






大模型的模型概括
当前大规模语言模型的能力在于给定一个基于自身需求的prompt就可以生成符合需求的结果。形式可以表达为:
从数学角都即学习一个分布:
t r a i n i n g D a t a = > p ( x t , . . . , x L ) trainingData => p(x_t,...,x_L) trainingData=>p(xt,...,xL)
分词
分词是一个非常古老的课题,其目的是将任意字符串转换为标记序列
基于空格的分词
对中文德语等很难生效,因此这里讨论了一些对于好的分词的标准:
- 首先我们不希望有太多的标记(极端情况:字符或字节),否则序列会变得难以建模。
- 其次我们也不希望标记过少,否则单词之间就无法共享参数(例如,mother-in-law和father-in-law应该完全不同吗?),这对于形态丰富的语言尤其是个问题(例如,阿拉伯语、土耳其语等)。
- 每个标记应该是一个在语言或统计上有意义的单位。
Byte pair encoding
著名的BPE编码算法,其需要通过模型训练数据进行学习以获得一些频率特征。

Unicode的问题
由于Unicode编码字符非常多,这会使得训练数据稀疏性过大。
因此可以对字节而不是Unicode字符进行BPE算法,以中文为例:
Unigram model
unigram模型的目标是定义一个目标函数来捕捉一个好的分词的特征,其具有更好的适应性。
给定一个序列 x i : L x_{i:L} xi:L , 一个分词器 T T T是 p ( x 1 : L ) = ∏ ( i , j ) ∈ T ( p ( x i : j ) ) p(x_{1:L})=\prod_{(i,j)\in{T}}(p(x_{i:j})) p(x1:L)=∏(i,j)∈T(p(xi:j))的一个集合。

通过将各个分词的概率相乘,可以得到整个训练数据的似然值,该似然值越高,则分词结果更为合理。该算法具体由以下流程表示:

这一过程目的在于剔除对似然值贡献较小的词汇,减少词汇的稀疏性,通过迭代优化和剪枝,这词汇表会得到提升,模型性能也会得到提升。
(不过不是很懂模型是怎么通过这一优化过程训练的…,有待重新学习)
模型架构
上下文向量表征(Contextual Embedding)要比整体的概率分布表示更高效,其主要标记序列由其相应的上下文向量进行表征:
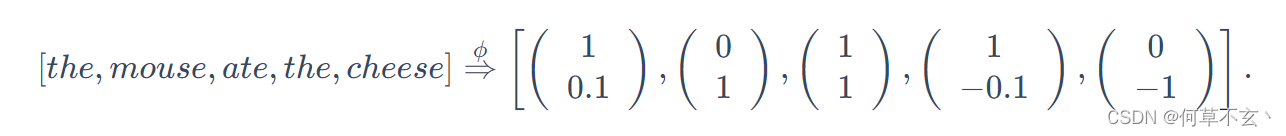
即对某个token的表征要通过其一定范围内的上下文token进行确定,通过定义嵌入函数,其能对标记序列生成上下文向量表征。
(未完待续















 1083
1083











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









