






目录
Java集合类主要由两个根接口Collection和Map派生出来的,Collection派生出了三个子接口:List、Set、Queue(Java5新增的队列),因此Java集合大致也可分成List、Set、Queue、Map四种接口体系,(注意:Map不是Collection的子接口)。
其中List代表了有序可重复集合,可直接根据元素的索引来访问;Set代表无序不可重复集合,只能根据元素本身来访问;Queue是队列集合;Map代表的是存储key-value对的集合,可根据元素的key来访问value。
集合和数组的区别:
- 数组是大小固定的,一旦创建无法扩容;集合大小不固定。
- 数组的存放的类型只能是一种,集合存放的类型可以不是一种(不加泛型时添加的类型是Object)。
- 初始化集合时,泛型类型不可以是基本数据类型。

1 Collection
Collection集合中,每个位置只能存储一个元素,下表中是Collection的所有方法。
| 返回类型 | 方法名与描述 |
| boolean | add(E e) 将元素添加到集合中(可选操作)。 |
| boolean | addAll(Collection<? extends E> c) 将指定集合中的所有元素添加到此集合(可选操作)。 |
| void | clear() 从此集合中删除所有元素(可选操作)。 |
| boolean | contains(Object o) 如果此集合包含指定的元素,则返回 true 。 |
| boolean | containsAll(Collection<?> c) 如果此集合包含指定 集合中的所有元素,则返回true。 |
| boolean | equals(Object o) 将指定的对象与此集合进行比较以获得相等性。 |
| int | hashCode() 返回此集合的哈希码值。 |
| boolean | isEmpty() 如果此集合不包含元素,则返回 true 。 |
| Iterator<E> | iterator() 返回此集合中的元素的迭代器。 |
| default Stream<E> | parallelStream() 返回可能并行的 Stream与此集合作为其来源。 |
| boolean | remove(Object o) 从该集合中删除指定元素的单个实例(如果存在)(可选操作)。 |
| E | remove(int index) 从该集合中删除指定索引的单个实例(如果存在)(可选操作)。 |
| boolean | removeAll(Collection<?> c) 删除指定集合中包含的所有此集合的元素(可选操作)。 |
| default boolean | removeIf(Predicate<? super E> filter) 删除满足给定谓词的此集合的所有元素。 |
| boolean | retainAll(Collection<?> c) 仅保留此集合中包含在指定集合中的元素(可选操作)。 |
| int | size() 返回此集合中的元素数。 |
| default Spliterator<E> | spliterator() 创建一个Spliterator在这个集合中的元素。 |
| default Stream<E> | stream() 返回以此集合作为源的顺序 Stream 。 |
| Object[] | toArray() 返回一个包含此集合中所有元素的数组。 |
| <T> T[] | toArray(T[] a) 返回包含此集合中所有元素的数组; 返回的数组的运行时类型是指定数组的运行时类型。 |
1.1 List
List集合代表一个有序、可重复集合,集合中每个元素都有其对应的顺序索引。List集合默认按照元素的添加顺序设置元素的索引,可以通过索引(类似数组的下标)来访问指定位置的集合元素。
实现List接口的集合主要有:ArrayList、LinkedList、Vector、Stack。
List除了collection的方法之外,还有以下常用的特有方法。
| 返回类型 | 方法名与描述 |
| void | add(int index, E element) 在此列表中的指定位置插入指定的元素。 |
| boolean | addAll(int index, Collection<? extends E> c) 将指定集合中的所有元素插入到此列表中,从指定的位置开始。 |
| E | get(int index) 返回此列表中指定位置的元素。 |
| int | indexOf(Object o) 返回此列表中指定元素的第一次出现的索引,如果此列表不包含元素,则返回-1。 |
| E | set(int index, E element) 用指定的元素(可选操作)替换此列表中指定位置的元素。 |
| default void | sort(Comparator<? super E> c) 使用随附的 Comparator排序此列表来比较元素。 |
| List<E> | subList(int fromIndex, int toIndex) 返回此列表中指定的 fromIndex (含)和 toIndex之间的视图。 |
| int | indexOf(Object o) 返回此列表中指定元素的第一次出现的索引,如果此列表不包含元素,则返回-1。 |
下图展示了List常用的方法,图中以ArrayList为例,但换成其他任何的List实现类都是一样的结果。
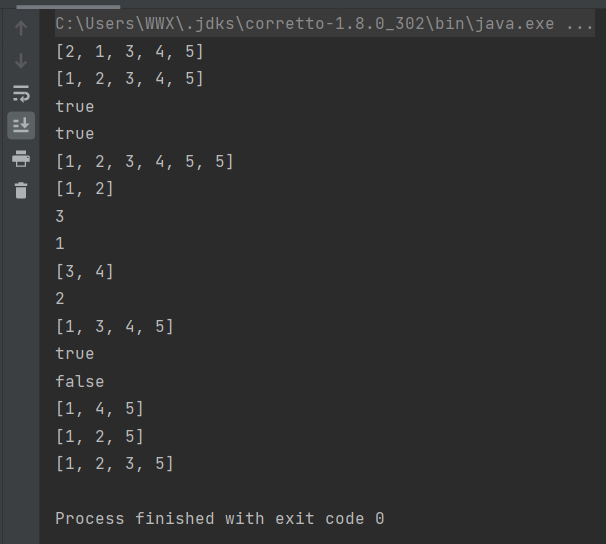
public class Test {
public static void main(String[] args) {
List arrayList = new Stack();
arrayList.add(2);//添加元素 [2]
arrayList.add(1);//添加元素 [2, 1]
Integer[] array ={3, 4, 5};//为了将数组转换成List,一定要用引用数据类型的数组,不可以用基本数据类型数组
List<Integer> tempArrayList = Arrays.asList(array);//将数组转换成集合
arrayList.addAll(tempArrayList);//将新集合添加到原集合中
System.out.println(arrayList);//打印arrayList [2, 1, 3, 4, 5]
arrayList.sort(Comparator.naturalOrder());//排序
System.out.println(arrayList);//打印arrayList [1, 2, 3, 4, 5]
System.out.println(arrayList.contains(1));//集合中包含元素1,打印:true
System.out.println(arrayList.containsAll(tempArrayList));//集合中包含集合tempArrayList,打印:true
arrayList.add(5);
System.out.println(arrayList);
arrayList.removeAll(tempArrayList);//删除arrayList中所有tempArrayList的元素,顺序并不需要与tempArrayList相同
System.out.println(arrayList);
arrayList.addAll(tempArrayList);
System.out.println(arrayList.get(2));//获得索引为2的对象 打印:3
System.out.println(arrayList.indexOf(2));//获得对象2的索引 打印:1
System.out.println(arrayList.subList(2, 4));//获得索引为2到4的List集合,包括索引2,但不包括索引4,打印该List:[3, 4]
System.out.println(arrayList.remove(1));//删除索引为1的对象,返回该对象 打印:2
System.out.println(arrayList);//打印ArrayList [1, 3, 4, 5]
System.out.println(arrayList.remove(new Integer(3)));//删除对象3,删除成功返回true 打印:true
System.out.println(arrayList.remove(new Integer(6)));//删除对象6,删除失败返回false 打印:false
System.out.println(arrayList);//打印arrayList [1, 4, 5]
arrayList.set(1, 2);//用对象2代替索引为1的对象
System.out.println(arrayList);//打印arrayList [1, 2, 5]
arrayList.add(2, 3);//在索引2的位置加入元素3,后续元素后移
System.out.println(arrayList);//打印arrayList [1, 2, 3, 5]
}
}1.1.1 ArrayList
ArrayList是一个动态数组,也是我们最常用的集合,是List类的典型实现。它允许任何符合规则的元素插入甚至包括null。每一个ArrayList都有一个初始容量(10),该容量代表了数组的大小。随着容器中的元素不断增加,容器的大小也会随着增加。在每次向容器中增加元素的同时都会进行容量检查,当快溢出时,就会进行扩容操作。所以如果我们明确所插入元素的多少,最好指定一个初始容量值,避免过多的进行扩容操作而浪费时间、效率。
ArrayList擅长于随机访问。同时ArrayList是非同步的,即非线程安全的。
1.1.2 Vector
与ArrayList相似,但是Vector是同步的。所以说Vector是线程安全的动态数组。它的操作与ArrayList几乎一样。
1.1.3 Stack
Stack继承自Vector,实现一个先进后出的堆栈。Stack提供5个额外的方法使得Vector得以被当作堆栈使用。基本的push和pop 方法,还有peek方法得到栈顶的元素,empty方法测试堆栈是否为空,search方法检测一个元素在堆栈中的位置。Stack刚创建后是空栈。
| 返回类型 | 方法名与描述 |
| boolean | empty() 测试此堆栈是否为空。与isEmpty()作用完全一致 |
| E | peek() 查看此堆栈顶部的对象,而不从堆栈中删除它。 |
| E | pop() 删除此堆栈顶部的对象,并将该对象作为此函数的值返回。 |
| E | push(E item) 将项目推送到此堆栈的顶部。 |
| int | search(Object o) 确定对象是否存在于堆栈中。如果找到该元素,它将从堆栈顶部返回元素的位置(栈顶的位置是1不是0)。否则,它返回-1。 |
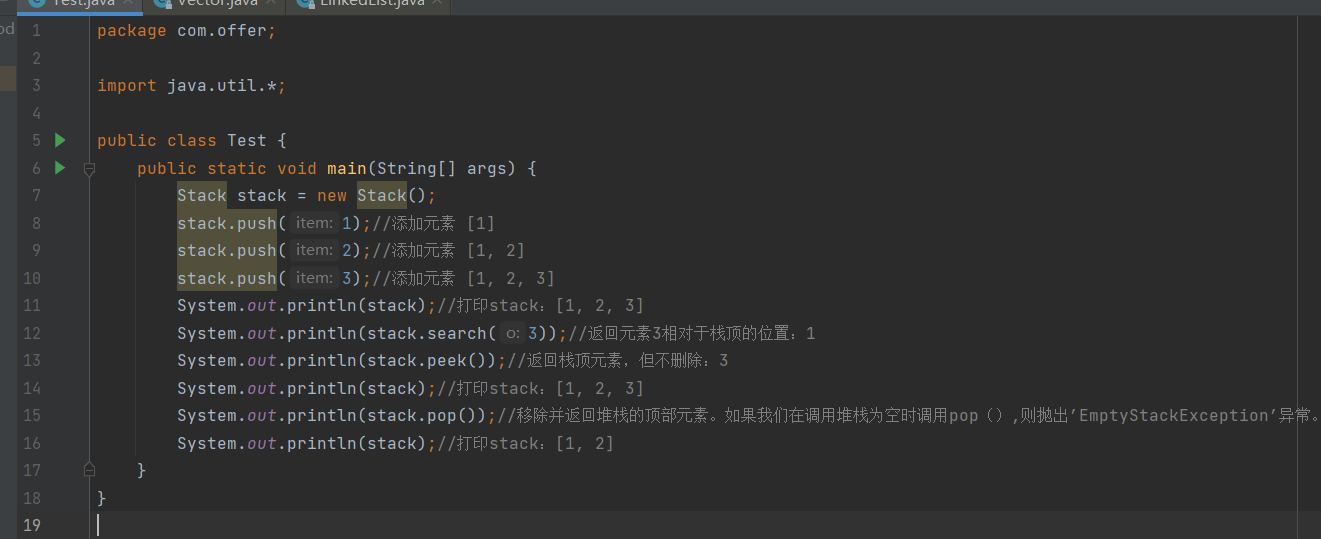
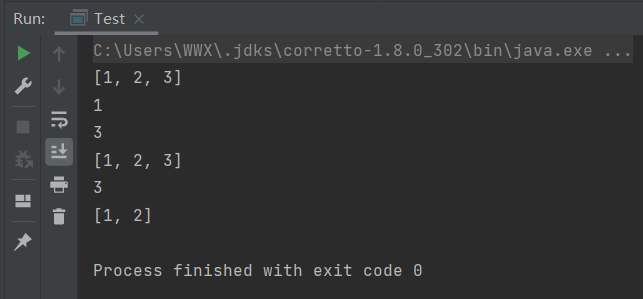
public class Test {
public static void main(String[] args) {
Stack stack = new Stack();
stack.push(1);//添加元素 [1]
stack.push(2);//添加元素 [1, 2]
stack.push(3);//添加元素 [1, 2, 3]
System.out.println(stack);//打印stack:[1, 2, 3]
System.out.println(stack.search(3));//返回元素3相对于栈顶的位置:1
System.out.println(stack.peek());//返回栈顶元素,但不删除:3
System.out.println(stack);//打印stack:[1, 2, 3]
System.out.println(stack.pop());//移除并返回堆栈的顶部元素。如果我们在调用堆栈为空时调用pop(),则抛出’EmptyStackException’异常。
System.out.println(stack);//打印stack:[1, 2]
}
}
1.1.4 LinkedList
LinkedList是List接口的另一个实现,除了可以根据索引访问集合元素外,LinkedList还实现了Deque接口,可以当作双端队列来使用,也就是说,既可以当作“栈”使用,又可以当作队列使用。
LinkedList的实现机制与ArrayList的实现机制完全不同,ArrayLiat内部以数组的形式保存集合的元素,所以随机访问集合元素有较好的性能;LinkedList内部以链表的形式保存集合中的元素,所以随机访问集合中的元素性能较差,但在插入删除元素时有较好的性能。
LinkedList的常用方法如下:
| 增
offer和add的区别: 一些队列有大小限制,因此如果想在一个满的队列中加入一个新项,多出的项就会被拒绝。 此时使用add方法会抛出IllegalStateException异常,而使用offer方法会返回false |
| 删
remove和poll的区别 在队列元素为空的情况下,remove方法会抛出NoSuchElementException异常,poll方法只会返回 null 。 |
| 改
|
| 查
get()和peek()的区别 在队列元素为空的情况下,get方法会抛出NoSuchElementException异常,peek方法只会返回 null 。 |
下图展示了LinkedList与其他List集合不一样的常用方法
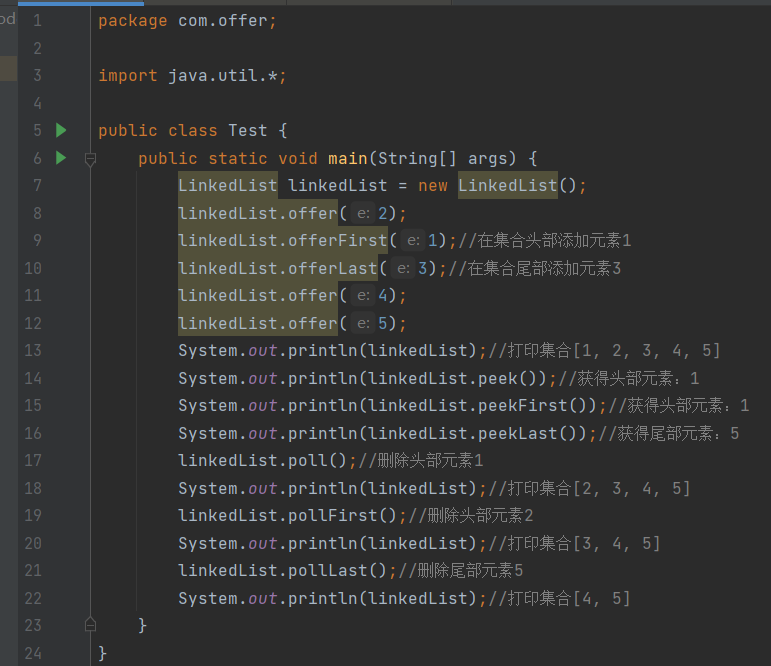
public class Test {
public static void main(String[] args) {
LinkedList linkedList = new LinkedList();
linkedList.offer(2);
linkedList.offerFirst(1);//在集合头部添加元素1
linkedList.offerLast(3);//在集合尾部添加元素3
linkedList.offer(4);
linkedList.offer(5);
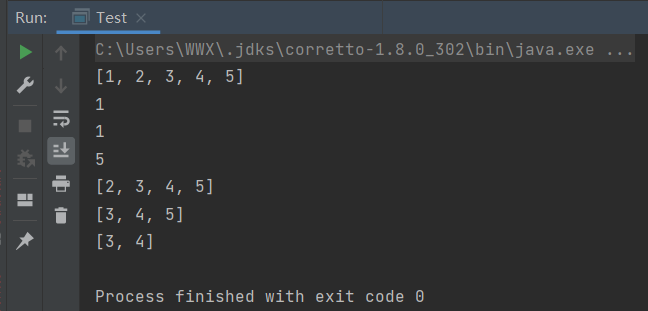
System.out.println(linkedList);//打印集合[1, 2, 3, 4, 5]
System.out.println(linkedList.peek());//获得头部元素:1
System.out.println(linkedList.peekFirst());//获得头部元素:1
System.out.println(linkedList.peekLast());//获得尾部元素:5
linkedList.poll();//删除头部元素1
System.out.println(linkedList);//打印集合[2, 3, 4, 5]
linkedList.pollFirst();//删除头部元素2
System.out.println(linkedList);//打印集合[3, 4, 5]
linkedList.pollLast();//删除尾部元素5
System.out.println(linkedList);//打印集合[4, 5]
}
}
1.2 Set
Set集合不允许存储相同的元素,所以如果把两个相同元素添加到同一个Set集合,则添加操作失败,新元素不会被加入,add()方法返回false。
Set常用类有HashSet、LinkedHashSet、TreeSet、EnumSet类。
1.2.1 HashSet
HashSet是Set集合最常用实现类,是其经典实现。HashSet是按照hash算法来存储元素的,因此具有很好的存取和查找性能。
HashSet具有如下特点:
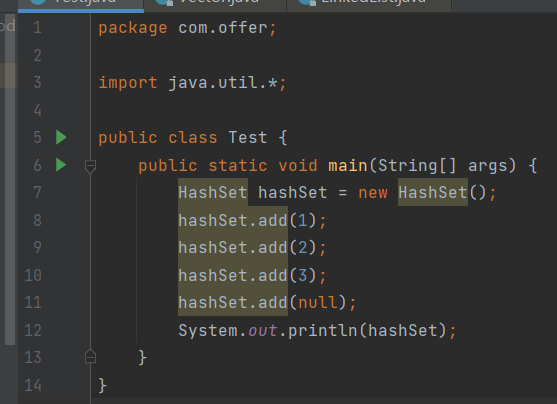
- 不能保证元素的顺序。见下图
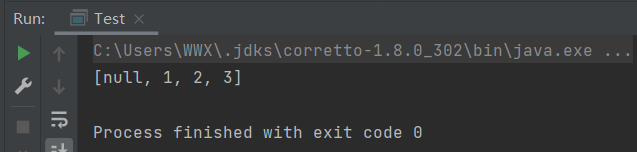
- HashSet不是线程同步的,如果多线程操作HashSet集合,则应通过代码来保证其同步。
- 集合元素值可以是null。
HashSet存储原理如下:
当向HashSet集合存储一个元素时,HashSet会调用该对象的hashCode()方法得到其hashCode值,然后根据hashCode值决定该对象的存储位置。HashSet集合判断两个元素相等的标准是(1)两个对象通过equals()方法比较返回true;(2)两个对象的hashCode()方法返回值相等。因此,如果(1)和(2)有一个不满足条件,则认为这两个对象不相等,可以添加成功。如果两个对象的hashCode()方法返回值相等,但是两个对象通过equals()方法比较返回false,HashSet会以链式结构将两个对象保存在同一位置,这将导致性能下降,因此在编码时应避免出现这种情况。
HashSet查找原理如下:
基于HashSet以上的存储原理,在查找元素时,HashSet先计算元素的HashCode值(也就是调用对象的hashCode方法的返回值),然后直接到hashCode值对应的位置去取出元素即可,这就是HashSet速度很快的原因。
重写hashCode()方法的基本原则如下:
- 在程序运行过程中,同一个对象的hashCode()方法返回值应相同。
- 当两个对象通过equals()方法比较返回true时,这两个对象的hashCode()方法返回值应该相等。
- 对象中用作equals()方法比较标准的实例变量,都应该用于计算hashCode值。
1.2.2 LinkedHashSet
LinkedHashSet是HashSet的一个子类,具有HashSet的特性,也是根据元素的hashCode值来决定元素的存储位置。但它使用链表维护元素的次序,元素的顺序与添加顺序一致。由于LinkedHashSet需要维护元素的插入顺序,因此性能略低于HashSet,但在迭代访问Set里的全部元素时由很好的性能。
1.2.3 TreeSet
TreeSet是SortedSet接口的实现类,不允许存放null,TreeSet可以保证元素处于排序状态,它采用红黑树的数据结构来存储集合元素。TreeSet支持两种排序方法:自然排序和定制排序,默认采用自然排序。
自然排序
TreeSet会调用集合元素的compareTo(Object obj)方法来比较元素的大小关系,然后将元素按照升序排列,这就是自然排序。如果试图将一个对象添加到TreeSet集合中,则该对象必须实现Comparable接口,否则会抛出异常。
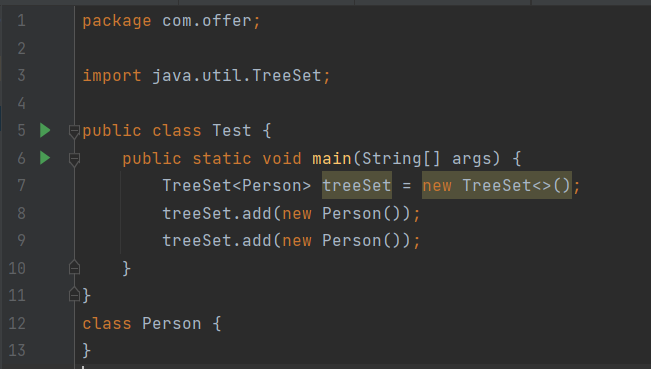

当一个对象调用方法与另一个对象比较时,例如obj1.compareTo(obj2),如果该方法返回0,则两个对象相等;如果返回一个正数,则obj1大于obj2;如果返回一个负数,则obj1小于obj2。
Java常用类中已经实现了Comparable接口的类有以下几个:
- BigDecimal、BigDecimal以及所有数值型对应的包装类:按照它们对应的数值大小进行比较。
- Character:按照字符的unicode值进行比较。
- Boolean:true对应的包装类实例大于false对应的包装类实例。
- String:按照字符串中的字符的unicode值进行比较。
- Date、Time:后面的时间、日期比前面的时间、日期大。
对于TreeSet集合而言,它判断两个对象是否相等的标准是:两个对象通过compareTo(Object obj)方法比较是否返回0,如果返回0则相等。
定制排序
想要实现定制排序,需要在创建TreeSet集合对象时,提供一个Comparator对象与该TreeSet集合关联,由Comparator对象负责集合元素的排序逻辑。
1.2.4 EnumSet
EnumSet 是一个专为枚举设计的集合类,EnumSet中的所有元素都必须是指定枚举类型的枚举值,该枚举类型在创建EnumSet时显式或隐式地指定。
- EnumSet的集合元素也是有序的,EnumSet以枚举值在Enum类内的定义顺序来决定集合元素的顺序。
- EnumSet在内部以位向量的形式存储,这种存储形式非常紧凑、高效,因此EnumSet对象占用内存很小,而且运行效率很好。尤其是进行批量操作(如调用containsAll()和retainAll()方法)时,如果其参数也是EnumSet集合,则该批量操作的执行速度也非常快。
- EnumSet集合不允许加入null元素,如果试图插入null元素,EnumSet将抛出NullPointerException异常。
- EnumSet类没有暴露任何构造器来创建该类的实例,程序应该通过它提供的类方法来创建EnumSet对象。
方法介绍:
- EnumSet allOf(Class elementType): 创建一个包含指定枚举类里所有枚举值的EnumSet集合。
- EnumSet complementOf(EnumSet e): 创建一个其元素类型与指定EnumSet里元素类型相同的EnumSet集合,新EnumSet集合包含原EnumSet集合所不包含的、此类枚举类剩下的枚举值(即新EnumSet集合和原EnumSet集合的集合元素加起来是该枚举类的所有枚举值)。
- EnumSet copyOf(Collection c): 使用一个普通集合来创建EnumSet集合。
- EnumSet copyOf(EnumSet e): 创建一个指定EnumSet具有相同元素类型、相同集合元素的EnumSet集合。
- EnumSet noneOf(Class elementType): 创建一个元素类型为指定枚举类型的空EnumSet。
- EnumSet of(E first,E…rest): 创建一个包含一个或多个枚举值的EnumSet集合,传入的多个枚举值必须属于同一个枚举类。
- EnumSet range(E from,E to): 创建一个包含从from枚举值到to枚举值范围内所有枚举值的EnumSet集合。
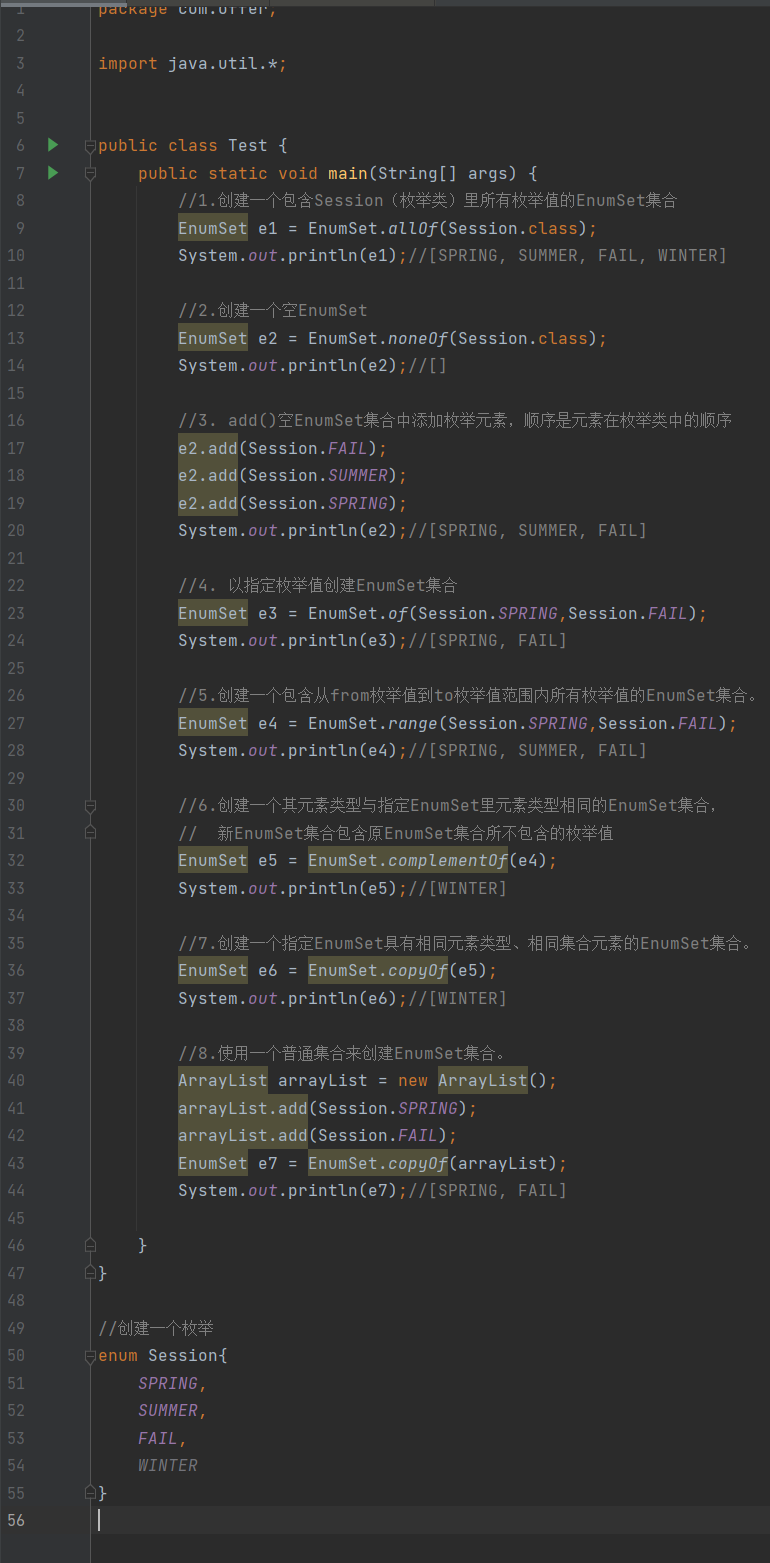
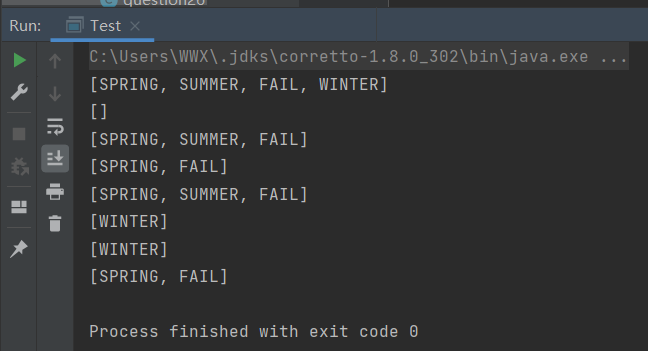
public class Test {
public static void main(String[] args) {
//1.创建一个包含Session(枚举类)里所有枚举值的EnumSet集合
EnumSet e1 = EnumSet.allOf(Session.class);
System.out.println(e1);//[SPRING, SUMMER, FAIL, WINTER]
//2.创建一个空EnumSet
EnumSet e2 = EnumSet.noneOf(Session.class);
System.out.println(e2);//[]
//3. add()空EnumSet集合中添加枚举元素,顺序是元素在枚举类中的顺序
e2.add(Session.FAIL);
e2.add(Session.SUMMER);
e2.add(Session.SPRING);
System.out.println(e2);//[SPRING, SUMMER, FAIL]
//4. 以指定枚举值创建EnumSet集合
EnumSet e3 = EnumSet.of(Session.SPRING,Session.FAIL);
System.out.println(e3);//[SPRING, FAIL]
//5.创建一个包含从from枚举值到to枚举值范围内所有枚举值的EnumSet集合。
EnumSet e4 = EnumSet.range(Session.SPRING,Session.FAIL);
System.out.println(e4);//[SPRING, SUMMER, FAIL]
//6.创建一个其元素类型与指定EnumSet里元素类型相同的EnumSet集合,
// 新EnumSet集合包含原EnumSet集合所不包含的枚举值
EnumSet e5 = EnumSet.complementOf(e4);
System.out.println(e5);//[WINTER]
//7.创建一个指定EnumSet具有相同元素类型、相同集合元素的EnumSet集合。
EnumSet e6 = EnumSet.copyOf(e5);
System.out.println(e6);//[WINTER]
//8.使用一个普通集合来创建EnumSet集合。
ArrayList arrayList = new ArrayList();
arrayList.add(Session.SPRING);
arrayList.add(Session.FAIL);
EnumSet e7 = EnumSet.copyOf(arrayList);
System.out.println(e7);//[SPRING, FAIL]
}
}
//创建一个枚举
enum Session{
SPRING,
SUMMER,
FAIL,
WINTER
}1.3 Queue
Queue队列是数据结构中比较重要的一种类型,它支持先进先出,尾部添加、头部删除(先进队列的元素先出队列),跟我们生活中的排队类似。Queue 一般用来存放等待处理的元素,这种场景一般用于缓冲、并发访问。Queue常用的方法如下
| 返回类型 | 方法名与描述 |
| boolean | add(E e) 将指定的元素插入到此队列中,如果不会违反容量限制立即执行此操作,并返回true。如果当前没有可用空间,则抛出IllegalStateException。 |
| E | element() 检索,但不删除,这个队列的头。如果没有元素,抛出NoSuchElementException异常 |
| boolean | offer(E e) 如果在不违反容量限制的情况下立即执行,将指定的元素插入到此队列中。 |
| E | peek() 检索但不删除此队列的头,如果此队列为空,则返回 null 。 |
| E | poll() 检索并删除此队列的头,如果此队列为空,则返回 null 。 |
| E | remove() 检索并删除此队列的头。如果没有元素可以删除,抛出NoSuchElementException异常 |
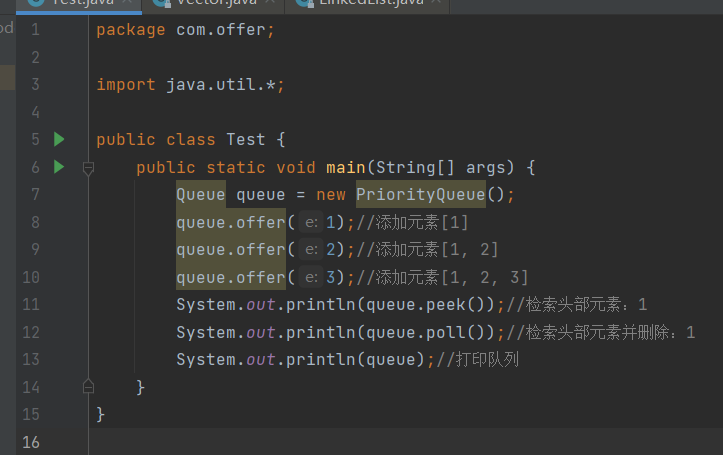
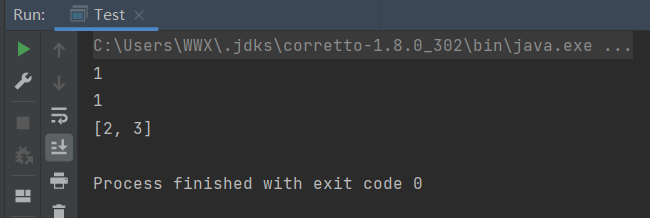
public class Test {
public static void main(String[] args) {
Queue queue = new PriorityQueue();
queue.offer(1);//添加元素[1]
queue.offer(2);//添加元素[1, 2]
queue.offer(3);//添加元素[1, 2, 3]
System.out.println(queue.peek());//检索头部元素:1
System.out.println(queue.poll());//检索头部元素并删除:1
System.out.println(queue);//打印队列
}
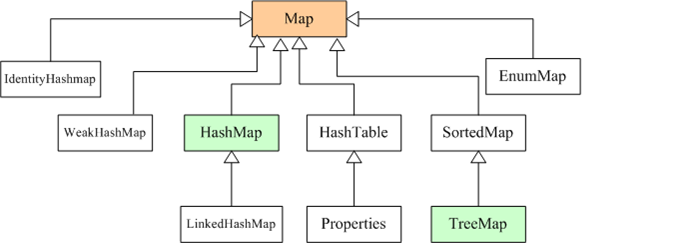
}2 Map
Map接口采用键值对Map<K,V>的存储方式,保存具有映射关系的数据,因此,Map集合里保存两组值,一组值用于保存Map里的key,另外一组值用于保存Map里的value,key和value可以是任意引用类型的数据。key值不允许重复,可以为null。如果添加key-value对时Map中已经有重复的key,则新添加的value会覆盖该key原来对应的value。常用实现类有HashMap、LinkedHashMap、TreeMap等。下表中是Map的所有方法。
| 返回类型 | 方法名与描述 |
| void | clear() 从该Map中删除所有的映射(可选操作)。 |
| default V | compute(K key, BiFunction<? super K,? super V,? extends V> remappingFunction) 对 hashMap 中指定 key 的值进行重新计算。如果 key 对应的 value 不存在,则返回该 null,如果存在,则返回通过 remappingFunction 重新计算后的值 |
| default V | computeIfAbsent(K key, Function<? super K,? extends V> mappingFunction) 对 hashMap 中指定 key 的值进行重新计算,如果不存在这个 key,则添加到 hashMap 中 |
| default V | computeIfPresent(K key, BiFunction<? super K,? super V,? extends V> remappingFunction) 对 hashMap 中指定 key 的值进行重新计算,前提是该 key 存在于 hashMap 中 |
| boolean | containsKey(Object key) 如果此Map包含指定键,则返回 true 。 |
| boolean | containsValue(Object value) 如果此Map拥有一个或多个指定的值,则返回 true 。 |
| Set<Map.Entry<K,V>> | entrySet() 返回此Map中包含的映射的Set视图。 |
| boolean | equals(Object o) 将指定的对象与此映射进行比较以获得相等性。 |
| default void | forEach(BiConsumer<? super K,? super V> action) 对此映射中的每个条目执行给定的操作,直到所有条目都被处理或操作引发异常。 |
| V | get(Object key) 返回到指定键所映射的值,或 null如果此映射包含该键的映射。 |
| default V | getOrDefault(Object key, V defaultValue) 返回 key 相映射的的 value,如果给定的 key 在映射关系中找不到,则返回指定的默认值。 |
| int | hashCode() 返回此Map的哈希码值。 |
| boolean | isEmpty() 如果此Map不包含键值映射,则返回 true 。 |
| Set<K> | keySet() 返回此Map中包含的键的Set视图。 |
| default V | merge(K key, V value, BiFunction<? super V,? super V,? extends V> remappingFunction) 如果指定的键尚未与值相关联或与null相关联,则将其与给定的非空值相关联。 |
| V | put(K key, V value) 将指定的值与该映射中的指定键相关联(可选操作)。 |
| void | putAll(Map<? extends K,? extends V> m) 将指定Map的所有映射复制到此映射(可选操作)。 |
| default V | putIfAbsent(K key, V value) 如果指定的键尚未与某个值相关联(或映射到 null )将其与给定值相关联并返回 null ,否则返回当前值。 |
| V | remove(Object key) 如果存在(从可选的操作),从该Map中删除一个键的映射。 |
| default boolean | remove(Object key, Object value) 仅当指定的键当前映射到指定的值时删除该条目。 |
| default V | replace(K key, V value) 只有当目标映射到某个值时,才能替换指定键的条目。 |
| default boolean | replace(K key, V oldValue, V newValue) 仅当当前映射到指定的值时,才能替换指定键的条目。 |
| default void | replaceAll(BiFunction<? super K,? super V,? extends V> function) 将每个条目的值替换为对该条目调用给定函数的结果,直到所有条目都被处理或该函数抛出异常。 |
| int | size() 返回此地图中键值映射的数量。 |
| Collection<V> | values() 返回此地图中包含的值的Collection视图。 |
下图通过HashMap展示Map集合常用的方法
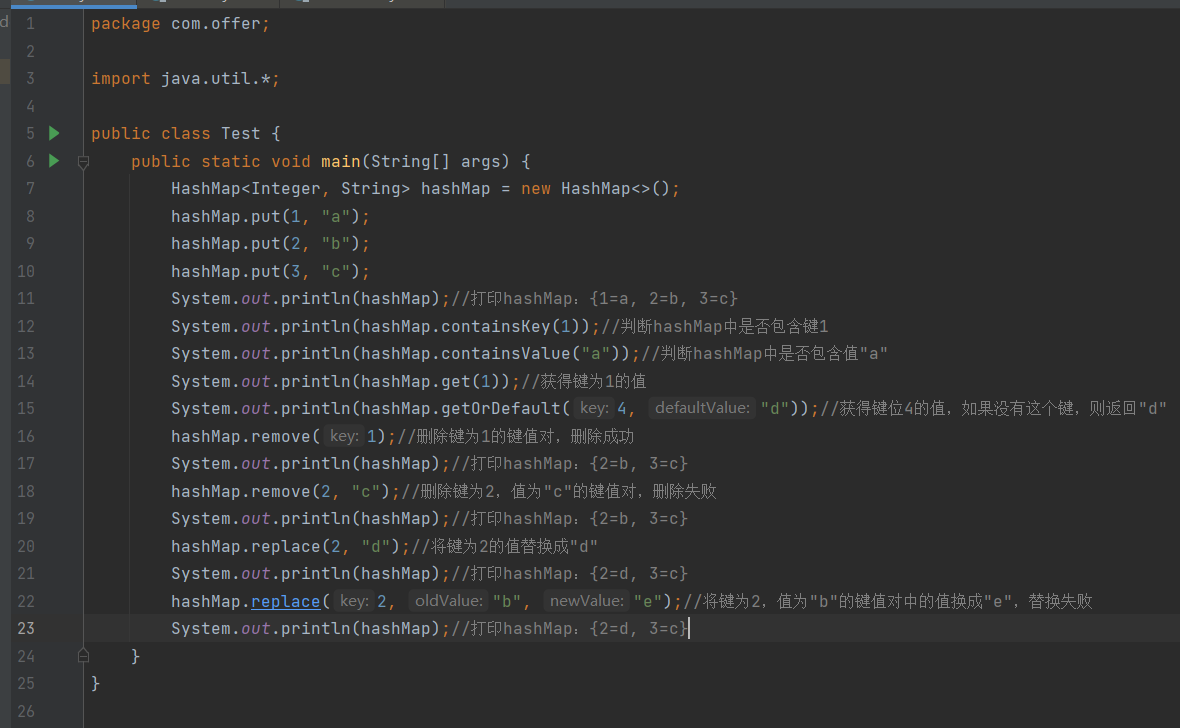
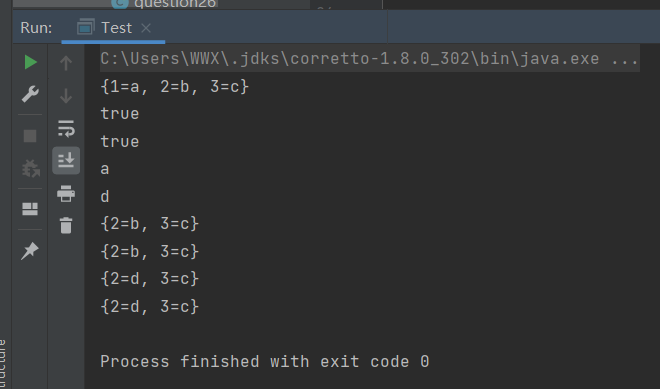
public class Test {
public static void main(String[] args) {
HashMap<Integer, String> hashMap = new HashMap<>();
hashMap.put(1, "a");
hashMap.put(2, "b");
hashMap.put(3, "c");
System.out.println(hashMap);//打印hashMap:{1=a, 2=b, 3=c}
System.out.println(hashMap.containsKey(1));//判断hashMap中是否包含键1
System.out.println(hashMap.containsValue("a"));//判断hashMap中是否包含值"a"
System.out.println(hashMap.get(1));//获得键为1的值
System.out.println(hashMap.getOrDefault(4, "d"));//获得键位4的值,如果没有这个键,则返回"d"
hashMap.remove(1);//删除键为1的键值对,删除成功
System.out.println(hashMap);//打印hashMap:{2=b, 3=c}
hashMap.remove(2, "c");//删除键为2,值为"c"的键值对,删除失败
System.out.println(hashMap);//打印hashMap:{2=b, 3=c}
hashMap.replace(2, "d");//将键为2的值替换成"d"
System.out.println(hashMap);//打印hashMap:{2=d, 3=c}
hashMap.replace(2, "b", "e");//将键为2,值为"b"的键值对中的值换成"e",替换失败
System.out.println(hashMap);//打印hashMap:{2=d, 3=c}
}
}2.1 HashMap与Hashtable
HashMap与Hashtable是Map接口的两个典型实现,它们之间的关系完全类似于ArrayList与Vertor。HashTable是一个古老的Map实现类,它提供的方法比较繁琐,目前基本不用了,HashMap与Hashtable主要存在以下两个典型区别:
- HashMap是线程不安全,HashTable是线程安全的。
- HashMap可以使用null值做为key或value;Hashtable不允许使用null值作为key和value,如果把null放进HashTable中,将会发生空指针异常。
为了成功的在HashMap和Hashtable中存储和获取对象,用作key的对象必须实现hashCode()方法和equals()方法。
HashMap工作原理如下:
HashMap基于hashing原理,通过put()和get()方法存储和获取对象。当我们将键值对传递给put()方法时,它调用建对象的hashCode()方法来计算hashCode值,然后找到bucket位置来储存值对象。当获取对象时,通过建对象的equals()方法找到正确的键值对,然后返回对象。HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会存储在链表的下一个节点中。
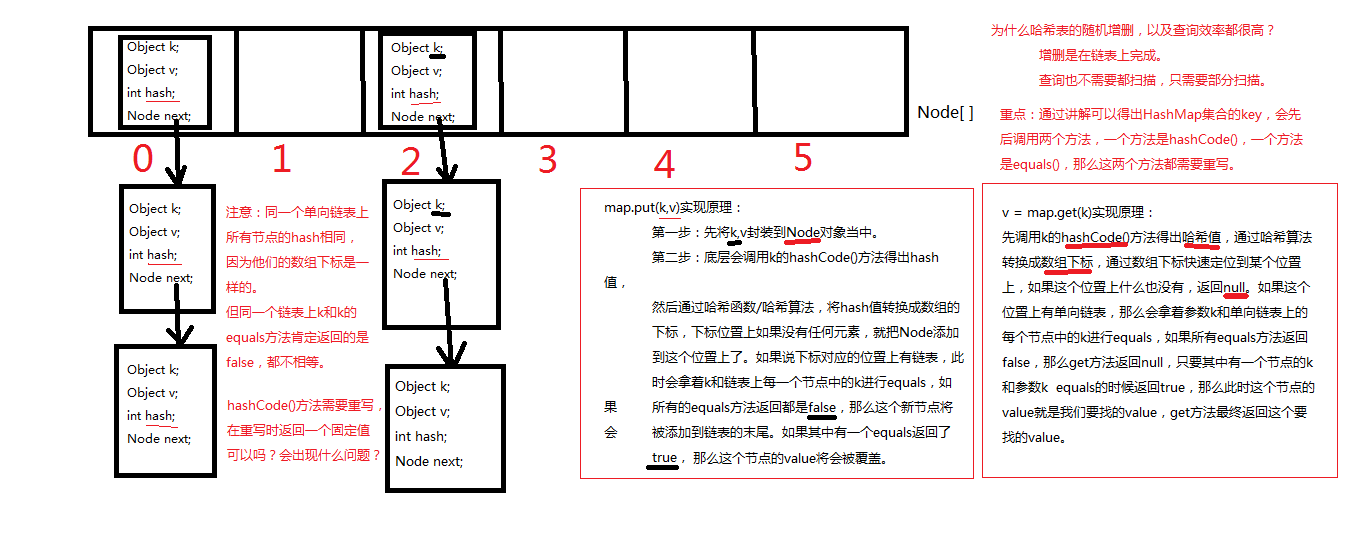
2.2 LinkedHashMap
LinkedHashMap使用双向链表来维护key-value对的次序(其实只需要考虑key的次序即可),该链表负责维护Map的迭代顺序,与插入顺序一致,因此性能比HashMap低,但在迭代访问Map里的全部元素时有较好的性能。
2.3 TreeMap
TreeMap是SortedMap的实现类,是一个红黑树的数据结构,每个key-value对作为红黑树的一个节点。TreeMap存储key-value对时,需要根据key对节点进行排序。TreeMap也有两种排序方式:
- 自然排序:TreeMap的所有key必须实现Comparable接口,而且所有的key应该是同一个类的对象,否则会抛出ClassCastException。
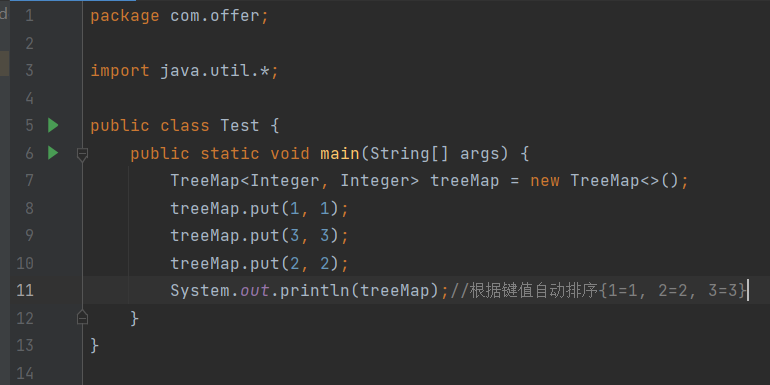
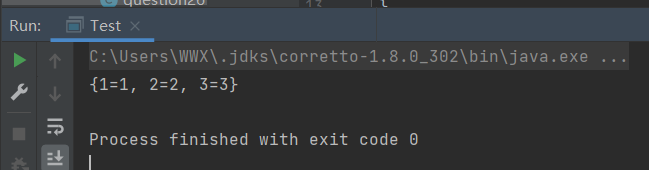
- 定制排序:创建TreeMap时,传入一个Comparator对象,该对象负责对TreeMap中的所有key进行排序。















 371
371











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









