行这个任务的 run 方法,run 方法正常结束,也就意味着任务完成了。
如果想在线程池外部去获得线程池内部任务的执行状态,有几种方法可以实现:
线程池提供了一个 isTerminated()方法,可以判断线程池的运行状态,我们可以循环判断 isTerminated()方法的返回结果来了解线程池的运行状态,一旦线程池的运行状态是 Terminated,意味着线程池中的所有任务都已经执行完了。想要通过这个方法获取状态的前提是,程序中主动调用了线程池的 shutdown()方法。在实际业务中,一般不会主动去关闭线程池,因此这个方法在实用性和灵活性方面都不是很好。
在线程池中,有一个 submit()方法,它提供了一个 Future 的返回值,我们通过Future.get()方法来获得任务的执行结果,当线程池中的任务没执行完之前,future.get()方法会一直阻塞,直到任务执行结束。因此,只要 future.get()方法正常返回,也就意味着传入到线程池中的任务已经执行完成了!
可以引入一个 CountDownLatch 计数器,它可以通过初始化指定一个计数器进行倒计时,其中有两个方法分别是 await()阻塞线程,以及 countDown()进行倒计时,一旦倒计时归零,所以被阻塞在 await()方法的线程都会被释放。基于这样的原理,我们可以定义一个 CountDownLatch 对象并且计数器为 1,接着在线程池代码块后面调用 await()方法阻塞主线程,然后,当传入到线程池中的任务执行完成后,调用 countDown()方法表示任务执行结束。最后,计数器归零 0,唤醒阻塞在 await()方法的线程。
多线程的好处,多线程应用场景:(dxcsycj)
多线程场景(dxcsycj):
1、后台任务,例如:定时向大量(100w以上)的用户发送邮件;
2、异步处理,例如:发微博、记录日志等;
3、分布式计算;
在 java 程序中怎么保证多线程的运行安全?(dxcaq)
线程安全就是说多线程访问同一段代码,不会产生不确定的结果。如果你的代码
在多线程下执行和在单线程下执行永远都能获得一样的结果,那么你的代码就是线程安全的。
线程安全在三个方面体现:
原子性,简单说就是相关操作不会中途被其他线程干扰,一般通过同步机制实现。
可见性,是一个线程修改了某个共享变量,其状态能够立即被其他线程知晓,通常被解释为将
线程本地状态反映到主内存上,volatile 就是负责保证可见性的。
有序性,是保证线程内串行语义,避免指令重排等。
什么是多线程中的上下文切换?(dxcsxwqh)
在上下文切换过程中,CPU会停止处理当前运行的程序,并保存当前程序运行的具体位置以便之后
继续运行。从这个角度来看,上下文切换有点像我们同时阅读几本书,在来回切换书本的同时我们
需要记住每本书当前读到的页码。
在程序中,上下文切换过程中的“页码”信息是保存在进程控制块(PCB)中的。PCB还经常被称
作“切换桢”(switchframe)。“页码”信息会一直保存到CPU的内存中,直到他们被再次使用。
上下文切换是存储和恢复CPU状态的过程,它使得线程执行能够从中断点恢复执行。上下文切换是
多任务操作系统和多线程环境的基本特征。
什么是Daemon线程?它有什么意义?(shxc htxc dnxc)
所谓后台(daemon)线程,也叫守护线程,是指在程序运行的时候在后台提供一种通用服务的线程,
并且这个线程并不属于程序中不可或缺的部分。
因此,当所有的非后台线程结束时,程序也就终止了,同时会杀死进程中的所有后台线程。反过来
说, 只要有任何非后台线程还在运行,程序就不会终止。
必须在线程启动之前调用setDaemon()方法,才能把它设置为后台线程。注意:后台进程在不执行
finally子句的情况下就会终止其run()方法。
比如:JVM的垃圾回收线程就是Daemon线程,Finalizer也是守护线程。
多线程锁的升级原理是什么?(dxcs)
在Java中,锁共有4种状态,级别从低到高依次为:无状态锁,偏向锁,轻量级锁和重量级锁状态,这几个状态会随着竞争情况逐渐升级。锁可以升级但不能降级。
多线程同步和互斥有几种实现方法,都是什么?(dxctbhc)
线程同步是指线程之间所具有的一种制约关系,一个线程的执行依赖另一个线程的消息,当它没有得到另一个线程的消息时应等待,直到消息到达时才被唤醒。
线程互斥是指对于共享的进程系统资源,在各单个线程访问时的排它性。当有若干个线程都要使用某一共享资源时,任何时刻最多只允许一个线程去使用,其它要使用该资源的线程必须等待,直到占用资源者释放该资源。线程互斥可以看成是一种特殊的线程同步。
线程间的同步方法大体可分为两类:用户模式和内核模式。顾名思义,内核模式就是指利用系统内核对象的单一性来进行同步,使用时需要切换内核态与用户态,
而用户模式就是不需要切换到内核态,只在用户态完成操作。
用户模式下的方法有:原子操作(例如一个单一的全局变量),临界区。内核模式下的方法有:事件,信号量,互斥量。
项目示例(xmsl):做的项目是一个审核类的项目,审核的数据需要推送给第三方监管系统,这只是一个很简单的对接,但是存在一个问题。我们需要推送的数据大概三十万条,但是第三方监管提供的接口只支持单条推送。可以估算一下,三十万条数据,一条数据按3秒算,大概需要250个小时。所以就考虑到引入多线程来进行并发操作,降低数据推送的时间,提高数据推送的实时性。 防止重复我们推送给第三方的数据肯定是不能重复推送的,必须要有一个机制保证各个线程推送数据的隔离。这里有两个思路:将所有数据取到集合(内存)中,然后进行切割,每个线程推送不同段的数据;第二种利用数据库分页的方式,每个线程取[start,limit]区间的数据推送,我们需要保证start的一致性,这里采用了第二种方式,因为考虑到可能数据量后续会继续增加,把所有数据都加载到内存中,可能会有比较大的内存占用。
失败机制我们还得考虑到线程推送数据失败的情况。
如果是自己的系统,我们可以把多线程调用的方法抽出来加一个事务,一个线程异常,整体回滚。但是是和第三方的对接,我们都没法做事务的,所以,我们采用了直接在数据库记录失败状态的方法,可以在后面用其它方式处理失败的数据。
线程同步的方式有哪些?(xctbfs)
1、临界区:当多个线程访问一个独占性共享资源时,可以使用临界区对象。拥有临界区的线程可以访问被保护起来的资源或代码段,其他线程若想访问,则被挂起,直到拥有临界区的线程放弃临界区为止,以此达到用原子方式操 作共享资源的目的。
2、事件:事件机制,则允许一个线程在处理完一个任务后,主动唤醒另外一个线程执行任务。
3、互斥量:互斥对象和临界区对象非常相似,只是其允许在进程间使用,而临界区只限制与同一进程的各个线程之间使用,但是更节省资源,更有效率。
4、信号量:当需要一个计数器来限制可以使用某共享资源的线程数目时,可以使用“信号量”对象。
区别:
互斥量与临界区的作用非常相似,但互斥量是可以命名的,也就是说互斥量可以跨越进程使用,但创建互斥量需要的资源更多,所以如果只为了在进程内部是用的话使用临界区会带来速度上的优势并能够减少资源占用量 。因为互斥量是跨进程的互斥量一旦被创建,就可以通过名字打开它。
互斥量,信号量,事件都可以被跨越进程使用来进行同步数据操作。
(xctbja)
- Java主要通过加锁的方式实现线程同步,而锁有两类,分别是synchronized和Lock。
- synchronized加在普通方法上,则锁是当前的实例(this)。加在静态方法上,则锁是当前类的Class对象。加在代码块上,则需要在关键字后面的小括号里,显式指定一个对象作为锁对象。
- 不同的锁对象,意味着不同的锁粒度,所以我们不应该无脑地将它加在方法前了事,尽管通常这可以解决问题。而是应该根据要锁定的范围,准确的选择锁对象,从而准确地确定锁的粒度,降低锁带来的性能开销。
- synchronized是比较早期的API,在设计之初没有考虑到超时机制、非阻塞形式,以及多个条件变量。若想通过升级的方式让synchronized支持这些相对复杂的功能,则需要大改它的语法结构,不利于兼容旧代码。因此,JDK的开发团队在1.5引入了Lock,并通过Lock支持了上述的功能。Lock支持的功能包括:支持响应中断、支持超时机制、支持以非阻塞的方式获取锁、支持多个条件变量(阻塞队列)。
- synchronized采用“CAS+Mark
Word”实现,为了性能的考虑,并通过锁升级机制降低锁的开销。在并发环境中,synchronized会随着多线程竞争的加剧,按照如下步骤逐步升级:无锁、偏向锁、轻量级锁、重量级锁。 - Lock则采用“CAS+volatile”实现,其实现的核心是AQS。AQS是线程同步器,是一个线程同步的基础框架,它基于模板方法模式。在具体的Lock实例中,锁的实现是通过继承AQS来实现的,并且可以根据锁的使用场景,派生出公平锁、不公平锁、读锁、写锁等具体的实现。
fail-safe 机制与 fail-fast 机制分别有什么作用(ffqb)
fail-safe 和 fail-fast,是多线程并发操作集合时的一种失败处理机制。
Fail-fast:表示快速失败,在集合遍历过程中,一旦发现容器中的数据被修改了,会立刻抛出 ConcurrentModificationException 异常,从而导致遍历失败,像这种情况。
定义一个 Map 集合,使用 Iterator 迭代器进行数据遍历,在遍历过程中,对集合数据做变更时,就会发生 fail-fast。java.util 包下的集合类都是快速失败机制的,常见的的使用 fail-fast 方式遍历的容
器有 HashMap 和 ArrayList 等。
Fail-safe,表示失败安全,也就是在这种机制下,出现集合元素的修改,不会抛出 ConcurrentModificationException。原因是采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。由于迭代时是对原集合的拷贝进行遍历,所以在遍历过程中对原集合所作的修改并不能被迭代器检测到.比如这种情况,定义了一个 CopyOnWriteArrayList,在对这个集合遍历过程中,对集合元素做修改后,不会抛出异常,但同时也不会打印出增加的元素。java.util.concurrent 包下的容器都是安全失败的,可以在多线程下并发使用,并发修改。常 见 的 的 使 用 fail-safe 方 式 遍 历 的 容 器 有 ConcerrentHashMap 和
CopyOnWriteArrayList 等。
什么是死锁?(ssdc)
死锁是指两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。是操作系统层面的一个错误,是进程死锁的简称,最早在
1965 年由 Dijkstra 在研究银行家算法时提出的.
例子1: 锁顺序引发的死锁:启用两个线程,一个调用leftRight()方法,一个调用rightLeft()方法,
并且这两个线程交错的执行,它们就会发生死锁。
避免死锁(bmss):比如支付场景中,x向y转钱,这个过程需要时原子性的,所以需要对金额的计算进行加锁。这个过程要对x与y的金额都要上锁,所以有两个锁。但是,可能有一个线程从x向y转账,一个线程从y向x转账,这样就形成了动态的死锁。
要避免这样动态锁的顺序造成的死锁问题,可以指定锁的顺序,使用Object.hashCode返回的值去决定先加那个锁,让每次锁的顺序都是一样的。比如前面的例子,不管是x向y转钱还是y向x转钱他们上锁的顺序都是一样的。可能都是先给x加锁。
例子2:单线程死锁:使用单线程的线程池,提交一个任务A到线程池,然后再执行A这个任务的过程中在给线程池提交一个任务B。由于是单线程的线程池,所以任务B的执行需要等待任务A执行完才能获得线程。但是A的执行完毕又依赖B,所以就形成了死锁。
怎么防止死锁?(fzss)
死锁的四个必要条件:
互斥条件:进程对所分配到的资源不允许其他进程进行访问,若其他进程访问该资源,只能等待,直至占有该资源的进程使用完成后释放该资源
请求和保持条件:进程获得一定的资源之后,又对其他资源发出请求,但是该资源可能被其他进程占有,此事请求阻塞,但又对自己获得的资源保持不放
不可剥夺条件:是指进程已获得的资源,在未完成使用之前,不可被剥夺,只能在使用完后自己释放
环路等待条件:是指进程发生死锁后,若干进程之间形成一种头尾相接的循环等待资源关系
这四个条件是死锁的必要条件,只要系统发生死锁,这些条件必然成立,而只要上述条件之 一不满足,就不会发生死锁。
理解了死锁的原因,尤其是产生死锁的四个必要条件,就可以最大可能地避免、预防和 解除死锁。
所以,在系统设计、进程调度等方面注意如何不让这四个必要条件成立,如何确 定资源的合理分配算法,避免进程永久占据系统资源。
此外,也要防止进程在处于等待状态的情况下占用资源。因此,对资源的分配要给予合理的规划。
ThreadLocal 是什么?有哪些使用场景?(tldc)
hreadLocal可以理解为线程本地变量,他会在每个线程都创建一个副本,那么在线程之间访问内部
副本变量就行了,做到了线程之间互相隔离,相比于synchronized的做法是用空间来换时间。
ThreadLocal有一个静态内部类ThreadLocalMap,ThreadLocalMap又包含了一个Entry数组,
Entry本身是一个弱引用,他的key是指向ThreadLocal的弱引用,Entry具备了保存key value键值对
的能力。
弱引用的目的是为了防止内存泄露,如果是强引用那么ThreadLocal对象除非线程结束否则始终无
法被回收,弱引用则会在下一次GC的时候被回收。
但是这样还是会存在内存泄露的问题,假如key和ThreadLocal对象被回收之后,entry中就存在key
为null,但是value有值的entry对象,但是永远没办法被访问到,同样除非线程结束运行。
但是只要ThreadLocal使用恰当,在使用完之后调用remove方法删除Entry对象,实际上是不会出
现这个问题的。经典的使用场景是为每个线程分配一个 JDBC 连接 Connection。这样就可以保证每个线程的都在各自的 Connection上进行数据库的操作,不会出现 A 线程关了 B线程正在使用的 Connection; 还有 Session 管理 等问题。
synchronized 和 volatile 的区别是什么?(svqb)
volatile本质是在告诉jvm当前变量在寄存器(工作内存)中的值是不确定的,需要从主存中读取;
synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住。volatile仅能使用在变量级别;synchronized则可以使用在变量、方法、和类级别的。
volatile仅能实现变量的修改可见性,不能保证原子性;而synchronized则可以保证变量的修改可见性和原子性。
volatile不会造成线程的阻塞;synchronized可能会造成线程的阻塞。
volatile标记的变量不会被编译器优化;synchronized标记的变量可以被编译器优化。
synchronized 和 Lock 有什么区别?(slqb)
Synchronized 是 Java 中的同步关键字,Lock 是 J.U.C 包中提供的接口,这个接口有很多实现类,其中就包括 ReentrantLock 重入锁
Synchronized 可以通过两种方式来控制锁的粒度:一种是把 synchronized 关键字修饰在方法层面,另一种是修饰在代码块上,并且我们可以通过 Synchronized 加锁对象的声明周期来控制锁的作用范围,比如锁对象是静态对象或者类对象,那么这个锁就是全局锁。
如果锁对象是普通实例对象,那这个锁的范围取决于这个实例的声明周期。
Lock 锁的粒度是通过它里面提供的 lock()和 unlock()方法决定的,包裹在这两个方法之间的代码能够保证线程安全性。而锁的作用域取决于 Lock 实例的生命周期。Lock 比 Synchronized 的灵活性更高,Lock 可以自主决定什么时候加锁,什么时候释放锁,只需要调用 lock()和 unlock()这两个方法就行,同时 Lock 还提供了非阻塞的竞争锁方法 tryLock()方法,这个方法通过返回 true/false 来告诉当前线程是否已经有其他线程正在使用锁。Synchronized 由于是关键字,所以它无法实现非阻塞竞争锁的方法,另外,Synchronized 锁的释放是被动的,就是当 Synchronized 同步代码块执行完以后或者代码出现异常时才会释放。
Lock 提供了公平锁和非公平锁的机制,公平锁(gpsdc)是指线程竞争锁资源时,如果已经有其他线程正在排队等待锁释放,那么当前竞争锁资源的线程无法插队。而非公平锁,就是不管是否有线程在排队等待锁,它都会尝试去竞争一次锁。
Synchronized 只提供了一种非公平锁的实现。
synchronized无法判断是否获取锁的状态,Lock可以判断是否获取到锁;
用synchronized关键字的两个线程1和线程2,如果当前线程1获得锁,线程2线程等待。如果线程1阻塞,线程2则会一直等待下去,而Lock锁就不一定会等待下去,如果尝试获取不到锁,线程可以不用一直等待就结束了;
synchronized的锁可重入、不可中断、非公平,而Lock锁可重入、可判断、可公平(两者皆可);
Lock锁适合大量同步的代码的同步问题,synchronized锁适合代码少量的同步问题。
synchronized 和 ReentrantLock 区别是什么?(srqb)
① 底层实现上来说
synchronized 是JVM层面的锁,是Java关键字,通过monitor对象来完成(monitorenter与monitorexit),对象只有在同步块或同步方法中才能调用wait/notify方法,ReentrantLock 是从jdk1.5以来(java.util.concurrent.locks.Lock)提供的API层面的锁。
synchronized 的实现涉及到锁的升级,具体为无锁、偏向锁、自旋锁、向OS申请重量级锁,
ReentrantLock 实现则是通过利用CAS(CompareAndSwap)自旋机制保证线程操作的原子性和volatile保证数据可见性以实现锁的功能。
② 是否可手动释放
synchronized 不需要用户去手动释放锁,synchronized 代码执行完后系统会自动让线程释放对锁的占用; ReentrantLock则需要用户去手动释放锁,如果没有手动释放锁,就可能导致死锁现象。一般通过lock()和unlock()方法配合try/finally语句块来完成,使用释放更加灵活。
③ 是否可中断
synchronized是不可中断类型的锁,除非加锁的代码中出现异常或正常执行完成; ReentrantLock则可以中断,可通过trylock(long timeout,TimeUnit unit)设置超时方法或者将lockInterruptibly()放到代码块中,调用interrupt方法进行中断。
④ 是否公平锁
synchronized为非公平锁 ReentrantLock则即可以选公平锁也可以选非公平锁,通过构造方法new ReentrantLock时传入boolean值进行选择,为空默认false非公平锁,true为公平锁。
SynchronizedMap 和 ConcurrentHashMap 有什么区别?(scqb)
SynchronizedMap 一次锁住整张表来保证线程安全,所以每次只能有一个线程来访为 map。ConcurrentHashMap 使用分段锁来保证在多线程下的性能。 ConcurrentHashMap 中则是一次锁住一个桶。ConcurrentHashMap 默认将 hash 表分为 16 个桶,诸如 get,put,remove 等常用操作只锁当前需要用到的桶。
这样,原来只能一个线程进入,现在却能同时有 16 个写线程执行,并发性能的提升是显而易见的。另外 ConcurrentHashMap 使用了一种不同的迭代方式。在这种迭代方式中,当 iterator 被创建后集合再发生改变就不再是抛出ConcurrentModificationException,取而代之的是在改变时 new 新的数据从而 不影响原有的数据 ,iterator 完成后再将头指针替换为新的数据 ,这样 iterator 线程可以使用原来老的数据,而写线程也可以并发的完成改变。
读写锁ReadWriteLock 是什么?(rkdc)
ReadWriteLock 是一个读写锁接口, ReentrantReadWriteLock 是 ReadWriteLock
接口的一个具体实现,实现了读写的分离,读锁是共享的,写锁是独占的,读和读之间不会互斥,读和写、写和读、 写和写之间才会互斥,提升了读写的性能。ReentrantLock 某些时候有局限。如果使用
ReentrantLock,可能本身是为了防止线程 A 在写数据、线程 B 在 读数据造成的数据不一致,但这样,如果线程 C 在读数据、线程 D 也在读数据, 读数据是不会改变数据的,没有必要加锁,但是还是加锁了,降低了程序的性能。 因为这个,才诞生了读写锁 ReadWriteLock。
说一下 atomic 的原理?(acdc)
Atomic包中的类基本的特性就是在多线程环境下,当有多个线程同时对单个(包括基本类型及引用类型)变量进行操作时,具有排他性,即当多个线程同时对该变量的值进行更新时,仅有一个线程能成功,而未成功的线程可以向自旋锁一样,继续尝试,一直等到执行成功。
Atomic系列的类中的核心方法都会调用unsafe类中的几个本地方法。我们需要先知道一个东西就是Unsafe类,全名为:sun.misc.Unsafe,这个类包含了大量的对C代码的操作,包括很多直接内存分配以及原子操作的调用,而它之所以标记为非安全的,是告诉你这个里面大量的方法调用都会存在安全隐患,需要小心使用,否则会导致严重的后果,例如在通过unsafe分配内存的时候,如果自己指定某些区域可能会导致一些类似C++一样的指针越界到其他进程的问题。
说一下volatile关键字(vedc)
特性: 被volatile修饰的共享变量,就具有了以下两点特性:
1)保证了不同线程对该变量操作的内存可见性,即一个线程修改了某个变量的值,这新值对
其他线程来说是立即可见的,volatile关键字会强制将修改的值立即写入主存。2) 禁止指令重排序;
不保证原子性(1、加入synchronized2、使用juc下的AtomicInteger)
如果把加入volatile关键字的代码和未加入volatile关键字的代码都生成汇编代码,会发现加入volatile关键字的代码会多出一个lock前缀指令。
volatile底层的实现机制是怎样的?
有volatile修饰的共享变量进行写操作的时候会多出Lock前缀的指令,该指令在多核处理器下会引发两件事情。 1. 将当前处理器缓存行数据刷写到系统主内存。 2. 这个刷写回主内存的操作会使其他CPU缓存的该共享变量内存地址的数据无效。
这样就保证了多个处理器的缓存是一致的,对应的处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器缓存行设置无效状态,当处理器对这个数据进行修改操作的时候会重新从主内存中把数据读取到缓存里。
volatile的使用场景1、修饰状态变量
2、单例模式的实现,双重检查锁定
说一下 synchronized 底层实现原理?(sddc)
synchronized关键字解决的是多个线程之间访问资源的同步性,synchronized关键字可以保证被它
修饰的方法或者代码块在任意时刻只能有一个线程执行。 另外,在 Java 早期版本中,
synchronized属于重量级锁,效率低下,因为监视器锁(monitor)是依赖于底层的操作系统的
Mutex Lock 来实现的,Java 的线程是映射到操作系统的原生线程之上的。如果要挂起或者唤醒一
个线程,都需要操作系统帮忙完成,而操作系统实现线程之间的切换时需要从用户态转换到内核
态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高,这也是为什么早期的
synchronized 效率低的原因。庆幸的是在 Java 6 之后 Java 官方对从 JVM 层面对synchronized 较
大优化,所以现在的 synchronized 锁效率也优化得很不错了。JDK1.6对锁的实现引入了大量的优
化,如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销。
说说自己是怎么使用 synchronized 关键字?(sdsy)
修饰实例方法: 作用于当前对象实例加锁,进入同步代码前要获得当前对象实例的锁 修饰静态方法:
也就是给当前类加锁,会作用于类的所有对象实例,因为静态成员不属于任何一个实例对象,是类
成员( static 表明这是该类的一个静态资源,不管new了多少个对象,只有一份)。所以如果一个
线程A调用一个实例对象的非静态 synchronized 方法,而线程B需要调用这个实例对象所属类的静
态 synchronized 方法,是允许的,不会发生互斥现象,因为访问静态 synchronized 方法占用的
锁是当前类的锁,而访问非静态 synchronized 方法占用的锁是当前实例对象锁。 修饰代码块: 指
定加锁对象,对给定对象加锁,进入同步代码库前要获得给定对象的锁。 总结: synchronized 关
键字加到 static 静态方法和 synchronized(class)代码块上都是是给 Class 类上锁。synchronized
关键字加到实例方法上是给对象实例上锁。尽量不要使用 synchronized(String a) 因为JVM中,字
符串常量池具有缓存功能!
synchronized的优化(sdyh)
优化机制包括自适应锁、自旋锁、锁消除、锁粗化、轻量级锁和偏向锁。
锁的状态从低到高依次为无锁->偏向锁->轻量级锁->重量级锁,升级的过程就是从低到高,降级在
一定条件也是有可能发生的。
自旋锁:由于⼤部分时候,锁被占⽤的时间很短,共享变量的锁定时间也很短,所有没有必要挂起线程,⽤户态和内核态的来回上下⽂切换严重影响性能。⾃旋的概念就是让线程执⾏⼀个忙循环,可以理解为就是啥也不⼲,防⽌从⽤户态转⼊内核态,⾃旋锁可以通过设置-XX:+UseSpining来开启,⾃旋的默认次数是10次,可以使⽤-XX:PreBlockSpin设置。
自适应锁:自适应锁就是自适应的自旋锁,自旋锁的时间不是固定时间,而是由前⼀次在同⼀个锁上的⾃旋时间和锁的持有者状态来决定。
锁消除:锁消除指的是JVM检测到⼀些同步的代码块,完全不存在数据竞争的场景,也就是不需要加锁,就会进⾏锁消除。
锁粗化:锁粗化指的是有很多操作都是对同⼀个对象进⾏加锁,就会把锁的同步范围扩展到整个操作序列之外。
偏向锁:当线程访问同步块获取锁时,会在对象头和栈帧中的锁记录⾥存储偏向锁的线程ID,之后这个线程再次进⼊同步块时都不需要CAS来加锁和解锁了,偏向锁会永远偏向第⼀个获得锁的线程,如果后续没有其他线程获得过这个锁,持有锁的线程就永远不需要进⾏同步,反之,当有其他线程竞争偏向锁时,持有偏向锁的线程就会释放偏向锁。可以⽤过设置-XX:+UseBiasedLocking开启偏向锁。
轻量级锁:JVM的对象的对象头中包含有⼀些锁的标志位,代码进⼊同步块的时候,JVM将会使⽤CAS⽅式来尝试获取锁,如果更新成功则会把对象头中的状态位标记为轻量级锁,如果更新失败,当前线程就尝试⾃旋来获得锁。
wait 和 notify 这个为什么要在synchronized 代码块中?(wnqb)
wait 和 notify 用来实现多线程之间的协调,wait 表示让线程进入到阻塞状态,notify 表示让阻塞的线程唤醒。wait 和 notify 必然是成对出现的,如果一个线程被 wait()方法阻塞,那么必然需要另外一个线程通过 notify()方法来唤醒这个被阻塞的线程,从而实现多线程之间的通信。
在多线程里面,要实现多个线程之间的通信,除了管道流以外,只能通过共享变量的方法来实现,也就是线程 t1 修改共享变量 s,线程 t2 获取修改后的共享变量 s,从而完成数据通信。
但是多线程本身具有并行执行的特性,也就是在同一时刻,多个线程可以同时执行。在这种情况下,线程 t2 在访问共享变量 s 之前,必须要知道线程 t1 已经修改过了共享变量 s,否则就需要等待。
同时,线程 t1 修改过了共享变量 S 之后,还需要通知在等待中的线程 t2。所以要在这种特性下要去实现线程之间的通信,就必须要有一个竞争条件控制线程在什么条件下等待,什么条件下唤醒。
而 Synchronized 同步关键字就可以实现这样一个互斥条件,也就是在通过共享变量来实现多个线程通信的场景里面,参与通信的线程必须要竞争到这个共享变量的锁资源,才有资格对共享变量做修改,修改完成后就释放锁,那么其他的线程就可以再次来竞争同一个共享变量的锁来获取修改后的数据,从而完成线程之前的通信。
所以这也是为什么 wait/notify 需要放在 Synchronized 同步代码块中的原因,有了 Synchronized 同步锁,就可以实现对多个通信线程之间的互斥,实现条件等待和条件唤醒。另外,为了避免 wait/notify 的错误使用,jdk 强制要求把 wait/notify 写在同步代码块里面,否则会抛IllegalMonitorStateException
最后,基于 wait/notify 的特性,非常适合实现生产者消费者的模型,比如说用wait/notify 来实现连接池就绪前的等待与就绪后的唤醒。
什么是AQS
简单说一下AQS,AQS全称为AbstractQueuedSychronizer,翻译过来应该是抽象队列同步器。
如果说java.util.concurrent的基础是CAS的话,那么AQS就是整个Java并发包的核心了,
ReentrantLock、CountDownLatch、Semaphore等等都用到了它。AQS实际上以双向队列的形式
连接所有的Entry,比方说ReentrantLock,所有等待的线程都被放在一个Entry中并连成双向队
列,前面一个线程使用ReentrantLock好了,则双向队列实际上的第一个Entry开始运行。
AQS定义了对双向队列所有的操作,而只开放了tryLock和tryRelease方法给开发者使用,开发者可
以根据自己的实现重写tryLock和tryRelease方法,以实现自己的并发功能。
AQS支持两种同步方式:1、独占式 2、共享式 这样方便使用者实现不同类型的同步组件,独占式如 ReentrantLock,共享式如Semaphore,CountDownLatch,组合式的如 ReentrantReadWriteLock。总之, AQS为使用提供了底层支撑,如何组装实现,开发人员可以自由发挥。
能谈一下 CAS 机制吗(casdc)
CAS 是 Java 中 Unsafe 类里面的方法,它的全称是 CompareAndSwap,比较并交换。它的主要功能是能够保证在多线程环境下,对于共享变量的修改的原子性。它包含三个操作数:
- 变量内存地址,V表示
- 旧的预期值,A表示
- 准备设置的新值,B表示
当执行CAS指令时,只有当V等于A时,才会用B去更新V的值,否则就不会执行更新操作。
CompareAndSwap 是一个 native 方法,就是先从内存地址中读取 state 的值,然后去比较,最后再修改。这个过程不管是在什么层面上实现,都会存在原子性问题。所以呢,CompareAndSwap 的底层实现中,在多核 CPU 环境下,会增加一个Lock 指令对缓存或者总线加锁,从而保证比较并替换这两个指令的原子性。
CAS 主要用在并发场景中,比较典型的使用场景有两个。
第一个是 J.U.C 里面 Atomic 的原子实现,比如 AtomicInteger,AtomicLong。
第 二 个 是 实 现 多 线 程 对 共 享 资 源 竞 争 的 互 斥 性 质 , 比 如 在 AQS 、
ConcurrentHashMap、ConcurrentLinkedQueue 等都有用到
CAS有什么缺点吗?(casqd)
ABA问题:ABA的问题指的是在CAS更新的过程中,当读取到的值是A,然后准备赋值的时候仍然是
A,但是实际上有可能A的值被改成了B,然后又被改回了A,这个CAS更新的漏洞就叫做ABA。只是
ABA的问题大部分场景下都不影响并发的最终效果。
Java中有AtomicStampedReference来解决这个问题,他加入了预期标志和更新后标志两个字段,
更新时不光检查值,还要检查当前的标志是否等于预期标志,全部相等的话才会更新。
循环时间长开销大:自旋CAS的方式如果长时间不成功,会给CPU带来很大的开销。
只能保证一个共享变量的原子操作:只对一个共享变量操作可以保证原子性,但是多个则不行,多
个可以通过AtomicReference来处理或者使用锁synchronized实现。
反射(103)
什么是Java反射机制?(fsdc)
反射主要是指程序可以访问、检测和修改它本身状态或行为的一种能力.JAVA 反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为 java 语言的反射机制。
应用场景:
使用JDBC时,如果要创建数据库的连接,则需要先通过反射机制加载数据库的驱动程序;
多数框架都支持注解/XML配置,从配置中解析出来的类是字符串,需要利用反射机制实例化;
面向切面编程(AOP)的实现方案,是在程序运行时创建目标对象的代理类,这必须由反射机制来实现。
反射之Field,Method的理解与应用(fmqb)
Field提供有关类或接口的单个字段的信息和动态访问。 反射的字段可以是类(静态)字段或实例字段。
Field允许在获取或设置访问操作期间扩展转换,但如果发生缩小转换,则抛出IllegalArgumentException 。Field就是通过hashcode和对象头中的数据偏移找到变量存贮地址,修改字节码文件
Method
方法提供有关类和接口上单一方法的信息和访问权限。 反射的方法可以是类方法或实例方法(包括抽象方法)。 方法允许在匹配实际参数以使用底层方法的形式参数进行IllegalArgumentException时发生扩展转换,但如果发生缩小转换,则会引发IllegalArgumentException
什么是 java 序列化?什么情况下需要序列化?(jaxlh)
序列化:将java对象转换为二进制序列(其中包含对象的类型、数据等信息),通过序列化流(ObjectOutputStream)把对象写入到文件中保存。
反序列化:将二进制序列重构为java对象,通过反序列化流(ObjectInputStream)把保存在文件中的二进制序列读出来使用。
jave对象想要实现序列化,则该类必须实现Serializable接口,在jvm中,由于类字节码文件进行加载的时候存在双亲委派机制,因此该类的父类也应该是可序列化的。什么情况下需要序列化:
a)当你想把的内存中的对象状态保存到一个文件中或者数据库中时候; b)当你想用套接字在网络上传送对象的时候;
c)当你想通过RMI传输对象的时候;
动态代理是什么?有哪些应用?(dtdl)
动态代理:
当想要给实现了某个接口的类中的方法,加一些额外的处理。比如说加日志,加事务等。可以给这个类创建一个代理,故名思议就是创建一个新的类,这个类不仅包含原来类方法的功能,而且还在原来的基础上添加了额外处理的新类。这个代理类并不是定义好的,是动态生成的。具有解耦意义,灵活,扩展性强。
动态代理的应用:
Spring的AOP
加事务
加权限
加日志
怎么实现动态代理?
首先必须定义一个接口,还要有一个InvocationHandler(将实现接口的类的对象传递给它)处理类。再有一个工具类Proxy(习惯性将其称为代理类,因为调用他的newInstance()可以产生代理对象,其实他只是一个产生代理对象的工具类)。利用到InvocationHandler,拼接代理类源码,将其编译生成代理类的二进制码,利用加载器加载,并将其实例化产生代理对象,最后返回。
静态代理和动态代理的区别,什么场景使用?(jdqb)
静态代理
显示声明代理对象,在编译期就生成了代理类
由程序员创建或特定工具自动生成源代码,再对其编译。在程序运行之前,代理类的类文件就已经被创建了
实现:一个公共接口、一个委托类、一个代理类
优点:简单、实用、效率高
缺点:由于静态代理在代码运行之前就已经存在代理类,因此对于每一个代理对象都需要建一个代理类去代理,当需要代理的对象很多时就需要创建很多的代理类,严重降低程序的可维护性。用动态代理就可以解决这个问题。
动态代理
在程序运行时通过反射机制动态创建代理类(平常我的业务代码中虽然几乎没有使用过动态代理,但是我工作中使用的Spring系列框架中的AOP,以及RPC框架中都用到了动态代理,以AOP为例,AOP通过动态代理对目标对象进行了增强,比如我们最常用的前置通知、后置通知等。)
优点:只需将被委托类作为参数传入即可,使用灵活;服务内容只需写在invoke方法中,减少了代码冗余
缺点:效率较低
基于JDK实现:通过JDK提供的工具方法Proxy.newProxyInstance动态构建全新的代理类(继承Proxy类,并持有InvocationHandler接口引用)字节码文件并实例化对象返回。由Java内部的反射机制来实例化代理对象,并代理的调用委托类方法
基于CGlib实现:基于继承被代理类生成代理子类,不用实现接口,只需被代理类为非final类,底层借用ASM字节码技术实现
基于AspectJ实现:修改目标类的字节,织入代理的字节,在程序编译的时候,插入动态代理的字节码,不会生成全新的class
基于Instrumentation实现:修改目标类的字节码,类装载的时候动态拦截,插入动态代理的字节码,不会生成全新的class,基于JavaAgent
对象拷贝(104)
为什么要使用克隆?
想对一个对象进行处理,又想保留原有的数据进行接下来的操作,就需要克隆了,Java语言中克隆针对的是类的实例。
如何实现对象克隆?(dxkl)
实现Cloneable接口并重写Object类中的clone()方法;
实现Serializable接口,通过对象的序列化和反序列化实现克隆,可以实现真正的深度克隆
深拷贝和浅拷贝区别是什么?(sqqb)
浅拷贝只是复制了对象的引用地址,两个对象指向同一个内存地址,所以修改其中任意的值,另一个值都会随之变化,这就是浅拷贝(例:assign())
深拷贝是将对象及值复制过来,两个对象修改其中任意的值另一个值不会改变,这就是深拷贝(例:JSON.parse()和JSON.stringify(),但是此方法无法复制函数类型)
Java Web(105)
jsp 和 servlet 有什么区别?
jsp经编译后就变成了Servlet.(JSP的本质就是Servlet,JVM只能识别java的类,不能识别JSP的代码,Web容器将JSP的代码编译成JVM能够识别的java类)
jsp更擅长表现于页面显示,servlet更擅长于逻辑控制。
Servlet中没有内置对象,Jsp中的内置对象都是必须通过HttpServletRequest对象,HttpServletResponse对象以及HttpServlet对象得到。
Jsp是Servlet的一种简化,使用Jsp只需要完成程序员需要输出到客户端的内容,Jsp中的Java脚本如何镶嵌到一个类中,由Jsp容器完成。而Servlet则是个完整的Java类,这个类的Service方法用于生成对客户端的响应。
jsp 有哪些内置对象?作用分别是什么?
JSP有9个内置对象:
request:封装客户端的请求,其中包含来自GET或POST请求的参数;
response:封装服务器对客户端的响应;
pageContext:通过该对象可以获取其他对象;
session:封装用户会话的对象;
application:封装服务器运行环境的对象;
out:输出服务器响应的输出流对象;
config:Web应用的配置对象;
page:JSP页面本身(相当于Java程序中的this);
exception:封装页面抛出异常的对象。
说一下 jsp 的 4 种作用域?(jspzyy)
JSP中的四种作用域包括page、request、session和application,具体来说:
page代表与一个页面相关的对象和属性。
request代表与Web客户机发出的一个请求相关的对象和属性。一个请求可能跨越多个页面,涉及多个Web组件;需要在页面显示的临时数据可以置于此作用域。
session代表与某个用户与服务器建立的一次会话相关的对象和属性。跟某个用户相关的数据应该放在用户自己的session中。
application代表与整个Web应用程序相关的对象和属性,它实质上是跨越整个Web应用程序,包括多个页面、请求和会话的一个全局作用域。
session 和 cookie 有什么区别?(scqb)
1、数据存储位置:cookie数据存放在客户的浏览器上,session数据放在服务器上。
2、安全性:cookie不是很安全,别人可以分析存放在本地的cookie并进行cookie欺骗,考虑到安全应当使用session。
3、服务器性能:session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,考虑到减轻服务器性能方面,应当使用cookie。
4、数据大小:单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
5、信息重要程度:可以考虑将登陆信息等重要信息存放为session,其他信息如果需要保留,可以放在cookie中。
对于敏感数据,应存放在session里,因为cookie不安全。
对于普通数据,优先考虑存放在cookie里,这样会减少对服务器资源的占用。
session与token区别(stqb)
session机制存在服务器压力增大,CSRF跨站伪造请求攻击,扩展性不强等问题;
session存储在服务器端,token存储在客户端
token提供认证和授权功能,作为身份认证,token安全性比session好;
session这种会话存储方式方式只适用于客户端代码和服务端代码运行在同一台服务器上,token适用于项目级的前后端分离(前后端代码运行在不同的服务器下)
会话cookie和持久cookie有什么区别?(ccqb)
如果 cookie 不包含到期日期,则可视为会话 cookie。 会话 cookie 存储在内存中,决不会写入磁盘。
当浏览器关闭时,cookie 将从此永久丢失。如果 cookie 包含到期日期,则可视为持久性 cookie。 在指定的到期日期,cookie 将从磁盘中删除。
说一下 session 的工作原理,session如何共享 ?(sndc)
其实session是一个存在服务器上的类似于一个散列表格的文件。里面存有我们需要的信息,在我们需要用的时候可以从里面取出来。类似于一个大号的map吧,里面的键存储的是用户的sessionid,用户向服务器发送请求的时候会带上这个sessionid。这时就可以从中取出对应的值了.session是依赖Cookie实现的。session是服务器端对象
session 是浏览器和服务器会话过程中,服务器分配的一块储存空间。服务器默认为浏览器在cookie中设置 sessionid,浏览器在向服务器请求过程中传输 cookie 包含 sessionid ,服务器根据 sessionid 获取出会话中存储的信息,然后确定会话的身份信息。
1、Java 集群之 session 共享
2、session 多服务器共享方案,还有一种方案就是使用一个固定的服务器专门保持 session,其他服务器共享
什么是Token(tndc)
Token是服务端生成的一串字符串,以作客户端进行请求的一个令牌,当第一次登录后,服务器生成一个Token便将此Token返回给客户端,以后客户端只需带上这个Token前来请求数据即可,无需再次带上用户名和密码。
使用Token的目的:Token的目的是为了减轻服务器的压力,减少频繁的查询数据库,使服务器更加健壮。
Token 是在服务端产生的。如果前端使用用户名/密码向服务端请求认证,服务端认证成功,那么在服务端会返回 Token 给前端。前端可以在每次请求的时候带上 Token 证明自己的合法地位
说一下 cookie 的工作原理?(cedc)
cookie是由Web服务器保存在用户浏览器上的小文件(key-value格式),包含用户相关的信息。客户端向服务器发起请求,如果服务器需要记录该用户状态,就使用response向客户端浏览器颁发一个Cookie。客户端浏览器会把Cookie保存起来。当浏览器再请求该网站时,浏览器把请求的网址连同该Cookie一同提交给服务器。服务器检查该Cookie,以此来辨认用户身份。
Cookie的传输流程(cecslc)
当在浏览器地址栏中键入了一个Web站点的URL,浏览器会向该Web站点发送一个读取网页的请求,并将结果在显示器上显示。这时该网页在你的电脑上寻找Amazon网站设置的Cookie文件,如果找到,浏览器会把Cookie文件中的数据连同前面输入的URL一同发送到Amazon服务器。服务器收到Cookie数据,就会在他的数据库中检索你的ID,你的购物记录、个人喜好等信息,并记录下新的内容,增加到数据库和Cookie文件中去。如果没有检测到Cookie或者你的Cookie信息与数据库中的信息不符合,则说明你是第一次浏览该网站,服务器的CGI程序将为你创建新的ID信息,并保存到数据库中。
Cookie是利用了网页代码中的HTTP头信息进行传递的,浏览器的每一次网页请求,都可以伴随Cookie传递,例如,浏览器的打开或刷新网页操作。服务器将Cookie添加到网页的HTTP头信息中,伴随网页数据传回到你的浏览器,浏览器会根据你电脑中的Cookie设置选择是否保存这些数据。如果浏览器不允许Cookie保存,则关掉浏览器后,这些数据就消失。Cookie在电脑上保存的时间是不一样的,这些都是由服务器的设置不同决定得。Cookie有一个Expires(有效期)属性,这个属性决定了Cookie的保存时间,服务器可以通过设定Expires字段的数值,来改变Cookie的保存时间。如果不设置该属性,那么Cookie只在浏览网页期间有效,关闭浏览器,这些Cookie自动消失,绝大多数网站属于这种情况。通常情况下,Cookie包含Server、Expires、Name、Value这几个字段,其中对服务器有用的只是Name和Value字段,Expires等字段的内容仅仅是为了告诉浏览器如何处理这些Cookies。
如果客户端禁止 cookie 能实现 session 还能用吗?
Cookie与 Session,一般认为是两个独立的东西,Session采用的是在服务器端保持状态的方案,而Cookie采用的是在客户端保持状态的方案。但为什么禁用Cookie就不能得到Session呢?因为Session是用Session
ID来确定当前对话所对应的服务器Session,而Session ID是通过Cookie来传递的,禁用Cookie相当于失去了Session ID,也就得不到Session了。假定用户关闭Cookie的情况下使用Session,其实现途径有以下几种:
设置php.ini配置文件中的“session.use_trans_sid = 1”,或者编译时打开打开了“–enable-trans-sid”选项,让PHP自动跨页传递Session ID。
手动通过URL传值、隐藏表单传递Session ID。
用文件、数据库等形式保存Session ID,在跨页过程中手动调用。
spring mvc 和 struts 的区别是什么?(ssqb)
拦截机制的不同
Struts2是类级别的拦截,每次请求就会创建一个Action,和Spring整合时Struts2的ActionBean注入作用域是原型模式prototype,然后通过setter,getter吧request数据注入到属性。Struts2中,一个Action对应一个request,response上下文,在接收参数时,可以通过属性接收,这说明属性参数是让多个方法共享的。Struts2中Action的一个方法可以对应一个url,而其类属性却被所有方法共享,这也就无法用注解或其他方式标识其所属方法了,只能设计为多例。
SpringMVC是方法级别的拦截,一个方法对应一个Request上下文,所以方法直接基本上是独立的,独享request,response数据。而每个方法同时又何一个url对应,参数的传递是直接注入到方法中的,是方法所独有的。处理结果通过ModeMap返回给框架。在Spring整合时,SpringMVC的Controller Bean默认单例模式Singleton,所以默认对所有的请求,只会创建一个Controller,有应为没有共享的属性,所以是线程安全的,如果要改变默认的作用域,需要添加@Scope注解修改。
Struts2有自己的拦截Interceptor机制,SpringMVC这是用的是独立的Aop方式,这样导致Struts2的配置文件量还是比SpringMVC大。
底层框架的不同
Struts2采用Filter(StrutsPrepareAndExecuteFilter)实现,SpringMVC(DispatcherServlet)则采用Servlet实现。Filter在容器启动之后即初始化;服务停止以后坠毁,晚于Servlet。Servlet在是在调用时初始化,先于Filter调用,服务停止后销毁。
性能方面
Struts2是类级别的拦截,每次请求对应实例一个新的Action,需要加载所有的属性值注入,SpringMVC实现了零配置,由于SpringMVC基于方法的拦截,有加载一次单例模式bean注入。所以,SpringMVC开发效率和性能高于Struts2。
配置方面
spring MVC和Spring是无缝的。从这个项目的管理和安全上也比Struts2高。
如何避免 sql注入?
PreparedStatement(简单又有效的方法)
使用正则表达式过滤传入的参数
字符串过滤
JSP中调用该函数检查是否包函非法字符
JSP页面判断代码
什么是 XSS攻击,如何避免?
XSS攻击又称CSS,全称Cross Site Script (跨站脚本攻击),其原理是攻击者向有XSS漏洞的网站中输入恶意的 HTML代码,当用户浏览该网站时,这段 HTML 代码会自动执行,从而达到攻击的目的。XSS 攻击类似于 SQL
注入攻击,SQL注入攻击中以SQL语句作为用户输入,从而达到查询/修改/删除数据的目的,而在xss攻击中,通过插入恶意脚本,实现对用户游览器的控制,获取用户的一些信息。
XSS是 Web 程序中常见的漏洞,XSS 属于被动式且用于客户端的攻击方式。XSS防范的总体思路是:对输入(和URL参数)进行过滤,对输出进行编码。
什么是 CSRF攻击,如何避免?
CSRF(Cross-site request forgery)也被称为 one-click attack或者 session riding,中文全称是叫跨站请求伪造。一般来说,攻击者通过伪造用户的浏览器的请求,向访问一个用户自己曾经认证访问过的网站发送出去,使目标网站接收并误以为是用户的真实操作而去执行命令。常用于盗取账号、转账、发送虚假消息等。攻击者利用网站对请求的验证漏洞而实现这样的攻击行为,网站能够确认请求来源于用户的浏览器,却不能验证请求是否源于用户的真实意愿下的操作行为。
如何避免:
- 验证 HTTP Referer 字段
- 使用验证码
- 在请求地址中添加token并验证
- 在HTTP 头中自定义属性并验证
异常(106)
throw 和 throws 的区别?(ttqb)
throws是用来声明一个方法可能抛出的所有异常信息,throws是将异常声明但是不处理,而是将异常往上传,谁调用我就交给谁处理。而throw则是指抛出的一个具体的异常类型。
final、finally、finalize 有什么区别?(fffqb)
final可以修饰类、变量、方法,修饰类表示该类不能被继承、修饰方法表示该方法不能被重写、修饰变量表示该变量是一个常量不能被重新赋值。
finally一般作用在try-catch代码块中,在处理异常的时候,通常我们将一定要执行的代码方法finally代码块中,表示不管是否出现异常,该代码块都会执行,一般用来存放一些关闭资源的代码。
finalize是一个方法,属于Object类的一个方法,而Object类是所有类的父类,该方法一般由垃圾回收器来调用,当我们调用System的gc()方法的时候,由垃圾回收器调用finalize(),回收垃圾。
try-catch-finally 中哪个部分可以省略?
catch 可以省略
更为严格的说法其实是:try只适合处理运行时异常,try+catch适合处理运行时异常+普通异常。也就是说,如果你只用try去处理普通异常却不加以catch处理,编译是通不过的,因为编译器硬性规定,普通异常如果选择捕获,则必须用catch显示声明以便进一步处理。而运行时异常在编译时没有如此规定,所以catch可以省略,你加上catch编译器也觉得无可厚非。
理论上,编译器看任何代码都不顺眼,都觉得可能有潜在的问题,所以你即使对所有代码加上try,代码在运行期时也只不过是在正常运行的基础上加一层皮。但是你一旦对一段代码加上try,就等于显示地承诺编译器,对这段代码可能抛出的异常进行捕获而非向上抛出处理。如果是普通异常,编译器要求必须用catch捕获以便进一步处理;如果运行时异常,捕获然后丢弃并且+finally扫尾处理,或者加上catch捕获以便进一步处理。
至于加上finally,则是在不管有没捕获异常,都要进行的“扫尾”处理。
try-catch-finally 中,如果 catch 中 return 了,finally 还会执行吗?
会执行,在 return 前执行。
常见的异常类有哪些?
NullPointerException:当应用程序试图访问空对象时,则抛出该异常。
SQLException:提供关于数据库访问错误或其他错误信息的异常。
IndexOutOfBoundsException:指示某排序索引(例如对数组、字符串或向量的排序)超出范围时抛出。
NumberFormatException:当应用程序试图将字符串转换成一种数值类型,但该字符串不能转换为适当格式时,抛出该异常。
FileNotFoundException:当试图打开指定路径名表示的文件失败时,抛出此异常。
IOException:当发生某种I/O异常时,抛出此异常。此类是失败或中断的I/O操作生成的异常的通用类。
ClassCastException:当试图将对象强制转换为不是实例的子类时,抛出该异常。
ArrayStoreException:试图将错误类型的对象存储到一个对象数组时抛出的异常。
IllegalArgumentException:抛出的异常表明向方法传递了一个不合法或不正确的参数。
ArithmeticException:当出现异常的运算条件时,抛出此异常。例如,一个整数“除以零”时,抛出此类的一个实例。
NegativeArraySizeException:如果应用程序试图创建大小为负的数组,则抛出该异常。
NoSuchMethodException:无法找到某一特定方法时,抛出该异常。
SecurityException:由安全管理器抛出的异常,指示存在安全侵犯。
UnsupportedOperationException:当不支持请求的操作时,抛出该异常。
RuntimeExceptionRuntimeException:是那些可能在Java虚拟机正常运行期间抛出的异常的超类。
网络(107)
http 响应码 301 和 302 代表的是什么?有什么区别?
301,302 都是HTTP状态的编码,都代表着某个URL发生了转移。
区别:
301 redirect: 301 代表永久性转移(Permanently Moved)。
302 redirect: 302 代表暂时性转移(Temporarily Moved )。
forward 和 redirect 的区别?(frqb)
Forward和Redirect代表了两种请求转发方式:直接转发和间接转发。
直接转发方式(Forward),客户端和浏览器只发出一次请求,Servlet、HTML、JSP或其它信息资源,由第二个信息资源响应该请求,在请求对象request中,保存的对象对于每个信息资源是共享的。
间接转发方式(Redirect)实际是两次HTTP请求,服务器端在响应第一次请求的时候,让浏览器再向另外一个URL发出请求,从而达到转发的目的。
简述 tcp 和 udp的区别?(tuqb)
TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接。
TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付。
TCP通过校验和,重传控制,序号标识,滑动窗口、确认应答实现可靠传输。如丢包时的重发控制,还可以对次序乱掉的分包进行顺序控制。
UDP具有较好的实时性,工作效率比TCP高,适用于对高速传输和实时性有较高的通信或广播通信。
每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信。 TCP对系统资源要求较多,UDP对系统资源要求较少。
TCP如何做到可靠的?(tcpkk)
在 TCP 中,传输报文都是通过建立的虚拟连接来进行传输,发送端传输的每一个 TCP 报文,都会对其进行编号(编号是由于网络传输的原因,发送的报文可能会乱序到达,因此需要根据编号对报文进行重排),并且开启一个计时器;当接收端收到报文后,并且通过校验和对收到的报文数据进行校验,若校验成功则会返回一个确认报文,告知发送端我已经成功收到该报文了;若发送端在计时器结束前仍未收到确认报文,则认为接收端接收失败,则会重传该报文;服务端若收到重复报文(根据编号发现已经是收到了),则会将该报文丢弃。
因此,从上面的机制可以知道,TCP 是通过重传、确认和校验和的方式来确保可靠。
应用场景:
什么时候应该使用TCP:
当对网络通讯质量有要求的时候,比如:整个数据要准确无误的传递给对方,这往往用于一些要求可靠的应用,比如HTTP、HTTPS、FTP等传输文件的协议,POP、SMTP等邮件传输的协议。
在日常生活中,常见使用TCP协议的应用如下:
浏览器,用的HTTP
FlashFXP,用的FTP
Outlook,用的POP、SMTP
Putty,用的Telnet、SSH
QQ文件传输
什么时候应该使用UDP:
当对网络通讯质量要求不高的时候,要求网络通讯速度能尽量的快,这时就可以使用UDP。
比如,日常生活中,常见使用UDP协议的应用如下:
QQ语音
QQ视频
TFTP
udp如何实现可靠传输(udpkk)
1、添加seq/ack机制,确保数据发送到对端
2、添加发送和接收缓冲区,主要是用户超时重传。
3、添加超时重传机制。
送端发送数据时,生成一个随机seq=x,然后每一片按照数据大小分配seq。
数据到达接收端后接收端放入缓存,并发送一个ack=x的包,表示对方已经收到了数据。
发送端收到了ack包后,删除缓冲区对应的数据。时间到后,定时任务检查是否需要重传数据。
TCP的首部:(tcpsb)
每一个TCP报文段分为首部和数据两部分,首部的各个字段都很好的体现了TCP的每个功能。TCP报文段首部的前20个字节是固定的,后面有4*n(整数)个字节是根据需要可选的,所以TCP首部的最小长度是20字节。首部字段分别是:源端口、目的端口、序号、确认号、数据偏移、保留、紧急URG、确认ACK、推送PSH、复位RST、同步SYN、终止FIN、窗口、检验和、紧急指针、选项。
- 源端口:占2字节。
- 目的端口:占2字节。
- 序号:占4字节。序号范围是[0,223-1],共223(4 294 967
296)个序号。当序号达到2^23-1时候,下一个序号就回到0。TCP是面向字节流的,在一个TCP连接中传送的字节流的每一个字节都按顺序编号。整个TCP的起始序号必须在建立时确认,首部中的序号字段指的是这个报文段所发送的数据的第一个字节的序号。例如报文序号是101,携带的数据共100个字节,所以这个报文的第一个字节序号是101,最后一个字节的序号是200。下一个报文段就从201开始。 - 确认号:占4字节。是希望收对方下一个报文段的第一个数据字节的序号。例如序号中讲的,序号就是201。
- 数据偏移:占4位。指出TCP数据的起始位置和TCP报文段的起始处相差多少。也可以理解为数据偏移就是TCP首部字段的长度。
- 保留:占6位。保留为以后使用,当前置为0。
- 紧急URG:当URG=1时,说明紧急指针字段有效。告诉系统这个报文中有紧急的数据,应该尽快处理,优先级最高。
- 确认ACK:仅当ACK=1时,确认号字段才有效。当ACK=0时,确认号无效。TCP中有规定在TCP连接建立之后,所有传送的报文段ACK都必须为1。
- 推送PSH:发送方将PSH置为1后,表示当前命令之后希望收到对方的相应,推送很少用,不做深究。
- 复位RST:当RST=1时,表示TCP中出现严重的差错,必须释放连接然后再重新建立连接。RST=1还可以用来拒绝一个恶意的报文段。
- 同步SYN:在连接建立时用来同步序号。当SYN=1并且ACK=0时,表示这是一个连接请求报文段。若对方同意连接,就应该在响应报文中使SYN=1并且ACK=1。所以SYN=1表示这是一个连接请求或者连接接受报文。
- 终止FIN:用来释放一个TCP连接。当FIN=1时,表示报文段的发送方的数据已经发送完毕,要求释放连接。
- 窗口:占2字节。指的是发送这个报文段那方的接收窗口。窗口值告诉对方从确认号算起,接收方目前允许对方发送的数据量,因为接收方的数据缓存空间是有限的。
- 检验和:占2字节。检验和字段的检查范围包括首部和数据两个部分。和UDP一样需要在首部之前添加12字节的伪首部
- 紧急指针:占2字节。只有URG=1时才有用,表示这个报文段中紧急数据的字节数。
选项:长度可变,最长可达40字节,当没有选项时,TCP首部长度就是20字节。
UDP的首部:(udpsb)
首部字段很简单,只有8个字节,由4个字段组成,每个字段的长度都是2个字节。
UDP报头结构:携带数据大小长度 - 8
1.源端口号:在需要对方回信时选用,不需要时可全用0
2.目的端口号:在终点交付时使用
3.长度:UDP用户数据报的长度,最小值是8
4.检验和:检测UDP用户数据报在传输中是否有错,有错就丢弃
浏览器输入一个url到整个页面显示出来经历了哪些过程?(urldc)
1. 在浏览器中输入url
用户输入url,例如http://www.baidu.com。其中http为协议,www.baidu.com为网络地址,及指出需要的资源在那台计算机上。一般网络地址可以为域名或IP地址,此处为域名。使用域名是为了方便记忆,但是为了让计算机理解这个地址还需要把它解析为IP地址。
2.应用层DNS解析域名
客户端先检查本地是否有对应的IP地址,若找到则返回响应的IP地址。若没找到则请求上级DNS服务器,直至找到或到根节点。
3.应用层客户端发送HTTP请求
HTTP请求包括请求报头和请求主体两个部分,其中请求报头包含了至关重要的信息,包括请求的方法(GET / POST)、目标url、遵循的协议(http / https / ftp…),返回的信息是否需要缓存,以及客户端是否发送cookie等。
4.传输层TCP传输报文
位于传输层的TCP协议为传输报文提供可靠的字节流服务。它为了方便传输,将大块的数据分割成以报文段为单位的数据包进行管理,并为它们编号,方便服务器接收时能准确地还原报文信息。TCP协议通过“三次握手”等方法保证传输的安全可靠。
5.网络层IP协议查询MAC地址
IP协议的作用是把TCP分割好的各种数据包传送给接收方。而要保证确实能传到接收方还需要接收方的MAC地址,也就是物理地址。IP地址和MAC地址是一一对应的关系,一个网络设备的IP地址可以更换,但是MAC地址一般是固定不变的。ARP协议可以将IP地址解析成对应的MAC地址。当通信的双方不在同一个局域网时,需要多次中转才能到达最终的目标,在中转的过程中需要通过下一个中转站的MAC地址来搜索下一个中转目标。
6.数据到达数据链路层
在找到对方的MAC地址后,就将数据发送到数据链路层传输。这时,客户端发送请求的阶段结束
7.服务器接收数据
接收端的服务器在链路层接收到数据包,再层层向上直到应用层。这过程中包括在运输层通过TCP协议讲分段的数据包重新组成原来的HTTP请求报文。
8.服务器响应请求
服务接收到客户端发送的HTTP请求后,查找客户端请求的资源,并返回响应报文,响应报文中包括一个重要的信息——状态码。状态码由三位数字组成,其中比较常见的是200 OK表示请求成功。301表示永久重定向,即请求的资源已经永久转移到新的位置。在返回301状态码的同时,响应报文也会附带重定向的url,客户端接收到后将http请求的url做相应的改变再重新发送。404 not found 表示客户端请求的资源找不到。
9.服务器返回相应文件
请求成功后,服务器会返回相应的HTML文件。接下来就到了页面的渲染阶段了。
tcp 为什么要三次握手,两次不行吗?为什么?(scws)
为了实现可靠数据传输, TCP 协议的通信双方, 都必须维护一个序列号, 以标识发送出去的数据包中, 哪些是已经被对方收到的。
三次握手的过程即是通信双方相互告知序列号起始值, 并确认对方已经收到了序列号起始值的必经步骤。如果只是两次握手, 至多只有连接发起方的起始序列号能被确认, 另一方选择的序列号则得不到确认。
TCP三次握手、四次挥手(scws)
三次握手:
“三次握手”的过程是,发送端先发送一个带有SYN(synchronize)标志的数据包给接收端,在一定的延迟时间内等待接收的回复。接收端收到数据包后,传回一个带有SYN/ACK标志的数据包以示传达确认信息。接收方收到后再发送一个带有ACK标志的数据包给接收端以示握手成功。在这个过程中,如果发送端在规定延迟时间内没有收到回复则默认接收方没有收到请求,而再次发送,直到收到回复为止。
第一次握手:建立连接时,客户端发送syn包(syn=x)到服务器,并进入SYN_SENT状态,等待服务器确认;SYN:同步序列编号。
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=x+1),同时自己也发送一个SYN包(syn=y),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=y+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手。
> 四次挥手:
1)客户端进程发出连接释放报文,并且停止发送数据。释放数据报文首部,FIN=1,其序列号为seq=u,此时,客户端进入FIN-WAIT-1(终止等待1)状态。
TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。
2)服务器收到连接释放报文,发出确认报文,ACK=1,ack=u+1,并且带上自己的序列号seq=v,此时,服务端就进入了CLOSE-WAIT(关闭等待)状态。TCP服务器通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个状态还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。
3)客户端收到服务器的确认请求后,此时,客户端就进入FIN-WAIT-2(终止等待2)状态,等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最后的数据)。
4)服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,FIN=1,ack=u+1,由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为seq=w,此时,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。
5)客户端收到服务器的连接释放报文后,必须发出确认,ACK=1,ack=w+1,而自己的序列号是seq=u+1,此时,客户端就进入了TIME-WAIT(时间等待)状态。注意此时TCP连接还没有释放,必须经过2∗∗MSL(最长报文段寿命)的时间后,当客户端撤销相应的TCB后,才进入CLOSED状态。
6)服务器只要收到了客户端发出的确认,立即进入CLOSED状态。同样,撤销TCB后,就结束了这次的TCP连接。可以看到,服务器结束TCP连接的时间要比客户端早一些。
TIME_WAIT和CLOSE_WAIT的区别(tcqb)
TIME_WAIT
四次挥手时,先发送FIN报文就会处于TIME_WAIT状态,这个是为了处理第三次挥手时,对方没有收到第四次挥手,从而多次发送第三次挥手(FIN报文)的情况,经过2MSL之后这个状态就会结束。一般的话,是客户端先向服务器发送FIN报文,则就是客户端处于TIME_wait状态。如果是服务器先发送FIN报文,会出现问题,先发送的就会处于那个TIME_WAIT的状态。服务器断开连接后,重启,会有一段时间重启不上,也就是那个bind()函数出错,得隔一段时间才能恢复,这个情况也可以设置一个TCP的可选项来关掉这个TIME_WAIT状态。
CLOSE_WAIT
这个是被动关闭连接方才有的状态。被动方收到FIN报文会立即返回ACK报文表示已接收到断开请求。
如果被动关闭连接方还有数据要发送就会进入CLOSE_WAIT状态。
说一下 tcp粘包是怎么产生的?
①. 发送方产生粘包
采用TCP协议传输数据的客户端与服务器经常是保持一个长连接的状态(一次连接发一次数据不存在粘包),双方在连接不断开的情况下,可以一直传输数据;但当发送的数据包过于的小时,那么TCP协议默认的会启用Nagle算法,将这些较小的数据包进行合并发送(缓冲区数据发送是一个堆压的过程);这个合并过程就是在发送缓冲区中进行的,也就是说数据发送出来它已经是粘包的状态了。
②. 接收方产生粘包接收方采用TCP协议接收数据时的过程是这样的:数据到底接收方,从网络模型的下方传递至传输层,传输层的TCP协议处理是将其放置接收缓冲区,然后由应用层来主动获取(C语言用recv、read等函数);这时会出现一个问题,就是我们在程序中调用的读取数据函数不能及时的把缓冲区中的数据拿出来,而下一个数据又到来并有一部分放入的缓冲区末尾,等我们读取数据时就是一个粘包。(放数据的速度 应用层拿数据速度)
IP协议的首部结构 (ipsb)
首部协议一共是20个字节(固定)
第一个4字节: 版本号;首部长度; 服务类型;总长度;
第二个4字节:标识;标志;片偏移;
第三个4字节:生存时间;协议;校验和;
第四个4字节:源ip地址;
第五个4字节:目的ip地址;
OSI 的七层模型都有哪些?(qcmx)
应用层:网络服务与最终用户的一个接口。HTTP、FTP、DNS、SMTP、TELNET
表示层:数据的表示、安全、压缩。ASCII、PNG、JPEG
会话层:建立、管理、终止会话。SSL、TLS传输安全协议、RPC
传输层:定义传输数据的协议端口号,以及流控和差错校验。TCP、UDP
网络层:进行逻辑地址寻址,实现不同网络之间的路径选择。IP、ICMP、ARP
数据链路层:建立逻辑连接、进行硬件地址寻址、差错校验等功能。点对点协议(PPP)、广播协议(CSMA/CD)、以太网协议
物理层:建立、维护、断开物理连接。WIFI协议、蓝牙连接协议、USB接口协议
TCP/IP 四层模型(scmx)
数据链路层,也有称作网络访问层、网络接口层。他包含了OSI模型的物理层和数据链路层,把电脑连接起来
网络层,也叫做IP层,处理IP数据包的传输、路由,建立主机间的通信
传输层,就是为两台主机设备提供端到端的通信
应用层,包含OSI的会话层、表示层和应用层,提供了一些常用的协议规范,比如FTP、SMPT、HTTP等
get 和 post 请求有哪些区别?(gpqb)
- Get是不安全的,因为在传输过程,数据被放在请求的URL中;Post的所有操作对用户来说都是不可见的。
但是这种做法也不时绝对的,大部分人的做法也是按照上面的说法来的,但是也可以在get请求加上 request body,给
post请求带上 URL 参数。 - Get请求提交的url中的数据最多只能是2048字节,这个限制是浏览器或者服务器给添加的,http协议并没有对url长度进行限制,目的是为了保证服务器和浏览器能够正常运行,防止有人恶意发送请求。Post请求则没有大小限制。
- Get限制Form表单的数据集的值必须为ASCII字符;而Post支持整个ISO10646字符集。
- Get执行效率却比Post方法好。Get是form提交的默认方法。
- GET产生一个TCP数据包;POST产生两个TCP数据包。 对于GET方式的请求,浏览器会把http
header和data一并发送出去,服务器响应200(返回数据); 而对于POST,浏览器先发送header,服务器响应100
continue,浏览器再发送data,服务器响应200 ok(返回数据)。
IP数据报文结构解析(ipbw)
IP包总长(Total Length):长度16比特。 以字节为单位计算的IP包的长度 (包括头部和数据),所以IP包最大长度65535字节。
标识符(Identifier):长度16比特。该字段和Flags和Fragment Offest字段联合使用,对较大的上层数据包进行分段(fragment)操作。路由器将一个包拆分后,所有拆分开的小包被标记相同的值,以便目的端设备能够区分哪个包属于被拆分开的包的一部分。
标记(Flags):长度3比特。该字段第一位不使用。第二位是DF(Don’t Fragment)位,DF位设为1时表明路由器不能对该上层数据包分段。如果一个上层数据包无法在不分段的情况下进行转发,则路由器会丢弃该上层数据包并返回一个错误信息。第三位是MF(More Fragments)位,当路由器对一个上层数据包分段,则路由器会在除了最后一个分段的IP包的包头中将MF位设为1。
片偏移(Fragment Offset):长度13比特。表示该IP包在该组分片包中位置,接收端靠此来组装还原IP包。
生存时间(TTL):长度8比特。当IP包进行传送时,先会对该字段赋予某个特定的值。当IP包经过每一个沿途的路由器的时候,每个沿途的路由器会将IP包的TTL值减少1。如果TTL减少为0,则该IP包会被丢弃。这个字段可以防止由于路由环路而导致IP包在网络中不停被转发。
协议(Protocol):长度8比特。标识了上层所使用的协议。以下是比较常用的协议号:
1 ICMP
2 IGMP
6 TCP
17 UDP
88 IGRP
89 OSPF
头部校验(Header Checksum):长度16位。用来做IP头部的正确性检测,但不包含数据部分。 因为每个路由器要改变TTL的值,所以路由器会为每个通过的数据包重新计算这个值。
起源和目标地址(Source and Destination Addresses):这两个地段都是32比特。标识了这个IP包的起源和目标地址。要注意除非使用NAT,否则整个传输的过程中,这两个地址不会改变。
什么是对称加密与非对称加密(jmdc)
对称密钥加密是指加密和解密使用同一个密钥的方式,这种方式存在的最大问题就是密钥发送问题,即如何安全地将密钥发给对方;
而非对称加密是指使用一对非对称密钥,即公钥和私钥,公钥可以随意发布,但私钥只有自己知道。发送密文的一方使用对方的公钥进行加密处理,对方接收到加密信息后,使用自己的私钥进行解密。
由于非对称加密的方式不需要发送用来解密的私钥,所以可以保证安全性;但是和对称加密比起来,非常的慢
如何实现跨域?(kydc)
方式一:图片ping或script标签跨域
图片ping常用于跟踪用户点击页面或动态广告曝光次数。
script标签可以得到从其他来源数据,这也是JSONP依赖的根据。
方式二:JSONP跨域
JSONP(JSON with Padding)是数据格式JSON的一种“使用模式”,可以让网页从别的网域要数据。根据 XmlHttpRequest 对象受到同源策略的影响,而利用
只能使用Get请求
不能注册success、error等事件监听函数,不能很容易的确定JSONP请求是否失败
JSONP是从其他域中加载代码执行,容易受到跨站请求伪造的攻击,其安全性无法确保
方式三:CORS
Cross-Origin Resource Sharing(CORS)跨域资源共享是一份浏览器技术的规范,提供了 Web 服务从不同域传来沙盒脚本的方法,以避开浏览器的同源策略,确保安全的跨域数据传输。现代浏览器使用CORS在API容器如XMLHttpRequest来减少HTTP请求的风险来源。
方式四:window.name+iframe
方式五:window.postMessage()
HTML5新特性,可以用来向其他所有的 window 对象发送消息。需要注意的是我们必须要保证所有的脚本执行完才发送 MessageEvent,如果在函数执行的过程中调用了它,就会让后面的函数超时无法执行。
方式六:修改document.domain跨子域
前提条件:这两个域名必须属于同一个基础域名!而且所用的协议,端口都要一致,否则无法利用document.domain进行跨域,所以只能跨子域
方式七:WebSocket
WebSocket protocol 是HTML5一种新的协议。它实现了浏览器与服务器全双工通信,同时允许跨域通讯,是server push技术的一种很棒的实现。相关文章,请查看:WebSocket、WebSocket-SockJS
需要注意:WebSocket对象不支持DOM 2级事件侦听器,必须使用DOM 0级语法分别定义各个事件。
方式八:代理
同源策略是针对浏览器端进行的限制,可以通过服务器端来解决该问题
说一下 JSONP 实现原理?
jsonp 即json+padding,动态创建script标签,利用script标签的src属性可以获取任何域下的js脚本,通过这个特性(也可以说漏洞),服务器端不在返货json格式,而是返回一段调用某个函数的js代码,在src中进行了调用,这样实现了跨域。
http和https的区别(hhqb)
1、HTTPS 协议需要到 CA (Certificate Authority,证书颁发机构)申请证书,一般免费证书较少,因而需要一定费用。(以前的网易官网是http,而网易邮箱是 https 。)
2、HTTP 是超文本传输协议,信息是明文传输,HTTPS 则是具有安全性的 SSL 加密传输协议。
3、HTTP 和 HTTPS 使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4、HTTP 的连接很简单,是无状态的。HTTPS 协议是由 SSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议,比 HTTP 协议安全。(无状态的意思是其数据包的发送、传输和接收都是相互独立的。无连接的意思是指通信双方都不长久的维持对方的任何信息。)
HTTP 原理:(hpdc)
① 客户端的浏览器首先要通过网络与服务器建立连接,该连接是通过 TCP 来完成的,一般 TCP 连接的端口号是80。 建立连接后,客户机发送一个请求给服务器,请求方式的格式为:统一资源标识符(URI)、协议版本号,后边是 MIME 信息包括请求修饰符、客户机信息和许可内容。
② 服务器接到请求后,给予相应的响应信息,其格式为一个状态行,包括信息的协议版本号、一个成功或错误的代码,后边是 MIME 信息包括服务器信息、实体信息和可能的内容。
HTTPS原理(hsdc):是以安全为目标的 HTTP 通道,是 HTTP 的安全版。HTTPS 的安全基础是 SSL。SSL 协议位于 TCP/IP 协议与各种应用层协议之间,为数据通讯提供安全支持。SSL 协议可分为两层:SSL 记录协议(SSL Record Protocol),它建立在可靠的传输协议(如TCP)之上,为高层协议提供数据封装、压缩、加密等基本功能的支持。SSL 握手协议(SSL Handshake Protocol),它建立在 SSL 记录协议之上,用于在实际的数据传输开始前,通讯双方进行身份认证、协商加密算法、交换加密密钥等。
HTTPS协议对称加密的过程? (hsdcjm)
- client请求服务端(指定SSL版本和加密组件) server返回CA证书+公钥
client用机构公钥认证server返回的CA证书上的签名是否正确 client生成一个密钥R,用公钥对密钥R加密发送给server
server用服务器的私钥解密获取密钥R 后续通信都是采用密钥R进行加密 - HTTPS数据加解密过程中数据进行对称加密,对称加密所要使用的密钥通过非对称加密传输。HTTPS协议加密的过程可以分为两个阶段,分别是:
证书的认证阶段:使用非对称加解密算法对数据传送阶段的对称加解密密钥进行加密和解密。
数据传送阶段:通过证书认证阶段获取到目标服务器的对称加解密密钥,对数据进行加密传送给服务器。
HTTPS为了兼顾安全与效率,同时使用了对称加密和非对称加密。数据是被对称加密传输的,对称加密过程需要客户端的一个密钥,为了确保能把该密钥安全传输到服务器端,采用非对称加密对该密钥进行加密传输。总的来说,对数据进行对称加密,对称加密所要使用的密钥通过非对称加密传输。
在整个HTTPS数据传输的过程中一共会涉及到四个密钥:
CA机构的公钥,用来验证数字证书是否可信任
服务器端的公钥
服务器端的私钥
客户端生成的随机密钥
一个HTTPS请求可以分为两个阶段,证书认证阶段和数据传送阶段。又可以细分为六个步骤:
- 客户端第一次向服务器发起HTTPS请求,连接到服务器的443(默认)端口。
- 服务器端有一个密钥对,公钥和私钥。用来进行非对称加密使用,服务器端保存私钥,不能泄露,公钥可以发送给任何人。服务器将自己的数字证书(包含公钥)发送给客户端。
- 客户端收到服务器端的数字证书之后,会对数字证书进行检查,验证合法性。如果发现数字证书有问题,那么HTTPS传输就中断。如果数字证书合格,那么客户端生成一个随机值,这个随机值是数据传输阶段时给数据对称加密的密钥,然后用数字证书中的公钥加密这个随机值密钥,这样就生成了加密数据使用的密钥的密文。到这时,HTTPS中的第一次HTTP请求就结束了。
- 客户端第二次向服务器发起HTTP请求,将对称加密密钥的密文发送给服务器。
- 服务器接收到客户端发来的密文之后,通过使用非对称加密中的私钥解密密文,得到数据传送阶段使用的对称加密密钥。然后对需要返回给客户端的数据通过这个对称加密密钥加密,生成数据密文,最后将这个密文发送给客户端。
- 客户端收到服务器端发送过来的密文,通过本地密钥对密文进行解密,得到数据明文。到这时,HTTPS中的第二次HTTP请求结束,整个HTTPS传输完成。
四、HTTPS 的优点(hsyd)
1、使用 HTTPS 协议可认证用户和服务器,确保数据发送到正确的客户机和服务器。
2、HTTPS 协议是由SSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议,要比 HTTP 协议安全,可防止数据在传输过程中不被窃取、修改,确保数据的完整性。
3、HTTPS 是现行架构下最安全的解决方案,虽然不是绝对安全,但它大幅增加了中间人攻击的成本。
五、HTTPS 的缺点(对比优点)
1、HTTPS 协议握手阶段比较费时,会使页面的加载时间延长近。
2、HTTPS 连接缓存不如 HTTP 高效,会增加数据开销,甚至已有的安全措施也会因此而受到影响。
3、HTTPS 协议的安全是有范围的,在黑客攻击、拒绝服务攻击和服务器劫持等方面几乎起不到什么作用。
4、SSL 证书通常需要绑定 IP,不能在同一 IP 上绑定多个域名,IPv4 资源不可能支撑这个消耗。
5、成本增加。部署 HTTPS 后,因为 HTTPS 协议的工作要增加额外的计算资源消耗,例如 SSL 协议加密算法和 SSL 交互次数将占用一定的计算资源和服务器成本。
6、HTTPS 协议的加密范围也比较有限。最关键的,SSL 证书的信用链体系并不安全,特别是在某些国家可以控制 CA 根证书的情况下,中间人攻击一样可行。
ARP协议工作原理?ARP攻击?如何解决(arpdc)
ARP协议及其工作原理
ARP(Address Resolution Protocol)即地址转换协议 是工作在TCP/IP模型的网络层的协议。在以太网(局域网)进行信息传输时,不是根据IP地址进行通信,因为IP地址是可变的,用于通信是不安全的。然而MAC地址是网卡的硬件地址,一般出厂后就具有唯一性。ARP协议就是将目标IP地址解析成MAC地址进行验证通信。
正常APR运作逻辑是:
假设A与C在同一局域网,A要和C实现通信,A会查询本地的ARP缓存表,找到C的IP地址对应的MAC地址后,就会进行数据传输。如果未找到,A会找广播地址(网关)广播一个ARP请求报文,所有主机都收到ARP请求,只有C主机会回复一个数据包给A,同时A主机会将返回的这个地址保存在ARP缓存表中。
那么什么是ARP攻击?(arpgj)
ARP是负责将网络中的IP地址转换为MAC地址(即网卡地址)的地址解析协议,在同一局域网下的设备如果需要互相传达信息,双方需要通过相应的MAC地址来确认身份,但黑客可以利用ARP数据包伪装身份,窃取设备间传达信息,还可以篡改数据,最终影响网络传输速率或造成用户隐私信息泄露等后果。
如何防御ARP攻击?
1.在pc端上做ip和MAC地址的绑定
2.在网络设备层面可以做ip mac 和端口的绑定,限制端口只能学习一个MAC地址,也可以做AAA认证,可以提前录入MAC地址,当终端连接时先判断合法性
3.可以部署一些arp防御软件,有条件的可以部署些arp防护的设备
DNS的解析过程(dnsjx)
DNS是用于实现域名和IP地址相互映射的一个分布式数据库,通过主机名,得到该主机名对应的IP地址的过程叫做域名解析。
1、首先客户端位置是一台电脑或手机,在打开浏览器以后,比如输入http://www.zdns.cn的域名,它首先是由浏览器发起一个DNS解析请求,如果本地缓存服务器中找不到结果,则首先会向根服务器查询,根服务器里面记录的都是各个顶级域所在的服务器的位置,当向根请求http://www.zdns.cn的时候,根服务器就会返回.cn服务器的位置信息。
2、递归服务器拿到.cn的权威服务器地址以后,就会寻问cn的权威服务器,知不知道http://www.zdns.cn的位置。这个时候cn权威服务器查找并返回http://zdns.cn服务器的地址。
3、继续向http://zdns.cn的权威服务器去查询这个地址,由http://zdns.cn的服务器给出了地址:202.173.11.10
4、最终才能进行http的链接,顺利访问网站。
5、这里补充说明,一旦递归服务器拿到解析记录以后,就会在本地进行缓存,如果下次客户端再请求本地的递归域名服务器相同域名的时候,就不会再这样一层一层查了,因为本地服务器里面已经有缓存了,这个时候就直接把http://www.zdns.cn的A记录返回给客户端就可以了。
如何用HTTP实现长连接?(hpclj)
HTTP短连接:
客户端和服务端进行一次HTTP请求/响应之后,就关闭连接。下一次的HTTP请求/响应操作需要重新建立。
在首部字段中设置Connection:close,则在一次请求/响应之后,就会关闭连接。
HTTP长连接:
客户端和服务端建立一次连接之后,可以在这条连接上进行多次请求/响应操作。
持久连接可以设置过期时间,也可以不设置。
在首部字段中设置Connection:keep-alive 和 Keep-Alive:timeout = 60,
表明连接建立之后,空闲时间超过60秒,连接失效。
如果在空闲第58秒使用此连接,则仍然有效,
并且使用完之后,重新计数空闲时间,空闲60秒无再使用,连接失效。
设置HTTP长连接,无过期时间,在首部字段中只设置Connection:keep-alive,表明连接永久有效。
中间人攻击知道吗?怎么做https的抓包?https怎么篡改?(zjrgj)
中间人攻击是指攻击者与通讯的两端分别创建独立的联系,并交换其所收到的数据,使通讯的两端认为他们正在通过一个私密的连接与对方直接对话,但事实上整个会话都被攻击者完全控制。
HTTPS 使用了 SSL 加密协议,是一种非常安全的机制,目前并没有方法直接对这个协议进行攻击,一般都是在建立 SSL 连接时,拦截客户端的请求,利用中间人获取到 CA证书、非对称加密的公钥、对称加密的密钥;有了这些条件,就可以对请求和响应进行拦截和篡改。
https 是如何防止中间人攻击的
https 无法防止中间人攻击,只有做证书固定ssl-pinning 或者 apk中预置证书做自签名验证可以防中间人攻击。
https 可以抓包吗
HTTPS 的数据是加密的,常规下抓包工具代理请求后抓到的包内容是加密状态,无法直接查看。
但是,我们可以通过抓包工具来抓包。它的原理其实是模拟一个中间人。通常 HTTPS 抓包工具的使用方法是会生成一个证书,用户需要手动把证书安装到客户端中,然后终端发起的所有请求通过该证书完成与抓包工具的交互,然后抓包工具再转发请求到服务器,最后把服务器返回的结果在控制台输出后再返回给终端,从而完成整个请求的闭环。
https怎么篡改(hscg)
打开wireshark准备抓包
查看电脑抓的包
你的账号密码都是明文传输的(密码是因为前端md5之后传的),中间的wifi(准确说是路由器)是直接可以截取查看的,能截取查看,是不是就可以篡改?答案当然是肯定的。
- 如果证书被篡改,浏览器就提示不可信,终止通信,如果验证通过,说明公钥没问题,一定没被篡改。
- 公钥没被篡改,那浏览器生成的对称加密用的密钥用公钥加密发送给服务端,也只有服务端的私钥能解开,所以保证了
对称密钥不可能被截获,对称密钥没被截获,那双方的通信就一定是安全的。 - 黑客依然可以截获数据包,但是全都是经过对称加密的密钥加密的,他也可以篡改,只是没有任何意义了,黑客也不会做吃力不讨好的事了。
设计模式(sjms)(108)
说一下你熟悉的设计模式?
单例模式
简单点说,就是一个应用程序中,某个类的实例对象只有一个,你没有办法去new,因为构造器是被private修饰的,一般通过getInstance()的方法来获取它们的实例。Spring 中的 Bean 默认都是单例的。
- 饿汉模式:所谓饿汉模式就是立即加载,一般情况下再调用getInstancef方法之前就已经产生了实例,
也就是在类加载的时候已经产生了。这种模式的缺点很明显,就是占用资源,当单例类很大的时候, 其实我们是想使用的时候再产生实例。因此这种方式适合占用资源少,在初始化的时候就会被用到的类。 - 2.懒汉模式:懒汉模式就是延迟加载,也叫懒加载。在程序需要用到的时候再创建实例, 这样保证了内存不会被浪费。
代理设计模式 : Spring AOP 功能的实现。
观察者模式
对象间一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。Spring 事件驱动模型就是观察者模式很经典的一个应用。(事件多级触发场景。跨系统的消息交换场景,如消息队列的处理机制。天气观测站和气象报告板的关系。但报告板想获取观测站的数据,可以注册加入到观测站的观察者列表中,这就可以使观测站有数据更新时,自动传给气象报告板。
装饰者模式
对已有的业务逻辑进一步的封装,使其增加额外的功能,如Java中的IO流就使用了装饰者模式,用户在使用的时候,可以任意组装,达到自己想要的效果。
模板方法模式 : Spring 中 jdbcTemplate、hibernateTemplate 等以 Template 结尾的对数据库操作的类,它们就使用到了模板模式。
适配器模式
Spring AOP 的增强或通知(Advice)使用到了适配器模式、spring MVC 中也是用到了适配器模式适配Controller。将两种完全不同的事物联系到一起,就像现实生活中的变压器。假设一个手机充电器需要的电压是20V,但是正常的电压是220V,这时候就需要一个变压器,将220V的电压转换成20V的电压,这样,变压器就将20V的电压和手机联系起来了。
工厂模式
工厂模式的用意是定义一个创建产品对象的工厂接口,将实际创建性工作推迟到子类中。工厂模式可分为简单工厂、工厂方法和抽象工厂模式。Spring使用工厂模式通过 BeanFactory、ApplicationContext 创建 bean 对象。
简单工厂模式:简单工厂的实现思路是,定义一个工厂类,根据传入的参数不同返回不同的实例,被创建的实例具有共同的父类或接口。简单工厂的适用场景是:简单工厂的实现思路是,定义一个工厂类,根据传入的参数不同返回不同的实例,被创建的实例具有共同的父类或接口。简单工厂的适用场景是:需要创建的对象较少。客户端不关心对象的创建过程。
简单工厂和抽象工厂有什么区别?(gcjcqb gccjqb)
简单工厂模式:
这个模式本身很简单而且使用在业务较简单的情况下。一般用于小项目或者具体产品很少扩展的情况(这样工厂类才不用经常更改)。
它由三种角色组成:
工厂类角色:这是本模式的核心,含有一定的商业逻辑和判断逻辑,根据逻辑不同,产生具体的工厂产品。如例子中的Driver类。
抽象产品角色:它一般是具体产品继承的父类或者实现的接口。由接口或者抽象类来实现。如例中的Car接口。
具体产品角色:工厂类所创建的对象就是此角色的实例。在java中由一个具体类实现,如例子中的Benz、Bmw类。
抽象工厂模式:来看看抽象工厂模式的各个角色(和工厂方法的如出一辙):
抽象工厂角色:
这是工厂方法模式的核心,它与应用程序无关。是具体工厂角色必须实现的接口或者必须继承的父类。在java中它由抽象类或者接口来实现。具体工厂角色:它含有和具体业务逻辑有关的代码。由应用程序调用以创建对应的具体产品的对象。在java中它由具体的类来实现。
抽象产品角色:它是具体产品继承的父类或者是实现的接口。在java中一般有抽象类或者接口来实现。
具体产品角色:具体工厂角色所创建的对象就是此角色的实例。在java中由具体的类来实现。
Spring/Spring MVC(109)
为什么要使用 spring?
核心思想:IOC控制反转,DI依赖注入,AOP切面编程。
IOC就是spring里的控制反转,把类的控制权呢交给spring来管理,我们在使用的时候,在spring的配置文件中,配置好bean标签,以及类的全路径,如果有参数,然后在配置上相应的参数。这样的话,spring就会给我们通过反射的机制实例化这个类,同时放到spring容器当中去。我们在使用的时候,需要结合DI依赖注入使用,把我们想使用的类注入到需要的地方就可以,依赖注入的方式有构造器注入、getset注入还有注解注入。我们现在都使用@autowired或者@Resource注解的方式注入。
AOP切面编程,他可以在不改变源代码的情况下对代码功能的一个增强。我们在配置文件中配置好切点,然后去实现切面的逻辑就可以实现代码增强,这个代码增强,包括在切点的执行前,执行中,执行后都可以进行增强逻辑处理,不用改变源代码,这块我们项目中一般用于权限认证、日志、事务处理这几个地方。
解释一下什么是 aop?(aopdc)(jdqb)
- 这块呢,我看过spring的源码,底层就是动态代理来实现的,所谓的动态代理就是说 AOP
框架不会去修改字节码,而是每次运行时在内存中临时为方法生成一个 AOP 对象,这个 AOP
对象包含了目标对象的全部方法,并且在特定的切点做了增强处理,并回调原对象的方法。 - Spring AOP是基于动态代理的,如果要代理的对象实现了InvocationHandler接口,那么Spring AOP就会使用JDK 动态代理去创建代理对象,InvocationHandler 通过 invoke()方法反射来调用目标类中的代码,动态地将横切逻辑和业务编织在一起;接着,Proxy 利用InvocationHandler
动态创建一个符合接口的的实例,生成目标类的代理对象。;而对于没有实现接口的对象,就无法使用JDK动态代理,转而使用CGlib动态代理生成一个被代理对象的子类来作为代理。
CGLIB 是通过继承的方式做的动态代理,因此如果某个类被标记为 final,那么它是无法使用 CGLIB做动态代理的。不过在我们的业务场景中没有代理过final的类,基本上都代理的controller层实现权限以及日志,还有就是service层实现事务统一管理。
AOP可以有多种实现方式,而Spring AOP支持如下两种实现方式。
JDK动态代理:这是Java提供的动态代理技术,可以在运行时创建接口的代理实例。Spring AOP默认采用这种方式,在接口的代理实例中织入代码。
CGLib动态代理:采用底层的字节码技术,在运行时创建子类代理的实例。当目标对象不存在接口时,Spring AOP就会采用这种方式,在子类实例中织入代码。
应用场景:
Spring AOP为IoC的使用提供了更多的便利,一方面,应用可以直接使用AOP的功能,设计应用的横切关注点,把跨越应用程序多个模块的功能抽象出来,并通过简单的AOP的使用,灵活地编制到模块中,比如可以通过AOP实现应用程序中的日志功能。另一方面,在Spring内部,一些支持模块也是通过Spring AOP来实现的,比如事务处理
Spring AOP不能对哪些类进行增强?
Spring AOP只能对IoC容器中的Bean进行增强,对于不受容器管理的对象不能增强。
由于CGLib采用动态创建子类的方式生成代理对象,所以不能对final修饰的类进行代理。
在Spring AOP 中,关注点和横切关注的区别是什么?(aopgzd)
关注点是应用中一个模块的行为,一个关注点可能会被定义成一个我们想实现的一个功能。
- 横切关注点是一个关注点,此关注点是整个应用都会使用的功能,并影响整个应用,比如日志,安全和数据传输,几乎应用的每个模块都需要的功能。因此这些都属于横切关注点。
- 连接点代表一个应用程序的某个位置,在这个位置我们可以插入一个AOP切面,它实际上是个应用程序执行Spring AOP的位置。
- 切入点是一个或一组连接点,通知将在这些位置执行。可以通过表达式或匹配的方 式指明切入点。
通知是程序执行时要通过SpringAOP框架触发的代码段。(aoptz)
Spring切面可以应用五种类型的通知: - before:前置通知,在一个方法执行前被调用。
- after: 在方法执行之后调用的通知,无论方法执行是否成功。
- after-returning: 仅当方法成功完成后执行的通知。
- after-throwing: 在方法抛出异常退出时执行的通知。
- around: 在方法执行之前和之后调用的通知。
Spring AOP和AspectJ AOP有什么区别?(aaqb)
Spring AOP是属于运行时增强,而AspectJ是编译时增强。Spring AOP基于代理(Proxying),而
AspectJ基于字节码操作(Bytecode Manipulation)。
Spring AOP已经集成了AspectJ,AspectJ应该算得上是Java生态系统中最完整的AOP框架了。
AspectJ相比于Spring AOP功能更加强大,但是Spring AOP相对来说更简单。
如果我们的切面比较少,那么两者性能差异不大。但是,当切面太多的话,最好选择AspectJ,它比
SpringAOP快很多。
解释一下什么是 ioc?(iocdc)
- IOC就是控制反转,是指创建对象的控制权的转移。以前创建对象的主动权和时机是由自己把
控的,而现在这种权力转移到Spring容器中,并由容器根据配置文件去创建实例和管理各个实例之
间的依赖关系。对象与对象之间松散耦合,也利于功能的复用。DI依赖注入,和控制反转是同一个 概念的不同角度的描述,即
应用程序在运行时依赖IoC容器来动态注入对象需要的外部资源。 - 最直观的表达就是,IOC让对象的创建不用去new了,可以由spring自动生产,使用java的反
射机制,根据配置文件在运行时动态的去创建对象以及管理对象,并调用对象的方法的。 - Spring的IOC有三种注入方式 :构造器注入、setter方法注入、根据注解注入。
说一说你对Spring容器的了解(sgrq baqb abqb)
Spring主要提供了两种类型的容器:BeanFactory和ApplicationContext。
- BeanFactory:是基础类型的IoC容器,提供完整的IoC服务支持。如果没有特殊指定,默认采用延迟初始化策略。只有当客户端对象需要访问容器中的某个受管对象的时候,才对该受管对象进行初始化以及依赖注入操作。所以,相对来说,容器启动初期速度较快,所需要的资源有限。对于资源有限,并且功能要求不是很严格的场景,BeanFactory是比较合适的IoC容器选择。
- ApplicationContext:它是在BeanFactory的基础上构建的,是相对比较高级的容器实现,除了拥有BeanFactory的所有支持,ApplicationContext还提供了其他高级特性,比如事件发布、国际化信息支持等。ApplicationContext所管理的对象,在该类型容器启动之后,默认全部初始化并绑定完成。所以,相对于BeanFactory来说,ApplicationContext要求更多的系统资源,同时,因为在启动时就完成所有初始化,容器启动时间较之BeanFactory也会长一些。在那些系统资源充足,并且要求更多功能的场景中,ApplicationContext类型的容器是比较合适的选择。
Spring 中 BeanFactory 和FactoryBean 的区别(bfqb fbqb)
首先,Spring 里面的核心功能是 IOC 容器,所谓 IOC 容器呢,本质上就是一个Bean 的容器或者是一个 Bean 的工厂。它能够根据 xml 里面声明的 Bean 配置进行 bean 的加载和初始化,然后BeanFactory 来生产我们需要的各种各样的 Bean。所以我对 BeanFactory 的理解了有两个。
BeanFactory 是所有 Spring Bean 容器的顶级接口,它为 Spring 的容器定义了一套规范,并提供像 getBean 这样的方法从容器中获取指定的 Bean 实例。BeanFactory 在产生 Bean 的同时,还提供了解决 Bean 之间的依赖注入的能力,也就是所谓的 DI。
FactoryBean 是一个工厂 Bean,它是一个接口,主要的功能是动态生成某一个类型的 Bean 的实例,也就是说,我们可以自定义一个 Bean 并且加载到 IOC 容器里面。它里面有一个重要的方法叫 getObject(),这个方法里面就是用来实现动态构建Bean 的过程。Spring Cloud 里 面 的 OpenFeign 组 件 , 客 户 端 的 代 理 类 , 就 是 使 用 了FactoryBean 来实现的
Spring Boot怎么更换bean组件(stthbn stghbn)
- 1.可以通过BeanPostProcessor来简单替换容器中的Bean。优点:直接利用Spring原生的扩展,可以平滑升级,实现简单,易操作好理解,对于只需要替换少数几个Bean的情况下推荐这种方式。缺点:beanName硬编码在代码里,虽然可以把替换关系配置在properties里,但是在多版本部署,替换Bean较多时,维护这种关系将是一种负担仅仅是替换了Bean对象,对于容器中元数据如BeanDefinition等等均是原对象的,存在一定局限性
- 2.Spring容器是可以直接动态注册Bean的,而且如果注册的Bean与容器中现有的Bean同名,则会直接替换现有Bean,可以绕过Spring启动时解析BeanDefinition的checkCandidate
- 3.Spring实际上就是一个容器,底层其实就是一个ConcurrentHashMap。如果要替换Map中的Entry,再次调用put方法设置相同的key不同的value就可以了。同理,如果要替换Spring容器中的Bean组件,那么我们重新定义一个同名的Bean并注册进去就可以了。当然直接申明两个同名的Bean是过不了Spring中ClassPathBeanDefinitionScanner的检查的,这时候需要我们做一点点扩展。
实现自己的ClassPathBeanDefinitionScanner
目前的想法是直接重写checkCandidate方法,通过判断Bean的类上是否有@Replace注解,来决定是否通过检查。
依次往上扩展就到了ConfigurationClassPostProcessor,这是Spring中非常重要的一个容器后置处理器BeanFactoryPostProcessor(上面我们用的是Bean后处理器:BeanPostProcessor),重写processConfigBeanDefinitions方法就可以引入自己实现的ClassPathBeanDefinitionScanner。
请描述Spring Boot自动装配的过程(stzdzp)
自动装配,简单来说就是自动把第三方组件的 Bean 装载到 Spring IOC 器里面,不需要开发人员再去写 Bean 的装配配置。在 Spring Boot 应用里面,只需要在启动类加上@SpringBootApplication 注解就可以实现自动装配。 @SpringBootApplication 是 一 个 复 合 注 解 , 真 正 实 现 自 动 装 配 的 注 解 是@EnableAutoConfiguration。
整个自动装配的过程是:Spring Boot通过@EnableAutoConfiguration注解开启自动配置,加载spring.factories中注册的各种AutoConfiguration类,当某个AutoConfiguration类满足其注解@Conditional指定的生效条件(Starters提供的依赖、配置或Spring容器中是否存在某个Bean等)时,实例化该AutoConfiguration类中定义的Bean(组件等),并注入Spring容器,就可以完成依赖框架的自动配置。
spring 中的 bean 是线程安全的吗?(snxcaq)
不是。Spring容器本身并没有提供Bean的线程安全策略。如果单例的Bean是一个无状态的Bean,即线程中的操作不会对Bean的成员执行查询以外的操作,那么这个单例的Bean是线程安全的。比如,Controller、Service、DAO这样的组件,通常都是单例且线程安全的。如果单例的Bean是一个有状态的Bean,则可以采用ThreadLocal对状态数据做线程隔离,来保证线程安全。
spring 支持几种 bean 的作用域?(snzyy)
当通过spring容器创建一个Bean实例时,不仅可以完成Bean实例的实例化,还可以为Bean指定特定的作用域。Spring支持如下5种作用域:
singleton:单例模式,在整个Spring IoC容器中,使用singleton定义的Bean将只有一个实例
prototype:原型模式,每次通过容器的getBean方法获取prototype定义的Bean时,都将产生一个新的Bean实例
request:对于每次HTTP请求,使用request定义的Bean都将产生一个新实例,即每次HTTP请求将会产生不同的Bean实例。只有在Web应用中使用Spring时,该作用域才有效
session:对于每次HTTP Session,使用session定义的Bean豆浆产生一个新实例。同样只有在Web应用中使用Spring时,该作用域才有效
globalsession:每个全局的HTTP Session,使用session定义的Bean都将产生一个新实例。典型情况下,仅在使用portlet context的时候有效。同样只有在Web应用中使用Spring时,该作用域才有效
其中比较常用的是singleton和prototype两种作用域。对于singleton作用域的Bean,每次请求该Bean都将获得相同的实例。容器负责跟踪Bean实例的状态,负责维护Bean实例的生命周期行为;如果一个Bean被设置成prototype作用域,程序每次请求该id的Bean,Spring都会新建一个Bean实例,然后返回给程序。在这种情况下,Spring容器仅仅使用new 关键字创建Bean实例,一旦创建成功,容器不在跟踪实例,也不会维护Bean实例的状态。
如果不指定Bean的作用域,Spring默认使用singleton作用域。Java在创建Java实例时,需要进行内存申请;销毁实例时,需要完成垃圾回收,这些工作都会导致系统开销的增加。因此,prototype作用域Bean的创建、销毁代价比较大。而singleton作用域的Bean实例一旦创建成功,可以重复使用。因此,除非必要,否则尽量避免将Bean被设置成prototype作用域。
spring 自动装配bean有哪些方式?(Spring创建bean的方式)(zdzpbn)(sgzrbn)
Spring容器负责创建应用程序中的bean同时通过ID来协调这些对象之间的关系。作为开发人员,我们需要告诉Spring要创建哪些bean并且如何将其装配到一起。
spring中bean装配有两种方式:
隐式的bean发现机制和自动装配
在java代码或者XML中进行显示配置
1. 通过构造方式创建bean
经常使用的范围就是springMVC 的配置文件中;
在xml 配置的目的主要有,对当前这个对象进行初始化,定义在全局范围内,之后可以自定义配置。
在工作期间,自己使用这个构造方式创建bean时,充当开关、权限控制(限制某些用户不能访问其他的方式)。数据阈值控制等等
2. set方式创建
简单的说就是,在你xml 配置文件中,一个bean的创建中,另外一个属性对象在这个bean内,我们通过对这个属性进行setter 和getter 的方式创建方法,在配置的过程中,属性的创建,ref 关键词进行注入。spring会对这个名称进行对应的查找,并通过set 方式进行装配。
3. @Autowired 方式注入
注解的方式,这个注解在我们的开发过程中是非常常用的,但是我们需要进行对他的实现类进行加入@service 的注解。
把 Bean 注入到 IOC 容器里面的方式有 7 种方式(bnzrioc)
- 使用 xml 的方式来声明 Bean 的定义,Spring 容器在启动的时候会加载并解析这个 xml,把 bean 装载到 IOC
容器中。 - 使用@CompontScan 注解来扫描声明了@Controller、@Service、@Repository、 @Component
注解的类。 - 使用@Configuration 注解声明配置类,并使用@Bean 注解实现 Bean 的定义,这种方式其实是 xml 配置方式的一种演变,是 Spring 迈入到无配置化时代的里程碑。
- 使用@Import 注解,导入配置类或者普通的 Bean
- 使 用 FactoryBean 工 厂 bean , 动 态 构 建 一 个 Bean 实 例 , Spring Cloud
OpenFeign 里面的动态代理实例就是使用 FactoryBean 来实现的。 - 实现 ImportBeanDefinitionRegistrar 接口,可以动态注入 Bean 实例。这个在Spring Boot
里面的启动注解有用到。 - 实现 ImportSelector 接口,动态批量注入配置类或者 Bean 对象,这个在 SpringBoot
里面的自动装配机制里面有用到。
Spring MVC的controller是线程安全的吗?怎么去保证线程安全呢?(mvcxcaq)
SpringMVC Controller默认情况下是Singleton(单例)的,当request过来,不用每次创建Controller,会用原来的instance去处理。
若每个线程中对全局变量、静态变量只有读操作,而无写操作,一般来说,这个全局变量是线程安全的;若有多个线程同时执行写操作,一般都需要考虑线程同步,否则的话就可能影响线程安全。
这么说的话,那实现SpringMVC Controller线程安全,最简单粗暴的方法就是将Controller的scope定义为prototype,也就是说每次request过来时,都去创建新的instance,当然这么做的代价就是增大了系统开销,这似乎也违背了SpringMVC框架的初衷。
另外一个解决方案,就是我们之前提到的,尽量不要在Controller中去定义变量属性。SpringMVC是基于方法的,通过形参传值,一个方法结束参数就销毁了。所以只要不在Controller中定义属性,那么Singleton(单例)是安全的。
spring 事务实现方式有哪些,事务特性?(sgswdc)
事务其实就是一系列指令的集合,要么都执行,要么都不执行。
事务的特性
- 原子性(Atomicity):事务是一个原子操作,由一系列动作组成。事务的原子性确保动作要么全部完成,要么完全不起作用。
- 一致性(Consistency):一旦事务完成(不管成功还是失败),系统必须确保它所建模的业务处于一致的状态,而不会是部分完成部分失败。在现实中的数据不应该被破坏。
- 隔离性(Isolation):可能有许多事务会同时处理相同的数据,因此每个事务都应该与其他事务隔离开来,防止数据损坏。
- 持久性(Durability):一旦事务完成,无论发生什么系统错误,它的结果都不应该受到影响,这样就能从任何系统崩溃中恢复过来。通常情况下,事务的结果被写到持久化存储器中。
事务实现方式(sgswsx)
-
编程式事务管理
编程式事务管理是侵入性事务管理,使用TransactionTemplate或者直接使用,PlatformTransactionManager,对于编程式事务管理,Spring推荐使用TransactionTemplate,编程式事务粒度可以到代码级别。 -
声明式事务管理
声明式事务管理建立在AOP之上,其本质是对方法前后进行拦截,然后在目标方法开始之前创建或者加入一个事务,执行完目标方法之后根据执行的情况提交或者回滚。
编程式事务每次实现都要单独实现,但业务量大功能复杂时,使用编程式事务无疑是痛苦的,而声明式事务不同,声明式事务属于无侵入式,不会影响业务逻辑的实现,只需要在配置文件中做相关的事务规则声明或者通过注解的方式,便可以将事务规则应用到业务逻辑中。
显然声明式事务管理要优于编程式事务管理,这正是Spring倡导的非侵入式的编程方式。唯一不足的地方就是声明式事务管理的粒度是方法级别,而编程式事务管理是可以到代码块的,但是可以通过提取方法的方式完成声明式事务管理的配置。
编程式事务管理对基于 POJO 的应用来说是唯一选择。我们需要在代码中调用beginTransaction()、commit()、rollback()等事务管理相关的方法,这就是编程式事务管理。
基于 TransactionProxyFactoryBean 的声明式事务管理
基于 @Transactional 的声明式事务管理
基于 Aspectj AOP 配置事务
事务三要素是什么?(swsys)
- 数据源:表示具体的事务性资源,是事务的真正处理者,如MySQL等。
- 事务管理器:像一个大管家,从整体上管理事务的处理过程,如打开、提交、回滚等。
- 事务应用和属性配置:像一个标识符,表明哪些方法要参与事务,如何参与事务,以及一些相关属 性如隔离级别、超时时间等。
说一下 spring 的事务隔离级别,事务传播行为?(sgswgl sgswcb sjkswgljb)
事务隔离级别指的是一个事务对数据的修改与另一个并行的事务的隔离程度,当多个事务同时访问相同数据时,如果没有采取必要的隔离机制,就可能发生以下问题:
脏读:一个事务读到另一个事务未提交的更新数据。
幻读:例如第一个事务对一个表中的数据进行了修改,比如这种修改涉及到表中的“全部数据行”。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入“一行新数据”。那么,以后就会发生操作第一个事务的用户发现表中还存在没有修改的数据行,就好象发生了幻觉一样。
不可重复读:比方说在同一个事务中先后执行两条一模一样的select语句,期间在此次事务中没有执行过任何DDL语句,但先后得到的结果不一致,这就是不可重复读。
事务隔离级别:
MySQL 的事务隔离是在 MySQL. ini 配置文件里添加的,在文件的最后添加:transaction-isolation =
REPEATABLE-READ
事务隔离级别(swgljb):
-
读未提交:就是一个事务可以读取另一个未提交事务的数据;
-
读提交,能解决脏读问题。读已提交:就是一个事务要等另一个事务提交后才能读取数据;
-
可重复读:就是在开始读取数据(事物开启)时,不再允许修改操作;
-
串行化:事务串行化顺序执行,事务只能排序依次执行。不能并发
这四种隔离级别的实现机制如下:
- READ UNCOMMITTED & READ COMMITTED: 通过Record Lock算法实现了行锁,但READ UNCOMMITTED允许读取未提交数据,所以存在脏读问题。而READ
COMMITTED允许读取提交数据,所以不存在脏读问题,但存在不可重复读问题。 - REPEATABLE READ: 使用Next-Key Lock算法实现了行锁,并且不允许读取已提交的数据,所以解决了不可重复读的问题。另外,该算法包含了间隙锁,会锁定一个范围,当对查询范围
id>4 and id<7 加锁的时候,会针对B+树中(4,7)这个开区间范围的索引加间隙锁。意味着在这种情况下,其他事务对这个区间的数据进行插入、更新、删除都会被锁住。因此也解决了幻读的问题。 - SERIALIZABLE: 对每个SELECT语句后自动加上LOCK IN SHARE MODE,即为每个读取操作加一个共享锁。因此在这个事务隔离级别下,读占用了锁,对一致性的非锁定读不再予以支持。
事务传播行为(sgswcbxw)当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行。Spring定义了七种传播行为:
- PROPAGATION_REQUIRED:表示当前方法必须运行在事务中。如果当前事务存在,方法将会在该事务中运行。否则,会启动一个新的事务
- PROPAGATION_SUPPORTS:表示当前方法不需要事务上下文,但是如果存在当前事务的话,那么该方法会在这个事务中运行
- PROPAGATION_MANDATORY:表示该方法必须在事务中运行,如果当前事务不存在,则会抛出一个异常
- PROPAGATION_REQUIRED_NEW:表示当前方法必须运行在它自己的事务中。一个新的事务将被启动。如果存在当前事务,在该方法执行期间,当前事务会被挂起。如果使用JTATransactionManager的话,则需要访问TransactionManager
- PROPAGATION_NOT_SUPPORTED:表示该方法不应该运行在事务中。如果存在当前事务,在该方法运行期间,当前事务将被挂起。如果使用JTATransactionManager的话,则需要访问TransactionManager
- PROPAGATION_NEVER:表示当前方法不应该运行在事务上下文中。如果当前正有一个事务在运行,则会抛出异常
- PROPAGATION_NESTED:表示如果当前已经存在一个事务,那么该方法将会在嵌套事务中运行。嵌套的事务可以独立于当前事务进行单独地提交或回滚。如果当前事务不存在,那么其行为与PROPAGATION_REQUIRED一样。
说一下 spring mvc 运行流程?(scyxlc scdc dtdc)
1、 用户发送请求至前端控制器DispatcherServlet。
2、 DispatcherServlet收到请求调用HandlerMapping处理器映射器。
3、 处理器映射器找到具体的处理器(可以根据xml配置、注解进行查找),生成处理器对象及处理器
拦截器(如果有则生成)一并返回给DispatcherServlet。
4、 DispatcherServlet调用HandlerAdapter处理器适配器。
5、 HandlerAdapter经过适配调用具体的处理器(Controller,也叫后端控制器)。
6、 Controller执行完成返回ModelAndView。
7、 HandlerAdapter将controller执行结果ModelAndView返回给DispatcherServlet。
8、 DispatcherServlet将ModelAndView传给ViewReslover视图解析器。
9、 ViewReslover解析后返回具体View。
10、DispatcherServlet根据View进行渲染视图(即将模型数据填充至视图中)。
11、 DispatcherServlet响应用户。
spring mvc 有哪些组件(sczj):
前端控制器(DispatcherServlet):接收请求,响应结果,相当于电脑的CPU。作为前端控制器,整个流程控制的中心,控制其它组件执行,统一调度,降低组件之间的耦合性,提高每个组件的扩展性。
处理器映射器(HandlerMapping):通过扩展处理器映射器实现不同的映射方式,例如:配置文件方式,实现接口方式,注解方式等。
处理器(Handler):需要程序员去写代码处理逻辑的。
处理器适配器(HandlerAdapter):会把处理器包装成适配器,这样就可以支持多种类型的处理
器,类比笔记本的适配器(适配器模式的应用)。
视图解析器(ViewResovler):进行视图解析,多返回的字符串,进行处理,可以解析成对应的页
面。
Interceptors :拦截器,负责拦截我们定义的请求然后做处理工作
spring中都用了哪些设计模式(sgsjms)
- 简单工厂模式:Spring 中的 BeanFactory 就是简单工厂模式的体现。根据传入一个唯一的标识来获 得 Bean对象,但是在传入参数后创建还是传入参数前创建,要根据具体情况来定。
- 工厂模式:Spring 中的 FactoryBean 就是典型的工厂方法模式,实现了 FactoryBean 接口的 bean 是一类叫做 factory 的 bean。其特点是,spring 在使用 getBean() 调用获得该 bean 时,会自动调 用该 bean 的 getObject() 方法,所以返回的不是 factory 这个 bean,而是这个 bean.getOjbect() 方法的返回值。
- 单例模式:在 spring 中用到的单例模式有: scope=“singleton” ,注册式单例模式,bean 存放于 Map中。bean name 当做 key,bean 当做 value。
- 原型模式:在 spring 中用到的原型模式有: scope=“prototype” ,每次获取的是通过克隆生成的新实例,对其进行修改时对原有实例对象不造成任何影响。
- 迭代器模式:在 Spring 中有个 CompositeIterator 实现了 Iterator,Iterable 接口和
Iterator 接 口,这两个都是迭代相关的接口。可以这么认为,实现了 Iterable 接口,则表示某个对象是可被迭代的。Iterator 接口相当于是一个迭代器,实现了 Iterator 接口,等于具体定义了这个可被迭代的 对象时如何进行迭代的。 - 代理模式:Spring 中经典的 AOP,就是使用动态代理实现的,分 JDK 和 CGlib 动态代理。
- 适配器模式:Spring 中的 AOP 中 AdvisorAdapter 类,它有三个实现:
MethodBeforAdviceAdapter、AfterReturnningAdviceAdapter、ThrowsAdviceAdapter。Spring
会根据不同的 AOP 配置来使用对应的 Advice,与策略模式不同的是,一个方法可以同时拥有多个 Advice。Spring 存在很多以Adapter 结尾的,大多数都是适配器模式。 - 观察者模式:Spring 中的 Event 和 Listener。spring 事件:ApplicationEvent,该抽象类继承了
EventObject 类,JDK 建议所有的事件都应该继承自 EventObject。spring 事件监听器:
ApplicationListener,该接口继承了 EventListener 接口,JDK 建议所有的事件监听器都应该继承
EventListener。 - 模板模式:Spring 中的 org.springframework.jdbc.core.JdbcTemplate 就是非常经典的模板模式
的应用,里面的 execute 方法,把整个算法步骤都定义好了。
Spring 是如何解决循环依赖问题的?(sgxhyl sgsjhc)
我们都知道,如果在代码中,将两个或多个 Bean 互相之间持有对方的引用就会发生循环依赖。循环的依赖将会导致注入死循环。这是 Spring 发生循环依赖的原因。
循环依赖有三种形态:
- 第一种互相依赖:A 依赖 B,B 又依赖 A,它们之间形成了循环依赖。
- 而 Spring 中设计了三级缓存来解决循环依赖问题,当我们去调用 getBean()方法的时候,Spring 会先从一级缓存中去找到目标Bean,如果发现一级缓存中没有便会去二级缓存中去找,而如果一、二级缓存中都没有找到,意味着该目标Bean还没有实例化。于是,Spring 容器会实例化目标 Bean(PS:刚初始化的 Bean称为早期 Bean) 。然后,将目标Bean 放入到二级缓存中,同时,加上标记是否存在循环依赖。如果不存在循环依赖便会将目标 Bean 存入到二级缓存,否则,便会标记该Bean 存在循环依赖,然后将等待下一次轮询赋值,也就是解析@Autowired 注解。等@Autowired注解赋值完成后(PS:完成赋值的 Bean 称为成熟 Bean) ,会将目标 Bean 存入到一级缓存。
- Spring 一级缓存中存放所有的成熟 Bean, 二级缓存中存放所有的早期 Bean,先取一级缓存,再取二级缓存
Spring 中哪些情况下,不能解决循环依赖问题?(sgxhyl)
1.多例 Bean 通过 setter 注入的情况,不能解决循环依赖问题
2.构造器注入的 Bean 的情况,不能解决循环依赖问题
3.单例的代理 Bean 通过 Setter 注入的情况,不能解决循环依赖问题
4.设置了@DependsOn 的 Bean 的情况,不能解决循环依赖问题
Spring三级缓存的作用是什么?(sgsjhczy)
三级缓存是用来存储代理 Bean,当调用 getBean()方法时,发现目标 Bean 需要
通过代理工厂来创建,此时会将创建好的实例保存到三级缓存,最终也会将赋值
好的 Bean 同步到一级缓存中。
代理设计中的正向代理和反向代理?(zfqb)
正向代理:代理客户;隐藏真实的客户,为客户端收发请求,使真实客户端对服务器不可见;一个局域网内的所有用户可能被一台服务器做了正向代理,由该台服务器负责 HTTP请求;意味着同服务器做通信的是正向代理服务器;
反向代理:代理服务器;隐藏了真实的服务器,为服务器收发请求,使真实服务器对客户端不可见;负载均衡服务器,将用户的请求分发到空闲的服务器上;意味着用户和负载均衡服务器直接通信,即用户解析服务器域名时得到的是负载均衡服务器的
IP。
springbean的生命周期(snsmzq)
Spring 生命周期全过程大致分为五个阶段:创建前准备阶段、创建实例阶段、依赖注入阶段、容器缓存阶段和销毁实例阶段。
一、创建前准备阶段
这个阶段主要的作用是,Bean 在开始加载之前,需要从上下文和相关配置中解析并查找 Bean 有关的扩展实现,比如像 init-method-容器在初始化 bean 时调用的方法、destory-method,容器在销毁 bean 时调用的方法。以及,BeanFactoryPostProcessor 这类的 bean 加载过程中的前置和后置处理。这些类或者配置其实是 Spring 提供给开发者,用来实现 Bean 加载过程中的扩展机制,在很多和 Spring 集成的中间件中比较常见,比如 Dubbo。
二、创建实例阶段
这个阶段主要是通过反射来创建 Bean 的实例对象,并且扫描和解析 Bean 声明的一些属性。
三、依赖注入阶段
如果被实例化的 Bean 存在依赖其他 Bean 对象的情况,则需要对这些依赖 bean进行对象注入。比如常见的@Autowired、setter 注入等依赖注入的配置形式。同 时 , 在 这 个 阶 段 会 触 发 一 些 扩 展 的 调 用 , 比 如 常 见 的 扩 展 类 :BeanPostProcessors(用来实现 bean 初始化前后的扩展回调)、InitializingBean(这个类有一个afterPropertiesSet(),这个在工作中也比较常见)、
BeanFactoryAware 等等。
四、容器缓存阶段
容器缓存阶段主要是把 bean 保存到容器以及 Spring 的缓存中,到了这个阶段,Bean 就可以被开发者使用了。这个阶段涉及到的操作,常见的有,init-method 这个属性配置的方法, 会在这个阶段调用。以 及 像 BeanPostProcessors 方 法 中 的 后 置 处 理 器 方 法 如 postProcessAfterInitialization,也会在这个阶段触发。
五、销毁实例阶段
当 Spring 应用上下文关闭时,该上下文中的所有 bean 都会被销毁。如果存在 Bean 实现了 DisposableBean 接口,或者配置了 destory-method 属性,会在这个阶段被调用。
Spring是如何管理Bean的?(sgglbn)
Spring通过IoC容器来管理Bean,我们可以通过XML配置或者注解配置,来指导IoC容器对Bean的管理。因为注解配置比XML配置方便很多,所以现在大多时候会使用注解配置的方式。
以下是管理Bean时常用的一些注解:
1.@ComponentScan用于声明扫描策略,通过它的声明,容器就知道要扫描哪些包下带有声明的类,也可以知道哪些特定的类是被排除在外的。
2.@Component、@Repository、@Service、@Controller用于声明Bean,它们的作用一样,但是语义不同。@Component用于声明通用的Bean,@Repository用于声明DAO层的Bean,@Service用于声明业务层的Bean,@Controller用于声明视图层的控制器Bean,被这些注解声明的类就可以被容器扫描并创建。
3.@Autowired、@Qualifier用于注入Bean,即告诉容器应该为当前属性注入哪个Bean。其中,@Autowired是按照Bean的类型进行匹配的,如果这个属性的类型具有多个Bean,就可以通过@Qualifier指定Bean的名称,以消除歧义。
4.@Scope用于声明Bean的作用域,默认情况下Bean是单例的,即在整个容器中这个类型只有一个实例。可以通过@Scope注解指定prototype值将其声明为多例的,也可以将Bean声明为session级作用域、request级作用域等等,但最常用的还是默认的单例模式。
5.@PostConstruct、@PreDestroy用于声明Bean的生命周期。其中,被@PostConstruct修饰的方法将在Bean实例化后被调用,@PreDestroy修饰的方法将在容器销毁前被调用。
如何自己去定义注解(zdyzj)
Spring 中如果检测到说你的类被 @Component注解标记的话,Spring 容器在启动的时候就会把这个类归为自己管理,这样你就可以通过 @Autowired注解注入这个对象了。
第一步通过@interface声明注解:
第二步通过四种元注解修饰注解:
元注解的作用就是负责其他注解,java中一共有四个元注解,分别是@Target,@Retention,@Documented,@Inherited,下面先介绍以下四种注解的作用:
- @Target说明了注解所修饰的对象范围;
- @Retention:Retention定义了注解的保留范围;
- @Documented:Documented用于描述其它类型的annotation应该被作为被标注的程序成员的公共API,因此可以被例如javadoc此类的工具文档化。Documented是一个标记注解,没有成员。
- @Inherited:Inherited 元注解是一个标记注解,@Inherited阐述了某个被标注的类型是被继承的。如果一个使用了@Inherited修饰的annotation类型被用于一个class,则这个annotation将被用于该class的子类。
第三步使用注解,因为定义Target时定义了MEHTOD和FIELD,因此可以在属性和方法中使用这个注解:
第四步利用反射解析注解
@Autowired和@Resource注解有什么区别?(arqb)
@Autowired是Spring提供的注解,@Resource是JDK提供的注解。
@Autowired是只能按类型注入,@Resource默认按名称注入,也支持按类型注入。
@Autowired按类型装配依赖对象,默认情况下它要求依赖对象必须存在,如果允许null值,可以设置它required属性为false,如果我们想使用按名称装配,可以结合@Qualifier注解一起使用。@Resource有两个中重要的属性:name和type。name属性指定byName,如果没有指定name属性,当注解标注在字段上,即默认取字段的名称作为bean名称寻找依赖对象,当注解标注在属性的setter方法上,即默认取属性名作为bean名称寻找依赖对象。需要注意的是,@Resource如果没有指定name属性,并且按照默认的名称仍然找不到依赖对象时,
@Resource注解会回退到按类型装配。但一旦指定了name属性,就只能按名称装配了。
Spring如何管理事务(sgglsw)
-
Spring为事务管理提供了一致的编程模板,在高层次上建立了统一的事务抽象。也就是说,不管是选择MyBatis、Hibernate、JPA还是SpringJDBC,Spring都可以让用户以统一的编程模型进行事务管理。
Spring支持两种事务编程模型(swbcmx): -
编程式事务
Spring提供了TransactionTemplate模板,利用该模板我们可以通过编程的方式实现事务管理,而无需关注资源获取、复用、释放、事务同步及异常处理等操作。相对于声明式事务来说,这种方式相对麻烦一些,但是好在更为灵活,我们可以将事务管理的范围控制的更为精确。
-
声明式事务
Spring事务管理的亮点在于声明式事务管理,它允许我们通过声明的方式,在IoC配置中指定事务的边界和事务属性,Spring会自动在指定的事务边界上应用事务属性。相对于编程式事务来说,这种方式十分的方便,只需要在需要做事务管理的方法上,增加@Transactional注解,以声明事务特征即可。
Spring的事务如何配置,常用注解有哪些?(sgswpz)
事务的打开、回滚和提交是由事务管理器来完成的,我们使用不同的数据库访问框架,就要使用与之对应的事务管理器。在Spring Boot中,当你添加了数据库访问框架的起步依赖时,它就会进行自动配置,即自动实例化正确的事务管理器。
对于声明式事务,是使用@Transactional进行标注的。这个注解可以标注在类或者方法上。
当它标注在类上时,代表这个类所有公共(public)非静态的方法都将启用事务功能。
当它标注在方法上时,代表这个方法将启用事务功能。
另外,在@Transactional注解上,我们可以使用isolation属性声明事务的隔离级别,使用propagation属性声明事务的传播机制。
声明式事务:Spring事务管理的亮点在于声明式事务管理,它允许我们通过声明的方式,在IoC配置中指定事务的边界和事务属性,Spring会自动在指定的事务边界上应用事务属性。相对于编程式事务来说,这种方式十分的方便,只需要在需要做事务管理的方法上,增加@Transactional注解,以声明事务特征即可
说一说你知道的Spring MVC注解 (zjdc)
1.@RequestMapping:
作用:该注解的作用就是用来处理请求地址映射的,也就是说将其中的处理器方法映射到url路径上。
属性:
method:是让你指定请求的method的类型,比如常用的有get和post。
value:是指请求的实际地址,如果是多个地址就用{}来指定就可以啦。
produces:指定返回的内容类型,当request请求头中的Accept类型中包含指定的类型才可以返回的。
consumes:指定处理请求的提交内容类型,比如一些json、html、text等的类型。
headers:指定request中必须包含那些的headed值时,它才会用该方法处理请求的。
params:指定request中一定要有的参数值,它才会使用该方法处理请求。
2.@RequestParam:
作用:是将请求参数绑定到你的控制器的方法参数上,是Spring MVC中的接收普通参数的注解。
属性:
value是请求参数中的名称。
required是请求参数是否必须提供参数,它的默认是true,意思是表示必须提供。
3.@RequestBody:
作用:如果作用在方法上,就表示该方法的返回结果是直接按写入的Http responsebody中(一般在异步获取数据时使用的注解)。
属性:required,是否必须有请求体。它的默认值是true,在使用该注解时,值得注意的当为true时get的请求方式是报错的,如果你取值为false的话,get的请求是null。
4.@PathVaribale:
作用:该注解是用于绑定url中的占位符,但是注意,spring3.0以后,url才开始支持占位符的,它是Spring
MVC支持的rest风格url的一个重要的标志。
依赖注入的方式有几种,各是什么?(ylzr zrdc)
一、构造器注入 将被依赖对象通过构造函数的参数注入给依赖对象,并且在初始化对象的时候注
入。
优点: 对象初始化完成后便可获得可使用的对象。
缺点: 当需要注入的对象很多时,构造器参数列表将会很长; 不够灵活。若有多种注入方式,每种
方式只需注入指定几个依赖,那么就需要提供多个重载的构造函数,麻烦。
二、setter方法注入 IoC Service Provider通过调用成员变量提供的setter函数将被依赖对象注入给
依赖类。
优点: 灵活。可以选择性地注入需要的对象。
缺点: 依赖对象初始化完成后由于尚未注入被依赖对象,因此还不能使用。
三、接口注入 依赖类必须要实现指定的接口,然后实现该接口中的一个函数,该函数就是用于依赖
注入。该函数的参数就是要注入的对象。
优点 接口注入中,接口的名字、函数的名字都不重要,只要保证函数的参数是要注入的对象类型即
可。
缺点: 侵入行太强,不建议使用。
PS:什么是侵入行? 如果类A要使用别人提供的一个功能,若为了使用这功能,需要在自己的类中
增加额外的代码,这就是侵入性。
Spring应用上下文的生命周期(sgsxw)
Spring应用上下文就是ApplicationContext,生命周期主要体现在org.springframework.context.support.AbstractApplicationContext#refresh()方法中,大致如下:
Spring应用上下文启动准备阶段,设置相关属性,例如启动时间、状态标识、Environment对象。
BeanFactory初始化阶段,初始化一个BeanFactory对象,加载出BeanDefinition们;设置相关组件,例如ClassLoader类加载器、表达式语言处理器、属性编辑器,并添加几个BeanPostProcessor处理器。
BeanFactory后置处理阶段,主要是执行BeanFactoryPostProcessor和BeanDefinitionRegistryPostProcessor的处理,对BeanFActory和BeanDefinitionRegistry进行后置处理,这里属于Spring应用上下文的一个扩展点。
BeanFactory注册BeanPostProcessor阶段,主要初始化BeanPostProcessor类型的Bean(依赖查找),在Spring Bean生命周期的许多节点都能见到该类型的处理器。
初始化内建Bean阶段,初始化当前Spring应用上下文的MessageSource对象(国际化文案相关)、ApplicationEventMulticast而时间广播器对象,ThemeSource对象。
Spring时间监听器注册阶段,主要获取到所有的ApplicationListener时间监听器进行注册,并广播早期事件。
BeanFactory初始化完成阶段,主要是初始化所有还未初始化的Bean(不是抽象、单例模式、不是懒加载方式)。
Spring应用上下文刷新完成阶段,清除当前Spring应用上下文中的缓存,例如通过ASM(java字节码操作和分析框架)。
Spring 应用上下文启动阶段,需要主动调用 AbstractApplicationContext#start() 方法,会调用所有 Lifecycle 的 start() 方法,最后会发布上下文启动事件
Spring 应用上下文停止阶段,需要主动调用 AbstractApplicationContext#stop() 方法,会调用所有 Lifecycle 的 stop() 方法,最后会发布上下文停止事件
Spring 应用上下文关闭阶段,发布当前 Spring 应用上下文关闭事件,销毁所有的单例 Bean,关闭底层 BeanFactory 容器;注意这里会有一个钩子函数(Spring 向 JVM 注册的一个关闭当前 Spring 应用上下文的线程),当 JVM “关闭” 时,会触发这个线程的运行
Spring Boot/Spring Cloud(110)
什么是 spring boot?
SpringBoot是一个框架,简化了Spring众多框架中所需的大量且繁琐的配置文件,所以 SpringBoot是一个服务于框架的框架,服务范围是简化配置文件。
Spring Boot Starter有什么用(stsr)
Spring Boot通过提供众多起步依赖(Starter)降低项目依赖的复杂度。起步依赖本质上是一个Maven项目对象模型(Project Object Model, POM),定义了对其他库的传递依赖,这些东西加在一起即支持某项功能。很多起步依赖的命名都暗示了它们提供的某种或某类功能。
1.它整合了这个模块需要的依赖库
2.提供对模块的配置项给使用者
3.提供自动配置类对模块内的Bean进行自动装配
spring boot 配置文件有哪几种类型?它们有什么区别?
Spring Boot提供了两种常用的配置文件,分别是properties文件和yml文件。相对于properties文件而言,yml文件更年轻,也有很多的坑。yml通过空格来确定层级关系,使配置文件结构更清晰,但也会因为微不足道的空格而破坏了层级关系。
spring boot 有哪些方式可以实现热部署?
①. 使用spring loaded
②. 使用spring-boot-devtools
SpringBoot启动过程(stqdgc)
一.SpringBoot启动时通过执行main方法中的SpringApplication.run方法去启动,在run方法中调用了SpringApplication的构造方法,在该构造方法中加载了META-INFA\spring.factories文件配置的ApplicationContextInitializer的实现类和ApplicationListenerr的实现类
二、ApplicationContextInitializer 这个类当springboot上下文Context初始化完成后会调用。 ApplicationListener当springboot启动时事件change后都会触发。
三、SpringApplication实例构造完之后会调用它的run方法,在run方法中作了以下几步重要操作:
- 获取事件监听器SpringApplicationRunListener类型,并且执行starting()方法
- 准备环境,并且把环境跟spring上下文绑定好,并且执行environmentPrepared()方法
- 创建上下文,根据项目类型创建上下文
- 执行spring的启动流程扫描并且初始化单实列bean
四、通过@SpringBootApplication注解将ClassPath路径下所有的META-INF\spring.factories文件中的EnableAutoConfiguration实例注入到IOC容器中
jpa 和 hibernate 有什么区别?
JPA Java Persistence API,是Java EE 5的标准ORM接口,也是ejb3规范的一部分。
Hibernate,当今很流行的ORM框架,是JPA的一个实现,但是其功能是JPA的超集。
JPA和Hibernate之间的关系,可以简单的理解为JPA是标准接口,Hibernate是实现。那么Hibernate是如何实现与JPA的这种关系的呢。Hibernate主要是通过三个组件来实现的,及hibernate-annotation、hibernate-entitymanager和hibernate-core。
ibernate-annotation是Hibernate支持annotation方式配置的基础,它包括了标准的JPA annotation以及Hibernate自身特殊功能的annotation。
hibernate-core是Hibernate的核心实现,提供了Hibernate所有的核心功能。
hibernate-entitymanager实现了标准的JPA,可以把它看成hibernate-core和JPA之间的适配器,它并不直接提供ORM的功能,而是对hibernate-core进行封装,使得Hibernate符合JPA的规范。
什么是 spring cloud?什么是微服务?
Spring Cloud 是一套分布式微服务的技术解决方案,它提供了快速构建分布式系统的常用的一些组件
比如说配置管理、服务的注册与发现、服务调用的负载均衡、资源隔离、熔断降级等等
Spring Cloud Netflix 是基于 Netflix 这个公司的开源组件集成的一套微服务解决
方案,其中的组件有
- Ribbon——负载均衡
- Hystrix——服务熔断
- Zuul——网关
- Eureka——服务注册与发现
- Feign——服务调用
Spring Cloud Alibaba 是基于阿里巴巴开源组件集成的一套微服务解决方案,其
中包括 - Dubbo——消息通讯
- Nacos——服务注册与发现
- Seata——事务隔离
- Sentinel——熔断降级
有了 Spring Cloud 这样的技术生态,使得我们在落地微服务架构时,不用去考虑第三方技术集成带来额外成本,只要通过配置组件来完成架构下的技术问题,从而可以让我们更加侧重性能方面
服务治理的基础角色
服务注册中心:提供服务注册与发现的能力。
服务提供者:提供服务的应用,会把自己提供的服务注册到注册中心。
服务消费者:服务的消费者,从注册中心获取服务列表。
spring cloud 断路器的作用是什么?Hystrix
在Spring Cloud中使用了Hystrix来实现断路器的功能,断路器可以防止一个应用程序多次试图执行一个操作,即很可能失败,允许它继续而不等待故障恢复或者浪费 CPU周期,而它确定该故障是持久的。断路器模式也使应用程序能够检测故障是否已经解决,如果问题似乎已经得到纠正,应用程序可以尝试调用操作。
断路器增加了稳定性和灵活性,以一个系统,提供稳定性,而系统从故障中恢复,并尽量减少此故障的对性能的影响。它可以帮助快速地拒绝对一个操作,即很可能失败,而不是等待操作超时(或者不返回)的请求,以保持系统的响应时间。如果断路器提高每次改变状态的时间的事件,该信息可以被用来监测由断路器保护系统的部件的健康状况,或以提醒管理员当断路器跳闸,以在打开状态。
什么是自我保护机制?
在运行期间,注册中心会统计心跳失败比例在15分钟之内是否低于85%,如果低于的情况,注册中心会将
当前注册实例信息保护起来,不再删除这些实例信息,当网络恢复后,退出自我保护机制。
自我保护机制让服务集群更稳定、健壮。
spring cloud 的核心组件有哪些?
①. 服务发现——Netflix Eureka
一个RESTful服务,用来定位运行在AWS地区(Region)中的中间层服务。由两个组件组成:Eureka服务器和Eureka客户端。Eureka服务器用作服务注册服务器。Eureka客户端是一个java客户端,用来简化与服务器的交互、作为轮询负载均衡器,并提供服务的故障切换支持。Netflix在其生产环境中使用的是另外的客户端,它提供基于流量、资源利用率以及出错状态的加权负载均衡。
②. 客服端负载均衡——Netflix Ribbon
Ribbon,主要提供客户侧的软件负载均衡算法。Ribbon客户端组件提供一系列完善的配置选项,比如连接超时、重试、重试算法等。Ribbon内置可插拔、可定制的负载均衡组件。
③. 断路器——Netflix Hystrix
断路器可以防止一个应用程序多次试图执行一个操作,即很可能失败,允许它继续而不等待故障恢复或者浪费 CPU 周期,而它确定该故障是持久的。断路器模式也使应用程序能够检测故障是否已经解决。如果问题似乎已经得到纠正,应用程序可以尝试调用操作。
④. 服务网关——Netflix Zuul
类似nginx,反向代理的功能,不过netflix自己增加了一些配合其他组件的特性。
⑤. 分布式配置——Spring Cloud Config
这个还是静态的,得配合Spring Cloud Bus实现动态的配置更新。
Eureka和ZooKeeper都可以提供服务注册与发现的功能,请说说两个的区别(ezqb)
1.ZooKeeper保证的是CP,Eureka保证的是AP
ZooKeeper在选举期间注册服务瘫痪,虽然服务最终会恢复,但是选举期间不可用的
Eureka各个节点是平等关系,只要有一台Eureka就可以保证服务可用,而查询到的数据并不是最新的
自我保护机制会导致
- Eureka不再从注册列表移除因长时间没收到心跳而应该过期的服务
- Eureka仍然能够接受新服务的注册和查询请求,但是不会被同步到其他节点(高可用)
- 当网络稳定时,当前实例新的注册信息会被同步到其他节点中(最终一致性)
Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,而不会像ZooKeeper一样使得整个注册系统瘫痪
2.ZooKeeper有Leader和Follower角色,Eureka各个节点平等
3.ZooKeeper采用过半数存活原则,Eureka采用自我保护机制解决分区问题
4.Eureka本质上是一个工程,而ZooKeeper只是一个进程
Ribbon和Feign的区别?
1、Ribbon都是调用其他服务的,但方式不同。
2、启动类注解不同,Ribbon是@RibbonClient feign的是@EnableFeignClients
3、服务指定的位置不同,Ribbon是在@RibbonClient注解上声明,Feign则是在定义抽象方法的接口中使用@FeignClient声明。
4、调用方式不同,Ribbon需要自己构建http请求,模拟http请求然后使用RestTemplate发送给其他服务,步骤相当繁琐。Feign需要将调用的方法定义成抽象方法即可。
Ribbon负载均衡策略有哪些?@LoadBalanced(rndc)
提供云端负载均衡,有多种负载均衡策略可供选择,可配合服务发现和断路器使用。
RandomRule : 随机。
RoundRobinRule : 轮询。
RetryRule : 重试。
WeightedResponseTimeRule : 权重。
ClientConfigEnabledRoundRobinRule : 一般不用,通过继承该策略,默认的choose就实现了线性轮询
机制。可以基于它来做扩展。
BestAvailableRule : 通过便利负载均衡器中维护的所有服务实例,会过滤到故障的,并选择并发请求最
小的一个。
PredicateBasedRule : 先过滤清单,再轮询。
AvailabilityFilteringRule :继承了父类的先过滤清单,再轮询。调整了算法。
ZoneAvoidanceRule : 该类也是PredicateBasedRule的子类,它可以组合过滤条件。以
ZoneAvoidancePredicate为主过滤条件,以AvailabilityPredicate为次过滤条件。
REST 和RPC对比(rrqb)
1、RPC主要的缺陷是服务提供方和调用方式之间的依赖太强,需要对每一个微服务进行接口的定义,并通过持续继承发布,严格版本控制才不会出现冲突。
2、REST是轻量级的接口,服务的提供和调用不存在代码之间的耦合,只需要一个约定进行规范。
1、rest
REST是一种架构风格,指的是一组架构约束条件和原则。满足这些约束条件和原则的应用程序或设计就是 RESTful。REST规范把所有内容都视为资源,网络上一切皆资源。
REST并没有创造新的技术,组件或服务,只是使用Web的现有特征和能力。 可以完全通过HTTP协议实现,使用 HTTP 协议处理数据通信。REST架构对资源的操作包括获取、创建、修改和删除资源的操作正好对应HTTP协议提供的GET、POST、PUT和DELETE方法。
2、rpc
RPC(Remote Procedure Call)—远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序之间携带信息数据。在OSI网络通信模型中,RPC跨越了传输层和应用层,RPC使得开发包括网络分布式多程序在内的应用程序更加容易。
3、rest优缺点
1、优点:耦合性低,兼容性好,提高开发效率,不用关心接口实现细节,相对更规范,更标准,更通用,跨语言支持
2、缺点:性能不如 RPC 高。
4、rpc优缺点
1、优点:
—调用简单,清晰,透明,不用像 rest 一样复杂,就像调用本地方法一样简单。
—高效低延迟,性能高
—自定义协议(让传输报文提及更小)
—性能消耗低,高效的序列化协议可以支持高效的二进制传输
—自带负载均衡
2、缺点:
----耦合性强
例如:我们为每个微服务定义了各自的 service 抽象接口,并通过持续集成发布到私有仓库中,调用方应用对微服务提供的抽象接口存在强依赖关系,因此不论开发、测试、集成环境都需要严格的管理版本依赖,才不会出现服务方与调用方的不一致导致应用无法编译成功等一系列问题,以及这也会直接影响本地开发的环境要求,往往一个依赖很多服务的上层应用,每天都要更新很多代码并 install 之后才能进行后续的开发。若没有严格的版本管理制度或开发一些自动化工具,这样的依赖关系会成为开发团队的一大噩梦。
而 REST 接口相比 RPC 更为轻量化,服务提供方和调用方的依赖只是依靠一纸契约,不存在代码级别的强依赖,当然 REST 接口也有痛点,因为接口定义过轻,很容易导致定义文档与实际实现不一致导致服务集成时的问题,但是该问题很好解决,只需要通过每个服务整合swagger,让每个服务的代码与文档一体化,就能解决。所以在分布式环境下,REST 方式的服务依赖要比 RPC 方式的依赖更为灵活。
—无法跨语言,平台敏感
Java 写的 RPC 微服务无法给 Python 调用。需要再实现一层 REST 来对外提供服务
5、rest与rpc选择
RPC 适用于内网服务调用,对外提供服务请走 REST。
IO 密集的服务调用用 RPC,低频服务用 REST
服务调用过于密集与复杂,RPC 就比较适用
Spring Cloud 和dubbo区别(scqb)
1、服务调用方式 dubbo是RPC springcloud Rest Api
2、注册中心,dubbo 是zookeeper springcloud是eureka,也可以是zookeeper
3、服务网关,dubbo本身没有实现,只能通过其他第三方技术整合,springcloud有Zuul路由网关,作为路由服务器,进行消费者的请求分发,springcloud支持断路器,与git完美集成配置文件支持版本控制,事物总线实现配置文件的更新与服务自动装配等等一系列的微服务架构要素。
服务注册和发现是什么意思?Spring Cloud 如何实现?
当我们开始一个项目时,我们通常在属性文件中进行所有的配置。随着越来越多的服务开发和部署,添加和修改这些属性变得更加复杂。有些服务可能会下降,而某些位置可能会发生变化。手动更改属性可能会产生问题。
Eureka 服务注册和发现可以在这种情况下提供帮助。由于所有服务都在 Eureka 服务器上注册并通过调用 Eureka 服务器完成查找,因此无需处理服务地点的任何更改和处理。
实现:
1.服务发布时,指定对应的服务名,将服务注册到 注册中心(eureka zookeeper)
2.注册中心加@EnableEurekaServer,服务用@EnableDiscoveryClient,然后用ribbon或feign进行服务直接的调用发现。
什么是 Hystrix?它如何实现容错?
Hystrix 是一个延迟和容错库,旨在隔离远程系统,服务和第三方库的访问点,当出现故障是不可避免的故障时,停止级联故障并在复杂的分布式系统中实现弹性。通常对于使用微服 构开发的系统,涉及到许多微服务。这些微服务彼此协作。由于某些原因,employee-consumer 公开服务会引发异常。在这种情况下使用Hystrix 我们定义了一个回退方法。如果在公开服务中发生异常,则回退方法返回一些默认值。
Zuul有几种过滤器类型?分别是?
4种。
pre : 可以在请求被路由之前调用。适用于身份认证的场景,认证通过后再继续执行下面的流程。
route : 在路由请求时被调用。适用于灰度发布场景,在将要路由的时候可以做一些自定义的逻辑。
post :在 route 和 error 过滤器之后被调用。这种过滤器将请求路由到达具体的服务之后执行。适用于需要添加响应头,记录响应日志等应用场景。
error : 处理请求时发生错误时被调用。在执行过程中发送错误时会进入 error 过滤器,可以用来统一记录错误信息。
什么是Sleuth
日志收集工具包,封装了Dapper和log-based追踪以及Zipkin和HTrace操作,为SpringCloud应用实现
了一种分布式追踪解决方案。
可以方便的了解到每个采样的请求耗时,分析出哪些服务调用比较耗时。
对于程序未捕捉的异常,可以在集成Zipkin服务页面上看到。
识别调用比较频繁的服务,从而进行优化。
熔断器如何设计?(rdqsj)
在微服务架构中,为了方便系统的前期的开发以及后期升级、维护,提交工作效率,一般会将系统划分为多个服务单元。各个服务单元通过服务注册以及订阅的方式互相依赖。同时,在各个服务单元中,会出现服务间互相调用的情况。这就有可能因为网络问题或所依赖的服务单元自身故障造成调用失败。如果此时系统出现大量调用已出现故障的服务单元,最后会因为等待该单元响应而造成请求积压,最终导致整个系统出现瘫痪。
为了解决这个问题,在微服务架构中采用了熔断器技术。当一个服务单元出现故障无法响应请求时,微服务架构的熔断器会认为该服务已出现故障,对该服务单元进行隔离。当有其它业务单元调用该服务单元的请求时,熔断器会将请求隔离,并快速返回失败;而不再进行具体的请求工作。这样可以防止已出故障的服务单元出现请求积压,避免其它服务单元出现请求等待,最终造成整个系统瘫痪的问题。
熔断器本身就是一个状态机。
1.关闭状态:熔断器的初始化状态,该状态下允许请求通过。当失败超过阀值,转入打开状态,
2.打开状态:熔断状态,该状态下不允许请求通过,当进入该状态经过一段时间,进入半开状态。
3.半开状态:在半开状态期间,允许部分请求通过,在半开期间,观察失败状态是否超过阀值。如果没有超过进入关闭状态,如果超过了进入关闭状态。如此往复
熔断器的出现,大大提高了系统的稳定性及可用性。目前熔断器的开发过程,基本上分为三步:
第一步,定义本服务单元的接口类interface,该接口类定义了本服务单元的所有的服务接口。
第二步,实现服务单元的接口类,一般为实现类,并实现服务接口ihterface的所有方法;在方法体中,一般会调用其它服务单元的服务方法。
第三步,为了防止第二步因调用的服务单元出现故障造成请求积压,需要定义本服务单元各个服务方法的熔断器方法;因此熔断器处需要实现服务单元接口ihterface的所有服务方法。
因为熔断器主要处理请求失效后的快速隔离方法,熔断器里的方法基础是一致的,基本是实现日志记录、通知等功能。由于熔断器的方法需与服务单元的方法一致,因此随着系统的功能越来越丰富,服务单元的接口方法也会随之增加,这样熔断器实现方法的也必须同步增多。这样系统会增加非常多的重复代码,增加开发工作量,降低效率。
Spring Boot 常用注解汇总(stzj)
一、启动注解 @SpringBootApplication
查看源码可发现,@SpringBootApplication是一个复合注解,包含了@SpringBootConfiguration,@EnableAutoConfiguration,@ComponentScan这三个注解
@SpringBootConfiguration 注解,继承@Configuration注解,主要用于加载配置文件
@SpringBootConfiguration继承自@Configuration,二者功能也一致,标注当前类是配置类, 并会将当前类内声明的一个或多个以@Bean注解标记的方法的实例纳入到spring容器中,并且实例名就是方法名。
@EnableAutoConfiguration 注解,开启自动配置功能
@EnableAutoConfiguration可以帮助SpringBoot应用将所有符合条件的@Configuration配置都加载到当前SpringBoot创建并使用的IoC容器。借助于Spring框架原有的一个工具类:SpringFactoriesLoader的支持,@EnableAutoConfiguration可以智能的自动配置功效才得以大功告成
@ComponentScan 注解,主要用于组件扫描和自动装配
@ComponentScan的功能其实就是自动扫描并加载符合条件的组件或bean定义,最终将这些bean定义加载到容器中。我们可以通过basePackages等属性指定@ComponentScan自动扫描的范围,如果不指定,则默认Spring框架实现从声明@ComponentScan所在类的package进行扫描,默认情况下是不指定的,所以SpringBoot的启动类最好放在root package下。
二、Controller 相关注解
@Controller
控制器,处理http请求。
@RestController 复合注解
@RestController注解相当于@ResponseBody+@Controller合在一起的作用,RestController使用的效果是将方法返回的对象直接在浏览器上展示成json格式.
@RequestBody
通过HttpMessageConverter读取Request Body并反序列化为Object(泛指)对象
@RequestMapping
@RequestMapping 是 Spring Web 应用程序中最常被用到的注解之一。这个注解会将 HTTP 请求映射到 MVC 和 REST 控制器的处理方法上
@GetMapping用于将HTTP get请求映射到特定处理程序的方法注解
注解简写:@RequestMapping(value = “/say”,method = RequestMethod.GET)等价于:@GetMapping(value = “/say”)
@PostMapping用于将HTTP post请求映射到特定处理程序的方法注解
三、取请求参数值
@PathVariable:获取url中的数据
@RequestParam:获取请求参数的值
@RequestHeader 把Request请求header部分的值绑定到方法的参数上
@CookieValue 把Request header中关于cookie的值绑定到方法的参数上
四、注入bean相关
@Repository
DAO层注解,DAO层中接口继承JpaRepository<T,ID extends Serializable>,需要在build.gradle中引入相关jpa的一个jar自动加载。
@Service
@Service是@Component注解的一个特例,作用在类上
@Service注解作用域默认为单例
使用注解配置和类路径扫描时,被@Service注解标注的类会被Spring扫描并注册为Bean
@Service用于标注服务层组件,表示定义一个bean
@Service使用时没有传参数,Bean名称默认为当前类的类名,首字母小写
@Service(“serviceBeanId”)或@Service(value=”serviceBeanId”)使用时传参数,使用value作为Bean名字
@Scope作用域注解
@Scope作用在类上和方法上,用来配置 spring bean 的作用域,它标识 bean 的作用域
@Entity实体类注解
@Table(name =“数据库表名”),这个注解也注释在实体类上,对应数据库中相应的表。
@Id、@Column注解用于标注实体类中的字段,pk字段标注为@Id,其余@Column。
@Bean产生一个bean的方法
@Bean明确地指示了一种方法,产生一个bean的方法,并且交给Spring容器管理。支持别名@Bean(“xx-name”)
@Autowired 自动导入
@Autowired注解作用在构造函数、方法、方法参数、类字段以及注解上
@Autowired注解可以实现Bean的自动注入
@Component
把普通pojo实例化到spring容器中,相当于配置文件中的
虽然有了@Autowired,但是我们还是要写一堆bean的配置文件,相当麻烦,而@Component就是告诉spring,我是pojo类,把我注册到容器中吧,spring会自动提取相关信息。那么我们就不用写麻烦的xml配置文件了
Dubbo
什么是 Dubbo?它有哪些核心功能?(dodc)
Dubbo 是一款高性能、轻量级的开源 RPC 框架.
第一层的 Business 业务逻辑层由我们自己来提供接口和实现还有一些配置信息。
第二层的 RPC 调用的核心层负责封装和实现整个 RPC 的调用过程、负载均衡、
集群容错、代理等核心功能。
Remoting 则是对网络传输协议和数据转换的封装。
根据 Dubbo 官方文档的介绍,Dubbo 提供了六大核心能力
l 面向接口代理的高性能 RPC 调用。
l 智能容错和负载均衡。
l 服务自动注册和发现。
l 高度可扩展能力。
l 运行期流量调度。
l 可视化的服务治理与运维。
请详细说说 Dubbo 负载均衡的几种策略(dofzjh)
Dubbo 有五种负载策略:
第一种是加权随机:假设我们有一组服务器 servers = [A, B, C],他们对应的权
重为 weights = [5, 3, 2],权重总和为 10。现在把这些权重值平铺在一维坐标值
上,[0, 5) 区间属于服务器 A,[5, 8) 区间属于服务器 B,[8, 10) 区间属于服
务器 C。接下来通过随机数生成器生成一个范围在 [0, 10) 之间的随机数,然后
计算这个随机数会落到哪个区间上就可以了。
第二种是最小活跃数:每个服务提供者对应一个活跃数 active,初始情况下,
所有服务提供者活跃数均为 0。每收到一个请求,活跃数加 1,完成请求后则将
活跃数减 1。在服务运行一段时间后,性能好的服务提供者处理请求的速度更快,
因此活跃数下降的也越快,此时这样的服务提供者能够优先获取到新的服务请求。
第三种是一致性 hash:通过 hash 算法,把 provider 的 invoke 和随机节点生成
hash,并将这个 hash 投射到 [0, 2^32 - 1] 的圆环上,查询的时候根据 key 进
行 md5 然后进行 hash,得到第一个节点的值大于等于当前 hash 的 invoker。
第四种是加权轮询:比如服务器 A、B、C 权重比为 5:2:1,那么在 8 次请求中,
服务器 A 将收到其中的 5 次请求,服务器 B 会收到其中的 2 次请求,服务器 C
则收到其中的 1 次请求。
第五种是最短响应时间权重随机: 计算目标服务的请求的响应时间,根据响应
时间最短的服务,配置更高的权重进行随机访问。
Dubbo 的工作原理是什么样的?(dogzyl)
1.服务启动的时候,provider 和 consumer 根据配置信息,连接到注册中心
register,分别向注册中心注册和订阅服务
2.register 根据服务订阅关系,返回 provider 信息到 consumer,同时 consumer
会把 provider 信息缓存到本地。如果信息有变更,consumer 会收到来自 register
的推送
3.consumer 生成代理对象,同时根据负载均衡策略,选择一台 provider,同时
定时向 monitor 记录接口的调用次数和时间信息
4.拿到代理对象之后,consumer 通过代理对象发起接口调用
5.provider 收到请求后对数据进行反序列化,然后通过代理调用具体的接口实现
Dubbo 与 Spring Cloud 的区别吧(dsqb)
Dubbo 是 SOA 时代的产物,它的关注点主要在于服务的调用,流量分发、流量监控和熔断。而 Spring Cloud 诞生于微服务架构时代,考虑的是微服务治理的方方面面,另外由于依托了 Spirng、Spirng Boot 的优势之上,两个框架在开始目标就不一致,Dubbo 定位服务治理、Spirng Cloud 是一个生态。两者最大的区别是 Dubbo 底层是使用 Netty 这样的 NIO 框架,是基于 TCP协议传输的,配合以 Hession 序列化完成 RPC 通信。而 SpringCloud 是基于 Http 协议+Rest 接口调用远程过程的通信,相对来说,Http 请求会有更大的报文,占的带宽也会更多。但是 REST 相比 RPC 更为灵活,服务提供方和调用方的依赖只依靠一纸契约,不存在代码级别的强依赖。
Dubbo 的服务请求失败怎么处理?(doqqsb)
对于 Dubbo 服务请求失败的场景,默认提供了重试的容错机制,也就是说,如果基于 Dubbo 进行服务间通信出现异常,服务消费者会对服务提供者集群中其他的节点发起重试,确保这次请求成功,默认的额外重试次数是 2 次。要注意的是,默认基于重试策略的容错机制中,需要注意幂等性的处理,否则在事务型的操作中,容易出现多次数据变更的问题。
快速失败策略,服务消费者只发起一次请求,如果请求失败,就直接把错误抛出去。这种比较适合在非幂等性场景中使用
失败安全策略,如果出现服务通信异常,直接把这个异常吞掉不做任何处理
失败自动恢复策略,后台记录失败请求,然后通过定时任务来对这个失败的请求进行重发。
并行调用多个服务策略,就是把这个消息广播给服务提供者集群,只要有任何一个节点返回,就表示请求执行成功。
广播调用策略,逐个调用服务提供者集群,只要集群中任何一个节点出现异常,就表示本次请求失败
Hibernate(111)
为什么要使用 hibernate?
对JDBC访问数据库的代码做了封装,大大简化了数据访问层繁琐的重复性代码。
Hibernate是一个基于JDBC的主流持久化框架,是一个优秀的ORM实现。他很大程度的简化DAO层的编码工作
hibernate使用Java反射机制,而不是字节码增强程序来实现透明性。
hibernate的性能非常好,因为它是个轻量级框架。映射的灵活性很出色。它支持各种关系数据库,从一对一到多对多的各种复杂关系。
什么是 ORM 框架?
对象-关系映射(Object-Relational Mapping,简称ORM),面向对象的开发方法是当今企业级应用开发环境中的主流开发方法,关系数据库是企业级应用环境中永久存放数据的主流数据存储系统。对象和关系数据是业务实体的两种表现形式,业务实体在内存中表现为对象,在数据库中表现为关系数据。内存中的对象之间存在关联和继承关系,而在数据库中,关系数据无法直接表达多对多关联和继承关系。因此,对象-关系映射(ORM)系统一般以中间件的形式存在,主要实现程序对象到关系数据库数据的映射.
hibernate 有几种查询方式?
hql查询
sql查询
条件查询
hibernate 实体类可以被定义为 final 吗?
可以将Hibernate的实体类定义为final类,但这种做法并不好。因为Hibernate会使用代理模式在延迟关联的情况下提高性能,如果你把实体类定义成final类之后,因为Java不允许对final类进行扩展,所以Hibernate就无法再使用代理了,如此一来就限制了使用可以提升性能的手段。不过,如果你的持久化类实现了一个接口而且在该接口中声明了所有定义于实体类中的所有public的方法轮到话,你就能够避免出现前面所说的不利后果。
在 hibernate 中使用 Integer 和 int 做映射有什么区别?
在Hibernate中,如果将OID定义为Integer类型,那么Hibernate就可以根据其值是否为null而判断一个对象是否是临时的,如果将OID定义为了int类型,还需要在hbm映射文件中设置其unsaved-value属性为0。
get()和 load()的区别?
load() 没有使用对象的其他属性的时候,没有SQL 延迟加载
get() 没有使用对象的其他属性的时候,也生成了SQL 立即加载
说一下 hibernate 的缓存机制?
Hibernate中的缓存分为一级缓存和二级缓存。
一级缓存就是 Session 级别的缓存,在事务范围内有效是,内置的不能被卸载。
二级缓存是SesionFactory级别的缓存,从应用启动到应用结束有效。是可选的,默认没有二级缓存,需要手动开启。保存数据库后,缓存在内存中保存一份,如果更新了数据库就要同步更新。
hibernate 对象有哪些状态?
hibernate里对象有三种状态:
Transient(瞬时):对象刚new出来,还没设id,设了其他值。
Persistent(持久):调用了save()、saveOrUpdate(),就变成Persistent,有id。
etached(脱管):当session close()完之后,变成Detached。
在 hibernate 中 getCurrentSession 和 openSession 的区别是什么?
openSession 从字面上可以看得出来,是打开一个新的session对象,而且每次使用都是打开一个新的session,假如连续使用多次,则获得的session不是同一个对象,并且使用完需要调用close方法关闭session。
getCurrentSession ,从字面上可以看得出来,是获取当前上下文一个session对象,当第一次使用此方法时,会自动产生一个session对象,并且连续使用多次时,得到的session都是同一个对象,这就是与openSession的区别之一,简单而言,getCurrentSession 就是:如果有已经使用的,用旧的,如果没有,建新的。
注意:在实际开发中,往往使用getCurrentSession多,因为一般是处理同一个事务(即是使用一个数据库的情况),所以在一般情况下比较少使用openSession或者说openSession是比较老旧的一套接口了。
hibernate 实体类必须要有无参构造函数吗?为什么?
必须,因为hibernate框架会调用这个默认构造方法来构造实例对象,即Class类的newInstance方法,这个方法就是通过调用默认构造方法来创建实例对象的。
另外再提醒一点,如果你没有提供任何构造方法,虚拟机会自动提供默认构造方法(无参构造器),但是如果你提供了其他有参数的构造方法的话,虚拟机就不再为你提供默认构造方法,这时必须手动把无参构造器写在代码里,否则new Xxxx()是会报错的,所以默认的构造方法不是必须的,只在有多个构造方法时才是必须的,这里“必须”指的是“必须手动写出来”。
Mybatis(112)
mybatis 中 #{}和 ${}的区别是什么?
1、#{}是预编译处理,$ {}是字符串替换。
2、MyBatis在处理#{}时,会将SQL中的#{}替换为?号,使用PreparedStatement的set方法来赋值;MyBatis在处理
$ { } 时,就是把 ${ } 替换成变量的值。3、使用 #{} 可以有效的防止SQL注入,提高系统安全性。
既然 ${}不安全,为什么还需要 ${},什么时候会用到它?:它可以解决一些特殊情况下的问题。例如,在一些动态表格(根据不同的条件产生不同的动态列)中,我们要传递SQL的列名,根据某些列进行排序,或者传递列名给SQL都是比较常见的场景,这就无法使用预编译的方式了
MyBatis 使用了哪些设计模式 (mssjms)
-
1.工厂模式 工厂模式想必都比较熟悉,它是 Java 中最常用的设计模式之一。工厂模式就是提供一个工厂类,当有客户端需要调用的时候,只调用这个工厂类就可以得到自己想要的结果,从而无需关注某类的具体实现过程。这就好比你去餐馆吃饭,可以直接点菜,而不用考虑厨师是怎么做的。
工厂模式在 MyBatis 中的典型代表是 SqlSessionFactory。
SqlSession 是 MyBatis 中的重要 Java 接口,可以通过该接口来执行 SQL 命令、获取映射器示例和管理事务,而SqlSessionFactory 正是用来产生 SqlSession 对象的,所以它在 MyBatis 中是比较核心的接口之一。工厂模式应用解析:SqlSessionFactory 是一个接口类,它的子类 DefaultSqlSessionFactory 有一个
openSession(ExecutorType execType) 的方法,其中使用了工厂模式 建造者模式在 MyBatis
中的典型代表是 SqlSessionFactoryBuilder。 -
2.建造者模式(Builder) 普通的对象都是通过 new 关键字直接创建的,但是如果创建对象需要的构造参数很多,且不能保证每个参数都是正确的或者不能一次性得到构建所需的所有参数,那么就需要将构建逻辑从对象本身抽离出来,让对象只关注功能,把构建交给构建类,这样可以简化对象的构建,也可以达到分步构建对象的目的,而
SqlSessionFactoryBuilder 的构建过程正是如此。在 SqlSessionFactoryBuilder 中构建 SqlSessionFactory 对象的过程是这样的,首先需要通过
XMLConfigBuilder 对象读取并解析 XML 的配置文件,然后再将读取到的配置信息存入到 Configuration
类中,然后再通过 build 方法生成需要的 DefaultSqlSessionFactory 对象 -
3.单例模式 单例模式(Singleton Pattern)是 Java 中最简单的设计模式之一,此模式保证某个类在运行期间,只有一个实例对外提供服务,而这个类被称为单例类。
单例模式也比较好理解,比如一个人一生当中只能有一个真实的身份证号,每个收费站的窗口都只能一辆车子一辆车子的经过,类似的场景都是属于单例模式。
单例模式在 MyBatis 中的典型代表是 ErrorContext。
ErrorContext 是线程级别的的单例,每个线程中有一个此对象的单例,用于记录该线程的执行环境的错误信息。 -
4.适配器模式 适配器模式是指将一个不兼容的接口转换成另一个可以兼容的接口,这样就可以使那些不兼容的类可以一起工作。
例如,最早之前我们用的耳机都是圆形的,而现在大多数的耳机和电源都统一成了方形的 typec
接口,那之前的圆形耳机就不能使用了,只能买一个适配器把圆形接口转化成方形的 而这个转换头就相当于程序中的适配器模式,适配器模式在MyBatis 中的典型代表是 Log。
MyBatis 中的日志模块适配了以下多种日志类型:
SLF4J
Apache Commons Logging
Log4j 2
Log4j
JDK logging
mybatis 有几种分页方式?(msfy)
- Mybatis使用RowBounds对象进行分页,它是针对ResultSet结果集执行的内存分页,而非物理分
页。可以在sql内直接拼写带有物理分页的参数来完成物理分页功能,也可以使用分页插件来完成物理分页,比如:MySQL数据的时候,在原有SQL后面拼写limit。 - 分页插件的基本原理是使用Mybatis提供的插件接口,实现自定义插件,在插件的拦截方法内拦截
待执行的sql,然后重写sql,根据dialect方言,添加对应的物理分页语句和物理分页参数。
mybatis 逻辑分页和物理分页的区别是什么?
物理分页速度上并不一定快于逻辑分页,逻辑分页速度上也并不一定快于物理分页。
物理分页总是优于逻辑分页:没有必要将属于数据库端的压力加诸到应用端来,就算速度上存在优势,然而其它性能上的优点足以弥补这个缺点。
mybatis 是否支持延迟加载?延迟加载的原理是什么?(msycjz)
Mybatis仅支持association关联对象和collection关联集合对象的延迟加载,association指的就是一对一,collection指的就是一对多查询。在Mybatis配置文件中,可以配置是否启用延迟加载lazyLoadingEnabled=true|false。
它的原理是,使用CGLIB创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,比如调用a.getB().getName(),拦截器invoke()方法发现a.getB()是null值,那么就会单独发送事先保存好的查询关联B对象的sql,把B查询上来,然后调用a.setB(b),于是a的对象b属性就有值了,接着完成a.getB().getName()方法的调用。这就是延迟加载的基本原理。
当然了,不光是Mybatis,几乎所有的包括Hibernate,支持延迟加载的原理都是一样的。
说一下 mybatis 的一级缓存和二级缓存?(mshcjz)
-
一级缓存: 基于 PerpetualCache 的 HashMap 本地缓存,其存储作用域为 Session,当 Session flush或 close 之后,该 Session 中的所有 Cache 就将清空,默认打开一级缓存。
-
二级缓存与一级缓存其机制相同,默认也是采用 PerpetualCache,HashMap 存储,不同在于其存储作用域为Mapper(Namespace),并且可自定义存储源,如Ehcache。默认不打开二级缓存,要开启二级缓存,使用二级缓存属性类需要实现Serializable序列化接口(可用来保存对象的状态),可在它的映射文件中配置; 对于缓存数据更新机制,当某一个作用域(一级缓存 Session/二级缓存Namespaces)的进行了C/U/D 操作后,默认该作用域下所有 select 中的缓存将被 clear。
mybatis 和 hibernate 的区别有哪些?(mhqb)
(1)Mybatis和hibernate不同,它不完全是一个ORM框架,因为MyBatis需要程序员自己编写Sql语句。
(2)Mybatis直接编写原生态sql,可以严格控制sql执行性能,灵活度高,非常适合对关系数据模型要求不高的软件开发,因为这类软件需求变化频繁,一但需求变化要求迅速输出成果。但是灵活的前提是mybatis无法做到数据库无关性,如果需要实现支持多种数据库的软件,则需要自定义多套sql映射文件,工作量大。
(3)Hibernate对象/关系映射能力强,数据库无关性好,对于关系模型要求高的软件,如果用hibernate开发可以节省很多代码,提高效率。
mybatis 有哪些执行器(Executor)?(mszxq)
Mybatis有三种基本的执行器(Executor):
- SimpleExecutor:每执行一次update或select,就开启一个Statement对象,用完立刻关闭Statement对象。
- ReuseExecutor:执行update或select,以sql作为key查找Statement对象,存在就使用,不存在就创建,用完后,不关闭Statement对象,而是放置于Map内,供下一次使用。简言之,就是重复使用Statement对象。
- BatchExecutor:执行update(没有select,JDBC批处理不支持select),将所有sql都添加到批处理中(addBatch()),等待统一执行(executeBatch()),它缓存了多个Statement对象,每个Statement对象都是addBatch()完毕后,等待逐一执行executeBatch()批处理。与JDBC批处理相同。
mybatis 如何编写一个自定义插件?(mszdycj)
Mybatis自定义插件针对Mybatis四大对象(Executor、StatementHandler 、ParameterHandler 、ResultSetHandler )进行拦截,具体拦截方式为:
Executor:拦截执行器的方法(log记录)
StatementHandler :拦截Sql语法构建的处理
ParameterHandler :拦截参数的处理
ResultSetHandler :拦截结果集的处理
Mybatis自定义插件必须实现Interceptor接口:
intercept方法:拦截器具体处理逻辑方法
plugin方法:根据签名signatureMap生成动态代理对象
setProperties方法:设置Properties属性
页面报400错误是什么意思?
400状态码标识请求的语义有误,当前请求无法被服务器理解。除非进行修改,否则客户端不应该重复提交这个请求。通常情况下,是本次请求中包含有错误的参数,此时应该排查前端传递的参数。
请求数据出现乱码该怎么处理?(lmdc)
服务端出现请求乱码的原因是,客户端编码与服务器解码方案不一致,可以有如下几种解决办法:
1.将获得的数据按照客户端编码转成BYTE,再将BYTE按服务端编码转成字符串,这种方案对各种请求方式均有效,但是十分的麻烦。
2.在接受请求数据之前,显示声明实体内容的编码与服务器一致,这种方式只对POST请求有效。
3.修改服务器的配置文件,显示声明请求路径的编码与服务器一致,这种方式只对GET请求有效。
了解Spring Boot JPA吗?
JPA即Java Persistence API,它是一个基于O/R映射的标准规范。也就是说它指定以了标准规则,不提供实现,软件提供商可以按照标准规范来实现,而使用者只需按照规范中定义的方式来使用,不用和软件提供商打交道。JPA主要实现有Hibernate、EclipseLink、OpenJPA等,我们使用JPA来开发,无论是采用哪一种实现方式都一样。
RabbitMQ(113)
消息丢列的使用场景有哪些?(xxdlds)
概述:消息队列中间件是分布式系统中重要的组件,主要解决应用耦合,异步消息,流量削锋等问题。实现高性能,高可用,可伸缩和最终一致性架构。是大型分布式系统不可缺少的中间件。
①.
跨系统的异步通信,所有需要异步交互的地方都可以使用消息队列。就像我们除了打电话(同步)以外,还需要发短信,发电子邮件(异步)的通讯方式。②.
多个应用之间的耦合,由于消息是平台无关和语言无关的,而且语义上也不再是函数调用,因此更适合作为多个应用之间的松耦合的接口。基于消息队列的耦合,不需要发送方和接收方同时在线。在企业应用集成(EAI)中,文件传输,共享数据库,消息队列,远程过程调用都可以作为集成的方法。场景说明:用户下单后,订单系统需要通知库存系统。传统的做法是,订单系统调用库存系统的接口。传统模式的缺点:
1) 假如库存系统无法访问,则订单减库存将失败,从而导致订单失败;
2) 订单系统与库存系统耦合;
引入应用消息队列后的方案:
- 订单系统:用户下单后,订单系统完成持久化处理,将消息写入消息队列,返回用户订单下单成功。
- 库存系统:订阅下单的消息,采用拉/推的方式,获取下单信息,库存系统根据下单信息,进行库存操作。
- 假如:在下单时库存系统不能正常使用。也不影响正常下单,因为下单后,订单系统写入消息队列就不再关心其他的后续操作了。实现订单系统与库存系统的应用解耦。
③.
应用内的同步变异步,比如订单处理,就可以由前端应用将订单信息放到队列,后端应用从队列里依次获得消息处理,高峰时的大量订单可以积压在队列里慢慢处理掉。由于同步通常意味着阻塞,而大量线程的阻塞会降低计算机的性能。④.
消息驱动的架构(EDA),系统分解为消息队列,和消息制造者和消息消费者,一个处理流程可以根据需要拆成多个阶段(Stage),阶段之间用队列连接起来,前一个阶段处理的结果放入队列,后一个阶段从队列中获取消息继续处理。⑤. 应用需要更灵活的耦合方式,如发布订阅,比如可以指定路由规则。
⑥. 跨局域网,甚至跨城市的通讯(CDN行业),比如北京机房与广州机房的应用程序的通信。
(7)流量削锋
流量削锋也是消息队列中的常用场景,一般在秒杀或团抢活动中使用广泛。
应用场景:秒杀活动,一般会因为流量过大,导致流量暴增,应用挂掉。为解决这个问题,一般需要在应用前端加入消息队列。可以控制活动的人数;可以缓解短时间内高流量压垮应用;
用户的请求,服务器接收后,首先写入消息队列。假如消息队列长度超过最大数量,则直接抛弃用户请求或跳转到错误页面;
秒杀业务根据消息队列中的请求信息,再做后续处理。
(8)日志处理
日志处理是指将消息队列用在日志处理中,比如Kafka的应用,解决大量日志传输的问题
日志采集客户端,负责日志数据采集,定时写受写入Kafka队列;
Kafka消息队列,负责日志数据的接收,存储和转发;
日志处理应用:订阅并消费kafka队列中的日志数据;
以下是新浪kafka日志处理应用案例
(1)Kafka:接收用户日志的消息队列。
(2)Logstash:做日志解析,统一成JSON输出给Elasticsearch。
(3)Elasticsearch:实时日志分析服务的核心技术,一个Schemaless,实时的数据存储服务,通过index组织数据,兼具强大的搜索和统计功能。
(4)Kibana:基于Elasticsearch的数据可视化组件,超强的数据可视化能力是众多公司选择ELK stack的重要原因。
(9)消息通讯
消息通讯是指,消息队列一般都内置了高效的通信机制,因此也可以用在纯的消息通讯。比如实现点对点消息队列,或者聊天室等。
rabbitmq 有哪些重要的角色?
RabbitMQ 中重要的角色有:生产者、消费者和代理:
生产者:消息的创建者,负责创建和推送数据到消息服务器;
消费者:消息的接收方,用于处理数据和确认消息;
代理:就是 RabbitMQ 本身,用于扮演“快递”的角色,本身不生产消息,只是扮演“快递”的角色。
rabbitmq 有哪些重要的组件?
ConnectionFactory(连接管理器):应用程序与Rabbit之间建立连接的管理器,程序代码中使用。
Channel(信道):消息推送使用的通道。
Exchange(交换器):用于接受、分配消息。
Queue(队列):用于存储生产者的消息。
RoutingKey(路由键):用于把生成者的数据分配到交换器上。
BindingKey(绑定键):用于把交换器的消息绑定到队列上。
rabbitmq 中 vhost 的作用是什么?
vhost 可以理解为虚拟 broker ,即 mini-RabbitMQ server。其内部均含有独立的 queue、exchange
和 binding 等,但最最重要的是,其拥有独立的权限系统,可以做到 vhost 范围的用户控制。当然,从 RabbitMQ 的全局角度,vhost 可以作为不同权限隔离的手段(一个典型的例子就是不同的应用可以跑在不同的 vhost 中)。
rabbitmq 的消息是怎么发送的?
首先客户端必须连接到 RabbitMQ 服务器才能发布和消费消息,客户端和 rabbit server 之间会创建一个 tcp 连接,一旦tcp 打开并通过了认证(认证就是你发送给 rabbit 服务器的用户名和密码),你的客户端和 RabbitMQ 就创建了一条 amqp 信道(channel),信道是创建在“真实” tcp 上的虚拟连接,amqp 命令都是通过信道发送出去的,每个信道都会有一个唯一的id,不论是发布消息,订阅队列都是通过这个信道完成的。
rabbitmq 怎么保证消息的稳定性?
提供了事务的功能。
通过将 channel 设置为 confirm(确认)模式。
rabbitmq 怎么避免消息丢失?
首先在如下三个部分都可能会出现丢失消息的情况:
Producer端
Broker端
Consumer端
1 、Producer端如何保证消息不丢失
采取send()同步发消息,发送结果是同步感知的。
发送失败后可以重试,设置重试次数。默认3次。
集群部署,比如发送失败了的原因可能是当前Broker宕机了,重试的时候会发送到其他Broker上。
2、Broker端如何保证消息不丢失
修改刷盘策略为同步刷盘。默认情况下是异步刷盘的。
集群部署,主从模式,高可用。
3、Consumer端如何保证消息不丢失
完全消费正常后在进行手动ack确认。
要保证消息持久化成功的条件有哪些?
声明队列必须设置持久化 durable 设置为 true.
消息推送投递模式必须设置持久化,deliveryMode 设置为 2(持久)。
消息已经到达持久化交换器。
消息已经到达持久化队列。
以上四个条件都满足才能保证消息持久化成功。
rabbitmq 持久化有什么缺点?
持久化的缺地就是降低了服务器的吞吐量,因为使用的是磁盘而非内存存储,从而降低了吞吐量。可尽量使用 ssd 硬盘来缓解吞吐量的问题。
rabbitmq 有几种广播类型?
三种广播模式:
fanout: 所有bind到此exchange的queue都可以接收消息(纯广播,绑定到RabbitMQ的接受者都能收到消息);
direct: 通过routingKey和exchange决定的那个唯一的queue可以接收消息;
topic:所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息;
rabbitmq 怎么实现延迟消息队列?
通过消息过期后进入死信交换器,再由交换器转发到延迟消费队列,实现延迟功能;
使用 RabbitMQ-delayed-message-exchange 插件实现延迟功能。
.rabbitmq 集群有什么用?
集群主要有以下两个用途:
高可用:某个服务器出现问题,整个 RabbitMQ 还可以继续使用;
高容量:集群可以承载更多的消息量。
rabbitmq 节点类型有哪些?
磁盘节点:消息会存储到磁盘。
内存节点:消息都存储在内存中,重启服务器消息丢失,性能高于磁盘类型。
rabbitmq 集群搭建需要注意哪些问题?
各节点之间使用“–link”连接,此属性不能忽略。
各节点使用的 erlang cookie 值必须相同,此值相当于“秘钥”的功能,用于各节点的认证。
整个集群中必须包含一个磁盘节点。
rabbitmq 每个节点是其他节点的完整拷贝吗?为什么?
不是,原因有以下两个:
存储空间的考虑:如果每个节点都拥有所有队列的完全拷贝,这样新增节点不但没有新增存储空间,反而增加了更多的冗余数据;
性能的考虑:如果每条消息都需要完整拷贝到每一个集群节点,那新增节点并没有提升处理消息的能力,最多是保持和单节点相同的性能甚至是更糟。
rabbitmq 集群中唯一一个磁盘节点崩溃了会发生什么情况?
如果唯一磁盘的磁盘节点崩溃了,不能进行以下操作:
不能创建队列
不能创建交换器
不能创建绑定
不能添加用户
不能更改权限
不能添加和删除集群节点
唯一磁盘节点崩溃了,集群是可以保持运行的,但你不能更改任何东西。
rabbitmq 对集群节点停止顺序有要求吗?
RabbitMQ 对集群的停止的顺序是有要求的,应该先关闭内存节点,最后再关闭磁盘节点。如果顺序恰好相反的话,可能会造成消息的丢失。
Kafka(114)
Kafka底层(kadc)
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群机来提供实时的消费。
Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性:
通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。(文件追加的方式写入数据,过期的数据定期删除)
高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
支持通过Kafka服务器和消费机集群来分区消息。
支持Hadoop并行数据加载。
Kafka使用场景?为什么用?为什么吞吐量高?(kasycj)
消息系统或是说消息队列中间件是当前处理大数据一个非常重要的组件,用来解决应用解耦、异步通信、流量控制等问题,从而构建一个高效、灵活、消息同步和异步传输处理、存储转发、可伸缩和最终一致性的稳定系统。当前比较流行的消息中间件有Kafka、RocketMQ、RabbitMQ、ZeroMQ、ActiveMQ、MetaMQ、Redis等,这些消息中间件在性能及功能上各有所长。如何选择一个消息中间件取决于我们的业务场景、系统运行环境、开发及运维人员对消息中件间掌握的情况等。我认为在下面这些场景中,Kafka是一个不错的选择。
(1)消息系统。Kafka作为一款优秀的消息系统,具有高吞吐量、内置的分区、备份冗余分布式等特点,为大规模消息处理提供了一种很好的解决方案。
(2)应用监控。利用Kafka采集应用程序和服务器健康相关的指标,如CPU占用率、IO、内存、连接数、TPS、QPS等,然后将指标信息进行处理,从而构建一个具有监控仪表盘、曲线图等可视化监控系统。例如,很多公司采用Kafka与ELK(ElasticSearch、Logstash和Kibana)整合构建应用服务监控系统。
(3)网站用户行为追踪。为了更好地了解用户行为、操作习惯,改善用户体验,进而对产品升级改进,将用户操作轨迹、内容等信息发送到Kafka集群上,通过Hadoop、Spark或Strom等进行数据分析处理,生成相应的统计报告,为推荐系统推荐对象建模提供数据源,进而为每个用户进行个性化推荐。
(4)流处理。需要将已收集的流数据提供给其他流式计算框架进行处理,用Kafka收集流数据是一个不错的选择,而且当前版本的Kafka提供了Kafka Streams支持对流数据的处理。
(5)持久性日志。Kafka可以为外部系统提供一种持久性日志的分布式系统。日志可以在多个节点间进行备份,Kafka为故障节点数据恢复提供了一种重新同步的机制。同时,Kafka很方便与HDFS和Flume进行整合,这样就方便将Kafka采集的数据持久化到其他外部系统。
使用kafka的理由:
1.分布式,高吞吐量,速度快(kafka是直接通过磁盘存储,线性读写,速度快:避免了数据在JVM内存和系统内存之间的复制,减少耗性能的对象创建和垃圾回收)
2.同时支持实时和离线两种解决方案(相信很多项目都有类似的需求,这也是Linkedin的官方架构,我们是一部分数据通过storm做实时计算处理,一部分到hadoop做离线分析)。
3.open source (open source 谁不喜欢呢)
4.源码由scala编写,可以运行在JVM上(笔者对scala很有好感,函数式语言一直都挺帅的,spark也是由scala写的,看来以后有空得刷刷scala)
使用场景:
笔者主要是用来做日志分析系统,其实Linkedin也是这么用的,可能是因为kafka对可靠性要求不是特别高,除了日志,网站的一些浏览数据应该也适用。(只要原始数据不需要直接存DB的都可以)
Kafka 消息数据积压,消费能力不足怎么处理?(kaxxjy)
1)可以考虑增加Topic的分区数,并且同时提升消费组的消费者数量,消费者数=分区数。(两者缺一不可)
2)如果是下游的数据处理不及时:提高每批次拉取的数量。批次拉取数据过少(拉取数据/处理时间<生产速度),使处理的数据小于生产的数据,也会造成数据积压。
Kafka 有哪些情形会造成重复消费?
消费者消费后没有commit offset(程序崩溃/强行kill/消费耗时/自动提交偏移情况下unscrible)
那些情景会造成消息漏消费?
先提交offset,后消费,有可能造成数据的重复
Kafka中的ISR、AR又代表什么?☆☆☆☆☆
ISR:与leader保持同步的follower集合(保持所有同步的副本包括leader)
AR:分区的所有副本
Kafka中的HW、LEO等分别代表什么? ☆☆☆☆☆
LEO:每个副本的最后一条消息的offset
HW:一个分区中所有副本最小的offset
Kafka中的分区器、序列化器、拦截器是否了解?它们之间的处理顺序是什么?☆☆☆
拦截器 -> 序列化器 -> 分区器
当你使用kafka-topics.sh创建(删除)了一个topic之后,Kafka背后会执行什么逻辑? ☆☆☆
1)会在zookeeper中的/brokers/topics节点下创建一个新的topic节点,如:/brokers/topics/first
2)触发Controller的监听程序
3)kafka Controller 负责topic的创建工作,并更新metadata cache
topic的分区数可不可以增加?如果可以怎么增加?如果不可以,那又是为什么?☆☆☆☆☆
可以增加
bin/kafka-topics.sh --zookeeper localhost:2181/kafka --alter --topic topic-config --partitions 3
不可以减少,被删除的分区数据难以处理。
Kafka有内部的topic吗?如果有是什么?有什么所用? ☆☆☆☆
__consumer_offsets,保存消费者offset
Kafka分区分配的概念? ☆☆☆☆☆
一个topic多个分区,一个消费者组多个消费者,故需要将分区分配个消费者(roundrobin、range)
Kafka中有那些地方需要选举?这些地方的选举策略又有哪些?☆☆☆☆☆
partition leader(ISR),controller(先到先得)
Kafka怎么保证高吞吐量的?(kagttl)
-
1.顺序读写 Kafka操作的是序列文件I / O(序列文件的特征是按顺序写,按顺序读),为保证顺序,Kafka强制点对点的按顺序传递消息,这意味着,一个consumer在消息流(或分区)中只有一个位置。
-
2.零拷贝 在这之前先来了解一下零拷贝(直接让操作系统的 Cache 中的数据发送到网卡后传输给下游的消费者):平时从服务器读取静态文件时,服务器先将文件从复制到内核空间,再复制到用户空间,最后再复制到内核空间并通过网卡发送出去,而零拷贝则是直接从内核到内核再到网卡,省去了用户空间的复制。
Kafka把所有的消息存放到一个文件中,当消费者需要数据的时候直接将文件发送给消费者,比如10W的消息共10M,全部发送给消费者,10M的消息在内网中传输是非常快的,假如需要1s,那么kafka的tps就是10w。Zero copy对应的是Linux中sendfile函数,这个函数会接受一个offsize来确定从哪里开始读取。现实中,不可能将整个文件全部发给消费者,他通过消费者传递过来的偏移量来使用零拷贝读取指定内容的数据返回给消费者。
在Linux kernel2.2之后出现了一种叫做"零拷贝(zero-copy)"系统调用机制,就是跳过“用户缓冲区”的拷贝,建立一个磁盘空间和内存的直接映射,数据不再复制到“用户态缓冲区”,系统上下文切换减少为2次,可以提升一倍的性能。 -
3.分区 kafka中的topic中的内容可以被分为多分partition存在,每个partition又分为多个段segment,所以每次操作都是针对一小部分做操作,很轻便,并且增加并行操作的能力
-
4.批量发送 kafka允许进行批量发送消息,producter发送消息的时候,可以将消息缓存在本地,等到了固定条件发送到kafka
-
5.数据压缩 Kafka还支持对消息集合进行压缩,Producer可以通过GZIP或Snappy格式对消息集合进行压缩。 压缩的好处就是减少传输的数据量,减轻对网络传输的压力。Producer压缩之后,在Consumer需进行解压,虽然增加了CPU的工作,但在对大数据处理上,瓶颈在网络上而不是CPU,所以这个成本很值得
kafka零拷贝原理(kalkb)
在实际应用中,如果我们需要把磁盘中的某个文件内容发送到远程服务器上,
那么它必须要经过几个拷贝的过程。从磁盘中读取目标文件内容拷贝到内核缓冲区,CPU 控制器再把内核缓冲区的数据赋值到用户空间的缓冲区中,接着在应用程序中,调用 write()方法,把用户空间缓冲区中的数据拷贝到内核下的 Socket Buffer 中。最后,把在内核模式下的 SocketBuffer 中的数据赋值到网卡缓冲区(NIC Buffer)网卡缓冲区再把数据传输到目标服务器上。在这个过程中我们可以发现,数据从磁盘到最终发送出去,要经历 4 次拷贝,而在这四次拷贝过程中,有两次拷贝是浪费的,分别是:从内核空间赋值到用户空间,从用户空间再次复制到内核空间,除此之外,由于用户空间和内核空间的切换会带来CPU的上线文切换,对于CPU性能也会造成性能影响。
而零拷贝,就是把这两次多于的拷贝省略掉,应用程序可以直接把磁盘中的数据从内核中直接传输给 Socket,而不需要再经过应用程序所在的用户空间.
零拷贝通过 DMA(Direct Memory Access)技术把文件内容复制到内核空间中的 Read Buffer,
接着把包含数据位置和长度信息的文件描述符加载到 Socket Buffer 中,DMA 引擎直接可以把数据从内核空间中传递给网卡设备。在这个流程中,数据只经历了两次拷贝就发送到了网卡中,并且减少了 2 次 cpu的上下文切换,对于效率有非常大的提高。零拷贝,并不是完全没有数据赋值,只是相对于用户空间来说,不再需要进行数据拷贝。对于前面说的整个流程来说,零拷贝只是减少了不必要的拷
贝次数而已。
在程序中如何实现零拷贝呢?
在 Linux 中,零拷贝技术依赖于底层的 sendfile()方法实现
在 Java 中,FileChannal.transferTo()方法的底层实现就是 sendfile()方法。除此之外,还有一个 mmap 的文件映射机制
它的原理是:将磁盘文件映射到内存,用户通过修改内存就能修改磁盘文件。使用这种方式可以获取很大的 I/O 提升,省去了用户空间到内核空间复制的开销。
kafka 可以脱离 zookeeper 单独使用吗?为什么?
kafka 不能脱离 zookeeper 单独使用,因为 kafka 使用 zookeeper 管理和协调 kafka 的节点服务器。
kafka 有几种数据保留的策略?
kafka 有两种数据保存策略:按照过期时间保留和按照存储的消息大小保留。
kafka 同时设置了 7 天和 10G 清除数据,到第五天的时候消息达到了 10G,这个时候 kafka 将如何处理?
什么情况会导致 kafka 运行变慢?
cpu 性能瓶颈
磁盘读写瓶颈
网络瓶颈
使用 kafka 集群需要注意什么?
集群的数量不是越多越好,最好不要超过 7 个,因为节点越多,消息复制需要的时间就越长,整个群组的吞吐量就越低。 集群数量最好是单数,因为超过一半故障集群就不能用了,设置为单数容错率更高。
消息队列如何保证顺序消费(xxdlsxxf)
在生产中经常会有一些类似报表系统这样的系统,需要做 MySQL 的 binlog 同步。比如订单系统要同步订单表的数据到大数据部门的
MySQL 库中用于报表统计分析,通常的做法是基于 Canal 这样的中间件去监听订单数据库的 binlog,然后把这些 binlog发送到 MQ 中,再由消费者从 MQ 中获取 binlog 落地到大数据部门的 MySQL 中。在这个过程中,可能会有对某个订单的增删改操作,比如有三条 binlog执行顺序是增加、修改、删除。消费者愣是换了顺序给执行成删除、修改、增加,这样能行吗?肯定是不行的。不同的消息队列产品,产生消息错乱的原因,以及解决方案是不同的。下面我们以RabbitMQ、Kafka、RocketMQ为例,来说明保证顺序消费的办法。
RabbitMQ:
对于 RabbitMQ
来说,导致上面顺序错乱的原因通常是消费者是集群部署,不同的消费者消费到了同一订单的不同的消息。如消费者A执行了增加,消费者B执行了修改,消费者C执行了删除,但是消费者C执行比消费者B快,消费者B又比消费者A快,就会导致消费
binlog 执行到数据库的时候顺序错乱,本该顺序是增加、修改、删除,变成了删除、修改、增加。RabbitMQ 的问题是由于不同的消息都发送到了同一个 queue 中,多个消费者都消费同一个 queue
的消息。解决这个问题,我们可以给 RabbitMQ 创建多个 queue,每个消费者固定消费一个 queue
的消息,生产者发送消息的时候,同一个订单号的消息发送到同一个 queue 中,由于同一个 queue
的消息是一定会保证有序的,那么同一个订单号的消息就只会被一个消费者顺序消费,从而保证了消息的顺序性。Kafka:
对于 Kafka 来说,一个 topic 下同一个 partition 中的消息肯定是有序的,生产者在写的时候可以指定一个
key,通过我们会用订单号作为 key,这个 key 对应的消息都会发送到同一个 partition
中,所以消费者消费到的消息也一定是有序的。那么为什么 Kafka 还会存在消息错乱的问题呢?问题就出在消费者身上。通常我们消费到同一个 key
的多条消息后,会使用多线程技术去并发处理来提高消息处理速度,否则一条消息的处理需要耗时几十 毫秒,1
秒也就只能处理几十条消息,吞吐量就太低了。而多线程并发处理的话,binlog 执行到数据库的时候就不一定还是原来的顺序了。Kafka
从生产者到消费者消费消息这一整个过程其实都是可以保证有序的,导致最终乱序是由于消费者端需要使用多线程并发处理消息来提高吞吐量,比如消费者消费到了消息以后,开启
32 个线程处理消息,每个线程线程处理消息的快慢是不一致的,所以才会导致最终消息有可能不一致。
所以对于 Kafka 的消息顺序性保证,其实我们只需要保证同一个订单号的消息只被同一个线程处理的就可以了。由此我们可以在线程处理前增加个内存队列,每个线程只负责处理其中一个内存队列的消息,同一个订单号的消息发送到同一个内存队列中即可。RocketMQ:
对于 RocketMQ 来说,每个 Topic 可以指定多个 MessageQueue,当我们写入消息的时候,会把消息均匀地分发到不同的
MessageQueue 中,比如同一个订单号的消息,增加 binlog 写入到 MessageQueue1 中,修改 binlog 写入到
MessageQueue2 中,删除 binlog 写入到 MessageQueue3 中。但是当消费者有多台机器的时候,会组成一个 Consumer Group,Consumer Group 中的每台机器都会负责消费一部分
MessageQueue 的消息,所以可能消费者A消费了 MessageQueue1 的消息执行增加操作,消费者B消费了
MessageQueue2 的消息执行修改操作,消费者C消费了 MessageQueue3 的消息执行删除操作,但是此时消费 binlog
执行到数据库的时候就不一定是消费者A先执行了,有可能消费者C先执行删除操作,因为几台消费者是并行执行,是不能够保证他们之间的执行顺序的。RocketMQ 的消息乱序是由于同一个订单号的 binlog 进入了不同的 MessageQueue,进而导致一个订单的 binlog
被不同机器上的 Consumer 处理。要解决 RocketMQ 的乱序问题,我们只需要想办法让同一个订单的 binlog 进入到同一个 MessageQueue
中就可以了。因为同一个 MessageQueue 内的消息是一定有序的,一个 MessageQueue 中的消息只能交给一个
Consumer 来进行处理,所以 Consumer 消费的时候就一定会是有序的。
消息队列避免消息丢失?(xxdlbmxxds)
丢数据一般分为两种,一种是mq把消息丢了,一种就是消费时将消息丢了。下面从rabbitmq和kafka分别说一下,丢失数据的场景。
RabbitMQ:
RabbitMQ丢失消息分为如下几种情况:
生产者丢消息:生产者将数据发送到RabbitMQ的时候,可能在传输过程中因为网络等问题而将数据弄丢了。
RabbitMQ自己丢消息:如果没有开启RabbitMQ的持久化,那么RabbitMQ一旦重启数据就丢了。所以必须开启持久化将消息持久化到磁盘,这样就算RabbitMQ挂了,恢复之后会自动读取之前存储的数据,一般数据不会丢失。除非极其罕见的情况,RabbitMQ还没来得及持久化自己就挂了,这样可能导致一部分数据丢失。
消费端丢消息: 主要是因为消费者消费时,刚消费到还没有处理,结果消费者就挂了,这样你重启之后,RabbitMQ就认为你已经消费过了,然后就丢了数据。针对上述三种情况,RabbitMQ可以采用如下方式避免消息丢失:
生产者丢消息:
可以选择使用RabbitMQ提供是事务功能,就是生产者在发送数据之前开启事务,然后发送消息,如果消息没有成功被RabbitMQ接收到,那么生产者会受到异常报错,这时就可以回滚事务,然后尝试重新发送。如果收到了消息,那么就可以提交事务。这种方式有明显的缺点,即RabbitMQ事务开启后,就会变为同步阻塞操作,生产者会阻塞等待是否发送成功,太耗性能会造成吞吐量的下降。
可以开启confirm模式。在生产者那里设置开启了confirm模式之后,每次写的消息都会分配一个唯一的id,然后如何写入了RabbitMQ之中,RabbitMQ会给你回传一个ack消息,告诉你这个消息发送OK了。如果RabbitMQ没能处理这个消息,会回调你一个nack接口,告诉你这个消息失败了,你可以进行重试。而且你可以结合这个机制知道自己在内存里维护每个消息的id,如果超过一定时间还没接收到这个消息的回调,那么你可以进行重发。
事务机制是同步的,你提交了一个事物之后会阻塞住,但是confirm机制是异步的,发送消息之后可以接着发送下一个消息,然后RabbitMQ会回调告知成功与否。
一般在生产者这块避免丢失,都是用confirm机制。RabbitMQ自己丢消息:
设置消息持久化到磁盘,设置持久化有两个步骤:
创建queue的时候将其设置为持久化的,这样就可以保证RabbitMQ持久化queue的元数据,但是不会持久化queue里面的数据。
发送消息的时候讲消息的deliveryMode设置为2,这样消息就会被设为持久化方式,此时RabbitMQ就会将消息持久化到磁盘上。
必须要同时开启这两个才可以。而且持久化可以跟生产的confirm机制配合起来,只有消息持久化到了磁盘之后,才会通知生产者ack,这样就算是在持久化之前RabbitMQ挂了,数据丢了,生产者收不到ack回调也会进行消息重发。
消费端丢消息:
使用RabbitMQ提供的ack机制,首先关闭RabbitMQ的自动ack,然后每次在确保处理完这个消息之后,在代码里手动调用ack。这样就可以避免消息还没有处理完就ack。
Kafka:
Kafka丢失消息分为如下几种情况:
生产者丢消息:
生产者没有设置相应的策略,发送过程中丢失数据。
Kafka自己丢消息:
比较常见的一个场景,就是Kafka的某个broker宕机了,然后重新选举partition的leader时。如果此时follower还没来得及同步数据,leader就挂了,然后某个follower成为了leader,它就少了一部分数据。
消费端丢消息:
消费者消费到了这个数据,然后消费之自动提交了offset,让Kafka知道你已经消费了这个消息,当你准备处理这个消息时,自己挂掉了,那么这条消息就丢了。
针对上述三种情况,Kafka可以采用如下方式避免消息丢失:
生产者丢消息:
关闭自动提交offset,在自己处理完毕之后手动提交offset,这样就不会丢失数据。
Kafka自己丢消息:
一般要求设置4个参数来保证消息不丢失:
给topic设置 replication.factor 参数,这个值必须大于1,表示要求每个partition必须至少有2个副本。
在kafka服务端设置 min.isync.replicas 参数,这个值必须大于1,表示
要求一个leader至少感知到有至少一个follower在跟自己保持联系正常同步数据,这样才能保证leader挂了之后还有一个follower。在生产者端设置 acks=all ,表示 要求每条每条数据,必须是写入所有replica副本之后,才能认为是写入成功了。
在生产者端设置 retries=MAX (很大的一个值),表示这个是要求一旦写入事变,就无限重试。
消费端丢消息:
如果按照上面设置了ack=all,则一定不会丢失数据,要求是,你的leader接收到消息,所有的follower都同步到了消息之后,才认为本次写成功了。如果没满足这个条件,生产者会自动不断的重试,重试无限次。
消息队列如何保证避免重复消费(xxdlbmcfxf)
先大概说一说可能会有哪些重复消费的问题。首先就是比如rabbitmq、rocketmq、kafka,都有可能会出现消费重复消费的问题,正常。因为这问题通常不是mq自己保证的,是给你保证的。然后我们挑一个kafka来举个例子,说说怎么重复消费吧。
kafka实际上有个offset的概念,就是每个消息写进去,都有一个offset,代表他的序号,然后consumer消费了数据之后,每隔一段时间,会把自己消费过的消息的offset提交一下,代表我已经消费过了,下次我要是重启啥的,你就让我继续从上次消费到的offset来继续消费吧。
但是凡事总有意外,比如我们之前生产经常遇到的,就是你有时候重启系统,看你怎么重启了,如果碰到点着急的,直接kill进程了,再重启。这会导致consumer有些消息处理了,但是没来得及提交offset,尴尬了。重启之后,少数消息会再次消费一次。
其实重复消费不可怕,可怕的是你没考虑到重复消费之后,怎么保证幂等性。
举个例子,假设你有个系统,消费一条往数据库里插入一条,要是你一个消息重复两次,你不就插入了两条,这数据不就错了?但是你要是消费到第二次的时候,自己判断一下已经消费过了,直接扔了,不就保留了一条数据?一条数据重复出现两次,数据库里就只有一条数据,这就保证了系统的幂等性幂等性。通俗点说,就一个数据,或者一个请求,给你重复来多次,你得确保对应的数据是不会改变的,不能出错。想要保证不重复消费,其实还要结合业务来思考,这里给几个思路:
(1)比如你拿个数据要写库,你先根据主键查一下,如果这数据都有了,你就别插入了,update一下。
(2)比如你是写redis,那没问题了,反正每次都是set,天然幂等性。
比如你不是上面两个场景,那做的稍微复杂一点,你需要让生产者发送每条数据的时候,里面加一个全局唯一的id,类似订单id之类的东西,然后你这里消费到了之后,先根据这个id去比如redis里查一下,之前消费过吗?如果没有消费过,你就处理,然后这个id写redis。如果消费过了,那你就别处理了,保证别重复处理相同的消息即可。
还有比如基于数据库的唯一键来保证重复数据不会重复插入多条,我们之前线上系统就有这个问题,就是拿到数据的时候,每次重启可能会有重复,因为kafka消费者还没来得及提交offset,重复数据拿到了以后我们插入的时候,因为有唯一键约束了,所以重复数据只会插入报错,不会导致数据库中出现脏数据。
什么是幂等?如何解决幂等性问题?
所谓幂等,其实它是一个数学上的概念,在计算机编程领域中,幂等是指一个方法被多次重复执行的时候产生的影响和第一次执行的影响相同。之所以要考虑到幂等性问题,是因为在网络通信中,存在两种行为可能会导致接口被重复执行。用户的重复提交或者用户的恶意攻击,导致这个请求会被多次重复执行。在分布式架构中,为了避免网络通信导致的数据丢失,在服务之间进行通信的时候都会设计超时重试的机制,而这种机制有可能导致服务端接口被重复调用。所以在程序设计中,对于数据变更类操作的接口,需要保证接口的幂等性。
而幂等性的核心思想,其实就是保证这个接口的执行结果只影响一次,后续即便再次调用,也不能对数据产生影响,所以基于这样一个诉求,常见的解决方法有很多。
- 使用数据库的唯一约束实现幂等,比如对于数据插入类的场景,比如创建订单,因为订单号肯定是唯一的,所以如果是多次调用就会触发数据库的唯一约束异常,从而避免一个请求创建多个订单的问题。
- 使用 redis 里面提供的 setNX 指令,比如对于 MQ 消费的场景,为了避免 MQ
重复消费导致数据多次被修改的问题,可以在接受到 MQ 的消息时,把这个消息通过 setNx 写入到 redis
里面,一旦这个消息被消费过,就不会再次消费。 - 使用状态机来实现幂等,所谓的状态机是指一条数据的完整运行状态的转换流程,比如订单状态,因为它的状态只会向前变更,所以多次修改同一条数据的时候,一旦状态发生变更,那么对这条数据修改造成的影响只会发生一次。
当然,除了这些方法以外,还可以基于 token 机制、去重表等方法来实现,但是不管是什么方法,无非就是两种,要么就是接口只允许调用一次,比如唯一约束、基于 redis 的锁机制。要么就是对数据的影响只会触发一次,比如幂等性、乐观锁
Zookeeper(115)
zookeeper 是什么?
zookeeper 是一个分布式的,开放源码的分布式应用程序协调服务,是 google chubby 的开源实现,是 hadoop 和hbase 的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
zookeeper 都有哪些功能?(zkgn)
集群管理:监控节点存活状态、运行请求等。 主节点选举:主节点挂掉了之后可以从备用的节点开始新一轮选主,主节点选举说的就是这个选举的过程,使用 zookeeper 可以协助完成这个过程。
分布式锁:zookeeper提供两种锁:独占锁、共享锁。独占锁即一次只能有一个线程使用资源,共享锁是读锁共享,读写互斥,即可以有多线线程同时读同一个资源,如果要使用写锁也只能有一个线程使用。zookeeper可以对分布式锁进行控制。
Master:在分布式系统中,通过使用命名服务,客户端应用能够根据指定名字来获取资源或服务的地址,提供者等信息。
四种类型的znode
1、PERSISTENT-持久化目录节点
客户端与zookeeper断开连接后,该节点依旧存在
2、PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
3、EPHEMERAL-临时目录节点
客户端与zookeeper断开连接后,该节点被删除
4、EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
Zookeeper通知机制
client端会对某个znode建立一个watcher事件,当该znode发生变化时,这些client会收到zk的通知,然后client可以根据znode变化来做出业务上的改变等。
zookeeper 有几种部署模式?
zookeeper 有三种部署模式:
单机部署:一台集群上运行;
集群部署:多台集群运行;
伪集群部署:一台集群启动多个 zookeeper 实例运行。
zookeeper 怎么保证主从节点的状态同步?(zkzctb)
zookeeper 的核心是原子广播,这个机制保证了各个 server 之间的同步。实现这个机制的协议叫做 zab 协议。 zab 协议有两种模式,分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,zab就进入了恢复模式,当领导者被选举出来,且大多数 server 完成了和 leader 的状态同步以后,恢复模式就结束了。状态同步保证了 leader 和 server 具有相同的系统状态。
集群中为什么要有主节点?
在分布式环境中,有些业务逻辑只需要集群中的某一台机器进行执行,其他的机器可以共享这个结果,这样可以大大减少重复计算,提高性能,所以就需要主节点。
集群中有 3 台服务器,其中一个节点宕机,这个时候 zookeeper 还可以使用吗?
可以继续使用,单数服务器只要没超过一半的服务器宕机就可以继续使用。
说一下 zookeeper 的通知机制?(zktzjz)
客户端端会对某个 znode 建立一个 watcher 事件,当该 znode 发生变化时,这些客户端会收到 zookeeper
的通知,然后客户端可以根据 znode 变化来做出业务上的改变。
zookeeper是如何选取主leader的(zkxz)
当leader崩溃或者leader失去大多数的follower,这时zk进入恢复模式,恢复模式需要重新选举出一个新的leader,让所有的Server都恢复到一个正确的状态。Zk的选举算法有两种:一种是基于basic paxos实现的,另外一种是基于fast paxos算法实现的。系统默认的选举算法为fast paxos。
1、Zookeeper选主流程(basic paxos)
(1)选举线程由当前Server发起选举的线程担任,其主要功能是对投票结果进行统计,并选出推荐的Server;
(2)选举线程首先向所有Server发起一次询问(包括自己);
(3)选举线程收到回复后,验证是否是自己发起的询问(验证zxid是否一致),然后获取对方的id(myid),并存储到当前询问对象列表中,最后获取对方提议的leader相关信息(id,zxid),并将这些信息存储到当次选举的投票记录表中;
(4)收到所有Server回复以后,就计算出zxid最大的那个Server,并将这个Server相关信息设置成下一次要投票的Server;
(5)线程将当前zxid最大的Server设置为当前Server要推荐的Leader,如果此时获胜的Server获得n/2 + 1的Server票数,设置当前推荐的leader为获胜的Server,将根据获胜的Server相关信息设置自己的状态,否则,继续这个过程,直到leader被选举出来。通过流程分析我们可以得出:要使Leader获得多数Server的支持,则Server总数必须是奇数2n+1,且存活的Server的数目不得少于n+1. 每个Server启动后都会重复以上流程。在恢复模式下,如果是刚从崩溃状态恢复的或者刚启动的server还会从磁盘快照中恢复数据和会话信息,zk会记录事务日志并定期进行快照,方便在恢复时进行状态恢复。
2、Zookeeper选主流程(basic paxos) fast paxos流程是在选举过程中,某Server首先向所有Server提议自己要成为leader,当其它Server收到提议以后,解决epoch和 zxid的冲突,并接受对方的提议,然后向对方发送接受提议完成的消息,重复这个流程,最后一定能选举出Leader。
Zookeeper同步流程(zktb)
选完Leader以后,zk就进入状态同步过程。
1、Leader等待server连接;
2、Follower连接leader,将最大的zxid发送给leader;
3、Leader根据follower的zxid确定同步点;
4、完成同步后通知follower 已经成为uptodate状态;
5、Follower收到uptodate消息后,又可以重新接受client的请求进行服务了。
zk节点宕机如何处理?(zkdj)
Zookeeper本身也是集群,推荐配置不少于3个服务器。Zookeeper自身也要保证当一个节点宕机时,其他节点会继续提供服务。
如果是一个Follower宕机,还有2台服务器提供访问,因为Zookeeper上的数据是有多个副本的,数据并不会丢失;
如果是一个Leader宕机,Zookeeper会选举出新的Leader。
ZK集群的机制是只要超过半数的节点正常,集群就能正常提供服务。只有在ZK节点挂得太多,只剩一半或不到一半节点能工作,集群才失效。
所以
3个节点的cluster可以挂掉1个节点(leader可以得到2票>1.5)
2个节点的cluster就不能挂掉任何1个节点了(leader可以得到1票<=1)
zookeeper负载均衡和nginx负载均衡区别(znqb)
zk的负载均衡是可以调控,nginx只是能调权重,其他需要可控的都需要自己写插件;但是nginx的吞吐量比zk大很多,应该说按业务选择用哪种方式。
zookeeper watch机制(zkwhjz)
Watch机制官方声明:一个Watch事件是一个一次性的触发器,当被设置了Watch的数据发生了改变的时候,则服务器将这个改变发送给设置了Watch的客户端,以便通知它们。
Zookeeper机制的特点:
1、一次性触发数据发生改变时,一个watcher event会被发送到client,但是client只会收到一次这样的信息。
2、watcher event异步发送watcher的通知事件从server发送到client是异步的,这就存在一个问题,不同的客户端和服务器之间通过socket进行通信,由于网络延迟或其他因素导致客户端在不通的时刻监听到事件,由于Zookeeper本身提供了ordering guarantee,即客户端监听事件后,才会感知它所监视znode发生了变化。所以我们使用Zookeeper不能期望能够监控到节点每次的变化。Zookeeper只能保证最终的一致性,而无法保证强一致性。
3、数据监视Zookeeper有数据监视和子数据监视getdata() and exists()设置数据监视,getchildren()设置了子节点监视。
4、注册watcher getData、exists、getChildren
5、触发watcher create、delete、setData
6、setData()会触发znode上设置的data watch(如果set成功的话)。一个成功的create() 操作会触发被创建的znode上的数据watch,以及其父节点上的child watch。而一个成功的delete()操作将会同时触发一个znode的data watch和child watch(因为这样就没有子节点了),同时也会触发其父节点的child watch。
7、当一个客户端连接到一个新的服务器上时,watch将会被以任意会话事件触发。当与一个服务器失去连接的时候,是无法接收到watch的。而当client重新连接时,如果需要的话,所有先前注册过的watch,都会被重新注册。通常这是完全透明的。只有在一个特殊情况下,watch可能会丢失:对于一个未创建的znode的exist watch,如果在客户端断开连接期间被创建了,并且随后在客户端连接上之前又删除了,这种情况下,这个watch事件可能会被丢失。
8、Watch是轻量级的,其实就是本地JVM的Callback,服务器端只是存了是否有设置了Watcher的布尔类型
zookeeper是如何保证事务的顺序一致性的?(zkswyzx)
zookeeper采用了递增的事务Id来标识,所有的proposal(提议)都在被提出的时候加上了zxid,zxid实际上是一个64位的数字,高32位是epoch(时期; 纪元; 世; 新时代)用来标识leader是否发生改变,如果有新的leader产生出来,epoch会自增,低32位用来递增计数。当新产生proposal的时候,会依据数据库的两阶段过程,首先会向其他的server发出事务执行请求,如果超过半数的机器都能执行并且能够成功,那么就会开始执行。
Zookeeper工作原理(zkgzyl)
Zookeeper 的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和 leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。
Zookeeper数据复制(zksjfz)
Zookeeper作为一个集群提供一致的数据服务,自然,它要在所有机器间做数据复制。数据复制的好处:
1、容错:一个节点出错,不致于让整个系统停止工作,别的节点可以接管它的工作;
2、提高系统的扩展能力 :把负载分布到多个节点上,或者增加节点来提高系统的负载能力;
3、提高性能:让客户端本地访问就近的节点,提高用户访问速度。
从客户端读写访问的透明度来看,数据复制集群系统分下面两种:
1、写主(WriteMaster) :对数据的修改提交给指定的节点。读无此限制,可以读取任何一个节点。这种情况下客户端需要对读与写进行区别,俗称读写分离;
2、写任意(Write Any):对数据的修改可提交给任意的节点,跟读一样。这种情况下,客户端对集群节点的角色与变化透明。
对zookeeper来说,它采用的方式是写任意。通过增加机器,它的读吞吐能力和响应能力扩展性非常好,而写,随着机器的增多吞吐能力肯定下降(这也是它建立observer的原因),而响应能力则取决于具体实现方式,是延迟复制保持最终一致性,还是立即复制快速响应。
Zookeeper队列管理(文件系统、通知机制)(zkdlgl)
两种类型的队列:
1、同步队列,当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达。
2、队列按照 FIFO 方式进行入队和出队操作。
第一类,在约定目录下创建临时目录节点,监听节点数目是否是我们要求的数目。
第二类,和分布式锁服务中的控制时序场景基本原理一致,入列有编号,出列按编号。在特定的目录下创建PERSISTENT_SEQUENTIAL节点,创建成功时Watcher通知等待的队列,队列删除序列号最小的节点用以消费。此场景下Zookeeper的znode用于消息存储,znode存储的数据就是消息队列中的消息内容,SEQUENTIAL序列号就是消息的编号,按序取出即可。由于创建的节点是持久化的,所以不必担心队列消息的丢失问题。
zookeeper获取分布式锁的流程(zkhqfbss)
在获取分布式锁的时候在locker节点下创建临时顺序节点,释放锁的时候删除该临时节点。客户端调用createNode方法在locker下创建临时顺序节点,然后调用getChildren(“locker”)来获取locker下面的所有子节点,注意此时不用设置任何Watcher。客户端获取到所有的子节点path之后,如果发现自己创建的节点在所有创建的子节点序号最小,那么就认为该客户端获取到了锁。如果发现自己创建的节点并非locker所有子节点中最小的,说明自己还没有获取到锁,此时客户端需要找到比自己小的那个节点,然后对其调用exist()方法,同时对其注册事件监听器。之后,让这个被关注的节点删除,则客户端的Watcher会收到相应通知,此时再次判断自己创建的节点是否是locker子节点中序号最小的,如果是则获取到了锁,如果不是则重复以上步骤继续获取到比自己小的一个节点并注册监听。当前这个过程中还需要许多的逻辑判断。
Zookeeper分布式锁(zkfbss)
1.每个线程或进程在 Zookeeper 上的/lock 目录下创建一个临时有序的节点表示去抢占锁,所有创建的节点会按照先后顺序生成一个带有序编号的节点。
2、线程创建节点后,获取/lock 节点下的所有子节点,判断当前线程创建的节点是否是所有的节点的序号最小的。
3、如果当前线程创建的节点是所有节点序号最小的节点,则认为获取锁成功。
4、如果当前线程创建的节点不是所有节点序号最小的节点,则对节点序号的前一个节点添加一个事件监听,当前一个被监听的节点释放锁之后,触发回调通知,从而再次去尝试抢占锁。
zookeeper分布式锁有什么缺陷(zkfbssqx)
1.zookeeper 天生设计定位就是分布式协调,强一致性。锁的模型健壮、简单易用、适合做分布式锁。
2.如果获取不到锁,只需要添加一个监听器就可以了,不用一直轮询,性能消耗较小。
2.如果要在两者之间做选择,就我个人而言的话,比较推崇 ZK 实现的锁,因为对于分布式锁而言,它应该符合 CP 模型,但是 Redis 是 AP 模型,所以在这个点上,Zookeeper 会更加合适。
请说一下你对分布式锁的理解,以及分布式锁的实现(fbssdc)
分布式锁,是一种跨进程的跨机器节点的互斥锁,它可以用来保证多机器节点对于共享资源访问的排他性。分布式锁和线程锁本质上是一样的,线程锁的生命周期是单进程多线程,分布式锁的生命周期是多进程多机器节点。
在本质上,他们都需要满足锁的几个重要特性:
排他性,也就是说,同一时刻只能有一个节点去访问共享资源。
可重入性,允许一个已经获得锁的进程,在没有释放锁之前再次重新获得锁。
锁的获取、释放的方法
锁的失效机制,避免死锁的问题
所以,我认为,只要能够满足这些特性的技术组件都能够实现分布式锁。
关系型数据库,可以使用唯一约束来实现锁的排他性,
如果要针对某个方法加锁,就可以创建一个表包含方法名称字段,并且把方法名设置成唯一的约束。
那抢占锁的逻辑就是:往表里面插入一条数据,如果已经有其他的线程获得了某个方法的锁,那这个时候插入数据会失败,从而保证了互斥性。这种方式虽然简单啊,但是要实现比较完整的分布式锁,还需要考虑重入性、锁失效机制、没抢占到锁的线程要实现阻塞等,就会比较麻烦。
Redis,它里面提供了 SETNX 命令可以实现锁的排他性,当 key 不存在就返回1,存在就返回 0。然后还可以用 expire 命令设置锁的失效时间,从而避免死锁问题。当然有可能存在锁过期了,但是业务逻辑还没执行完的情况。所以这种情况,可以写一个定时任务对指定的 key 进行续期。
Redisson 这个开源组件,就提供了分布式锁的封装实现,并且也内置了一个Watch Dog 机制来对 key 做续期。我认为 Redis 里面这种分布式锁设计已经能够解决 99%的问题了,当然如果在Redis 搭建了高可用集群的情况下出现主从切换导致 key 失效,这个问题也有可能造成多个线程抢占到同一个锁资源的情况,所以 Redis 官方也提供了一个 RedLock的解决办法,但是实现会相对复杂一些。
在我看来,分布式锁应该是一个 CP 模型,而 Redis 是一个 AP 模型,所以在集群架构下由于数据的一致性问题导致极端情况下出现多个线程抢占到锁的情况很难避免。
那么基于 CP 模型又能实现分布式锁特性的组件,我认为可以选择 Zookeeper,在数据一致性方面,zookeeper 用到了 zab 协议来保证数据的一致性,在锁的互斥方面,zookeeper 可以基于有序节点再结合 Watch 机制实现互斥和唤醒,etcd 可以基于 Prefix 机制和 Watch 实现互斥和唤醒。
MySql(116)
数据库的三范式是什么?(sjksfs)
第一范式:强调的是列的原子性,即数据库表的每一列都是不可分割的原子数据项。
第二范式:要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性。
第三范式:任何非主属性不依赖于其它非主属性。
一张自增表里面总共有 7 条数据,删除了最后 2 条数据,重启 mysql 数据库,又插入了一条数据,此时 id 是几?
表类型如果是 MyISAM ,那 id 就是 8。
表类型如果是 InnoDB,那 id 就是 6。
InnoDB 表只会把自增主键的最大 id 记录在内存中,所以重启之后会导致最大 id 丢失。
如何获取当前数据库版本?
使用 select version() 获取当前 MySQL 数据库版本。
char 和 varchar 的区别是什么?(cvqb)
char(n) :固定长度类型,比如订阅 char(10),当你输入"abc"三个字符的时候,它们占的空间还是 10 个字节,其他 7 个是空字节。
chat 优点:效率高;缺点:占用空间;适用场景:存储密码的 md5 值,固定长度的,使用 char 非常合适。
varchar(n) :可变长度,存储的值是每个值占用的字节再加上一个用来记录其长度的字节的长度。
所以,从空间上考虑 varcahr 比较合适;从效率上考虑 char 比较合适,二者使用需要权衡。
float 和 double 的区别是什么?(fdqb)
float 最多可以存储 8 位的十进制数,并在内存中占 4 字节。
double 最可可以存储 16 位的十进制数,并在内存中占 8 字节。
mysql 的内连接、左连接、右连接有什么区别?(nzyqb)
内连接关键字:inner join;左连接:left join;右连接:right join。
内连接是把匹配的关联数据显示出来;左连接是左边的表全部显示出来,右边的表显示出符合条件的数据;右连接正好相反。
mysql 数据库索引是怎么实现的?(数据库索引sjksy)
索引是满足某种特定查找算法的数据结构,而这些数据结构会以某种方式指向数据,从而实现高效查找数据。
具体来说 MySQL 中的索引,不同的数据引擎实现有所不同,但目前主流的数据库引擎的索引都是 B+ 树实现的,B+树的搜索效率,可以到达二分法的性能,找到数据区域之后就找到了完整的数据结构了,所有索引的性能也是更好的。B+树(红黑树),经过优化的 B+树 主要是在所有的叶子结点中增加了指向下一个叶子节点的指针,因此 InnoDB 建议为大部分表使用默认自增的主键作为主索引。优点:快速访问数据表中的特定信息,提高检索速度 创建唯一性索引,保证数据库表中每一行数据的唯一性。 加速表和表之间的连接 使用分组和排序子句进行数据检索时,可以显著减少查询中分组和排序的时间
什么情况下不推荐使用索引?
(1)表记录太少(2)经常增删改的表或者字段(3)Where条件里用不到的字段不创建索引。(4)过滤性不好的不适合建索引。
哪些情况下需要创建使用索引:
主键自动建立唯一索引。频繁作为查询条件的字段应该创建索引。查询中与其他表关联的字段,外键关系建立索引;查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度。查询中统计或者分组字段
怎么验证 mysql 的索引是否满足需求?
使用 explain 查看 SQL 是如何执行查询语句的,从而分析你的索引是否满足需求。
explain 语法:explain select * from table where type=1。
最左匹配的原理(zzqz)(zzpp)
最左匹配原则就是指在联合索引中,如果你的 SQL 语句中用到了联合索引中的最左边的索引,那么这条 SQL 语句就可以利用这个联合索引去进行匹配。
最左匹配原则都是针对联合索引来说的,所以我们可以从联合索引的原理来了解最左匹配原则。
我们都知道索引的底层是一颗 B+ 树,那么联合索引当然还是一颗 B+ 树,只不过联合索引的键值数量不是一个,而是多个。构建一颗 B+ 树只能根据一个值来构建,因此数据库依据联合索引最左的字段来构建 B+ 树。
在 InnoDB 中联合索引只有先确定了前一个(左侧的值)后,才能确定下一个值。如果有范围查询的话,那么联合索引中使用范围查询的字段后的索引在该条 SQL 中都不会起作用。值得注意的是,in 和 = 都可以乱序,比如有索引(a,b,c),语句 select * from t where c =1 and a=1 and b=1,这样的语句也可以用到最左匹配,因为 MySQL 中有一个优化器,他会分析 SQL 语句,将其优化成索引可以匹配的形式,即 select * from t where a =1 and a=1 and c=1
为什么要使用联合索引(lhsy)
减少开销。建一个联合索引(col1,col2,col3),实际相当于建了(col1),(col1,col2),(col1,col2,col3)三个索引。每多一个索引,都会增加写操作的开销和磁盘空间的开销。对于大量数据的表,使用联合索引会大大的减少开销!
覆盖索引(fgsy)。对联合索引(col1,col2,col3),如果有如下的sql: select col1,col2,col3 from test where col1=1 and col2=2。那么MySQL可以直接通过遍历索引取得数据,而无需回表,这减少了很多的随机io操作。减少io操作,特别的随机io其实是dba主要的优化策略。所以,在真正的实际应用中,覆盖索引是主要的提升性能的优化手段之一。
效率高。索引列越多,通过索引筛选出的数据越少。有1000W条数据的表,有如下sql:select from table where col1=1 and col2=2 and col3=3,假设假设每个条件可以筛选出10%的数据,如果只有单值索引,那么通过该索引能筛选出1000W10%=100w条数据,然后再回表从100w条数据中找到符合col2=2 and col3= 3的数据,然后再排序,再分页;如果是联合索引,通过索引筛选出1000w10% 10% *10%=1w,效率提升可想而知!
索引下推是什么?(syxt)
MySQL 5.6引入了索引下推优化,可以在索引遍历过程中,对索引中包含的字段先做判断,过滤掉不符合条件的记录,减少回表字数
说一下数据库事务 ACID 是什么?(acid)
事务可由一条非常简单的SQL语句组成,也可以由一组复杂的SQL语句组成。在事务中的操作,要么都执行修改,要么都不执行,这就是事务的目的,也是事务模型区别于文件系统的重要特征之一。事务需遵循ACID四个特性:
Atomicity(原子性):一个事务(transaction)中的所有操作,或者全部完成,或者全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被恢复(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。即,事务不可分割、不可约简。
Consistency(一致性):在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设约束、触发器、级联回滚等。
Isolation(隔离性):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read
uncommitted)、读提交(read committed)、可重复读(repeatable
read)和串行化(Serializable)。
Durability(持久性):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
数据库事务有哪几种类型,它们之间有什么区别?(sjkswlx)
扁平事务:是事务类型中最简单的一种,而在实际生产环境中,这可能是使用最为频繁的事务。在扁平事务中,所有操作都处于同一层次,其由BEGIN WORK开始,由COMMIT WORK或ROLLBACK WORK结束。处于之间的操作是原子的,要么都执行,要么都回滚。
带有保存点的扁平事务:除了支持扁平事务支持的操作外,允许在事务执行过程中回滚到同一事务中较早的一个状态,这是因为可能某些事务在执行过程中出现的错误并不会对所有的操作都无效,放弃整个事务不合乎要求,开销也太大。保存点(savepoint)用来通知系统应该记住事务当前的状态,以便以后发生错误时,事务能回到该状态。
链事务:可视为保存点模式的一个变种。链事务的思想是:在提交一个事务时,释放不需要的数据对象,将必要的处理上下文隐式地传给下一个要开始的事务。注意,提交事务操作和开始下一个事务操作将合并为一个原子操作。这意味着下一个事务将看到上一个事务的结果,就好像在一个事务中进行的。
嵌套事务:是一个层次结构框架。有一个顶层事务(top-level transaction)控制着各个层次的事务。顶层事务之下嵌套的事务被称为子事务(subtransaction),其控制每一个局部的变换。
分布式事务:通常是一个在分布式环境下运行的扁平事务,因此需要根据数据所在位置访问网络中的不同节点。对于分布式事务,同样需要满足ACID特性,要么都发生,要么都失效。
MySQL事务如何回滚?(sjkswhg)
在MySQL默认的配置下,事务都是自动提交和回滚的。当显示地开启一个事务时,可以使用ROLLBACK语句进行回滚。该语句有两种用法:
ROLLBACK:要使用这个语句的最简形式,只需发出ROLLBACK。同样地,也可以写为ROLLBACK WORK,但是二者几乎是等价的。回滚会结束用户的事务,并撤销正在进行的所有未提交的修改。
ROLLBACK TO [SAVEPOINT] identifier :这个语句与SAVEPOINT命令一起使用。可以把事务回滚到标记点,而不回滚在此标记点之前的任何工作。
说一下 mysql 常用的引擎?(sjkyq)
InnoDB 引擎:InnoDB 引擎提供了对数据库 acid 事务的支持,并且还提供了行级锁和外键的约束,它的设计的目标就是处理大数据容量的数据库系统。MySQL 运行的时候,InnoDB
会在内存中建立缓冲池,用于缓冲数据和索引。但是该引擎是不支持全文搜索,同时启动也比较的慢,它是不会保存表的行数的,所以当进行 select count(*) from table
指令的时候,需要进行扫描全表。由于锁的粒度小,写操作是不会锁定全表的,所以在并发度较高的场景下使用会提升效率的。MyIASM 引擎:MySQL 的默认引擎,但不提供事务的支持,也不支持行级锁和外键。因此当执行插入和更新语句时,即执行写操作的时候需要锁定这个表,所以会导致效率会降低。不过和 InnoDB 不同的是,MyIASM 引擎是保存了表的行数,于是当进行 select count(*) from table 语句时,可以直接的读取已经保存的值而不需要进行扫描全表。所以,如果表的读操作远远多于写操作时,并且不需要事务的支持的,可以将 MyIASM作为数据库引擎的首选。
说一下 mysql 的行锁和表锁?(hbqb)
MyISAM 只支持表锁,InnoDB 支持表锁和行锁,默认为行锁。
表级锁:开销小,加锁快,不会出现死锁。锁定粒度大,发生锁冲突的概率最高,并发量最低。
行级锁:开销大,加锁慢,会出现死锁。锁力度小,发生锁冲突的概率小,并发度最高。
说一下乐观锁和悲观锁?(lbqb)
乐观锁:每次获取数据的时候,都不会担心数据被修改,所以每次获取数据的时候都不会进行加锁,但是在更新数据的时候需要判断该数据是否被别人修改过。如果数据被其他线程修改,则不进行数据更新,如果数据没有被其他线程修改,则进行数据更新。由于数据没有进行加锁,期间该数据可以被其他线程进行读写操作。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。
悲观锁:每次获取数据的时候,都会担心数据被修改,所以每次获取数据的时候都会进行加锁,确保在自己使用的过程中数据不会被别人修改,使用完成后进行数据解锁。由于数据进行加锁,期间对该数据进行读写的其他线程都会进行等待。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做
操作之前先上锁。再比如Java里面的同步原语synchronized关键字的实现也是悲观锁。c)适用场景:
i.悲观锁:比较适合写入操作比较频繁的场景,如果出现大量的读取操作,每次读取的时候都会进行加锁,这样会增加大量的锁的开销,降低了系统的吞吐量。
ii.乐观锁:比较适合读取操作比较频繁的场景,如果出现大量的写入操作,数据发生冲突的可能性就会增大,为了保证数据的一致性,应用层需要不断的重新获取数据,这样会增加大量的查询操作,降低了系统的吞吐量。
d)优点与不足
i.悲观并发控制实际上是“先取锁再访问”的保守策略,为数据处理的安全提供了保证。但是在效率方面,处理加锁的机制会让数据库产生额外的开销,还有增加产生死锁的机会;
ii.在只读型事务处理中由于不会产生冲突,也没必要使用锁,这样做只能增加系统负载;还有会降低了并行性,一个事务如果锁定了某行数据,其他事务就必须等待该事务处理完才可以处理那行数
乐观锁的实现方式:
1、使用版本标识来确定读到的数据与提交时的数据是否一致。提交后修改版本标识,不一致时可
以采取丢弃和再次尝试的策略。
2、java中的Compare and Swap即CAS ,当多个线程尝试使用CAS同时更新同一个变量时,只有其
中一个线程能更新变量的值,而其它线程都失败,失败的线程并不会被挂起,而是被告知这次竞争
中失败,并可以再次尝试。 CAS 操作中包含三个操作数 —— 需要读写的内存位置(V)、进行比
较的预期原值(A)和拟写入的新值(B)。如果内存位置V的值与预期原值A相匹配,那么处理器会自
动将该位置值更新为新值B。否则处理器不做任何操作。
e)死锁
i.概念:死锁的形式为两个(多个)线程相互等待来自对方的锁;
ii.解决死锁:调整锁的顺序:调用的顺序保持一致。
数据库的乐观锁需要自己实现,在表里面添加一个 version 字段,每次修改成功值加 1,这样每次修改的时候先对比一下,自己拥有的version 和数据库现在的 version 是否一致,如果不一致就不修改,这样就实现了乐观锁。
mysql 问题排查都有哪些手段?(sjkwtpc)
使用 show processlist 命令查看当前所有连接信息。
使用 explain 命令查询 SQL 语句执行计划。
开启慢查询日志,查看慢查询的 SQL。
什么叫视图?游标是什么?
视图是一种虚拟的表,具有和物理表相同的功能。可以对视图进行增,改, 查,操作,视图通常是有一个表或者多个表的行或列的子集。对视图的修改不影响基本表。它使得我们获取数据更容易,相比多表查询。 游标:是对查询出来的结果集作为一个单元来有效的处理。游标可以定在该单元中的特定行,从结果集的当前行检索一行或多行。可以对结果集当前行做修改。 一般不使用游标,但是需要逐条处理数据的时候,游标显得十分重要。
MySQL 中有哪几种锁?(sjks)
加锁是实现数据库并发控制的一个非常重要的技术。当事务在对某个数据对象进行操作前,先向系统发出请求,对其加锁。加锁后事务就对该数据对象有了一定的控制,在该事务释放锁之前,其他的事务不能对此数据对象进行更新操作。从锁的粒度上分:
1、表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最 高,并发度最低。
2、行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最 低,并发度也最高。
3、页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表 锁和行锁之间,并发度一般。
从锁的类别上分有共享锁和排他锁。共享锁,又叫读锁,当用户进行数据的读取时,对数据加上共享锁,共享锁可以同时加上多个,排他锁:又叫写锁,当用户进行数据的写入时,对数据加上排他锁,排他锁只能加一个,和其他的排他锁,共享锁都互斥。
mysql数据库索引都有哪些?如何创建索引?索引的底层实现原理和优化(sjksydc)
索引是一个单独的、存储在磁盘上的数据库结构,包含着对数据表里所有记录的引用指针。使用索引可以快速找出在某个或多个列中有一特定值的行,所有MySQL列类型都可以被索引,对相关列使用索引是提高查询操作速度的最佳途径。 索引是在存储引擎中实现的,因此,每种存储引擎的索引都不一定完全相同,并且每种存储引擎也不一定支持所有索引类型。MySQL中索引的存储类型有两种,即BTREE和HASH,具体和表的存储引擎相关。MyISAM和InnoDB存储引擎只支持BTREE索引;MEMORY/HEAP存储引擎可以支持HASH和BTREE索引。
索引的优点主要有以下几条:
通过创建唯一索引,可以保证数据库表中每一行数据的唯一性。
可以大大加快数据的查询速度,这也是创建索引的主要原因。
在实现数据的参考完整性方面,可以加速表和表之间的连接。
在使用分组和排序子句进行数据查询时,也可以显著减少查询中分组和排序的时间。
增加索引也有许多不利的方面,主要表现在如下几个方面:
创建索引和维护索引要耗费时间,并且随着数据量的增加所耗费的时间也会增加。
索引需要占磁盘空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果有大量的索引,索引文件可能比数据文件更快达到最大文件尺寸。
当对表中的数据进行增加、删除和修改的时候,索引也要动态地维护,这样就降低了数据的维护速度。
MySQL的索引分类可以分为以下几类:(syfl)
1.普通索引和唯一索引普通索引是MySQL中的基本索引类型,允许在定义索引的列中插入重复值和空值。
唯一索引要求索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
主键索引是一种特殊的唯一索引,不允许有空值。
2.单列索引和组合索引: 单列索引即一个索引只包含单个列,一个表可以有多个单列索引。组合索引是指在表的多个字段组合上创建的索引,只有在查询条件中使用了这些字段的左边字段时,索引才会被使用。使用组合索引时遵循最左前缀集合。
3.全文索引:全文索引类型为FULLTEXT,在定义索引的列上支持值的全文查找,允许在这些索引列中插入重复值和空值。全文索引可以在CHAR、VARCHAR或者TEXT类型的列上创建。
4.空间索引: 空间索引是对空间数据类型的字段建立的索引,MySQL中的空间数据类型有4种,分别是GEOMETRY、POINT、LINESTRING和POLYGON。MySQL使用SPATIAL关键字进行扩展,使得能够用创建正规索引类似的语法创建空间索引。创建空间索引的列,必须将其声明为NOT NULL,空间索引只能在存储引擎为MyISAM的表中创建。
只要创建了索引,就一定会走索引(不走索引)吗? 不一定。 比如,在使用组合索引的时候,如果没有遵从“最左前缀”的原则进行搜索,则索引是不起作用的。 举例,假设在id、name、age字段上已经成功建立了一个名为MultiIdx的组合索引。索引行中按id、name、age的顺序存放,索引可以搜索id、(id,name)、(id,name,age)字段组合。如果列不构成索引最左面的前缀,那么MySQL不能使用局部索引,如(age)或者(name,age)组合则不能使用该索引查询。
如何判断数据库的索引(索引生效)有没有生效? 可以使用EXPLAIN语句查看索引是否正在使用。
索引是越多越好吗(索引越多越好)?索引并非越多越好,一个表中如有大量的索引,不仅占用磁盘空间,还会影响INSERT、DELETE、UPDATE等语句的性能,因为在表中的数据更改时,索引也会进行调整和更新。
联合索引的存储结构是什么,它的有效方式是什么?从本质上来说,联合索引还是一棵B+树,不同的是联合索引的键值数量不是1,而是大于等于2。另外,只有在查询条件中使用了这些字段的左边字段时,索引才会被使用,所以使用联合索引时遵循最左前缀集合。定义:联合索引是指对表上的多个列进行索引,联合索引的创建方法与单个索引创建的方法一样,不同之处仅在于有多个索引列。从本质上来说,联合索引还是一棵B+树,不同的是联合索引的键值数量不是1,而是大于等于2,参考下图。另外,只有在查询条件中使用了这些字段的左边字段时,索引才会被使用,所以使用联合索引时遵循最左前缀集合。
索引在什么情况下会失效?(sysx)
- 条件中有or,例如select * from table_name where a = 1 or b = 3
- 在索引上进行计算会导致索引失效,例如select * from table_name where a + 1 = 2
- 在索引的类型上进行数据类型的隐形转换,会导致索引失效,例如字符串一定要加引号,假设 select * from table_name where a = '1’会使用到索引,如果写成select * from table_name where a = 1则会导致索引失效。
- 在索引中使用函数会导致索引失效,例如select * from table_name where abs(a) = 1
- 在使用like查询时以%开头会导致索引失效
- 索引上使用!、=、<>进行判断时会导致索引失效,例如select * from table_name where a != 1
索引字段上使用 is null/is not null判断时会导致索引失效,例如select * from table_name
where a is null
数据库索引优化(sjksyyh)
1.最左前缀匹配原则,上面讲到了
2. 主键外检一定要建索引
3.对 where,on,group by,order by 中出现的列使用索引
4.尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0
5.对较小的数据列使用索引,这样会使索引文件更小,同时内存中也可以装载更多的索引键
6.索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) =
’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time
= unix_timestamp(’2014-05-29’);
7.为较长的字符串使用前缀索引
8.尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可
9.不要过多创建索引,权衡索引个数与DML之间关系,DML也就是插入、删除数据操作。这里需要权衡一个问题,建立索引的目的是为了提高查询效率的,但建立的索引过多,会影响插入、删除数据的速度,因为我们修改的表数据,索引也需要进行调整重建
10.对于like查询,”%”不要放在前面。 SELECT * FROMhoudunwangWHEREunameLIKE’后盾%’ – 走索引
SELECT * FROMhoudunwangWHEREunameLIKE “%后盾%” – 不走索引
11.查询where条件数据类型不匹配也无法使用索引 字符串与数字比较不使用索引; CREATE TABLEa(achar(10));
EXPLAIN SELECT * FROMaWHEREa=“1” – 走索引 EXPLAIN SELECT * FROM a WHERE
a=1 – 不走索引 正则表达式不使用索引,这应该很好理解,所以为什么在SQL中很难看到regexp关键字的原因
索引的设计原则?(sysjyz)
最适合索引的列是在where后面出现的列或者连接句子中指定的列,而不是出现在SELECT关键字后面的选择列表中的列。
索引列的基数越大,索引的效果越好,换句话说就是索引列的区分度越高,索引的效果越好。比如使用性别这种区分度很低的列作为索引,效果就会很差,因为列的基数最多也就是三种,大多不是男性就是女性。
尽量使用短索引,对于较长的字符串进行索引时应该指定一个较短的前缀长度,因为较小的索引涉及到的磁盘I/O较少,并且索引高速缓存中的块可以容纳更多的键值,会使得查询速度更快。
尽量利用最左前缀。
不要过度索引,每个索引都需要额外的物理空间,维护也需要花费时间,所以索引不是越多越好。
索引的使用场景有哪些?(sysycj)
对于中大型表建立索引非常有效,对于非常小的表,一般全部表扫描速度更快些。
对于超大型的表,建立和维护索引的代价也会变高,这时可以考虑分区技术。
如何表的增删改非常多,而查询需求非常少的话,那就没有必要建立索引了,因为维护索引也是需要代价的。
一般不会出现再where条件中的字段就没有必要建立索引了。
多个字段经常被查询的话可以考虑联合索引。
字段多且字段值没有重复的时候考虑唯一索引。
字段多且有重复的时候考虑普通索引。
聚簇索引和非聚簇索引有什么区别?(jfqb)
在InnoDB存储引擎中,可以将B+树索引分为聚簇索引和辅助索引(非聚簇索引)。无论是何种索引,每个页的大小都为16KB,且不能更改。
聚簇索引是根据主键创建的一棵B+树,聚簇索引的叶子节点存放了表中的所有记录。非聚簇索引是根据索引键创建的一棵B+树,与聚簇索引不同的是,其叶子节点仅存放索引键值,以及该索引键值指向的主键。也就是说,如果通过非聚簇索引来查找数据,那么当找到非聚簇索引的叶子节点后,很有可能还需要根据主键值查找聚簇索引来得到数据,这种查找方式又被称为书签查找。因为非聚簇索引不包含行记录的所有数据,这就意味着每页可以存放更多的键值,因此其高度一般都要小于聚簇索引。
非聚簇索引一定会进行回表查询吗?
答案是不一定的,这里涉及到一个索引覆盖的问题,如果查询的数据再辅助索引上完全能获取到便不需要回表查询。例如有一张表存储着个人信息包括id、name、age等字段。假设聚簇索引是以ID为键值构建的索引,非聚簇索引是以name为键值构建的索引,select id,name from user where name = ‘zhangsan’;这个查询便不需要进行回表查询因为,通过非聚簇索引已经能全部检索出数据,这就是索引覆盖的情况。如果查询语句是这样,select id,name,age from user where name = ‘zhangsan’;则需要进行回表查询,因为通过非聚簇索引不能检索出age的值。那应该如何解决那呢?只需要将索引覆盖即可,建立age和name的联合索引再使用select id,name,age from user where name = ‘zhangsan’;进行查询即可。
所以通过索引覆盖能解决非聚簇索引回表查询的问题。
谈谈你对SQL注入的理解(sqlzr)
SQL注入的原理是将SQL代码伪装到输入参数中,传递到服务器解析并执行的一种攻击手法。也就是说,在一些对SERVER端发起的请求参数中植入一些SQL代码,SERVER端在执行SQL操作时,会拼接对应参数,同时也将一些SQL注入攻击的“SQL”拼接起来,导致会执行一些预期之外的操作。
比如我们的登录功能,其登录界面包括用户名和密码输入框以及提交按钮,登录时需要输入用户名和密码,然后提交。此时调用接口/user/login/
加上参数username、password,首先连接数据库,然后后台对请求参数中携带的用户名、密码进行参数校验,即SQL的查询过程。假设正确的用户名和密码为ls和123456,输入正确的用户名和密码、提交,相当于调用了以下的SQL语句。其实上面的SQL注入只是在参数层面做了些手脚,如果是引入了一些功能性的SQL那就更危险了,比如上面的登录功能,如果用户名使用这个
’ or 1=1;delete * from users;
#,那么在";"之后相当于是另外一条新的SQL,这个SQL是删除全表,是非常危险的操作,因此SQL注入这种还是需要特别注意的。
> 如何解决SQL注入?1.严格的参数校验
参数校验就没得说了,在一些不该有特殊字符的参数中提前进行特殊字符校验即可。
2.SQL预编译
服务器启动时,MySQL Client把SQL语句的模板(变量采用占位符进行占位)发送给MySQL服务器,MySQL服务器对SQL语句的模板进行编译,编译之后根据语句的优化分析对相应的索引进行优化,在最终绑定参数时把相应的参数传送给MySQL服务器,直接进行执行,节省了SQL查询时间,以及MySQL服务器的资源,达到一次编译、多次执行的目的,除此之外,还可以防止SQL注入。
具体是怎样防止SQL注入的呢?实际上当将绑定的参数传到MySQL服务器,MySQL服务器对参数进行编译,即填充到相应的占位符的过程中,做了转义操作。我们常用的JDBC就有预编译功能,不仅提升性能,而且防止SQL注入。
WHERE和HAVING有什么区别?(whqb)
WHERE是一个约束声明,使用WHERE约束来自数据库的数据,WHERE是在结果返回之前起作用的,WHERE中不能使用聚合函数。
HAVING是一个过滤声明,是在查询返回结果集以后对查询结果进行的过滤操作,在HAVING中可以使用聚合函数。另一方面,HAVING子句中不能使用除了分组字段和聚合函数之外的其他字段。
从性能的角度来说,HAVING子句中如果使用了分组字段作为过滤条件,应该替换成WHERE子句。因为WHERE可以在执行分组操作和计算聚合函数之前过滤掉不需要的数据,性能会更好。
说一说你对数据库优化的理解(sjkyh)
MySQL数据库优化是多方面的,原则是减少系统的瓶颈,减少资源的占用,增加系统的反应速度。例如,通过优化文件系统,提高磁盘I\O的读写速度;通过优化操作系统调度策略,提高MySQL在高负荷情况下的负载能力;优化表结构、索引、查询语句等使查询响应更快。
- 搭建 Mysql 主从集群,单个 Mysql 服务容易单点故障,一旦服务器宕机,将
会导致依赖 Mysql 数据库的应用全部无法响应。 主从集群或者主主集群可以保
证服务的高可用性。 - 读写分离设计,在读多写少的场景中,通过读写分离的方案,可以避免读写
冲突导致的性能影响 - 引入分库分表机制,通过分库可以降低单个服务器节点的 IO 压力,通过分表
的方式可以降低单表数据量,从而提升 sql 查询的效率。 - 针对热点数据,可以引入更为高效的分布式数据库,比如 Redis、MongoDB
等,他们可以很好的缓解 Mysql 的访问压力,同时还能提升数据检索性能。 - 针对查询,我们可以通过使用索引、使用连接代替子查询的方式来提高查询速度。
- 针对慢查询,我们可以通过分析慢查询日志,来发现引起慢查询的原因,从而有针对性的进行优化。
- 针对插入,我们可以通过禁用索引、禁用检查等方式来提高插入速度,在插入之后再启用索引和检查。
- 针对数据库结构,我们可以通过将字段很多的表拆分成多张表、增加中间表、增加冗余字段等方式进行优化。
该如何优化MySQL的查询?(数据库查询优化sjkcxyh)
-
1.使用索引:
如果查询时没有使用索引,查询语句将扫描表中的所有记录。在数据量大的情况下,这样查询的速度会很慢。如果使用索引进行查询,查询语句可以根据索引快速定位到待查询记录,从而减少查询的记录数,达到提高查询速度的目的。
索引可以提高查询的速度,但并不是使用带有索引的字段查询时索引都会起作用。有几种特殊情况,在这些情况下有可能使用带有索引的字段查询时索引并没有起作用。
-
2.优化子查询:
使用子查询可以进行SELECT语句的嵌套查询,即一个SELECT查询的结果作为另一个SELECT语句的条件。子查询可以一次性完成很多逻辑上需要多个步骤才能完成的SQL操作。
子查询虽然可以使查询语句很灵活,但执行效率不高。执行子查询时,MySQL需要为内层查询语句的查询结果建立一个临时表。然后外层查询语句从临时表中查询记录。查询完毕后,再撤销这些临时表。因此,子查询的速度会受到一定的影响。如果查询的数据量比较大,这种影响就会随之增大。
在MySQL中,可以使用连接(JOIN)查询来替代子查询。连接查询不需要建立临时表,其速度比子查询要快,如果查询中使用索引,性能会更好。
mysql怎样插入数据才能更高效?(数据库插入优化sjkcryh)
影响插入速度的主要是索引、唯一性校验、一次插入记录条数等。针对这些情况,可以分别进行优化。
** 对于MyISAM引擎的表,常见的优化方法如下**:1.禁用索引:对于非空表,插入记录时,MySQL会根据表的索引对插入的记录建立索引。如果插入大量数据,建立索引会降低插入记录的速度。为了解决这种情况,可以在插入记录之前禁用索引,数据插入完毕后再开启索引。对于空表批量导入数据,则不需要进行此操作,因为MyISAM引擎的表是在导入数据之后才建立索引的。
2. 禁用唯一性检查: 插入数据时,MySQL会对插入的记录进行唯一性校验。这种唯一性校验也会降低插入记录的速度。为了降低这种情况对查询速度的影响,可以在插入记录之前禁用唯一性检查,等到记录插入完毕后再开启。
3.使用批量插入:插入多条记录时,可以使用一条INSERT语句插入一条记录,也可以使用一条INSERT语句插入多条记录。使用一条INSERT语句插入多条记录的情形如下,而这种方式的插入速度更快。
4.使用LOAD DATA INFILE批量导入: 当需要批量导入数据时,如果能用LOAD DATA INFILE语句,就尽量使用。因为LOAD DATA INFILE语句导入数据的速度比INSERT语句快。对于InnoDB引擎的表,常见的优化方法如下:
1.禁用唯一性检查:插入数据之前执行set unique_checks=0来禁止对唯一索引的检查,数据导入完成之后再运行set unique_checks=1。这个和MyISAM引擎的使用方法一样。
2.禁用外键检查: 插入数据之前执行禁止对外键的检查,数据插入完成之后再恢复对外键的检查。
3.禁用自动提交: 插入数据之前禁止事务的自动提交,数据导入完成之后,执行恢复自动提交操作。
表中包含几千万条数据该怎么办(大数据量优化dsjyh)
优化SQL和索引;
增加缓存,如memcached、redis;
读写分离,可以采用主从复制,也可以采用主主复制;
使用MySQL自带的分区表,这对应用是透明的,无需改代码,但SQL语句是要针对分区表做优化的;
做垂直拆分,即根据模块的耦合度,将一个大的系统分为多个小的系统;
做水平拆分,要选择一个合理的sharding key,为了有好的查询效率,表结构也要改动,做一定的冗余,应用也要改,sql中尽量带sharding key,将数据定位到限定的表上去查,而不是扫描全部的表。
MySQL的慢查询优化有了解吗?(慢查询优化mcxyh)
开启慢查询日志:
MySQL中慢查询日志默认是关闭的,可以通过配置文件my.ini或者my.cnf中的log-slow-queries选项打开,也可以在MySQL服务启动的时候使用–log-slow-queries[=file_name]启动慢查询日志。
启动慢查询日志时,需要在my.ini或者my.cnf文件中配置long_query_time选项指定记录阈值,如果某条查询语句的查询时间超过了这个值,这个查询过程将被记录到慢查询日志文件中。
分析慢查询日志:
直接分析mysql慢查询日志,利用explain关键字可以模拟优化器执行SQL查询语句,来分析sql慢查询语句。
常见慢查询优化:
1.索引没起作用的情况:(1)在使用LIKE关键字进行查询的查询语句中,如果匹配字符串的第一个字符为“%”,索引不会起作用。只有“%”不在第一个位置,索引才会起作用。(2)MySQL可以为多个字段创建索引。一个索引可以包括16个字段。对于多列索引,只有查询条件中使用了这些字段中的第1个字段时索引才会被使用。(3)查询语句的查询条件中只有OR关键字,且OR前后的两个条件中的列都是索引时,查询中才使用索引。否则,查询将不使用索引。
2.优化数据库结构:(1)对于字段比较多的表,如果有些字段的使用频率很低,可以将这些字段分离出来形成新表。因为当一个表的数据量很大时,会由于使用频率低的字段的存在而变慢。(2)对于需要经常联合查询的表,可以建立中间表以提高查询效率。通过建立中间表,把需要经常联合查询的数据插入到中间表中,然后将原来的联合查询改为对中间表的查询,以此来提高查询效率。
3.分解关联查询很多高性能的应用都会对关联查询进行分解,就是可以对每一个表进行一次单表查询,然后将查询结果在应用程序中进行关联,很多场景下这样会更高效。
4.优化LIMIT分页: 当偏移量非常大的时候,例如可能是limit
10000,20这样的查询,这是mysql需要查询10020条然后只返回最后20条,前面的10000条记录都将被舍弃,这样的代价很高。优化此类查询的一个最简单的方法是尽可能的使用索引覆盖扫描,而不是查询所有的列。然后根据需要做一次关联操作再返回所需的列。对于偏移量很大的时候这样做的效率会得到很大提升。
MySQL主从同步是如何实现的(数据库主从同步 sjkzctb)
复制(replication)是MySQL数据库提供的一种高可用高性能的解决方案,一般用来建立大型的应用。总体来说,replication的工作原理分为以下3个步骤:
1.主服务器(master)把数据更改记录到二进制日志(binlog)中。
2.从服务器(slave)把主服务器的二进制日志复制到自己的中继日志(relay log)中。
3.从服务器重做中继日志中的日志,把更改应用到自己的数据库上,以达到数据的最终一致性。
复制的工作原理并不复杂,其实就是一个完全备份加上二进制日志备份的还原。不同的是这个二进制日志的还原操作基本上实时在进行中。这里特别需要注意的是,复制不是完全实时地进行同步,而是异步实时。这中间存在主从服务器之间的执行延时,如果主服务器的压力很大,则可能导致主从服务器延时较大。复制的工作原理如下图所示,其中从服务器有2个线程,一个是I/O线程,负责读取主服务器的二进制日志,并将其保存为中继日志;另一个是SQL线程,复制执行中继日志。
mysql日志(sjkrz)
错误日志:-log-err (记录启动,运行,停止mysql时出现的信息)
二进制日志:-log-bin (记录所有更改数据的语句,还用于复制,恢复数据库用)
查询日志:-log (记录建立的客户端连接和执行的语句)
慢查询日志: -log-slow-queries (记录所有执行超过long_query_time秒的所有查询)
更新日志: -log-update (二进制日志已经代替了老的更新日志,更新日志在MySQL 5.1中不再使用)
查询当前日志记录的状况
mysql>show variables like ‘log%’;(是否启用了日志)
mysql> show master status;(怎样知道当前的日志)
mysql> show master logs;(显示二进制日志的数目)
SQL的执行过程?(sqlzxlc)
MySQL 执行查询的过程
客户端通过 TCP 连接发送连接请求到 MySQL 连接器,连接器会对该请求进行权限验证及连接资源分配
查缓存。(当判断缓存是否命中时,MySQL 不会进行解析查询语句,而是直接使用 SQL 语句和客户端发送过来的其他原始信息。所以,任何字符上的不同,例如空格、注解等都会导致缓存的不命中。)
语法分析(SQL 语法是否写错了)。 如何把语句给到预处理器,检查数据表和数据列是否存在,解析别名看是否存在歧义。
优化。是否使用索引,生成执行计划。
交给执行器,将数据保存到结果集中,同时会逐步将数据缓存到查询缓存中,最终将结果集返回给客户端。
更新SQL的执行过程
首先客户端发送请求到服务端,建立连接。
服务端先看下查询缓存,对于更新某张表的SQL,该表的所有查询缓存都失效。
接着来到解析器,进行语法分析,一些系统关键字校验,校验语法是否合规。
然后优化器进行SQL优化,比如怎么选择索引之类,然后生成执行计划。
执行引擎去存储引擎查询需要更新的数据。
存储引擎判断当前缓冲池中是否存在需要更新的数据,存在就直接返回,否则去从磁盘加载数据。
执行引擎调用存储引擎API去更新数据。
存储引擎更新数据,同时写入undo_log、redo_log信息。
执行引擎写binlog,提交事务,流程结束。
说一说你对redolog、undolog、binlog的了解(redolog)
binlog(Binary Log): 二进制日志文件就是常说的binlog。二进制日志记录了MySQL所有修改数据库的操作,然后以二进制的形式记录在日志文件中,其中还包括每条语句所执行的时间和所消耗的资源,以及相关的事务信息。默认情况下,二进制日志功能是开启的,启动时可以重新配置–log-bin[=file_name]选项,修改二进制日志存放的目录和文件名称。
redo log:重做日志用来实现事务的持久性,即事务ACID中的D。它由两部分组成:一是内存中的重做日志缓冲(redo log buffer),其是易失的;二是重做日志文件(redo log file),它是持久的。InnoDB是事务的存储引擎,它通过Force Log at Commit机制实现事务的持久性,即当事务提交(COMMIT)时,必须先将该事务的所有日志写入到重做日志文件进行持久化,待事务的COMMIT操作完成才算完成。这里的日志是指重做日志,在InnoDB存储引擎中,由两部分组成,即redo log和undo log。 redo log用来保证事务的持久性,undo log用来帮助事务回滚及MVCC的功能。redolog基本上都是顺序写的,在数据库运行时不需要对redo log的文件进行读取操作。而undo log是需要进行随机读写的。
undo log: 重做日志记录了事务的行为,可以很好地通过其对页进行“重做”操作。但是事务有时还需要进行回滚操作,这时就需要undo。因此在对数据库进行修改时,InnoDB存储引擎不但会产生redo,还会产生一定量的undo。这样如果用户执行的事务或语句由于某种原因失败了,又或者用户用一条ROLLBACK语句请求回滚,就可以利用这些undo信息将数据回滚到修改之前的样子。
redo存放在重做日志文件中,与redo不同,undo存放在数据库内部的一个特殊段(segment)中,这个段称为undo段(undo segment),undo段位于共享表空间内。
redolog刷盘时机和策略
MySQL是采用两段提交策略来保证事务的原子性的,redo log刷盘的时机是在事务提交的commit阶段采取刷盘的,在此之前,redo log都存在于redo log buffer这块指定的内存区域中。
MySQL日志刷盘控制参数
innodb_flush_logs_at_trx_commit(redo log)
取值0:每次提交事务都只把redo log留在redo log buffer中
取值1:每次提交事务都将redo log 持久化到磁盘上,也就是write+fsync
取值2:每次都把redo log写到系统的page cache中,也就是只write,不fsync
sync_binlog(binlog)
取值0:每次提交都将binlog 从binlog cache中 write到磁盘上,而不fsync到磁盘
取值1:每次提交事务都将binlog fsync到磁盘上
取值N:每次提交事务都将binlog write到磁盘上,累计N个事务之后,执行fsync
什么是redolog的“两阶段提交” (ljdtj)
当MySQL更新数据的时候,其内部流程是怎么实现的呢?
假设我要执行一条SQL:update T set name = ‘winner’ where ID=2,那么内部执行流程为:
1、优化器找存储引擎取出ID=2这一行,如果ID=2这一行记录所在的数据页本身就在内存当中,那么就直接返回给执行器;否则需要从磁盘读取到内存当中,然后再返回给优化器;
2、优化器拿到行数据之后,会对内存中的数据页进行修改,同时将这个更新操作记录到Redo Log。此时Redo Log处于 perpare 状态,然后告知执行器已经完成了,可以随时提交事务;
3、接下来执行器会生成这个更新操作的binlog;
4、执行器调用存储引擎的提交事务的接口,将刚刚写入的Redo Log改成commit状态;
为什么是需要两阶段呢?
这里它的2阶段是对应于不同类型的日志,所以两阶段为的就是让这个2个不同的日志做好处理与准备。
1、假设是先写Redo Log,后写binlog。如果这个时候MySQL发生了进程的异常重启,由于Redo Log已经写完,MySQL崩溃之后通过crash_safe能力,能够把数据恢复回来。但是由于binlog还没写完就crash了,所以binlog里面并没有记录该SQL语句,所以使用binlog回档数据的时候,恢复出来的数据其实是少了一次更新操作的,这样就造成了灾难恢复出来的库和原库数据不一致;
2、假设是先写binlog,后写Redo Log。Binlog写完之后发生了crash,由于Redo Log还没有写,崩溃恢复之后这个事务的更新是无效的。但是binlog里面记录了这条更新的语句,所以使用binlog回档的时候就多了一条事务的更新。造成回档出来的数据和原库的数据不一致。
那么两阶段提交就是:
1、prepare阶段,写redo log;
2、commit阶段,写binlog并且将redo log的状态改成commit状态;
mysql发生崩溃恢复的过程中,会根据redo log日志,结合 binlog 记录来做事务回滚:
1、如果redo log 和 binlog都存在,逻辑上一致,那么提交事务;
2、如果redo log存在而binlog不存在,逻辑上不一致,那么回滚事务;
最后大家可发现,这里的两阶段提交,实际是存在与redo log与binlog。所以当未开启binlog,那就是提交事务直接写到redo log里面。这也就是redo log事务两阶段提交。
谈谈你对MVCC的了解(mvccdc)
InnoDB默认的隔离级别是RR(REPEATABLE READ),RR解决脏读、不可重复读、幻读等问题,使用的是MVCC。MVCC全称Multi-Version Concurrency Control,即多版本的并发控制协议。它最大的优点是读不加锁,因此读写不冲突,并发性能好。InnoDB实现MVCC,多个版本的数据可以共存,主要基于以下技术及数据结构:
1.隐藏列:InnoDB中每行数据都有隐藏列,隐藏列中包含了本行数据的事务id、指向undo log的指针等。
2.基于undo log的版本链:每行数据的隐藏列中包含了指向undo log的指针,而每条undo log也会指向更早版本的undo log,从而形成一条版本链。
3.ReadView:通过隐藏列和版本链,MySQL可以将数据恢复到指定版本。但是具体要恢复到哪个版本,则需要根据ReadView来确定。所谓ReadView,是指事务(记做事务A)在某一时刻给整个事务系统(trx_sys)打快照,之后再进行读操作时,会将读取到的数据中的事务id与trx_sys快照比较,从而判断数据对该ReadView是否可见,即对事务A是否可见。
MySQL的Hash索引和B树索引有什么区别?索引数据结构(hbqb) (b+dc)
hash索引底层就是hash表,进行查找时,调用一次hash函数就可以获取到相应的键值,之后进行回表查询获得实际数据。B+树底层实现是多路平衡查找树,对于每一次的查询都是从根节点出发,查找到叶子节点方可以获得所查键值,然后根据查询判断是否需要回表查询数据。它们有以下的不同:
hash索引进行等值查询更快(一般情况下),但是却无法进行范围查询。因为在hash索引中经过hash函数建立索引之后,索引的顺序与原顺序无法保持一致,不能支持范围查询。而B+树的的所有节点皆遵循(左节点小于父节点,右节点大于父节点,多叉树也类似),天然支持范围。
hash索引不支持使用索引进行排序,原理同上。
hash索引不支持模糊查询以及多列索引的最左前缀匹配,原理也是因为hash函数的不可预测。
hash索引任何时候都避免不了回表查询数据,而B+树在符合某些条件(聚簇索引,覆盖索引等)的时候可以只通过索引完成查询。
hash索引虽然在等值查询上较快,但是不稳定,性能不可预测,当某个键值存在大量重复的时候,发生hash碰撞,此时效率可能极差。而B+树的查询效率比较稳定,对于所有的查询都是从根节点到叶子节点,且树的高度较低。
因此,在大多数情况下,直接选择B+树索引可以获得稳定且较好的查询速度。而不需要使用hash索引。
MySQL采用B+树的优缺点,B树与B+树比较(bbqb)
由于mysql通常将数据存放在磁盘中,读取数据就会产生磁盘IO消耗。而B+树的非叶子节点中不保存数据,B树中非叶子节点会保存数据,通常一个节点大小会设置为磁盘页大小,这样B+树每个节点可放更多的key,B树则更少。这样就造成了,B树的高度会比B+树更高,从而会产生更多的磁盘IO消耗。
B+树叶子节点构成链表,更利用范围查找和排序。而B树进行范围查找和排序则要对树进行递归遍历
B树与B+树比较
B树适用于随机检索,而B+树适用于随机检索和顺序检索
B+树的空间利用率更高,因为B树每个节点要存储键和值,而B+树的内部节点只存储键,这样B+树的一个节点就可以存储更多的索引,从而使树的高度变低,减少了I/O次数,使得数据检索速度更快。
B+树的叶子节点都是连接在一起的,所以范围查找,顺序查找更加方便
B+树的性能更加稳定,因为在B+树中,每次查询都是从根节点到叶子节点,而在B树中,要查询的值可能不在叶子节点,在内部节点就已经找到。
B树优点:如果在B树中查找的数据离根节点近,由于B树节点中保存有数据,那么这时查询速度比B+树快。
为什么不使用红黑树(自平衡二叉搜索树)?
如果使用红黑树,会使树的高度更高,增加IO消耗
为什么不使用哈希表
哈希表对于范围查找和排序效率低,但对于单个数据的查询效率很高。
索引的类型有哪些?(sylx)
MySQL主要的索引类型主要有FULLTEXT,HASH,BTREE,RTREE。
FULLTEXT
FULLTEXT即全文索引,MyISAM存储引擎和InnoDB存储引擎在MySQL5.6.4以上版本支持全文索引,一般用于查找文本中的关键字,而不是直接比较是否相等,多在CHAR,VARCHAR,TAXT等数据类型上创建全文索引。全文索引主要是用来解决WHERE name LIKE "%zhang%"等针对文本的模糊查询效率低的问题。
HASH
HASH即哈希索引,哈希索引多用于等值查询,时间复杂夫为o(1),效率非常高,但不支持排序、范围查询及模糊查询等。
BTREE
BTREE即B+树索引,INnoDB存储引擎默认的索引,支持排序、分组、范围查询、模糊查询等,并且性能稳定。
RTREE
RTREE即空间数据索引,多用于地理数据的存储,相比于其他索引,空间数据索引的优势在于范围查找
索引的种类有哪些?(syzl)
主键索引:数据列不允许重复,不能为NULL,一个表只能有一个主键索引
组合索引:由多个列值组成的索引。
唯一索引:数据列不允许重复,可以为NULL,索引列的值必须唯一的,如果是组合索引,则列值的组合必须唯一。
全文索引:对文本的内容进行搜索。
普通索引:基本的索引类型,可以为NULL
MySQL高可用方案整理(sjkgky)
第一种:主从复制+读写分离
客户端通过Master对数据库进行写操作,slave端进行读操作,并可进行备份。Master出现问题后,可以手动将应用切换到slave端。
对于数据实时性要求不是特别严格的应用,只需要通过廉价的pc server来扩展Slave的数量,将读压力分散到多台Slave的机器上面,即可通过分散单台数据库服务器的读压力来解决数据库端的读性能瓶颈,毕竟在大多数数据库应用系统中的读压力要比写压力大的多。这在很大程度上解决了目前很多中小型网站的数据库压力瓶颈问题,甚至有些大型网站也在使用类似的方案解决数据库瓶颈问题。
第二种:Mysql Cluster
MySQL Cluster 由一组计算机构成,每台计算机上均运行着多种进程,包括 MySQL 服务器,NDB Cluster的数据节点,管理服务器,以及(可能)专门的数据访问程序。
由于MySQL Cluster架构复杂,部署费时(通常需要DBA几个小时的时间才能完成搭建),而依靠 MySQL Cluster Manager 只需一个命令即可完成,但 MySQL Cluster Manager 是收费的。并且业内资深人士认为NDB 不适合大多数业务场景,而且有安全问题。因此,使用的人数较少。
第三种:Heartbeat+双主从复制
heartbeat 是 Linux-HA 工程的一个组件,heartbeat 最核心的包括两个部分:心跳监测和资源接管。在指定的时间内未收到对方发送的报文,那么就认为对方失效,这时需启动资源接管模块来接管运 行在对方主机上的资源或者服务
第四种:HeartBeat+DRBD+Mysql
DRBD 是通过网络来实现块设备的数据镜像同步的一款开源 Cluster 软件,它自动完成网络中两个不同服务
器上的磁盘同步,相对于 binlog 日志同步,它是更底层的磁盘同步,理论上 DRDB 适合很多文件型系统的高可
用。
第五种:Lvs+keepalived+双主复制
Lvs 是一个虚拟的服务器集群系统,可以实现 LINUX 平台下的简单负载均衡。keepalived 是一个类似于
layer3, 4 & 5 交换机制的软件,主要用于主机与备机的故障转移,这是一种适用面很广的负载均衡和高可用方案,最常用于 Web 系统。
第六种:MariaDB Galera
MariaDB Galera Cluster 是一套在mysql innodb存储引擎上面实现multi-master及数据实时同步的系统架构,业务层面无需做读写分离工作,数据库读写压力都能按照既定的规则分发到 各个节点上去。在数据方面完全兼容 MariaDB 和 MySQL。
该架构主要有以下几种特性:
(1).同步复制 Synchronous replication
(2).Active-active multi-master 拓扑逻辑
(3).可对集群中任一节点进行数据读写
(4).自动成员控制,故障节点自动从集群中移除
(5).自动节点加入
(6).真正并行的复制,基于行级
(7).直接客户端连接,原生的 MySQL 接口
(8).每个节点都包含完整的数据副本
(9).多台数据库中数据同步由 wsrep 接口实现
其局限性体现在以下几点:
(1).目前的复制仅仅支持InnoDB存储引擎,任何写入其他引擎的表,包括mysql.*表将不会复制,但是DDL语句会被复制的,因此创建用户将会被复制,但是insert into mysql.user…将不会被复制的.
(2).DELETE操作不支持没有主键的表,没有主键的表在不同的节点顺序将不同,如果执行SELECT…LIMIT… 将出现不同的结果集.
(3).在多主环境下LOCK/UNLOCK TABLES不支持,以及锁函数GET_LOCK(), RELEASE_LOCK()…
(4).查询日志不能保存在表中。如果开启查询日志,只能保存到文件中。
(5).允许最大的事务大小由wsrep_max_ws_rows和wsrep_max_ws_size定义。任何大型操作将被拒绝。如大型的LOAD DATA操作。
(6).由于集群是乐观的并发控制,事务commit可能在该阶段中止。如果有两个事务向在集群中不同的节点向同一行写入并提交,失败的节点将中止。对 于集群级别的中止,集群返回死锁错误代码(Error: 1213 SQLSTATE: 40001 (ER_LOCK_DEADLOCK)).
(7).XA事务不支持,由于在提交上可能回滚。
(8).整个集群的写入吞吐量是由最弱的节点限制,如果有一个节点变得缓慢,那么整个集群将是缓慢的。为了稳定的高性能要求,所有的节点应使用统一的硬件。
(9).集群节点建议最少3个。
(10).如果DDL语句有问题将破坏集群。
秒杀实用方案(msfa)
秒杀的场景一般就是秒杀开始的前几分钟,大量用户进入商品详情界面,不断刷新。这时候系统的其他功能压力会变大。实际上,基本都是秒杀参与人多,秒杀成功的人很少。如何设计秒杀系统:
1.页面静态化
因为要秒杀的哪些商品,价格等信息都已经在秒杀之前就已经确定了,所以我们可以把相关信息全部放到这个静态页面中,然后把这个页面传到CDN上进行预热,用CDN抗流量。
2.请求拦截
前端,点击按钮置灰,防止重复提交
网关,避免攻击脚本,对下单等接口按userId限流,几秒钟只允许请求一次,更有甚者,其实可以把绝大部分的请求直接在网关层拒绝掉,按秒杀失败处理。比如我们有200个库存,我们可以只放行200个请求到后端服务,同时200个请求不是一起放行的,每隔100ms放行10个,把请求分在在各个时间段,缓解后端服务器的压力。
秒杀过程网关压力会比较大,网关可以做成集群,多节点分摊访问压力。
3.后端服务设计
假如秒杀库存就有几百万个,放行的下单就有几万个,这时候压力就在数据库了,扣减库存压力,创建订单压力。
库存可以放在Redis里面,来提高扣减库存吞吐的能力,对于热点商品的库存可以利用Redis分片存储。
创建订单可以走异步消息队列。后端服务接到下单请求,直接放进消息队列,监听服务取出消息后,先将订单信息写入Redis,每隔100ms或者积攒100条订单,批量写入数据库一次。前端页面下单后定时向后端拉取订单信息,获取到订单信息后跳转到支付页面。用这种批量异步写入数据库的方式大幅减少了数据库写入频次,从而明显降低了订单数据库写入压力。
4.隔离
业务隔离。从业务上把秒杀和日常的售卖区分开来,把秒杀做为营销活动,要参与秒杀的商品需要提前报名参加活动,这样我们就能提前知道哪些商家哪些商品要参与秒杀,可以根据提报的商品提前生成静态页面并上传到CDN预热,提报的商品库存也需要提前预热,可以将商品库存在活动开始前预热到Redis,避免秒杀开始后大量的缓存穿透。
部署隔离。秒杀相关服务和日常服务要分组部署,不能因为秒杀出问题影响日常售卖业务。可以申请单独的秒杀域名,从网络入口层就开始分流。网关也单独部署,秒杀走自己单独的网关,从而避免日常网关受到影响。秒杀可以复用订单,库存,支付等日常服务,只是需要一些小的改造(比如下单流程走消息队列,批量写入订单库,以及在Redis中扣减库存)。
数据隔离。为了避免秒杀活动影响到日常售卖业务,Redis缓存需要单独部署,甚至数据库也需要单独部署!数据隔离后,秒杀剩余的库存怎么办?秒杀活动结束后,剩余库存可以归还到日常库存继续做为普通商品售卖。数据隔离后,秒杀订单和日常订单不在相同的数据库,之后的订单查询怎么展示?可以在创建秒杀订单后发消息到消息队列,日常订单服务采取拉的方式消费消息,这时日常订单服务是主动方,可以采用线程池的方式,根据机器的性能来增加或缩小线程池的大小,控制拉取消息的速度,来控制订单数据库的写入压力。
5.网络
秒杀前要和网络运营商、CDN服务商提前申请带宽。
聊聊分库分表,需要停服嘛(fkfb)
假设有一个电商数据库存放订单、商品、支付三张业务表。随着业务量越来越大,这三张业务数据表也越来越大,查询性能显著降低,数据拆分势在必行,那么数据拆分可以从纵向和横向两个维度进行。
纵向拆分
纵向拆分就是按照业务拆分,我们将电商数据库拆分成三个库,订单库、商品库。支付库,订单表在订单库,商品表在商品库,支付表在支付库。这样每个库只需要存储本业务数据,物理隔离不会互相影响。
横向拆分
按照纵向拆分方案,现在我们已经有三个库了,平稳运行了一段时间。但是随着业务增长,每个单库单表的数据量也越来越大,逐渐到达瓶颈。
这时我们就要对数据表进行横向拆分,所谓横向拆分就是根据某种规则将单库单表数据分散到多库多表,从而减小单库单表的压力。
横向拆分策略有很多方案,最重要的一点是选好ShardingKey,也就是按照哪一列进行拆分,怎么分取决于我们访问数据的方式。
-
范围分片
如果我们选择的ShardingKey是订单创建时间,那么分片策略是拆分四个数据库,分别存储每季度数据,每个库包含三张表,分别存储每个月数据:
这个方案的优点是对范围查询比较友好,例如我们需要统计第一季度的相关数据,查询条件直接输入时间范围即可。这个方案的问题是容易产生热点数据。例如双11当天下单量特别大,就会导致11月这张表数据量特别大从而造成访问压力。 -
查表分片
查表法是根据一张路由表决定ShardingKey路由到哪一张表,每次路由时首先到路由表里查到分片信息,再到这个分片去取数据。我们分析一个查表法思想应用实际案例。
Redis官方在3.0版本之后提供了集群方案RedisCluster,其中引入了哈希槽(slot)这个概念。一个集群固定有16384个槽,在集群初始化时这些槽会平均分配到Redis集群节点上。
一个key请求过来怎么知道去哪台Redis节点获取数据?这就要用到查表法思想:(1) 客户端连接任意一台Redis节点,假设随机访问到节点A (2) 节点A根据key计算出slot值 (3)
每个节点都维护着slot和节点映射关系表 (4) 如果节点A查表发现该slot在本节点,直接返回数据给客户端 (5)
如果节点A查表发现该slot不在本节点,返回给客户端一个重定向命令,告诉客户端应该去哪个节点请求这个key的数据 (6)
客户端向正确节点发起连接请求
查表法方案优点是可以灵活制定路由策略,如果我们发现有的分片已经成为热点则修改路由策略。缺点是多一次查询路由表操作增加耗时,而且路由表如果是单点也可能会有单点问题。 -
哈希分片
现在比较流行的分片方法是哈希分片,相较于范围分片,哈希分片可以较为均匀将数据分散在数据库中。我们现在将订单库拆分为4个库编号为[0,3],每个库包含3张表编号为[0,2]
停服拆分
停服是指停止服务,系统不再接收新业务数据,那么旧数据在分库分表这个时间段内是静止不变的,数据全部变为了存量数据。停服拆分一般分为三个阶段。
第一阶段首先编写代理层和新DAO,代理层通过开关决定访问旧表还是新表,此时流量还是全部访问旧表:
第二阶段停止服务,整个应用都没有流量,旧表数据已经处于静止状态,此时通过脚本将存量数据从旧表迁移至新表:
第三阶段通过代理层访问新表,如果出现错误可以停服排查问题:
不停服拆分
停服拆分方案比较简单,但是在分表这段时间没有业务流量,对业务是有损的,所以我们一般采用不停服拆分方案,一边有流量访问,一边进行分库分表,此时数据不仅有存量还有增量,相对而言会复杂一些。
第一阶段首先编写代理层和新DAO,代理层通过开关决定访问旧表还是新表,此时流量还是全部访问旧表:
第二阶段开启双写,增量数据不仅在旧表新增和修改,也在新表新增和修改,日志或者临时表记录下写入新表ID起始值,旧表中小于这个值的数据就是存量数据:
第三阶段存量数据迁移,通过脚本将存量数据写入新表:
第四阶段停读旧表改读新表,此时新表已经承载了所有读写业务,但是不要立刻停写旧表,需要保持双写一段时间。
不停写旧表有两个原因:第一是因为如果读新表出现问题,还可以将读流量切回旧表。第二是因为可以进行数据校对,例如新表和旧表数据都同步至Hive,选取几天的数据进行校对,从而验证数据同步的准确性。
第五阶段当读写新表一段时间之后,没有发生业务问题,可以停写旧表:
怎么设计一个短链地址(dldz)
数据库设计
需要存储的数据的性质:
会有30B条记录
每条记录所占空间很小
记录与记录之间没有关系(relation)
服务是频繁读
数据库架构
我们需要两个表:
URL mapping表
用户信息表
算法
-
Hash编码 利用Hash编码软件,例如MD5或者SHA256,对原始长链接进行编码。
一个必须考虑的问题是,生成多长的Hash码,才能满足我们系统的需求?
编码的base可以是base36 ([a-z ,0-9])或者base62 ([A-Z, a-z,
0-9]),如果再加上+和/,我们可以使用base64的编码。使用base64的编码, 6字母编码有 64^6 = ~68.7 billion 不同的字符串。 使用base64的编码, 8字母编码有
64^8 = ~281 billion 不同的字符串。 因为我们的系统只需要存储30B条记录,6字母编码就足够了。采取此算法应注意Hash collision问题。
-
离线生成键 我们也可以使用独立的键生成服务(Key Generation
Service)。它提前生成随机的6位字符串,然后存储在键数据库里,需要产生短链接的时候,就从里面拿一个来用。这会使得整个事情变得非常简单便捷:我们不仅不需要为长链接编码,而且也不需要担心重复或者Hash
collision这样的事情。
并发问题
一个键被使用之后,数据库应该把它标记为已经被使用。但是,如果有多个服务器同时试图读写数据库里的键,并发问题就产生了。
一种解决办法是用唯一的KGS,而且KGS保证不会将同一个key分配给不同的服务器请求,这需要KGS有某种lock。
数据分区和副本
为了适用于大规模场景,我们可能需要将数据库进行分区或者增加副本。
-
根据首字母分区 根据Hash
key的首字母对数据库进行分区。更进一步,我们可以把更少访问的首字母分到一个区,更频繁访问的字母分成单独的区,以此来平衡分区大小。美中不足的是无法严格控制分区大小,比如以e开头的字母会很多,远超过其他字母。
-
根据Hash分区 根据Hash编码来分区,这样分区大小是可预计且可控的,会更加均衡一些。
缓存
应该对经常被访问到的链接进行cache,可以提高访问速度。
缓存大小 和前面估计的一样,我们会cache top20%的链接。这部分估计很小,很容易放进内存里。
什么时候清理缓存? 当cache满了之后,我们要删除一些链接并放入新的,怎么选择呢?可以使用LRU。
更新副本缓存
负载均衡器
我们可以在系统的三个地方添加负载均衡器(load balancer):
在用户层与代理层之间
在应用服务器与数据库之间
在应用服务器与缓存之间
一开始,我们可以使用最简单的round-robin方式,将访问请求平均分配到各个服务器上面。这个方法的优点是没有overhead,而且容易实现。如果一个服务器坏了,就把它从负载均衡器里面拿掉。
清理数据库
数据库累积太多数据的时候就应该被清理一下以腾出空间。当链接失效或者过时了,我们也应该清理掉相关数据。
我们应该做lazy cleanup来缓解数据库压力, 具体表现为:
- 当用户试图访问过时链接的时候,清理掉它并给用户返回错误信息。
- 建立一个单独的清理服务。这个服务定时周期运行,而且应该非常轻量。
- 我们可以给每个链接设置失效时限,过时自动清理。
- 清理掉的链接使用的key可以放回备用key库里面。
- 我们也可以清理长期没人访问的链接。
布隆过滤器(blglq)
布隆过滤器(英语:Bloom Filter)是 1970 年由 Burton Bloom 提出的。它实际上是一个很长的二进制矢量和一系列随机映射函数。它可以用来判断一个元素是否在一个集合中。它的优势是只需要占用很小的内存空间以及有着高效的查询效率。对于布隆过滤器而言,它的本质是一个位数组:位数组就是数组的每个元素都只占用 1 bit ,并且每个元素只能是 0 或者 1。
误判率
布隆过滤器可以插入元素,但不可以删除已有元素。其中的元素越多,false positive rate(误报率)越大,但是false negative (漏报)是不可能的。
补救方法
布隆过滤器存在一定的误识别率。常见的补救办法是在建立白名单,存储那些可能被误判的元素。 比如你苦等的offer 可能被系统丢在邮件垃圾箱(白名单)了。
使用场景
布隆过滤器的最大的用处就是,能够迅速判断一个元素是否在一个集合中。因此它有如下三个使用场景:
•网页爬虫对 URL 的去重,避免爬取相同的 URL 地址
•进行垃圾邮件过滤:反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮箱是否垃圾邮箱(同理,垃圾短信)
•有的黑客为了让服务宕机,他们会构建大量不存在于缓存中的 key 向服务器发起请求,在数据量足够大的情况下,频繁的数据库查询可能导致 DB 挂掉。布隆过滤器很好的解决了缓存击穿的问题。
为什么不能用散列表?
100 亿是一个很大的数量级,这里每条 url 平均 64 字节,全部存储的话需要 640G 的内存空间。又因为使用了散列表这种数据结构,而散列表是会出现散列冲突的。为了让散列表维持较小的装载因子,避免出现过多的散列冲突,需要使用链表法来处理,这里就要存储链表指针。因此最后的内存空间可能超过 1000G 了。
只是存储个 url 就需要 1000G 的空间,老板肯定不能忍!
位图法:就是用每一位来存放某种状态,适用于大规模数据,但数据状态又不是很多的情况。
另外,位图法有一个优势就是空间不随集合内元素个数的增加而增加。它的存储空间计算方式是找到所有元素里面最大的元素(假设为 N )缺点:空间复杂度随集合内最大元素增大而线性增大。对于开头的题目而言,使用位图进行处理,实际上内存消耗也是不少的。
采用自增ID和UUID的区别?(iuqb)
自增ID与UUID的比较
自增ID是有序的,而UUID是随机的。前面已经说了,如果主键是有序的,数据库可以具有更好的性能(至少对MySQL而已是如此)
自增ID所需的存储空间比UUID要小
由于自增ID比UUID更加简单,因此生成自增ID的生成速度也比UUID更快
自增ID与数据相关,主键会暴露出去的话,自增ID会显示当前表中的数据规模;而UUID则无此风险
自增ID在不同的数据库中可能重复,在分布式的环境下无法保证唯一。而UUID在分布式环境下也可以保证唯一
具体而已,自增ID在性能上更有优势,而UUID则更加适应分布式场景
何时使用自增ID,何时使用UUID
如果数据量非常大需要分库,或者需要更好的安全性,那么使用UUID
对于非敏感数据或者数据量没有大需要分库,使用自增id能节省存储空间并获得更好的性能
谈一谈,id全局唯一且自增,如何实现?(idzz xhsfdc)
例如之前单体项目中一个表中的数据主键id都是自增的,mysql是利用autoincrement来实现自增,而oracle是利用序列来实现的,但是当单表数据量上来以后就要进行水平分表,阿里java开发建议是单表大于500w的时候就要分表,但是具体还是得看业务,如果索引用的号的话,单表千万的数据也是可以的。水平分表就是将一张表的数据分成多张表,那么问题就来了如果还是按照以前的自增来做主键id,那么就会出现id重复,这个时候就得考虑用什么方案来解决分布式id的问题了。
SnowFlake雪花算法
雪花ID生成的是一个64位的二进制正整数,然后转换成10进制的数。64位二进制数由如下部分组成:
snowflake id生成规则
- 1位标识符:始终是0,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0。
- 41位时间戳:41位时间截不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 开始时间截
)得到的值,这里的的开始时间截,一般是我们的id生成器开始使用的时间,由我们程序来指定的。 - 10位机器标识码:可以部署在1024个节点,如果机器分机房(IDC)部署,这10位可以由 5位机房ID + 5位机器ID 组成。
- 12位序列:毫秒内的计数,12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号
优点
简单高效,生成速度快。
时间戳在高位,自增序列在低位,整个ID是趋势递增的,按照时间有序递增。
灵活度高,可以根据业务需求,调整bit位的划分,满足不同的需求。
缺点
依赖机器的时钟,如果服务器时钟回拨,会导致重复ID生成。
在分布式环境上,每个服务器的时钟不可能完全同步,有时会出现不是全局递增的情况。
一条 SQL 执行过长的时间,你如何优化,从哪些方面?(sqlyh)
1、查看 SQL 是否涉及多表的联表或者子查询,如果有,看是否能进行业务拆分,相关字段冗余或者合并成临时表(业务和算法的优化)
2、涉及链表的查询,是否能进行分表查询,单表查询之后的结果进行字段整合
3、如果以上两种都不能操作,非要链表查询,那么考虑对相对应的查询条件做索引。加快查询速度
4、针对数量大的表进行历史表分离(如交易流水表)
5、数据库主从分离,读写分离,降低读写针对同一表同时的压力,至于主从同步,MySQL 有自带的 binlog 实现 主从同步
6、explain 分析 SQL 语句,查看执行计划,分析索引是否用上,分析扫描行数等等
7、查看 MySQL 执行日志,看看是否有其他方面的问题
个人理解:从根本上来说,查询慢是占用 MySQL 内存比较多,那么可以从这方面去酌手考虑
垂直权限漏洞与水平权限漏洞(czqxld spqxld)
简单举例:假设A可以更改1 2 3三条数据 而B可以更改 2 3条数据。
那么我们一般会怎么做呢,会让用户A查询到123条数据,而用户B查询到23条数据
但是一般情况下,我们是对接口做的做的权限验证 此时B权限会拿到23条数据,那么B提交修改的时候只需要将修改的id更改成1的id即可(很多情况下我们会使用主键自增长的方式),所以很容易出现问题。
修复方案1:
这个是最直接有效的修复方案:在web层的逻辑中做鉴权,检查提交CRUD请求的操作者(通过session信息得到)与目标对象的权限所有者(查数据库)是否一致,如果不一致则阻断。这个方案实现成本低、能确保漏洞的修复质量,缺点是增加了一次查库操作。我之前一直用这种方案来对已发生的水平权限漏洞做紧急修复。
修复方案2:
我认为最正规的方案:把权限的控制转移到数据接口层中,避免出现select/update/delete … where addressID=#addressID#的SQL语句,使用selectt/update/delete… where addressID=#addressID# and ownerId=#userId#来代替,要求web层在调用数据接口层的接口时额外提供userid,而这个userid在web层看来只能通过seesion来取到。这样在面对水平权限攻击时,web层的开发者不用额外花精力去注意鉴权的事情,也不需要增加一个SQL来专门判断权限——如果权限不对的话,那个and条件就满足不了,SQL自然就找不到相关对象去操作。而且这个方案对于一个接口多个地方使用的情况也比较有利,不需要每个地方都鉴权了。但这个方案的缺陷在于实现起来要改动底层的设计,所以不适合作为修复方案,更适合作为统一的控制方案在最开始设计时就注意这方面的问题。
Redis(117)
redis 是什么?都有哪些使用场景?(rssycj)
Redis 使用场景:
1.缓存
这是Redis应用最广泛地方,基本所有的Web应用都会使用Redis作为缓存,来降低数据源压力,提高响应速度。
2.计数器
Redis天然支持计数功能,而且计数性能非常好,可以用来记录浏览量、点赞量等等。
3.排行榜
Redis提供了列表和有序集合数据结构,合理地使用这些数据结构可以很方便地构建各种排行榜系统。
4.社交网络
赞/踩、粉丝、共同好友/喜好、推送、下拉刷新。
5.消息队列
Redis提供了发布订阅功能和阻塞队列的功能,可以满足一般消息队列功能。
6.分布式锁
分布式环境下,利用Redis实现分布式锁,也是Redis常见的应用。
以一个电商项目的用户服务为例:
Token存储:用户登录成功之后,使用Redis存储Token
登录失败次数计数:使用Redis计数,登录失败超过一定次数,锁定账号
地址缓存:对省市区数据的缓存
分布式锁:分布式环境下登录、注册等操作加分布式锁
① Token 令牌生成,替代 Session,Session只存在于当前的 jvm 中,将 Token 存入 redis 里实现共享。
② 短信验证码 code。
③ 热点 key 预热,数据库第一次请求速度非常慢,热点数据(经常会被查询,但是不经常被修改或者删除的数据)放入redis。
④ 网页 PVUV 计数,由于 redis 是单线程线程安全可以保证计数的原子性。
⑤ 分布式锁 setnx、使用框架 resdison。
⑥ 订单的有效期 、使用 redis key 的有效期,key 失效监听,进行回调。
⑦ 实现注册中心、分布式配置中心
Redis为什么快呢?(rsk)
单机的Redis就可以⽀撑每秒十几万的并发,速度快的原因主要有⼏点:
完全基于内存操作
使⽤单线程,避免了线程切换和竞态产生的消耗
基于⾮阻塞的IO多路复⽤机制
C语⾔实现,优化过的数据结构,基于⼏种基础的数据结构,redis做了⼤量的优化,性能极⾼
Redis 线程是否安全 ?(rsxcaq)
安全,依靠 IO 多路复用提高处理效率
redis 官方不支持 windows 版本,windows 不支持 epoll
Redis的底层采用Nio中的多路复用的机制,能够非常好的支持这样的并发,从而保证
线程安全问题;。
Redis单线程,也就是底层采用一个线程维护多个不同的客户端io操作。.
但是 NIO 在不同的操作系统上实现的方式有所不同,在我们windows操作系统使用select
实现轮训时间复杂度是为o(n),而且还存在空轮训的情况,效率非常低,其次是 默认对我
们轮训的数据有一定限制,所以支持上万的 tcp 连接是非常难。
所以在 linux 操作系统采用 epoll 实现事件驱动回调,不会存在空轮训的情况,只对活跃的
socket 连接实现主动回调这样在性能上有大大的提升,所以时间复杂度是为o(1)。
所以为什么nginx redis.都能够非常高支持高并发,最终都是linux中的 IO 多路复用机制
epoll.
io 多路复用原则
服务器端只有一个线程去处理 n 多个请求,判断是否有数据,有数据进行流入 buffer 中写满后由才进行操作。
字节传输与 buffer 传输
字节流传输效率比较低,传输字节一个一个写入
buffer 传输效率比较高,写满后以一个块的形式把字节写入
Linux系统有三种方式实现IO多路复用:select、poll和epoll。(iodlfy)
(1)select:时间复杂度 O(n)
select 仅仅知道有 I/O 事件发生,但并不知道是哪几个流,所以只能无差别轮询所有流,找出能读出数据或者写入数据的流,并对其进行操作。所以 select 具有 O(n) 的无差别轮询复杂度,同时处理的流越多,无差别轮询时间就越长。
(2)poll:时间复杂度 O(n)
poll 本质上和 select 没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个 fd 对应的设备状态, 但是它没有最大连接数的限制,原因是它是基于链表来存储的。
(3)epoll:时间复杂度 O(1)
epoll 可以理解为 event poll,不同于忙轮询和无差别轮询,epoll 会把哪个流发生了怎样的 I/O 事件通知我们。所以说 epoll 实际上是事件驱动(每个事件关联上 fd)的。
**select,poll,epoll 都是 IO 多路复用的机制。**I/O 多路复用就是通过一种机制监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),就通知程序进行相应的读写操作。但 select,poll,epoll 本质上都是同步 I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步 I/O 则无需自己负责进行读写,异步 I/O 的实现会负责把数据从内核拷贝到用户空间。
Redis 中是否有事务机制?事务支持回滚吗?(rsswjz)
redis 不存在事务回滚。
Redis 支持事务,和 mysql 的事务有很大区别 ,Redis 一旦开启事务其他线程也可以对这个 key进行操作很难像mysql 一样保证数据的原子性 。
mysql 中一旦有线程对一行数据进行事务操作,其他线程对这一行数据是不能进行操作的,redis和mysql 正好相反。
Redis 的 Watch 采用乐观锁机制控制,乐观锁主要是指当每次拿数据的时候都认为都别人不会更改,所以不会上锁,允许多个线程进行操作,这也是 Redis 不能保证数据原子性的原因所在。
为什么 redis 不采用事务回滚?
回滚的目的就是将mysql的行锁进行释放,而 redis 不存在行锁,但是 redis 有取消事务,使用discard 会放弃事务块的所有命令。
Redis 与 mysql 如何保持数据一致性?(mrsjyzx)
根据CAP理论,在保证可用性和分区容错性的前提下,无法保证一致性,所以缓存和数据库的绝对一致是不可能实现的,只能尽可能保存缓存和数据库的最终一致性。
选择合适的缓存更新策略
1. 删除缓存而不是更新缓存
当一个线程对缓存的key进行写操作的时候,如果其它线程进来读数据库的时候,读到的就是脏数据,产生了数据不一致问题。
相比较而言,删除缓存的速度比更新缓存的速度快很多,所用时间相对也少很多,读脏数据的概率也小很多。
先更数据,后删缓存先更数据库还是先删缓存?这是一个问题。
更新数据,耗时可能在删除缓存的百倍以上。在缓存中不存在对应的key,数据库又没有完成更新的时候,如果有线程进来读取数据,并写入到缓存,那么在更新成功之后,这个key就是一个脏数据。
毫无疑问,先删缓存,再更数据库,缓存中key不存在的时间的时间更长,有更大的概率会产生脏数据。
目前最流行的缓存读写策略cache-aside-pattern就是采用先更数据库,再删缓存的方式。
1.消息队列保证key被删除可以引入消息队列,把要删除的key或者删除失败的key丢尽消息队列,利用消息队列的重试机制,重试删除对应的key。
2.通过 redis 发布订阅,去订阅到数据库的 binlog 保持和mysql数据一致性。
3.采用增量 binlog 同步的方案,可以直接通过 Canal 组件,监控 Mysql 中 binlog 的日志,把更新后的数据同 步到 Redis 里面
Redis 与 本地缓存 如何保持数据一致性?(rbsjyzx)
在日常的开发中,我们常常采用两级缓存:本地缓存+分布式缓存。
所谓本地缓存,就是对应服务器的内存缓存,比如Caffeine,分布式缓存基本就是采用Redis。
Redis缓存,数据库发生更新,直接删除缓存的key即可,因为对于应用系统而言,它是一种中心化的缓存。
但是本地缓存,它是非中心化的,散落在分布式服务的各个节点上,没法通过客户端的请求删除本地缓存的key,所以得想办法通知集群所有节点,删除对应的本地缓存key。
可以采用消息队列的方式:
- 采用Redis本身的Pub/Sub机制,分布式集群的所有节点订阅删除本地缓存频道,删除Redis缓存的节点,同事发布删除本地缓存消息,订阅者们订阅到消息后,删除对应的本地key。但是Redis的发布订阅不是可靠的,不能保证一定删除成功。
- 引入专业的消息队列,比如RocketMQ,保证消息的可靠性,但是增加了系统的复杂度。
- 设置适当的过期时间兜底,本地缓存可以设置相对短一些的过期时间。
Redis 宕机,数据会丢失吗? ☆☆☆☆☆
不会,因为有 RDB 和AOF
开启AOF 持久化最多可能丢失 1s 数据。
Redis 中如何存放对象 ☆☆☆
存放 json 、存放二进制
json 阅读性比较强
二进制 阅读性比较差(不能跨语言)
Redis 内存满了怎么办?☆☆☆☆
使用淘汰策略,将一些不使用的 key 提前释放掉
voltile-lru 从已经设置过期时间的数据集中挑选最近最少使用的数据淘汰
voltile-ttl 从已经设置过期时间的数据库集当中挑选将要过期的数据
voltile-random 从已经设置过期时间的数据集任意选择淘汰数据
allkeys-lru 从数据集中挑选最近最少使用的数据淘汰
allkeys-random 从数据集中任意选择淘汰的数据
no-eviction 禁止驱逐数据
Redis 如何实现高可用? 哨兵机制的作用?☆☆☆☆☆(rsgkyjz)
保证redis高可用机制需要redis主从复制、redis持久化机制、哨兵机制、keepalived等的支持。
主从复制的作用:数据备份、读写分离、分布式集群、实现高可用、宕机容错机制等。
为什么要做高可用集群?
redis 可能出现单点故障,如果采用主从复制一旦宕机,需要手动的去选择一个主节点出来效率极低。
因此引用哨兵机制,让哨兵进程监控 master 状态,当它存在宕机会自动的选出一个从节点作为新的主节点。
一.redis主从复制原理(rszcfz)
首先主从复制需要分为两个角色:master(主) 和 slave(从) ,注意:redis里面只支持一个主,不像Mysql、Nginx主从复制可以多主多从。
1、redis的复制功能是支持多个数据库之间的数据同步。一类是主数据库(master)一类是从数据库(slave),主数据库可以进行读写操作,当发生写操作的时候自动将数据同步到从数据库,而从数据库一般是只读的,并接收主数据库同步过来的数据,一个主数据库可以有多个从数据库,而一个从数据库只能有一个主数据库。
2、通过redis的复制功能可以很好的实现数据库的读写分离,提高服务器的负载能力。主数据库主要进行写操作,而从数据库负责读操作。
Redis主从复制的工作流程大概可以分为如下几步:
- 保存主节点(master)信息 这一步只是保存主节点信息,保存主节点的ip和port。
- 主从建立连接 从节点(slave)发现新的主节点后,会尝试和主节点建立网络连接。
- 发送ping命令 连接建立成功后从节点发送ping请求进行首次通信,主要是检测主从之间网络套接字是否可用、主节点当前是否可接受处理命令。
- 权限验证 如果主节点要求密码验证,从节点必须正确的密码才能通过验证。
- 同步数据集 主从复制连接正常通信后,主节点会把持有的数据全部发送给从节点。
- 命令持续复制 接下来主节点会持续地把写命令发送给从节点,保证主从数据一致性。
二.哨兵机制需要主从复制的支持。(rssbjz)
Redis的哨兵(sentinel) 系统用于管理多个 Redis 服务器,该系统执行以下三个任务:
· 监控(Monitoring): 哨兵(sentinel) 会不断地检查你的Master和Slave是否运作正常。
· 提醒(Notification):当被监控的某个Redis出现问题时, 哨兵(sentinel) 可以通过 API 向管理员或者其他应用程序发送通知。
· 自动故障迁移(Automatic failover):当一个Master不能正常工作时,哨兵(sentinel) 会开始一次自动故障迁移操作,它会将失效Master的其中一个Slave升级为新的Master, 并让失效Master的其他Slave改为复制新的Master; 当客户端试图连接失效的Master时,集群也会向客户端返回新Master的地址,使得集群可以使用Master代替失效Master。
哨兵(sentinel) 是一个分布式系统,你可以在一个架构中运行多个哨兵(sentinel) 进程,这些进程使用流言协议(gossipprotocols)来接收关于Master是否下线的信息,并使用投票协议(agreement protocols)来决定是否执行自动故障迁移,以及选择哪个Slave作为新的Master.
每个哨兵(sentinel) 会向其它哨兵(sentinel)、master、slave定时发送消息,以确认对方是否”活”着,如果发现对方在指定时间(可配置)内未回应,则暂时认为对方已挂(所谓的”主观认为宕机” Subjective Down,简称sdown).
若“哨兵群”中的多数sentinel,都报告某一master没响应,系统才认为该master"彻底死亡"(即:客观上的真正down机,Objective Down,简称odown),通过一定的vote算法,从剩下的slave节点中,选一台提升为master,然后自动修改相关配置.
哨兵机制的作用?(rssbjz)
哨兵机制,比较类似ZK的设计思路。
哨兵数量与Redis节点数量一致,单个哨兵监控主节点,发现主节点出现故障或者宕机会让另一个哨兵对主节点进行检查如果发现主节点失效,会选择新一个主节点。
** 哨兵机制的优缺点**
1、哨兵集群中只要有一台宕了,整个集群的故障转移机制就失效了。
2、哨兵启动时候redis主库必需运行正常,否则故障转移机制也失效。
3、应用端需要先询问哨兵才能访问到redis主库,是否对效率也有明显的影响。
4、只能存在一个master节点不能存在多个,数据可能产生冗余,数据同步效率较低,浪费资源。
光靠redis主从复制和哨兵机制不足以实现redis高可用。为什么呢?
因为若某一节点宕机后,不会实现自动重启。最稳健实现高可用的做法 :
redis主从复制+哨兵机制(监控、提醒、自动故障迁移)+keepalived(自动重启),若重启多次仍不成功,可以通过邮件短信等方式通知。
Redis 集群有哪些方案?(三种方案)☆☆☆(rsjqdc)
前面说到了主从存在高可用和分布式的问题,哨兵解决了高可用的问题,而集群就是终极方案,一举解决高可用和分布式问题。
Redis集群通过数据分区来实现数据的分布式存储,通过自动故障转移实现高可用。
数据分区: 数据分区 (或称数据分片) 是集群最核心的功能。集群将数据分散到多个节点,一方面 突破了 Redis 单机内存大小的限制,存储容量大大增加;另一方面 每个主节点都可以对外提供读服务和写服务,大大提高了集群的响应能力。
集群中数据如何分区?
方案一:节点取余分区
节点取余分区,非常好理解,使用特定的数据,比如Redis的键,或者用户ID之类,对响应的hash值取余:hash(key)%N,来确定数据映射到哪一个节点上。
不过该方案最大的问题是,当节点数量变化时,如扩容或收缩节点,数据节点映射关 系需要重新计算,会导致数据的重新迁移。
方案二:一致性哈希分区
将整个 Hash 值空间组织成一个虚拟的圆环,然后将缓存节点的 IP 地址或者主机名做 Hash 取值后,放置在这个圆环上。当我们需要确定某一个 Key 需 要存取到哪个节点上的时候,先对这个 Key 做同样的 Hash 取值,确定在环上的位置,然后按照顺时针方向在环上“行走”,遇到的第一个缓存节点就是要访问的节点。
方案三:虚拟槽分区
这个方案 一致性哈希分区的基础上,引入了 虚拟节点 的概念。Redis 集群使用的便是该方案,其中的虚拟节点称为 槽(slot)。槽是介于数据和实际节点之间的虚拟概念,每个实际节点包含一定数量的槽,每个槽包含哈希值在一定范围内的数据。
高可用: 集群支持主从复制和主节点的 自动故障转移 (与哨兵类似),当任一节点发生故障时,集群仍然可以对外提供服务。故障发现Redis集群内节点通过ping/pong消息实现节点通信,集群中每个节点都会定期向其他节点发送ping消息,接收节点回复pong 消息作为响应。如果在cluster-node-timeout时间内通信一直失败,则发送节 点会认为接收节点存在故障,把接收节点标记为主观下线(pfail)状态。当某个节点判断另一个节点主观下线后,相应的节点状态会跟随消息在集群内传播。通过Gossip消息传播,集群内节点不断收集到故障节点的下线报告。当 半数以上持有槽的主节点都标记某个节点是主观下线时。触发客观下线流程。故障节点变为客观下线后,如果下线节点是持有槽的主节点则需要在它 的从节点中选出一个替换它,从而保证集群的高可用。
设置节点
Redis集群一般由多个节点组成,节点数量至少为6个才能保证组成完整高可用的集群。每个节点需要开启配置cluster-enabled yes,让Redis运行在集群模式下。
节点握手
节点握手是指一批运行在集群模式下的节点通过Gossip协议彼此通信, 达到感知对方的过程。节点握手是集群彼此通信的第一步,由客户端发起命 令:cluster meet{ip}{port}。完成节点握手之后,一个个的Redis节点就组成了一个多节点的集群。
分配槽(slot)
Redis集群把所有的数据映射到16384个槽中。每个节点对应若干个槽,只有当节点分配了槽,才能响应和这些槽关联的键命令。通过 cluster addslots命令为节点分配槽。
redis集群三种方案(rsjqszfa)
1.主从模式
为什么要用主从复制
单机redis的风险与问题
问题一:机器故障
硬盘故障,系统崩溃
本质:数据丢失,可能对业务造成灾难性打击
问题二:容量瓶颈
内存不足,一台redis内存是有限的
解决方案:
为了避免单点Redis服务器故障,准备多台服务器,互相联通,将数据复制多个副本保存在不同服务器上,连接在一起,并保证数据是同步的,即使有其中一台服务器宕机,其他服务器依然可以继续提供服务,实现Redis的高可用,同时实现数据冗余备份
特征
一个master可以拥有多个slave,一个slave只对应一个master
主从复制即将master中的数据及时,有效的复制到slave中
作用
读写分离:master写,slave度,提高服务器的读写负载能力
负载均衡:基于主从结构,配合读写分离,由slave分担master负载,并根据需求的变化,改变slave的数据,通过多个结点分担数据读取负载,大大提高Redis服务器并发量与数据吞吐量
故障恢复:当master出现问题时,由slave提供服务,实现快速的故障恢复
数据冗余:实现数据热备份,是持久化之外的一种数据冗余方式
高可用基石:基于主从复制,构建哨兵模式与集群,实现Redis的高可用方案
工作流程
分三个阶段
建立连接阶段-建立slave到master的连接,使master能够识别slave,并保存slave端口号
数据同步阶段-在slave初次连接master后,复制master中的所有数据到slave
命令传播阶段-当master数据库状态被修改后,导致主从服务器数据库状态不一致,此时需要让主从数据同步到一致的状态
心跳机制
进入命令传播阶段候,master与slave间需要进行信息交换,使用心跳机制进行维护,实现双方连接保持在
master心跳:
指令:PING
周期:由repl-ping-slave-period决定,默认10秒
作用:判断slave是否在线
查询:INFO replication 获取slave最后一次连接时间间隔,lag项维持在0或1视为正常
slave心跳任务
指令:REPLCONF ACK {offset}
周期:1秒
作用1:汇报slave自己的复制偏移量,获取最新的数据变更指令
作用2:判断master是否在线
总结:
主数据库可以进行读写操作,当读写操作导致数据变化时会自动将数据同步给从数据库
从数据库一般都是只读的,并且接收主数据库同步过来的数据
一个master可以拥有多个slave,但是一个slave只能对应一个master
slave挂了不影响其他slave的读和master的读和写,重新启动后会将数据从master同步过来
master挂了以后,不影响slave的读,但redis不再提供写服务,master重启后redis将重新对外提供写服务
master挂了以后,不会在slave节点中重新选一个master,只能手动的一个一个改,不合适,就有了之后的哨兵
2.哨兵模式
哨兵(sentinel)是一个分布式系统,用于对主从结构中的每台服务器进行监控,当出现故障时通过投票机制选择新的master并将所有slave连接到新的master
为什么有哨兵
主机宕机,如何能够高可用的恢复正常,不用人为进行干预
作用
监控
- 不断地检查master和slave是否正常运行
- master存活检测,master与slave运行清空检测
通知(提醒)
- 当被监控地服务器出现问题时,向其他(哨兵、客户端)发送通知
自动故障转移
- 断开master与slave连接,选取一个slave作为master,将其他slave连接到新地master,并告知客户端新地服务器地址
注意:
哨兵也是一台redis服务器,只是不提供数据服务
通常哨兵配置数量为单数
3.Cluster模式
redis最开始使用主从模式做集群,若master宕机需要手动配置slave转为master;后来为了高可用提出来哨兵模式,该模式下有一个哨兵监视master和slave,若master宕机可自动将slave转为master,但它也有一个问题,就是不能动态扩充,哨兵模式还是只有一个master;所以在3.x提出cluster集群模式。
redis cluster在设计的时候,就考虑到了去中心化,去中间件,也就是说,集群中的每个节点都是平等的关系,都是对等的,每个节点都保存各自的数据和整个集群的状态。每个节点都和其他所有节点连接,而且这些连接保持活跃,这样就保证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据。
那么redis 是如何合理分配这些节点和数据的呢?
Redis 集群没有并使用传统的一致性哈希来分配数据,而是采用另外一种叫做哈希槽 (hash slot)的方式来分配的。redis cluster 默认分配了 16384 个slot,当我们set一个key 时,会用CRC16算法来取模得到所属的slot,然后将这个key 分到哈希槽区间的节点上,具体算法就是:CRC16(key) % 16384。
在redis-cluster架构中,redis-master节点一般用于接收读写,而redis-slave节点则一般只用于备份,其与对应的master拥有相同的slot集合,若某个redis-master意外失效,则再将其对应的slave进行升级为临时redis-master。
订单超时自动取消如何实现? ☆☆☆☆☆
使用 Token 当 Token 失效时会走客户端的回调方法,检测订单是否支付,没有支付直接提示订单超时。
Redis 主从复制如果网络延时怎么办?☆☆☆☆(rszcfz)
不能解决属于强一致性问题,只能采用最终一致性方案,人工进行数据迁移,如果做了持久化将持久化文件传到从节点中。
1、强一致性:在任何时刻所有的用户或者进程查询到的都是最近一次成功更新的数据。强一致性是程度最高一致性要求,也是最难实现的。关系型数据库更新操作就是这个案例。
2、最终一致性:和强一致性相对,在某一时刻用户或者进程查询到的数据可能都不同,但是最终成功更新的数据都会被所有用户或者进程查询到。当前主流的nosql数据库都是采用这种一致性策略。
Redis 主从同步效率非常慢怎么解决?☆☆☆☆
采用多主多从或者是树状形式实现同步。
Redis Cluster 集群 ☆☆☆☆☆
对key进行分片存储在不同卡槽,分摊 key 存放
卡槽逻辑根据 crc16(meite)=50018%16384=9666
快速进行扩容和缩容,同步效率比较高
说说你对redis 哨兵机制的理解 ☆☆☆☆☆(rssbjz)
(1)集群监控,负责监控redis master 和slave进程是否正常工作。
(2)消息通知,如果某个redis实例有故障,那么哨兵负责发送消息作为报警通知给管理员。
(3)故障转移,如果master node挂掉了,会自动转移到slave node上。
(4)配置中心,如果故障转移发生了,通知client客户端新的master地址。
(1)故障转移时,判断一个master node宕机了,需要大部分哨兵都同意才行,涉及到分布式选举问题。
(2)即使部分哨兵节点挂掉了,哨兵集群还是能正常工作的,因为如果一个作为高可用机制重要组成部分的故障转移系统本身就是单点,那么就不靠谱。
哨兵的核心知识
哨兵至少需要3个实例,来保证自己的健壮性。
哨兵+redis主从的部署架构,是不会保证数据零丢失的,只能保证redis集群的高可用性
对于哨兵+redis主从这种复杂的部署架构,尽量在测试环境和生产环境,都进行充分的测试和演练。
为什么 Redis 需要把所有数据放到内存中?☆☆☆☆☆(rsnc)
Redis 为了达到最快的读写速度将数据都读到内存中,并通过异步的方式将数据写入磁盘。
所以 redis 具有快速和数据持久化的特征,如果不将数据放在内存中,磁盘 I/O 速度为严重影响 redis 的性能。
在内存越来越便宜的今天,redis 将会越来越受欢迎, 如果设置了最大使用的内存,则数据已有记录数达
到内存限值后不能继续插入新值。
redis 和 memecache 有什么区别?(rmqb)
memcached所有的值均是简单的字符串,redis作为其替代者,支持更为丰富的数据类型
redis的速度比memcached快很多
redis可以持久化其数据
说说 Redis 的线程模型(rsxcmx rsdxcmx)
Redis 内部使用文件事件处理器 file event handler ,这个文件事件处理器是单线程的,所以
Redis 才叫做单线程的模型。它采用 IO 多路复用机制同时监听多个 socket ,根据 socket 上的事
件来选择对应的事件处理器进行处理。
文件事件处理器的结构包含 4 个部分:
- 多个 socket 。
- IO 多路复用程序。
- 文件事件分派器。
- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)。
多个 socket 可能会并发产生不同的操作,每个操作对应不同的文件事件,但是 IO 多路复用程序会监听多个 socket,会将 socket 产生的事件放入队列中排队,事件分派器每次从队列中取出一个事件,把该事件交给对应的事件处理器进行处理。
redis 为什么是单线程的?(rsdxc)
因为 cpu 不是 Redis 的瓶颈,Redis 的瓶颈最有可能是机器内存或者网络带宽。既然单线程容易实现,而且 cpu又不会成为瓶颈,那就顺理成章地采用单线程的方案了。
关于 Redis 的性能,官方网站也有,普通笔记本轻松处理每秒几十万的请求。
而且单线程并不代表就慢, nginx 和 nodejs 也都是高性能单线程的代表。
Redis6.0的多线程是用多线程来处理数据的读写和协议解析,但是Redis执行命令还是单线程的。这样做的⽬的是因为Redis的性能瓶颈在于⽹络IO⽽⾮CPU,使⽤多线程能提升IO读写的效率,从⽽整体提⾼Redis的性能。
什么是缓存穿透,缓存击穿,缓存雪崩,缓存预热,缓存更新?怎么解决?(hcjc)
缓存穿透:指查询一个一定不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,造成缓存穿透。
解决方案:最简单粗暴的方法如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们就把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。一种方式是在数据库不命中之后,把一个空对象或者默认值保存到缓存,之后再访问这个数据,就会从缓存中获取,这样就保护了数据库。
缓存击穿:是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个key不停进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞.
解决办法:1:加锁更新,⽐如请求查询A,发现缓存中没有,对A这个key加锁,同时去数据库查询数据,写⼊缓存,再返回给⽤户,这样后⾯的请求就可以从缓存中拿到数据了。2:将过期时间组合写在value中,通过异步的⽅式不断的刷新过期时间,防⽌此类现象。
缓存雪崩:是指在某一个时间段,缓存集中过期失效,比方说:我们设置缓存时采用了相同的过期时间,在同一时刻出现大面积的缓存过期,所有原本应该访问缓存的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机。从而形成一系列连锁反应,造成整个系统崩溃。
解决办法:一个简单方案就是缓存失效时间分散开,不设置固定的失效时间,采用随机失效的策略来解决。最多的解决方案就是锁,或者队列的方式来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。
缓存预热:缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
操作方式:1、直接写个缓存刷新页面,上线时手工操作下;2、数据量不大,可以在项目启动的时候自动进行加载;3、定时任务刷新缓存.
缓存更新:1、定时去清理过期的缓存;2.、当有用户请求过来时,再判断这个请求所用到的缓存是否过期,过期的话就去底层系统得到新数据并更新缓存。
redis 支持的数据类型有哪些?(rssjlx)
1.String:这个没啥好说的,最常规的 set/get 操作,Value 可以是 String 也可以是数字。一般做一些复杂的计数功能的缓存。我们项目用户登录获取短信验证码、还有首页广告位及banner图这些热点数据都是放的String类型
2.Hash:这里 Value 存放的是结构化的对象,比较方便的就是操作其中的某个字段。 我在做单点登录的时候,就是用这种数据结构存储用户信息,以 CookieId 作为 Key,设置 30 分钟为缓存过期时间,能很好的模拟出类似
Session 的效果。
3.List:使用 List 的数据结构,可以做简单的消息队列的功能。另外还有一个就是,可以利用 lrange 命令,做基于 Redis 的分页功能,性能极佳,用户体验好。列表主要有以下几种使用场景:消息队列,文章列表
4.Set:因为 Set 堆放的是一堆不重复值的集合。所以可以做全局去重的功能。为什么不用 JVM 自带的 Set 进行去重?因为我们的系统一般都是集群部署,使用 JVM 自带的Set,比较麻烦,难道为了一个做一个全局去重,再起一个公共服务,太麻烦了。另外,就是利用交集、并集、差集等操作,可以计算共同喜好,全部的喜好,自己独有的喜好等功能。集合主要有如下使用场景:标签(tag),共同关注
5.Sorted Set:Sorted Set多了一个权重参数 Score,集合中的元素能够按Score 进行排列。可以做排行榜应用,取TOP N 操作。Sorted Set可以用来做延时任务。最后一个应用就是可以做范围查找。
**跳表(tbdc)**是一种有序的数据结构,它通过在每个节点中维持多个指向其他的几点指针,从而达到快速访问队尾目的。跳跃表的效率可以和平衡树想媲美了,最关键是它的实现相对于平衡树来说,代码的实现上简单很多。skiplist本质上是并行的有序链表,但它克服了有序链表插入和查找性能不高的问题。它的插入和查询的时间复杂度都是O(logN)。每个跳表都必须设定一个最大的连接层数MaxLevel,第一层连接会连接到表中的每个元素,插入一个元素会随机生成一个连接层数值[1, MaxLevel]之间,根据这个值跳表会给这元素建立N个连接,插入某个元素的时候先从最高层开始,当跳到比目标值大的元素后,回退到上一个元素,用该元素的下一层连接进行遍历,周而复始直到第一层连接,最终在第一层连接中找到合适的位置。
说说Redis底层数据结构?(rsdcsjjg)
Redis有动态字符串(sds)、链表(list)、字典(ht)、跳跃表(skiplist)、整数集合(intset)、压缩列表(ziplist) 等底层数据结构。
Redis并没有使用这些数据结构来直接实现键值对数据库,而是基于这些数据结构创建了一个对象系统,来表示所有的key-value。
1.字符串:redis没有直接使⽤C语⾔传统的字符串表示,⽽是⾃⼰实现的叫做简单动态字符串SDS的抽象类型。
C语⾔的字符串不记录⾃身的⻓度信息,⽽SDS则保存了⻓度信息,这样将获取字符串⻓度的时间由O(N)降低到了O(1),同时可以避免缓冲区溢出和减少修改字符串⻓度时所需的内存重分配次数。
2.链表linkedlist:redis链表是⼀个双向⽆环链表结构,很多发布订阅、慢查询、监视器功能都是使⽤到了链表来实现,每个链表的节点由⼀个listNode结构来表示,每个节点都有指向前置节点和后置节点的指针,同时表头节点的前置和后置节点都指向NULL。
3.字典dict:⽤于保存键值对的抽象数据结构。Redis使⽤hash表作为底层实现,一个哈希表里可以有多个哈希表节点,而每个哈希表节点就保存了字典里中的一个键值对。每个字典带有两个hash表,供平时使⽤和rehash时使⽤,hash表使⽤链地址法来解决键冲突,被分配到同⼀个索引位置的多个键值对会形成⼀个单向链表,在对hash表进⾏扩容或者缩容的时候,为了服务的可⽤性,rehash的过程不是⼀次性完成的,⽽是渐进式的。
4.跳跃表skiplist:跳跃表是有序集合的底层实现之⼀,Redis中在实现有序集合键和集群节点的内部结构中都是⽤到了跳跃表。Redis跳跃表由zskiplist和zskiplistNode组成,zskiplist⽤于保存跳跃表信息(表头、表尾节点、⻓度等),zskiplistNode⽤于表示表跳跃节点,每个跳跃表节点的层⾼都是1-32的随机数,在同⼀个跳跃表中,多个节点可以包含相同的分值,但是每个节点的成员对象必须是唯⼀的,节点按照分值⼤⼩排序,如果分值相同,则按照成员对象的⼤⼩排序。
5.整数集合intset:⽤于保存整数值的集合抽象数据结构,不会出现重复元素,底层实现为数组。
6.压缩列表ziplist:压缩列表是为节约内存⽽开发的顺序性数据结构,它可以包含任意多个节点,每个节点可以保存⼀个字节数组或者整数值。
redis 支持的 java 客户端都有哪些?
Redisson、Jedis、lettuce等等,官方推荐使用Redisson。
jedis 和 redisson 有哪些区别?(jrqb)
Jedis是Redis的Java实现的客户端,其API提供了比较全面的Redis命令的支持。
Redisson实现了分布式和可扩展的Java数据结构,和Jedis相比,功能较为简单,不支持字符串操作,不支持排序、事务、管道、分区等Redis特性。Redisson的宗旨是促进使用者对Redis的关注分离,从而让使用者能够将精力更集中地放在处理业务逻辑上。
怎么保证缓存和数据库数据的一致性?(mrsjyzx)
合理设置缓存的过期时间。
新增、更改、删除数据库操作时同步更新 Redis,可以使用事务机制来保证数据的一致性。
延迟双删策略:先进行缓存清除,再执行update,最后(延迟N秒)再执行缓存清除。
方案一
通过key的过期时间,mysql更新时,redis不更新。
这种方式实现简单,但不一致的时间会很长。如果读请求非常频繁,且过期时间比较长,则会产生很多长期的脏数据。
优点:开发成本低,易于实现;管理成本低,出问题的概率会比较小。
不足:完全依赖过期时间,时间太短容易缓存频繁失效,太长容易有长时间更新延迟(不一致)
方案二
在方案一的基础上扩展,通过key的过期时间兜底,并且,在更新mysql时,同时更新redis。
优点:相对方案一,更新延迟更小。
不足:如果更新mysql成功,更新redis却失败,就退化到了方案一;在高并发场景,业务server需要和mysql,redis同时进行连接。这样是损耗双倍的连接资源,容易造成连接数过多的问题。
方案三
针对方案二的同步写redis进行优化,增加消息队列,将redis更新操作交给kafka,由消息队列保证可靠性,再搭建一个消费服务,来异步更新redis。
优点:消息队列可以用一个句柄,很多消息队列客户端还支持本地缓存发送,有效解决了方案二连接数过多的问题;使用消息队列,实现了逻辑上的解耦;消息队列本身具有可靠性,通过手动提交等手段,可以至少一次消费到redis。
不足:依旧解决不了时序性问题,如果多台业务服务器分别处理针对同一行数据的两条请求,举个栗子,a = 1;a = 5; 如果mysql中是第一条先执行,而进入kafka的顺序是第二条先执行,那么数据就会产生不一致。
引入了消息队列,同时要增加服务消费消息,成本较高,还有重复消费的风险。
方案四
通过订阅binlog来更新redis,把我们搭建的消费服务,作为mysql的一个slave,订阅binlog,解析出更新内容,再更新到redis。
优点:在mysql压力不大情况下,延迟较低;和业务完全解耦;解决了时序性问题。
缺点:要单独搭建一个同步服务,并且引入binlog同步机制,成本较大。
redis持久化有几种方式?(rscjh)
Redis 提供两种持久化机制 RDB 和 AOF 机制:
-
1、RDB(Redis DataBase)持久化方式:
是指用数据集快照的方式半持久化模式) 记录 redis 数据库的所有键值对,在某个时间点将数据写入一个临时文件,持久化结束后,用这个临时文件替换上次持久化的文件,达到数据恢复。
优点:
1、只有一个文件 dump.rdb,方便持久化。
2、容灾性好,一个文件可以保存到安全的磁盘。
3、性能最大化,fork 子进程来完成写操作,让主进程继续处理命令,所以是 IO 最大化。使用单独子进程来进行持久化,主进程不会进行任何 IO 操作,保证了 redis 的高性能)
4.相对于数据集大时,比 AOF的启动效率更高。
缺点: 1、数据安全性低。RDB 是间隔一段时间进行持久化,如果持久化之间 redis 发生故障,会发生数据丢失。所以这种方式更适合数据要求不严谨的时候)
手动触发分别对应save和bgsave命令:
- save命令:阻塞当前Redis服务器,直到RDB过程完成为止,对于内存比较大的实例会造成长时间阻塞,线上环境不建议使用。
- bgsave命令:Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。
以下场景会自动触发RDB持久化: - 使用save相关配置,如“save m n”。表示m秒内数据集存在n次修改时,自动触发bgsave。
- 如果从节点执行全量复制操作,主节点自动执行bgsave生成RDB文件并发送给从节点
- 执行debug reload命令重新加载Redis时,也会自动触发save操作
- 默认情况下执行shutdown命令时,如果没有开启AOF持久化功能则自动执行bgsave。
-
2、AOF(append only file)
持久化,采用日志的形式来记录每个写操作,追加到文件中,重启时再重新执行AOF文件中的命令来恢复数据。它主要解决数据持久化的实时性问题。默认是不开启的。
AOF的优点:数据的一致性和完整性更高
AOF的缺点:AOF记录的内容越多,文件越大,数据恢复变慢。
AOF的工作流程操作:命令写入 (append)、文件同步(sync)、文件重写(rewrite)、重启加载 (load)(aofgzlc)
流程如下:
1)所有的写入命令会追加到aof_buf(缓冲区)中。
2)AOF缓冲区根据对应的策略向硬盘做同步操作。
3)随着AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩 的目的。
4)当Redis服务器重启时,可以加载AOF文件进行数据恢复。
Redis 如何实现分布式锁? ☆☆☆☆ (rsfbss)
先拿 setnx 来争抢锁,抢到之后,再用 expire 给锁加一个过期时间防止锁忘记了释放。利用 Redis 提供的 SET key value NX PX milliseconds 指令,这个指令是设置一个key-value,如果 key 已经存在,则返回 0,否则返回 1,我们基于这个返回值来判断锁的占用情况从而实现分布式锁。
如果在 setnx 之后执行 expire 之前进程意外 crash 或者要重启维护了,那会怎么样?
set 指令有非常复杂的参数,这个应该是可以同时把 setnx 和 expire 合成一条指令来用的!
使用setnx、getset、expire、del这4个redis命令实现
setnx 是『SET if Not eXists』(如果不存在,则 SET)的简写。 命令格式:SETNX key value;使用:只在键 key 不存在的情况下,将键 key 的值设置为 value 。若键 key 已经存在, 则 SETNX 命令不做任何动作。返回值:命令在设置成功时返回 1 ,设置失败时返回 0 。
getset 命令格式:GETSET key value,将键 key 的值设为 value ,并返回键 key 在被设置之前的旧的value。返回值:如果键 key 没有旧值, 也即是说, 键 key 在被设置之前并不存在, 那么命令返回 nil 。当键 key 存在但不是字符串类型时,命令返回一个错误。
expire 命令格式:EXPIRE key seconds,使用:为给定 key 设置生存时间,当 key 过期时(生存时间为 0 ),它会被自动删除。返回值:设置成功返回 1 。 当 key 不存在或者不能为 key 设置生存时间时(比如在低于 2.1.3 版本的 Redis 中你尝试更新 key 的生存时间),返回 0 。
del 命令格式:DEL key [key …],使用:删除给定的一个或多个 key ,不存在的 key 会被忽略。返回值:被删除 key 的数量
过程分析:
A尝试去获取锁lockkey,通过setnx(lockkey,currenttime+timeout)命令,对lockkey进行setnx,将value值设置为当前时间+锁超时时间;
如果返回值为1,说明redis服务器中还没有lockkey,也就是没有其他用户拥有这个锁,A就能获取锁成功;
在进行相关业务执行之前,先执行expire(lockkey),对lockkey设置有效期,防止死锁。因为如果不设置有效期的话,lockkey将一直存在于redis中,其他用户尝试获取锁时,执行到setnx(lockkey,currenttime+timeout)时,将不能成功获取到该锁;
执行相关业务;
释放锁,A完成相关业务之后,要释放拥有的锁,也就是删除redis中该锁的内容,del(lockkey),接下来的用户才能进行重新设置锁新值。
redis 分布式锁有什么缺陷?(rsfbssqx)
1.它获取锁的方式简单粗暴,如果获取不到锁,会不断尝试获取锁,比较消耗性能。
2. Redis 是 AP 模型,在集群模式中由于数据的一致性会导致锁出现问题,即便使用 Redlock 算法来实现,在某些复杂场景下,也无法保证其实现 100%的可靠性。
3.不过在实际开发中使用 Redis 实现分布式锁还是比较常见,而且大部分场情况下不会遇到”极端复杂的场景“,更重要的是 Redis 性能很高,在高并发场景中比较合适。
redis 如何做内存优化?(rsncyh)
尽可能使用散列表(hashes),散列表(是说散列表里面存储的数少)使用的内存非常小,所以你应该尽可能的将你的数据模型抽象到一个散列表里面。
比如你的web系统中有一个用户对象,不要为这个用户的名称,姓氏,邮箱,密码设置单独的key,而是应该把这个用户的所有信息存储到一张散列表里面。
Redis报内存不足怎么处理?
- 修改配置文件 redis.conf 的 maxmemory 参数,增加 Redis 可用内存
- 也可以通过命令set maxmemory动态设置内存上限
- 修改内存淘汰策略,及时释放内存空间
- 使用 Redis 集群模式,进行横向扩容。
redis 常见的性能问题有哪些?该如何解决?(rswt)
主服务器写内存快照,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性暂停服务,所以主服务器最好不要写内存快照。 Redis
主从复制的性能问题,为了主从复制的速度和连接的稳定性,主从库最好在同一个局域网内。
redis集群
Redis本身就支持集群操作redis_cluster,集群至少需要3主3从,且每个实例使用不同的配置文件,主从不用配置,集群会自己选举主数据库和从数据库,为了保证选举过程最后能选出leader,就一定不能出现两台机器得票相同的僵局,所以一般的,要求集群的server数量一定要是奇数,也就是2n+1台,并且,如果集群出现问题,其中存活的机器必须大于n+1台,否则leader无法获得多数server的支持,系统就自动挂掉。所以一般是3个或者3个以上的奇数节点。
Redis2.8中提供了哨兵工具来实现自动化的系统监控和故障恢复功能。哨兵的作用就是监控redis主、从数据库是否正常运行,主数据库出现故障自动将从数据库转换为主数据库。我们公司搭建的redis集群是用的ruby脚本配合搭建的,我们一共搭建了6台服务器,3主3备,他们之间通信的原理是有一个乒乓协议进行通信的,我再给你说下一他们往里存储数据的机制吧,其实这个redis搭建好集群以后每个节点都存放着一个hash槽,每次往里存储数据的时候,redis都会根据存储进来的key值算出一个hash值,通过这个hash值可以判断到底应该存储到哪一个哈希槽中,取的时候也是这么取的,这就是我了解的redis集群
Redis 做异步队列(延时队列)(rsybdl)
一般使用 list 结构作为队列,rpush 生产消息,lpop 消费消息。当 lpop 没有 消息的时候,要适当 sleep 一会再重试。list 还有个指令叫 blpop,在没有消息的时候,它会阻塞住直到消息到来。如果对 方追问能不能生产一次消费多次呢?使用pub/sub 主题订阅者模式,可以实现 1:N 的消息队列。使用 sortedset,拿时间戳作为 score,消息内容作为 key 调用zadd 来生产消息,消费者用 zrangebyscore 指令 获取 N 秒之前的数据轮询进行处理。
Redis 做延时队列(rsysdl)
使用zset,利用排序实现
可以使用 zset这个结构,用设置好的时间戳作为score进行排序,使用 zadd score1 value1 …命令就可以一直往内存中生产消息。再利用 zrangebysocre 查询符合条件的所有待处理的任务,通过循环执行队列任务即可。
Redis 回收进程如何工作(rshsjc)
一个客户端运行了新的命令,添加了新的数据。Redis 检查内存使用情况,如果大于 maxmemory 的限制,
则根据设定好的策略进行回收。一个新的命令被执 行,等等。所以我们不断地穿越内存限制的边界,通过不断达到边界然后不断地回收回到边界以下。如果一个命令的结果导致大量内存被使用(例如很大的集合 的交集保存到一个新的键),不用多久内存限制就会被这个内存使用量超越。
Redis和Lua脚本的使用了解吗?(rsluadc)
Redis的事务功能比较简单,平时的开发中,可以利用Lua脚本来增强Redis的命令。
Lua脚本能给开发人员带来这些好处:
Lua脚本在Redis中是原子执行的,执行过程中间不会插入其他命令。
Lua脚本可以帮助开发和运维人员创造出自己定制的命令,并可以将这 些命令常驻在Redis内存中,实现复用的效果。
Lua脚本可以将多条命令一次性打包,有效地减少网络开销。
Redis 如何做内存优化(rsncyh)
尽可能使用散列表(hashes),散列表(是说散列表里面存储的数少)使用
的内存非常小,所以你应该尽可能的将你的数据模型抽象到一个散列表里面。比 如你的 web
系统中有一个用户对象,不要为这个用户的名称,姓氏,邮箱,密码 设置单独的 key,而是应该把这个用户的所有信息存储到一张散列表里面.
Redis 事务(rssw)
Redis提供了简单的事务,但它对事务ACID的支持并不完备。
multi命令代表事务开始,exec命令代表事务结束,它们之间的命令是原子顺序执行的:
Redis事务的原理,是所有的指令在 exec 之前不执行,而是缓存在 服务器的一个事务队列中,服务器一旦收到 exec 指令,才开执行整个事务队列,执行完毕后一次性返回所有指令的运行结果。
需要注意的点有:
Redis 事务是不支持回滚的,不像 MySQL 的事务一样,要么都执行要么都不执行;
Redis 服务端在执行事务的过程中,不会被其他客户端发送来的命令请求打断。直到事务命令全部执行完毕才会执行其他客户端的命令。
Redis 事务为什么不支持回滚?
Redis 的事务不支持回滚。
如果执行的命令有语法错误,Redis 会执行失败,这些问题可以从程序层面捕获并解决。但是如果出现其他问题,则依然会继续执行余下的命令。
这样做的原因是因为回滚需要增加很多工作,而不支持回滚则可以保持简单、快速的特性。
Redis的管道了解吗?(rsgd)
- Redis 提供三种将客户端多条命令打包发送给服务端执行的方式:
Pipelining(管道) 、 Transactions(事务) 和 Lua Scripts(Lua 脚本) 。 - Pipelining(管道) Redis 管道使用 pipeline(管道)的好处在于可以将多次 I/O
往返的时间缩短为一次,但是要求管道中执行的指令间没有因果关系。 用 pipeline
的原因在于可以实现请求/响应服务器的功能,当客户端尚未读取旧响应时,它也可以
处理新的请求。如果客户端存在多个命令发送到服务器时,那么客户端无需等待服务端的每次响应
才能执行下个命令,只需最后一步从服务端读取回复即可。 - Redis服务端接收到管道发送过来的多条命令后,会一直执命令,并将命令的执行结果进行缓存,直到最后一条命令执行完成,再所有命令的执行结果一次性返回给客户端
在性能方面, Pipeline 有下面两个优势:(gdyd peyd) - 节省了RTT:将多条命令打包一次性发送给服务端,减少了客户端与服务端之间的网络调用次数
- 减少了上下文切换:当客户端/服务端需要从网络中读写数据时,都会产生一次系统调用,系统调用是非常耗时的操作,其中设计到程序由用户态切换到内核态,再从内核态切换回用户态的过程。当我们执行10 条 redis 命令的时候,就会发生 10 次用户态到内核态的上下文切换,但如果我们使用 Pipeining将多条命令打包成一条一次性发送给服务端,就只会产生一次上下文切换。
Redis集群的主从复制模型是怎样的(rszcfz)
通过持久化功能,Redis保证了即使在服务器重启的情况下也不会损失(或少量损失)数据,因为持久化会把内存中数据保存到硬盘上,重启会从硬盘上加载数据。但是由于数据是存储在一台服务器上的,如果这台服务器出现硬盘故障等问题,也会导致数据丢失。为了避免单点故障,通常的做法是将数据库复制多个副本以部署在不同的服务器上,这样即使有一台服务器出现故障,其他服务器依然可以继续提供服务。为此,Redis 提供了复制功能,可以实现当一台数据库中的数据更新后,自动将更新的数据同步到其他数据库上。 Redis的主从结构可以采用一主多从或者级联结构,Redis主从复制可以根据是否是全量分为全量同步和增量同步,配置非常简单,只需要在从节点配置slave of主节点的ip即可,如果有密码,还需要配置上密码,从节点只能读数据,不能写数据.
Redis 集群最大节点个数是多少? 答:16384 个。
redis主从复制过程如果出现数据不一致怎么办(rssjbyz)
由于网络因素,多个从节点的数据会不一致。这个因素是没有办法避免的。
关于这个问题给出俩个解决方案:
第一个数据需要高度一致配置一台redis服务器,读写都用一台服务器,这种方式仅限于少量数据,并且数据需高度一致。
第二个监控主从节点的偏移量,如果从节点的延迟过大,暂时屏蔽客户端对该从节点的访问。设置参数为slave-serve-stale-data yes|no。这个参数一但设置就只能响应info slaveof等少数命令。
Redis哈希槽(rshxc)
Redis 集群没有使用一致性 hash,而是引入了哈希槽的概念,Redis 集群有 16384 个哈希槽,每个 key 通过 CRC16校验后对 16384 取模来决定放置哪个槽, 集群的每个节点负责一部分 hash 槽。
Redis集群的原理是什么(rsjqyl)
1)、Redis Sentinal 着眼于高可用,在 master 宕机时会自动将 slave 提升为 master,继续提供服务。
2)、Redis Cluster 着眼于扩展性,在单个 redis 内存不足时,使用 Cluster 进行 分片存储。
Redis的主从数据同步机制(rszctb)
Redis在2.8及以上版本使用psync命令完成主从数据同步,同步过程分为:全量复制和部分复制。
全量复制
全量复制一般用于初次复制场景,Redis早期支持的复制功能只有全量复制,它会把主节点全部数据一次性发送给从节点,当数据量较大时,会对主从节点和网络造成很大的开销。
部分复制
部分复制主要是Redis针对全量复制的过高开销做出的一种优化措施, 使用psync{runId}{offset}命令实现。当从节点(slave)正在复制主节点 (master)时,如果出现网络闪断或者命令丢失等异常情况时,从节点会向 主节点要求补发丢失的命令数据,如果主节点的复制积压缓冲区内存在这部分数据则直接发送给从节点,这样就可以保持主从节点复制的一致性。
这个 Redis 有自带的集群同步机制,即复制功能. Redis 可以使用主从同步,从从同步。第一次同步时,主节点做一次 bgsave, 并同时将后续修改操作记录到内存 buffer,待完成后将rdb 文件全量同步到复制节点,复制节点接受完成后将 rdb镜像加载到内存。加载完成后,再通知主节点将期间修改的操作记录同步到复制节点进行重放就完成了同步过程。
redis 过期键的删除策略?(rssccl)
1、定时删除:在设置键的过期时间的同时,创建一个定时器 timer). 让定时器在键的过期时间来临时,立即执行对键的删除操作。
2、惰性删除:放任键过期不管,但是每次从键空间中获取键时,都检查取得的键是 否过期,如果过期的话,就删除该键;如果没有过期,就返回该键。
3、定期删除:每隔一段时间程序就对数据库进行一次检查,删除里面的过期键。至于要删除多少过期键,以及要检查多少个数据库,则由算法决定。
redis 淘汰策略有哪些?(rsttcl)
volatile-lru:从已设置过期时间的数据集(server. db[i]. expires)中挑选最近最少使用的数据淘汰。
volatile-ttl:从已设置过期时间的数据集(server. db[i]. expires)中挑选将要过期的数据淘汰。
volatile-random:从已设置过期时间的数据集(server. db[i]. expires)中任意选择数据淘汰。
allkeys-lru:从数据集(server. db[i]. dict)中挑选最近最少使用的数据淘汰。
allkeys-random:从数据集(server. db[i]. dict)中任意选择数据淘汰。
no-enviction(驱逐):禁止驱逐数据。
Redis4.0新增的
(1)已经设置过期时间的数据集中,把 访问次数最少的删掉
(2)普通的数据集中,把访问次数最少的删掉
怎么处理热key?(rsrdk)
所谓的热key,就是访问频率比较的key。假如Redis集群部署,热key可能会造成整体流量的不均衡,个别节点出现OPS过大的情况,极端情况下热点key甚至会超过 Redis本身能够承受的OPS。
怎么处理热key?
对热key的处理,最关键的是对热点key的监控,可以从这些端来监控热点key:
- 客户端
客户端其实是距离key“最近”的地方,因为Redis命令就是从客户端发出的,例如在客户端设置全局字典(key和调用次数),每次调用Redis命令时,使用这个字典进行记录。 - 代理端
像Twemproxy、Codis这些基于代理的Redis分布式架构,所有客户端的请求都是通过代理端完成的,可以在代理端进行收集统计。 - Redis服务端 使用monitor命令统计热点key是很多开发和运维人员首先想到,monitor命令可以监控到Redis执行的所有命令。
只要监控到了热key,对热key的处理就简单了:
- 把热key打散到不同的服务器,降低压⼒
- 加⼊⼆级缓存,提前加载热key数据到内存中,如果redis宕机,⾛内存查询
大key问题了解吗?(rsdk)
Redis使用过程中,有时候会出现大key的情况, 比如:
单个简单的key存储的value很大,size超过10KB
hash, set,zset,list 中存储过多的元素(以万为单位)
大key会造成什么问题呢?
客户端耗时增加,甚至超时
对大key进行IO操作时,会严重占用带宽和CPU
造成Redis集群中数据倾斜
主动删除、被动删等,可能会导致阻塞
如何找到大key?
bigkeys命令:使用bigkeys命令以遍历的方式分析Redis实例中的所有Key,并返回整体统计信息与每个数据类型中Top1的大Key
redis-rdb-tools:redis-rdb-tools是由Python写的用来分析Redis的rdb快照文件用的工具,它可以把rdb快照文件生成json文件或者生成报表用来分析Redis的使用详情。
如何处理大key?
1.删除大key
当Redis版本大于4.0时,可使用UNLINK命令安全地删除大Key,该命令能够以非阻塞的方式,逐步地清理传入的Key。
当Redis版本小于4.0时,避免使用阻塞式命令KEYS,而是建议通过SCAN命令执行增量迭代扫描key,然后判断进行删除。
2.压缩和拆分key
当vaule是string时,比较难拆分,则使用序列化、压缩算法将key的大小控制在合理范围内,但是序列化和反序列化都会带来更多时间上的消耗。
当value是string,压缩之后仍然是大key,则需要进行拆分,一个大key分为不同的部分,记录每个部分的key,使用multiget等操作实现事务读取。
当value是list/set等集合类型时,根据预估的数据规模来进行分片,不同的元素计算后分到不同的片。
无底洞问题吗?如何解决?
Facebook的Memcache节点已经达到了3000个,承载着TB级别的缓存数据。但开发和运维人员发现了一个问题,为了满足业务要求添加了大量新Memcache节点,但是发现性能不但没有好转反而下降了,当时将这 种现象称为缓存的“无底洞”现象。
通常来说添加节点使得Memcache集群 性能应该更强了,但事实并非如此。键值数据库由于通常采用哈希函数将 key映射到各个节点上,造成key的分布与业务无关,但是由于数据量和访问量的持续增长,造成需要添加大量节点做水平扩容,导致键值分布到更多的 节点上,所以无论是Memcache还是Redis的分布式,批量操作通常需要从不同节点上获取,相比于单机批量操作只涉及一次网络操作,分布式批量操作会涉及多次网络时间。
先分析一下无底洞问题:
客户端一次批量操作会涉及多次网络操作,也就意味着批量操作会随着节点的增多,耗时会不断增大。
网络连接数变多,对节点的性能也有一定影响。
常见的优化思路如下:
命令本身的优化,例如优化操作语句等。
减少网络通信次数。
降低接入成本,例如客户端使用长连/连接池、NIO等。
如果让你设计一个KV数据库,该如何设计(sjksj)
假设现在我们已经设计好了一个KV数据库,首先如果我们要使用,是不是得有入口,我们是通过动态链接库还是通过网络socket对外提供访问入口,这就涉及到了访问模块。Redis就是通过
通过访问模块访问KV数据库之后,我们的数据存储在哪里?为了保证访问的高性能,我们选择存储在内存中,这又需要有存储模块。存在内存中的数据,虽然访问速度快,但存在的的问题就是断电后,无法恢复数据,所以我们还需要支持持久化操作。
有了存储模块,我们还需要考虑,数据是以什么样的形式存储?怎样设计才能让数据操作更优,这就设计到了,数据类型的支持,索引模块。 索引的作用是让键值数据库根据 key 找到相应 value 的存储位置,进而执行操作。
有了以上模块的只是,我们是不是要对数据进行操作了?比如往KV数据库中插入或更新一条数据,删除和查询,这就是需要有操作模块了。
至此我们已经构造出了一个KV数据库的基本框架了,带着这些架构,我们再深入到每个点中去探究,这样就会轻松很多,不会迷失在末枝细节中了。
JVM(118)
说一下 jvm 的主要组成部分? JVM 结构原理、GC 工作机制详解(jvmdc)
1.类加载器(ClassLoader):在JVM启动时或者在类运行时将需要的class加载到JVM中
2.执行引擎:负责执行class文件中包含的字节码指令
3.内存区(也叫运行时数据区):是在JVM运行的时候操作所分配的内存区。运行时内存区主要可以划分为5个区域:
- 方法区(MethodArea):用于存储类结构信息的地方,包括常量池、静态变量、构造函数等。虽然JVM规范把方法区描述为堆的一个逻辑部分,
但它却有个别名non-heap(非堆),所以大家不要搞混淆了。方法区还包含一个运行时常量池。 - java堆(Heap):存储java实例或者对象的地方。这块是GC的主要区域(后面解释)。从存储的内容我们可以很容易知道,方法区和堆是被所有java线程共享的。
- java栈(Stack):java栈总是和线程关联在一起,每当创建一个线程时,JVM就会为这个线程创建一个对应的java栈。在这个java栈中又会包含多个栈帧,每运行一个方法就创建一个栈帧,用于存储局部变量表、操作栈、方法返回值等。每一个方法从调用直至执行完成的过程,就对应一个栈帧在java栈中入栈到出栈的过程。所以java栈是现成私有的。
- 程序计数器(PC Register):用于保存当前线程执行的内存地址。由于JVM程序是多线程执行的(线程轮流切换),所以为了保证线程切换回来后,还能恢复到原先状态,就需要一个独立的计数器,记录之前中断的地方,可见程序计数器也是线程私有的。
- 本地方法栈(Native Method Stack):和java栈的作用差不多,只不过是为JVM使用到的native方法服务的。
4.本地方法接口:主要是调用C或C++实现的本地方法及返回结果。
Java虚拟机是先一次性分配一块较大的空间,然后每次new时都在该空间上进行分配和释放,减少了系统调用的次数,节省了一定的开销,这有点类似于内存池的概念;二是有了这块空间过后,如何进行分配和回收就跟GC机制有关了。
java一般内存申请有两种:静态内存和动态内存。很容易理解,编译时就能够确定的内存就是静态内存,即内存是固定的,系统一次性分配,比如int类型变量;动态内存分配就是在程序执行时才知道要分配的存储空间大小,比如java对象的内存空间。
java栈、程序计数器、本地方法栈都是线程私有的,线程生就生,线程灭就灭,栈中的栈帧随着方法的结束也会撤销,内存自然就跟着回收了。所以这几个区域的内存分配与回收是确定的,我们不需要管的。但是java堆和方法区则不一样,我们只有在程序运行期间才知道会创建哪些对象,所以这部分内存的分配和回收都是动态的。一般我们所说的垃圾回收也是针对的这一部分。
垃圾检测
- 引用计数法:给一个对象添加引用计数器,每当有个地方引用它,计数器就加1;引用失效就减1。
- 可达性分析算法:以根集对象为起始点进行搜索,如果有对象不可达的话,即是垃圾对象。这里的根集一般包括java栈中引用的对象、方法区常量池中引用的对象
回收算法也有如下几种:(ljhssf)
-
1.标记-清除(Mark-sweep)
算法和名字一样,分为两个阶段:标记和清除。标记所有需要回收的对象,然后统一回收。这是最基础的算法,后续的收集算法都是基于这个算法扩展的。
不足:效率低;标记清除之后会产生大量碎片
-
2.复制(Copying)
此算法把内存空间划为两个相等的区域,每次只使用其中一个区域。垃圾回收时,遍历当前使用区域,把正在使用中的对象复制到另外一个区域中。此算法每次只处理正在使用中的对象,因此复制成本比较小,同时复制过去以后还能进行相应的内存整理,不会出现“碎片”问题。当然,此算法的缺点也是很明显的,就是需要两倍内存空间。
-
3.标记-整理(Mark-Compact)
此算法结合了“标记-清除”和“复制”两个算法的优点。也是分两阶段,第一阶段从根节点开始标记所有被引用对象,第二阶段遍历整个堆,把清除未标记对象并且把存活对象“压缩”到堆的其中一块,按顺序排放。此算法避免了“标记-清除”的碎片问题,同时也避免了“复制”算法的空间问题。
-
4.分代收集算法
为什么要运用分代垃圾回收策略?在java程序运行的过程中,会产生大量的对象,因每个对象所能承担的职责不同所具有的功能不同所以也有着不一样的生命周期,有的对象生命周期较长,比如Http请求中的Session对象,线程,Socket连接等;有的对象生命周期较短,比如String对象,由于其不变类的特性,有的在使用一次后即可回收。试想,在不进行对象存活时间区分的情况下,每次垃圾回收都是对整个堆空间进行回收,那么消耗的时间相对会很长,而且对于存活时间较长的对象进行的扫描工作等都是徒劳。因此就需要引入分治的思想,所谓分治的思想就是因地制宜,将对象进行代的划分,把不同生命周期的对象放在不同的代上使用不同的垃圾回收方式。
如何划分:垃圾回收算法主要采用的是 分代收集算法【GC】。GC是根据对象的存活周期的不同将内存划分为几块。一般是把java堆分成新生代和老年代。新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要复制少量存活对象即可完成收集。而老年代中因为对象存活率高、没有额外的空间对它进行分配担保,就必须使用“标记-清理”或者“标记-整理”算法来回收。
将对象按其生命周期的不同划分成:
- 年轻代(Young Generation)、年老代(Old Generation)、持久代(Permanent
Generation)。其中持久代主要存放的是类信息,所以与java对象的回收关系不大,与回收息息相关的是年轻代和年老代。 - 年轻代(Minor GC):是所有新对象产生的地方。年轻代被分为3个部分——Enden区和两个Survivor区(From和to)当Eden区被对象填满时,就会执行Minor
GC。并把所有存活下来的对象转移到其中一个survivor区(假设为from区)。Minor
GC同样会检查存活下来的对象,并把它们转移到另一个survivor区(假设为to区)。这样在一段时间内,总会有一个空的survivor区。经过多次GC周期后,仍然存活下来的对象会被转移到年老代内存空间。通常这是在年轻代有资格提升到年老代前通过设定年龄阈值来完成的。需要注意,Survivor的两个区是对称的,没先后关系,from和to是相对的。 - 年老代:在年轻代中经历了N次回收后仍然没有被清除的对象,就会被放到年老代中,可以说他们都是久经沙场而不亡的一代,都是生命周期较长的对象。对于年老代和永久代,就不能再采用像年轻代中那样搬移腾挪的回收算法,因为那些对于这些回收战场上的老兵来说是小儿科。通常会在老年代内存被占满时将会触发Full
GC,回收整个堆内存。 - 持久代:用于存放静态文件,比如java类、方法等。持久代对垃圾回收没有显著的影响。
类加载机制:
组件的作用: 首先通过类加载器(ClassLoader)会把 Java 代码转换成字节码,运行时数据区(Runtime Data Area)再把字节码加载到内存中,而字节码文件只是 JVM 的一套指令集规范,并不能直接交个底层操作系统去执行,因此需要特定的命令解析器执行引擎(Execution Engine),将字节码翻译成底层系统指令,再交由 CPU 去执行,而这个过程中需要调用其他语言的本地库接口(Native Interface)来实现整个程序的功能。
详细说一下G1的回收过程?(ljhsgc)
- 初始标记(会STW):仅仅只是标记一下 GC Roots能直接关联到的对象,并且修改TAMS指针的值,让下一阶段用户线程并发运行时,能正确地在可用的Region中分配新对象。这个阶段需要停顿线程,但耗时很短,而且是借用进行Minor GC的时候同步完成的,所以G1收集器在这个阶段实际并没有额外的停顿。
- 并发标记:从 GC Roots开始对堆中对象进行可达性分析,递归扫描整个堆里的对象图,找出要回收的对象,这阶段耗时较长,但可与用户程序并发执行。当对象图扫描完成以后,还要重新处理在并发时有引用变动的对象。
- 最终标记(会STW):对用户线程做短暂的暂停,处理并发阶段结束后仍有引用变动的对象。
- 清理阶段(会STW):更新Region的统计数据,对各个Region的回收价值和成本进行排序,根据用户所期望的停顿时间来制定回收计划,可以自由选择任意多个Region构成回收集,然后把决定回收的那一部分Region的存活对象复制到空的Region中,再清理掉整个旧Region的全部空间。这里的操作涉及存活对象的移动,必须暂停用户线程,由多条回收器线程并行完成的。
说一下类加载的执行过程?(ljz)
类加载分为以下 5 个步骤:
加载:根据查找路径找到相应的 class 文件然后导入;
检查:检查加载的 class 文件的正确性;
准备:给类中的静态变量分配内存空间;
解析:虚拟机将常量池中的符号引用替换成直接引用的过程。符号引用就理解为一个标示,而在直接引用直接指向内存中的地址;
初始化:对静态变量和静态代码块执行初始化工作。它们的初始化顺序依次是(静态变量、静态初始化块)>(变量、初始化块)>构造器。如果有父类,则顺序是:父类static方法 –> 子类static方法 –> 父类构造方法- -> 子类构造方法
常见内存泄露的几种场景(oomdc)
内存泄露:
指程序中动态分配内存给一些临时对象,但是对象不会被GC所回收,它始终占用内存。即被分配的对象可达但已无用。
内存溢出:
指程序运行过程中无法申请到足够的内存而导致的一种错误。内存溢出通常发生于OLD段或Perm段垃圾回收后,仍然无内存空间容纳新的Java对象的情况。
常见内存泄露的几种场景
1、长生命周期的对象持有短生命周期对象的引用
这是内存泄露最常见的场景,也是代码设计中经常出现的问题。例如:在全局静态map中缓存局部变量,且没有清空操作,随着时间的推移,这个map会越来越大,造成内存泄露。
2、修改hashset中对象的参数值,且参数是计算哈希值的字段
当一个对象被存储进HashSet集合中以后,就不能修改这个对象中的那些参与计算哈希值的字段,否则对象修改后的哈希值与最初存储进HashSet集合中时的哈希值就不同了,在这种情况下,即使在contains方法使用该对象的当前引用作为参数去HashSet集合中检索对象,也将返回找不到对象的结果,这也会导致无法从HashSet集合中删除当前对象,造成内存泄露。
3、机器的连接数和关闭时间设置
长时间开启非常耗费资源的连接,也会造成内存泄露。
内存溢出的几种情况:
1、堆内存溢出(outOfMemoryError:Java heap space)
在jvm规范中,堆中的内存是用来生成对象实例和数组的。
如果细分,堆内存还可以分为年轻代和年老代,年轻代包括一个eden区和两个survivor区
2、方法区内存溢出(outOfMemoryError:permgem space)
在jvm规范中,方法区主要存放的是类信息、常量、静态变量等。
所以如果程序加载的类过多,或者使用反射、gclib等这种动态代理生成类的技术,就可能导致该区发生内存溢出,
一般该区发生内存溢出时的错误信息为: outOfMemoryError:permgem space
3、线程栈溢出(java.lang.StackOverflowError)
线程栈时线程独有的一块内存结构,所以线程栈发生问题必定是某个线程运行时产生的错误。一般线程栈溢出是由于递归太深或方法调用层级过多导致的。
发生了内存泄露或溢出怎么办?
要解决这个区域的异常,一般的手段是首先通过内存映像分析工具(如Eclipse Memory Analyzer)对dump 出来的堆转储快照进行分析,重点是确认内存中的对象是否是必要的,也就是要先分清楚到底是出现了内存泄漏(Memory Leak)还是内存溢出(Memory Overflow)。
如果是内存泄漏,可进一步通过工具查看泄漏对象到GC Roots 的引用链。于是就能找到泄漏对象是通过怎样的路径与GC Roots 相关联并导致垃圾收集器无法自动回收它们的。掌握了泄漏对象的类型信息,以及GC Roots 引用链的信息,就可以比较准确地定位出泄漏代码的位置。
如果不存在泄漏,换句话说就是内存中的对象确实都还必须存活着,那就应当检查虚拟机的堆参数(-Xmx 与-Xms),与机器物理内存对比看是否还可以调大,从代码上检查是否存在某些对象生命周期过长、持有状态时间过长的情况,尝试减少程序运行期的内存消耗。
怎么样避免发生内存泄露和溢出
1、尽早释放无用对象的引用
2、使用字符串处理,避免使用String,应大量使用StringBuffer,每一个String对象都得独立占用内存一块区域
3、尽量少用静态变量,因为静态变量存放在永久代(方法区),永久代基本不参与垃圾回收
4、避免在循环中创建对象
5、开启大型文件或从数据库一次拿了太多的数据很容易造成内存溢出,所以在这些地方要大概计算一下数据量的最大值是多少,并且设定所需最小及最大的内存空间值。
说一下堆栈的区别?(dzqb)
java的内存分为两类,一类是栈内存,一类是堆内存。栈内存是指程序进入一个方法时,会为这个方法单独分配一块私属存储空间,用于存储这个方法内部的局部变量,当这个方法结束时,分配给这个方法的栈会释放,这个栈中的变量也将随之释放。堆是与栈作用不同的内存,一般用于存放不放在当前方法栈中的那些数据,例如,使用new创建的对象都放在堆里,所以,它不会随方法的结束而消失。方法中的局部变量使用final
修饰后,放在堆中,而不是栈中。
什么是双亲委派模型?(sqwp)
双亲委派机制的意思是除了顶层的启动类加载器以外,其余的类加载器,在加载之前,都会委
派给它的父加载器进行加载。这样一层层向上传递,直到祖先们都无法胜任,它才会真正的加
载。
在介绍双亲委派模型之前先说下类加载器。对于任意一个类,都需要由加载它的类加载器和这个类本身一同确立在 JVM中的唯一性,每一个类加载器,都有一个独立的类名称空间。类加载器就是根据指定全限定名称将 class 文件加载到 JVM 内存,然后再转化为 class 对象。当某个类加载器需要加载某个.class文件时,它首先把这个任务委托给他的上级类加载器,递归这个操作,如果上级的类加载器没有加载,自己才会去加载这个类。
双亲委派机制的作用
1、防止重复加载同一个.class。通过委托去向上面问一问,加载过了,就不用再加载一遍。保证数据安全。
2、保证核心.class不能被篡改。通过委托方式,不会去篡改核心.clas,即使篡改也不会去加载,即使加载也不会是同一个.class对象了。不同的加载器加载同一个.class也不是同一个Class对象。这样保证了Class执行安全。
类加载器分类:
启动类加载器(Bootstrap ClassLoader),是虚拟机自身的一部分,用来加载Java_HOME/lib/目录中的,或者被
-Xbootclasspath 参数所指定的路径中并且被虚拟机识别的类库; 其他类加载器: 扩展类加载器(Extension ClassLoader):负责加载<java_home style=“box-sizing: border-box;
-webkit-tap-highlight-color: transparent; text-size-adjust: none; -webkit-font-smoothing: antialiased; outline: 0px !important;”>\lib\ext目录或Java. ext. dirs系统变量指定的路径中的所有类库;</java_home>
应用程序类加载器(Application
ClassLoader)。负责加载用户类路径(classpath)上的指定类库,我们可以直接使用这个类加载器。一般情况,如果我们没有自定义类加载器默认就是用这个加载器。双亲委派模型:如果一个类加载器收到了类加载的请求,它首先不会自己去加载这个类,而是把这个请求委派给父类加载器去完成,每一层的类加载器都是如此,这样所有的加载请求都会被传送到顶层的启动类加载器中,只有当父加载无法完成加载请求(它的搜索范围中没找到所需的类)时,子加载器才会尝试去加载类。
怎么判断对象是否可以被回收?(dxhs)
一般有两种方法来判断:
引用计数器:为每个对象创建一个引用计数,有对象引用时计数器 +1,引用被释放时计数 -1,当计数器为 0
时就可以被回收。它有一个缺点不能解决循环引用的问题;
可达性分析:从 GC Roots开始向下搜索,搜索所走过的路径称为引用链。当一个对象到 GC Roots 没有任何引用链相连时,则证明此对象是可以被回收的。
说一说Java的四种引用方式(引用类型)?(yylx )
Java对象的四种引用方式分别是强引用、软引用、弱引用、虚引用,具体含义如下:
- 强引用指的就是代码中普遍存在的赋值方式,比如A a = new A()这种。强引用关联的对象,永
远不会被GC回收。 - 软引用可以用SoftReference来描述,指的是那些有用但是不是必须要的对象。系统在发生内存
溢出前会对这类引用的对象进行回收。 - 弱引用可以用WeakReference来描述,他的强度比软引用更低一点,弱引用的对象下一次GC
的时候一定会被回收,而不管内存是否足够。 - 虚引用也被称作幻影引用,是最弱的引用关系,可以用PhantomReference来描述,他必须和
ReferenceQueue一起使用,同样的当发生GC的时候,虚引用也会被回收。可以用虚引用来管
理堆外内存。
说一下 jvm 有哪些垃圾回收算法?(ljhssf)
GC最基础的算法有三种: 标记 -清除算法、复制算法、标记-压缩算法,我们常用的垃圾回收器一般都采用分代收集算法。
标记 -清除算法,“标记-清除”(Mark-Sweep)算法,如它的名字一样,算法分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收掉所有被标记的对象。
复制算法,“复制”(Copying)的收集算法,它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。
标记-压缩算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存
分代收集算法,“分代收集”(Generational Collection)算法,把Java堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。
说一下 jvm 有哪些垃圾回收器?(ljhsq)
Serial:最早的单线程串行垃圾回收器。
Serial Old:Serial 垃圾回收器的老年版本,同样也是单线程的,可以作为 CMS 垃圾回收器的备选预案。
ParNew:是 Serial 的多线程版本。
Parallel 和 ParNew 收集器类似是多线程的,但 Parallel 是吞吐量优先的收集器,可以牺牲等待时间换取系统的吞吐量。
Parallel Old 是 Parallel 老生代版本,Parallel 使用的是复制的内存回收算法,Parallel Old 使用的是标记-整理的内存回收算法。
CMS:一种以获得最短停顿时间为目标的收集器,非常适用 B/S 系统。
G1:一种兼顾吞吐量和停顿时间的 GC 实现,是 JDK 9 以后的默认 GC 选项。
详细介绍一下CMS垃圾回收器?
CMS 是英文 Concurrent Mark-Sweep
的简称,是以牺牲吞吐量为代价来获得最短回收停顿时间的垃圾回收器。对于要求服务器响应速度的应用上,这种垃圾回收器非常适合。在启动 JVM
的参数加上“-XX:+UseConcMarkSweepGC”来指定使用 CMS 垃圾回收器。CMS 使用的是标记-清除的算法实现的,所以在 gc 的时候回产生大量的内存碎片,当剩余内存不能满足程序运行要求时,系统将会出现
Concurrent Mode Failure,临时 CMS 会采用 Serial Old 回收器进行垃圾清除,此时的性能将会被降低。
新生代垃圾回收器和老生代垃圾回收器都有哪些?有什么区别?
新生代回收器:Serial、ParNew、Parallel Scavenge
老年代回收器:Serial Old、Parallel Old、CMS 整堆回收器:G1新生代垃圾回收器一般采用的是复制算法,复制算法的优点是效率高,缺点是内存利用率低;老年代回收器一般采用的是标记-整理的算法进行垃圾回收。
简述分代垃圾回收器是怎么工作的?(fdljhsq)(fdcl)
分代的策略
1)年轻代(Young Gen):年轻代主要存放新创建的对象,内存大小相对会比较小,垃圾回收会比较频繁。Young Gen垃圾回收时,采用将存活对象复制到到空的Suvivor Space的方式来确保尽量不存在内存碎片,采用空间换时间的方式来加速内存中不再被持有的对象尽快能够得到回收
2)年老代(Tenured Gen):年老代主要存放JVM认为生命周期比较长的对象(经过几次的Young
Gen的垃圾回收后仍然存在),内存大小相对会比较大,垃圾回收也相对没有那么频繁,年老代主要采用压缩的方式来避免内存碎片
3)持久代(Perm Gen):持久代主要存放类定义、字节码和常量等很少会变更的信息。JVM调优参数 JDK 自带了很多监控工具,都位于 JDK 的 bin目录下,其中最常用的是 jconsole 和 jvisualvm 这两款视图监控工具。 jconsole:用于对 JVM中的内存、线程和类等进行监控; jvisualvm:JDK 自带的全能分析工具,可以分析:内存快照、线程快照、程序死锁、监控内存的变化、gc变化等。
说一下 jvm 调优的工具?
JDK 自带了很多监控工具,都位于 JDK 的 bin 目录下,其中最常用的是 jconsole 和 jvisualvm
这两款视图监控工具。jconsole:用于对 JVM 中的内存、线程和类等进行监控; jvisualvm:JDK
自带的全能分析工具,可以分析:内存快照、线程快照、程序死锁、监控内存的变化、gc 变化等。
常用的 jvm 调优的参数都有哪些?(jvmty)
-Xms2g:初始化推大小为 2g;
-Xmx2g:堆最大内存为 2g;
-XX:NewRatio=4:设置年轻的和老年代的内存比例为 1:4;
-XX:SurvivorRatio=8:设置新生代 Eden 和 Survivor 比例为 8:2;
–XX:+UseParNewGC:指定使用 ParNew + Serial Old 垃圾回收器组合;
-XX:+UseParallelOldGC:指定使用 ParNew + ParNew Old 垃圾回收器组合;
-XX:+UseConcMarkSweepGC:指定使用 CMS + Serial Old 垃圾回收器组合;
-XX:+PrintGC:开启打印 gc 信息;
-XX:+PrintGCDetails:打印 gc 详细信息。
内存分配方式(内存模型)(ncfpff)(ncmx)
堆(heap):用于存放进程运行中被动态分配的内存段,大小不固定。当进程调用malloc或者new等函数时,新分配的内存就被动态添加到堆上(堆被扩张),当使用free或者delete等函数释放内存时,被释放的内存从堆中被删除。
栈(stack):存放程序临时创建的局部变量,不包括static声明的变量,static意味着在数据段中存放。除此之外,当函数被调用时,其参数也会被压到栈中,并在调用结束后,函数的返回值也会被放到栈中。栈由编译器自动释放。其操作方式类似于数据结构中的栈。栈内存分配运算内置于处理器的指令集中,一般使用寄存器来存取,效率很高,但是分配的内存容量有限。
静态存储区:从全局存储区域分配:这时内存在程序编译阶段就已经分配好,该内存在程序运行的整个周期都有效,如:全局变量、static静态变量。
创建对象的过程(cjdx)
(1)类加载检查:虚拟机遇到一条new指令时,首先将去检查这个指令的参数是否能在常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已被加载、解析和初始化过。如果没有,那必须先执行相应的类加载过程
(2)分配内存(指针碰撞和空闲列表的选择):在类加载检查通过后,接下来虚拟机将为新生对象分配内存。对象所需内存的大小在类加载完成后便可完全确定,为对象分配空间的任务等同于把一块确定大小的内存从Java堆中划分出来。指针碰撞:假设Java堆中内存是绝对规整的,所有用过的内存都放在一边,空闲的内存放在另一边,中间放着一个指针作为分界点的指示器,那所分配内存就仅仅是把那个指针向空闲空间那边挪动一段与对象大小相等的距离,这种分配方式称为“指针碰撞”
(3)空闲列表:如果Java堆中的内存并不是规整的,已使用的内存和空闲的内存相互交错,那就没有办法简单地进行指针碰撞了,虚拟机就必须维护一个列表,记
录上哪些内存块是可用的,在分配的时候从列表中找到一块足够大的空间划分给对象实例,
并更新列表上的记录,这种分配方式称为“空闲列表”。选择哪种分配方式由
Java堆是否规整决定,而Java堆是否规整又由所采用的垃圾收集器是否带有压缩整理功能决
定。因此,在使用Serial、ParNew等带Compact过程的收集器时,系统采用的分配算法是指针碰撞,而使用CMS这种基于Mark-Sweep算法的收集器时,通常采用空闲列表。
(4)并发处理:对象创建在虚拟机中是非常频繁的行为,即使是仅仅修改一个指针所指向的位置,在并发情况下也并不是线程安全的,
可能出现正在给对象A分配内存,指针还没来得及修改,对象B又同时使用了原来的指针来
分配内存的情况。解决这个问题有两种方案,一种是对分配内存空间的动作进行同步处理
—实际上虚拟机采用CAS配上失败重试的方式保证更新操作的原子性;另一种是把内存分
配的动作按照线程划分在不同的空间之中进行,即每个线程在Java堆中预先分配一小块内存,称为本地线程分配缓冲。哪个线程要分配内
存,就在哪个线程的TLAB上分配,只有TLAB用完并分配新的TLAB时,才需要同步锁定。
(5)零值初始化:内存分配完成后,虚拟机需要将分配到的内存空间都初始化为零值(不包括对象头),
如果使用TLAB,这一工作过程也可以提前至TLAB分配时进行
(6)由对象头信息设置对象:虚拟机要对对象进行必要的设置,例如这个对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希码、对象的GC分代年龄等信息。这些信息存放在对象的对
象头(Object Header)之中。根据虚拟机当前的运行状态的不同,如是否启用偏向锁等,对象头会有不同的设置方式。
(7)执行初始化和构造器:class是从子类到基类依次查找,有关静态初始化的动作从基类到子类依次执行。在为所创建对象的存储空间清零后,找到继承链中最上层的基类:
然后从基类到子类依次执行以下这两步操作。执行其出现在域定义处的初始化动作,然后再执行其构造器 。
描述一下 JVM 加载 class 文件的原理机制
JVM 中类的装载是由 ClassLoader 和它的子类来实现的,Java ClassLoader 是一个重要的Java 运行时系统组件。它负责在运行时查找和装入类文件的类。由于 Java 的跨平台性,经过编译的 Java 源程序并不是一个可执行程序,而是一个或多个类文件。当 Java 程序需要使用某个类时,JVM 会确保这个类已经被加载、 连接和初始化。类的加载是指把类的.class 文件中的数据读入到内存中,通常是创建一个字节数组读入.class 文件,然后产生与所加载类对应的 Class 对象。加载完成后,Class
对象还不完整,所以此时的类还不可用。当类被加载后就进入连接阶段,这一阶段包括验证、准备(为静态变量分配内存并设 置默认的初始值)和解析(将符号引用替换为直接引用)三个步骤。
最后 JVM 对类进行初始化,包括:1)如果类存在直接的父类并且这个类还没有被初始化,那么
就先初始化父类;2)如果类中存在初始化语句,就依次执行这些初始化语句。
int a=10;int a=-10(1234567在内存如何存储,这个方法叫什么(123nccc))
因为a为正数,所以在存储的时候先将十进制数,转化为二进制数原码,并且因为是正数,所以原、反、补码相同,不用转化。
因为b为负数,在进行十进制转化为二进制原码后,要进行原码和补码之间的转化,转化过程为符号位不变其他位按位取反,再加一。
数据结构与算法(119)
解释一下顺序存储与链式存储
顺序存储结构是用一段连续的存储空间来存储数据元素,可以进行随机访问,访问效率较高。链式存储结构是用任意的存储空间来存储数据元素,不可以进行随机访问,访问效率较低。
头指针和头结点的区别?
头指针:是指向第一个节点存储位置的指针,具有标识作用,头指针是链表的必要元素,无论链表是否为空,头指针都存在。
头结点:是放在第一个元素节点之前,便于在第一个元素节点之前进行插入和删除的操作,头结点不是链表的必须元素,可有可无,头结点的数据域也可以不存储任何信息。
数组和链表的区别?(slqb)
从逻辑结构来看:数组的存储长度是固定的,它不能适应数据动态增减的情况。链表能够动态分配存储空间以适应数据动态增减的情况,并且易于进行插入和删除操作。
从访问方式来看:数组在内存中是一片连续的存储空间,可以通过数组下标对数组进行随机访问,访问效率较高。链表是链式存储结构,存储空间不是必须连续的,可以是任意的,访问必须从前往后依次进行,访问效率较数组来说比较低。
如果从第i个位置插入多个元素,对于数组来说每一次插入都需要往后移动元素,每一次的时间复杂度都是O(n),而单链表来说只需要在第一次寻找i的位置时时间复杂度为O(n),其余的插入和删除操作时间复杂度均为O(1),提高了插入和删除的效率。
单链表结构和顺序存储结构的区别?
当进行插入和删除操作时,顺序存储结构每次都需要移动元素,总的时间复杂度为O(n^2),而链式存储结构确定i位置的指针后,其时间复杂度仅为O(1)。由于顺序存储结构需要进行预分配存储空间,所以容易造成空间浪费或者溢出。链式存储结构不需要预分配存储空间,元素个数不受限制。
栈和队列的区别(dzqb)
队列是允许在一段进行插入另一端进行删除的线性表,对于进入队列的元素按“先进先出”的规则处理,在表头进行删除在表尾进行插入。
栈是只能在表尾进行插入和删除操作的线性表。对于插入到栈的元素按“后进先出”的规则处理,插入和删除操作都在栈顶进行。由于进栈和出栈都是在栈顶进行,所以要有一个size变量来记录当前栈的大小,当进栈时size不能超过数组长度,size+1,出栈时栈不为空,size-1。
KMP算法:快速从主串找到子串
①上下子串前缀匹配
②找到公共前后缀(取最长且小于比较的上下字串长度)
③将下面的p子串前缀移动到后缀位置
介绍一下深度优先搜索和广度优先搜索是如何实现的?(sdyxss)
深度优先搜索:
(1)访问起始点v0
(2)若v0的第一个邻接点没有被访问过,则深度遍历该邻接点;
(3)若v0的第一个邻接点已经被访问,则访问其第二个邻接点,进行深度遍历;重复以上步骤直到所有节点都被访问过为止
广度优先搜索:
(1)访问起始点v0
(2)依次遍历v0的所有未访问过得邻接点
(3)再依次访问下一层中未被访问过得邻接点;重复以上步骤,直到所有的顶点都被访问过为止
介绍一下拓扑排序以及是如何实现的?
拓扑排序的步骤:(1)在有向图中任意选择一个没有前驱的节点输出(2)从图中删去该节点以及与它相连的边(3)重复以上步骤,直到所有的顶点都输出或者当前图中不存在无前驱的顶点为止,后者代表该图是有环图,所以可以通过拓扑排序来判断一个图是否存在环。
各种查找算法(czsf)
(1)顺序查找:把待查关键字key放入哨兵位置(i=0),再从后往前依次把表中元素和key比较,如果返回值为0则查找失败,表中没有这个key值,如果返回值为元素的位置i(i!=0)则查找成功,设置哨兵的位置是为了加快执行速度,时间复杂度为O(n),其特点是:结构简单,对顺序结构和链式式结构都适用,但查找效率太低。
(2)折半查找:要求查找表为顺序存储结构并且有序,若关键字在表中则返回关键字的位置,若关键字不在表中时停止查找的典型标志是:查找范围的上界<=查找范围的下界。
(3)分块查找:先把查找表分为若干子表,要求每个子表的元素都要比后面的子表的元素小,也就是保证块间是有序的(但是子表内不一定有序),把各子表中的最大关键字构成一张索引表,表中还包含各子表的起始地址。特点是:块间有序,块内无序,查找时块间进行索引查找,块内进行顺序查找。
(4)二分查找:二分查找的基本条件是,这个数组必须是有序排列,先将下标索引到数组最中间的值,然后再对中间值两边的数与要查找的数进行比较,再确定要从左右两边的那一边再执行同样的方法查找。
- 首先确定该数组的中间的下标mid = (left + right) / 2
- 然后让需要查找的数 findVal 和 arr[mid] 比较
2.1、findVal > arr[mid] , 说明你要查找的数在mid 的右边, 因此需要递归的向右查找
2.2findVal < arr[mid], 说明你要查找的数在mid 的左边, 因此需要递归的向左查找
2.3 findVal == arr[mid]说明找到,就返回
(5)插值查找法:插值查找法类似于二分查找,与此不同的是:插值查找每次都是从mid处开始查找。 在折半查找中我们求mid索引的公式,low表示左边索引left;high表示右边索引right,这里的可以就是折半查找中的findVal。
树的介绍
(4)二叉排序树:二叉排序树的定义为:一棵空树,或者是一棵具有如下特点的树:如果该树有左子树,则其左子树的所有节点值小于根的值;若该树有右子树,则其右子树的所有节点值均大于根的值;其左右子树也分别为二叉排序树
(5)平衡二叉树:平衡二叉树又称为AVL树,它或者是一棵空树或者具有如下特点:他的左子树和右子树的高度差的绝对值不能大于1,且他的左右子树也都是平衡二叉树。
哈希表的概念、构造方法、冲突的解决办法(hxb)
哈希表又称为散列表,是根据关键字码的值直接进行访问的数据结构,即它通过把关键码的值映射到表中的一个位置以加快查找速度,其中映射函数叫做散列函数,存放记录的数组叫做散列表。
哈希函数的构造方法包括:直接定址法,除留余数法,数字分析法,平方取中法,折叠法,随机数法
(1)直接定址法:取关键字的某个线性函数值作为散列地址,H(key)=akey+b。 (2)除留余数法:取关键字对p取余的值作为散列地址
(3)数字分析法:当关键字的位数大于地址的位数,对关键字的各位分布进行分析,选出分布均匀的任意几位作为散列的地址,适用于所有关键字都已知的情况。
(4)平方取中法:对关键字求平方,再取结果中的中间几位作为散列地址。
(5)折叠法:将关键字分为位数相同的几部分,然后取这几部分的叠加和作为散列地址。适用于关键字位数较多,且关键字中每一位上数字分布大致均匀。
(6)随机数法:选择一个随机函数,把关键字的随机函数值作为散列地址。适合于关键字的长度不相同时。
> 哈希冲突(hxct)的解决方法包括:开放定址法和拉链法,再 hash 法,建立公共溢出区,当冲突发生时,使用某种探测技术形成一个探测序列,然后沿此序列逐个单单元查找,直到找到该关键字或者碰到一个开放的地址为止,探测到开放的地址表明该表中没有此关键字,若要插入,则探测到开放地址时可将新节点插入该地址单元。其中开放定址法包括:线性探查法,二次探查法,双重散列法
(1)线性探查法:基本思想,探查时从地址d开始,首先探查T[d],在探查T[d+1]…直到查到T[m-1],此后循环到T[0],T[1]…直到探测到T[d-1]为止。
(2)二次探查法:基本思想,探查时从地址d开始,首先探查T[d],再探查T[d+12],T[d+22]…等,直到探查到有空余地址或者探查到T[d-1]为止,缺点是无法探查到整个散列空间。
(3)双重散列法:基本思想,使用两个散列函数来确定地址,探查时从地址d开始,首先探查T[d],再探查T[d+h1(d)],T[d+2h1(d)]…
链接法:将所有关键字为同义词的节点链接在同一个单链表中,若选定的散列表长度为m,则可将散列表定义为一个由m个头指针组成的指针数组,凡是散列地址为i的节点均插入到头指针为i的单链表中。
再 hash 法,就是当通过某个 hash 函数计算的 key 存在冲突时,再用另外一个hash 函数对这个 key 做 hash,一直运算直到不再产生冲突。这种方式会增加计算时间,性能影响较大。
建立公共溢出区,就是把 hash 表分为基本表和溢出表两个部分,凡事存在冲突的元素,一律放入到溢出表中。
HashMap 在 JDK1.8 版本中,通过链式寻址法+红黑树的方式来解决 hash 冲突问题,其中红黑树是为了优化 Hash 表链表过长导致时间复杂度增加的问题。当链表长度大于 8 并且 hash 表的容量大于 64 的时候,再向链表中添加元素就会触发转化。
各种排序算法(pxsf)
内部排序包括:插入排序、选择排序、交换排序、归并排序、基数排序。其中插入排序包括:直接插入排序、折半插入排序、希尔排序;选择排序包括:简单选择排序,堆排序;交换排序包括:冒泡排序、快速排序。
(1)直接插入排序(稳定):基本思想为:将序列分为有序部分和无序部分,从无序部分依次选择元素与有序部分比较找到合适的位置,将原来的元素往后移,将元素插入到相应位置上。时间复杂度为:O(n^2),空间复杂度为O(1)
(2)折半插入排序(稳定):基本思想为:设置三个变量low high
mid,令mid=(low+high)/2,若a[mid]>key,则令high=mid-1,否则令low=mid+1,直到low>high时停止循环,对序列中的每个元素做以上处理,找到合适位置将其他元素后移进行插入。比较次数为O(nlog2n),但是因为要后移,因此时间复杂度为O(n^2),空间复杂度为O(1)。
优点是:比较次数大大减少。
(3)希尔排序(不稳定):基本思想为:先将序列分为若干个子序列,对各子序列进行直接插入排序,等到序列基本有序时再对整个序列进行一次直接插入排序。优点是:让关键字值小的元素能够很快移动到前面,且序列基本有序时进行直接插入排序时间效率会提升很多,空间复杂度为O(1)。
(4)简单选择排序(不稳定):基本思想为:将序列分为2部分,每经过一趟就在无序部分找到一个最小值然后与无序部分的第一个元素交换位置。优点是:实现简单,缺点是:每一趟只能确定一个元素的位置,时间效率低。时间复杂度为O(n^2),空间复杂度为O(1)。
(5)堆排序(不稳定):堆排序就是把最大堆堆顶的最大数取出,将剩余的堆继续调整为最大堆,再次将堆顶的最大数取出,这个过程持续到剩余数只有一个时结束。在堆中定义以下几种操作:
(1)最大堆调整(Max-Heapify):将堆的末端子节点作调整,使得子节点永远小于父节点。
(2)创建最大堆(Build-Max-Heap):将堆所有数据重新排序,使其成为最大堆。
(3)堆排序(Heap-Sort):移除位在第一个数据的根节点,并做最大堆调整的递归运算。设有一个任意序列,k1,k2,…,kn,当满足下面特点时称之为堆:让此序列排列成完全二叉树,该树具有以下特点,该树中任意节点均大于或小于其左右孩子,此树的根节点为最大值或者最小值。优点是:对大文件效率明显提高,但对小文件效率不明显。时间复杂度为O(nlog2n),空间复杂度为O(1)。(6)冒泡排序(稳定):基本思路为:每一趟都将元素进行两两比较,并且按照“前小后大”的规则进行交换。优点是:每一趟不仅能找到一个最大的元素放到序列后面,而且还把其他元素理顺,如果下一趟排序没有发生交换则可以提前结束排序。时间复杂度为O(n^2),空间复杂度为O(1)。
(7)快速排序(不稳定):基本思路为:在序列中任意选择一个元素作为中心,比它大的元素一律向后移动,比它小的元素一律向前移动,形成左右两个子序列,再把子序列按上述操作进行调整,直到所有的子序列中都只有一个元素时序列即为有序。优点是:每一趟不仅能确定一个元素,时间效率较高。时间复杂度为O(nlog2n),空间复杂度为O(log2n).
(8)归并排序(稳定):基本思想为:把两个或者两个以上的有序表合并成一个新的有序表。时间复杂度为O(nlogn),空间复杂度和待排序的元素个数相同。(1)归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。
(2)首先考虑下如何将将二个有序数列合并。这个非常简单,只要从比较二个数列的第一个数,谁小就先取谁,取了后就在对应数列中删除这个数。然后再进行比较,如果有数列为空,那直接将另一个数列的数据依次取出即可。
(3)解决了上面的合并有序数列问题,再来看归并排序,其的基本思路就是将数组分成二组A,B,如果这二组组内的数据都是有序的,那么就可以很方便的将这二组数据进行排序。如何让这二组组内数据有序了?
可以将A,B组各自再分成二组。依次类推,当分出来的小组只有一个数据时,可以认为这个小组组内已经达到了有序,然后再合并相邻的二个小组就可以了。这样通过先递归的分解数列,再合并数列就完成了归并排序。
(9)基数排序:时间复杂度为:对于n个记录进行链式基数排序的时间复杂度为O(d(n+rd)),其中每一趟分配的时间复杂度为O(n),回收的时间复杂度为O(rd)。
“前小后大”的规则进行交换。优点是:每一趟不仅能找到一个最大的元素放到序列后面,而且还把其他元素理顺,如果下一趟排序没有发生交换则可以提前结束排序。时间复杂度为O(n^2),空间复杂度为O(1)。
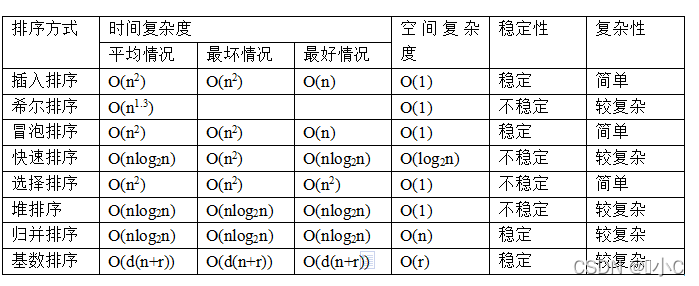
谈一谈,如何得到一个数据流中的中位数?
数据是从一个数据流中读出来的,数据的数目随着时间的变化而增加。如果用一个数据容器来保存从流中读出来的数据,当有新的数据流中读出来时,这些数据就插入到数据容器中。
数组是最简单的容器。如果数组没有排序,可以用 Partition 函数找出数组中的中位数。在没有排序的数组中插入一个数字和找出中位数的时间复杂度是 O(1)和 O(n)。
我们还可以往数组里插入新数据时让数组保持排序,这是由于可能要移动 O(n)个数,因此需要 O(n)时间才能完成插入操作。在已经排好序的数组中找出中位数是一个简单的操作,只需要 O(1)时间即可完成。
排序的链表时另外一个选择。我们需要 O(n)时间才能在链表中找到合适的位置插入新的数据。如果定义两个指针指向链表的中间结点(如果链表的结点数目是奇数,那么这两个指针指向同一个结点),那么可以在 O(1)时间得出中位数。此时时间效率与及基于排序的数组的时间效率一样。
如果能够保证数据容器左边的数据都小于右边的数据,这样即使左、右两边内部的数据没有排序,也可以根据左边最大的数及右边最小的数得到中位数。如何快速从一个容器中找出最大数?用最大堆实现这个数据容器,因为位于堆顶的就是最大的数据。同样,也可以快速从最小堆中找出最小数。
因此可以用如下思路来解决这个问题:用一个最大堆实现左边的数据容器,用最小堆实现右边的数据容器。往堆中插入一个数据的时间效率是 O(logn)。由于只需 O(1)时间就可以得到位于堆顶的数据,因此得到中位数的时间效率是 O(1)。
请你讲讲LRU算法的实现原理?(lrudc)
①LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也很高”,反过来说“如果数据最近这段时间一直都没有访问,那么将来被访问的概率也会很低”,两种理解是一样的;常用于页面置换算法,为虚拟页式存储管理服务。
LRU主要的两个函数 获取数据 get 和 写入数据 put 。
获取数据 get(key) - 如果关键字 (key) 存在于缓存中,则获取关键字的值(总是正数),否则返回 -1。
写入数据 put(key, value) - 如果关键字已经存在,则变更其数据值;如果关键字不存在,则插入该组「关键字/值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。
算法实现的关键
命中率:当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致 LRU 命中率急剧下降,缓存污染情况比较严重。于是像LRU-K、URL-Two queues原理、Multi Queue原理等都是将热点数据识别出来再放入LRU缓存队列,但是热点数据识别都是有一个识别窗口的,比如最近10000次内操作过两次的认为是热点数据会放入LRU缓存,避免LRU缓存的热点数据被污染掉,降低缓存命中率。
复杂度:实现起来较为简单。
存储成本:几乎没有空间上浪费。
代价:命中时需要遍历链表,找到命中的数据块索引,然后需要将数据移到头部。
// 继承LinkedHashMap
public class LRUCache<K, V> extends LinkedHashMap<K, V> {
private final int MAX_CACHE_SIZE;
public LRUCache(int cacheSize) {
// 使用构造方法 public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)
// initialCapacity、loadFactor都不重要
// accessOrder要设置为true,按访问排序
super((int) Math.ceil(cacheSize / 0.75) + 1, 0.75f, true);
MAX_CACHE_SIZE = cacheSize;
}
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
// 超过阈值时返回true,进行LRU淘汰
return size() > MAX_CACHE_SIZE;
}
}
Linux常见面试题(125)
Linux 下系统调用过程以及方法(lxxtdy)
首先,应用程序能直接调用的是系统提供的API,这个在用户态(Ring3)下就可做到。
然后相应的API就会将相应的系统调用号保存到eax寄存器中(这一步通过内联汇编实现),之后就是使用int 0x80触发中断(内联汇编),进入到中断处理函数中(该函数是完全由汇编代码编写),这个时候就进入到了内核态(Ring0)了。
在中断处理函数中就会调用与系统调用号相对应的那个系统调用。在这个函数中,会把ds(数据段寄存器)、es(额外寄存器)这两个寄存器设置为指向内核空间。这样一来,我们无法把数据从用户态中传到内核态啊(如open(const char * filename, int flag, …)中,filename指针指向的字符串的地址是在用户空间中的,在内核空间相应的地方取的话根本没有该字符串),这该怎么办呢?中断处理函数中的fs寄存器被设置为指向了用户空间,所以问题得以解决。
在系统调用中就是进行相应的操作了,如打开文件、写文件等。
处理完后,将会返回到中断处理函数,返回值保存在eax寄存器中。
从中断处理函数中返回到API,依旧是把返回值保存到eax寄存器中。这个时候就从内核态恢复成用户态。
在API中从eax中取出值,做相应的判断返回不同的值,用以表示操作完成情况。
系统调用三种方法(lxxtdy)
通过 glibc 提供的库函数
glibc 是 Linux 下使用的开源的标准 C 库,它是 GNU 发布的 libc 库,即运行时库。glibc 为程序员提供丰富的 API(Application Programming Interface),除了例如字符串处理、数学运算等用户态服务之外,最重要的是封装了操作系统提供的系统服务,即系统调用的封装。
2.2、使用 syscall 直接调用
使用上面的方法有很多好处,首先你无须知道更多的细节,如 chmod 系统调用号,你只需了解 glibc 提供的 API 的原型;其次,该方法具有更好的移植性,你可以很轻松将该程序移植到其他平台,或者将 glibc 库换成其它库,程序只需做少量改动。
但有点不足是,如果 glibc 没有封装某个内核提供的系统调用时,我就没办法通过上面的方法来调用该系统调用。如我自己通过编译内核增加了一个系统调用,这时 glibc 不可能有你新增系统调用的封装 API,此时我们可以利用 glibc 提供的syscall 函数直接调用。
2.3、通过 int 指令陷入
如果我们知道系统调用的整个过程的话,应该就能知道用户态程序通过软中断指令int 0x80 来陷入内核态(在Intel Pentium II 又引入了sysenter指令),参数的传递是通过寄存器,eax 传递的是系统调用号,ebx、ecx、edx、esi和edi 来依次传递最多五个参数,当系统调用返回时,返回值存放在 eax 中。
Linux 常用命令学习
1、ls命令:通过 ls 命令不仅可以查看 linux 文件夹包含的文件,而且可以查看文件权限(包括目录、文件夹、文件权限)查看目录信息等等。(lls)
常用参数搭配:
ls -a 列出目录所有文件,包含以.开始的隐藏文件
ls -A 列出除.及…的其它文件
ls -r 反序排列
ls -t 以文件修改时间排序
ls -S 以文件大小排序
ls -h 以易读大小显示
ls -l 除了文件名之外,还将文件的权限、所有者、文件大小等信息详细列出来
2.cat 命令(lcat)
1.一次显示整个文件:2.从键盘创建一个文件:2.从键盘创建一个文件:
3.more 命令:more 会以一页一页的显示方便使用者逐页阅读(lmore)
+n 从笫 n 行开始显示
-n 定义屏幕大小为n行
+/pattern 在每个档案显示前搜寻该字串(pattern),然后从该字串前两行之后开始显示
-c 从顶部清屏,然后显示
-d 提示“Press space to continue,’q’ to quit(按空格键继续,按q键退出)”,禁用响铃功能
-l 忽略Ctrl+l(换页)字符
-p 通过清除窗口而不是滚屏来对文件进行换页,与-c选项相似
-s 把连续的多个空行显示为一行
-u 把文件内容中的下画线去掉
4.less 命令:使用 less 可以随意浏览文件(lless)
-i 忽略搜索时的大小写
-N 显示每行的行号
-o <文件名> 将less 输出的内容在指定文件中保存起来
-s 显示连续空行为一行
/字符串:向下搜索“字符串”的功能
?字符串:向上搜索“字符串”的功能
n:重复前一个搜索(与 / 或 ? 有关)
N:反向重复前一个搜索(与 / 或 ? 有关)
-x <数字> 将“tab”键显示为规定的数字空格
b 向后翻一页
d 向后翻半页
h 显示帮助界面
Q 退出less 命令
u 向前滚动半页
y 向前滚动一行
空格键 滚动一行
回车键 滚动一页
[pagedown]: 向下翻动一页
[pageup]: 向上翻动一页
5.head 命令: 用来显示档案的开头至标准输出中,默认 head 命令打印其相应文件的开头 10 行。(lhead)
-n<行数> 显示的行数(行数为复数表示从最后向前数)
6.tail 命令:用于显示指定文件末尾内容,不指定文件时,作为输入信息进行处理。常用查看日志文件。(ltail)
-f 循环读取(常用于查看递增的日志文件)
-n<行数> 显示行数(从后向前)
7.which 命令:在 linux 要查找某个文件,但不知道放在哪里了(lwhich)
which 查看可执行文件的位置。
whereis 查看文件的位置。
locate 配合数据库查看文件位置。
find 实际搜寻硬盘查询文件名称。
8.whereis 命令(lwhere)
whereis 命令只能用于程序名的搜索,而且只搜索二进制文件(参数-b)、man说明文件(参数-m)和源代码文件(参数-s)。如果省略参数,则返回所有信息
常用参数:
-b 定位可执行文件。
-m 定位帮助文件。
-s 定位源代码文件。
-u 搜索默认路径下除可执行文件、源代码文件、帮助文件以外的其它文件。
9.locate 命令(llocate)
locate 通过搜寻系统内建文档数据库达到快速找到档案,数据库由 updatedb 程序来更新,updatedb 是由 cron daemon 周期性调用的。默认情况下 locate 命令在搜寻数据库时比由整个由硬盘资料来搜寻资料来得快,但较差劲的是 locate 所找到的档案若是最近才建立或 刚更名的,可能会找不到,在内定值中,updatedb 每天会跑一次,可以由修改 crontab 来更新设定值 (etc/crontab)。
locate 与 find 命令相似,可以使用如 *、? 等进行正则匹配查找
-l num(要显示的行数)
-f 将特定的档案系统排除在外,如将proc排除在外
-r 使用正则运算式做为寻找条件
10.find 命令:用于在文件树中查找文件,并作出相应的处理。(lfind)
命令参数:
pathname: find命令所查找的目录路径。例如用.来表示当前目录,用/来表示系统根目录。
-print: find命令将匹配的文件输出到标准输出。
-exec: find命令对匹配的文件执行该参数所给出的shell命令。相应命令的形式为’command’ { } ;,注意{ }和\;之间的空格。
-ok: 和-exec的作用相同,只不过以一种更为安全的模式来执行该参数所给出的shell命令,在执行每一个命令之前,都会给出提示,让用户来确定是否执行。
命令选项:
-name 按照文件名查找文件
-perm 按文件权限查找文件
-user 按文件属主查找文件
-group 按照文件所属的组来查找文件。
-type 查找某一类型的文件,诸如:
b - 块设备文件
d - 目录
c - 字符设备文件
l - 符号链接文件
p - 管道文件
f - 普通文件
-size n :[c] 查找文件长度为n块文件,带有c时表文件字节大小
-amin n 查找系统中最后N分钟访问的文件
-atime n 查找系统中最后n24小时访问的文件
-cmin n 查找系统中最后N分钟被改变文件状态的文件
-ctime n 查找系统中最后n24小时被改变文件状态的文件
-mmin n 查找系统中最后N分钟被改变文件数据的文件
-mtime n 查找系统中最后n*24小时被改变文件数据的文件
(用减号-来限定更改时间在距今n日以内的文件,而用加号+来限定更改时间在距今n日以前的文件。 )
-maxdepth n 最大查找目录深度
-prune 选项来指出需要忽略的目录。在使用-prune选项时要当心,因为如果你同时使用了-depth选项,那么-prune选项就会被find命令忽略
-newer 如果希望查找更改时间比某个文件新但比另一个文件旧的所有文件,可以使用-newer选项
11.chmod 命令:用于改变 linux 系统文件或目录的访问权限(lchmod)
用于改变 linux 系统文件或目录的访问权限。用它控制文件或目录的访问权限。该命令有两种用法。一种是包含字母和操作符表达式的文字设定法;另一种是包含数字的数字设定法。
每一文件或目录的访问权限都有三组,每组用三位表示,分别为文件属主的读、写和执行权限;与属主同组的用户的读、写和执行权限;系统中其他用户的读、写和执行权限。可使用 ls -l test.txt 查找。
常用参数:
-c 当发生改变时,报告处理信息
-R 处理指定目录以及其子目录下所有文件
12.chown 命令:chown 将指定文件的拥有者改为指定的用户或组(lchown)
chown 将指定文件的拥有者改为指定的用户或组,用户可以是用户名或者用户 ID;组可以是组名或者组 ID;文件是以空格分开的要改变权限的文件列表,支持通配符。
-c 显示更改的部分的信息
-R 处理指定目录及子目录
13.df 命令:显示磁盘空间使用情况。获取硬盘被占用了多少空间(ldf)
-a 全部文件系统列表
-h 以方便阅读的方式显示信息
-i 显示inode信息
-k 区块为1024字节
-l 只显示本地磁盘
-T 列出文件系统类型
df -hl
14.du 命令:du 命令也是查看使用空间的(ldu)
du 命令也是查看使用空间的,但是与 df 命令不同的是 Linux du 命令是对文件和目录磁盘使用的空间的查看:
-a 显示目录中所有文件大小
-k 以KB为单位显示文件大小
-m 以MB为单位显示文件大小
-g 以GB为单位显示文件大小
-h 以易读方式显示文件大小
-s 仅显示总计
-c或–total 除了显示个别目录或文件的大小外,同时也显示所有目录或文件的总和
15.ln 命令:功能是为文件在另外一个位置建立一个同步的链接(lln)
功能是为文件在另外一个位置建立一个同步的链接,当在不同目录需要该问题时,就不需要为每一个目录创建同样的文件,通过 ln 创建的链接(link)减少磁盘占用量。
链接分类:软件链接及硬链接
软链接:
1.软链接,以路径的形式存在。类似于Windows操作系统中的快捷方式
2.软链接可以 跨文件系统 ,硬链接不可以
3.软链接可以对一个不存在的文件名进行链接
4.软链接可以对目录进行链接
硬链接:
1.硬链接,以文件副本的形式存在。但不占用实际空间。
2.不允许给目录创建硬链接
3.硬链接只有在同一个文件系统中才能创建
常用参数:
-b 删除,覆盖以前建立的链接
-s 软链接(符号链接)
-v 显示详细处理过程
16.date 命令:显示或设定系统的日期与时间(ldate)
命令参数:
-d<字符串> 显示字符串所指的日期与时间。字符串前后必须加上双引号。
-s<字符串> 根据字符串来设置日期与时间。字符串前后必须加上双引号。
-u 显示GMT。
%H 小时(00-23)
(2)-d参数使用
date -d “nov 22” 今年的 11 月 22 日是星期三
date -d ‘2 weeks’ 2周后的日期
date -d ‘next monday’ (下周一的日期)
date -d next-day +%Y%m%d(明天的日期)或者:date -d tomorrow +%Y%m%d
17.cal 命令:可以用户显示公历(阳历)日历如只有一个参数(lcal)
常用参数:
-3 显示前一月,当前月,后一月三个月的日历
-m 显示星期一为第一列
-j 显示在当前年第几天
-y [year]显示当前年[year]份的日历
18.grep 命令:强大的文本搜索命令(lgrep)
强大的文本搜索命令,grep(Global Regular Expression Print) 全局正则表达式搜索。
grep 的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到标准输出,不影响原文件内容。
常用参数:
-A n --after-context显示匹配字符后n行
-B n --before-context显示匹配字符前n行
-C n --context 显示匹配字符前后n行
-c --count 计算符合样式的列数
-i 忽略大小写
-l 只列出文件内容符合指定的样式的文件名称
-f 从文件中读取关键词
-n 显示匹配内容的所在文件中行数
-R 递归查找文件夹
19.wc 命令:wc(word count)功能为统计指定的文件中字节数、字数、行数,并将统计结果输出(lwc)
命令参数:
-c 统计字节数
-l 统计行数
-m 统计字符数
-w 统计词数,一个字被定义为由空白、跳格或换行字符分隔的字符串
20.ps 命令:用来查看当前运行的进程状态(lps)
linux上进程有5种状态:
- 运行(正在运行或在运行队列中等待)
- 中断(休眠中, 受阻, 在等待某个条件的形成或接受到信号)
- 不可中断(收到信号不唤醒和不可运行, 进程必须等待直到有中断发生)
- 僵死(进程已终止, 但进程描述符存在, 直到父进程调用wait4()系统调用后释放)
- 停止(进程收到SIGSTOP, SIGSTP, SIGTIN, SIGTOU信号后停止运行运行)
ps 工具标识进程的5种状态码:
D 不可中断 uninterruptible sleep (usually IO)
R 运行 runnable (on run queue)
S 中断 sleeping
T 停止 traced or stopped
Z 僵死 a defunct (”zombie”) process
命令参数:
-A 显示所有进程
a 显示所有进程
-a 显示同一终端下所有进程
c 显示进程真实名称
e 显示环境变量
f 显示进程间的关系
r 显示当前终端运行的进程
-aux 显示所有包含其它使用的进程
ps -ef (system v 输出)
ps -aux bsd 格式输出
ps -ef | grep pid
21.top 命令:显示当前系统正在执行的进程的相关信息,包括进程 ID、内存占用率、CPU 占用率等(ltop)
常用参数:
-c 显示完整的进程命令
-s 保密模式
-p <进程号> 指定进程显示
-n <次数>循环显示次数
top 交互命令
h 显示top交互命令帮助信息
c 切换显示命令名称和完整命令行
m 以内存使用率排序
P 根据CPU使用百分比大小进行排序
T 根据时间/累计时间进行排序
W 将当前设置写入~/.toprc文件中
o或者O 改变显示项目的顺序
第二行,Tasks — 任务(进程),具体信息说明如下:
系统现在共有206个进程,其中处于运行中的有1个,205个在休眠(sleep),stoped状态的有0个,zombie状态(僵尸)的有0个。
第三行,cpu状态信息,具体属性说明如下:
5.9%us — 用户空间占用CPU的百分比。
3.4% sy — 内核空间占用CPU的百分比。
0.0% ni — 改变过优先级的进程占用CPU的百分比
90.4% id — 空闲CPU百分比
0.0% wa — IO等待占用CPU的百分比
0.0% hi — 硬中断(Hardware IRQ)占用CPU的百分比
0.2% si — 软中断(Software Interrupts)占用CPU的百分比
第五行,swap交换分区信息
第七行以下:各进程(任务)的状态监控,项目列信息说明如下:
PID — 进程id
USER — 进程所有者
PR — 进程优先级
NI — nice值。负值表示高优先级,正值表示低优先级
VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR — 共享内存大小,单位kb
S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
%CPU — 上次更新到现在的CPU时间占用百分比
%MEM — 进程使用的物理内存百分比
TIME+ — 进程使用的CPU时间总计,单位1/100秒
COMMAND — 进程名称(命令名/命令行)
22.kill 命令(lkill)
发送指定的信号到相应进程。不指定型号将发送SIGTERM(15)终止指定进程。如果任无法终止该程序可用"-KILL" 参数,其发送的信号为SIGKILL(9) ,将强制结束进程,使用ps命令或者jobs 命令可以查看进程号。root用户将影响用户的进程,非root用户只能影响自己的进程。
常用参数:
-l 信号,若果不加信号的编号参数,则使用“-l”参数会列出全部的信号名称
-a 当处理当前进程时,不限制命令名和进程号的对应关系
-p 指定kill 命令只打印相关进程的进程号,而不发送任何信号
-s 指定发送信号
-u 指定用户
23.free 命令:显示系统内存使用情况,包括物理内存、交互区内存(swap)和内核缓冲区内存(lfree)
命令参数:
-b 以Byte显示内存使用情况
-k 以kb为单位显示内存使用情况
-m 以mb为单位显示内存使用情况
-g 以gb为单位显示内存使用情况
-s<间隔秒数> 持续显示内存
-t 显示内存使用总合
24.Linux上如何查看某个进程的线程 (lckjcxc)
方法一:PS
在ps命令中,“-T”选项可以开启线程查看。下面的命令列出了由进程号为的进程创建的所有线程。
$ ps -T -p
方法二: Top
top命令可以实时显示各个线程情况。要在top输出中开启线程查看,请调用top命令的“-H”选项,该选项会列出所有Linux线程。在top运行时,你也可以通过按“H”键将线程查看模式切换为开或关。
要让top输出某个特定进程并检查该进程内运行的线程状况:
$ top -H -p
方法三: Htop
一个对用户更加友好的方式是,通过htop查看单个进程的线程,它是一个基于ncurses的交互进程查看器。该程序允许你在树状视图中监控单个独立线程。
要在htop中启用线程查看,请开启htop,然后按来进入htop的设置菜单。选择“设置”栏下面的“显示选项”,然后开启“树状视图”和“显示自定义线程名”选项。按退出设置。
怎么清屏?怎么退出当前命令?怎么执行睡眠?怎么查看当前用户 id?查看指定帮助用什么命令?
清屏:clear
退出当前命令:ctrl+c彻底退出
执行睡眠 :ctrl+z挂起当前进程fg恢复后台查看当前用户id:”id“:查看显示目前登陆账户的uid和gid及所属分组及用户名
查看指定帮助:如man adduser这个很全 而且有例子;adduser–help这个告诉你一些常用参数;info adduesr;
linux中ctrl+c的底层原理是什么?(+cdc)
ctrl-c 发送 SIGINT 信号给前台进程组中的所有进程。常用于终止正在运行的程序。
ctrl-z 发送 SIGTSTP 信号给前台进程组中的所有进程,常用于挂起一个进程。
ctrl-d 不是发送信号,而是表示一个特殊的二进制值,表示 EOF。
ctrl-\ 发送 SIGQUIT 信号给前台进程组中的所有进程,终止前台进程并生成 core 文件。
查看文件有哪些命令?
vi文件名#编辑方式查看,可修改
cat文件名#显示全部文件内容
more文件名#分页显示文件内容
less文件名#与more相似,更好的是可以往前翻页
tail文件名#仅查看尾部,还可以指定行数
head文件名#仅查看头部,还可以指定行数
列举几个常用的Linux命令。
列出文件列表:ls【参数 -a -l】
创建目录和移除目录:mkdir rmdir
用于显示文件后几行内容:tail,例如: tail -n 1000:显示最后1000行
打包:tar -xvf
打包并压缩:tar -zcvf
查找字符串:grep
显示当前所在目录:pwd创建空文件:touch
编辑器:vim vi
你平时是怎么查看日志的?(lckrz)
Linux查看日志的命令有多种:tail、cat、tac、head、echo等,本文只介绍几种常用的方法。
1、tail
最常用的一种查看方式
命令格式: tail[必要参数][选择参数][文件]
-f 循环读取
-q 不显示处理信息
-v 显示详细的处理信息
-c<数目> 显示的字节数
-n<行数> 显示行数
-q, --quiet, --silent 从不输出给出文件名的首部
-s, --sleep-interval=S 与-f合用,表示在每次反复的间隔休眠S秒
例如:
tail -n 10 test.log 查询日志尾部最后10行的日志;
tail -n +10 test.log 查询10行之后的所有日志;
tail -fn 10 test.log 循环实时查看最后1000行记录(最常用的)
一般还会配合着grep搜索用,例如;
tail -fn 1000 test.log | grep ‘关键字’
如果一次性查询的数据量太大,可以进行翻页查看,例如 :
tail -n 4700 aa.log |more -1000 可以进行多屏显示(ctrl + f 或者 空格键可以快捷键)
2、head
跟tail是相反的head是看前多少行日志
head -n 10 test.log 查询日志文件中的头10行日志;
head -n -10 test.log 查询日志文件除了最后10行的其他所有日志;
5、sed
这个命令可以查找日志文件特定的一段 , 根据时间的一个范围查询,可以按照行号和时间范围查询按照行号
sed -n ‘5,10p’ filename这样你就可以只查看文件的第5行到第10行。
按照时间段:sed -n ‘/2014-12-17 16:17:20/,/2014-12-17 16:17:36/p’ test.log
6、less
less log.log shift + G 命令到文件尾部 然后输入 ?加上你要搜索的关键字例如 ?1213 按 n 向上查找关键字 shift+n 反向查找关键字 less与more类似
使用less可以随意浏览文件,而more仅能向前移动,不能向后移动,而且 less 在查看 之前不会加载整个文件。
less log2013.log 查看文件 ps -ef | less ps查看进程信息并通过less分页显示 history | less 查看命令历史使用记录并通过less分页显示 less log2013.log log2014.log 浏览多个文件
建立软链接(快捷方式),以及硬链接的命令
软链接: ln -s slink source 硬链接: ln link source
文件权限修改: chmod
格式如下:
chmodu+xfile 给 file 的属主增加执行权限 chmod 751 file 给 file 的属主分配读、写、执行(7)的权限,给 file 的所在组分配读、执行(5)的权限,给其他用户分配执行(1)的权限chmodu=rwx,g=rx,o=xfile 上例的另一种形式 chmod =r file 为所有用户分配读权限chmod444file 同上例 chmod a-wx,a+r file 同上例$ chmod -R u+r directory 递归地给 directory 目录下所有文件和子目录的属主分配读的权限
查看文件内容有哪些命令可以使用?
vi文件名 #编辑方式查看,可修改
cat文件名 #显示全部文件内容
more文件名 #分页显示文件内容
less文件名#与 more 相似,更好的是可以往前翻页
tail 文件名 #仅查看尾部,还可以指定行数
head 文件名 #仅查看头部,还可以指定行数
随意写文件命令?怎么向屏幕输出带空格的字符串,比如”hello world”?
写文件命令:vi
向屏幕输出带空格的字符串:echo hello world
终端是哪个文件夹下的哪个文件?黑洞文件是哪个文件夹下的哪个命令?
终端 /dev/tty;黑洞文件 /dev/null
Linux下命令有哪几种可使用的通配符?分别代表什么含义?
? ”可替代单个字符。
“*” 可替代任意多个字符。
方括号“ [charset]” 可替代charset集中的任何单个字符, 如 [a-z], [abABC]
Linux中进程有哪几种状态?在ps显示出来的信息中分别用什么符号表示的?(lxjczt)
1、不可中断状态:进程处于睡眠状态,但是此刻进程是不可中断的。不可中断,指进程不响应异步信号。
2、暂停状态/跟踪状态:向进程发送一个SIGSTOP信号,它就会因响应该信号 而进入TASK_STOPPED
状态;当进程正在被跟踪时,它处于 TASK_TRACED 这个特殊的状态。正被跟踪”指的是进程暂停下来,等待跟踪它的进程对它进行操作。
3、就绪状态:在 run_queue 队列里的状态
4、运行状态:在 run_queue 队列里的状态
5、可中断睡眠状态:处于这个状态的进程因为等待某某事件的发生(比如等待socket 连接、等待信号量),而被挂起
6、zombie 状态(僵尸):父亲没有通过 wait 系列的系统调用会顺便将子进程的尸体(task_struct)也释放掉
7、退出状态
D 不可中断 Uninterruptible(usually IO)
R 正在运行,或在队列中的进程
S 处于休眠状态
T 停止或被追踪
Z 僵尸进程
W 进入内存交换(从内核 2.6 开始无效)
X 死掉的进程
怎么使一个命令在后台运行?
一般都是使用 & 在命令结尾来让程序自动运行。
哪个命令专门用来查看后台任务?
job -l
把后台任务调到前台执行使用什么命令?把停下的后台任务在后台执行起来用什么命令?(lfg)
把后台任务调到前台执行fg;把停下的后台任务在后台执行起来bg
怎么查看系统支持的所有信号?
kill -l
搜索文件用什么命令? 格式是怎么样的?
find / -name “string*”
使用什么命令查看用过的命令列表?
history
使用什么命令查看网络是否连通?
netstat
查看各类环境变量用什么命令?
查看所有env;查看某个,如home:env $HOME
查找命令的可执行文件是去哪查找的? 怎么对其进行设置及添加?
whereis [-bfmsu][-B <目 录 >…][-M <目 录 >…][-S <目 录 >…][文 件 …]
补充说明:whereis指令会在特定目录中查找符合条件的文件。这些文件的烈性应属于原始代码,二进制文件,或是帮助文件。
-b只查找二进制文件。
-B <目录> 只在设置的目录下查找二进制文件。 -f不显示文件名前的路径名称。
-m 只查找说明文件。
-M <目录> 只在设置的目录下查找说明文件。-s 只查找原始代码文件。
-S <目录> 只在设置的目录下查找原始代码文件。 -u 查找不包含指定类型的文件。
w -h ich 指令会在 PATH 变量指定的路径中,搜索某个系统命令的位置,并且返回第一个搜索结果。
-n 指定文件名长度,指定的长度必须大于或等于所有文件中最长的文件名。
-p 与-n 参数相同,但此处的包括了文件的路径。 -w 指定输出时栏位的宽度。
-V 显示版本信息
通过什么命令查找执行命令?
which只能查可执行文件;whereis只能查二进制文件、说明文档,源文件等
怎么对命令进行取别名?
alias la='ls -a
du和df的定义,以及区别?(ddqb)
du显示目录或文件的大小
df显示每个<文件>所在的文件系统的信息,默认是显示所有文件系统。(文件系统分配其中的一些磁盘块用来记录它自身的一些数据,如i节点,磁盘分布图,间接块,超级块等。这些数据对大多数用户级的程序来说是不可见的,通常称为MetaData。) du命令是用户级的程序,它不考虑Meta Data,而df命令则查看文件系统的磁盘分配图并考虑Meta Data。
df命令获得真正的文件系统数据,而du命令只查看文件系统的部分情况。
当你需要给命令绑定一个宏或者按键的时候,应该怎么做呢?
可以使用bind 命令,bind可以很方便地在shell中实现宏或按键的绑定。
在进行按键绑定的时候,我们需要先获取到绑定按键对应的字符序列。
比如获取F12的字符序列获取方法如下:先按下Ctrl+V,然后按下F12我们就可以得到F12的字符序列 ^[[24~。
接着使用bind进行绑定
当前系统支持的所有命令的列表
使用命令compgen-c,可以打印出所有支持的命令列表。
打印出当前的目录栈(lmlz)
使用Linux命令dirs可以将当前的目录栈打印出来。
你的系统目前有许多正在运行的任务,在不重启机器的条件下,有什么方法可以把所有正在运行的进程移除呢?
使用linux 命令 ’disown -r ’可以将所有正在运行的进程移除。
bash shell中的hash命令有什么作用?(lhash)
linux命令’hash’管理着一个内置的哈希表,记录了已执行过的命令的完整路径,用该命令可以打印出你所使用过的命令以及执行的次数。
哪一个bash内置命令能够进行数学运算。
bash shell 的内置命令 let 可以进行整型数的数学运算
怎样一页一页地查看一个大文件的内容呢?
通过管道将命令”cat file_name.txt” 和 ’more’ 连接在一起可以实现这个需要
数据字典属于哪一个用户的?
数据字典是属于’SYS’用户的,用户‘SYS’ 和 ’SYSEM’是由系统默认自动创建的
怎样查看一个linux命令的概要与用法?假设你在/bin 目录中偶然看到一个你从没见过的的命令,怎样才能知道它的作用和用法呢?
使用命令whatis可以先出显示出这个命令的用法简要,比如,你可以使用whatis zcat去查看‘zcat’的介绍以及使用简要。
使用哪一个命令可以查看自己文件系统的磁盘空间配额呢?
使用命令repquota 能够显示出一个文件系统的配额信息
Linux下创建进程的三种方式及特点(lxcjjc)
在Linux中主要提供了fork、vfork、clone三个进程创建方法。 在linux源码中这三个调用的执行过程是执行fork(),vfork(),clone()时,通过一个系统调用表映射到sys_fork(),sys_vfork(),sys_clone(),再在这三个函数中去调用do_fork()去做具体的创建进程工作。
Linux中进程的组成?(lxjczc)
Linux中的进程包含3个段,分别为数据段、代码段和堆栈段。
数据段,存放的是全局变量、常量、静态变量;
代码段,存放的是程序的可执行代码。
堆栈段,栈存放的是子程序的返回地址、子程序的参数以及程序的局部变量等。堆存放的是动态分配的数据空间。
进程调度算法?(jcddsf)
先来先服务:非抢占式的调度算法,按照请求的顺序进行调度。有利于长作业,但不利于短作业,因为短作业必须一直等待前面的长作业执行完毕才能执行,而长作业又需要执行很长时间,造成了短作业等待时间过长。另外,对I/O密集型进程也不利,因为这种进程每次进行I/O操作之后又得重新排队。
短作业优先:非抢占式的调度算法,按估计运行时间最短的顺序进行调度。长作业有可能会饿死,处于一直等待短作业执行完毕的状态。因为如果一直有短作业到来,那么长作业永远得不到调度。
最短剩余时间优先:最短作业优先的抢占式版本,按剩余运行时间的顺序进行调度。 当一个新的作业到达时,其整个运行时间与当前进程的剩余时间作比较。如果新的进程需要的时间更少,则挂起当前进程,运行新的进程。否则新的进程等待。
时间片轮转:将所有就绪进程按 FCFS 的原则排成一个队列,每次调度时,把 CPU 时间分配给队首进程,该进程可以执行一个时间片。当时间片用完时,由计时器发出时钟中断,调度程序便停止该进程的执行,并将它送往就绪队列的末尾,同时继续把 CPU 时间分配给队首的进程。
时间片轮转算法的效率和时间片的大小有很大关系:因为进程切换都要保存进程的信息并且载入新进程的信息,如果时间片太小,会导致进程切换得太频繁,在进程切换上就会花过多时间。 而如果时间片过长,那么实时性就不能得到保证。
优先级调度:为每个进程分配一个优先级,按优先级进行调度。为了防止低优先级的进程永远等不到调度,可以随着时间的推移增加等待进程的优先级。
什么叫孤儿进程,什么叫僵尸进程?(lxjsjc gejc)
在Linux中,正常情况下,子进程由父进程创建,子进程再创建新的子进程。子进程的结束和父进程的运行是一个异步过程,即父进程永远无法预测子进程到底是什么时候结束。当一个进程完成它的工作终止之后,它的父进程需要调用wait()或者waitpid()系统调用取得子进程的终止状态。
孤儿进程:顾名思义,就是没有了父进程的进程。如果一个父进程退出了,但它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。这些孤儿进程会被init进程接管,并由init进程对它们完成状态收集工作。
僵尸进程:子进程已经退出,而父进程没有调用wait()或waitpid()获取这个子进程的状态信息,于是父进程就不知道这个子进程有没有退出结束,也就没去回收子进程,最终导致子进程的进程描述符仍然保存在系统中。这种进程称之为僵尸进程。
进程控制函数(lxjckzhs)
1.fork
函数功能
创建一个子进程
除了PID和PPID不同,这个子进程复制了父进程的地址空间,并且在父进程作写操作时再次复制。
但不会继承父进程的文件锁和挂起信号。
函数返回值
fork这个函数很特殊,因为它有2个返回值,可能有三个不同的返回值
创建失败,返回-1, 并产生一个errno
创建成功,子进程返回0,父进程返回子进程的进程id
2.vfork
函数功能
和fork()一样都是创建一个子进程
有所不同的是vfork()创建的子进程共享了父进程的地址空间。
通常配合exec族函数使用
函数返回值
创建失败,返回-1, 并产生一个errno
创建成功,子进程返回0,父进程返回子进程的进程id
vfork()创建了子进程,在程序执行时一定是子进程优先执行,而且等到子进程执行完了父进程才执行。
vfork()创建的子进程再使用exec调用了新程序后,父进程就不需要再等它了。
3.exec族函数
函数功能
用被执行的程序替换调用它的程序
path&file:被执行的文件名,需要绝对路径。
arg,…&argv:被执行的程序所需要的命令行参数,包括程序,以空指针NULL结束。
函数返回值
错误返回 -1 并产生一个errno
exec会启动一个新程序来替换原有进程,因此进程ID不会改变
4.wait & waitpid
函数功能
wait的功能是等待任意一个子进程结束(阻塞),然后回收子进程资源。
waitpid的功能是暂时停止目前进程的执行,直到信号来到或指定的子进程结束。然后回收子进程资源。
status:子进程的状态
pid:指定的子进程的PID
options:通常设置为0
函数返回值
错误返回 -1 并产生一个errno
成功,wait()返回结束的子进程的PID, waitpid()返回状态改变了的子进程的PID
WIFEXITED(status)判断子进程是否正常退出,返回非0
WEXITSTATUS(status)获取子进程退出状态
5.exit&_exit
函数功能
使进程退出
status:传递进程结束状态,一般来说0表示正常退出
函数返回值
无返回值
6.kill
函数功能
发送信号
pid:进程ID
sig:要发送的信号
如果pid有效,kill会把信号发送给pid
如果pid=0,kill会把信号发送给当前进程所在的进程组的每个进程
如果pid=-1,kill会把信号发送给具有发送信号权限的每个进程,除了init
如果pid<-1,kill会把信号发送给进程组-pid的每个进程
如果sig=0,kill不会发送信号,错误检测不会报错
函数返回值
错误返回 -1
成功返回 0
7.raise
函数功能
发送信号给自己
等同于 kill(getpid(), sig);
函数返回值
错误返回 -1
成功返回 0
8.signal
函数功能
处理信号,及设置信号的默认处理 信号的安装与回复
signum:要处理的信号,可以在终端使用kill -l命令查看有哪些系统宏定义的信号
handler:选择处理信号的方式,是系统默认SIG_DFL还是忽略SIG_ING还是捕获(函数入口地址)
函数返回值
错误返回 SIG_ERR
Linux环境下定位CPU飙高的原因(cpubg)
导致 CPU 飙高的原因有几个方面
- CPU 上下文切换过多,对于 CPU 来说,同一时刻下每个 CPU 核心只能运行一个线程,如果有多个线程要执行,CPU 只能通过上下文切换的方式来执行不同的线程。上下文切换需要做两个事情:保存运行线程的执行状态,让处于等待中的线程执行。这两个过程需要 CPU 执行内核相关指令实现状态保存,如果较多的上下文切换会占据大量 CPU 资源,从而使得 cpu 无法去执行用户进程中的指令,导致响应速度下降。
- CPU 资源过度消耗,也就是在程序中创建了大量的线程,或者有线程一直占用
- CPU 资源无法被释放,比如死循环!
- CPU 利用率过高之后,导致应用中的线程无法获得 CPU 的调度,从而影响程序的执行效率!
1.查找java进程
通过top命令查询消耗cpu最高的java进程,然后shitf+p 倒序
2.根据进程号查询cpu利用率最高的线程号
在终端执行 top -H -p ,查询pid进程下的所有线程消耗cpu的情况,然后shift+p倒序找到消耗cpu最高的线程id
3.线程id转换
日志文件中线程id是采用16进制的,所以要将查询出来的10进制线程id转换成16进制,数字转换的方式有很多中,在这里通过linux命令printf转换
4.使用jstack下载堆栈信息
使用jstack下载堆栈信息日志文件,sudo -u appadmin jstack 179258 >/usr/local/test2.txt
5.查找日志
生成的日志文件位于linux上,可以通过sz下载到windows下进行查找,根据上文转成16进制的线程id进行全局搜索,就能定位到具体的原因
项目(126)
项目难点(xmnd)
项目介绍
此项目提供了小组成员共享任务提醒的功能。
具体功能为:
管理员对任务或事件的创建,以及对任务的分配。
定时给任务执行人发送提醒。
额外说明:
任务:固定时间点给执行人提醒要做的事情。
事件:所有成员都可以看到的有时间段的事件,事件本身不具备提醒功能,可以添加关联的任务给相应的执行人发送提醒,比如在事件开始的时候关联一个事件开始的任务,在事件结束的时候关联事件结束的任务,事件创建时可以选择是否同步创建关联任务,任务创建时可以选择是否关联已存在的事件。
1、设计任务和事件的规则计算及存储方式
设计方案
首先pass掉子任务全量落表的方式(无限重复规则的按时间落表往后半年或1年的数据),此方式对数据库的压力太大。
采用存储任务规则的方式,对已经发生的任务落历史表,未发生的任务使用规则计算发生时间,未发生已修改的存特殊(special)表。
问题
开发时间成本问题: 任务规则引擎设计,人力成本及时间成本太大。
计算性能问题: 考虑到规则解析计算的性能可能会出现瓶颈,提出此问题。
解决方案:
使用rfc-2445标准规范,选用开源项目组件。寻找可靠的开源组件并测试其性能表现,最终经过Jmeter压力测试发现其性能瓶颈出现在http的并发请求上,规则计算不是其性能瓶颈,为减少网络开销,最终对接口进行封装,采用一次请求计算多条规则的方式设计接口。
对入口服务的接口采用redis缓存进一步缓解服务器压力,对常用接口的结果进行缓存,如首页的接口,由于其参数一天才变动一次,所以完全可采用缓存的方式存储数据。
2、分布式事务解决方案
问题
微服务架构的系统中总会出现
数据压缩(sjys)
-
GZIP 一个压缩比高的慢速算法,压缩后的数据适合长期使用。 JDK中的java.util.zip.GZIPInputStream /
GZIPOutputStream便是这个算法的实现。 -
Deflate
一个基于LZ77算法和Huffman编码实现的压缩算法。
1.LZ77算法,利用相邻数据的相关性对原始数据压缩,该模块输入为原始数据,输出为literal、distance-length数据对;
2.huffman编码,对LZ77的结果分别进行数据统计生成huffman表,再对数据进行huffman编码。该模块的输入为literal和distance-length数据对,其中literal和length共用一个huffman表压缩,distance单独一个huffman表压缩。该模块的输出为两个huffman表以及经过huffman压缩后的数据;
3.序列化、游程编码,huffman表数据可进一步用Huffman编码压缩。该模块的输入为两个huffman表,输出为该huffman表统计后生成的huffman表,以及压缩后的数据流。 -
LZO 底层也是使用的LZ77算法
LZO是块压缩算法,它压缩和解压一个块数据。压缩和解压的块大小必须一样。
LZO将块数据压缩成匹配数据(滑动字典)和非匹配的文字序列。LZO对于长匹配和长文字序列有专门的处理,这样对于高冗余的数据能够获得很好的效果,这样对于不可压缩的数据,也能得到较好的效果。
说一说你对高并发的理解(gbfdc)
从宏观角度看,高并发系统设计的目标有三个:高性能、高可用,以及高可扩展。
高并发的实践方案有哪些?
3.1 通用的设计方法
针对高性能、高可用、高扩展3个方面,总结下可落地的实践方案。
3.2.1 高性能的实践方案
集群部署,通过负载均衡减轻单机压力。
多级缓存,包括静态数据使用CDN、本地缓存、分布式缓存等,以及对缓存场景中的热点key、缓存穿透、缓存并发、数据一致性等问题的处理。
分库分表和索引优化,以及借助搜索引擎解决复杂查询问题。
考虑NoSQL数据库的使用,比如HBase等
异步化,将次要流程通过多线程、MQ、甚至延时任务进行异步处理。
限流,需要先考虑业务是否允许限流(比如秒杀场景是允许的),包括前端限流、Nginx接入层的限流、服务端的限流。
对流量进行削峰填谷,通过MQ承接流量。
并发处理,通过多线程将串行逻辑并行化。
预计算,比如抢红包场景,可以提前计算好红包金额缓存起来,发红包时直接使用即可。
缓存预热,通过异步任务提前预热数据到本地缓存或者分布式缓存中。
减少IO次数,比如数据库和缓存的批量读写、RPC的批量接口支持、或者通过冗余数据的方式干掉RPC调用。
减少IO时的数据包大小,包括采用轻量级的通信协议、合适的数据结构、去掉接口中的多余字段、减少缓存key的大小、压缩缓存value等。
程序逻辑优化,比如将大概率阻断执行流程的判断逻辑前置、For循环的计算逻辑优化,或者采用更高效的算法。
各种池化技术的使用和池大小的设置,包括HTTP请求池、线程池(考虑CPU密集型还是IO密集型设置核心参数)、数据库和Redis连接池等。
JVM优化,包括新生代和老年代的大小、GC算法的选择等,尽可能减少GC频率和耗时。
锁选择,读多写少的场景用乐观锁,或者考虑通过分段锁的方式减少锁冲突。
上述方案无外乎从计算和 IO 两个维度考虑所有可能的优化点,需要有配套的监控系统实时了解当前的性能表现,并支撑你进行性能瓶颈分析,然后再遵循二八原则,抓主要矛盾进行优化。
3.2.2 高可用的实践方案
对等节点的故障转移,Nginx和服务治理框架均支持一个节点失败后访问另一个节点。
非对等节点的故障转移,通过心跳检测并实施主备切换(比如redis的哨兵模式或者集群模式、MySQL的主从切换等)。
接口层面的超时设置、重试策略和幂等设计。
降级处理:保证核心服务,牺牲非核心服务,必要时进行熔断;或者核心链路出问题时,有备选链路。
限流处理:对超过系统处理能力的请求直接拒绝或者返回错误码。
MQ场景的消息可靠性保证,包括producer端的重试机制、broker侧的持久化、consumer端的ack机制等。
灰度发布,能支持按机器维度进行小流量部署,观察系统日志和业务指标,等运行平稳后再推全量。
监控报警:全方位的监控体系,包括最基础的CPU、内存、磁盘、网络的监控,以及Web服务器、JVM、数据库、各类中间件的监控和业务指标的监控。
灾备演练:类似当前的“混沌工程”,对系统进行一些破坏性手段,观察局部故障是否会引起可用性问题。
高可用的方案主要从冗余、取舍、系统运维3个方向考虑,同时需要有配套的值班机制和故障处理流程,当出现线上问题时,可及时跟进处理。
3.2.3 高扩展的实践方案
合理的分层架构:比如上面谈到的互联网最常见的分层架构,另外还能进一步按照数据访问层、业务逻辑层对微服务做更细粒度的分层。
存储层的拆分:按照业务维度做垂直拆分、按照数据特征维度进一步做水平拆分(分库分表)
业务层的拆分:最常见的是按照业务维度拆(比如电商场

















 793
793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









