









 该博客介绍了通过引入混合注意力机制(HAM)改进YoloV8的三种策略。首先,在输出的FeatureMap上应用注意力,其次在Neck的上采样区域加入HAM,最后在Head层集成HAM。通过修改代码并训练,实验结果显示这些改进提升了模型的检测性能。
该博客介绍了通过引入混合注意力机制(HAM)改进YoloV8的三种策略。首先,在输出的FeatureMap上应用注意力,其次在Neck的上采样区域加入HAM,最后在Head层集成HAM。通过修改代码并训练,实验结果显示这些改进提升了模型的检测性能。
摘要
HAM通过快速一维卷积来缓解通道注意机制的负担,并引入通道分离技术自适应强调重要特征。HAM作为通用模块,在CIFAR-10、CIFAR-100和STL-10数据集上实现了SOTA级别的分类性能。
论文链接:https://www.sciencedirect.com/science/article/abs/pii/S0031320322002667?via%3Dihub
方法
通道注意力如下图:
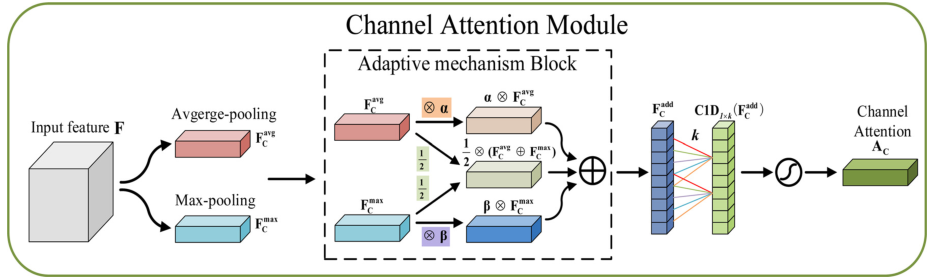
输入特征首先经过两个分支的不同池化得到和,这与CBAM中保持一致,平均池化可以学习到目标物体的程度信息,最大池化则能够学习到物体的判别性特征,同时使用的话,最大池化编码目标的显著性信息,能够很好地弥补平均池化编码的全局信息。
空间注意模块如下图:
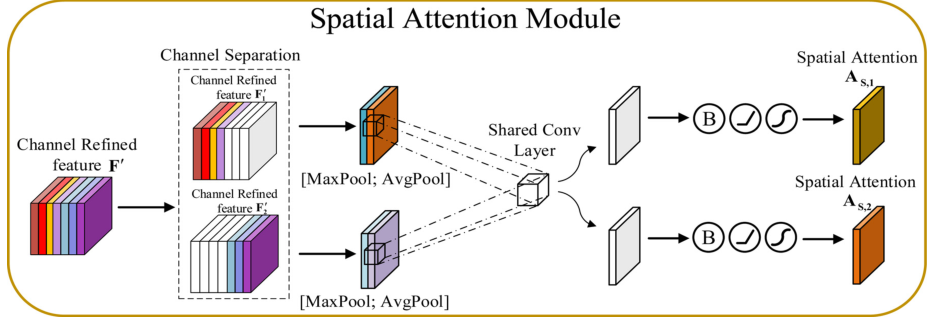
输入特征为经过通道注意模块的通道细化特征,其中每个通道都具有不同的重要性(在数值表现上,通道注意张量中重要的通道权重更大

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











