






AlexNet
- 更深的网络结构
- 使用层叠的卷积层,即卷积层+卷积层+池化层来提取图像的特征
- 使用Dropout抑制过拟合
- 使用数据增强Data Augmentation抑制过拟合
- 使用Relu替换之前的sigmoid的作为激活函数
- 多GPU训练
-
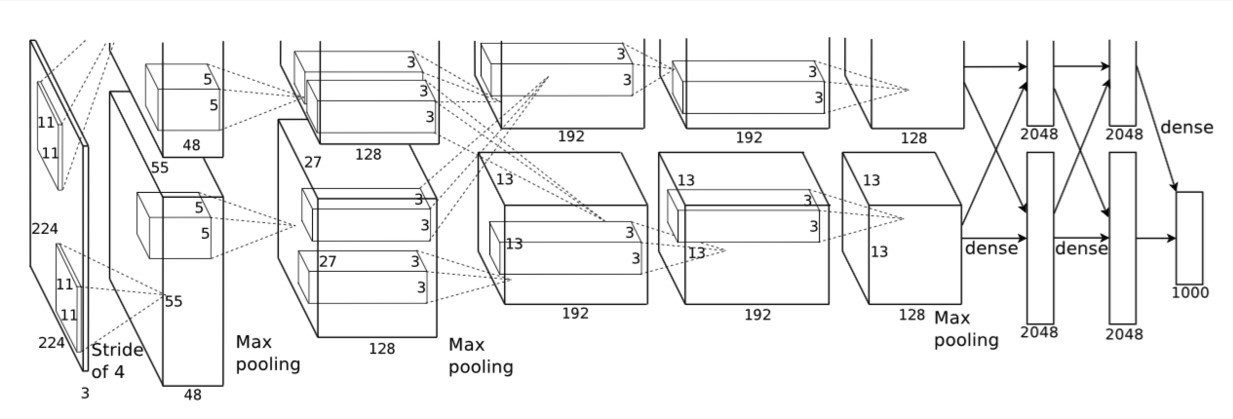
-
卷积层C1
该层的处理流程是: 卷积-->ReLU-->池化-->归一化。 -
卷积层C2
该层的处理流程是:卷积-->ReLU-->池化-->归一化。 -
卷积层C3
该层的处理流程是: 卷积-->ReLU -
卷积层C4
该层的处理流程是: 卷积-->ReLU
该层和C3类似 -
卷积层C5
该层处理流程为:卷积-->ReLU-->池化 -
全连接层FC6
该层的流程为:(卷积)全连接 -->ReLU -->Dropout -
全连接层FC7
流程为:全连接-->ReLU-->Dropout- 全连接,输入为4096的向量
- ReLU,这4096个运算结果通过ReLU激活函数生成4096个值
- Dropout,抑制过拟合,随机的断开某些神经元的连接或者是不激活某些神经元
-
输出层
第七层输出的4096个数据与第八层的1000个神经元进行全连接,经过训练后输出1000个float型的值,这就是预测结果。 -
VGG
-
VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5)。对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
-
VGG优缺点
VGG优点
- VGGNet的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)。
- 几个小滤波器(3x3)卷积层的组合比一个大滤波器(5x5或7x7)卷积层好:
- 验证了通过不断加深网络结构可以提升性能。
-
VGG缺点
- VGG耗费更多计算资源,并且使用了更多的参数(这里不是3x3卷积的锅),导致更多的内存占用(140M)。其中绝大多数的参数都是来自于第一个全连接层。VGG可是有3个全连接层啊!
-
PS:有的文章称:发现这些全连接层即使被去除,对于性能也没有什么影响,这样就显著降低了参数数量。
注:很多pretrained的方法就是使用VGG的model(主要是16和19),VGG相对其他的方法,参数空间很大,最终的model有500多m,AlexNet只有200m,GoogLeNet更少,所以train一个vgg模型通常要花费更长的时间,所幸有公开的pretrained model让我们很方便的使用。
-
GoogLeNet
- inception模块的基本机构如下图,整个inception结构就是由多个这样的inception模块串联起来的。inception结构的主要贡献有两个:一是使用1x1的卷积来进行升降维;二是在多个尺寸上同时进行卷积再聚合。
-
图1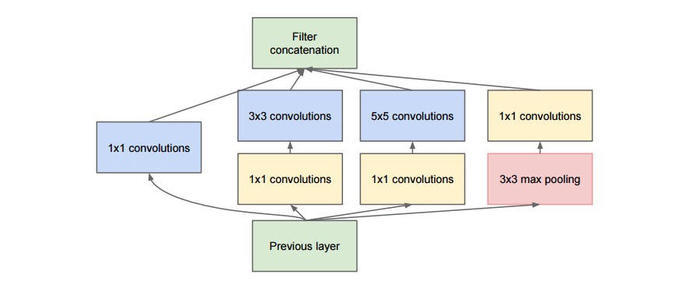
- 1、1x1卷积
- 作用1:在相同尺寸的感受野中叠加更多的卷积,能提取到更丰富的特征。这个观点来自于Network in Network(NIN, https://arxiv.org/pdf/1312.4400.pdf),图1里三个1x1卷积都起到了该作用。NIN的结构和传统的神经网络中多层的结构有些类似,后者的多层是跨越了不同尺寸的感受野(通过层与层中间加pool层),从而在更高尺度上提取出特征;NIN结构是在同一个尺度上的多层(中间没有pool层),从而在相同的感受野范围能提取更强的非线性。
- 作用2:使用1x1卷积进行降维,降低了计算复杂度。
- 2、多个尺寸上进行卷积再聚合
- 图2可以看到对输入做了4个分支,分别用不同尺寸的filter进行卷积或池化,最后再在特征维度上拼接到一起。这种全新的结构有什么好处呢?Szegedy从多个角度进行了解释:
- 解释1:在直观感觉上在多个尺度上同时进行卷积,能提取到不同尺度的特征。特征更为丰富也意味着最后分类判断时更加准确。
- 解释2:利用稀疏矩阵分解成密集矩阵计算的原理来加快收敛速度。
- 3、GoogLeNet网络有22层深(包括pool层,有27层深),在分类器之前,采用Network in Network中用Averagepool(平均池化)来代替全连接层的思想,而在avg pool之后,还是添加了一个全连接层,是为了大家做finetune(微调)。而无论是VGG还是LeNet、AlexNet,在输出层方面均是采用连续三个全连接层,全连接层的输入是前面卷积层的输出经过reshape得到。据发现,GoogLeNet将fully-connected layer用avg pooling layer代替后,top-1 accuracy 提高了大约0.6%;然而即使在去除了fully-connected layer后,依然必须dropout。(网络浅层常常见到maxpool)
- 4、辅助分类器
- 根据实验数据,发现神经网络的中间层也具有很强的识别能力,为了利用中间层抽象的特征,在某些中间层中添加含有多层的分类器。如下图所示,红色边框内部代表添加的辅助分类器。GoogLeNet中共增加了两个辅助的softmax分支,作用有两点,一是为了避免梯度消失,用于向前传导梯度。反向传播时如果有一层求导为0,链式求导结果则为0。二是将中间某一层输出用作分类,起到模型融合作用。最后的loss=loss_2 + 0.3 * loss_1 + 0.3 * loss_0。实际测试时,这两个辅助softmax分支会被去掉。
-
Inception V2
1、学习VGGNet的特点,用两个33卷积代替55卷积,可以降低参数量。
2、提出BN算法。BN算法是一个正则化方法,可以提高大网络的收敛速度。就是每一batch的输入分布标准化处理,使得规范化为N(0,1)的高斯分布,收敛速度大大提高。Inception V3
学习Factorization into small convolutions的思想,在Inception V2的基础上,将一个二维卷积拆分成两个较小卷积,例如将7*7卷积拆成1*7卷积和7*1卷积,这样做的好处是降低参数量。该paper中指出,通过这种非对称的卷积拆分比对称的拆分为几个相同的小卷积效果更好,可以处理更多,更丰富的空间特征,这就是Inception V3网络结构。

-
参考文章链接:https://blog.csdn.net/qq_37555071/article/details/108214680















 645
645











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









