







知识点05:Git管理的组成结构
掌握Git
本地版本控制Git服务器
工作区【Work Dir】:就是你开发和修改代码的地方
暂存区【Index】:临时存放你即将提交的版本的地方
所有需要保存的版本必须先添加到暂存区
本地版本仓库【HEAD】:本地的版本库,实现本地的版本的管理
所有暂存区的版本会被提交到本地版本库
远程版本仓库:用于共享项目代码版本
GitHub、Gitee
管理版本的组成结构
知识点06:本地仓库构建几种方式
基于自己的笔记本,在本地操作系统中实现Git本地仓库的构建
-
step1:准备
-
每个项目都可以基于Git构建版本库,每个项目都可以做版本管理
-
先创建一个目录,再创建三个子目录【三个本地库】
-
-
本地库只要构建成功就会创建一个 隐藏目录.git
修改配置 打开显示隐藏的项目
知识点07:Git基本操作--添加、提交
实现在Git本地工作区,添加文件到本地仓库
#添加一个或者多个文件到暂存区
git add [file1] [file2] ...#添加指定目录到暂存区,包括子目录
git add [dir]#添加当前目录下的所有文件到暂存区
git add .#如何嫌命令难记,也可以使用下述的tortoiseGit工具操作
注意啊,这里点确定表示添加到暂存区,点击提交就一步提交到仓库了。
#前面我们使用 git add 命令将内容写入暂存区。
#git commit 命令将暂存区内容添加到本地仓库中。
#master涉及分支的管理,我们后面细说。
git commit -m [message]
提交的时候最好写上提交日志 便于后续浏览排查。
知识点08:Git基本操作--修改、还原
实现基于本地版本库的修改提交
-
step1:修改文件
**step2:提交第二个版本*
还原:修改文件,但未提交
使用tortoiseGit工具,可以将工作区的内容还原至最后一个提交的版本。
知识点09:Git基本操作--版本差异比较、回退
-
修改文件
工作区与最新版本的差异
工作区与倒数第二个版本的差异
工作区与之前任意版本的差异比较
可以使用tortoiseGit工具选中文件、右键查看日志信息。
在日志信息中选中想要比较的版本和工作区的之间的差异。
版本回退
有时候用Git的时候,有可能commit提交代码后,发现这一次commit的内容是有错误的,那么有两种处理方法: 1、修改错误内容,再次commit一次
2、使用git reset 命令撤销这一次错误的commit 第一种方法比较直接,但会多次一次commit记录。 第二种方法会显得干净清爽,因为错误的commit没必要保留下来。但是使用的时候等慎重,对于新手而言。
git reset 命令用于回退版本,可以指定退回某一次提交的版本,有3种模式可供选择,详见画图。

小结
-
注意:如果重置回到某个版本时,关闭了tortoiseGit日志窗口,这个版本之后的版本全部会被删除,无法再次回到之后的版本
-
重置git reset,只能倒退回退,如果有前进的需求怎么办?
导出需要重置到的版本,重新提交版本,将原来的一个老版本变成最新版本
知识点10:Git基本操作--删除
-
情况1:文件删除
直接将工作区的已经提交的文件删除之后,不做提交动作,可以使用还原操作。
知识点10:Git基本操作--删除
-
情况1:文件删除
直接将工作区的已经提交的文件删除之后,不做提交动作,可以使用还原操作。
情况2:删除版本
将工作区的已经提交的文件删除之后,做提交动作,可以通过日志还原。
情况3:删除管理
也就是所谓的摆脱Git的控制
知识点11:添加整个项目
-
复制工程到本地库
添加到暂存区
忽略不需要做控制的目录
**提交到本地库
知识点12:暂存区的设计
-
没有暂存区
-
在提交的时候,会让你选择那些文件需要提交
-
我们所提交的必然是一个完整的版本
-
毛病1
-
文件特别多,挨个选非常麻烦
-
-
毛病2
-
版本1:ABC
-
版本2:ABD
-
想要一个版本:ACD
-
-
-
设计暂存区
-
设计Git的时候考虑到上面两个问题的主要原因是提交版本修改的颗粒度太大了
-
将可能需要提交的版本放入暂存区
-
每一次只放一个部分
-
第一次:A
-
第二次:B
-
提交一次:AB
-
第三次:A,B,C
-
提交一次:ABC版本
-
第四次:A,C,D
-
提交一次:ACD版本
-
-
理解:
-
暂存区:相当于你买东西的先添加购物车
-
将商品放入购物车的自由组合进行支付
-
-
版本:就是一次支付
-
-
知识点13:Git远程仓库--GitHub创建公共仓库
了解Git远程仓库的设计
-
问题
-
如何实现多台机器之间共同协作开发版本的管理?
-
-
解决
-
公共代码版本托管平台
-
-
商业代码托管平台
-
国外:GitHub
-
国内:Gitee
-
可以将代码发布到这个平台上进行托管,其他的人可以从这个平台下载代码
-
公共代码库:大家都可以看到的
-
私有代码库:可以控制访问权限,但是收费
-
-
-
注册GitHub,并登陆
-
参考附录一:https://github.com/
-
如果访问不了,添加DNS解析
-
#GitHub
140.82.114.4 github.com
199.232.69.194 github.global.ssl.fastly.net
创建公共仓库
知识点14:本地与GitHub的SSH连接
实现本地仓库与GitHub公共仓库的连接
-
需求
-
即使是public的公共仓库,也只是所有人可读,但不是所有人可写
-
哪些人可写呢?
-
需要配置SSH认证
-
需要将本地机器的公钥填写在GitHub中,只有填写公钥的机器才能推送
-
-
-
本地秘钥生成
-
step1:在自己Windows本地生成一对公私钥
-
ssh-keygen -t rsa
step2:找到自己的公钥的位置:当前用户的家目录下:C:\user\用户名 \ .ssh
step3:打开公钥的文件,并复制公钥的内容
将整个公钥的所有内容配置到SSH的key中,添加保存即可
实现本地仓库与GitHub公共仓库的连接
知识点15:同步到远程仓库
实现本地仓库代码同步到远程仓库
-
方式一:命令同步
#添加一个远程仓库的地址叫origin
git remote add origin git@github.com:Frank-itcast/repository1.git
练习中替换成自己的仓库地址
#git remote add origin git@github.com:AllenWoon/xls_1.git
#将本地master同步到远程的origin
git push -u origin master
**方式二:工具同步:SSH**
方式三:工具同步:HTTPS
知识点16:从远程仓库克隆
实现从远程仓库克隆到本地仓库
-
方式一:命令
git clone git@github.com:Frank-itcast/reps1.git
#git clone git@github.com:AllenWoon/xls_2.git
方式二:工具
知识点17:冲突问题
了解版本管理的冲突问题及解决方案
解决
-
本地reps3:拉取远程reps1中的版本,发现冲突的文件
-
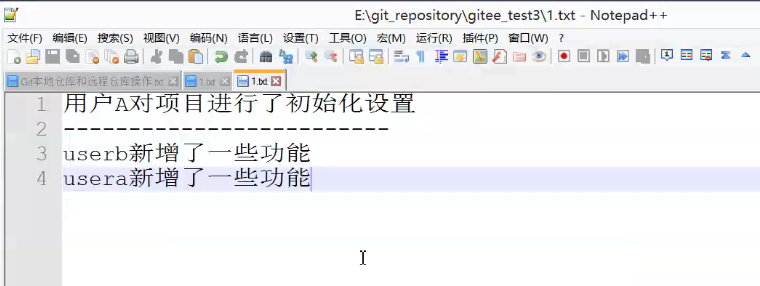
修改冲突的文件
-
解决冲突
-
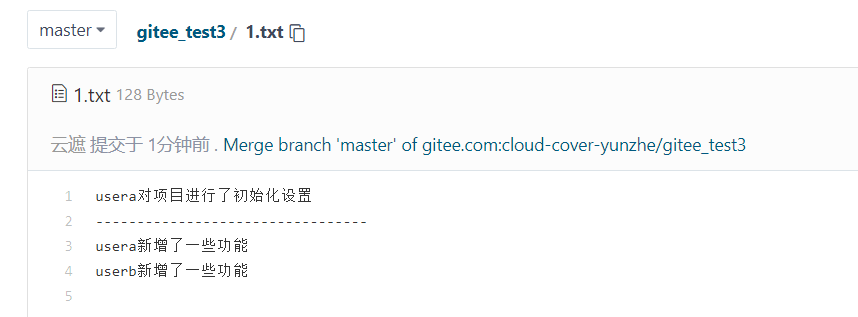
提交本地仓库
-
提交远程仓库
解决
-
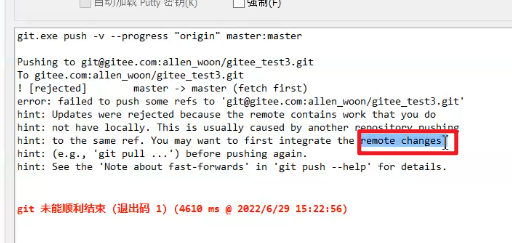
如果别人已经提交了某个版本,自己再次提交这个版本,会失败
-
将两个冲突的版本合并,由开发者自行选择到底应该 使用哪个版本
-
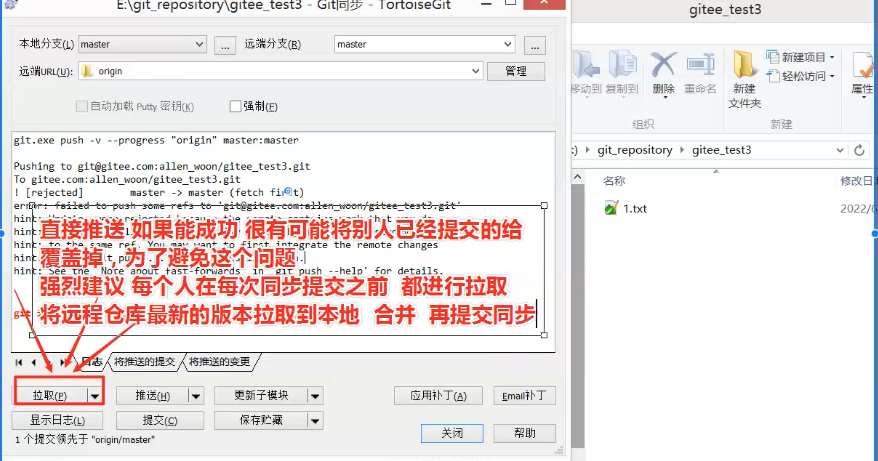
step1:先拉取远程仓库中的当前的这个版本
-
-
step2:与自己的版本做比较
-
step3:调整好确认的版本以后,再次提交
-
知识点18:分支的功能与分支管理
-
业务场景
-
开发一个APP
-
普通的开发线
-
A、B、C
-
v1/v2/v3
-
-
VIP的开发线
-
A、B、C、D
-
v1/v2/v3
-
-
测试开发线
-
A、B、C、D、E
-
v1/v2/v3
-
-
-
问题:如果一个项目中多条开发线都需要做版本控制怎么办?
-
解决:分支管理
-
-
分支管理
-
一个项目中可以有多个分支,每个分支独立管理各自的版本,默认只有一个分支:master
-
创建分支
注意:测试vip分支与master 分支
-
在vip分支中修改的这个版本,在master中是否能看到对应的修改?
-
看不到
-
所有的分支是独立的
-
-
在Master管理的文件或者版本,在vip中是否能看到?
-
看不到
-
删除分支
-
当前正在使用分支不允许删除
-
删除其他的分支
知识点19:分支合并
实现分支的合并
-
需求:将VIP的功能与普通的功能进行合并
-
普通的APP:master
-
ABCD
-
-
VIP的APP:vip
-
ABCE
-
-
这个功能可以给普通用户使用
-
希望得到普通用户的APP
-
ABCDE
-
-
-
分支的合并
-
vip内容
-
master内容
-
希望得到的结果:master分支合并vip的分支的内容
-
在Master中做一个新的版本
-
这个操作是不影响vip分支的
-

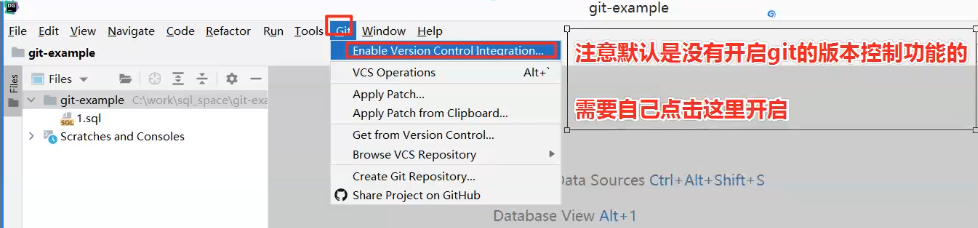
启动PyCharm,点击【File】→【Settings】→【Version Control】→【Git】,选择Git可执行文件路径(系统安装git后此处会默认显示路径),点击【Test】,路径下会显示当前Git版本。
如果不在某个具体的工程里面,则点击【Configure】→【Settings】→【Version Control】→【Git】

dg,完成一个文件就提交commit本地库,晚上下班就push到远程库,
Day10_新零售项目总结
#参考话术 只可意会 不可模仿
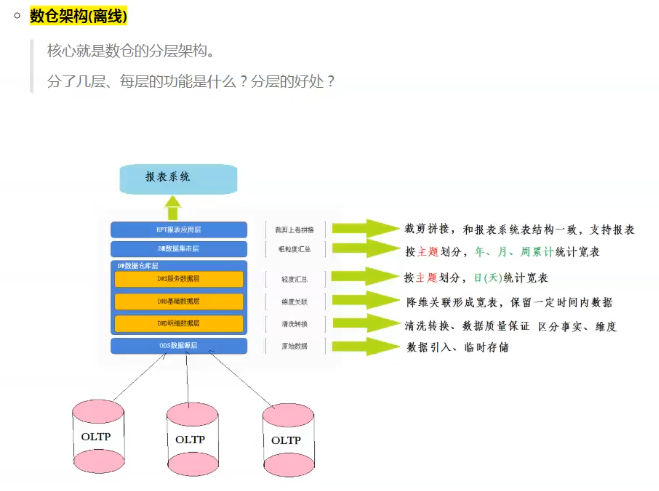
#1、通过sqoop将业务数据库中的数据采集同步到新零售数仓的ODS层中;
可能问到:sqoop工具知识点
几种同步方式及区别:全量覆盖、全量同步、增量同步(仅新增)、增量同步(新增及更新同步)
sqoop如何实现几种同步的,尤其是增量同步?
要求业务系统表设计的时候有 create_time update_time
sqoop --query "select where create_time between dt 00:00:00 23:59:59
sqoop在同步数据中有遇到什么问题吗?怎么解决的?
数据格式ORC(HCatalog) 表数据量大--m 字段分隔符 --split-by 文本格式
结合sqoop和hive建表如何使用
扩展问题:你是否了解其他的EL抽取工具?(可能他们公司就是用的询问的那个工具,) 多款同类型软件之间的比较? 知识视野宽度?
sqoop能否进行实时采集?(不能) 哪个实时抽取?(canal(mysql) ogg(oracle))
#2、基于ODS层数据进行清洗转换处理的工作, 根据分析需求区分事实表、维度表,后将数据同步至DWD层, 同时在DWD层完成了历史数据维护工作,项目采用拉链表的方案;
可能问到:清洗转换具体做了什么,怎么做的
空值处理
coalesce函数 (“COALESCE是一个函数, (expression_1, expression_2, ...,expression_n)依次参考各参数表达式,遇到非null值即停止并返回该值。)
nvl函数 (NVL(E1, E2)的功能为:如果E1为NULL,则函数返回E2,否则返回E1本身。)
日期转换 date timestamp
枚举类型解释 1 2 3 3
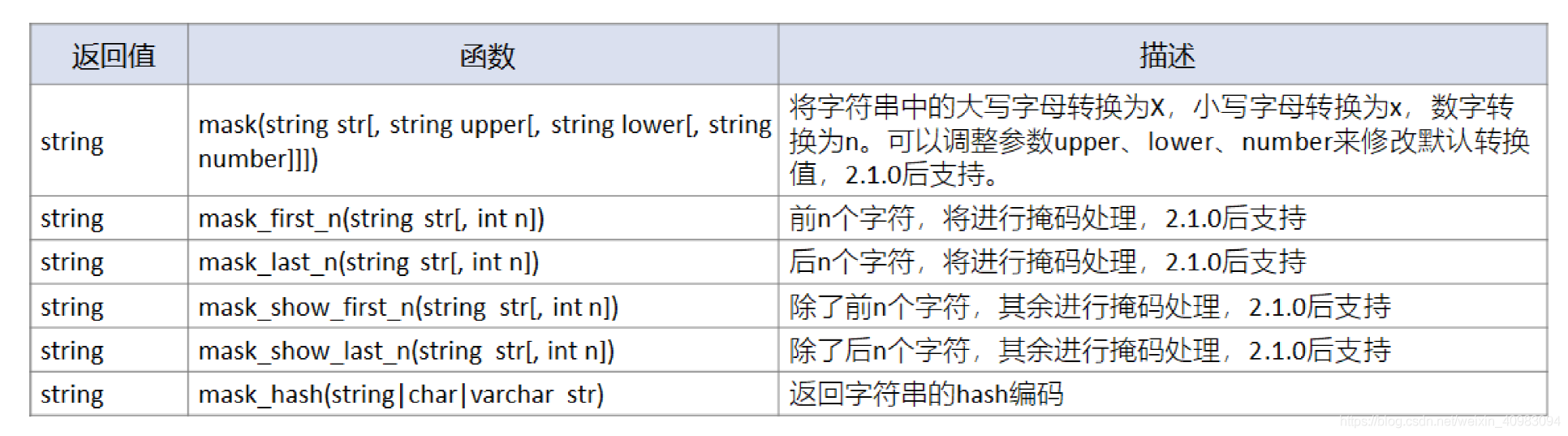
脱敏操作(mask) 手机号 身份证号码
mask(mask_first_n(string str[, int n]) 可对前n个字符进行掩码处理。
mask_last_n(string str[, int n]) 可对后n个字符进行掩码处理。
mask_show_first_n(string str[, int n]) 是除了前n个字符,其余进行掩码处理。
mask_show_last_n(string str[, int n]) 是除了后n个字符,其余进行掩码处理。
mask_hash(string|char|varchar str) 会返回字符串的hash编码。
如何区分事实、维度,什么是事实、什么是维度--->这一扩展可能会扯到维度建模整个理论
(day03)
事实:你分析关注的内容
维度:分析问题的角度
拉链表是什么?解决什么?如何实现拉链?
拉链表使用的关键原因:需要记录维护历史状态、数据还不能冗余
拉链实现的关键是开始时间 结束时间标识数据有效期 9999-12-31
sql技术角度实现拉链过程:
1、从ODS层查询增量数据(包括更新和新增的) ---->结果集1
2、历史拉链表 left join 结果集1 ---->is not null -->修改历史数据的结束
3、将1、2的结果union all合并 新的拉链结果
#3、接着对DWD层基于业务模块进行数据维度退化处理工作, 将退化后的宽表数据灌入到DWB层中, 构建了整个集团数据中心
可能问到:维度退化是什么?(维度表的核心字段退化到事实表中,)如何实现?
依据是什么?(ER图,业务流程)
优缺点?(不做退化,可能会涉及多表之间的来回join各种维度表,sql维护上,性能上,有问题,选择退化将需求中涉及的字段抽取出来,变成一张宽表,)
实际中有两种操作:1、维度表退化到事实表中
2、多个事实表退化到一个核心的事实上
3、多个维度表退化到一个维度表中
sql技术上实现降维:
select
抽取核心字段
from 事实 left join 维度1
left join 维度2;
优化:map join优化的问题(加分项)
【Day07_DWS层建设实战-1\4、今日重点、项目优化】
#4、开始进行主题统计分析, 整个项目主题共有三个宽表(销售主题, 商品主题, 用户主题), 根据业务需求、分析师提供的维度和指标, 进行统计分析, 在统计的时候, 先进行提前聚合处理工作, 将聚合统计后宽表数据同步到DWS层中;
可能问到:主题有哪些、指标、维度有哪些?主题、指标、维度怎么确定的?
主题有哪些表?
地址:Day06_DWB层建设实战、Presto计算引擎\1、笔记总结更新
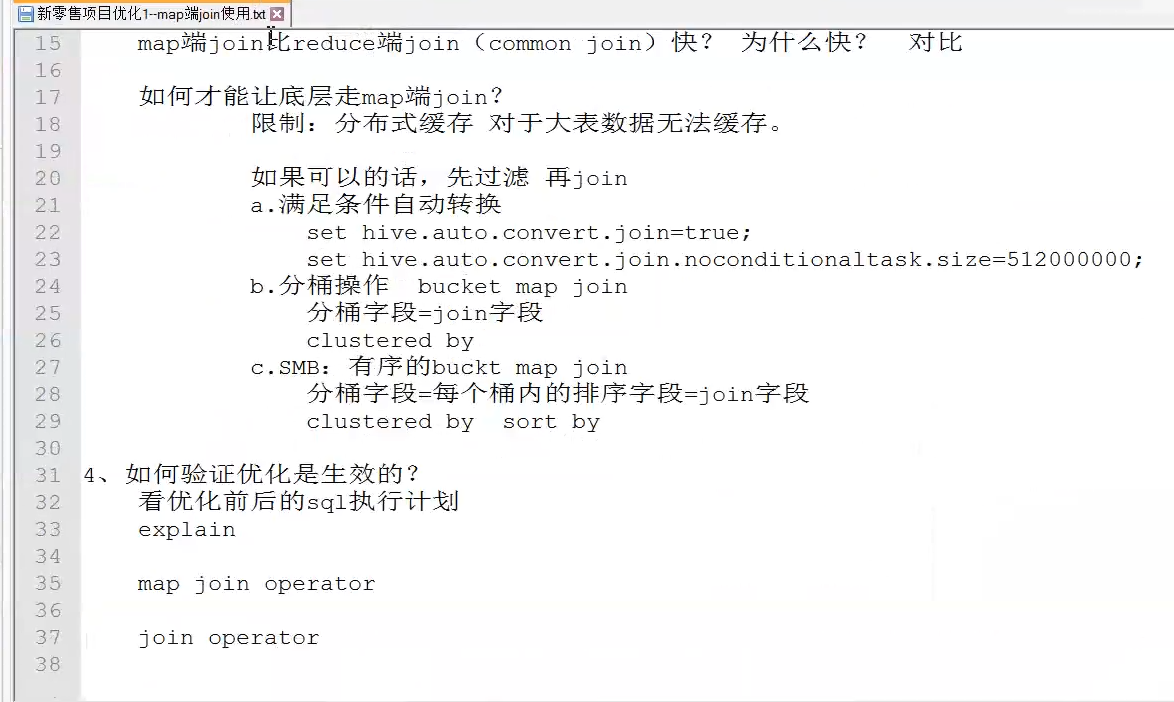
三个宽表(销售主题, 商品主题, 用户主题),由那些表查询而来??(
订单明细宽表 **==dwb_order_detail
核心表: yp_dwd.fact_shop_order订单主表
(也就说,其他表将围绕着订单主表拼接成为一张宽表)
退化维度表:
fact_shop_order_address_detail: 订单副表
记录订单额外信息 与订单主表是1对1关系 (id与orderID一一对应)
fact_shop_order_group: 订单组表
多笔订单构成一个订单组 (含orderID)
fact_order_pay: 订单组支付表
记录订单组支付信息,跟订单组是1对1关系 (含group_id)
fact_refund_order: 订单退款信息表
记录退款相关信息(含orderID)
fact_order_settle: 订单结算表
记录一笔订单中配送员、圈主、平台、商家的分成 (含orderID)
fact_shop_order_goods_details: 订单和商品的中间表
记录订单中商品的相关信息,如商品ID、数量、价格、总价、名称、规格、分类(含orderID)
fact_goods_evaluation: 订单评价表
记录订单综合评分,送货速度评分等(含orderID)
fact_order_delievery_item: 订单配送表
记录配送员信息、收货人信息、商品信息(含orderID)
)(
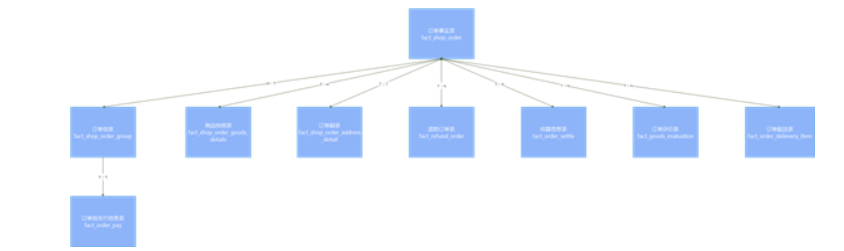
DWB层搭建--店铺明细宽表-
核心表: yp_dwd.dim_store 店铺表
退化维度表:
dim_trade_area 商圈表
记录商圈相关信息,店铺需要归属商圈中(ID主键是店铺表中的外键,trade_area_id)
dim_location 地址信息表
记录了店铺地址
dim_district 区域字典表
记录了省市县区域的名称、别名、编码、父级区域ID
)
(
DWB层搭建--商品明细宽表
核心表: dim_goods 商品SKU表
记录了商品相关信息
退化维度表:
dim_goods_class 商品分类表
记录了商品所属的分类信息:商品大类、商品中类、商品小类
dim_brand 品牌信息表
记录了品牌信息
)
如果表名和表个数张嘴说出来那就十分棒棒了。
如果说不出来?业务不熟悉,打酱油的?项目没做过?培训的?
预聚合这里指的是什么?为什么要预聚合?
先把粒度细的计算出来 便于后续上卷计算粒度粗的。
#4、后对DWS层进行细化上卷维度统计操作, 形成DM层数据;
可能问题:上卷是?如何实现?下钻?---->这里可能延伸出OLAP多维分析 rollup cube等
#5、最后根据报表系统应用要求, 从DM层获取相关的数据拼接, 同步到RPT层, 再通过presto将数据导出到mysql中, 后续供应用使用;
可能问题:RPT是什么?报表系统直接使用DM数据行吗?为什么? 解耦合
presto导出数据怎么操作的?
为什么使用mysql存储最终数据?
#以上每个步骤中,都可能会问到的是
sqoop、hive、presto功能技术点 优化点
你这这里做了什么工作? 负责某个主题的完整实现
遇到了哪些问题(回答好是强烈加分项 提前准备)
问题怎么发现的?怎么思考的?怎么寻找解决方案?怎么测试方案的?最终解决了吗? 有什么收获
这个问题你用A解决,B你知道吗? AB区别是?这个我不是很清楚但我有了解,到时候需要使用也容易上手,
针对你做的有考虑什么优化方案吗?
优化方案解决什么的? 查询效率 存储效率 逻辑清晰?
为什么用这个方案,其他相同类似的你还知道吗?
公司地址?成都,
上司联系方式?
map join优化,

宽表--核心表--退化额度表,
DWB层搭建--店铺明细宽表
完成项目总结,边补充老师讲的,边汇总项目笔记,
已完成:::::::::::::::















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









