






1
1-1
当研究一个机器学习问题时,建议使用一个简单粗暴的算法(可能并不是很完美)去实现,一旦有了一个算法实现,然后看看这个算法造成的错误,通过误差分析来优化算法。
1-2偏斜类与误差度量(查准率和召回率)
偏斜类:在分类问题中,一个类别的样本数非常多,另一个非常少,类别的样本数很极端。
出现偏斜类的模型,使用查准率和召回率来判断模型性能。
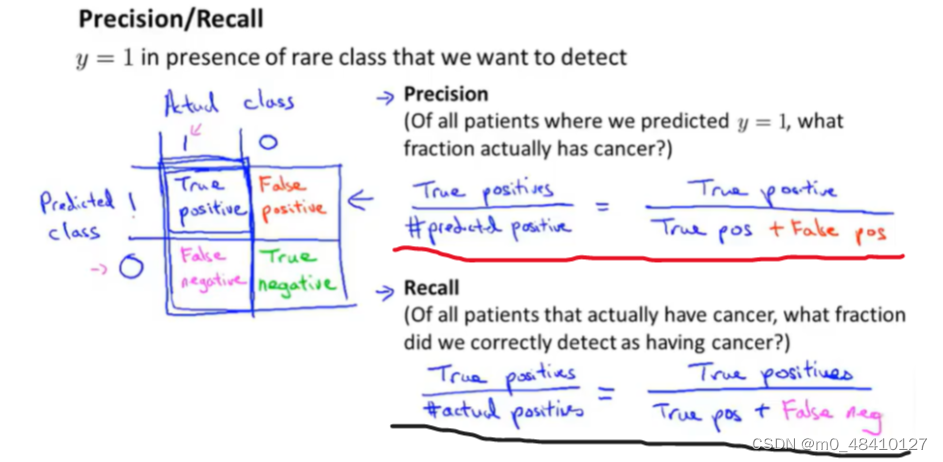 actual class是样本的实际类别,predictied class是用样本用模型预测的类别 。precision是查准率,recall是召回率。true positive(真阳性)=预测类别和实际类别都是阳性1。predicted postive=预测类别为阳性,actual positive=实际类别为阳性。
actual class是样本的实际类别,predictied class是用样本用模型预测的类别 。precision是查准率,recall是召回率。true positive(真阳性)=预测类别和实际类别都是阳性1。predicted postive=预测类别为阳性,actual positive=实际类别为阳性。
查准率是红线处的求法,召回率是黑线处的求法。

还是肿瘤的例子,一种情况:只有在非常确定的情况,才预测是恶性肿瘤(y=1),此时,可以设置临界值为0.7或0.9等等,该预测模型会获得高的查准率和低的召回率。另一种情况:不希望错过太多的恶性肿瘤的患者,避免把他们误诊为良性,这时,会把h(x)的临界值设为0.3等等,该预测模型会获得高的召回率,低的查准率。
查准率和召回率的关系如上图右边,可能图像不是很准确,但一定是一方增大,另一方就会减小。
一个可以权衡查准率和召回率的算法,我们认为它有好的性能。
 用F1分数来判断,P指的是查准率,R指的是召回率。F1分数越大,我们就认为这个算法更好,这里是算法1更好。
用F1分数来判断,P指的是查准率,R指的是召回率。F1分数越大,我们就认为这个算法更好,这里是算法1更好。
2.SVM算法
2-1 支持向量机(SVM)
是一种监督学习算法,按监督学习方式来二分类。
下面是的代价函数和假设函数,c是常量
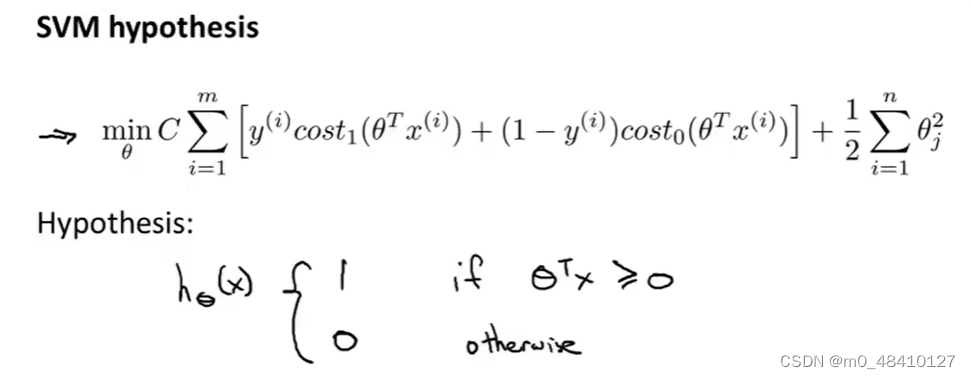
下图左边是cost1(z),右边是cost0(z)。cost1(z)的1指的是样本的y=1,cost0(z)中的0指的是样本的y=0。
根据上面的假设函数,y=1时,本来只需z=θTx >=0就可以使hθ(x)=1,但因为代价函数的设置,会使θTx>=1,这样不仅使hθ(x)=1,也使代价函数最小。同理,y=0时。
2-2线性分类
支持向量机有时又被叫做大间距分类器。

代价函数可以转换为红框中的表达式,s.t.是指这种表达时的限制条件。
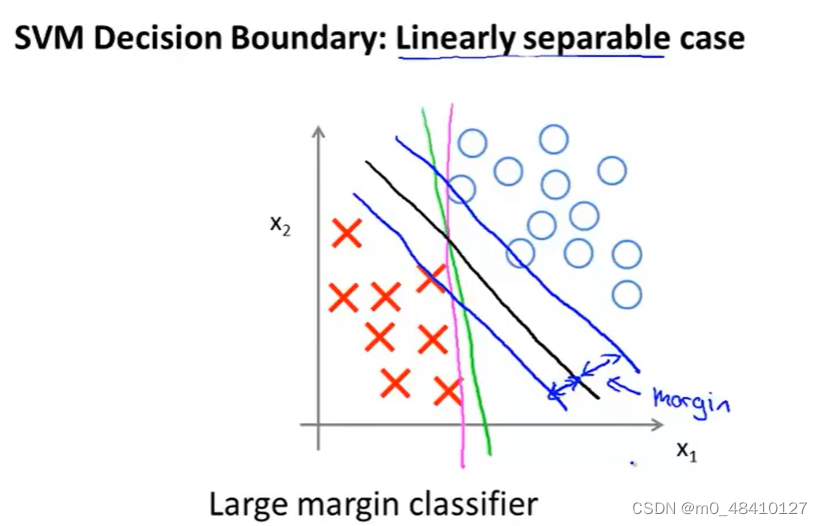 这种是可以线性划分的情况下,可以用红线、绿线和黑线都可以作为这个问题的决策边界,但黑线是SVM上张图优化的结果,比红线、绿线要好,可以更好地分开正负样本。因为这条黑色的决策边界到两条蓝线是决策边界到训练样本的距离,这个距离被叫做支持向量机的间距,可以看出黑色比红色、绿色离训练样本距离更远。这使得支持向量机具有鲁棒性。
这种是可以线性划分的情况下,可以用红线、绿线和黑线都可以作为这个问题的决策边界,但黑线是SVM上张图优化的结果,比红线、绿线要好,可以更好地分开正负样本。因为这条黑色的决策边界到两条蓝线是决策边界到训练样本的距离,这个距离被叫做支持向量机的间距,可以看出黑色比红色、绿色离训练样本距离更远。这使得支持向量机具有鲁棒性。
当c非常大时,决策边界会对异常点非常敏感(类似逻辑回归的过拟合?)。
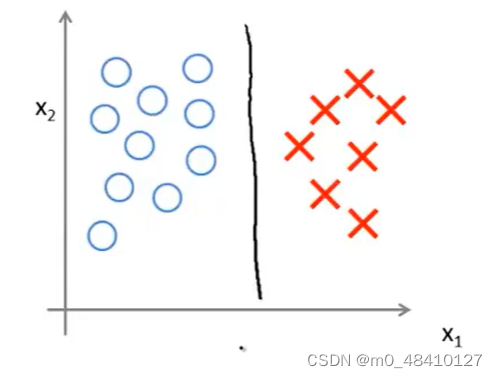
当c非常大且有异常点,决策边界会从黑线到红线,如果c不大且有异常点,那么还是黑线。
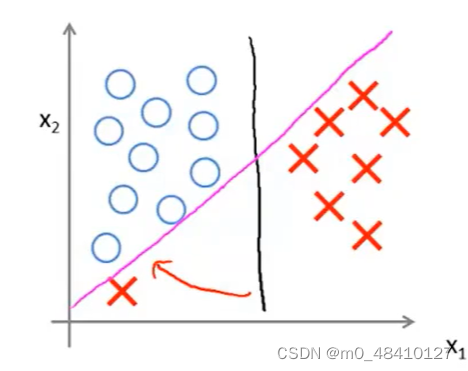
如果不能线性分开,正样本区域有些负样本,负样本区域有些正样本,SVM也能正确地进行分类。

上图是SVM会选择大间距分类器的原因。
2-3非线性分类
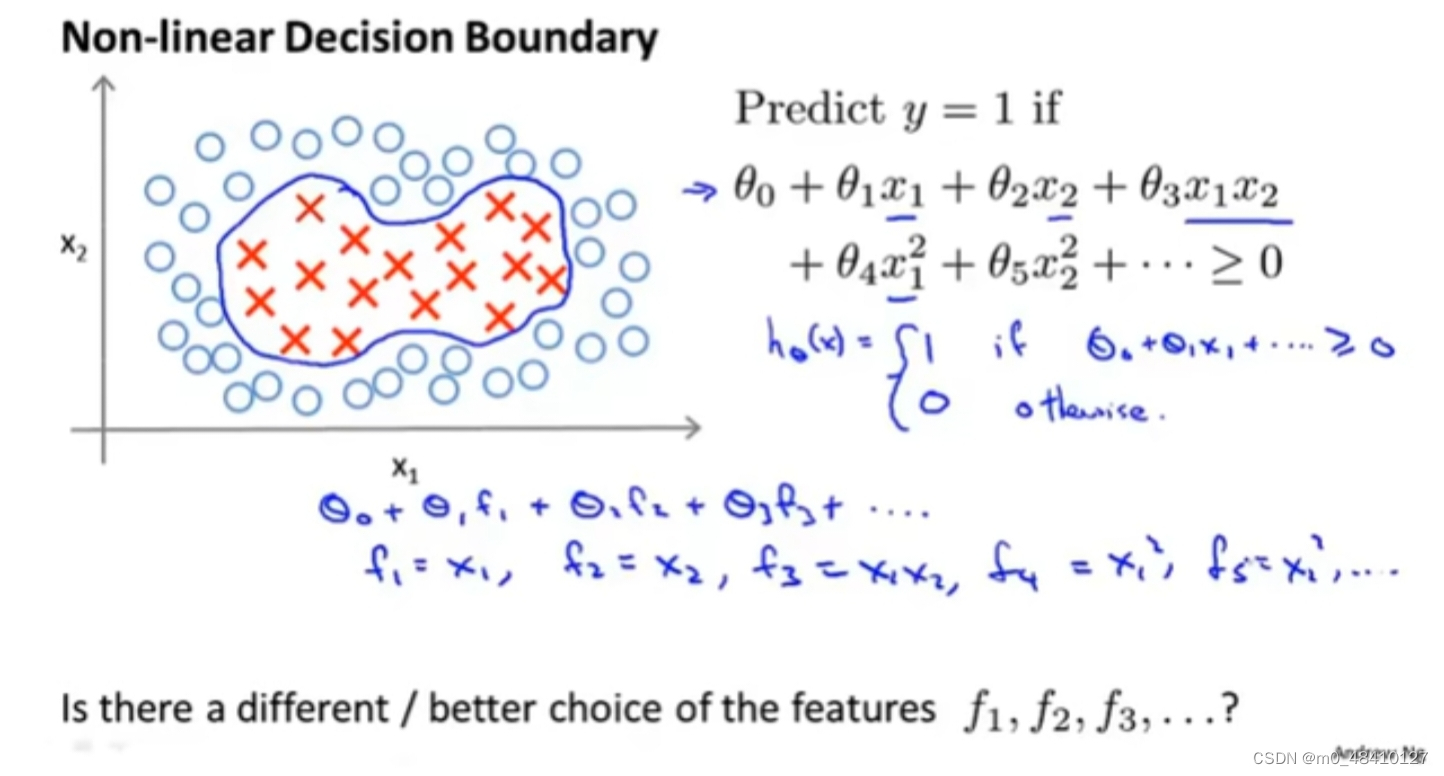
如上图,正负样本的决策边界非线性,上面hθ(x)是它的假设函数,当多项式....≥0预测y=1,但其实多项式中每一项是x1或者x2还是平方形式等等,这些具体形式对多项式...≥0并无影响,所以写成图中下方蓝字形式,f1,f2...

上图假设原本的特征是x1,x2。自己给出l(1),l(2),l(3)作为标记,把f1,f2,f3作为新的特征,将f1,f2,f3定义为相似度的度量。exp函数是eˣ函数,‖x‖表示向量x的长度,也就是向量模。σ是常数,这里f1,f2,f3的表达式都是核函数的形式,是高斯核函数。

这里说明样本x≈l(1),也就是x离l(1)距离很近很近时,f1≈1。反之f1≈0。当给出l(i)和样本x就能求出f1 。
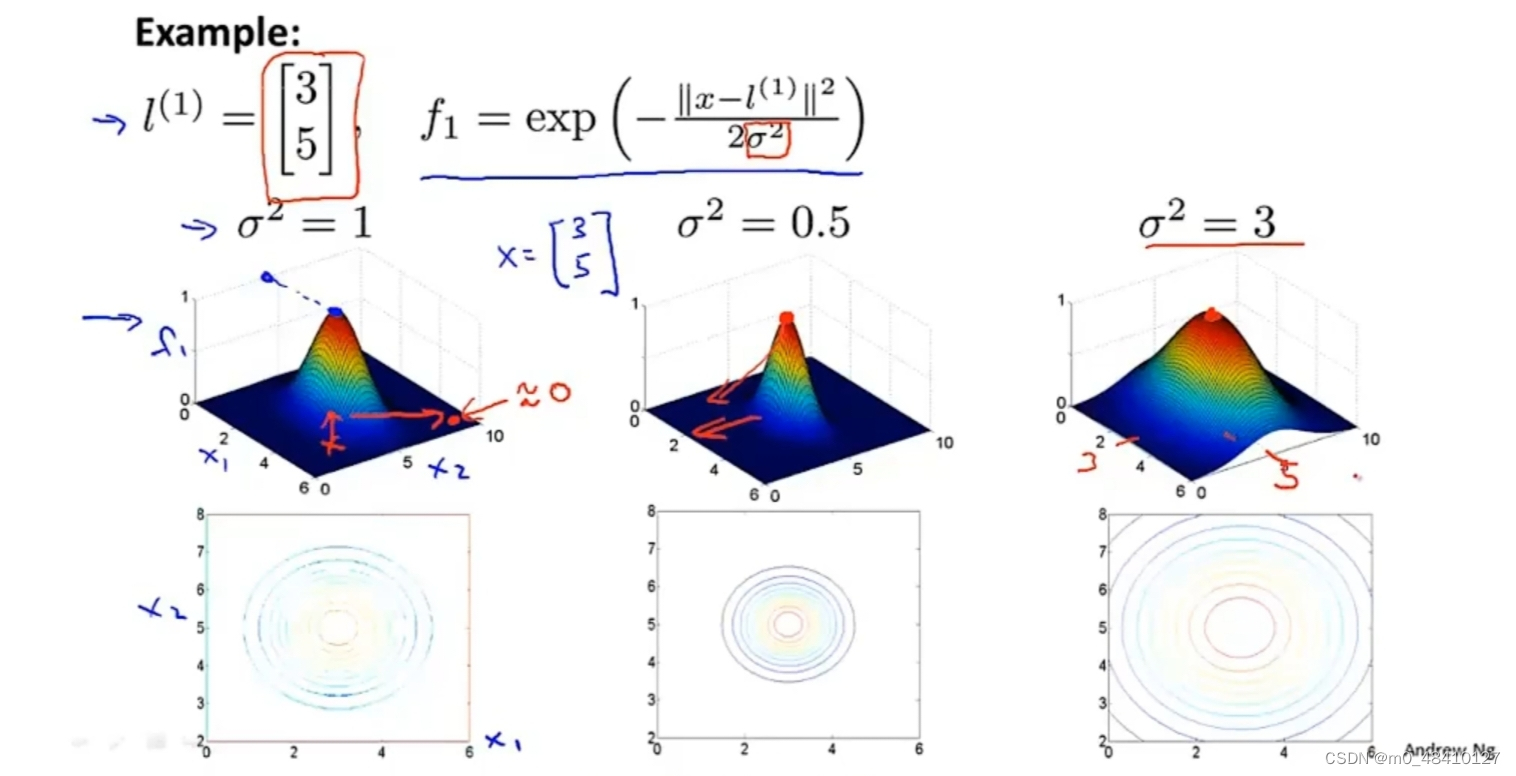
这里假设l(i) =[3,5]T,列举了σ²=1,2,3时,f1函数的图像有三个轴,竖着的是f1轴,下面两个轴,分别是x1和x2。当x=l(1)=(3,5),f1可取最大值1,当x越偏离l(1)时,f1越小。最下面三张图是等高线图。

这里l(i)已知,θ也已知。这里取离l(1)近的红色点,则f1≈0,f2≈0,f3≈0,多项式...≈0.5≥0,则预测结果为1。如果取偏远的蓝色点,代入可知,多项式≈-0.5<0,则预测结果为0。
因为上图中θ3=0,所以θ3f3=0,所以多项式...的值只与f1,f2有关,又因为θ0,θ1,θ2的取值,所以离l(1)或l(2)近,多项式取值就会>0,样本的预测就会为1,就是正样本。所以决策边界如下图。

关于标记l(i)的取值,直接将训练样本作为标记点。
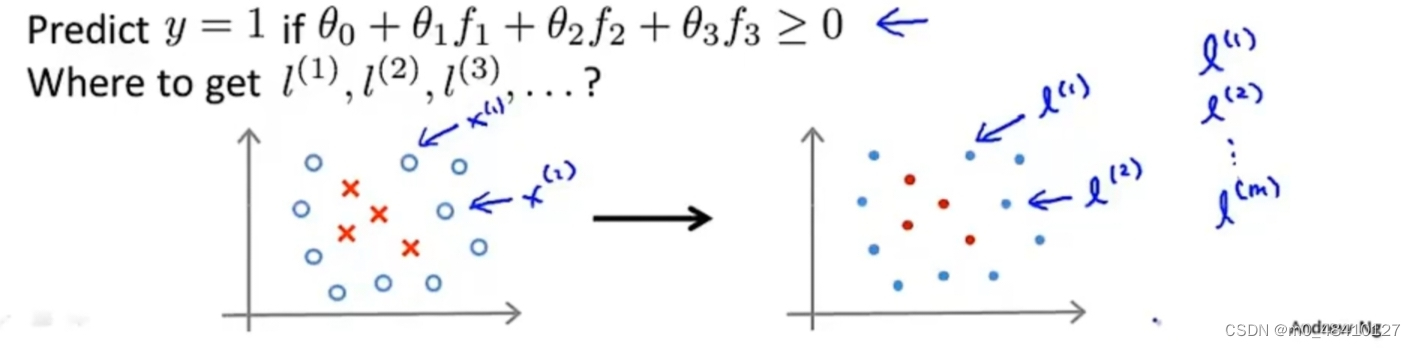

如上图,当给出训练样本求出fj(i)。x(i)是n维向量,n是原本的特征的项数,x(i)是某个训练样本对应的一系列特征的取值。注意,fi(i)的值为1。这一步是为了代入代价函数求θ的取值
当给出样本x可以代入求出f,注意f0=1。

由前文可知,θᵀx(i)已被换为θᵀf(i)。f(i)由上张图求得。要是代价函数最小化,前面的项=0,代价函数可转换为
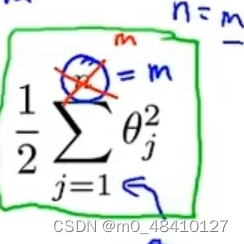
其中n=m,1/2也可以省略。

c的作用与1/λ类似,λ是逻辑回归中的正则化参数。如果c过大和逻辑回归中λ过小的效果一样,会造成低偏差,高方差,过拟合。其它如图。
还有σ²过大过小在前面也说过,过大会高偏差,低方差,fi曲线平缓;过小会低偏差,高方差,fi曲线陡峭。
2-4使用SVM
3k-means
3-1 无监督学习
对比监督学习,它的数据没有标签,没有对应结果。
所以把聚集在一起的点分成簇,这样样本就会分成若干簇,叫作聚类算法,是一种无监督学习算法。
3-2 k-means算法
把无标签的数据集自动地分成有紧密关系的子集或簇,k-means算法是运用最广泛的聚类算法。
k-means:
1.要分成若干类,先随机选择若干个聚类中心点
2.簇分配:样本点选择离它进的聚类中心点,归为该类。
3.移动聚类中心:上一步已经粗略分类,对每个类分别算出目前该类的均值点,该点作为新的聚类中心。
然后重复第2、3步,直到聚类中心不会再改变。


c(i)的值表示特征为x(i)的样本选择得簇是哪个,c(i)∈{1,2,...,K}
K是类别数目,μk是聚类中心,其中k∈{1,2,...,K}。
3-3k-means目标优化(代价函数)

μc(i)是样本x(i)所属类的聚类中心。
上图的下面部分就是代价函数,目标就是要使样本离该样本所属类的聚类中心近。

这里重新看k-means算法的过程,这个算法过程就是在最小化代价函数。其中的簇分配是在通过改变代价函数的变量c(i)来最小化代价函数的值,移动聚类中心是在通过改变代价函数的变量μk来最小化代价函数的值。
3-4k-means的的随机初始化
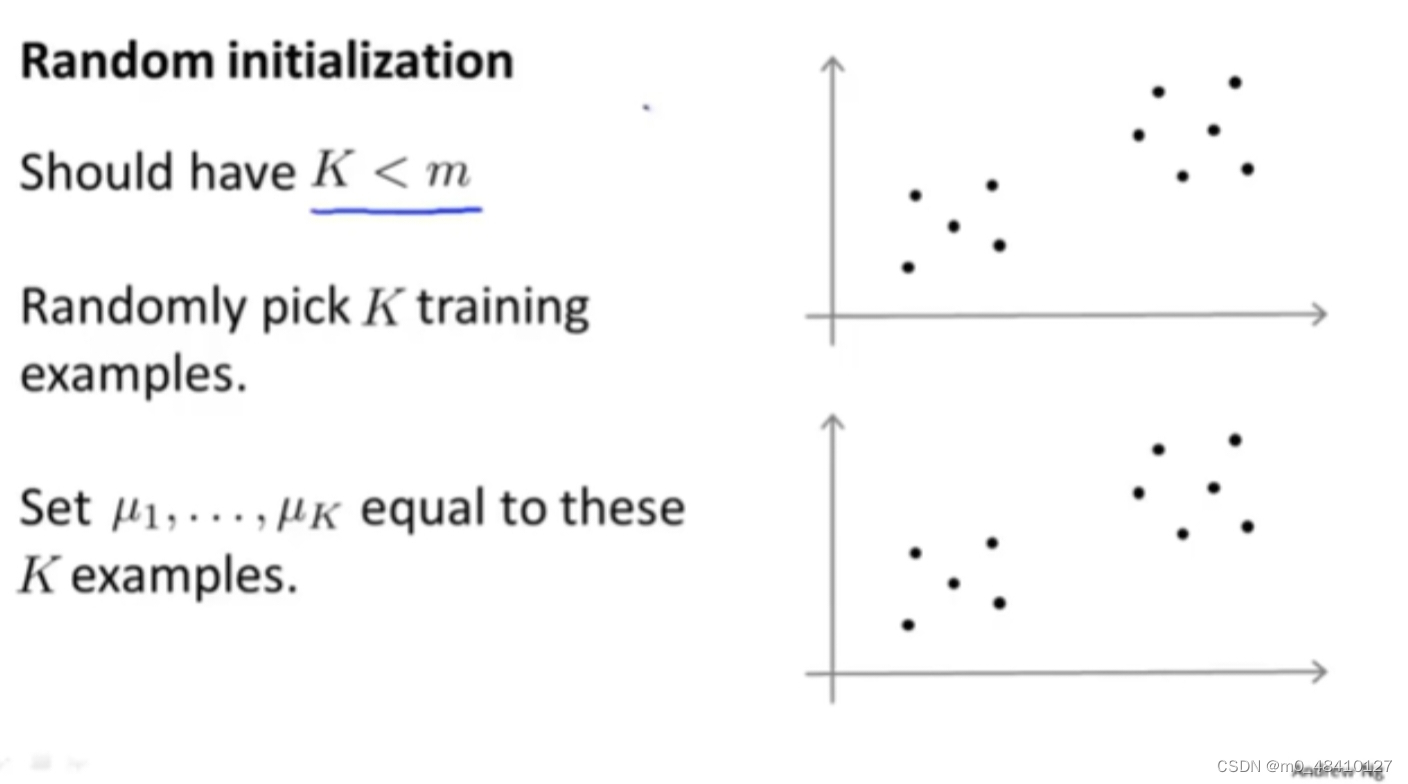
m是样本(训练集)的数量。应该使类别的数目K<m。从训练集中随机选择K个样本,把这K个样本作为最开始的聚类中心。这就是随机初始化的过程。
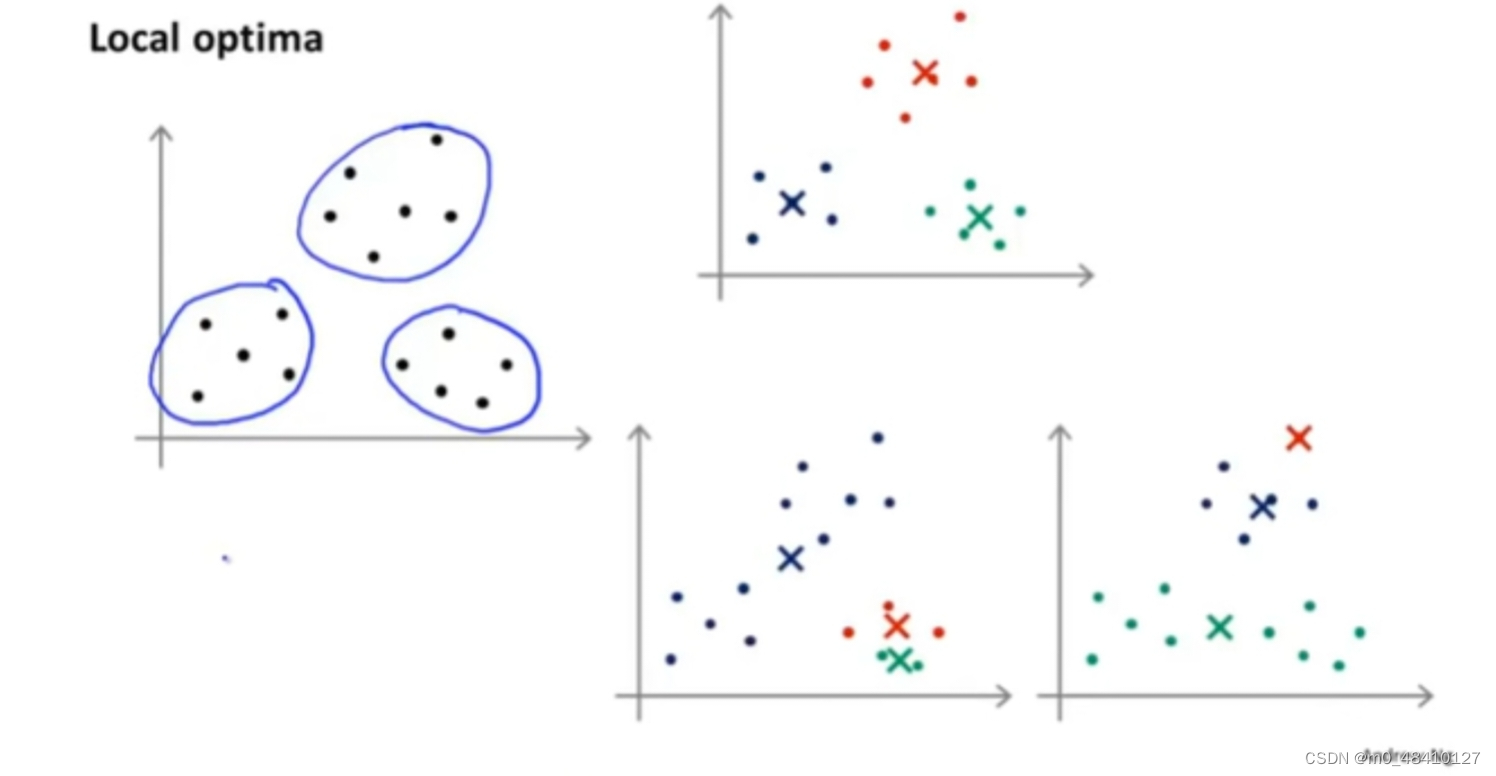
但是随机选择K个样本有很多的不同的方案,不同的K个样本会导致不同的分类结果,如上图,下面两种聚类结果不如上面的那种聚类结果,下面的聚类结果是局部最优,上面的聚类结果是全局最优。我们希望得到上面的聚类结果而不是下面的。所以通过多次随机化来得到全局最优的聚类结果。

通过多次随机初始化,对每种初始化分别执行k-means 算法,再分别计算代价函数的值,选择代价函数最小的值对应的分类结果作为最终结果。
3-5K的选择
要选择把训练集分成多少个类。
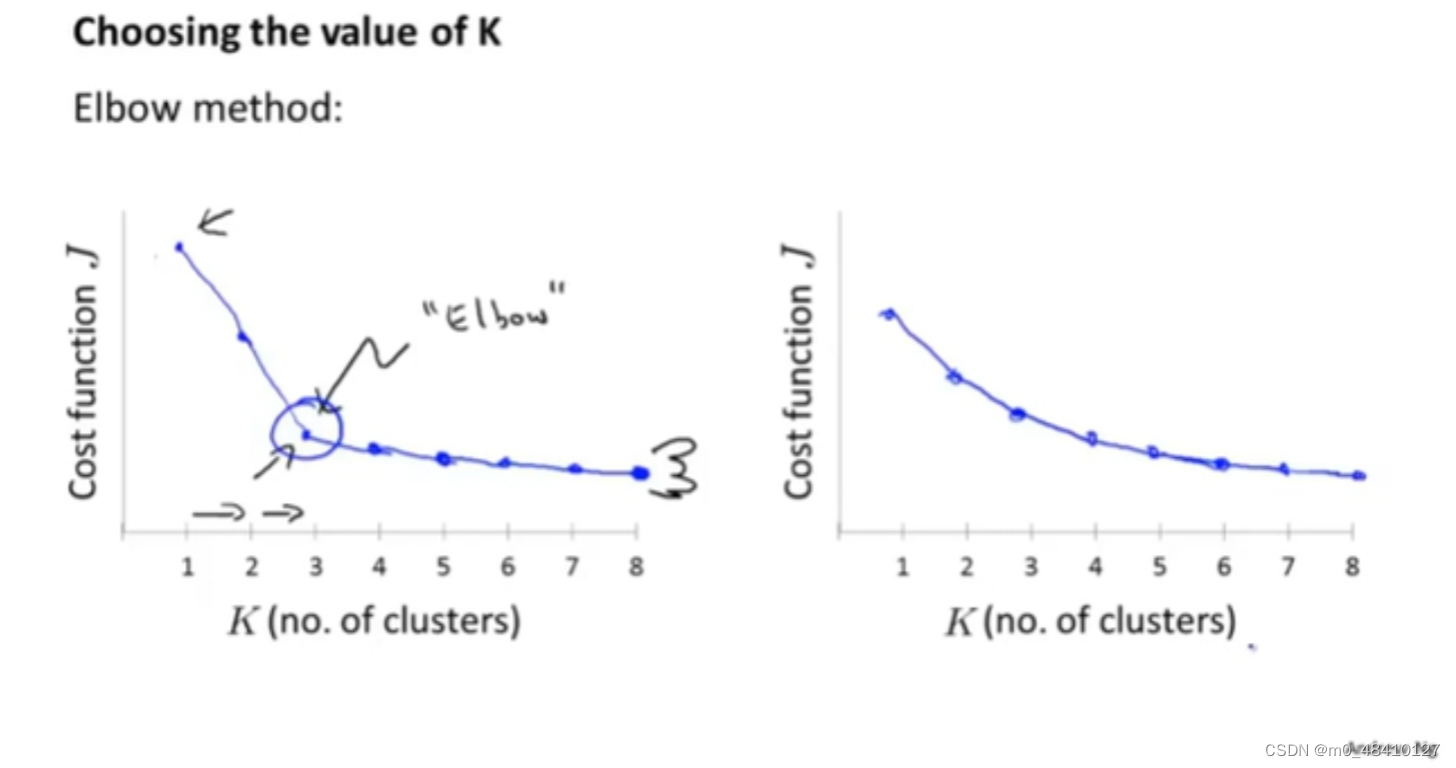
第一种方法,肘部法则。
K和代价函数的值有如下图所示的关系,如果是右图的情况,选择拐点处对应的K值作为最终的K值。但实际,往往会呈现右边所示的关系,没有明显的肘部,这时,肘部法则不适用。
第二种方法,根据需要。(更常见)
比如衣服厂商给衣服定型号,可以分为三种:s,m,l。也可以分为五种:xs,s,m,l,xl。到底分为几种,根据需要。
4.主成分分析法pca
4-1降维
降维的第一个应用:数据压缩,减小内存需求。
 如上图,从2d降到1d,从原来的两个特征x1和x2降到一个特征z1,只需要一个数就可以确定z1所在的位置,完成对样本的描述。原来的特征是一个二维向量,现在是一个实数。如上图,通过降维把数据的内存需求减半。
如上图,从2d降到1d,从原来的两个特征x1和x2降到一个特征z1,只需要一个数就可以确定z1所在的位置,完成对样本的描述。原来的特征是一个二维向量,现在是一个实数。如上图,通过降维把数据的内存需求减半。
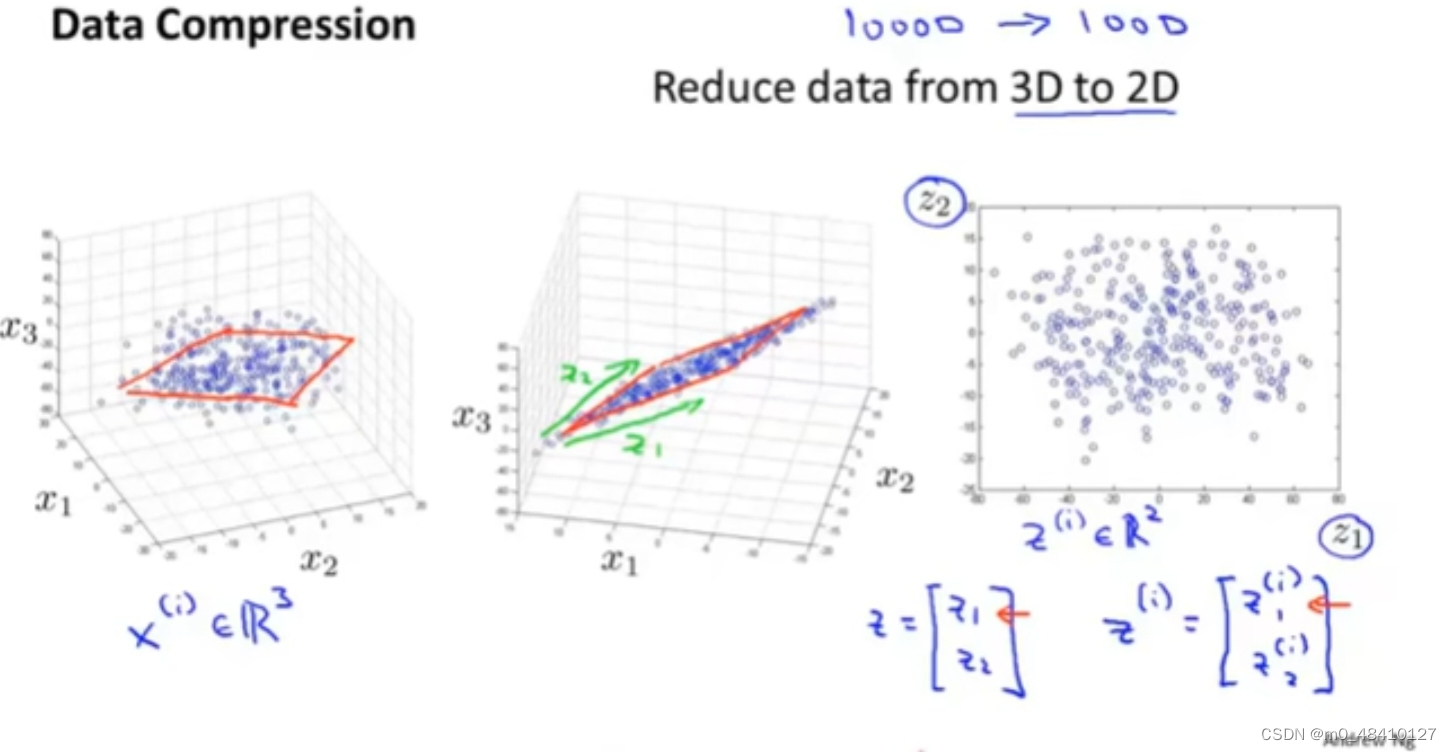
上图从3d降到2d,从一个三维向量降到二维向量。
降维的第二个应用:可视化数据。
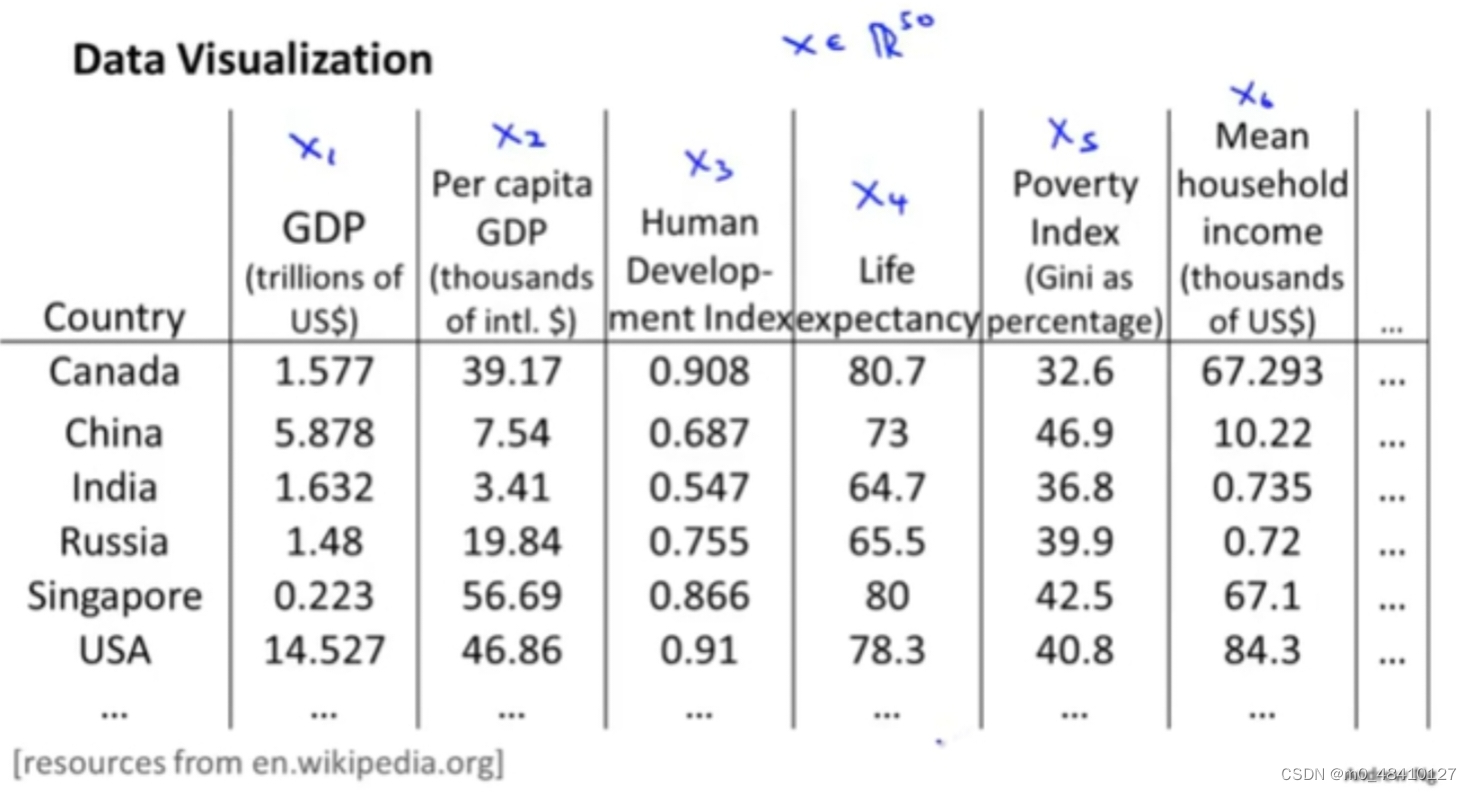
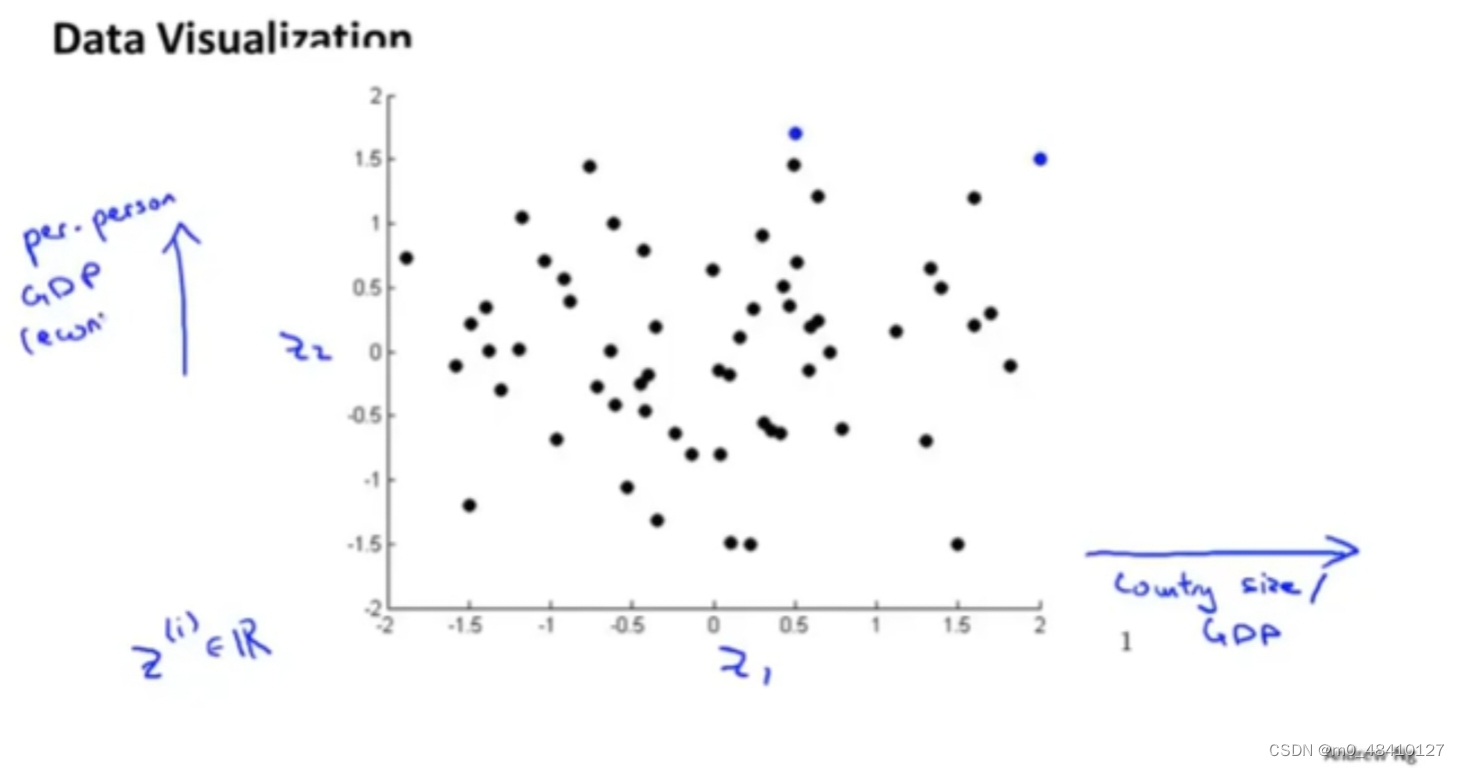
上图假如有50个特征,但是绘制一个有50维的数据是很难的。但是把数据降到2维,其中一维是个人gdp,另一维是国家gdp。那么可视化数据就变得简单。
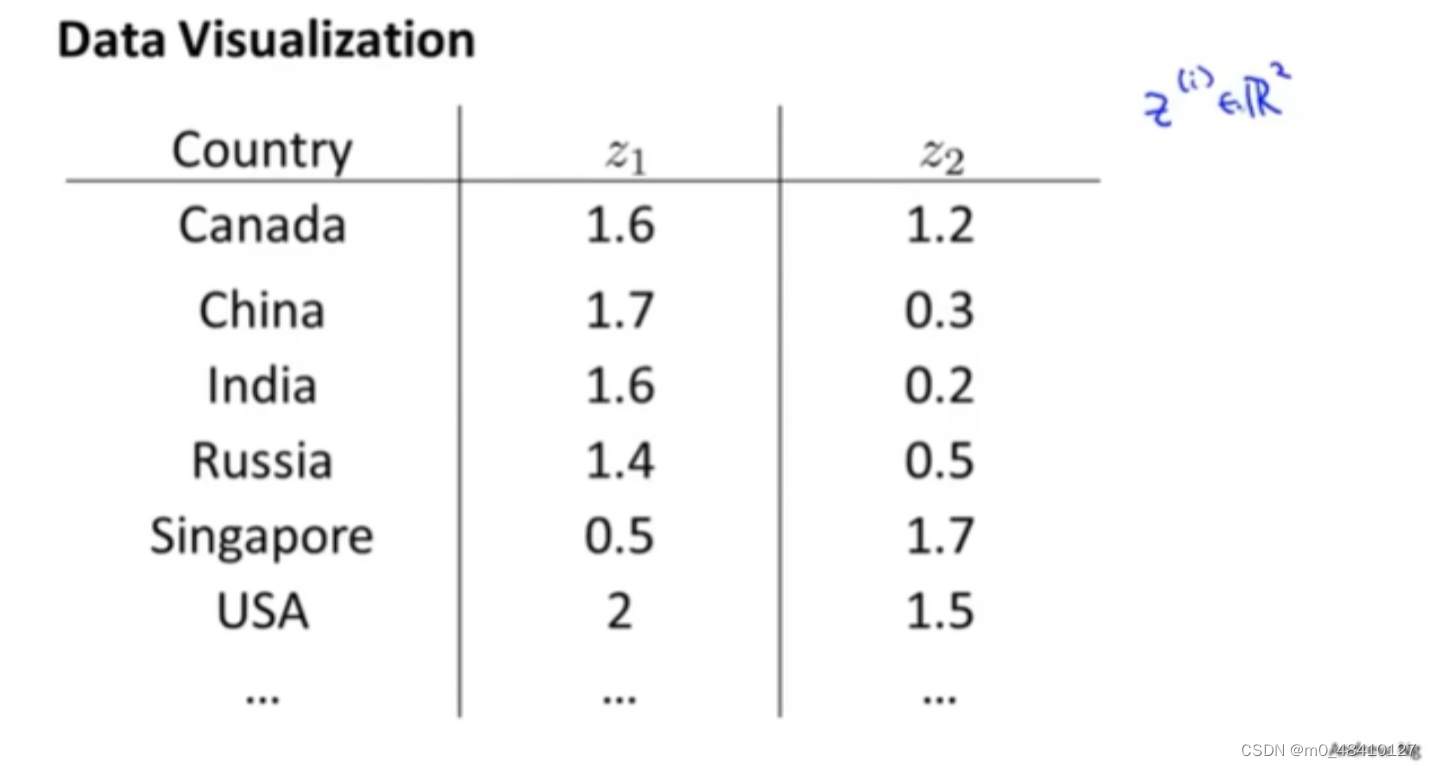
假如想把下面的数据降维,也就是想找到一条能够将数据投影到上面的直线。
如下图,能找到很多数据可以投影到上面的直线,要从这么多直线中选择最好的 。蓝线画出了数据到投影直线的距离,就是投影误差。pca要做的就是会寻找一个能最小化数据到投影空间的距离的投影空间,也就是最小化总的投影误差。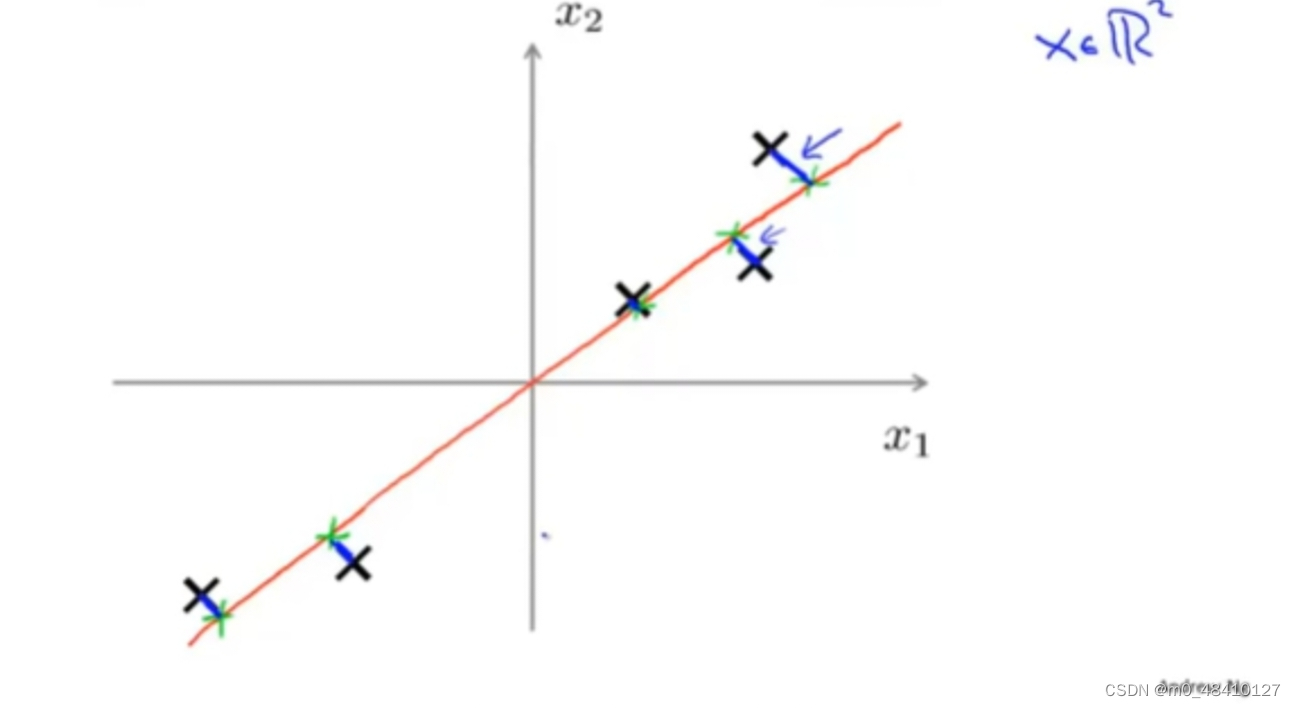
在pca之前会进行均值归一化和特征规范化使得特征量x1,x2,...,xi的均值为0。
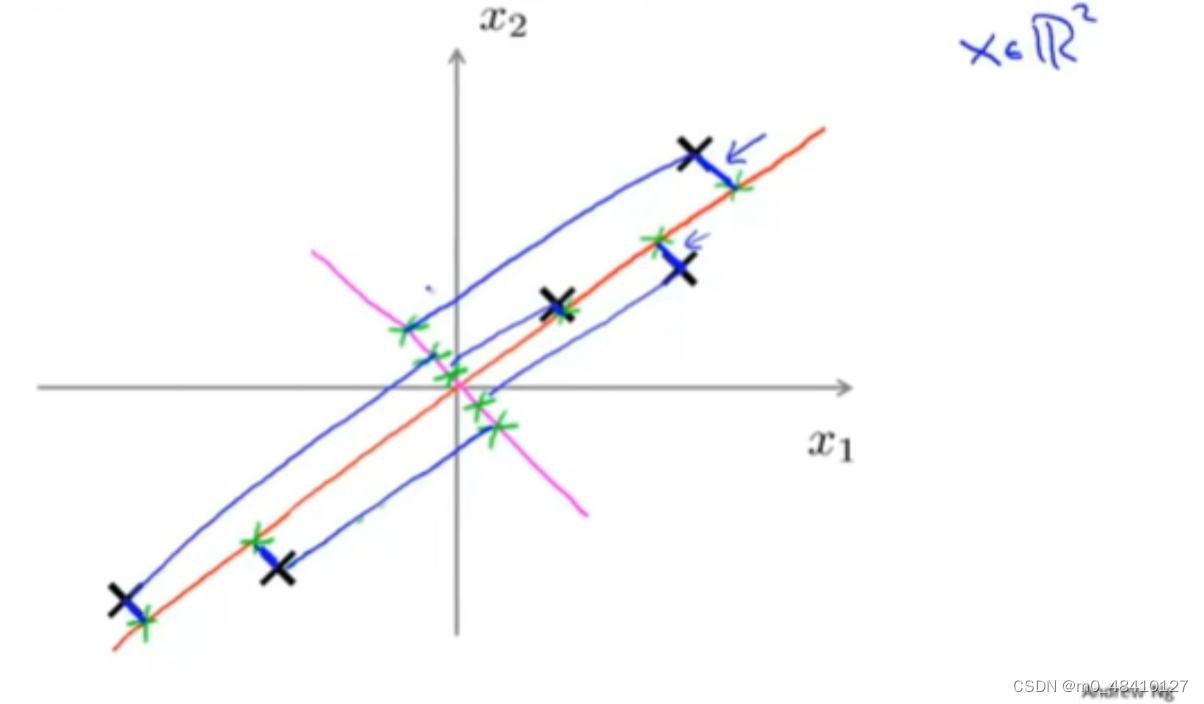
如上图两条投影直线,pca会选择橙色的线,而不是红色的线。
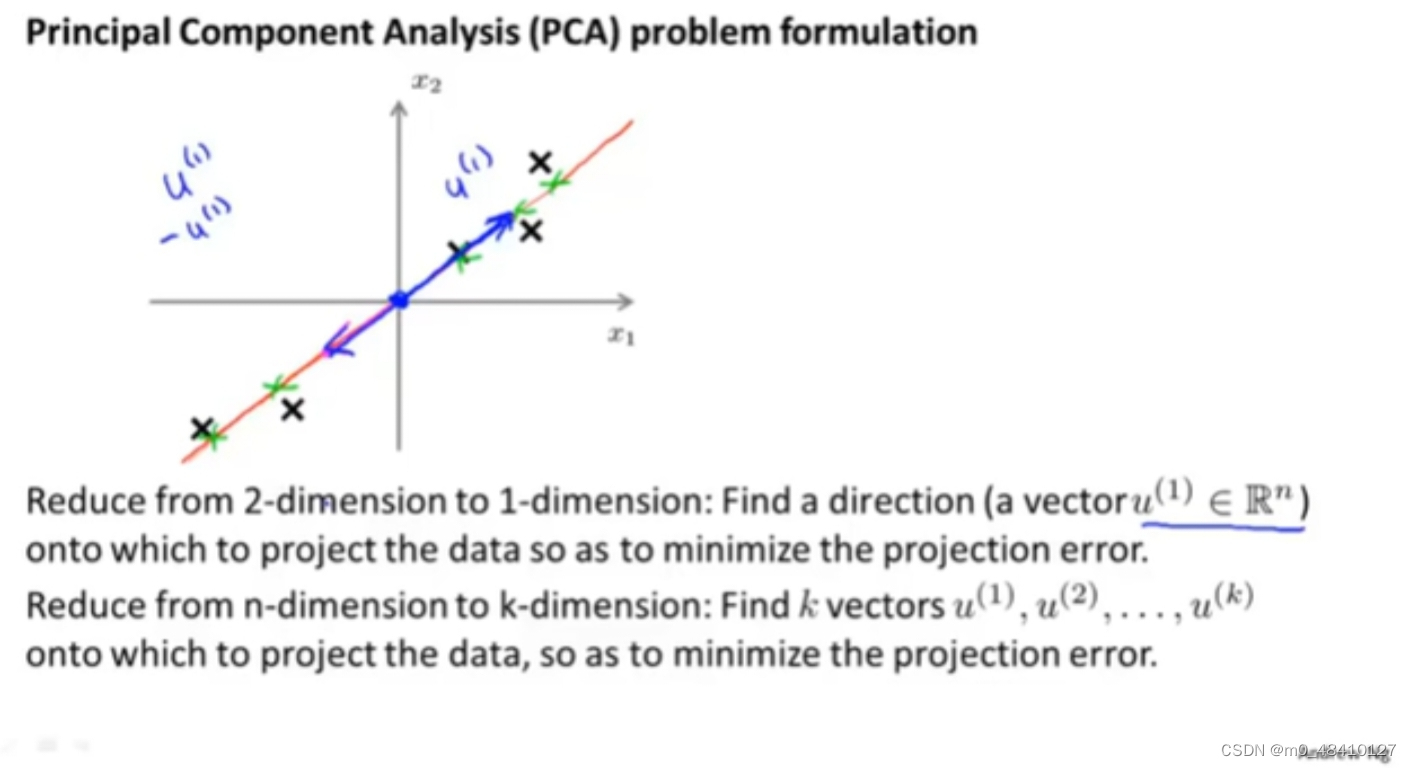 从二维降到一维,我们会选择一个向量来最小化投影误差,从n维降到k维,会选择k个向量来最小化投影误差。
从二维降到一维,我们会选择一个向量来最小化投影误差,从n维降到k维,会选择k个向量来最小化投影误差。
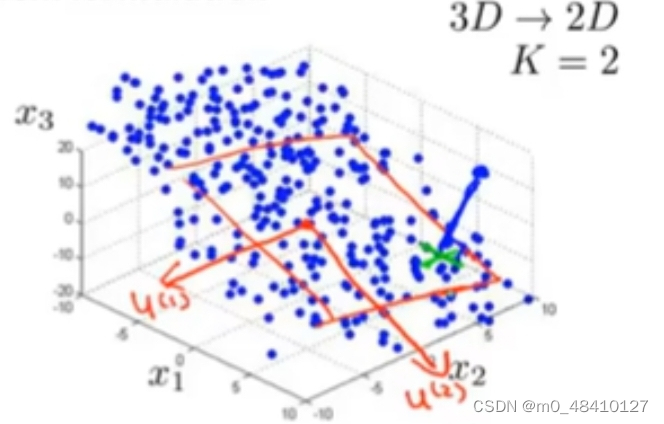
上图选择了两个向量u(1),u(2)。投影误差就是原来的数据点到对应的投影平面上投影点的距离和。pca是要找到一个线,投影平面或其他维的空间来最小化投影误差。
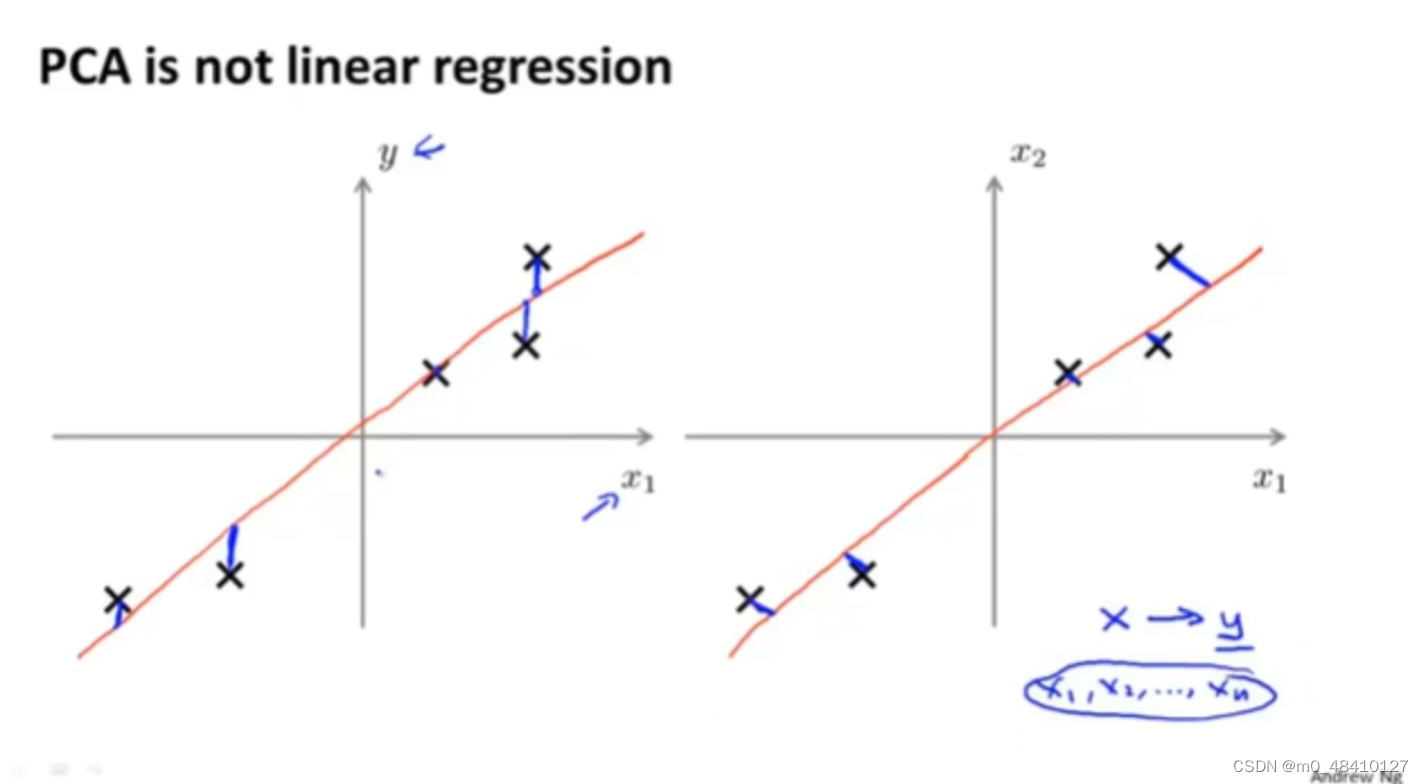
pca不是线性回归,两个是不同的概念。pca的y轴是预测值y,它的误差是平行于y轴的蓝线,是预测值与实际值之间的误差,pca的y轴是一个特征,它的误差是垂直于投影直线的蓝线。
4-2pca算法过程
4-2-1数据预处理

首先,对数据预处理:均值归一化和特征规范化。
计算每个样本在原来的特征xj上的均值μj。如果不同特征的值相差很大,比如房子面积大概是100m²,但是房子数量是1000000。100和1000000差距很大,再用特征规范化,类似于特征缩放。
上图下面的蓝字就完成了对数据的预处理。

4-2-2 基本算法

数据预处理后,计算协方差∑,n是原来的特征数n维,m是样本数。然后用svd进行奇异值分解svd(∑),得到U矩阵。
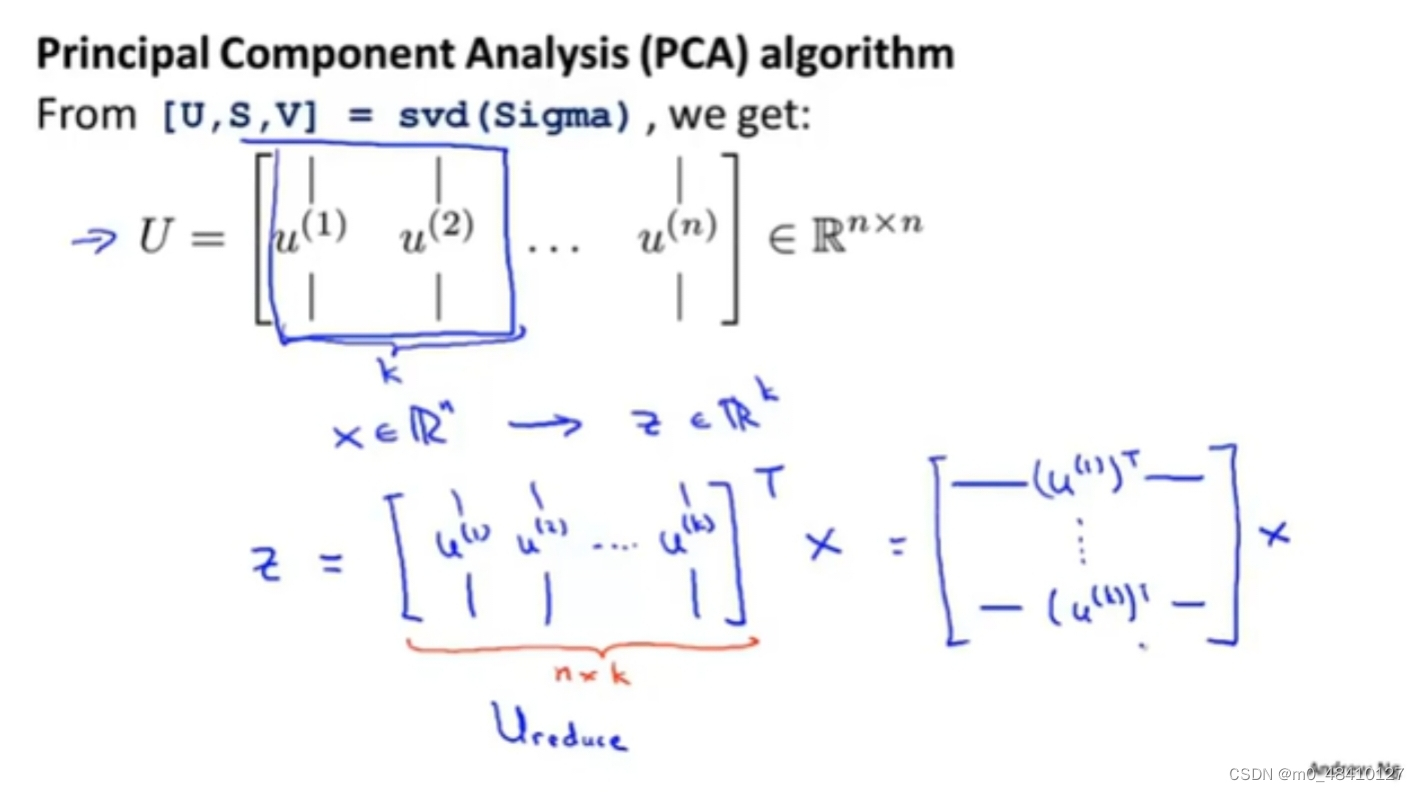
从秋n*n的U矩阵中选取前k列,然后Ureduce矩阵=
Z=Ureduceᵀ*X 。X矩阵的一列是一个用愿来特征值表示的样本,X是n×m维,Ureduce是n×k维,Z是k×m维,Z矩阵的一列是一个用新特征值表示样本。
或者,z(i)=Ureduceᵀ*x(i)。
4-3重建原始数据
压缩:
Z=Ureduceᵀ*X
从Z怎么变回X?
解压缩:
Xappox=Ureduce*Z,Xappox≈X
这就从Z变回原有空间。
4-4选择主成分的数量
4-5用处与建议
pca的用处:
降维:减小存储需求,加速学习算法。
可视化数据。
建议:1.过拟合往往需要减少特征数量,但pca并不是用来解决过拟合的好方法,解决过拟合问题建议使用正则化。
2.不建议在任何问题都直接使用pca来处理数据。建议先通常使用原有的数据来处理问题,当达不到想要的结果时,尝试使用pca。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









