






前言:
项目的难点是如何保证缓存和数据库的一致性。无论我们是先更新数据库,后更新缓存还是先更新数据库,然后删除缓存,在并发场景之下,仍然会存在数据不一致的情况(也存在删除失败的情况,删除失败可以使用异步重试解决)。有一种解决方法是延迟双删的策略,先删除缓存,再更新数据库,然后休眠一会儿,再删除一次缓存,这样做可以提高提高数据的一致性,但是,延迟的时间是要根据业务需求决定的,需要谨慎设置,同时由于删除了两次缓存,导致性能下降。这个项目中选择的是借助canal,订阅binlog的方式来实现同步。当我们对数据进行修改的时候,数据库就有一个binlog,用canal订阅这个binlog,并将消息投放到kafka中,获取到变更数据的id,删除缓存,如果失败,则重新从消息队列中获得该数据进行重试,超过次数后提示错误信息。重试使用的是@Retryable注解,有最大重试次数、重试延迟时间等属性,如果三次重试后仍然失败,会抛出 RuntimeException,然后触发@recover注解标记的备用方法。
(把canal.serverMode = kafka,canal.destinations = example (对应一个数据库实例),
在example下修改MySQL实例配置文件,设置用户名、登陆密码、需要同步的表,topic等等)
然后创建消费者,接收topic传过来的消息,进行解析,获取id,删除缓存。
canal本质(工作原理)
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送 dump 协议;
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal );
- canal 解析 binary log 对象(原始为 byte 流);
- 并将其发送给下游消息队列
/**
* canal 发送过来的消息
*
* @author huan.fu 2021/9/2 - 下午4:06
*/
@Getter
@Setter
@ToString
public class CanalMessage {
/**
* 测试得出 同一个事物下产生多个修改,这个id的值是一样的。
*/
private Integer id;
/**
* 数据库或schema
*/
private String database;
/**
* 表名
*/
private String table;
/**
* 主键字段名
*/
private List<String> pkNames;
/**
* 是否是ddl语句
*/
private Boolean isDdl;
/**
* 类型:INSERT/UPDATE/DELETE
*/
private String type;
/**
* binlog executeTime, 执行耗时
*/
private Long es;
/**
* dml build timeStamp, 同步时间
*/
private Long ts;
/**
* 执行的sql,dml sql为空
*/
private String sql;
/**
* 数据列表
*/
private List<Map<String, Object>> data;
/**
* 旧数据列表,用于update,size和data的size一一对应
*/
private List<Map<String, Object>> old;
}
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.retry.annotation.Backoff;
import org.springframework.retry.annotation.Recover;
import org.springframework.retry.annotation.Retryable;
import org.springframework.stereotype.Component;
@Component
@Slf4j
public class KafkaConsumer {
@KafkaListener(topics = "customer", groupId = "canal-kafka-springboot-001", concurrency = "5")
@Retryable(maxAttempts = 3, backoff = @Backoff(delay = 1000))
public void consumer(ConsumerRecord<String, String> record, Acknowledgment ack) throws InterruptedException {
log.info(Thread.currentThread().getName() + ":" + LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")) + "接收到kafka消息,partition:" + record.partition() + ",offset:" + record.offset() + "value:" + record.value());
CanalMessage canalMessage = JSON.parseObject(record.value(), CanalMessage.class);
log.info("\r=================================");
log.info("接收到的原始 canal message为: {}", record.value());
log.info("转换成Java对象后转换成Json为 : {}", JSON.toJSONString(canalMessage));
// 重试删除缓存的操作
retryDeleteCache(canalMessage);
ack.acknowledge();
}
@Retryable(maxAttempts = 3, backoff = @Backoff(delay = 1000))
private void retryDeleteCache(CanalMessage canalMessage) {
// 实现删除缓存的逻辑,如果失败将会重试,最多三次
try {
// 删除缓存的操作
deleteCache(canalMessage);
} catch (Exception e) {
// 处理删除缓存失败的异常
log.error("删除缓存失败:{}", e.getMessage());
throw new RuntimeException("删除缓存失败");
}
}
private void deleteCache(CanalMessage canalMessage) {
// 实际的删除缓存的操作
// ...
log.info("删除缓存成功");
}
@Recover
private void recoverAfterMaxAttempts(Exception e, CanalMessage canalMessage) {
// 在达到最大重试次数后执行的备用方法
log.error("删除缓存达到最大重试次数,执行备用方法:{}", e.getMessage());
// 可以在这里处理达到最大重试次数后的逻辑,例如记录日志、发送通知等
}
}
先更新数据库,后更新缓存
假设我们采用「先更新数据库,再更新缓存」的方案,并且两步都可以「成功执行」的前提下,如果存在并发,情况会是怎样的呢?
有线程 A 和线程 B 两个线程,需要更新「同一条」数据,会发生这样的场景:
-
线程 A 更新数据库(X = 1)
-
线程 B 更新数据库(X = 2)
-
线程 B 更新缓存(X = 2)
-
线程 A 更新缓存(X = 1)
最终 X 的值在缓存中是 1,在数据库中是 2,发生不一致。A 虽然先于 B 发生,但 B 操作数据库和缓存的时间,却要比 A 的时间短,执行时序发生「错乱」,最终这条数据结果是不符合预期的。
先更新数据库,后删除缓存
依旧是 2 个线程并发「读写」数据:
-
缓存中 X 不存在(数据库 X = 1)
-
线程 A 读取数据库,得到旧值(X = 1)
-
线程 B 更新数据库(X = 2)
-
线程 B 删除缓存
-
线程 A 将旧值写入缓存(X = 1)
最终 X 的值在缓存中是 1(旧值),在数据库中是 2(新值),也发生不一致。
相关代码:
public R save(UserVO userVO) {
User user = new User();
BeanUtils.copyProperties(userVO, user);
saveUser(user);
//删除缓存
redisTemplate.delete("userInfo:" + user.getUserName());
return R.success("操作成功");
}
在查询数据时,先从缓存获取,如果缓存没有,就从数据库查询,并同时存放到缓存上,这样保证了下次访问时数据能直接从缓存获取,减少了数据库压力
public User getByUserName(String userName) {
User user = (User) redisTemplate.opsForValue().get(userName);
if (user != null) {
return user;
}
user = this.getOne(Wrappers.<User>lambdaQuery().eq(User::getUserName, userName));
redisTemplate.opsForValue().set("userInfo:" + userName, user);
return user;
}
但是执行redis的删除操作时,比如因为网络问题,或者redis本身服务问题,就会失败,而且多线程并发访问时,也会出现数据不一致的情况。
//使用注解,直接实现先更新数据库,后删除缓存的操作
@CacheEvict(value = "category",allEntries = true) //删除某个分区下的所有数据延迟双删:
- 首先,删除了 Redis 中的缓存数据,以确保接下来的读取操作会从数据库中读取最新的数据。
- 接着,更新数据库中的数据,将数据更新为最新的值。
- 在此之后,代码让当前线程休眠一段时间N,这个时间段是为了给数据库操作足够的时间来完成,确保数据已经持久化到数据库中。
- 最后,代码再次删除 Redis 中的缓存数据。这里是延迟双删的关键步骤。由于之前已经删除了缓存数据,再次删除的目的是为了防止在休眠的时间内有其他线程读取到旧的数据,加载到缓存中。
休眠时间的控制
-
延迟时间要大于「主从复制」的延迟时间
-
延迟时间要大于线程 B 读取数据库 + 写入缓存的时间
方案的选择:
- 延时双删适用于对数据一致性要求较高的场景。它能够保证在数据库更新期间,读取请求不会读取到已经失效的缓存数据,从而保证数据的一致性。但是它需要进行两次缓存删除操作,可能会增加一定的资源开销;
- 先更新数据库后删除缓存对性能要求较高的场景。它能够减少一次缓存删除的开销,但是在数据库更新期间,读取请求可能会读取到已经失效的缓存数据,从而导致数据不一致。

RedisUtils.del(key);// 先删除缓存
updateDB(user);// 更新db中的数据
Thread.sleep(N);// 延迟一段时间,在删除该缓存key
RedisUtils.del(key);// 先删除缓存最好的方法是开设一个线程池,在线程中删除key,而不是使用Thread.sleep进行等待,这样会阻塞用户的请求。
代码:
OrderController中新增接口:
/**
* 下单接口:先更新数据库,再删缓存
* @param sid
* @return
*/
@RequestMapping("/createOrderWithCacheV2/{sid}")
@ResponseBody
public String createOrderWithCacheV2(@PathVariable int sid) {
int count = 0;
try {
// 完成扣库存下单事务
orderService.createPessimisticOrder(sid);
// 删除库存缓存
stockService.delStockCountCache(sid);
} catch (Exception e) {
LOGGER.error("购买失败:[{}]", e.getMessage());
return "购买失败,库存不足";
}
LOGGER.info("购买成功,剩余库存为: [{}]", count);
return String.format("购买成功,剩余库存为:%d", count);
}新增线程池接口
// 延时双删线程池
private static ExecutorService cachedThreadPool = new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());
/**
* 缓存再删除线程
*/
private class delCacheByThread implements Runnable {
private int sid;
public delCacheByThread(int sid) {
this.sid = sid;
}
public void run() {
try {
LOGGER.info("异步执行缓存再删除,商品id:[{}], 首先休眠:[{}] 毫秒", sid, DELAY_MILLSECONDS);
Thread.sleep(DELAY_MILLSECONDS);
stockService.delStockCountCache(sid);
LOGGER.info("再次删除商品id:[{}] 缓存", sid);
} catch (Exception e) {
LOGGER.error("delCacheByThread执行出错", e);
}
}
}异步重试:
将删除缓存的请求写到消息队列中,如果删除成功,则去除消息;如果删除失败,执行失败策略,重试服务从消息队列中重新读取这些值,然后再次进行删除重试,重试超过的一定次数,向业务层发送报错信息。但是这在一定程度上也会增加代码的耦合度和维护成本。
高内聚,低耦合:耦合指模块与模块之间的关系,依赖程度,尽量减少一个模块过度依赖另一个模块的情况(我们在A元素去调用B元素,当B元素有问题或者不存在的时候,A元素就不能正常的工作,那么就说元素A和元素B耦合)。内聚模块内部的功能职责的相关性,如果元素有高度的相关职责,除了这些职责在没有其他的工作,那么该元素就有高内聚。这样做是为了可读性,复用性,可维护性和易变更性。
代码实现(使用rocketmq):
pom.xml新增rocketmq依赖:
<rocketmq-spring-boot-starter-version>2.0.3</rocketmq-spring-boot-starter-version>
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-client</artifactId>
<version>4.9.3</version>
</dependency>
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-spring-boot-starter</artifactId>
<version>${rocketmq-spring-boot-starter-version}</version>
</dependency>
yaml配置
rocketmq:
name-server: xxx.xxx.xxx.174:9876;xxx.xxx.xxx.246:9876
producer:
group: shopDataGroup创建服务:
@Override
@Transactional
public Result updateShopById(Shop shop) {
Long id = shop.getId();
if(ObjectUtil.isNull(id)){
return Result.fail("====>店铺ID不能为空");
}
log.info("====》开始更新数据库");
//更新数据库
updateById(shop);
String shopRedisKey = SHOP_CACHE_KEY + id;
Message message = new Message(TOPIC_SHOP,"shopRe",shopRedisKey.getBytes());
//异步发送MQ
try {
rocketMQTemplate.getProducer().send(message);
} catch (Exception e) {
log.info("=========>发送异步消息失败:{}",e.getMessage());
}
//stringRedisTemplate.delete(SHOP_CACHE_KEY + id);
//int i = 1/0; 验证异常流程后,
return Result.ok();
}
创建消费者:
package com.hmdp.mq;
/**
* @author xbhog
* @describe:
* @date 2022/12/21
*/
@Slf4j
@Component
@RocketMQMessageListener(topic = TOPIC_SHOP,consumerGroup = "shopRe",
messageModel = MessageModel.CLUSTERING)
public class RocketMqNessageListener implements RocketMQListener<MessageExt> {
@Resource
private StringRedisTemplate stringRedisTemplate;
@SneakyThrows
@Override
public void onMessage(MessageExt message) {
log.info("========>异步消费开始");
String body = null;
body = new String(message.getBody(), "UTF-8");
stringRedisTemplate.delete(body);
int reconsumeTimes = message.getReconsumeTimes();
log.info("======>重试次数{}",reconsumeTimes);
if(reconsumeTimes > 3){
log.info("消费失败:{}",body);
return;
}
throw new RuntimeException("模拟异常抛出");
}
}
kafuka的删除重试机制:Kafka 生产者负责将删除缓存的请求发送到指定主题,而 Kafka 消费者则监听该主题,处理删除缓存的逻辑。在处理失败时,通过不提交偏移量来实现消息的重试。
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class CacheDeletionConsumer {
private static final String TOPIC = "cache-deletion-topic";
private static final String GROUP_ID = "cache-deletion-group";
private static final String BOOTSTRAP_SERVERS = "your_bootstrap_servers";
public static void main(String[] args) {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props)) {
consumer.subscribe(Collections.singletonList(TOPIC));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
try {
// 处理删除缓存的业务逻辑
processCacheDeletion(record);
// 如果删除成功,手动提交偏移量
consumer.commitSync();
} catch (Exception e) {
// 处理删除缓存失败,不提交偏移量,消息将在下次拉取时重新获取
handleCacheDeletionFailure(record, e);
}
}
}
}
}
private static void processCacheDeletion(ConsumerRecord<String, String> record) {
// 实际的删除缓存逻辑
String cacheKey = record.value().substring("DELETE_CACHE:".length());
System.out.println("Deleting cache for key: " + cacheKey);
}
private static void handleCacheDeletionFailure(ConsumerRecord<String, String> record, Exception e) {
// 处理删除缓存失败的逻辑,可以记录日志、进行重试等
System.err.println("Error deleting cache for key: " + record.value() + ". Exception: " + e.getMessage());
}
}
参考:两难!先更新数据库再删缓存?还是先删缓存再更新数据库?-CSDN博客
https://www.cnblogs.com/xbhog/p/17004151.html
订阅binlog异步删除,使用canal
流程如下图所示:
(1)更新数据库数据
(2)数据库会将操作信息写入binlog日志当中
(3)canal订阅程序提取出所需要的数据以及key
(4)另起一段非业务代码,获得该信息
(5)尝试删除缓存操作,发现删除失败
(6)将这些信息发送至消息队列
(7)重新从消息队列中获得该数据,重试操作
canal基础知识:
Canal组件是一个基于MysQL数据库增量日志解析,提供增量数据订阅和消费,支持将增量数据投递到下游消费者(如Kafka、RocketMQ等)或者存储(如Elasticsearch、HBase等)的组件。
binlog的格式:

canal工作原理
- Canal将自己伪装为MysQL slave(从库),向MysQL master(住库)发送dump协议
- MysQLmaster(主库)收到dump请求,开始推送binarylog给slave(即canal).
- Canal接收并解析Binlog日志,得到变更的数据,执行后续逻辑
修改配置支持binlog:
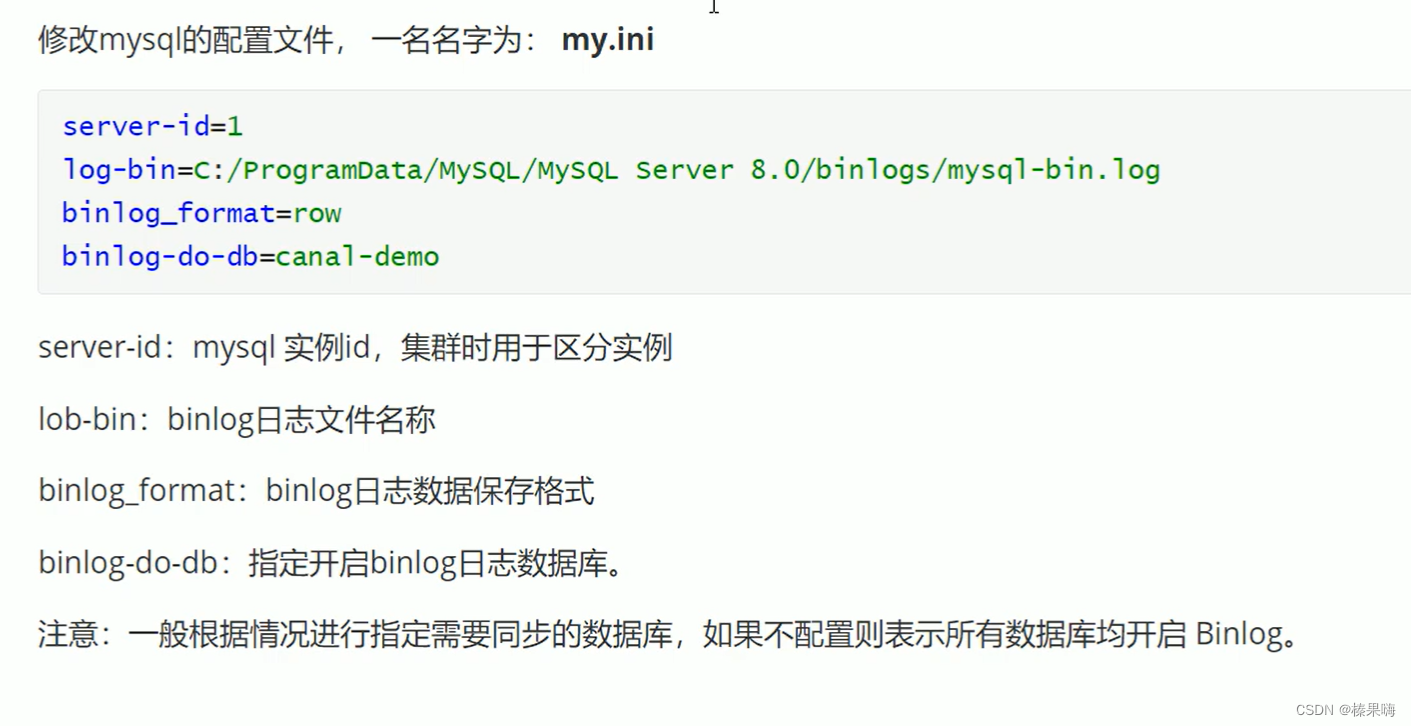
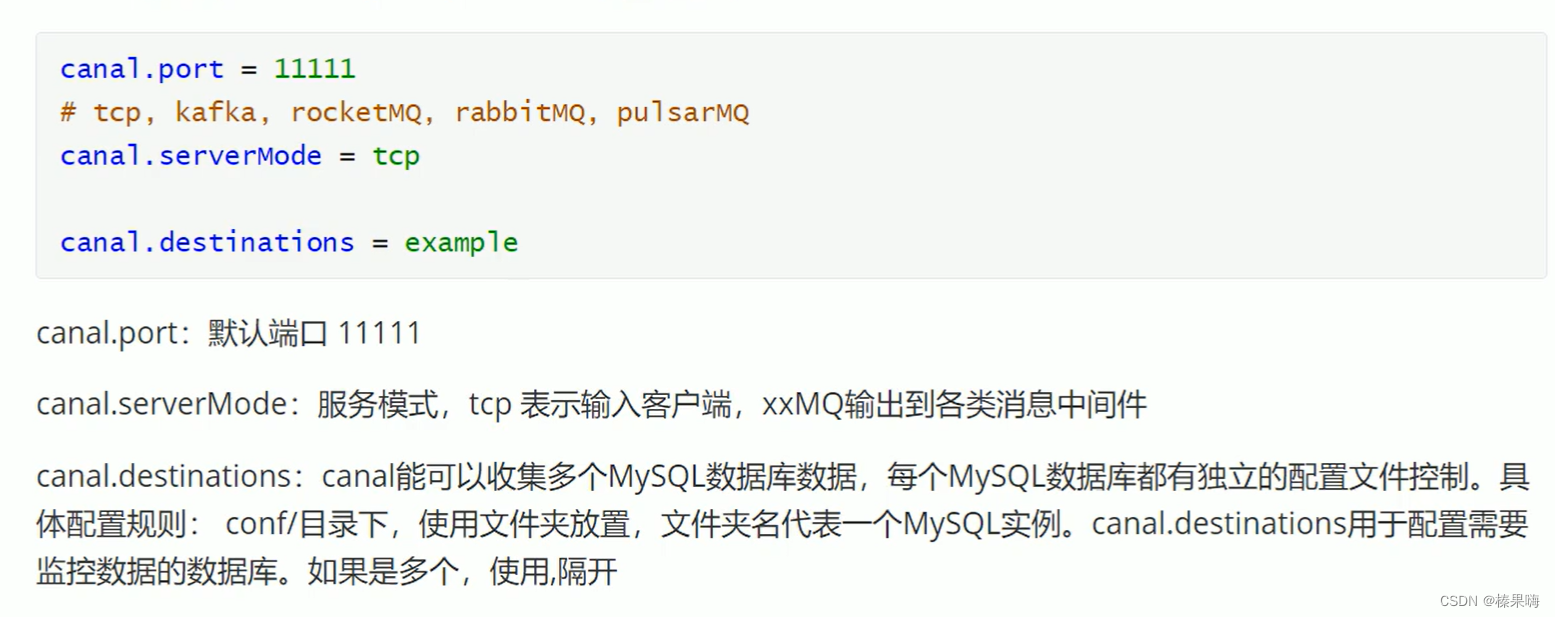
修改canal.properties配置:
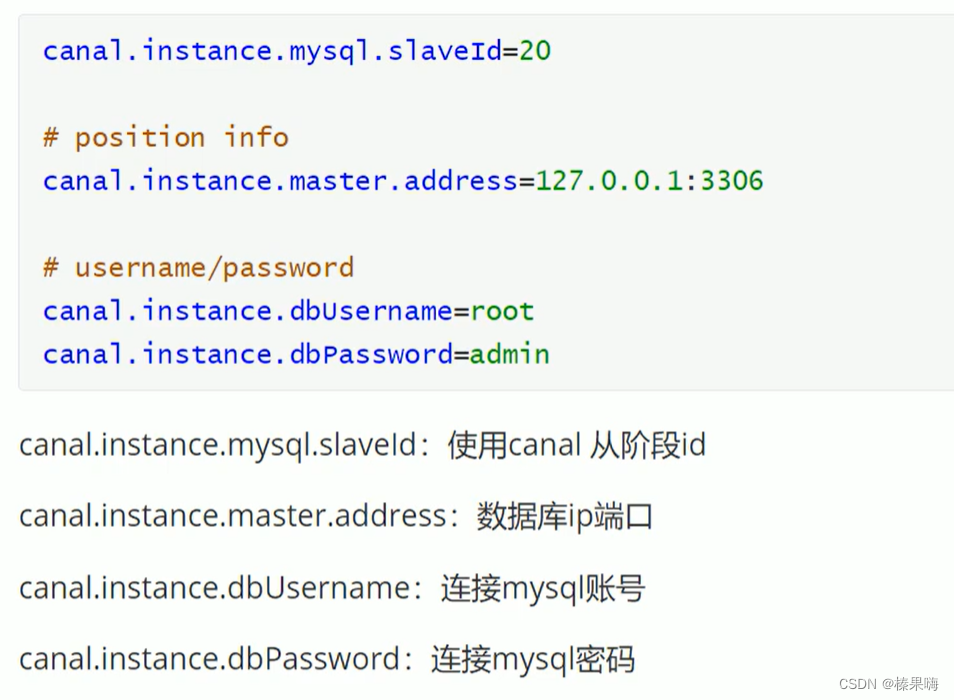
修改mysql文件的instance.properties配置:
代码:
//1.获取canal连接对象
CanalConnector canalConnector=CanalConnectors.newSingleConnector(new InetSocketAddress( hostname:"localhost",port:11111),destination:"example",username:"",password:"");
while(true){
//2.获取连接
canalConnector.connect(;
//3.指定要监控的数据库
canalConnector.subscribe( s:"canal-demo.*");
//4.获取Message
Message message =canalConnector.get(100);
List<CanalEntry.Entry>entries =message.getEntries();
if(entries.size()<=0){
System.out.println("没有数据,休息一会");
try {
Thread.sleep(millis:1000);
}catch(InterruptedException e){
e.printStackTrace();
}
}else{
for(CanalEntry.Entry entry:entries){
//获取表名
String tableName =entry.getHeader().getTableName();
//Entry类型
CanalEntry.EntryType entryType =entry.getEntryType();
//判断entryType 是否为ROWDATA
if (CanalEntry.EntryType.ROWDATA.equals(entryType)){
//序列化数据
ByteString storeValue =entry.getStoreValue();
// 反序列化
CanalEntry.RowChange rowChange =CanalEntry.RowChange.parseForm(storeValue);
//获取事件类型
CanalEntry.EventType eventType =rowChange.getEventType();
//获取具体的数据
List<CanalEntry.RowData>rowDatasList =rowChange.getRowDatasList();
//遍历并打卬
for (CanalEntry.RowData rowData : rowDatasList){
//获取变更前的列
List<CanalEntry.Column> beforeColumnsList = rowData.getBeforeColumnsList();
Map<String,0bject>bMap=new HashMap<>();
for (CanalEntry.CoLumn coLumn : beforeCoLumnsList)
//列名和对应的值
Map.put(column.getName(O),column.getValue(0);
Map<String,0bject> afMap =new HashMap>();
//变更后的
List<CanalEntry.ColumnafterColumnsList=rowData.getAfterColumnsList(); 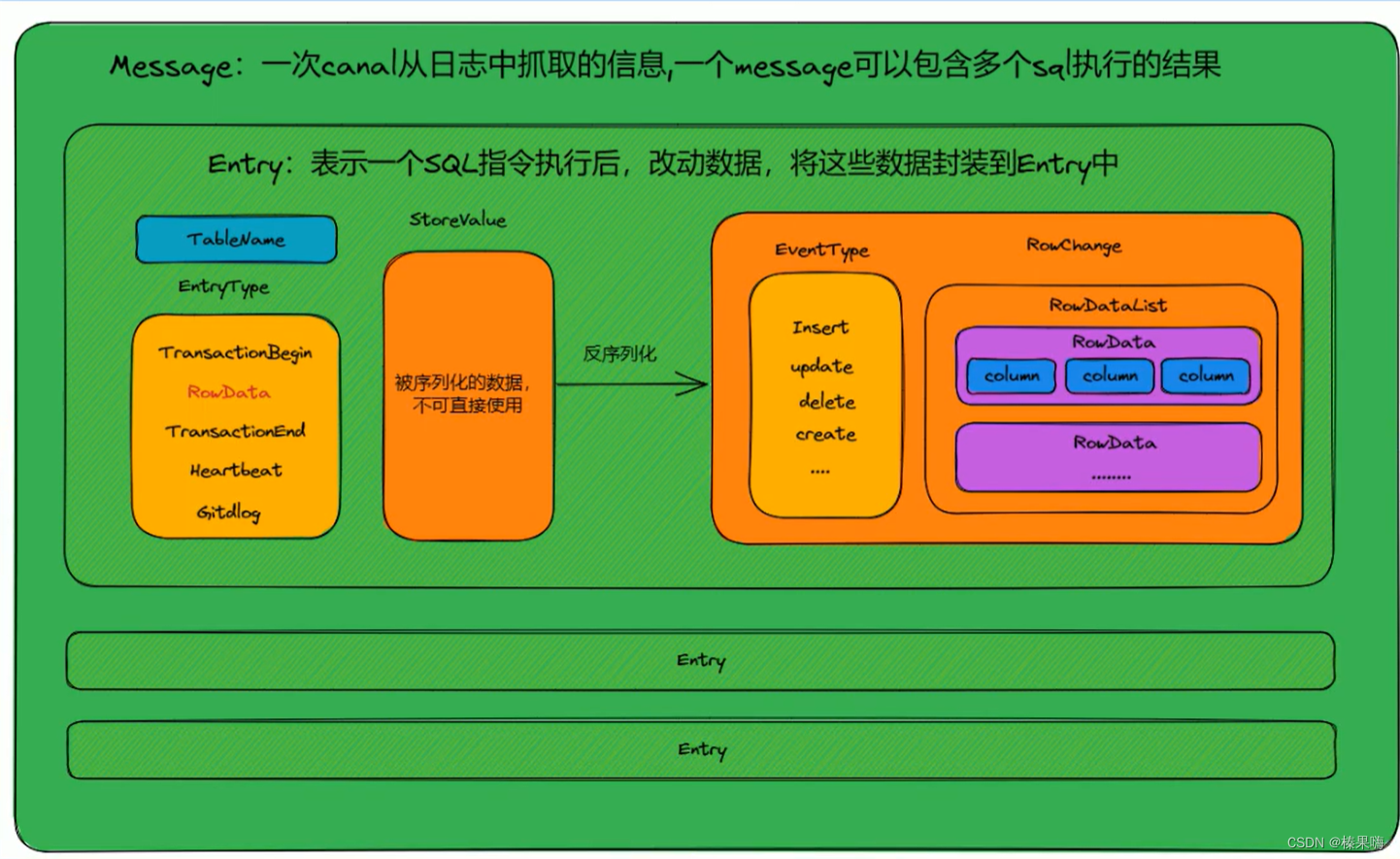
问:Canal是什么?有哪些特性?
答:Canal是阿里巴巴开源的一款基于Netty实现的分布式、高性能、可靠的消息队列,在实时数据同步和数据分发场景下有着广泛的应用。Canal具有以下特性:支持MysQL、Oracle等数据库的日志解析和订阅;支持多种数据输出方式,如Kafka、RocketMQ、ActiveMQ等;支持支持数据过滤和格式转换;拥有低延迟和高可靠性等优秀的性能指标。
问:Canal的工作原理是什么?
答:Canal主要通过解析数据库的binlog日志来获取到数据库的增、删、改操作,然后将这些变更事件发送给下游的消费者。Canal核心组件包括Client和Server两部分,Client负责连接数据库,并启动日志解析工作,将解析出来的数据发送给Server;Server则负责接收Client发送的数据,并进行数据过滤和分发。Canal还支持多种数据输出器,如Kafka、RocketMQ、ActiveMQ等,可以将解析出来的数据发送到不同的消息队列中,以便进行进一步的处理和分析。
问:Canal的优缺点是什么?
答:Canal的优点主要包括:高性能、分布式、可靠性好、支持数据过滤和转换、跨数据库类型(如MysQL、Oracle等)等。缺点包括:使用难度较大、对数据库的日志产生一定的影响、不支持数据的回溯(即无法获取历史数据)等。
问:Canal在业务中有哪些应用场景?
答:Canal主要用于实时数据同步和数据分发场景,常见的应用场景包括:数据备份与灾备、增量数据抽取和同步、数据实时分析、在线数据迁移等。特别是在互联网大数据场景下,Canal已经成为了各种数据处理任务的重要工具之一。















 1115
1115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









