







前言:学习自霹雳吧啦Wz
YOLOV1
论文思想
1、将一幅图像分成SxS个网格(grid cell),如果某个object的中心落在这个网格中,则这个网格就负责预测这个object。
2、每个网格要预测B个bounding box,每个bounding box除了要预测位置(x,y,w,h)之外,还要附带预测一个confidence值。每个网格还要预测C个类别的分数。因此对于PASCAL VOC(20个类别),使用S = 7,B = 2,每个网格有5(x,y,w,h,confidence)x 2(两个网格)+20(类别)= 30个预测结果,因此一张图像有7 x 7 x 30个tensor。
4、预测位置x,y,w,h。x,y的位置是相对于网格而言的。w,h是相对于整张图像而言的。
5、置信度confidence。定义为 ,式中的第一项为bounding box内存在物体的概率,第二项为预测框和真实框的IOU。在测试时,每个物体的概率就为C个类别分数 x confidence,如下。
,式中的第一项为bounding box内存在物体的概率,第二项为预测框和真实框的IOU。在测试时,每个物体的概率就为C个类别分数 x confidence,如下。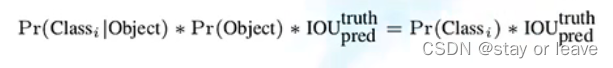
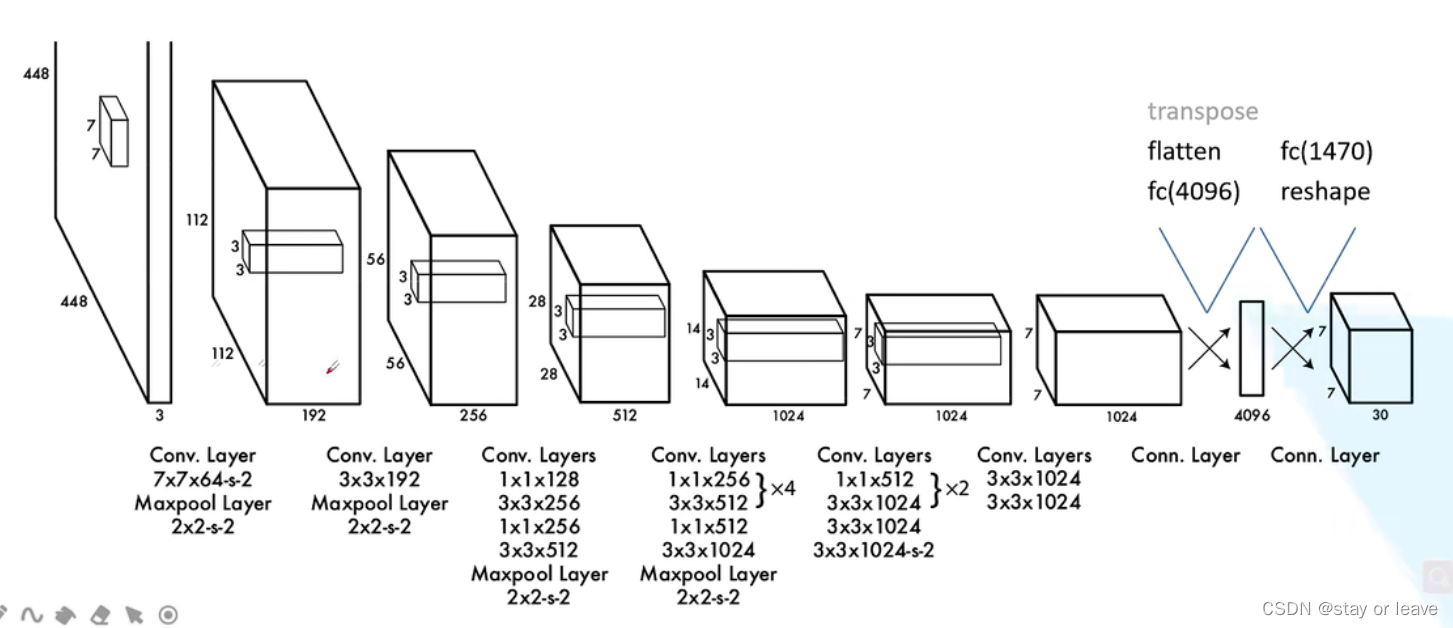
网络结构
损失函数 
存在的问题
1、当小目标聚集在一起的时候,检测效果很差,例如一群鸟。原因是,每个网格只预测一个类别。
2、当目标出现新的尺寸的时候,检测效果很差。
3、定位不准确,原因是,yolov1是直接预测目标的位置,而不是基于anchor预测目标的回归参数,因此yolov2中采用了基于anchor预测目标的回归参数的方法。(题外话,Faster-RCNN和SSD也是采用基于anchor预测目标的回归参数的方法)。
YOLOV2
对yolov1的改进之处
Batch Normalization
1、加速网络收敛,避免梯度消失爆炸。
2、有利于模型的正则化,可以移除dropout的使用。
3、提高模型的泛化能力, BN通过使每个层输入的分布标准化,有助于提高模型的泛化能力。
High Resolution Classifier
采用更高分辨率的分类器(448 x 448)。
Convolutional With Anchor Boxes
采用基于anchor偏移的预测方式,简化目标边界框预测的问题,使用网络更容易收敛。使用这种方式使预测的召回率更高。
Dimension Clusters
根据k-means聚类的方法去计算anchors的尺寸。
Direct location prediction
使用sigmoid函数对预测值tx,ty进行限制,使其不会飘出中心网格之外。公式如下。
Fine-Grained Features
底层特征下采样与高层特征相融合,如图。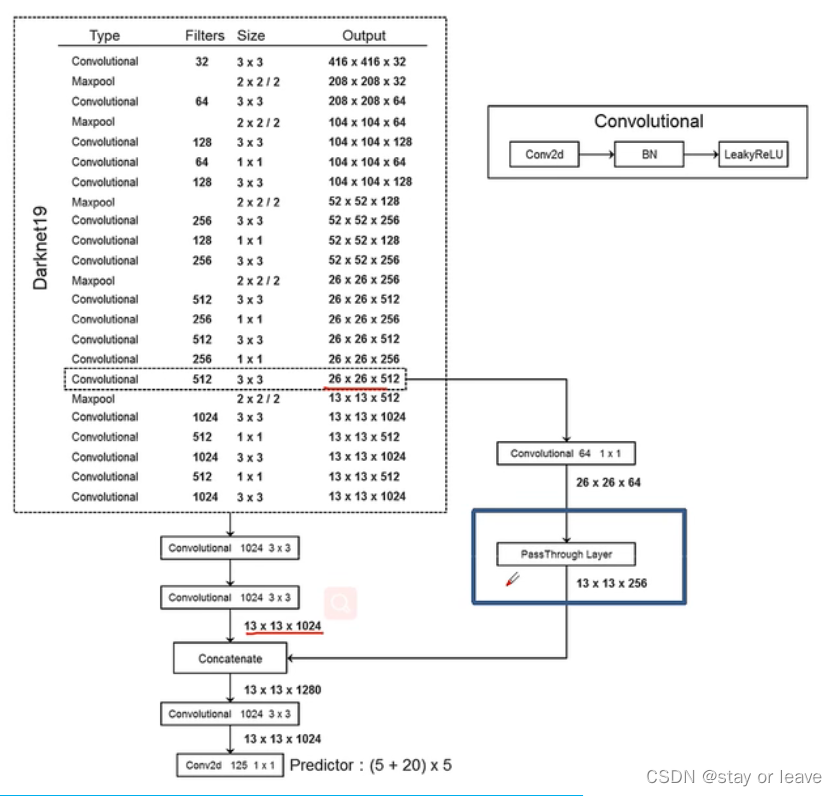
下采样方式,如图。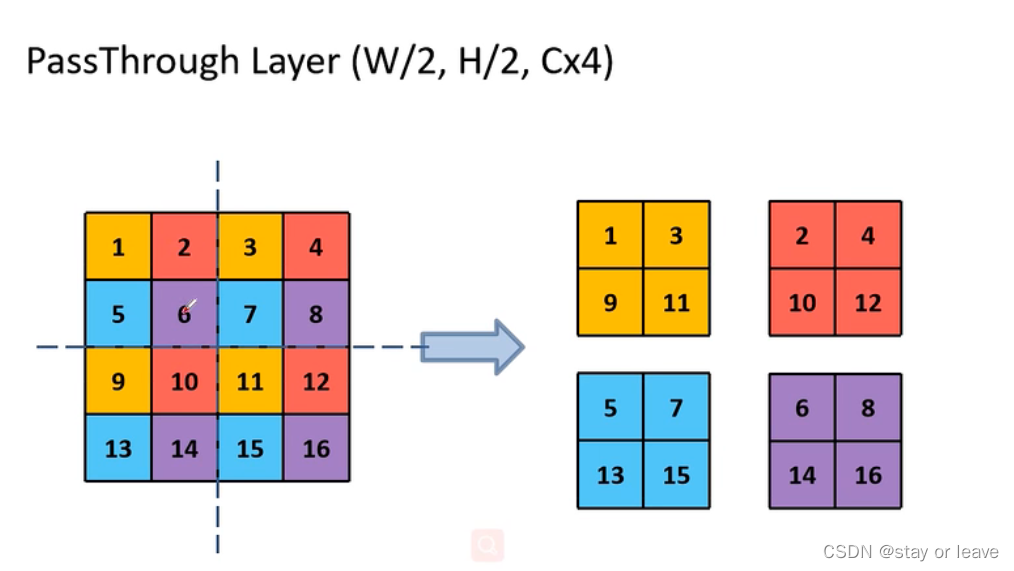
Multi-Scale Training
我们每隔几次迭代就改变输入图像的大小。每10个epoch我们的网络随机选择一个新的图像尺寸大小。由于我们的模型将样本降为32的倍数,我们从32的倍数中提取:{320,352,…, 608},因此,最小的选项是320 x 320,最大的是608 x 608,我们将网络调整到该维度并继续训练
主干网络Darknet19(19个卷积层)
网络结构如下。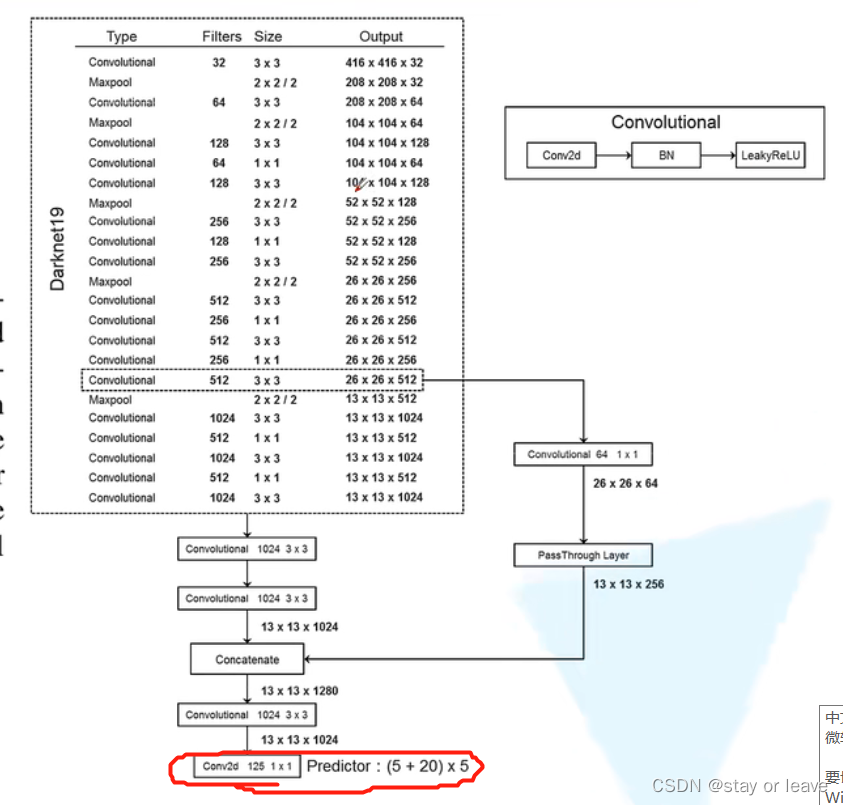
YOLOV3
主干网络Darknet-53
1、网络结构如下。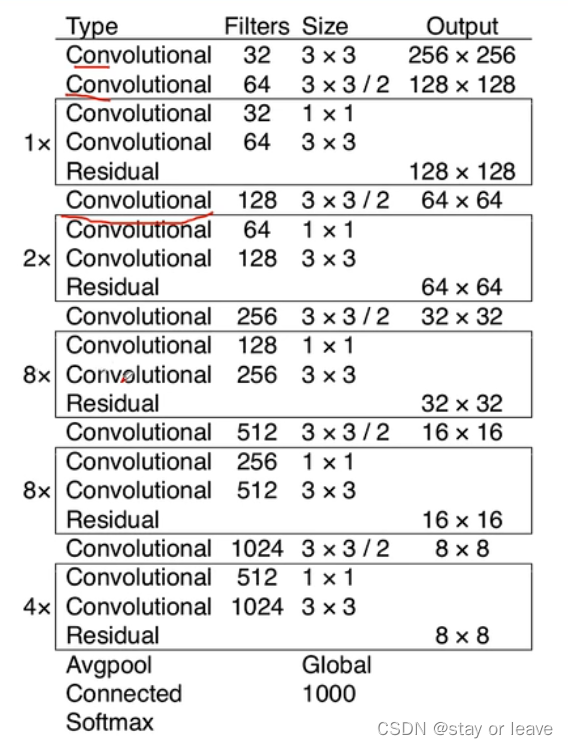
2、Darknet-53与Resnet网络的对比如下。
可以看到,虽然Darknet-53的网络深度比ResNet-152更深,但Darknet-53的检测速度是ResNet-152的两倍,并且检测精度相差无几。
优势原因:
第一,Darknet53使用池化层替代了卷积层,减少了信息的损失,因此检测精度较好。
第二,相对于Resnet152,Darknet53的卷积核个数更少,参数更少,因此计算量更少,检测速度更快。
yolov3的网络结构
目标边界框的预测
和yolov2是一样的。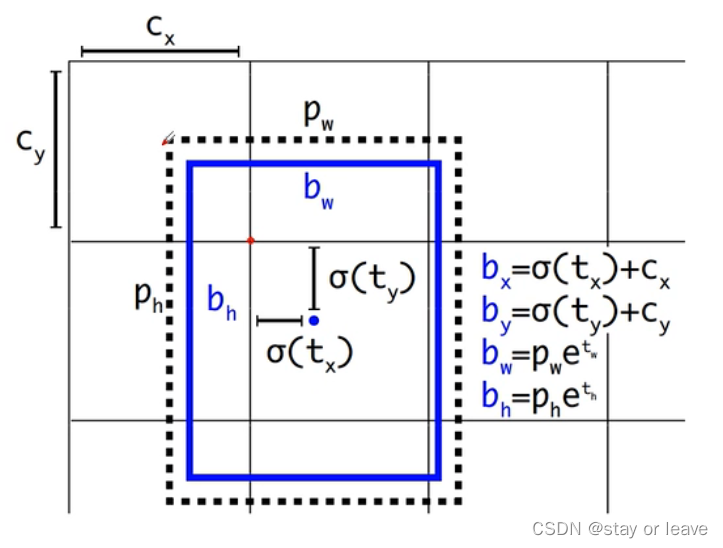
正负样本的匹配
和SSD的匹配方式相同。
损失的计算
1、置信度损失
2、类别损失
3、定位损失
YOLOV3SPP
Mosaic图像增强
优点:增加数据的多样性,增加目标个数,BN能一次性统计多张图片的参数。
SPP模块
结构如下。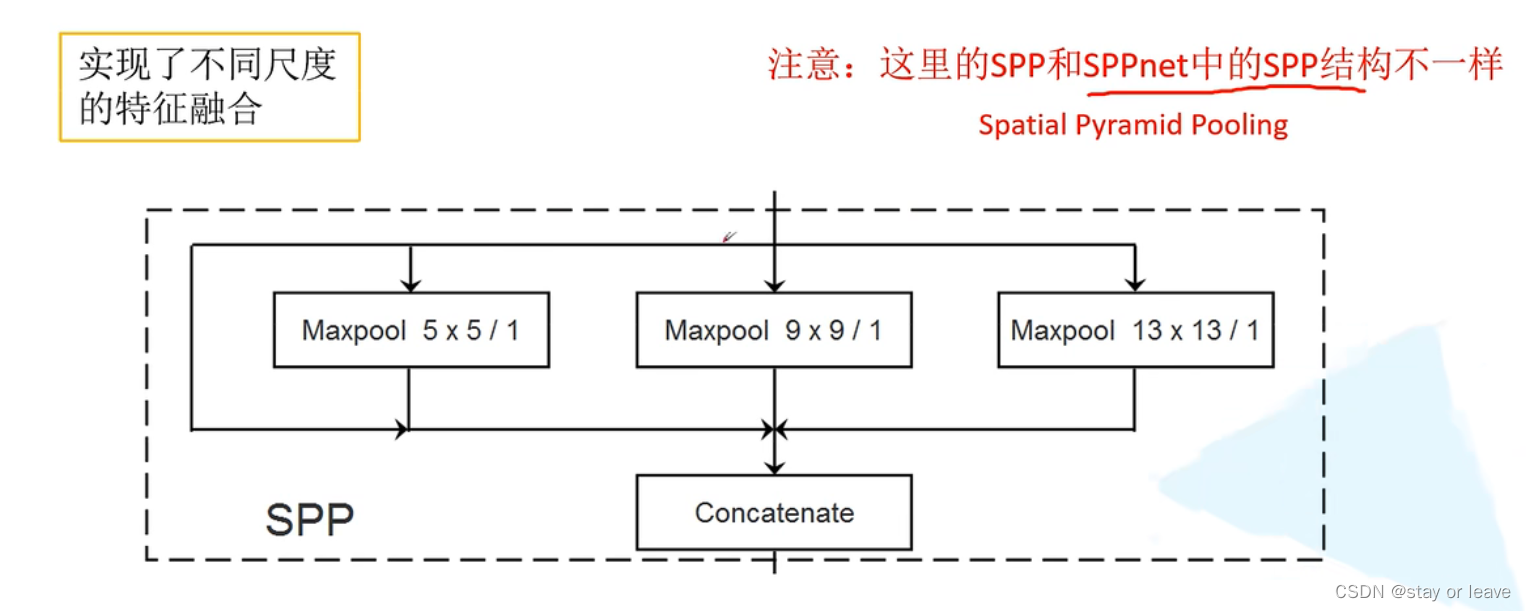
SSP模块在yolov3网络中的位置如下。 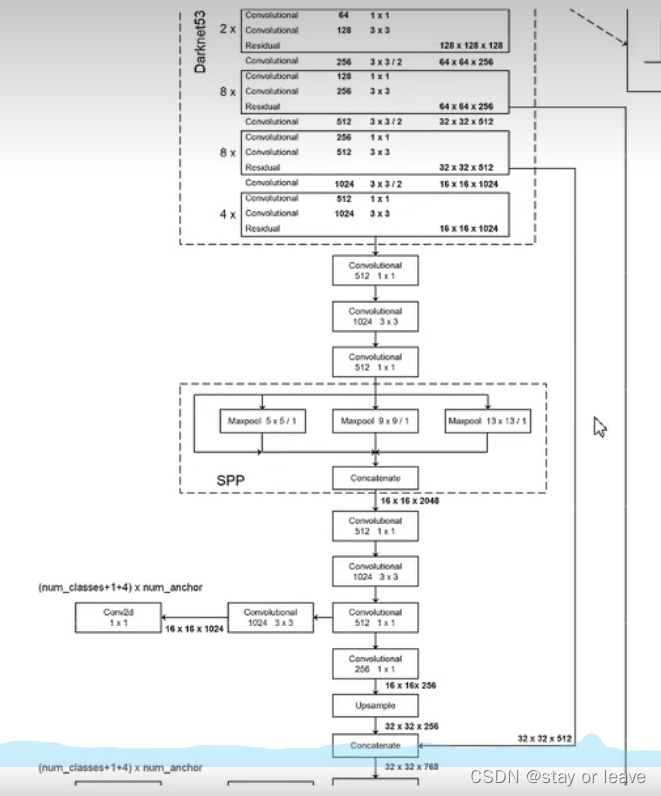
IOU DIOU CIOU
IOU LOSS
优点:1.能够更好的反应重合程度 2.具有尺度不变性。
缺点:1.当不相交时loss为0。
DIOU LOSS
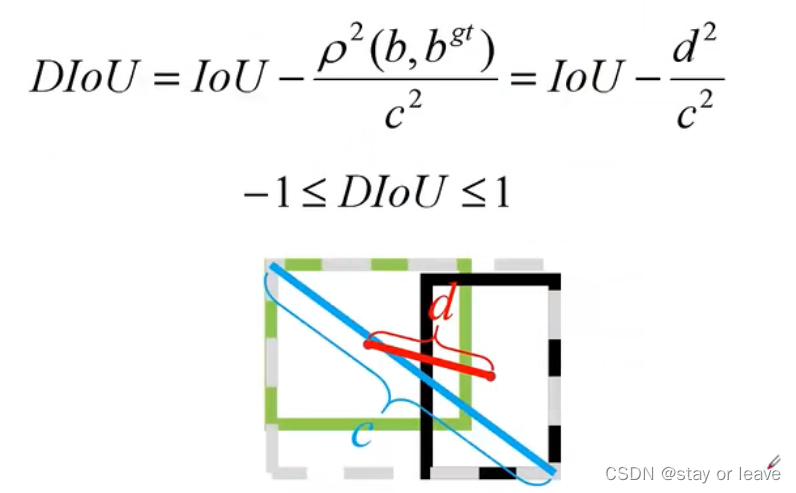

GIOU LOSS

Focal loss
交叉熵损失
交叉熵损失: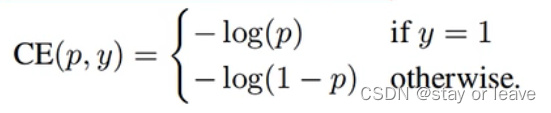
令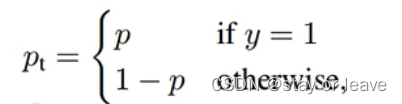
则有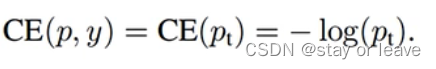
Focal loss
1、主要思想
减小对于大多数容易分类的样本的loss,增大对于难以分类的样本的loss。
较难区分的样本是指:当检测目标为正样本时,目标概率却较小。或者,当检测目标为负样本时,目标概率却较大。
2、公式推理
- 对于表达式
 可知,当样本较难区分时,Pt 较小。当样本较容易区分时,Pt 较大。
可知,当样本较难区分时,Pt 较小。当样本较容易区分时,Pt 较大。 - 因此我们要使Pt 较小时,loss较大,Pt 较大时,loss较小。 于是可以得到损失公式:

- 加上平衡因子,得到最终的Focal loss公式:
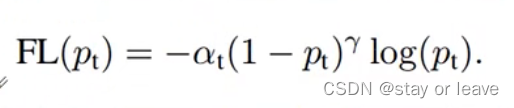
3、注意的点
Focal loss容易受到噪声的干扰。















 855
855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









