







一、 kafka概述
1、kafka是什么
Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。
发布/订阅模式
消息的发布者不会将消息发给特定的订阅者,而是将发布的消息分为不同的类别,订阅者只接受感兴趣的消息。
消息队列
1)三个特点
- 缓冲/消峰: 有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
- 解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
- 异步通信: 允许用户把一个消息放入队列,但并不立即处理它,然后在需要的时候再去处理它们。
2)两种模式
- 点对点模式:消费者主动拉取数据,消息收到后清除消息
- 发布/订阅模式:可以有多个topic主题;消费者消费数据后,不删除数据;每个消费者相互独立,都可以消费到数据
2、kafka高效读写数据
1)Kafka 本身是分布式集群,可以采用分区技术,并行度高
2)读数据采用稀疏索引,可以快速定位要消费的数据
3)顺序写磁盘,写的过程是一直追加到文件末端,省去了大量磁头寻址的时间。
4)页缓存 + 零拷贝技术
二、kafka架构
- Producer:消息生产者,就是向Kafka broker发消息的客户端
- Consumer:消息消费者,向Kafka Broker取消息的客户端
- Consumer Group:消费者组,由多个consumer组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费,消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- Broker:一台服务器就是一个Broker,一个集群由多个broker组成。一个broker可以容纳多个topic
- Topic:可以理解为一个队列,生产者和消费者面向的都是一个topic
- Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker上,一个topic可以分为多个partition,每个partition是一个有序队列。------leader
- Repica:副本,一个leader和多个Follower
文件存储
1、文件存储机制
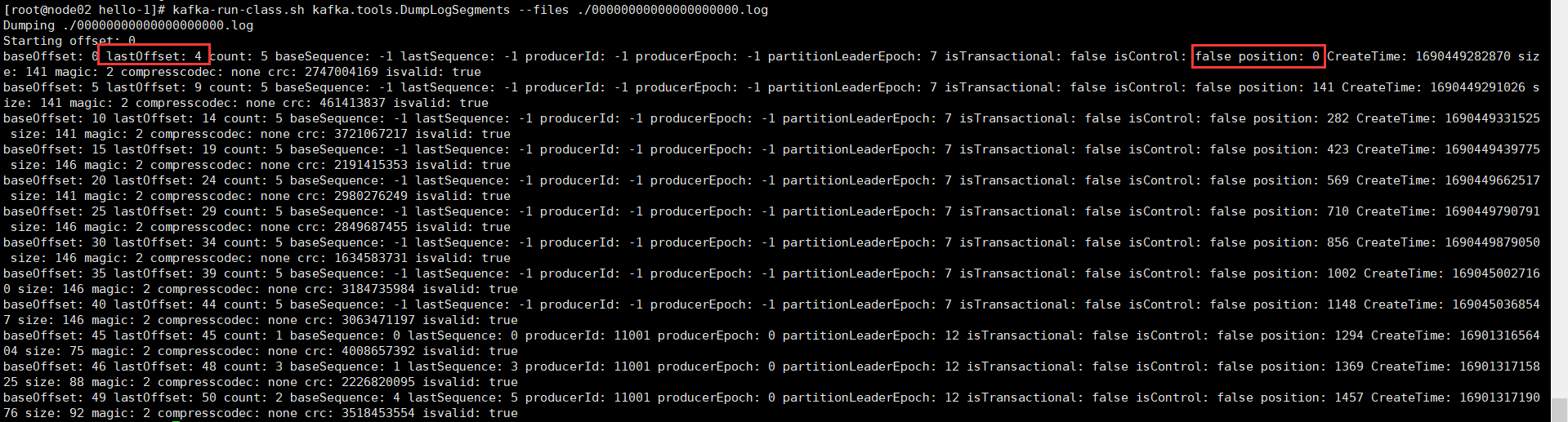
topic是逻辑概念,partition是物理层面的概念,每个partition对应一个log文件夹,producer生产数据会不断追加到log文件末端,防止log文件过大导致定位效率低下,Kafka采取了分片和索引机制,将每个partition分为多个segment。每个segment包括:“.index”文件、“.log”文件和.timeindex等文件。

实用工具查看log文件以及索引文件
kafka-run-class.sh kafka.tools.DumpLogSegments --files ./00000000000000000000.index

kafka-run-class.sh kafka.tools.DumpLogSegments --files ./00000000000000000000.log
步骤
①根据目标offset定位到Segment文件
②找到小于等于目标offset的最大offset对应索引项
③定位到log文件
④向下遍历找到record
2、文件清理策略
Kafka 中默认的日志保存时间为 7 天,可以通过调整如下参数修改保存时间。
- log.retention.hours,最低优先级小时,默认 7 天。
- log.retention.minutes,分钟。
- log.retention.ms,最高优先级毫秒。
- log.retention.check.interval.ms,负责设置检查周期,默认 5 分钟。
日志超过设置时间,日志清理策略
- log.cleanup.policy = delete 所有数据启用删除策略
如果一个 segment 中有一部分数据过期,一部分没有过期,怎么处理?
处理的规则:等待获取最新数据时间戳,也就是所有记录中的最大时间戳,作为判断过期的依据,然后进行清理。
- log.cleanup.policy = compact 所有数据启用压缩策略
副本概念
1、副本作用
副本它的作用是提高数据可靠性,kafka默认副本数是一个,在生产环境中一般配置俩个,保证数据的可靠性,如果太多的副本会增加磁盘存储空间,增加网络上数据传输,降低效率。
Kafka 分区中的所有副本统称为 AR,AR又分为ISR和OSR
ISR(in -sync Replicas):
①达到时间阈值和消息条数阈值,如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR。
②Leader 发生故障之后,就会从 ISR 中选举新的 Leader。
OSR(out -sync Replicas):
表示 Follower 与 Leader 副本同步时,延迟过多的副本。
2、选举机制
Leader 发生故障后,就会从 ISR 中选举出新的 Leader。
当follower变成主节点后,其他follower开始从新的leader同步offset。如果新leader的LEO低于follower,那么follower多余的数据会被删除;最终保证和主节点的数据—致。
kafka leader选举流程
(1)查看 Leader 分布情况
kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic hello

(2)停掉节点broker=1的节点
bin/kafka-server-stop.sh
(3)查看leader分区情况:broker=1被提出ISR

broker=1的节点不可用

(4)启动节点broker=1的节点 leader分区情况

三、分配策略
生产
一个consumer group中有多个consumer组成,一个 topic有多个partition组成,现在的问题是,到底由哪个consumer来消费哪个partition的数据。
可以通过配置参数partition.assignment.strategy,修改分区的分配策略。
1.Range
Range 是对每个 topic 而言的。
首先对同一个 topic 里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。
通过 partitions数/consumer数 来决定每个消费者应该消费几个分区。如果除不尽,那么前面几个消费者将会多消费 1 个分区。
再平衡
如果一个消费者挂掉了如何实现再平衡呢
一个消费者挂掉后,会把他的任务会整体被分配到其他消费者,消费者组需要按照超时时间45s来判断它是否退出,所以需要等待,时间到了45s后,判断它真的退出就会把任务分配给其他broker执行。
2.RoundRobin
RoundRobin 针对集群中所有Topic而言。
RoundRobin 轮询分区策略,是把所有的 partition 和所有的consumer 都列出来,然后按照 hashcode 进行排序,最后通过轮询算法来分配 partition 给到各个消费者。
再平衡
一个消费者挂掉,会按轮询的方式把它的数据分给其他的消费者,也是再过45s后确认是否真正退出。
3.Sticky
首先会尽量均衡的放置分区到消费者上面,在出现同一消费者组内消费者出现问题的时候,会尽量保持原有分配的分区不变化
再平衡
一个消费者挂掉之后,会按照粘性规则,尽可能随机分配分区,有其他消费者消费。
生产者发送消息
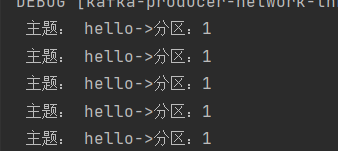
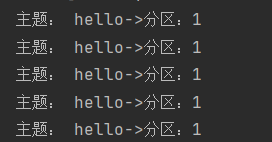
案例一
将数据发往指定 partition 的情况下,例如,将所有数据发往分区 1 中。
生产者端
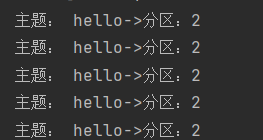
案例二
没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition 数进行取余得到 partition 值
key 值为 a,b,f
四、offset
offset是什么
生产者把数据存放在leader分区,存放完毕后,消费者组开始消费分区数据,消费过程中会有offset,就是指消费者消费到哪里
offset维护位置
0.9之前,维护在zookeeper中,但是会造成一个问题,每个消费者都会和zookeeper进行通讯,造成大量网络通讯问题,效率比较低下
0.9之后。默认将offset存放在kafka一个内置的topic中,名称为_consumer_offsets
__consumer_offsets 主题里面采用 key 和 value 的方式存储数据。key 是 group.id+topic+分区号,value 就是当前 offset 的值。每隔一段时间,kafka 内部会对这个 topic进行compact,也就是每个 group.id+topic+分区号就保留最新数据。
offset提交方式
自动提交
enable.auto.commit:是否开启自动提交offset功能,默认是true
auto.commit.interval.ms:自动提交offset的时间间隔,默认是5s
产生的问题: 重复消费
1) Consumer:每5s提交offset
2)如果提交offset后的2s,consumer挂了
3)再次重启consumer,则从上一次提交的offset处继续消费,导致重复消费
手动提交
手动提交offset的方法有两种:分别是commitSync(同步提交)和commitAsync(异步提交)。
commitSync(同步提交):必须等待offset提交完毕,再去消费下一批数据。
commitAsync(异步提交) :发送完提交offset请求后,就开始消费下一批数据了。
相同点:都会将本次提交的一批数据最高的偏移量提交
不同点:同步提交阻塞当前线程,一直到提交成功,并且会自动失败重试(由不可控因素导致,也会出现提交失败);而异步提交则没有失败重试机制,故有可能提交失败。
产生的问题: 漏消费
当offset被提交时,数据还在内存中未落盘,此时刚好消费者线程被kill掉,那么offset已经提交,但是数据未处理,导致这部分内存中的数据丢失。
五、kafka安全
- 幂等性
幂等性就是指Producer不论向Broker发送多少次重复数据,Broker端都只会持久化一条,保证了不重复。
幂等性的实现原理,kafka引入了PID和Sequence Number。
PID。每个新的Producer在初始化的时候会被分配一个唯一的PID,这个PID对用户是不可见的。
Sequence Numbler。(对于每个PID,该Producer发送数据的每个<Topic, Partition>都对应一个从0开始单调递增的Sequence Number)
幂等性无法实现跨分区和跨会话数据不重复,因为服务器在重启之后,首先PID,就是刚才所说的生产者分配的ID会被打乱,所以无法实现跨会话,然后就是partition的主键会被打乱,所以幂等性无法实现跨分区的数据不重复
- 开启事务:
弥补了这一缺陷,需要开始事务
事务它的实现原理: Producer 端引入了一个 TransactionalId 来解决这个问题,它可以用来标识一个事务操作,便于这个事务的所有操作都能在一个地方(同一个 TransactionCoordinator)进行处理,这个操作把消费和生产的处理在一 个原子单元内完成,操作要么全部完成、要么全部失败。















 834
834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









