






动机:
提出新架构主要是因为Transformer这种稠密的模型架构对于资源的消耗度极大,扩展这类模型很难,需要数据,模型和流水并行等多种方法。
目前来说,规模已经到了极限。因此,部分研究提出一种“新”的 架构,试图提高大模型的能力上限,同时又不会被规模所限制。
混合专家模型
基础知识
其实就是多个弱学习器组合起来通过门控函数控制的集成学习算法。
Sparsely-gated mixture of experts (Lepikhin et al. 2021)
对每个token或每层Transformer block应用混合专家系统
- 将前馈网络转变为MoE前馈网络:
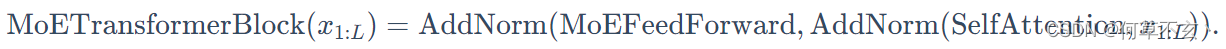
- 隔层使用MoE Transformer block
- 设计特别的门控函数

- 平衡专家

Switch Transformer

稀疏到单个专家(这真的能靠谱嘛
Balanced Assignment of Sparse Experts (BASE) layers (Lewis et al., 2021)

这里剩下的文献堆叠并没有什么分析。。。不如有空去看原文到底在针对大模型特性上做了什么优劣处理对比
基于检索的模型
类似于QA任务中,为大模型提供一个问答库,从而可以使用较小的大模型来完成同等质量的QA任务。
检索方法

剩下也是方法堆叠,暂不做整理。
总结
两类利用弱分类器和外部知识的方法可以有效缓解稠密Transformer带来的规模难以scale的问题。
目前尚不清楚这些模型是否具有与稠密Transformer相同的通用能力。















 2634
2634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









