






什么是LRU?
如果你学过操作系统,必然有听过 LRU 算法,他是一种常用的页面置换算法
实现的思想:选择最近最久未使用的数据予以淘汰。
常见的页面置换算法还有很多,例如:最近最久未使用算法(LRU)、先进先出算法(FIFO) 、最佳置换算法(OPT) 、最不经常使用算法(LFU)、时钟算法(Clock)等
LRU算法实现分析
1、底层数据结构的分析
缓存,必须要读 + 写 两个操作 ,如果读的效率要快,底层是采用哈希表结构,写的效率要快,底层就要采用 链表,所以 LRU的底层实现
采用的数据结构就是哈希链表 (哈希表 + 双向链表),而java中就提供了一个集合类LinkedHashMap就是所采用的数据结构正是哈希链表
这是LRU缓存淘汰的过程图:
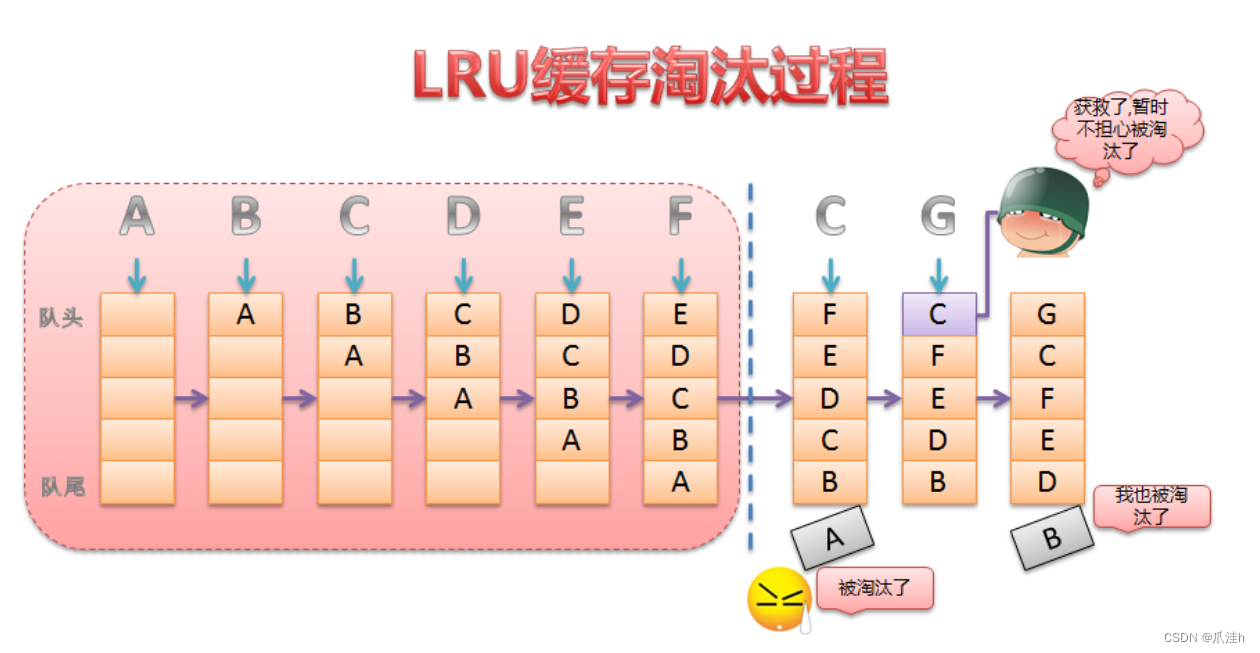
这是LinkedHashMap的数据结构图解:
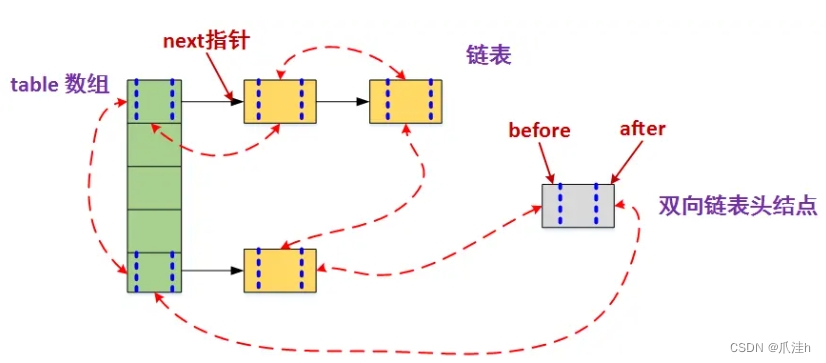
此数据结构正好保证了LinkedHashMap的(插入顺序/访问顺序)和遍历顺序是一致的,而实现LRU淘汰算法就是利用了LinkedHashMap能够保证访问顺序的特性,在此基础上再设置指定的缓存容量,当超出缓存容量时则将最近最久未使用的元素删除 。
LRU缓存淘汰算法具体实现
import java.util.LinkedHashMap;
import java.util.Map;
/**
* 利用LinkedHashMap实现LRU缓存淘汰算法(最近最久未使用)
* @param <K>
* @param <V>
*/
public class LRUCache<K, V> extends LinkedHashMap<K, V> {
private int capacity; //缓存容量
public LRUCache(int capacity){
//initialCapacity:初始容量
//loadFactor:负载因子(建议0.75)
//accessOrder:true表示LinkedHashMap是按照访问的顺序添加指针(默认插入的顺序)
super(capacity, 0.75f, true);
this.capacity = capacity;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > capacity;
}
//测试代码
public static void main(String[] args) {
LRUCache<Integer, String> lruCache = new LRUCache<>(3);
lruCache.put(1, "a");
lruCache.put(2, "b");
lruCache.put(3, "c");
System.out.println(lruCache);// {1=a, 2=b, 3=c}
lruCache.put(4, "d");
System.out.println(lruCache);// {2=b, 3=c, 4=d}
lruCache.get(2);
System.out.println(lruCache);// {3=c, 4=d, 2=b}
}
}













 504
504











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









