









目录

1. 内连接
select * from table_name1 join table_name2 [on 条件] [where 表达式];select * from table_name1 inner join table_name2[on 条件][where 表达式];select * from table_name1 cross join table_name2[on 条件][where 表达式];select * from table_name1 , table_name2[where 条件];(on是过滤笛卡尔积中的无效数据)
内连接实现1:要求查询张三的成绩
步骤:1. 进行内连接查询(笛卡尔积) 2. 去掉无效的数据 3. 查询张三的成绩(where过滤条件)
1. 进行内连接查询(笛卡尔积):

2. 去掉无效的数据:

3. 查询张三的成绩(where过滤条件):

或者

不强制要求起别名,但是建议加上别名可以简化程序并且以免相同字段过多而报错。
内连接实现2:查询每个人成绩、科目名、个人信息
步骤:1. 连表查询(3张表)select * from t1 join t2 join t3; 2. 过滤无意义数据

2. 外连接
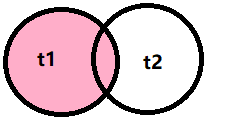
1. 左(外)连接
select * from t1 left join t2 [on 连接条件][where 条件查询];
(on是过滤笛卡尔积中的无效数据)
(t1是主表,t2是次表)
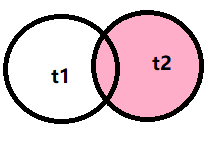
2. 右(外)连接
select * from t1 right join t2 [on 连接条件][where 条件查询];
(on是过滤笛卡尔积中的无效数据)
(t2是主表,t1是次表)
将右连接用左连接来实现:
select * from t2 left join t1 [on 连接条件][where查询条件];
(t2是主表,t1是次表)
联表查询中,on与where的区别:
1. 内连接on是可以省略的,而外连接on不能省略。
2. on在内连接中的执行效果和外连接中的执行效果是不一样的。
3. 在外连接中on和where是不一样的。


外连接中on不能过滤掉主表中的数据,而内连接on可以过滤掉全局数据。
外连接查询时,如果有多个查询条件,是将查询条件的表达式全部写在where表达式中,而非on中,在on中一般情况下只需要写一个笛卡尔积无效数据的过滤条件即可。
3. 自连接
自连接是指在同一张表上连接自身进行查询。
自连接实现:查询英语成绩小于计算机程序的数据(自己和自己进行连表查询)
步骤:1.先根据科目名称查询出科目id 2. 子查询(笛卡尔积) 3. 取出笛卡尔集中无效数据 4. 设置where条件,让表1只查询英语成绩,表2查询计算机程序 5. 设置where 多条件查询,让英语成绩大于计算机成绩

4. 子查询(嵌套查询)
子查询实现1:查询张三的同班同学
步骤:1. 查询张三的班级id 2. 学生表里面根据上一条查询的班级id查询出所有的列表,找出张三的同班同学

子查询实现2:查询计算机或英语成绩
步骤:1. 计算机或者英语的科目id 2. 查询成绩表where科目id等于计算机id或者是英语id
 in 和 = 的区别:
in 和 = 的区别:
= 查询需要一个具体确定的值
in 查询可以使一个或多个值,并且满足任意一个将返回true
![]()
5. 合并查询
union查询 id 小于 3 ,或者名字为 “ 英文 ” 的课程:select * from course where id< 3unionselect * from course where name= ' 英文 ' ;-- 或者使用 or 来实现select * from course where id< 3 or name= ' 英文 ' ;
union all查询 id 小于 3 ,或者名字为 “Java” 的课程select * from course where id< 3union allselect * from course where name= ' 英文';


union 和 union all 区别:
union会将合并的结果集中的重复数据去重,只保留重复数据中的一条,而union all 是即将结果集全部合并,即使有重复的数据结果也不会进行合并操作。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









