







目录
1、推导式
推导式,又称解析式,是python的一种独有特性。推导式是可以从一个数据序列构建另一个新的数据序列的结构体。共有三种推导,在python2和3中都有支持:
- 列表(list)推导式
- 字典(dict)推导式
- 集合(set)推导式
1.1、列表推导式
result = [i * i for i in range(20) if i % 3]
# 等价于
tmp = []
for i in range(20):
if i % 3:
tmp.append(i * i)
print(tmp)
print(result)1.1.1、列表推导式练习
# 使用列表推到是输出200以内,开平方是整数的数
import math
re = [i for i in range(200) if math.sqrt(i) % 1 == 0]
re = [i * i for i in range(200) if 0 <= i * i <= 200]
re = [i for i in range(200) if isinstance(int(math.sqrt(i)),int)]
print(re)# # 对列表中的数,取两位小数
re1 = [2.45345, 4.3454325, 9, 82.234324, 9.841234]
# re2 = [round(i,2) for i in re1 ]
# re2 = [f"{i:.2f}" for i in re1]
re2 = [('%.2f'%i) for i in re1]
print(re2)# 求下面名字中出现两次e的名字
names = [['Tom', 'Billy', 'Jefferson', 'Andrew', 'Wesley', 'Steven', 'Joe'],
['Alice', 'Jill', 'Ana', 'Wendy', 'Jennifer', 'Sherry', 'Eva', 'Elven']]
print([name for lst in names for name in lst if name.lower().count("e")>=2])
# 运行结果
['Jefferson', 'Wesley', 'Steven', 'Jennifer', 'Elven']
1.2、集合推导式
和前面的列表推导式差不多,不过就是[]变成了{}
print({i for i in str1})
# 结果
{'f', 'a', 'l', 'k', 's', 'g', 'd'}1.2.1、集合和列表的区别
- 集合天生去重
- 集合无序,列表有序
- 集合只能存放可hash对象(不可变数据类型),列表可以存放任何数据类型
1.3、字典推导式
# 统计字符串中出现字母的次数
str1 = 'fdsakjghasdg'
print({x: str1.count(x) for x in set(str1)})
# 结果
{'j': 1, 'f': 1, 'k': 1, 'a': 2, 's': 2, 'g': 2, 'h': 1, 'd': 2}
# 这个方法不用字典推导式的话,可以用下面这个方法统计
tmp = {}
for i in str1:
tmp[i] = tmp.get(i,0) + 11.4、推导式小练习
# 过滤掉长度小于3的字符串列表,并将剩下的转化成大写字母
q1 = ['a', 'ab', 'abc', 'abcd', 'abcde']
print([i.upper() for i in q1 if len(i) >= 3])
# 结果
['ABC', 'ABCD', 'ABCDE']
# 求(x,y)其中x是0-5之间的偶数,y是0-5之间的奇数组成的元组列表
result = [(x, y) for x in range(6) for y in range(6) if x % 2 == 0 and y % 2 == 1]
print(result)
# 结果
[(0, 1), (0, 3), (0, 5), (2, 1), (2, 3), (2, 5), (4, 1), (4, 3), (4, 5)]
# 快速更换key和value
q3 = {'a': 10, 'b': 34}
result1 = {y: x for x,y in q3.items()}
print(result1)
# 结果
{10: 'a', 34: 'b'}
# 合并大小写对应的value值,将k统一写成小写
q4 = {'B':3,"a":1,"b":6,"c":3,"A":4}
result2 = {x.lower():q4.get(x.lower(),0) + q4.get(x.upper(),0) for x,y in q4.items()}
print(result2)
{'b': 9, 'a': 5, 'c': 3}2、迭代器与生成器⭐⭐⭐(面试常考题)
2.1、可迭代对象
- 实现了__iter__方法,并且该方法返回一个迭代器
- 这样子的对象就是一个可迭代对象
- __iter__,魔术方法
可以用Iterable来获取是否是一个迭代对象,但是这个方法有点不准确,如下所示
str1 = "abc"
print(dir(str1)) # 属性中有一个__iter__方法
class A:
def __iter__(self):
return None
a = A()
from collections import Iterable
print(isinstance("abc",Iterable))
print(isinstance(a,Iterable)) # 这里不怎么准,因为a返回的不是一个迭代器,而是一个None,但是这里是True。所以判断不大准确。
2.1.1、可迭代对象有哪些
-
可迭代对象有哪些
-
容器类型都是可迭代对象
-
打开的文件
-
range
2.2、迭代器
- 实现了__iter__()方法和__next__()方法都是迭代器
- __iter__方法 返回自身
- __next__方法 返回下一个值
迭代器一定是一个可迭代对象
for循环底层是这么实现的👇
for循环 -- 先调用对象的__iter__方法得到一个迭代器
再调用__next__方法,不断返回下一个值
如果容器中没有更多的元素了,则抛出StopIteration
for 循环中遇到异常就退出
print(dir([1,2,3]))
# 这里面没有__next__方法,但是有__iter__方法
print(hasattr([1,2,3],"__next__"))
# 结果为False
lst = [1,2,3]
# 这里返回了一个迭代器
lst_it = lst.__iter__()
lst_it2 = iter(lst)
print(hasattr(lst_it,"__next__"),hasattr(lst_it,"__iter__"))
print(hasattr(lst_it2,"__next__"),hasattr(lst_it2,"__iter__"))
# 这两个结果都是True
print(lst_it.__next__())
print(next(lst_it))
print(next(lst_it))
print(next(lst_it)) # 当迭代到最后会抛出StopIteration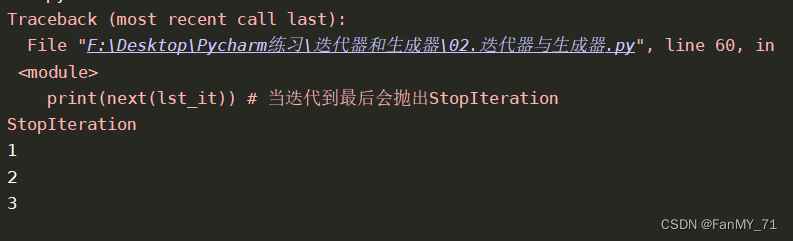
这是因为迭代器是懒加载、惰性求值的。只有用到这个值的时候,这个值才会在迭代器中生成。比如python2中xrange(这个是python3中的range) ,就是惰性求值的。这样可以减少短时间内内存大量的消耗。
2.2.1、编写迭代器
# 编写迭代器实现range
class MyRange():
def __init__(self, num):
self.start = -1
self.num = num
def __iter__(self):
return self
def __next__(self):
if self.start < self.num - 1:
self.start += 1
return self.start
else:
raise StopIteration
for i in MyRange(5): # for循环的时候,会自动调用__iter__和__next__方法
print(i)
# 执行结果
0
1
2
3
4# 编写迭代器写一个斐波那契数列
# 1.1.2.3.5.8.13.21
class MyRange:
def __init__(self, num):
self.num = num
self.start = 0
self.lst = [1,1]
def __iter__(self):
return self
def __next__(self):
if self.start <= 1 and self.num >= self.start:
self.start += 1
return self.lst[0]
elif self.num >= self.start:
self.lst.append(self.lst[self.start-1]+self.lst[self.start-2])
num = self.lst[self.start]
self.start += 1
return num
else:
raise StopIteration
for i in MyRange(0):
print(i)
# 执行结果
1
1
1
2
3
52.3、生成器
-
特殊的迭代器
-
就是为了写迭代器更加的简单优雅
-
不需要手动实现__iter__和__next__方法
有两种生成器:
- 生成器表达式
- 生成器函数
2.3.1、生成器表达式
lst = [4,5,6]
g1 = (x*2 for x in lst)
print(dir(g1))
# g1有__iter__和__next__方法
print(next(g1))
# 运行结果
8
# 当我们多次使用print(next(g1)),超出列表的索引范围外的话,就会抛出StopIteration2.3.2、生成器函数
有yield关键字就是一个生成器函数
yield关键字的算法过程:
yield保留中间算法,下次继续执行
当调用next时,遇到yield就暂停运行,并且返回yield后面表达式的值
当再次调用yield时,就会从刚才暂停的地方继续运行,直到遇到下一个yield或者整个生成器结束为止。
def get_content():
print("start yield.....")
yield 3
print("second yield...")
yield 4
print("end.....")
g1 = get_content()
print(next(g1))
print("*"*20)
print(next(g1))
print("*"*20)
print(next(g1))
print("*"*20)
print(next(g1))
# 运行结果
Traceback (most recent call last):
File "F:\Desktop\Pycharm练习\迭代器和生成器\02.迭代器与生成器.py", line 160, in <module>
print(next(g1))
StopIteration
start yield.....
3
********************
second yield...
4
********************
end.....
# 出现这个错误,是因为我们使用了四次__next__超出了我们生成器的范围。我们使用生成器函数再次编辑斐波那契数列
def MyRange(num):
left, right = 0, 1
start = 1
while start <= num:
yield right
left, right = right, left + right
start += 1
for i in MyRange(5):
print(i)
# 执行结果
1
1
2
3
5
2.3.3、 send数据
除了可以使用 next() 方法来获取下一个生成的值,用户还可以使用 send() 方法将一个 新的或者是被修改的值返回给生成器。除此之外,还可以使用 close() 方法来随时退出 生成器。
def counter():
count = 1
while 1:
val = yield count
print(f"val is {val}")
if val is not None:
print(f"val is {val}")
count += val
else:
count += 1
count = counter()
# count.send(10) # 修改数据,必须先激活生成器,可以调用next激活
print(next(count))
print("*"*20)
# send修改生成器的值,并且再执行一次next
count.send(10)
print("*"*20)
print(next(count))
#########运行结果
1
********************
val is 10
val is 10
********************
val is None
12【手动关闭当前生成器】
关闭之后不能再继续生成值
count.close()
print(next(count))
######## 运行结果
Traceback (most recent call last):
File "F:\Desktop\Pycharm练习\迭代器和生成器\02.迭代器与生成器.py", line 205, in <module>
print(next(count))
StopIteration2.3.4、yield from
def f1():
yield range(10)
def f2():
yield from range(10) # yield from后面一定要接迭代对象!!!
# 等价于
# for item in range(10):
# yield item
iter1 = f1()
iter2 = f2()
print(iter1)
print(iter2)
print(next(iter1))
# print(next(iter1)) # 会抛出StopIteration
print(next(iter2))
print(next(iter2))
#####运行结果
<generator object f1 at 0x00000224A80BB190>
<generator object f2 at 0x00000224A80BB0B0>
range(0, 10)
0
1
2.3.5、使用生成器最好的场景
当你需要以迭代的方式去处理一个巨大的数据集合。比如:一个巨大的文件/一个复杂的数据库查询等。
def read_file(fpath):
BLOCK_SIZE = 1024
with open(fpath,'rb') as fp:
while 1:
block = fp.read(BLOCK_SIZE)
if block:
yield block
else:
return如果直接对文件对象调用read()方法,会导致不可预测的内存占用。好的方法是利用固定长度的缓冲区来不断读取文件的部分内容。通过yield,我们不再需要编写读文件的迭代类,就可以轻松实现文件读取。
处理特大文件方法:生成器+切割多个小文件并行处理。比较文件的哈希值就能够判断文件是否传输完成
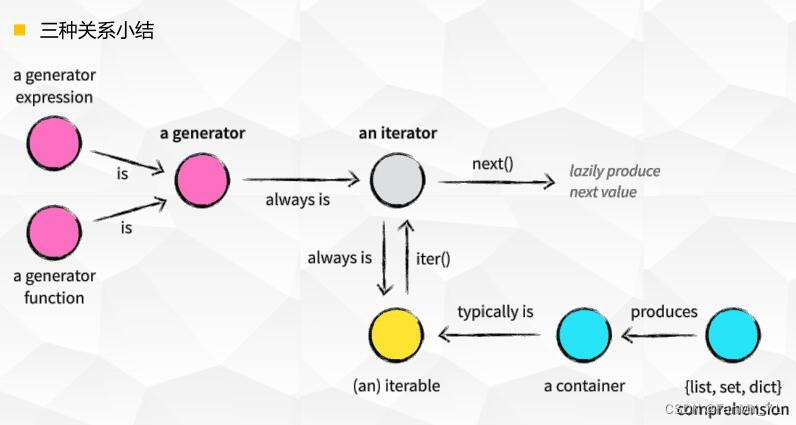
3、推导式、生成器和迭代器之间的关系
















 402
402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











