







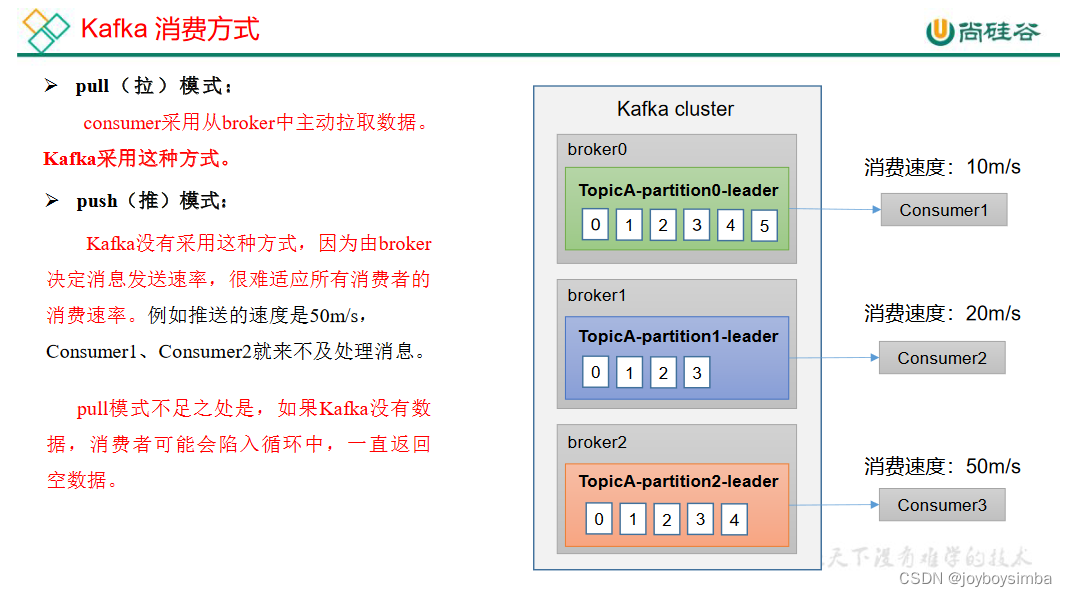
1 Kafka 消费方式
2 Kafka 消费者工作流程
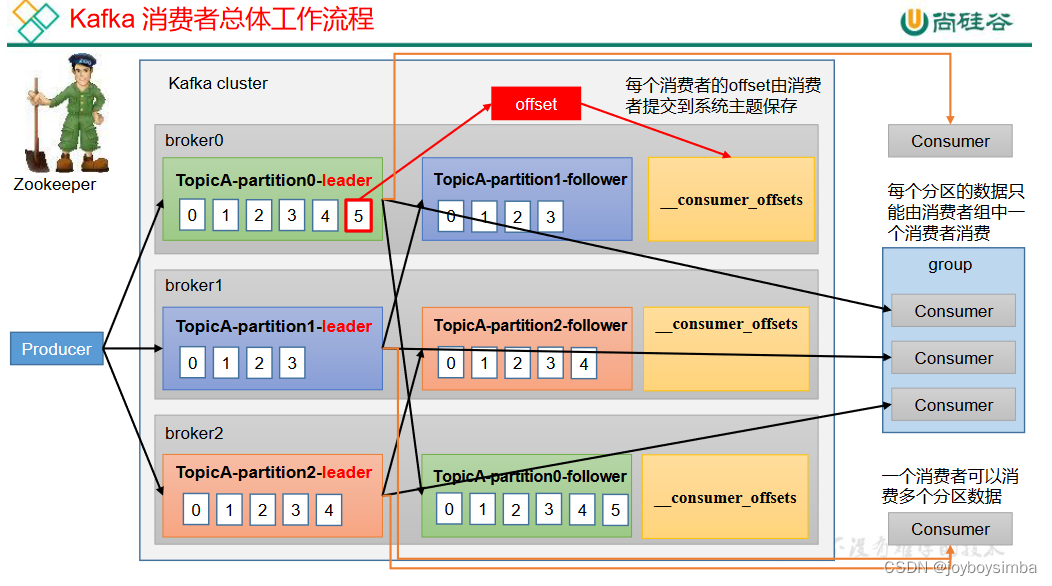
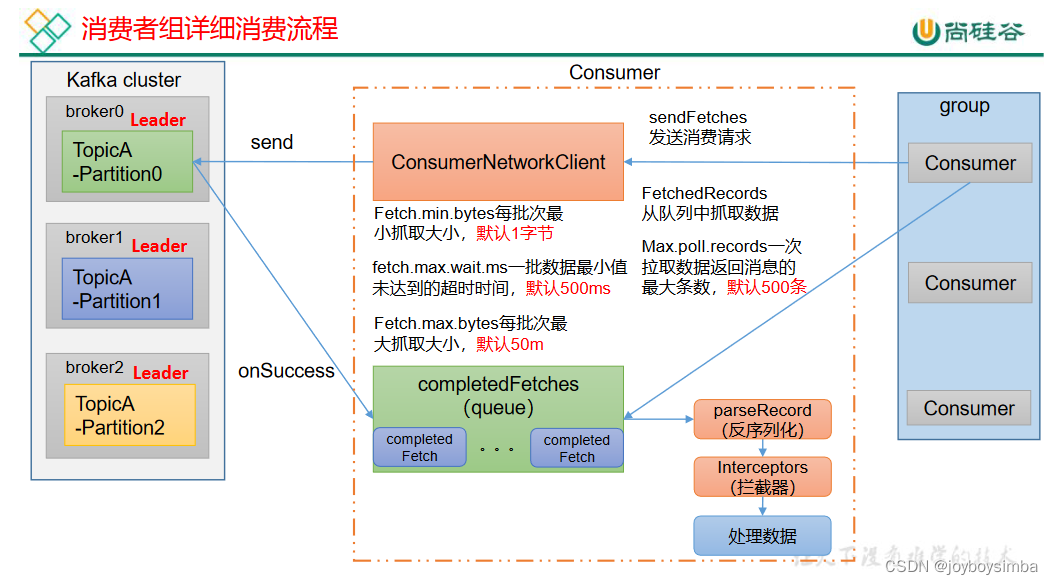
2.1 消费者总体工作流程
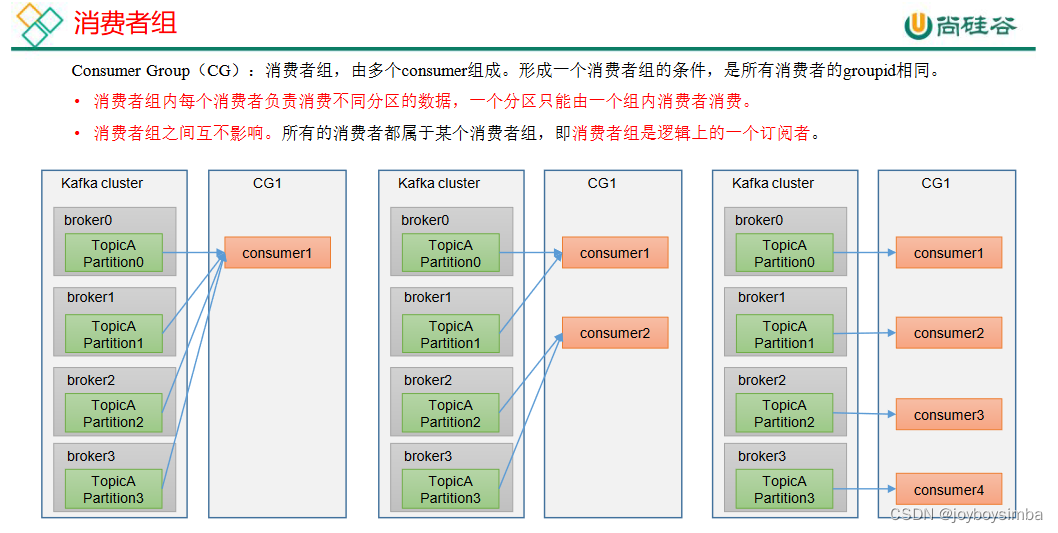
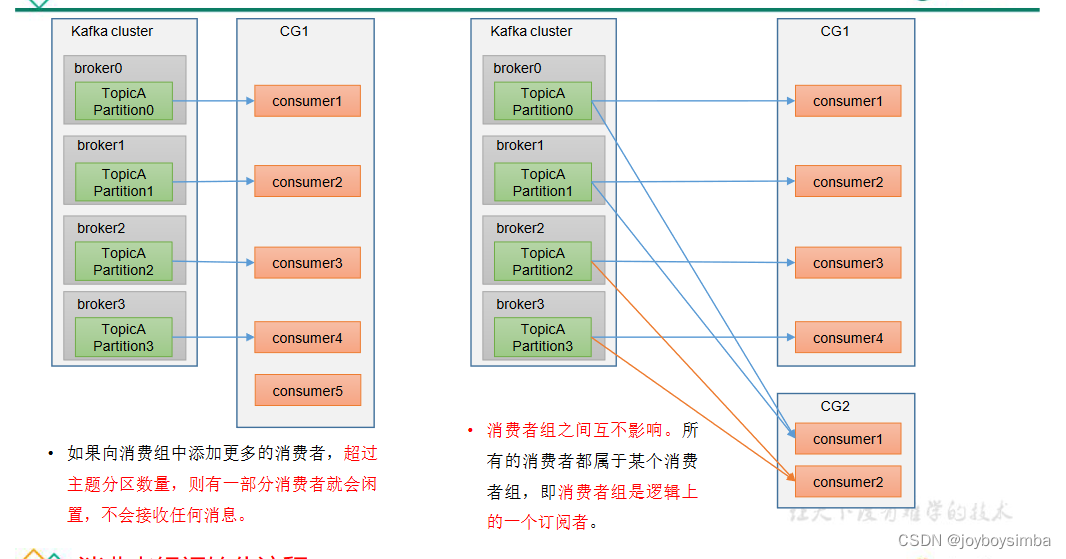
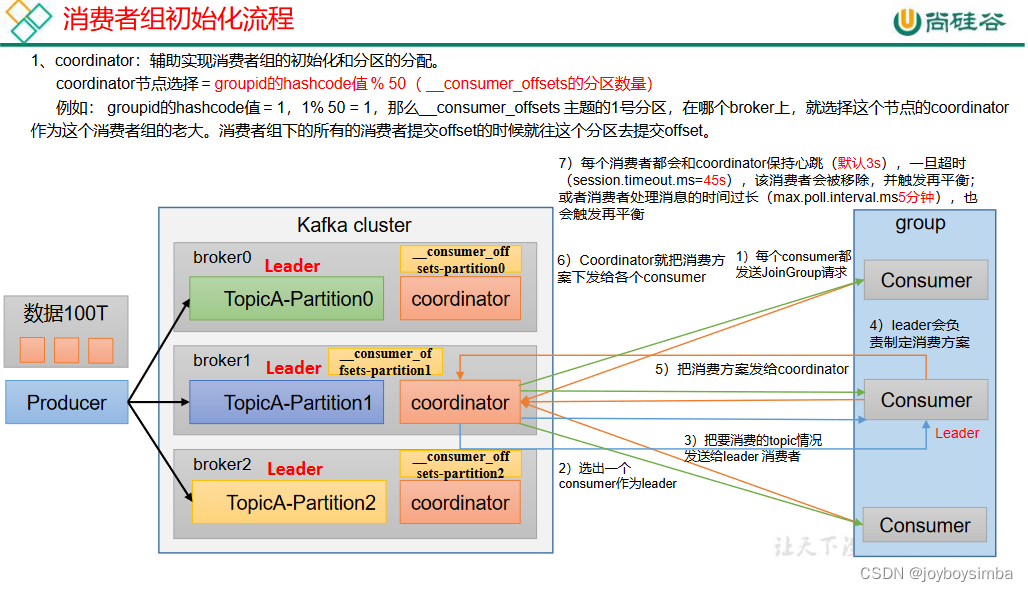
2.2 消费者组原理
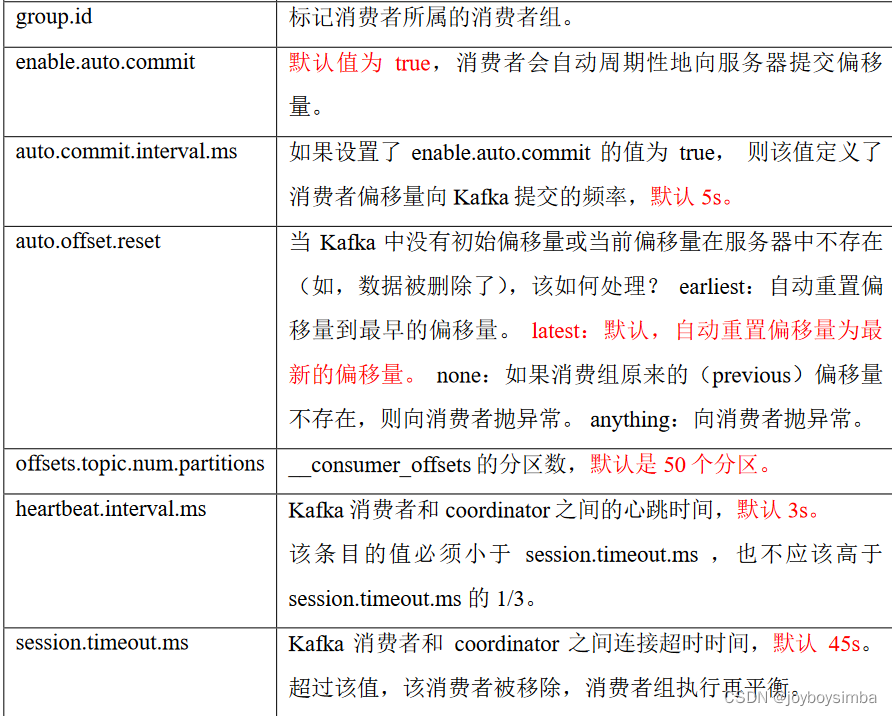
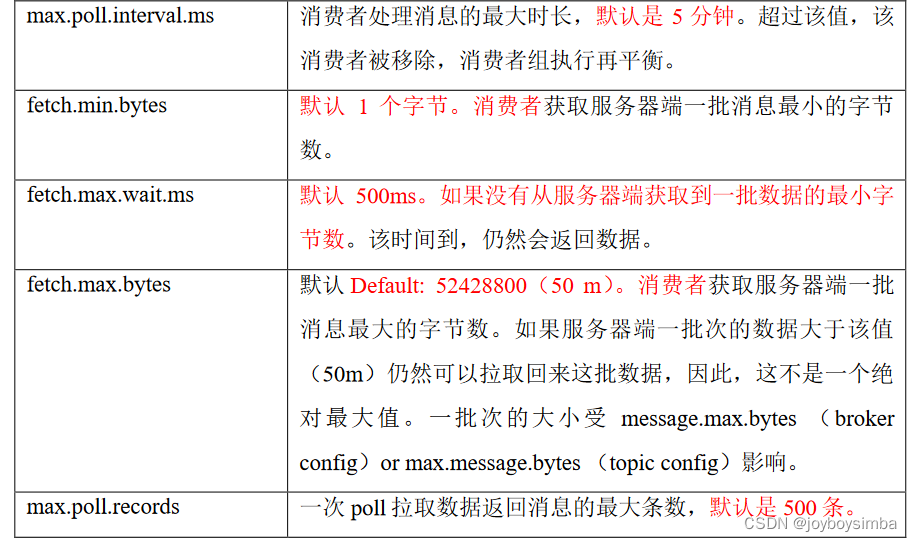
2.3 消费者重要参数
3 消费者 API
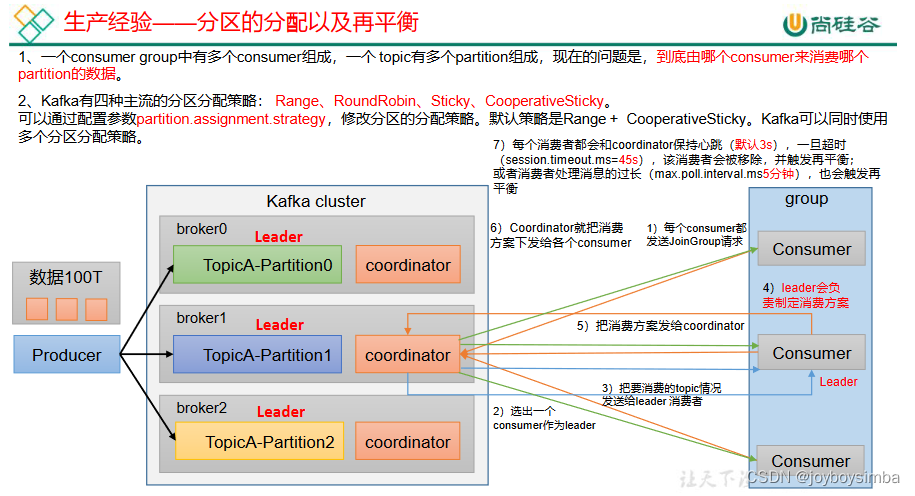
4 生产经验——分区的分配以及再平衡

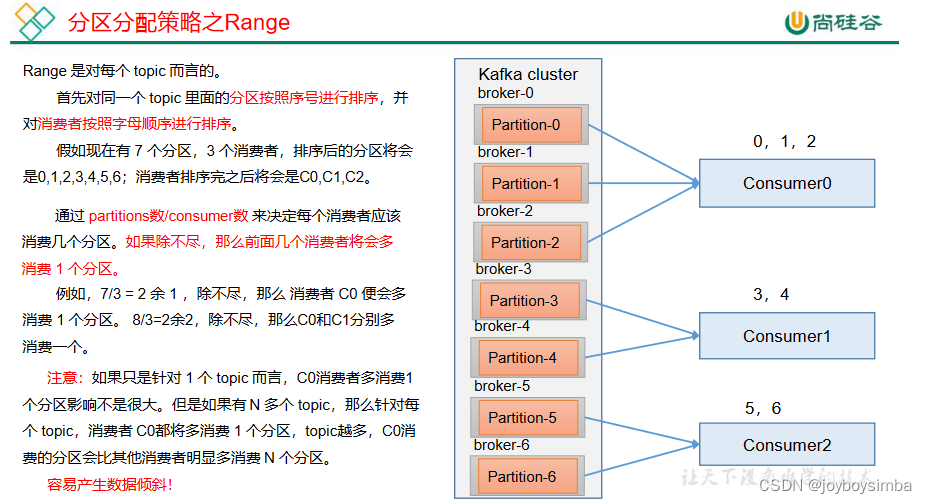
4.1 Range 以及再平衡
1)Range 分区策略原理
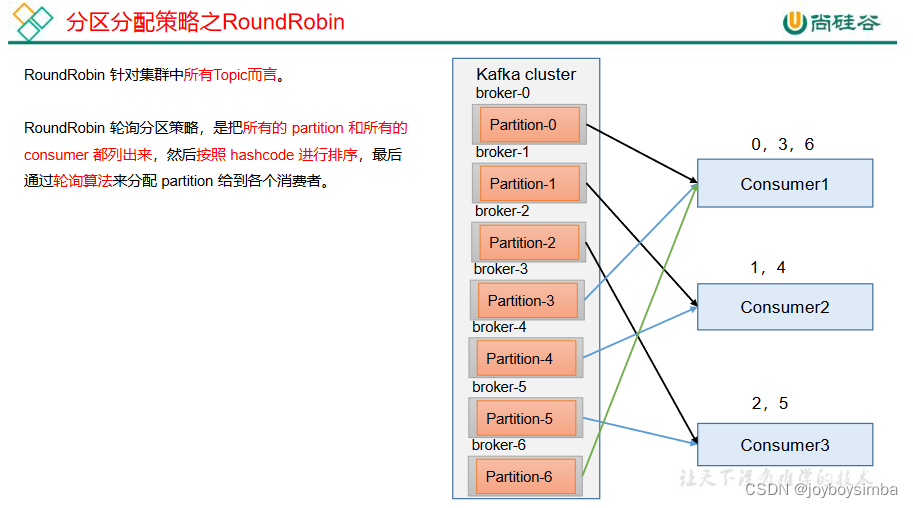
4.2 RoundRobin 以及再平衡
1)RoundRobin 分区策略原理
4.3 Sticky 以及再平衡
粘性分区定义:可以理解为分配的结果带有“粘性的”。即在执行一次新的分配之前,
考虑上一次分配的结果,尽量少的调整分配的变动,可以节省大量的开销。
粘性分区是 Kafka 从 0.11.x 版本开始引入这种分配策略,首先会尽量均衡的放置分区
到消费者上面,在出现同一消费者组内消费者出现问题的时候,会尽量保持原有分配的分
区不变化。
5 offset 位移
5.1 offset 的默认维护位置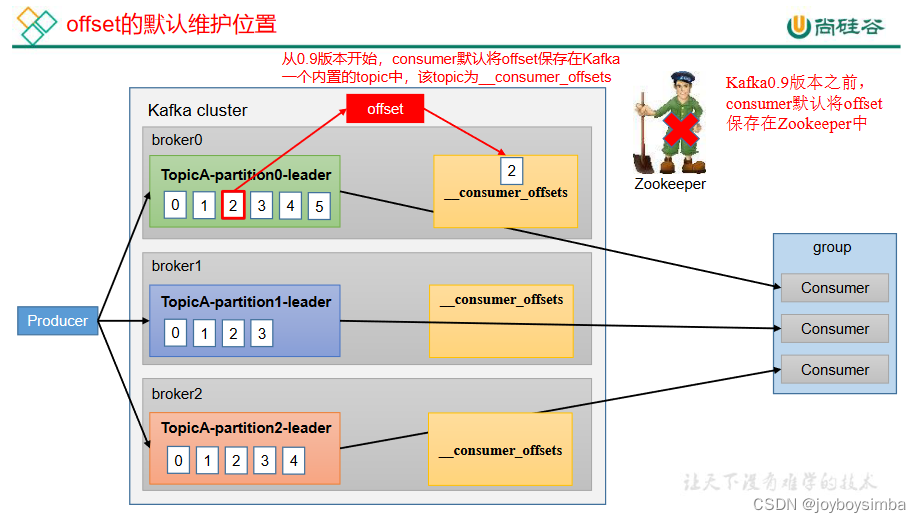
__consumer_offsets 主题里面采用 key 和 value 的方式存储数据。key 是 group.id+topic+
分区号,value 就是当前 offset 的值。每隔一段时间,kafka 内部会对这个 topic 进行
compact,也就是每个 group.id+topic+分区号就保留最新数据。
5.2 自动提交 offset
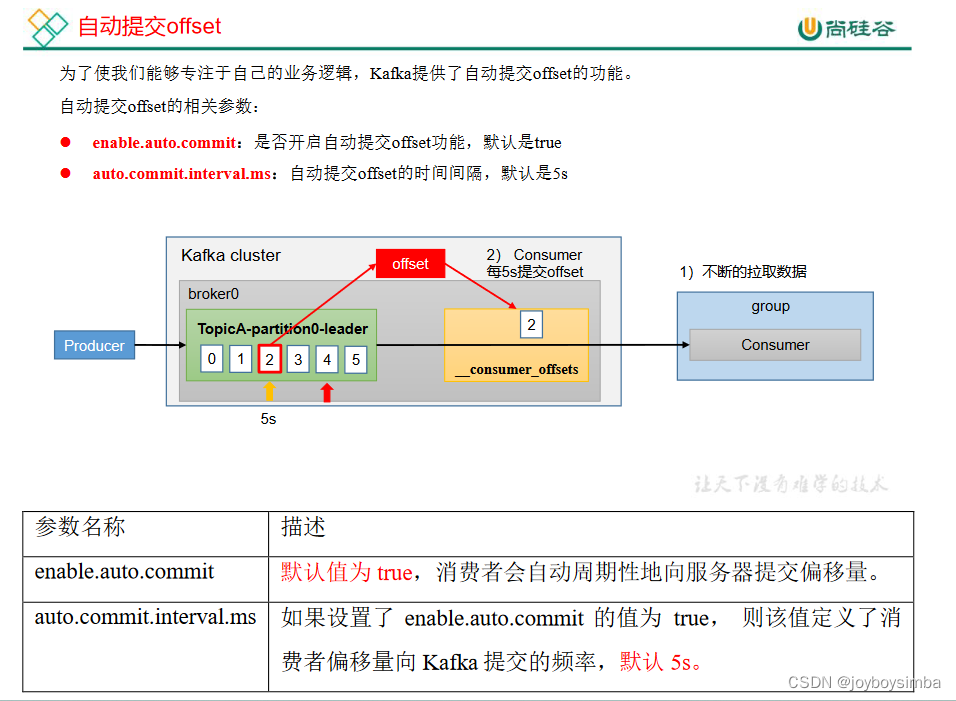
5.3 手动提交 offset(分为同步异步)
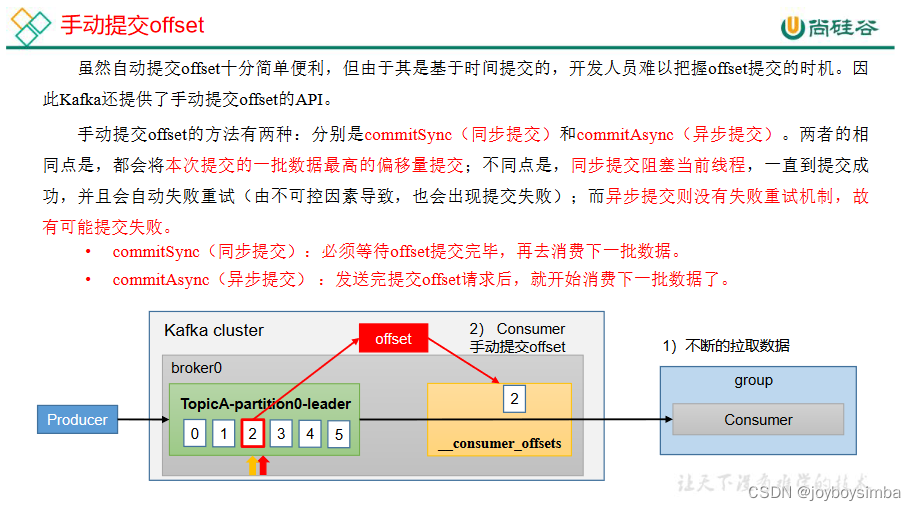 5.4 指定 Offset 消费
5.4 指定 Offset 消费
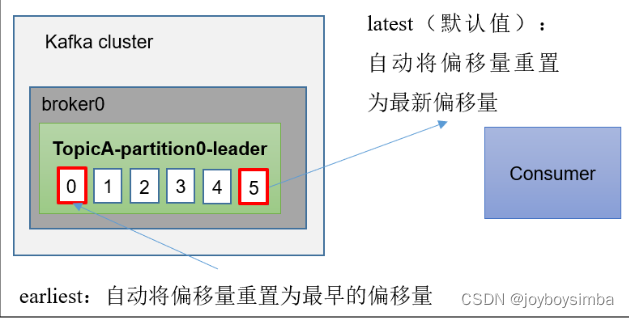
auto.offset.reset = earliest | latest | none 默认是 latest。
当 Kafka 中没有初始偏移量(消费者组第一次消费)或服务器上不再存在当前偏移量时(例如该数据已被删除),该怎么办?
(1)earliest:自动将偏移量重置为最早的偏移量,--from-beginning。(2)latest(默认值):自动将偏移量重置为最新偏移量。(3)none:如果未找到消费者组的先前偏移量,则向消费者抛出异常。
(4)任意指定 offset 位移开始消费
每次执行完需要修改消费者组名。
5.5 指定时间消费
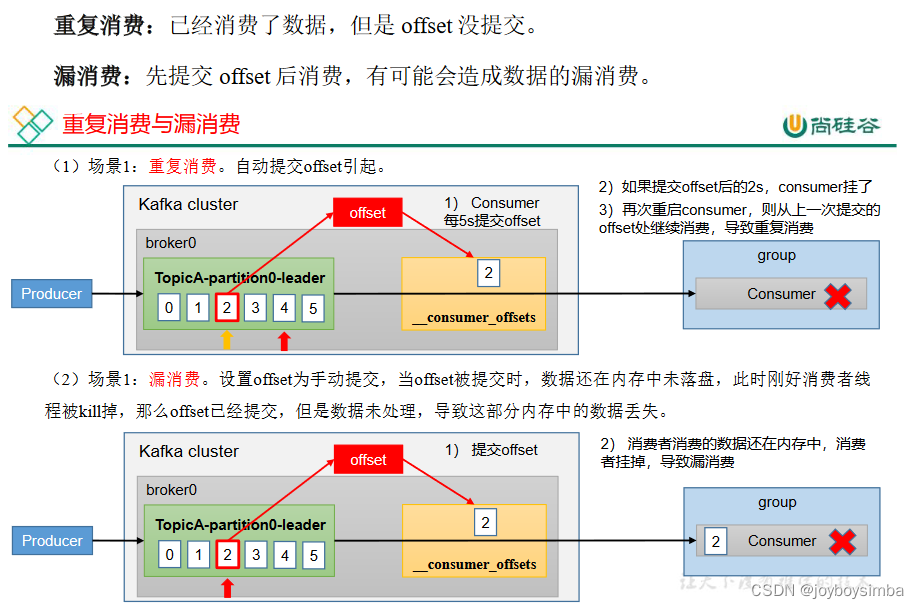
5.6 漏消费和重复消费
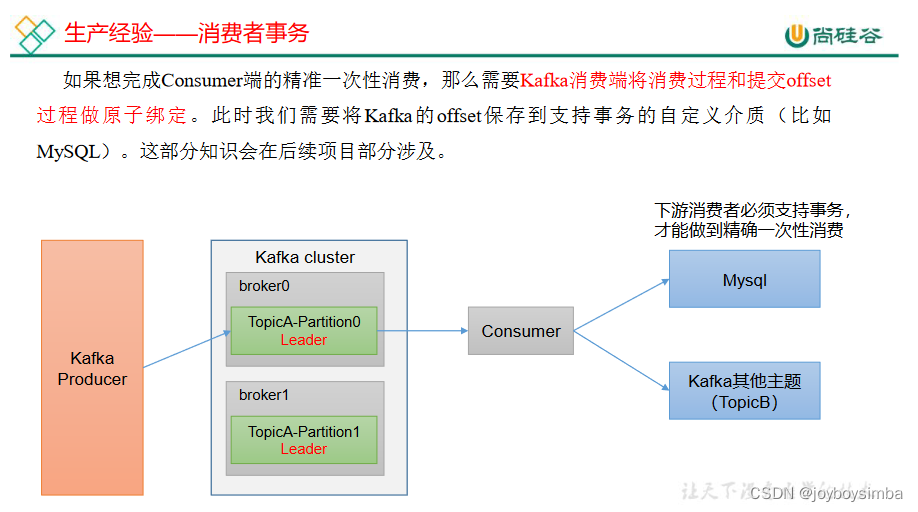
6 生产经验——消费者事务
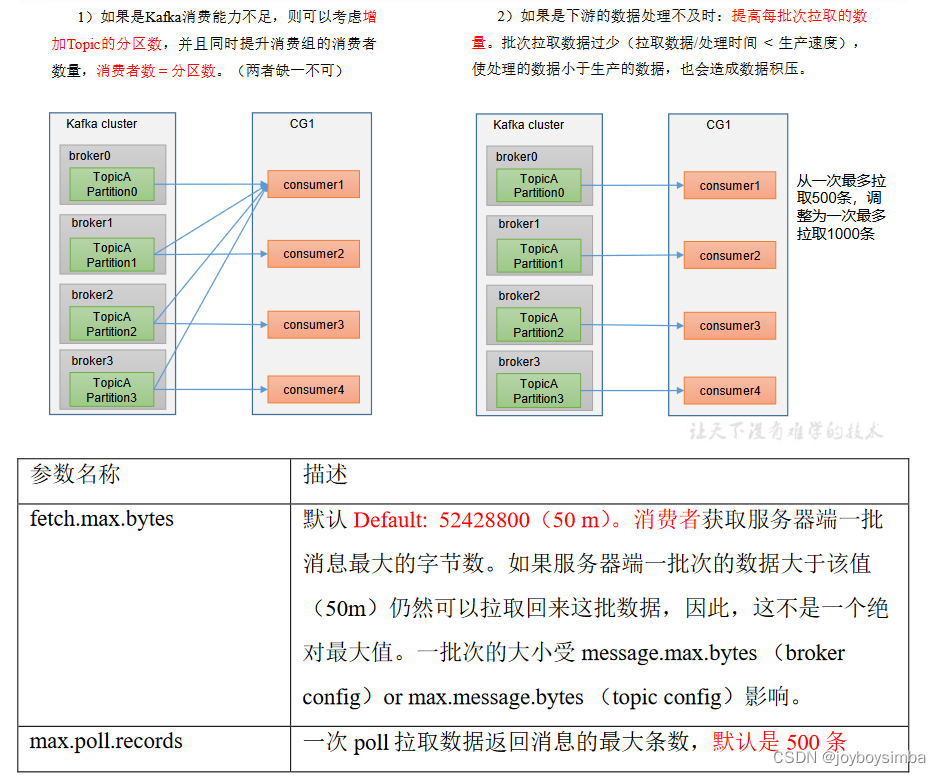
7 生产经验——数据积压(消费者如何提高吞吐量)















 2310
2310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









