









文章目录
基础知识
文章当中的图片截图来自【可能是全网最好的《概率统计》期末速成,2小时不到冲刺60分,概率论与数理统计】
概率的性质
加法公式:
- 对于任意事件A、B,有 P ( A ⋃ B ) = P ( A ) + P ( B ) − P ( A B ) P(A\bigcup{B})=P(A)+P(B)-P(AB) P(A⋃B)=P(A)+P(B)−P(AB)
- 对于任意事件A、B、C,有 P ( A ⋃ B ⋃ C ) = P ( A ) + P ( B ) + ( C ) − P ( A B ) − P ( B C ) − P ( A C ) + P ( A B C ) P(A\bigcup{B}\bigcup{C})=P(A)+P(B)+(C)-P(AB)-P(BC)-P(AC)+P(ABC) P(A⋃B⋃C)=P(A)+P(B)+(C)−P(AB)−P(BC)−P(AC)+P(ABC)
- 若A、B、C互不相容,则 P ( A ⋃ B ⋃ C ) = P ( A ) + P ( B ) + P ( C ) P(A\bigcup{B}\bigcup{C})=P(A)+P(B)+P(C) P(A⋃B⋃C)=P(A)+P(B)+P(C)
减法公式:
- 对于事件A、B,有 P ( A − B ) = P ( A ) − P ( A B ) P(A-B)=P(A)-P(AB) P(A−B)=P(A)−P(AB)
- 若 B ⊂ A B \sub A B⊂A,则有 P ( B ) ≤ P ( A ) P(B)\leq{P(A)} P(B)≤P(A),且 P ( A − B ) = P ( A ) − P ( B ) P(A-B)=P(A)-P(B) P(A−B)=P(A)−P(B)
对立事件概率:
- P ( A ‾ ) = 1 − P ( A ) P(\overline{A})=1-P(A) P(A)=1−P(A)
分配律:
- P { ( A ⋃ B ) ⋂ C } = P { A C ⋃ B C } P\{(A\bigcup{B})\bigcap{C}\}=P\{AC\bigcup{BC}\} P{(A⋃B)⋂C}=P{AC⋃BC}
- P { ( A B ) ⋃ C } = P { ( A ⋃ C ) ⋂ ( B ⋃ C ) } P\{(AB)\bigcup{C}\}=P\{(A\bigcup{C})\bigcap{(B\bigcup{C})}\} P{(AB)⋃C}=P{(A⋃C)⋂(B⋃C)}
对偶率:
- P { A ⋃ B ‾ } = P { A ‾ ⋂ B ‾ } P\{\overline{A\bigcup{B}}\}=P\{\overline{A}\bigcap{\overline{B}}\} P{A⋃B}=P{A⋂B}
- P { A ⋂ B ‾ } = P { A ‾ ⋃ B ‾ } P\{\overline{A\bigcap{B}}\}=P\{\overline{A}\bigcup{\overline{B}}\} P{A⋂B}=P{A⋃B}
条件概率
事件A发生的条件下,B发生的概率为 P ( B ∣ A ) = P ( A B ) P ( A ) P(B\vert{A})=\frac{P(AB)}{P(A)} P(B∣A)=P(A)P(AB)
若 P ( A ) > 0 P(A)>0 P(A)>0,则 P ( A B ) = P ( B ∣ A ) P ( A ) P(AB)=P(B\vert{A})P(A) P(AB)=P(B∣A)P(A)
性质:
- P ( B ‾ ∣ A ) = 1 − P ( B ∣ A ) = 1 − P ( A B ) P ( A ) P(\overline{B}\vert{A})=1-P(B\vert{A})=1-\frac{P(AB)}{P(A)} P(B∣A)=1−P(B∣A)=1−P(A)P(AB)
- P ( B ⋃ C ∣ A ) = P ( B ∣ A ) + P ( C ∣ A ) − P ( B C ∣ A ) P(B\bigcup{C}\vert{A})=P(B\vert{A})+P(C\vert{A})-P(BC\vert{A}) P(B⋃C∣A)=P(B∣A)+P(C∣A)−P(BC∣A)
古典概型
若随机试验的样本空间
Ω
\Omega
Ω只有有限个样本点,且每个基本事件发生的可能性相等,则事件A发生的概率为
P
(
A
)
=
A
中所含样本点
k
Ω
中所有样本点数
n
=
k
n
C
n
m
=
n
!
m
!
(
n
−
m
)
!
=
C
7
4
=
7
×
6
×
5
×
4
×
3
×
2
×
1
4
×
3
×
2
×
1
×
3
×
2
×
1
P(A)=\frac{A中所含样本点k}{\Omega{中所有样本点数n}}=\frac{k}{n}\\ C^{m}_{n}=\frac{n!}{m!(n-m)!}=C^{4}_{7}=\frac{7\times6\times5\times4\times3\times2\times1}{4\times3\times2\times1\times3\times2\times1}\\
P(A)=Ω中所有样本点数nA中所含样本点k=nkCnm=m!(n−m)!n!=C74=4×3×2×1×3×2×17×6×5×4×3×2×1
全概率与贝叶斯公式
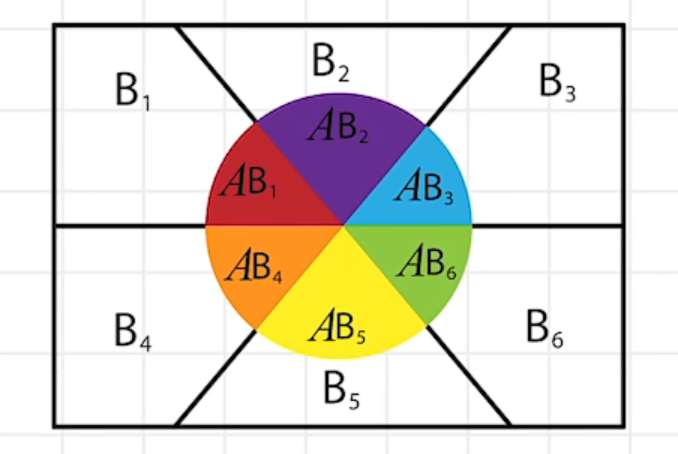
全概率公式:
P
(
A
)
=
∑
i
=
1
n
P
(
A
B
i
)
=
∑
i
=
1
n
P
(
A
∣
B
i
)
P
(
B
i
)
当所求事件
A
可以分成几种情况时,
A
发生的概率就是这些情况对应的概率之和
P(A)=\sum^{n}_{i=1}{P(AB_{i})}=\sum^{n}_{i=1}{P(A\vert{B_{i}})P(B_{i})}\\ 当所求事件A可以分成几种情况时,A发生的概率就是这些情况对应的概率之和\\
P(A)=i=1∑nP(ABi)=i=1∑nP(A∣Bi)P(Bi)当所求事件A可以分成几种情况时,A发生的概率就是这些情况对应的概率之和
贝叶斯公式:
P
(
B
i
∣
A
)
=
P
(
B
i
A
)
P
(
A
)
=
P
(
A
∣
B
i
)
P
(
B
i
)
∑
j
=
1
n
P
(
A
∣
B
j
)
P
(
B
j
)
如果
A
事件发生,判断是发生在哪个情况的时候,用贝叶斯公式
P(B_{i}\vert{A})=\frac{P(B_{i}A)}{P(A)}=\frac{P(A\vert{B_{i}})P(B_{i})}{\sum_{j=1}^{n}{P(A\vert{B_{j}})P(B_{j})}}\\ 如果A事件发生,判断是发生在哪个情况的时候,用贝叶斯公式\\
P(Bi∣A)=P(A)P(BiA)=∑j=1nP(A∣Bj)P(Bj)P(A∣Bi)P(Bi)如果A事件发生,判断是发生在哪个情况的时候,用贝叶斯公式
事件的独立性
-
A和B独立
P ( A B ) = P ( A ) ∗ P ( B ) P ( B ) = P ( B ∣ A ) ( P ( A ) > 0 ) P ( B ∣ A ) = P ( B ∣ A ‾ ) ( 0 < P ( A ) < 1 ) P(AB)=P(A)\ast{P(B)}\\ P(B)=P(B\vert{A})\space(P(A)>0)\\ P(B\vert{A})=P(B\vert{\overline{A}})\space(0<P(A)<1)\\ P(AB)=P(A)∗P(B)P(B)=P(B∣A) (P(A)>0)P(B∣A)=P(B∣A) (0<P(A)<1) -
A和B相互独立,则A和 B ‾ \overline{B} B, A ‾ \overline{A} A和B,
-
A ‾ \overline{A} A和 B ‾ \overline{B} B也相互独立
-
若三个事件相互独立,则任意两个事件均满足上述性质;三个事件同时满足 P ( A B C ) = P ( A ) P ( B ) P ( C ) P(ABC)=P(A)P(B)P(C) P(ABC)=P(A)P(B)P(C)
离散型随机变量分布律与分布函数
| 名称 | 定义 | 性质 |
|---|---|---|
| 分布律 | P ( X = x k ) = p k ( k = 1 , 2 , ⋯ ) P(X=x_{k})=p_{k}\space(k=1,2,\cdots) P(X=xk)=pk (k=1,2,⋯) | p k ≥ 0 , k = 1 , 2 , ⋯ ∑ p k = 1 p_{k}\geq0,{k=1,2,\cdots}\\\sum{p_{k}=1} pk≥0,k=1,2,⋯∑pk=1 |
| 分布函数 | F ( x ) = P ( X ≤ x ) = ∑ x k ≤ x p k F(x)=P(X\leq{x})=\sum_{x_{k}\leq{x}}p_{k} F(x)=P(X≤x)=∑xk≤xpk | 0 ≤ F ( x ) ≤ 1 F ( x ) 单调,不减 F ( x ) 定义域左闭右开 0\leq{F(x)}\leq1\\F(x)单调,不减\\F(x)定义域左闭右开 0≤F(x)≤1F(x)单调,不减F(x)定义域左闭右开 |
| 概率 | P ( X ≤ a ) = F ( a ) P(X\leq{a})=F(a) P(X≤a)=F(a) | P ( X > a ) = 1 − F ( a ) P ( a < X ≤ b ) = F ( b ) − F ( a ) P(X>a)=1-F(a)\\P(a<X\leq{b})=F(b)-F(a) P(X>a)=1−F(a)P(a<X≤b)=F(b)−F(a) |

二项分布和泊松分布
| 名称 | 符号 | 分布律 | 含义 |
|---|---|---|---|
| 二项分布 | B ( n , p ) B(n,p) B(n,p) | P { X = k } = C n k p k q n − k , ( q = 1 − p , k = 0 , 1 , 2 , ⋯ ) P\{X=k\}=C_{n}^{k}{p^{k}q^{n-k}},\space(q=1-p,k=0,1,2,\cdots) P{X=k}=Cnkpkqn−k, (q=1−p,k=0,1,2,⋯) | n表示伯努利试验中A发生的次数 X ∼ B ( n , p ) X\sim{B(n,p)} X∼B(n,p), p p p表示每次试验中A发生的概率。 |
| 泊松分布 | P ( λ ) P(\lambda) P(λ) | P { X = k } = λ k e − λ k ! , ( λ > 0 , k = 0 , 1 , 2 , ⋯ ) P\{X=k\}=\frac{\lambda^{k}e^{-\lambda}}{k!},(\lambda>0,k=0,1,2,\cdots) P{X=k}=k!λke−λ,(λ>0,k=0,1,2,⋯) | 若 X ∼ B ( n , p ) X\sim{B(n,p)} X∼B(n,p),当 n n n较大, p p p较小时, X X X近似服从 P ( n p ) P(np) P(np) |
连续型随机变量分布函数的分布
| 名称 | 定义 | 性质 |
|---|---|---|
| 分布函数 | F ( x ) = P ( X ≤ x ) = ∫ − ∞ x f ( t ) d t F(x)=P(X\leq{x})=\int_{-\infty}^{x}{f(t)dt} F(x)=P(X≤x)=∫−∞xf(t)dt | 0 ≤ F ( x ) ≤ 1 F ( x ) 单调,不减 F ( x ) 定义域左闭右开 0\leq{F(x)}\leq1\\F(x)单调,不减\\F(x)定义域左闭右开 0≤F(x)≤1F(x)单调,不减F(x)定义域左闭右开 |
| 概率密度 | f ( x ) , − ∞ < x < + ∞ f(x),-\infty<x<+\infty f(x),−∞<x<+∞ | f ( x ) ≥ 0 ∫ − ∞ + ∞ f ( x ) d x = 1 若 f ( x ) 连续,则 F ′ ( x ) = f ( x ) f(x)\geq0\\\int_{-\infty}^{+\infty}f(x)dx=1\\若f(x)连续,则F\prime(x)=f(x) f(x)≥0∫−∞+∞f(x)dx=1若f(x)连续,则F′(x)=f(x) |
| 概率 | P ( X ) ≤ a = F ( a ) P(X)\leq{a}=F(a) P(X)≤a=F(a) | P ( X = a ) = 0 P ( X < a ) = P ( X ≤ a ) = 1 − F ( a ) P ( a < X ≤ b ) = P ( a ≤ X ≤ b ) = P ( a < X < b ) = F ( b ) − F ( a ) P(X=a)=0\\P(X<a)=P(X\leq{a})=1-F(a)\\P(a<X\leq{b})=P(a\leq{X}\leq{b})=P(a<X<b)=F(b)-F(a) P(X=a)=0P(X<a)=P(X≤a)=1−F(a)P(a<X≤b)=P(a≤X≤b)=P(a<X<b)=F(b)−F(a) |
分布函数法
通过给定的
Y
=
g
(
X
)
Y=g(X)
Y=g(X)和关于
X
X
X的概率密度函数来求关于
Y
Y
Y的分布函数和概率密度
因为关于
X
的概率密度函数有范围,根据这个范围和
Y
=
g
(
X
)
来求出
Y
的范围
F
Y
(
y
)
=
P
(
Y
≤
y
)
=
P
(
g
(
X
)
≤
y
)
=
P
(
X
∈
G
y
)
=
∫
G
y
f
X
(
x
)
d
x
由上式得出,关于
Y
的分布函数,求导得到概率密度
因为关于X的概率密度函数有范围,根据这个范围和Y=g(X)来求出Y的范围\\ F_{Y}(y)=P(Y\leq{y})=P(g(X)\leq{y})=P(X\in{G_{y}})=\int_{G_{y}}{f_{X}(x)dx}\\ 由上式得出,关于Y的分布函数,求导得到概率密度
因为关于X的概率密度函数有范围,根据这个范围和Y=g(X)来求出Y的范围FY(y)=P(Y≤y)=P(g(X)≤y)=P(X∈Gy)=∫GyfX(x)dx由上式得出,关于Y的分布函数,求导得到概率密度


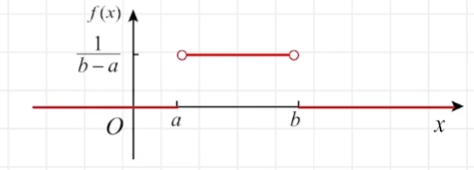
均匀分布
均匀分布
⋃
(
a
,
b
)
\bigcup(a,b)
⋃(a,b)的概率密度函数为:
f
(
x
)
=
{
0
,
其他
1
b
−
a
,
a
<
x
<
b
f(x)=\{^{\frac{1}{b-a},a<x<b}_{0,其他}
f(x)={0,其他b−a1,a<x<b
正态分布
正态分布
N
(
u
,
σ
2
)
N(u,\sigma^{2})
N(u,σ2)的概率密度函数为:
f
(
x
)
=
1
2
π
σ
e
−
(
x
−
μ
)
2
2
σ
2
,
(
−
∞
<
x
<
+
∞
)
f(x)=\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x-\mu)^{2}}{2\sigma^{2}}},(-\infty<x<+\infty)
f(x)=2πσ1e−2σ2(x−μ)2,(−∞<x<+∞)
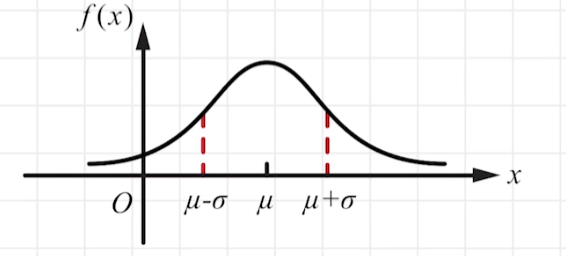
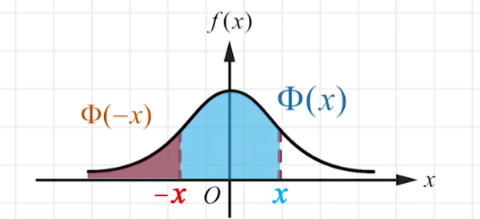
当 μ = 0 , σ = 1 \mu=0,\sigma=1 μ=0,σ=1时,称作标准正态分布,记作 N ( 0 , 1 ) N(0,1) N(0,1)
其分布函数为 Φ ( x ) = P ( X ≤ x ) \Phi(x)=P(X\leq{x}) Φ(x)=P(X≤x)
显然, Φ ( x ) + Φ ( − x ) = 1 \Phi(x)+\Phi(-x)=1 Φ(x)+Φ(−x)=1
若 X ∼ N ( μ , σ 2 ) X\sim{N(\mu,\sigma^{2})} X∼N(μ,σ2),则 X − μ σ ∼ N ( 0 , 1 ) \frac{X-\mu}{\sigma}\sim{N(0,1)} σX−μ∼N(0,1)
其分布函数可表示为:
F
(
x
)
=
P
(
X
≤
x
)
=
P
(
X
−
μ
σ
≤
x
−
μ
σ
)
=
Φ
(
x
−
μ
σ
)
F(x)=P(X\leq{x})=P(\frac{X-\mu}{\sigma}\leq{\frac{x-\mu}{\sigma}})=\Phi(\frac{x-\mu}{\sigma})
F(x)=P(X≤x)=P(σX−μ≤σx−μ)=Φ(σx−μ)

离散型随机变量函数的分布
设 X X X为一维离散型随机变量,其分布率为
| X X X | P P P |
|---|---|
| x 1 x_{1} x1 | p 1 p_{1} p1 |
| x 2 x_{2} x2 | p 2 p_{2} p2 |
| ⋯ \cdots ⋯ | ⋯ \cdots ⋯ |
那么函数 Y = g ( X ) Y=g(X) Y=g(X)的分布律就是
| g ( X ) g(X) g(X) | P P P |
|---|---|
| g ( x 1 ) g(x_{1}) g(x1) | p 1 p_{1} p1 |
| g ( x 2 ) g(x_{2}) g(x2) | p 2 p_{2} p2 |
| ⋯ \cdots ⋯ | ⋯ \cdots ⋯ |
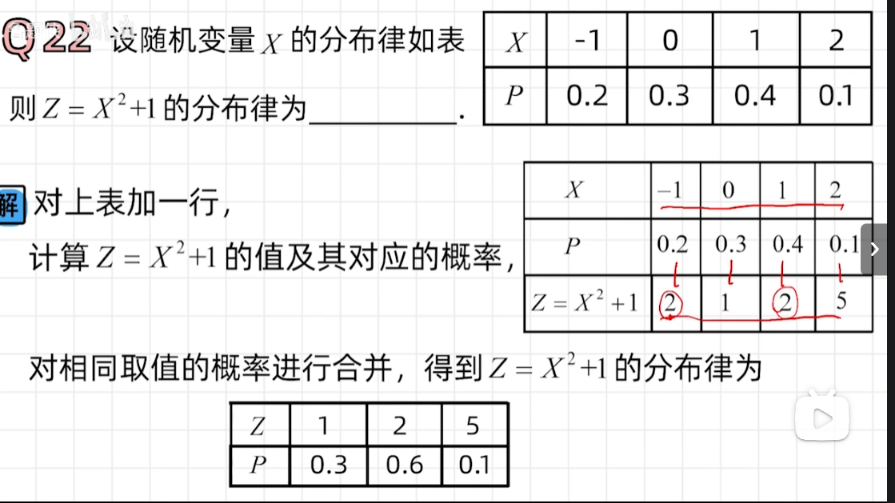
二维离散型随机变量的分布
| X X X | Y Y Y | P ( X i Y j ) P(X_{i}Y_{j}) P(XiYj) | P ( X = x i ) P(X=x_{i}) P(X=xi) | P ( Y = y j ) P(Y=y_{j}) P(Y=yj) |
|---|---|---|---|---|
| x 1 x_{1} x1 | y1 | P 11 P_{11} P11 | P ( x 1 ) = P 11 + P 12 P(x_{1})=P_{11}+P_{12} P(x1)=P11+P12 | |
| x 1 x_{1} x1 | y 2 y_{2} y2 | P 12 P_{12} P12 | P ( y 2 ) = P 12 + P 22 P(y_{2})=P_{12}+P_{22} P(y2)=P12+P22 | |
| x 2 x_{2} x2 | y 1 y_{1} y1 | P 21 P_{21} P21 | P ( y 1 ) = P 11 + P 21 P(y_{1})=P_{11}+P_{21} P(y1)=P11+P21 | |
| x 2 x_{2} x2 | y 2 y_{2} y2 | P 22 P_{22} P22 | P ( x 2 ) = P 21 + P 22 P(x_{2})=P_{21}+P_{22} P(x2)=P21+P22 | |
| ⋯ \cdots ⋯ | ⋯ \cdots ⋯ | P ⋯ P_{\cdots} P⋯ | ∑ P ( X = x i ) \sum{P(X=x_{i})} ∑P(X=xi) | ∑ P ( Y = y j ) \sum{P(Y=y_{j})} ∑P(Y=yj) |
两者概率总和结果为 1 ∑ P ( X = x i ) + ∑ P ( Y = y j ) = 1 X 和 Y 相互独立要满足,当 i j 取任意数字只要等于就相互独立 P ( X = x i , Y = y j ) = P ( X = x i ) ⋅ P ( Y = y j ) , ( 任意的 i , j = 1 , 2 , 3 , 4 ⋯ ) 两者概率总和结果为1\\ \sum{P(X=x_{i})}+\sum{P(Y=y_{j})}=1\\ X和Y相互独立要满足,当ij取任意数字只要等于就相互独立\\ P(X=x_{i},Y=y_{j})=P(X=x_{i})\cdot{P(Y=y_{j})},(任意的i,j=1,2,3,4\cdots) 两者概率总和结果为1∑P(X=xi)+∑P(Y=yj)=1X和Y相互独立要满足,当ij取任意数字只要等于就相互独立P(X=xi,Y=yj)=P(X=xi)⋅P(Y=yj),(任意的i,j=1,2,3,4⋯)
二维连续型随机变量的分布
联合分布函数: F ( x , y ) = P { X ≤ x , Y ≤ y } = ∫ − ∞ x ∫ − ∞ y f ( u , v ) d u d v 联合概率密度满足: f ( x , y ) ≥ 0 ; ∫ − ∞ + ∞ ∫ − ∞ + ∞ f ( x , y ) d x d y = 1 边缘概率密度: f X ( x ) = ∫ − ∞ + ∞ f ( x , y ) d y ; f Y ( y ) = ∫ − ∞ + ∞ f ( x , y ) d x ; 条件概率密度: f Y ∣ X ( y ∣ x ) = f ( x , y ) f X ( x ) ; f X ∣ Y ( x ∣ y ) = f ( x , y ) f Y ( y ) X 和 Y 相互独立 ⟺ f ( x , y ) = f X ( x ) f Y ( y ) 联合分布函数:F(x,y)=P\{X\leq{x},Y\leq{y}\}=\int_{-\infty}^{x}\int_{-\infty}^{y}f(u,v)dudv\\ 联合概率密度满足:f(x,y)\geq{0};\int_{-\infty}^{+\infty}\int_{-\infty}^{+\infty}f(x,y)dxdy=1\\ 边缘概率密度:f_{X}(x)=\int_{-\infty}^{+\infty}f(x,y)dy;f_{Y}(y)=\int_{-\infty}^{+\infty}f(x,y)dx;\\ 条件概率密度:f_{Y\vert{X}}(y\vert{x})=\frac{f(x,y)}{f_{X}(x)};f_{X\vert{Y}}(x\vert{y})=\frac{f(x,y)}{f_{Y}(y)}\\ X和Y相互独立\Longleftrightarrow{f(x,y)=f_{X}(x)f_{Y}(y)} 联合分布函数:F(x,y)=P{X≤x,Y≤y}=∫−∞x∫−∞yf(u,v)dudv联合概率密度满足:f(x,y)≥0;∫−∞+∞∫−∞+∞f(x,y)dxdy=1边缘概率密度:fX(x)=∫−∞+∞f(x,y)dy;fY(y)=∫−∞+∞f(x,y)dx;条件概率密度:fY∣X(y∣x)=fX(x)f(x,y);fX∣Y(x∣y)=fY(y)f(x,y)X和Y相互独立⟺f(x,y)=fX(x)fY(y)
离散型随机变量函数的分布
函数 U = g ( X , Y ) U=g(X,Y) U=g(X,Y)的分布律为 P { U = k } = P { g ( X , Y ) = k } P\{U=k\}=P\{g(X,Y)=k\} P{U=k}=P{g(X,Y)=k}
连续型随机变量函数的分布
求 Z = g ( X , Y ) Z=g(X,Y) Z=g(X,Y)的概率密度函数的步骤为:(分布函数法)
-
先求 Z = g ( X , Y ) Z=g(X,Y) Z=g(X,Y)的分布函数:
F ( z ) = P ( Z ≤ z ) = P ( g ( X , Y ) ≤ z ) = P ( ( X , Y ) ∈ G z ) = ∬ G z f ( x , y ) d x d y F(z)=P(Z\leq{z})=P(g(X,Y)\leq{z})=P((X,Y)\in{G_{z}})=\iint_{G_{z}}{f(x,y)dxdy} F(z)=P(Z≤z)=P(g(X,Y)≤z)=P((X,Y)∈Gz)=∬Gzf(x,y)dxdy -
求导得到 Z Z Z的概率密度函数: f ( z ) = F ′ ( z ) f(z)=F\prime(z) f(z)=F′(z)
若
X
,
Y
X,Y
X,Y相互独立,其分布函数分别为
F
X
(
x
)
F_{X}(x)
FX(x)和
F
Y
(
y
)
F_{Y}(y)
FY(y),则
Z
=
m
a
x
(
X
,
Y
)
Z=max(X,Y)
Z=max(X,Y)的分布函数为:
F
Z
(
z
)
=
P
(
m
a
x
(
X
,
Y
)
≤
z
)
=
P
(
X
≤
z
,
Y
≤
z
)
=
P
(
X
≤
z
)
P
(
Y
≤
z
)
=
F
X
(
z
)
F
Y
(
z
)
\begin{aligned} F_{Z}(z)=P(max(X,Y)\leq{z})&=P(X\leq{z},Y\leq{z})\\ &=P(X\leq{z})P(Y\leq{z})\\ &=F_{X}(z)F_{Y}(z) \end{aligned}
FZ(z)=P(max(X,Y)≤z)=P(X≤z,Y≤z)=P(X≤z)P(Y≤z)=FX(z)FY(z)
若
X
,
Y
X,Y
X,Y相互独立,其分布函数分别为
F
X
(
x
)
F_{X}(x)
FX(x)和
F
Y
(
y
)
F_{Y}(y)
FY(y),则
Z
=
m
i
n
(
X
,
Y
)
Z=min(X,Y)
Z=min(X,Y)的分布函数为:
F
Z
(
z
)
=
P
(
m
i
n
(
X
,
Y
)
≤
z
)
=
1
−
P
(
m
i
n
(
X
,
Y
)
>
z
)
=
1
−
P
(
X
>
z
,
Y
>
z
)
=
1
−
P
(
X
>
z
)
P
(
Y
>
z
)
=
1
−
[
1
−
F
X
(
z
)
]
[
1
−
F
Y
(
z
)
]
\begin{aligned} F_{Z}(z)=P(min(X,Y)\leq{z})&=1-P(min(X,Y)>z)\\ &=1-P(X>z,Y>z)\\ &=1-P(X>z)P(Y>z)\\ &=1-[1-F_{X}(z)][1-F_{Y}(z)] \end{aligned}
FZ(z)=P(min(X,Y)≤z)=1−P(min(X,Y)>z)=1−P(X>z,Y>z)=1−P(X>z)P(Y>z)=1−[1−FX(z)][1−FY(z)]
正态分布的可加性:设
X
∼
N
(
μ
,
σ
1
2
)
,
X
∼
N
(
μ
2
,
σ
2
2
)
X\sim{N}(\mu,\sigma_1^2),X\sim{N}(\mu_2,\sigma_2^2)
X∼N(μ,σ12),X∼N(μ2,σ22),且
X
,
Y
X,Y
X,Y相互独立,则
X
+
Y
∼
N
(
μ
1
+
μ
2
,
σ
1
2
+
σ
2
2
)
X+Y\sim{N}(\mu_1+\mu_2,\sigma_1^2+\sigma_2^2)
X+Y∼N(μ1+μ2,σ12+σ22)
数学期望
离散型随机变量的期望: E ( X ) = ∑ i = 1 ∞ x i p i E(X)=\sum_{i=1}^{\infty}{x_{i}p_{i}} E(X)=∑i=1∞xipi
连续型随机变量的期望: E ( X ) = ∫ − ∞ + ∞ x f ( x ) d x E(X)=\int_{-\infty}^{+\infty}{xf(x)dx} E(X)=∫−∞+∞xf(x)dx
期望的性质:
- E ( C ) = C E(C)=C E(C)=C, C C C为常数
- E ( C X ) = C E ( X ) E(CX)=CE(X) E(CX)=CE(X), C C C为常数
- E ( X + Y ) = E ( X ) + E ( Y ) E(X+Y)=E(X)+E(Y) E(X+Y)=E(X)+E(Y)
- 设 X , Y X,Y X,Y相互独立,则 E ( X Y ) = E ( X ) E ( Y ) E(XY)=E(X)E(Y) E(XY)=E(X)E(Y)

方差和标准差
方差: D ( X ) = E [ X − E ( X ) ] 2 = E ( X 2 ) − [ E ( X ) ] 2 D(X)=E[X-E(X)]^{2}=E(X^{2})-[E(X)]^{2} D(X)=E[X−E(X)]2=E(X2)−[E(X)]2
标准差: σ = D ( X ) \sigma=\sqrt{D(X)} σ=D(X)
性质:
- D ( C ) = 0 D(C)=0 D(C)=0, C C C为常数
- D ( X + C ) = D ( X ) D(X+C)=D(X) D(X+C)=D(X), C C C为常数
- D ( C X ) = C 2 E ( X ) D(CX)=C^{2}E(X) D(CX)=C2E(X), C C C为常数
- D ( X ± Y ) = D ( X ) + D ( Y ) ± 2 E { [ X − E ( X ) ] [ Y − E ( Y ) ] } D(X\pm{Y})=D(X)+D(Y)\pm{2E\{[X-E(X)][Y-E(Y)]\}} D(X±Y)=D(X)+D(Y)±2E{[X−E(X)][Y−E(Y)]}
- 设 X , Y X,Y X,Y相互独立,则 D ( X ± Y ) = D ( X ) + D ( Y ) D(X\pm{Y})=D(X)+D(Y) D(X±Y)=D(X)+D(Y)
常用的分布的期望和方差
| 分布 | 分布律或概率密度 | 数学期望 | 方差 |
|---|---|---|---|
| 0-1分布 | P { x = k } = p k ( 1 − p ) 1 − k , ( k = 0 , 1 ) P\{x=k\}=p^{k}(1-p)^{1-k},(k=0,1) P{x=k}=pk(1−p)1−k,(k=0,1) | p p p | p ( 1 − p ) p(1-p) p(1−p) |
| 二项分布 B ( n , p ) B(n,p) B(n,p) | P { x = k } = C n k p k ( 1 − p ) 1 − k P\{x=k\}=C_{n}^{k}{p^{k}(1-p)^{1-k}} P{x=k}=Cnkpk(1−p)1−k | n p np np | n p ( 1 − p ) np(1-p) np(1−p) |
| 泊松分布 P ( λ ) P(\lambda) P(λ) | P { x = k } = λ k e − λ k ! P\{x=k\}=\frac{\lambda^{k}e^{-\lambda}}{k!} P{x=k}=k!λke−λ | λ \lambda λ | λ \lambda λ |
| 均匀分布 U ( a , b ) U(a,b) U(a,b) | f ( x ) = 1 b − a , ( a < x < b ) f(x)=\frac{1}{b-a},(a<x<b) f(x)=b−a1,(a<x<b) | a + b 2 \frac{a+b}{2} 2a+b | ( b − a ) 2 12 \frac{(b-a)^{2}}{12} 12(b−a)2 |
| 正态分布 N ( μ , σ 2 ) N(\mu,\sigma^{2}) N(μ,σ2) | f ( x ) = 1 2 π σ e ( x − μ ) 2 2 σ 2 f(x)=\frac{1}{\sqrt{2\pi}\sigma}e^{\frac{(x-\mu)^{2}}{2\sigma^2}} f(x)=2πσ1e2σ2(x−μ)2 | μ \mu μ | σ 2 \sigma^{2} σ2 |
| 指数分布 E ( θ ) E(\theta) E(θ) | f ( x ) = { θ e − θ x , x > 0 0 , 其他 f(x)=\begin{cases}\theta{e^{-\theta{x}}},x>0\\0,其他\end{cases} f(x)={θe−θx,x>00,其他 | 1 θ \frac{1}{\theta} θ1 | 1 θ 2 \frac{1}{\theta^{2}} θ21 |
协方差和相关系数
协方差: C o v ( X , Y ) = E ( X Y ) − E ( X ) E ( Y ) Cov(X,Y)=E(XY)-E(X)E(Y) Cov(X,Y)=E(XY)−E(X)E(Y)
协方差的性质:
- C o v ( X , C ) = 0 Cov(X,C)=0 Cov(X,C)=0, C C C为常数
- C o v ( a X , b Y ) = a b C o v ( X , Y ) Cov(aX,bY)=abCov(X,Y) Cov(aX,bY)=abCov(X,Y), a , b a,b a,b为常数
- C o v ( X 1 + X 2 , Y ) = C o v e ( X 1 , Y ) + C o v ( X 2 , Y ) Cov(X_1+X_2,Y)=Cove(X_1,Y)+Cov(X_2,Y) Cov(X1+X2,Y)=Cove(X1,Y)+Cov(X2,Y)
- D ( X ± Y ) = D ( X ) + D ( Y ) ± 2 C o v ( X , Y ) D(X\pm{Y})=D(X)+D(Y)\pm{2Cov(X,Y)} D(X±Y)=D(X)+D(Y)±2Cov(X,Y)
- 若 X X X与 Y Y Y相互独立,则 C o v ( X , Y ) = 0 Cov(X,Y)=0 Cov(X,Y)=0
相关系数: ρ X Y = C o v ( X , Y ) D ( X ) ⋅ D ( Y ) \rho_{XY}=\frac{Cov(X,Y)}{\sqrt{D(X)}\cdot{\sqrt{D(Y)}}} ρXY=D(X)⋅D(Y)Cov(X,Y)
中心极限定理
设随即变量 X 1 , X 2 , ⋯ X_1,X_2,\cdots X1,X2,⋯独立同分布, E ( X k ) = μ E(X_k)=\mu E(Xk)=μ, D ( X k ) = σ 2 ≠ 0 , ( k = 1 , 2 , ⋯ ) D(X_k)=\sigma^2\neq0,(k=1,2,\cdots) D(Xk)=σ2=0,(k=1,2,⋯),则当 n n n充分大时,近似有 ∑ k = 1 n X k ∼ N ( n μ , n σ 2 ) \sum_{k=1}^{n}{X_k\sim{N}(n\mu,n\sigma^2)} ∑k=1nXk∼N(nμ,nσ2),即 ∑ k = 1 n X k − n μ n σ ∼ N ( 0 , 1 ) \frac{\sum_{k=1}^{n}{X_k-n\mu}}{\sqrt{n}\sigma}\sim{N(0,1)} nσ∑k=1nXk−nμ∼N(0,1)
设随机变量 X ∼ B ( n , p ) X\sim{B(n,p)} X∼B(n,p),则当 n n n充分大时,近似有 X ∼ N ( n p , n p q ) X\sim{N(np,npq)} X∼N(np,npq),即 X − n p n p q ∼ N ( 0 , 1 ) \frac{X-np}{\sqrt{npq}}\sim{N(0,1)} npqX−np∼N(0,1)

三大分布
X 2 ( n ) X^2(n) X2(n)分布:
若 X 1 , X 2 , ⋯ , X n X_1,X_2,\cdots,X_n X1,X2,⋯,Xn相互独立,且 X i ∼ N ( 0 , 1 ) , ( i = 1 , 2 , ⋯ ) X_i\sim{N(0,1),(i=1,2,\cdots)} Xi∼N(0,1),(i=1,2,⋯),则 X 1 2 , X 2 2 , ⋯ , X n 2 ∼ X 2 ( n ) X_1^2,X_2^2,\cdots,X_n^2\sim{X^2(n)} X12,X22,⋯,Xn2∼X2(n)
t ( n ) t(n) t(n)分布:
设 X ∼ N ( 0 , 1 ) , Y ∼ X 2 ( n ) X\sim{N(0,1),Y\sim{X^2(n)}} X∼N(0,1),Y∼X2(n), X , Y X,Y X,Y相互独立,则称 T = X Y / n ∼ t ( n ) T=\frac{X}{\sqrt{Y/n}}\sim{t(n)} T=Y/nX∼t(n)
F F F分布:
设 X ∼ X 1 2 ( n 1 ) , Y ∼ X 2 2 ( n 2 ) X\sim{X_1^2(n_1)},Y\sim{X_2^2(n_2)} X∼X12(n1),Y∼X22(n2), X , Y X,Y X,Y相互独立,则 F = X / n 1 Y / n 2 ∼ F ( n 1 , n 2 ) F=\frac{X/n_1}{Y/n_2}\sim{F(n_1,n_2)} F=Y/n2X/n1∼F(n1,n2)
矩估计
求解步骤:
- 写出总体一阶矩 E ( X ) = g ( θ ) E(X)=g(\theta) E(X)=g(θ),和样本一阶矩 X ‾ = ∑ i = 1 n X i / n \overline{X}=\sum_{i=1}^{n}{X_i/n} X=∑i=1nXi/n
- 令总体矩=样本矩,即 g ( θ ) = X ‾ g(\theta)=\overline{X} g(θ)=X,反解出估计量 θ ^ = h ( X ‾ ) \widehat{\theta}=h(\overline{X}) θ =h(X)
- 将 X ‾ \overline{X} X具体值代入 θ ^ = h ( X ‾ ) \widehat{\theta}=h(\overline{X}) θ =h(X),得到估计值
无偏估计:如果 E ( θ ^ ) = θ E(\widehat{\theta})=\theta E(θ )=θ,则称 θ ^ \widehat{\theta} θ 为 θ \theta θ的无偏估计量。


极大似然估计
离散型总体的最大似然估计步骤
- 设离散性总体 X X X的分布律为 P { X = x } = p ( X , θ ) P\{X=x\}=p(X,\theta) P{X=x}=p(X,θ),其中 θ \theta θ为未知参数,设 x 1 , x 2 , ⋯ , x n x_1,x_2,\cdots,x_n x1,x2,⋯,xn是一组样本观测值
- 计算似然函数 L ( θ ) = ∏ i = 1 n p ( x i , θ ) L(\theta)=\prod_{i=1}^{n}{p(x_i,\theta)} L(θ)=∏i=1np(xi,θ)
- 对似然函数取对数得到 l n L ( θ ) = ∑ i = 1 n l n p ( x i , θ ) lnL(\theta)=\sum_{i=1}^{n}lnp(x_i,\theta) lnL(θ)=∑i=1nlnp(xi,θ)
- 令 d d θ l n L ( θ ) = 0 \frac{d}{d\theta}{lnL(\theta)}=0 dθdlnL(θ)=0,解出最大似然估计 θ ^ \widehat\theta θ
连续型总体的最大似然估计步骤
- 设连续性总体 X X X的分布律为 f ( x , θ ) f(x,\theta) f(x,θ),其中 θ \theta θ为未知参数,设 x 1 , x 2 , ⋯ , x n x_1,x_2,\cdots,x_n x1,x2,⋯,xn是一组样本观测值
- 计算似然函数 L ( θ ) = ∏ i = 1 n f ( x i , θ ) L(\theta)=\prod_{i=1}^{n}{f(x_i,\theta)} L(θ)=∏i=1nf(xi,θ)
- 对似然函数取对数得到 l n L ( θ ) = ∑ i = 1 n l n f ( x i , θ ) lnL(\theta)=\sum_{i=1}^{n}lnf(x_i,\theta) lnL(θ)=∑i=1nlnf(xi,θ)
- 令 d d θ l n L ( θ ) = 0 \frac{d}{d\theta}{lnL(\theta)}=0 dθdlnL(θ)=0,解出最大似然估计 θ ^ \widehat\theta θ



假设检验
假设检验的步骤
- 根据题意构造原假设 H 0 H_0 H0和它的对立假设 H 1 H_1 H1
- 按照下表构造检验统计量
- 给定显著性水平 α \alpha α,写出拒绝域
- 带入样本观察值,算出统计量的具体值
- 如果该值落入拒绝域,则拒绝原假设
- 否则接受原假设
| 检验参数 | 检验参数 | 原假设与备择假设 | 计算统计量的值 | 拒绝域W |
|---|---|---|---|---|
| 均值 μ \mu μ | σ 2 \sigma^2 σ2已知 | H 0 : μ = μ 0 H 1 : μ ≠ μ 0 H_0:\mu=\mu_0\space{H_1:\mu\neq{\mu_0}} H0:μ=μ0 H1:μ=μ0 | z = X ‾ − μ 0 σ / n z=\frac{\overline{X}-\mu_0}{\sigma/\sqrt{n}} z=σ/nX−μ0 | ∣ z ∣ > u 1 − α 2 \vert{z}\vert>u_{1-\frac{\alpha}{2}} ∣z∣>u1−2α |
| 均值 μ \mu μ | σ 2 \sigma^2 σ2已知 | H 0 : μ = μ 0 H 1 : μ > μ 0 H_0:\mu=\mu_0\space{H_1:\mu>{\mu_0}} H0:μ=μ0 H1:μ>μ0 | z = X ‾ − μ 0 σ / n z=\frac{\overline{X}-\mu_0}{\sigma/\sqrt{n}} z=σ/nX−μ0 | z > u 1 − α z>u_{1-\alpha} z>u1−α |
| 均值 μ \mu μ | σ 2 \sigma^2 σ2已知 | H 0 : μ = μ 0 H 1 : μ < μ 0 H_0:\mu=\mu_0\space{H_1:\mu<{\mu_0}} H0:μ=μ0 H1:μ<μ0 | z = X ‾ − μ 0 σ / n z=\frac{\overline{X}-\mu_0}{\sigma/\sqrt{n}} z=σ/nX−μ0 | z < − u 1 − α z<-u_{1-\alpha} z<−u1−α |
| 均值 μ \mu μ | σ 2 \sigma^2 σ2未知 | H 0 : μ = μ 0 H 1 : μ ≠ μ 0 H_0:\mu=\mu_0\space{H_1:\mu\neq{\mu_0}} H0:μ=μ0 H1:μ=μ0 | t = X ‾ − μ 0 S / n t=\frac{\overline{X}-\mu_0}{S/\sqrt{n}} t=S/nX−μ0 | ∣ t ∣ < t 1 − α 2 ( n − 1 ) \vert{t}\vert<t_{1-\frac{\alpha}{2}}(n-1) ∣t∣<t1−2α(n−1) |
| 均值 μ \mu μ | σ 2 \sigma^2 σ2未知 | H 0 : μ = μ 0 H 1 : μ > μ 0 H_0:\mu=\mu_0\space{H_1:\mu>{\mu_0}} H0:μ=μ0 H1:μ>μ0 | t = X ‾ − μ 0 S / n t=\frac{\overline{X}-\mu_0}{S/\sqrt{n}} t=S/nX−μ0 | t > − t 1 − a ( n − 1 ) t>-t_{1-a}(n-1) t>−t1−a(n−1) |
| 均值 μ \mu μ | σ 2 \sigma^2 σ2未知 | H 0 : μ = μ 0 H 1 : μ < μ 0 H_0:\mu=\mu_0\space{H_1:\mu<{\mu_0}} H0:μ=μ0 H1:μ<μ0 | t = X ‾ − μ 0 S / n t=\frac{\overline{X}-\mu_0}{S/\sqrt{n}} t=S/nX−μ0 | t < − t 1 − a ( n − 1 ) t<-t_{1-a}(n-1) t<−t1−a(n−1) |
u α u_{\alpha} uα是标准正态分布的 α \alpha α分位数; t α ( n − 1 ) t_{\alpha}(n-1) tα(n−1)是自由度为 n − 1 n-1 n−1的 t t t分布的 α \alpha α分位数
| 检验参数 | 检验参数 | 原假设与备择假设 | 计算统计量的值 | 拒绝域W |
|---|---|---|---|---|
| 方差 σ 2 \sigma^2 σ2 | μ \mu μ已知 | H 0 : σ 2 = σ 0 2 H 1 : σ 2 ≠ σ 0 2 H_0:\sigma^2=\sigma_0^2\space{H_1:\sigma^2\neq{\sigma_0^2}} H0:σ2=σ02 H1:σ2=σ02 | X 2 = ∑ i = 1 n ( X i − μ ) 2 σ 0 2 X^2=\frac{\sum_{i=1}^{n}{(X_i-\mu)^2}}{\sigma_0^2} X2=σ02∑i=1n(Xi−μ)2 | X 2 < X α x 2 ( n ) 或 X 2 > X 1 − α 2 2 ( n ) X^2<X_{\frac{\alpha}{x}}^2(n)或X^2>X_{1-\frac{\alpha}{2}}^2(n) X2<Xxα2(n)或X2>X1−2α2(n) |
| 方差 σ 2 \sigma^2 σ2 | μ \mu μ已知 | H 0 : σ 2 = σ 0 2 H 1 : σ 2 > σ 0 2 H_0:\sigma^2=\sigma_0^2\space{H_1:\sigma^2>{\sigma_0^2}} H0:σ2=σ02 H1:σ2>σ02 | X 2 = ∑ i = 1 n ( X i − μ ) 2 σ 0 2 X^2=\frac{\sum_{i=1}^{n}{(X_i-\mu)^2}}{\sigma_0^2} X2=σ02∑i=1n(Xi−μ)2 | X 2 > X 1 − α 2 ( n ) X^2>X_{1-\alpha}^2(n) X2>X1−α2(n) |
| 方差 σ 2 \sigma^2 σ2 | μ \mu μ已知 | H 0 : σ 2 = σ 0 2 H 1 : σ 2 < σ 0 2 H_0:\sigma^2=\sigma_0^2\space{H_1:\sigma^2<{\sigma_0^2}} H0:σ2=σ02 H1:σ2<σ02 | X 2 = ∑ i = 1 n ( X i − μ ) 2 σ 0 2 X^2=\frac{\sum_{i=1}^{n}{(X_i-\mu)^2}}{\sigma_0^2} X2=σ02∑i=1n(Xi−μ)2 | X 2 < X α 2 ( n ) X^2<X_{\alpha}^2(n) X2<Xα2(n) |
| 方差 σ 2 \sigma^2 σ2 | μ \mu μ未知 | H 0 : σ 2 = σ 0 2 H 1 : σ 2 ≠ σ 0 2 H_0:\sigma^2=\sigma_0^2\space{H_1:\sigma^2\neq{\sigma_0^2}} H0:σ2=σ02 H1:σ2=σ02 | X 2 = ∑ i = 1 n ( X i − X ‾ ) 2 σ 0 2 X^2=\frac{\sum_{i=1}^{n}{(X_i-\overline{X})^2}}{\sigma_0^2} X2=σ02∑i=1n(Xi−X)2 | X 2 < X α x 2 ( n − 1 ) 或 X 2 > X 1 − α 2 2 ( n − 1 ) X^2<X_{\frac{\alpha}{x}}^2(n-1)或X^2>X_{1-\frac{\alpha}{2}}^2(n-1) X2<Xxα2(n−1)或X2>X1−2α2(n−1) |
| 方差 σ 2 \sigma^2 σ2 | μ \mu μ未知 | H 0 : σ 2 = σ 0 2 H 1 : σ 2 > σ 0 2 H_0:\sigma^2=\sigma_0^2\space{H_1:\sigma^2>{\sigma_0^2}} H0:σ2=σ02 H1:σ2>σ02 | X 2 = ∑ i = 1 n ( X i − X ‾ ) 2 σ 0 2 X^2=\frac{\sum_{i=1}^{n}{(X_i-\overline{X})^2}}{\sigma_0^2} X2=σ02∑i=1n(Xi−X)2 | X 2 > X 1 − α 2 ( n − 1 ) X^2>X_{1-\alpha}^2(n-1) X2>X1−α2(n−1) |
| 方差 σ 2 \sigma^2 σ2 | μ \mu μ未知 | H 0 : σ 2 = σ 0 2 H 1 : σ 2 < σ 0 2 H_0:\sigma^2=\sigma_0^2\space{H_1:\sigma^2<{\sigma_0^2}} H0:σ2=σ02 H1:σ2<σ02 | X 2 = ∑ i = 1 n ( X i − X ‾ ) 2 σ 0 2 X^2=\frac{\sum_{i=1}^{n}{(X_i-\overline{X})^2}}{\sigma_0^2} X2=σ02∑i=1n(Xi−X)2 | X 2 < X α 2 ( n − 1 ) X^2<X_{\alpha}^2(n-1) X2<Xα2(n−1) |
X α 2 ( n ) X_{\alpha}^2(n) Xα2(n)是自由度为 n n n的 X 2 X^2 X2分布的 α \alpha α分位数

















 2438
2438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











