






**
股票数据爬取
**
1.大作业目的
从网易股票爬取股票信息,包括每只股票的代码、名称、价格、涨跌幅、涨跌额;
2.大作业内容
(1) 从网易股票爬取股票信息,包括每只股票的代码,名称,价格,涨跌幅,涨跌额;
链接: 点击此处
(2) 根据成交额对获取到的股票进行排序;
(3) 将结果存储到csv文件中;
(4) 将结果存储到MySQL或MongoDB数据库里;
(5) 创新性设计与实现(如代理,异步携协程,分布式爬虫等)。
3.需求分析
实现爬取网易股票数据的需求
根据大作业要求,完成指定内容的爬取和保存,并撰写大作业报告,要求内容翔实,条理清晰,图文并茂(用例图、流程图、效果截图),主要(关键代码)须有详细注释,写清楚测试结果,并对存在的问题及后续需改进的方面进行分析。
1)完成相关模块和第三方库的安装配置;
2)通过相关技术完成源码的爬取;
3)实现指定内容的提取;
4)实现数据的保存;
2、问题的解决方案:
根据系统功能要求,可以将问题解决分为以下步骤:
(1) 完成爬虫的设计;
(2) 完成相关爬虫的部署;
(3) 根据问题描述,设计提取方法;
(4) 将结果存入文件及数据库中;
(5) 功能调试;
(6) 完成大作业总结报告。
4.实现思路
1、问题描述(功能要求):
(1)完成相关模块和第三方库的安装配置;
(2)通过相关技术完成源码的爬取;
(3)实现指定内容的提取;
(4)实现数据的保存;
2、问题的解决方案:
根据系统功能要求,可以将问题解决分为以下步骤:
(1) 根据问题描述,设计提取方法;
(2) 将结果存入文件及数据库中;
(3) 进行数据分析并生成可视化图像
(4) 功能调试;
环境介绍:python 3.9
pycharm
requests
csv
MySQL
5.详细实现
(1)打开网易股票网易股票网址链接: link
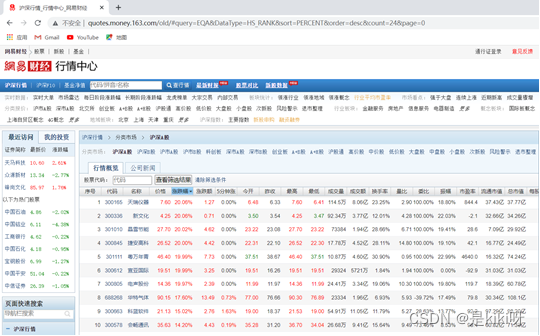
(2)<分析网页性质>
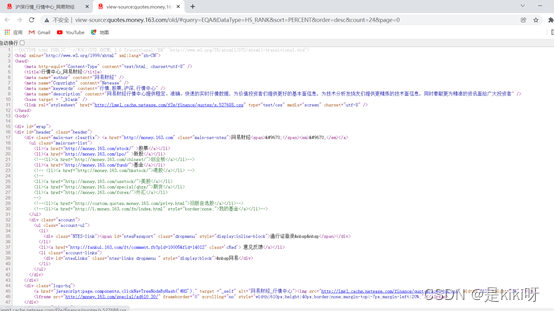
发现窗口中都是静态数据,找不到数据所在地址
股票首页都是动态展示的数据
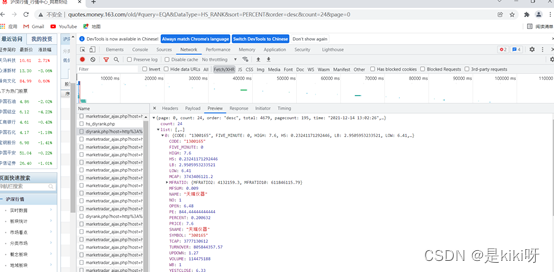
(3)打开开发者工具
找到要爬取的股票,network(浏览器自带的抓包工具)->Fetch/XHR->Preview->Headers ,找到请求字段,获取URL和User-Agent
(4)pycharm安装好requests等工具和开发环境和配置文件。调用scrapy、csv、selenium、webdriver、time、HtmlResponse、WordCloud、ItemAdapter、adbapi、MySQLab、matplotlib等函数库
根据要求,设定要爬取的内容和格式
 确定URL地址
确定URL地址
发送网络请求

数据解析
将结果存储在CSV文件中
使根据成交额对获取到的股票进行排序;
创建数据库表
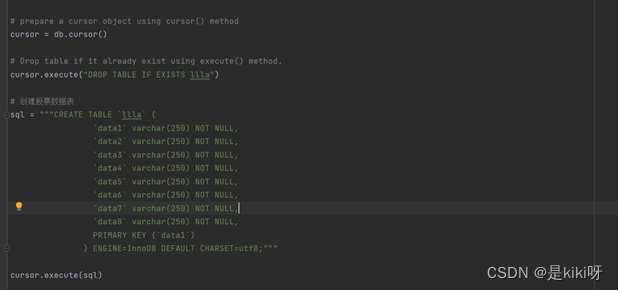
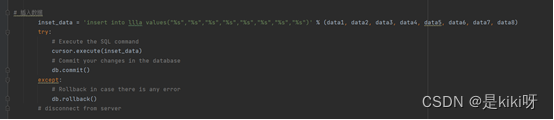
将结果存储到MySQL数据库里;
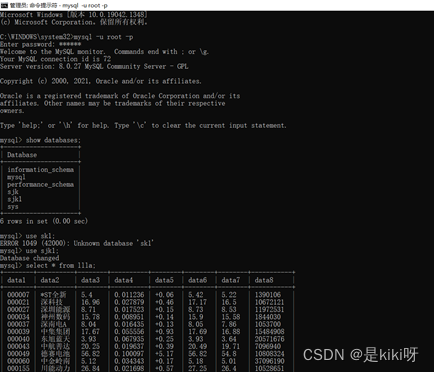
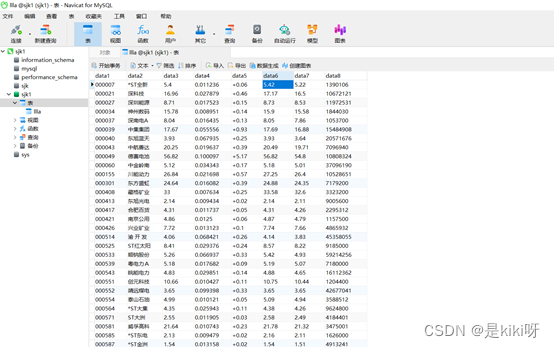
数据可视化 从MySQL中读取所需数据存入列表中
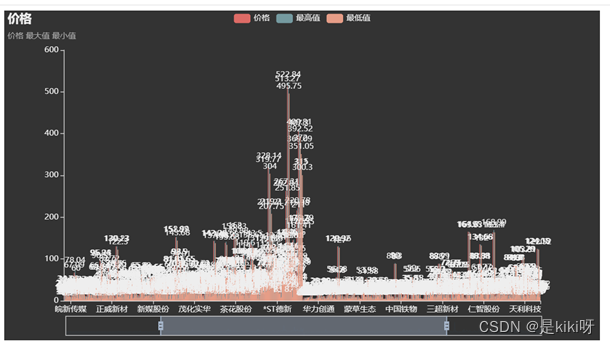
价格可视化
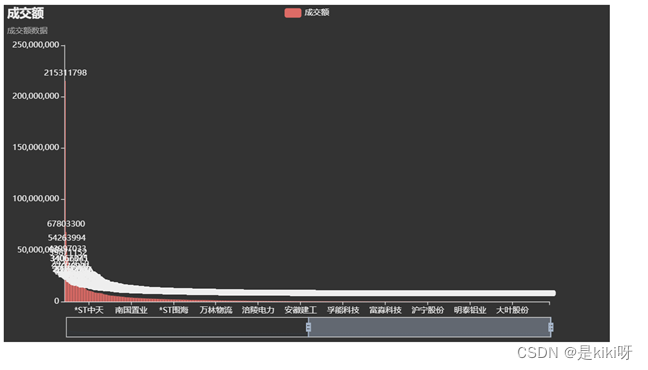
成交额可视化
6. 源代码
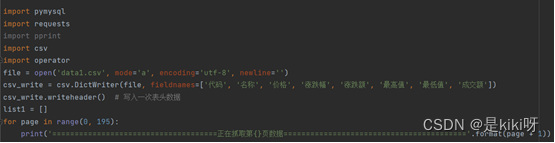
import pymysql
import requests
#导入request工具
import pprint
import csv
import operator
file = open('data1.csv', mode='a', encoding='utf-8', newline='')
csv_write = csv.DictWriter(file, fieldnames=['代码', '名称', '价格', '涨跌幅', '涨跌额', '最高值', '最低值', '成交额'])
csv_write.writeheader() # 写入一次表头数据
list1 = []
# 连接数据库
db=pymysql.connect(host='127.0.0.1',port=3306,user='root', password='123456', db='sjk1',charset='utf8') # charset 是编码
# prepare a cursor object using cursor() method
cursor = db.cursor()
# Drop table if it already exist using execute() method.
cursor.execute("DROP TABLE IF EXISTS llla")
# 创建股票数据表
sql = """CREATE TABLE `llla` (
`data1` varchar(250) NOT NULL,
`data2` varchar(250) NOT NULL,
`data3` varchar(250) NOT NULL,
`data4` varchar(250) NOT NULL,
`data5` varchar(250) NOT NULL,
`data6` varchar(250) NOT NULL,
`data7` varchar(250) NOT NULL,
`data8` varchar(250) NOT NULL,
PRIMARY KEY (`data1`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;"""
cursor.execute(sql)
for page in range(0, 195):
print('=====================================正在抓取第{}页数据========================================='.format(page + 1))
# 1.确定url地址
url = 'http://quotes.money.163.com/hs/service/diyrank.php?host=http://quotes.money.163.com/hs/service/diyrank.php' \
'&page={}&query=STYPE:EQA&fields=NO,SYMBOL,NAME,PRICE,PERCENT,UPDOWN,FIVE_MINUTE,OPEN,YESTCLOSE,HIGH,LOW,' \
'VOLUME,TURNOVER,HS,LB,WB,ZF,PE,MCAP,TCAP,MFSUM,MFRATIO.MFRATIO2,MFRATIO.MFRATIO10,SNAME,CODE,ANNOUNMT,' \
'UVSNEWS&sort=PERCENT&order=desc&count=24&type=query'.format(page)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/96.0.4664.93 Safari/537.36'}
# 2.发送网络请求
response = requests.get(url=url, headers=headers)
json_data = response.json()
# pprint.pprint(json_data)
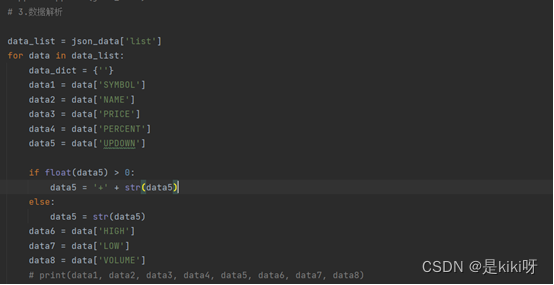
# 3.数据解析
data_list = json_data['list']
for data in data_list:
data_dict = {''}
data1 = data['SYMBOL']
data2 = data['NAME']
data3 = data['PRICE']
data4 = data['PERCENT']
data5 = data['UPDOWN']
if float(data5) > 0:
data5 = '+' + str(data5)
else:
data5 = str(data5)
data6 = data['HIGH']
data7 = data['LOW']
data8 = data['VOLUME']
# print(data1, data2, data3, data4, data5, data6, data7, data8)
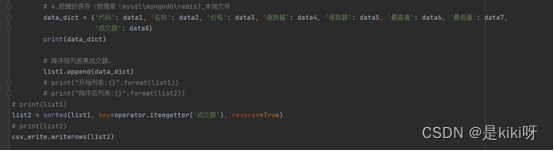
# 4.数据的保存(数据库(mysql\mongodb\redis),本地文件
data_dict = {'代码': data1, '名称': data2, '价格': data3, '涨跌幅': data4, '涨跌额': data5, '最高值': data6, '最低值': data7,'成交额': data8}
print(data_dict)
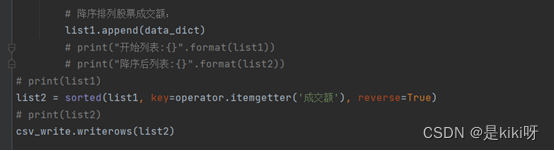
# 降序排列股票成交额:
list1.append(data_dict)
# print("开始列表:{}".format(list1))
# print("降序后列表:{}".format(list2))
# 插入数据
inset_data = 'insert into llla values("%s","%s","%s","%s","%s","%s","%s","%s")' % (data1, data2, data3, data4, data5, data6, data7, data8)
try:
# Execute the SQL command
cursor.execute(inset_data)
# Commit your changes in the database
db.commit()
except:
# Rollback in case there is any error
db.rollback()
# disconnect from server
# print(list1)
list2 = sorted(list1, key=operator.itemgetter('成交额'), reverse=True)
# print(list2)
csv_write.writerows(list2)
db.close()
运行
(1)运行过程:
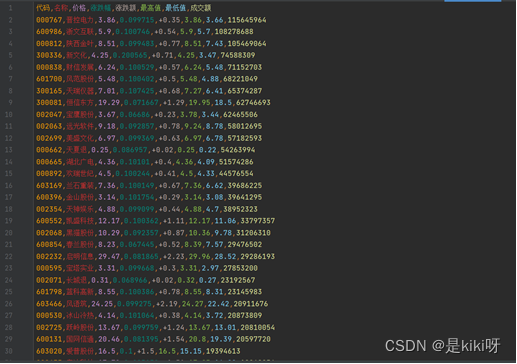
(2)Csv存储
保存到csv文件
将所爬取数据按照’代码’, ‘名称’, ‘价格’, ‘涨跌幅’, ‘涨跌额’, ‘最高值’, ‘最低值’, '成交额’分栏保存到文件中。
(3)Mysql存储
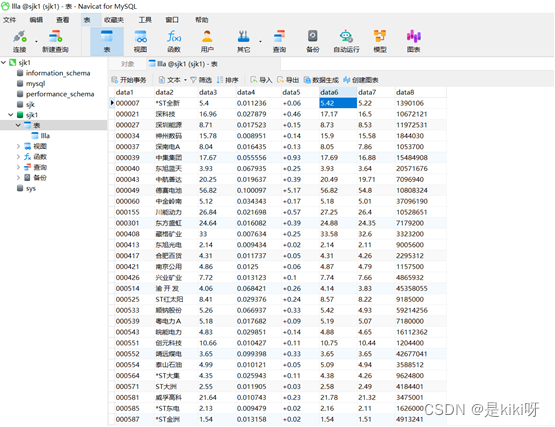
利用异步储存的方法将数据按表格分栏进行储存。
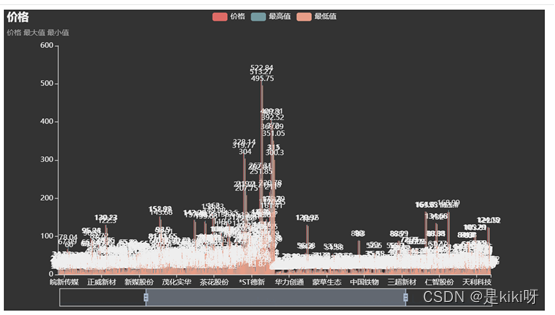
(4)数据可视化
1.生成的所爬取股票价格的柱状图等
小结
本次对股票数据进行爬取作业,使用到的工具主要有python,pycharm,csv,和MySQL,涉及的知识有爬取全站,获取正确的URL,用字典或者导入数据库进行排序,为了加快多项数据运行效率,我添加了异步协程。也让我对正则化表达式有了更深的理解,并且学习到很多新的知识,还有很多python和MySQL的语法需要我格外注意,也明白了平时要多学多问,向老师和同学请教。















 8273
8273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









