







po框架
一、ui自动化po框架介绍
(1)PO是Page Object的缩写(pom模型)
(2)业务流程与页面元素操作分离的模式,可以简单理解为每个页面下面都有一个配置class, 配置class就用来维护页面元素或操作方法
(3)提高测试用例的可维护性、可读取性
对比:传统的设计测试用例存在的弊端:
1.易读性差
2.复用性差
3.可维护性差
4.扩展性差
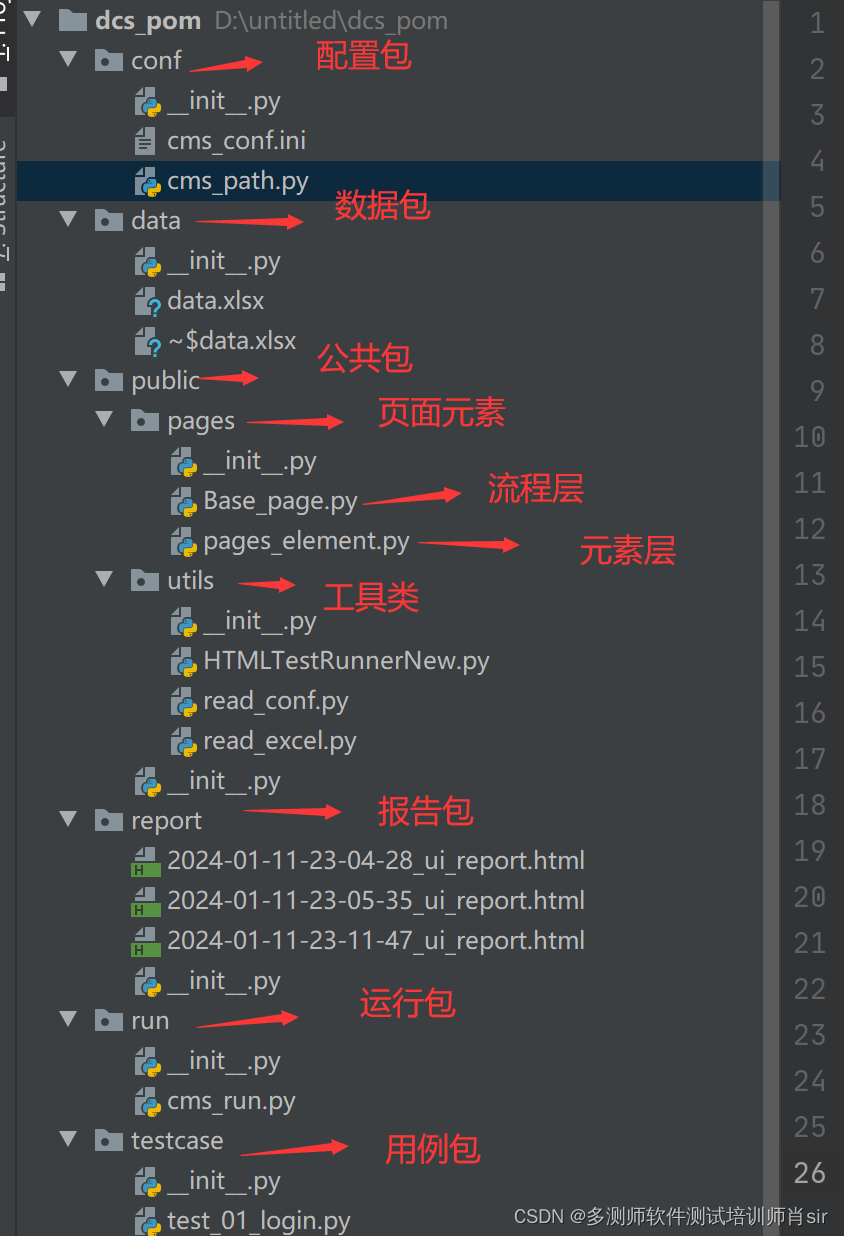
二、ui自动化框架6个包
‘’'1、先创建一个cms项目
(1)创建第一个conf包存放所有配置文件信息(比如项目路径和数据,用例的路径)
可以封装路径
‘‘ini是一种配置文件
在ui自动化测试中配置文件的种类
ini、Excel、.py、yaml、txt’’’
在创建第二个Data包放数据(测试数据)
(2) 在data包中创建一个TestData目录(放测试数据)
测试环境的一些url地址和账号密码可以放在TestDta中
(3)在创建第三个report包==存放测试报告
在report包中创建一个Testrepot目录(存放报告)
(4)在创建第四个public公共公开的包(存放一些功能用例)
在public包中创建pages存放元素层流程层(封装所有页面的公共方法,基类)
在public包中创建utils包(处理公共类公共函数都存放在此)
可以在utils中来读取pages中封装的登录的流程(封装读取ini文件或者EXCEL表格的工具类和工具函数
(5)在创建第五个testcase用例包用来存放用例
编写测试用例
(6)在创建第六个run包用来运行
通过运行测试用例中封装好的用例在运行然后在repot中生成测试报告
框架的思想:把整个用例结构
三、框架的编写
1、先conf包中新建cms_path将项目中的项目包的路径都打印出来
import os
base_path=os.path.dirname(os.path.dirname(__file__))
print(base_path) #项目路径
conf_path=os.path.join(base_path,'conf')
print(conf_path) #conf路径
data_path=os.path.join(base_path,'data')
print(data_path) #data路径
public_path=os.path.join(base_path,'public')
print(public_path) #public路径
pages_path=os.path.join(base_path,'public','pages')
print(pages_path) #pages路径
utils_path=os.path.join(base_path,'public','utils')
print(utils_path) #pages路径
report_path=os.path.join(base_path,'report')
print(report_path) #report路径
run_path=os.path.join(base_path,'run')
print(run_path) #data路径
testcase_path=os.path.join(base_path,'testcase')
print(testcase_path) #data路径
2、在conf包中新建一个cms_conf.ini的文件:
将cms中url、账号、密码写上
[test_data]
url=http://cms.e70w.com/manage/login.do
username=admin
pwd=123456
新建好了ini文件,就要读取ini文件
3、在public中utils中新建 read_conf.py来读取ini文件
from configparser import ConfigParser
from conf.cms_path import *
class Read_Tni(ConfigParser):
def __init__(self,filename):
super(Read_Tni,self).__init__() #用来调用父类(或超类)的方法的 #在子类中调用父类的方法时,你可以使用 super() 函数。
#用了返回的临时对象的 __init__ 方法#调用了父类的构造函数
以上代码:
super(Read_Ini, self).__init__() 这行代码的作用是在 Read_Ini 类中调用其父类(ConfigParser)的构造函数,确保父类的初始化代码被正确执行。这是在子类中重写父类方法时常见的做法,以确保父类的原始行为不会被意外地覆盖或遗漏
self.filename=filename #将传入的filename参数值赋给类的实例变量(即属性)filename
self.read(self.filename) #这行代码调用了ConfigParser类的read方法,用于读取与实例关联的.ini文件
def read_data_ini(self,section=None,option=None):
value=self.get(section,option)
return value
file_path=os.path.join(conf_path,'cms_conf.ini')
read=Read_Tni(file_path)
url=read.read_data_ini('test_data','url')
# print(url)
username=read.read_data_ini('test_data','username')
# print(username)
pwd=read.read_data_ini('test_data','pwd')
# print(pwd)
4、在data包下新建一个excel 表格,填写信息如下
(1)打开data存放地址
(2)xlsx中填写的内容
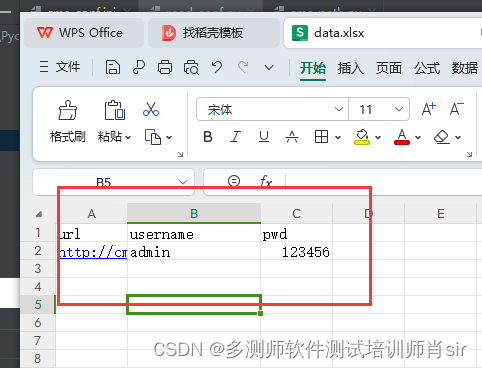
写好以上内容,进行保存。有了excel表格就要读取excel中的内容
==================================
5、我们要读取excel表格:在util中新建read_excel.py文件,通过xlrd
在下载 下载 :pip install xlrd==1.2.0

import xlrd
from conf.cms_path import *
import os
class Read_Excel(object):
def __init__(self,filename,sheet_name):
self.wookbook=xlrd.open_workbook(filename)
self.sheetname=self.wookbook.sheet_by_name(sheet_name)
def get_excel_data(self,row,col):
value=self.sheetname.cell(row,col).value
return value
if __name__ == '__main__':
file=os.path.join(data_path,'data.xlsx')
dx=Read_Excel(file,'cms_data')
url=dx.get_excel_data(1,0)
print(url)
username=dx.get_excel_data(1,1)
print(username)
pwd= dx.get_excel_data(1, 2)
print(pwd)
===================================
在public中pages包下新建两个:BasePages和pages_elemnet 两个py文件:
BasePages包:
import unittest #导入unittest 框架
from time import *
# 调试代码
from selenium import webdriver
driver = webdriver.Chrome() #创建一个调试代码
class BasePage(unittest.TestCase): #创建一个BasePage类,这个类继承unittest框架中TestCase这个类
@classmethod #类方法你#类的# 装饰器
def set_driver(cls,driver): #设置driver属性,里面driver是一个参数,
#入参是一个driver对象,把创建好的driver对象传进来,变成BasePage这个类的属性
#把传进来的谷歌浏览器对象作为当前类、基类属性,基类的变量
cls.driver = driver #类变量
@classmethod
def get_driver(cls): #单例设计模式# 获取driver属性
return cls.driver
# baidu_input=("id","kw")
@classmethod
def find_element(cls,element):
type = element[0] #id
value = element[1] #kw
if type == "id":
elem = cls.driver.find_element_by_id(value)
elif type == "xpath":
elem = cls.driver.find_element_by_xpath(value)
elif type == "class":
elem = cls.driver.find_element_by_class_name(value)
elif type == "name":
elem = cls.driver.find_element_by_name(value)
elif type == "css":
elem = cls.driver.find_element_by_css_selector(value)
elif type == "link_text":
elem = cls.driver.find_element_by_link_text(value)
elif type == "partial":
elem = cls.driver.find_element_by_partial_link_text(value)
else:
raise ValueError("plese input corrt paramters")
return elem
@classmethod #封装输入函数
def sendKeys(cls,elem,text):
return elem.send_keys(text)
@classmethod #封装点击操作
def click(cls,elem):
return elem.click()
@classmethod
def wait(cls,sec):
'''封装一个隐式等待'''
return driver.implicitly_wait(sec)
@classmethod
def sleep(cls,sec):
return sleep(sec)
@classmethod
def frame(cls,elem):
'''定位iframe框'''
return cls.driver.switch_to.frame(elem)
@classmethod
def outframe(cls):
return cls.driver.switch_to.default_content()
@classmethod
def get_text(cls,element):
'''封装根据网页元素拿到text值'''
value = BasePage.find_element(element).text
return value
if __name__ == '__main__':
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
driver.maximize_window()
baidu_input = ("id","kw")
elem = BasePage.find_element(baidu_input).send_keys("多测师")
# elem = BasePage.find_element(baidu_input)
# BasePage.sendKeys(elem,"多测师")
以上是将定位元素和方法封装好,在将
=============================================================
在新建:pages_element.py 包;将实际我们定位的(定位方法,定位地址)
class Pages_Element():
#1.输入用户名
userName = ("id", "userAccount")
#2.输入密码
passWord = ("id", "loginPwd")
#3.点击登陆
loginBtn = ("id", "loginBtn")
#4.断言
desktop = ("xpath", "/html/body/div/section/div[1]/div[1]/ul/li/span")
# 5.点击用户中心
user_center = ("xpath",'//*[@id="menu-user"]/dt')
#6.点击用户管理
user_manager = ("link_text","用户管理")
#7.定位外层iframe框
iframe = ("xpath","/html/body/div/section/div[2]/div[2]/iframe")
#8.点击添加用户
user_add = ("partial","添加用户")
以上是数据和定位方法,元素都确定好,开始编写用例
=============================================================
我们在编写测试用例:登陆用例
```python
from public.pages.Base_page import BasePage
from selenium import webdriver
from public.utils.read_excel import Read_Excel
from public.utils.read_conf import *
from public.pages.pages_element import Pages_Element as p
import unittest
class Test_Login(BasePage):
@classmethod
def setUpClass(cls) -> None:
driver= webdriver.Chrome() #创建一个唯一的driver对象
BasePage.set_driver(driver)
@classmethod
def tearDownClass(cls) -> None:
BasePage.sleep(2)
def test_01_login(self):
driver=BasePage.get_driver()
driver.get(url)
driver.maximize_window()
driver.implicitly_wait(20)
elem=BasePage.find_element(p.userName)
BasePage.sendKeys(elem,username)
elem=BasePage.find_element(p.passWord)
BasePage.sendKeys(elem,pwd)
elem=BasePage.find_element(p.loginBtn)
BasePage.click(elem)
# v=BasePage.get_text(p.desktop)
# assert v=='我的桌面'
# driver.quit()
def test_02_login2(self):
elem = BasePage.find_element(p.user_center)
BasePage.click(elem)
BasePage.sleep(2)
elem2 = BasePage.find_element(p.user_manager)
BasePage.click(elem2)
BasePage.sleep(1)
elem2 = BasePage.find_element(p.iframe)
BasePage.frame(elem2)
BasePage.sleep(2)
elem3 = BasePage.find_element(p.user_add)
BasePage.click(elem3)
if __name__ == '__main__':
unittest.main()
编写完登陆用例后就可以运行用例,
=============================================================
在run包下新建:run_allcase
import time
import unittest
from public.utils.HTMLTestRunnerNew import HTMLTestRunner
from conf.cms_path import *
#定义生成报告的路径以及文件名称
now = time.strftime(‘%Y-%m-%d-%H-%M-%S’)
print(now)
filename = report_path+ “/” + str(now) + “_ui_report.html”
print(filename)
def auto_run():
discover = unittest.defaultTestLoader.discover(start_dir=testcase_path,
pattern=“test_*.py”)
f = open(filename,“wb”)
runner = HTMLTestRunner(stream=f,
title=“Cms后台系统UI自动化测试报告”,
description=“用例执行情况如下”,
tester=“dcs”)
runner.run(discover)
f.close() #关闭文件
if name == ‘main’:
auto_run()
=============================================================
在查看报告包:
report包:
接着在testcase包编写:test_add
from public.pages.Base_page import BasePage
from public.pages.pages_element import Pages_Element as p
class User_Center(BasePage):
@classmethod
def setUpClass(cls) -> None:
BasePage.sleep(1)
@classmethod
def tearDownClass(cls) -> None:
BasePage.sleep(1)
def test_02_user_center(self):
elem = BasePage.find_element(p.user_center)
BasePage.click(elem)
BasePage.sleep(2)
elem2 = BasePage.find_element(p.user_manager)
BasePage.click(elem2)
BasePage.sleep(1)
elem2 = BasePage.find_element(p.iframe)
BasePage.frame(elem2)
BasePage.sleep(2)
elem3 = BasePage.find_element(p.user_add)
BasePage.click(elem3)
















 614
614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











