







文章目录
一、orm简介
(一) orm概述
1 orm:对象关系映射(跟语言无关)
数据库中的表 ----》对应程序的一个类
数据库中的一行数据----》对应程序中的一个对象
2 python中常见orm框架
-django的orm框架
-sqlachemy orm框架
3 orm能干的事
-创建表(不能创建数据库,手动创建数据库)
-增加删除表内字段
-增删查改数据
查询数据层次图解:如果操作mysql,ORM是在pymysq之上又进行了一层封装。

ORM图示:

(二) django中orm的使用
0 sqlite:也是要给数据库,文件数据库,一个库就是一个文件,不需要单独安装
-咱们现在在用,也要用到关系型数据库,不想装mysql,就可以使用sqlite
-移动开发本地存储数据,存在sqlite中
1 创建个UserInfo表,在models中写一个类
2 表中有字段(类属性),字段有属性,
# 第一步在models中写要给类
class UserInfo(models.Model):
# 字段属性--》后面那个对象决定的,
# 改字段自增,并且是主键
id = models.AutoField(primary_key=True)
# 改字段是varchar类型,长度为32(唯一约束,是否是索引,默认值是,是否可以为空)
name = models.CharField(max_length=32)
# 密码字段
password =models.CharField(max_length=64)
# 第二步,把表创建出来(执行两个命令)
-python3 manage.py makemigrations # 这条命令会在migrations创建一条记录,数据库变更记录
-python3 manage.py migrate # 把更改同步到数据库,若数据库没有变化,执行此命令则没变化(删除字段在models中注释代码即可完成删除字段)
二、单表操作
(一) 创建表
1 创建模型
2 常用的字段、参数和元信息
#1) 常用字段
-IntegerField 整数
-AutoField
-BooleanField
-CharField
-DateField
-DateTimeField
-DecimalField
-FileField 上传文件,本质是varchar
-ImageField 图片,本质是varchar,继承了FileField
-TextField 存大文本
-EmailField 本质是varchar
#2) 非常用字段
-BigAutoField
-SmallIntegerField
-PositiveSmallIntegerField
-PositiveIntegerField
-BigIntegerField
"""
'AutoField': 'integer AUTO_INCREMENT',
'BigAutoField': 'bigint AUTO_INCREMENT',
'BinaryField': 'longblob',
'BooleanField': 'bool',
'CharField': 'varchar(%(max_length)s)',
'CommaSeparatedIntegerField': 'varchar(%(max_length)s)',
'DateField': 'date',
'DateTimeField': 'datetime',
'DecimalField': 'numeric(%(max_digits)s, %(decimal_places)s)',
'DurationField': 'bigint',
'FileField': 'varchar(%(max_length)s)',
'FilePathField': 'varchar(%(max_length)s)',
'FloatField': 'double precision',
'IntegerField': 'integer',
'BigIntegerField': 'bigint',
'IPAddressField': 'char(15)',
'GenericIPAddressField': 'char(39)',
'NullBooleanField': 'bool',
'OneToOneField': 'integer',
'PositiveIntegerField': 'integer UNSIGNED',
'PositiveSmallIntegerField': 'smallint UNSIGNED',
'SlugField': 'varchar(%(max_length)s)',
'SmallIntegerField': 'smallint',
'TextField': 'longtext',
'TimeField': 'time',
'UUIDField': 'char(32)',
"""
#3) 常用参数
-null
-max_length
-default
-primary_key
-unique
-db_index
#
-choices:比较常用(后面再说)
-blank: django admin里提交数据,限制
#4) 元数据
-必须记住的
class Meta:
# 表名
db_table = "book"
#联合索引
index_together = [
("name", "publish"),
]
# 联合唯一索引
unique_together = (("name", "publish"),)
-了解
# admin中显示的表名称
verbose_name='图书表'
#verbose_name加s
verbose_name_plural='图书表'
3 settings配置信息
若想将模型转为mysql数据库中的表,需要在settings中配置:
#1) settings.py
DATABASES = {
'default': {
# 配置使用mysql
'ENGINE': 'django.db.backends.mysql', # 数据库产品
'HOST': "localhost", # 数据库ip
'PORT': 3306, # 数据库端口
'USER': "root", # 用户名
'PASSWORD': "123", # 密码
'NAME': "xxx", # 数据库名
}
}
'''
'NAME': 要连接的数据库,连接前需要创建好
'USER': 连接数据库的用户名
'PASSWORD':连接数据库的密码
'HOST': 连接主机,默认本机
'PORT': 端口 默认3306
'ATOMIC_REQUEST': True,
设置为True统一个http请求对应的所有sql都放在一个事务中执行(要么所有都成功,要么所有都失败)。
是全局性的配置, 如果要对某个http请求放水(然后自定义事务),可以用non_atomic_requests修饰器
'OPTIONS': {
"init_command": "SET storage_engine=MyISAM",
}
设置创建表的存储引擎为MyISAM,INNODB
'''
#2) 项目同名文件夹下的 __init__.py中
import pymysql
pymysql.install_as_MySQLdb()
#3) 两条数据库迁移命令即可在指定的数据库中创建表 :
python3 manage.py makemigrations
python3 manage.py migrate
#4) 确保配置文件中的INSTALLED_APPS中写入我们创建的app名称:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
"book" # 或者这种形式:'app名字.apps.App01Config',
]
4 增加、删除字段
# 1) 删除,直接注释掉字段,执行数据库迁移命令即可
# 2) 新增字段,在类里直接新增字段,直接执行数据库迁移命令会提示输入默认值,此时需要设置
publish = models.CharField(max_length=12,default='人民出版社',null=True)
# 注意:
——1) 数据库迁移记录都在 app01下的migrations里
——2) 使用showmigrations命令可以查看没有执行migrate的文件
——3) makemigrations是生成一个文件,migrate是将更改提交到数据量
(二) 添加表记录
# 方式一:使用create方法
# create方法的返回值book_obj就是插入book表中的python葵花宝典这本书籍纪录对象
book_obj=Book.objects.create(title="python葵花宝典",state=True,price=100,publish="苹果出版社",pub_date="2012-12-12")
# 方式二:对象自己的方法,然后对象.save()。
book_obj=Book(title="python葵花宝典",state=True,price=100,publish="苹果出版社",pub_date="2012-12-12")
book_obj.save()
(三) 查询表记录API
#1) 返回queryset对象
<1> all(): 查询所有结果
<2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象
<4> exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象
<5> order_by(*field): 对查询结果排序(默认升序) 加-表示降序
<6> reverse(): 对查询结果反向排序
<11> values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列
<12> values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列
<13> distinct(): 从返回结果中剔除重复纪录
#2) 返回数据对象本身
<3> get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。
<8> first(): 返回第一条记录
<9> last(): 返回最后一条记录
#3) 返回数字
<7> count(): 返回数据库中匹配查询(QuerySet)的对象数量。
#4) 返回布尔值
<10> exists(): 如果QuerySet包含数据,就返回True,否则返回False
代码示例:
# 在脚本中调用djagno服务
import os
if __name__ == '__main__':
# 1 引入django配置文件
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'day067.settings')
# 2 让djagno启动
import django
django.setup()
# 3 使用表模型
from app01 import models
models.Book.objects.create(name='测试书籍', publish='xx出版社')
models.Book.objects.create(name='凡人修仙传', publish='古彭出版社')
models.Book.objects.create(name='神墓', publish='古彭出版社')
models.Book.objects.create(name='从姑获鸟开始', publish='南京出版社')
models.Book.objects.create(name='铁血残明', publish='南京出版社')
for i in range(198):
models.Book.objects.create(name='重返东京有点热%s' % i, publish='东京出版社')
# 单表API查询
# < 1 > all(): 查询所有结果,返回queryset对象,可以看作是列表
res = models.Book.objects.all()
print(res)
print(type(res)) # <class 'django.db.models.query.QuerySet'>
# < 2 > filter(**kwargs): 过滤 queryset对象的方法
res = models.Book.objects.filter(name='从姑获鸟开始')
print(res) # <QuerySet [<Book: 从姑获鸟开始>]>
res = models.Book.objects.all().filter(name='从姑获鸟开始')
print(res) # <QuerySet [<Book: 从姑获鸟开始>]>
res = models.Book.objects.all().filter(name='从姑获鸟开始', publish='南京出版社')
print(res) # <QuerySet [<Book: 从姑获鸟开始>]>
print(type(models.Book.objects)) # <class 'django.db.models.manager.Manager'>
# < 3 > get(**kwargs): queryset对象的方法,返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。
res = models.Book.objects.all().get(name='从姑获鸟开始')
res1 = models.Book.objects.get(name='从姑获鸟开始')
res2 = models.Book.objects.filter().get(name='从姑获鸟开始')
print(res, type(res), res1, res2) # 从姑获鸟开始 <class 'app01.models.Book'> 从姑获鸟开始 从姑获鸟开始
# 返回的数据是——————————————》》》》》》数据对象本身
# < 4 > exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象,可以继续链式调用
res = models.Book.objects.exclude(name='从姑获鸟开始')
print(type(res)) # <class 'django.db.models.query.QuerySet'>
# < 5 > order_by(*field): 对查询结果排序(默认升序) 加-表示降序
res = models.Book.objects.all().order_by('id')
res = models.Book.objects.all().order_by('-id')
res = models.Book.objects.all().order_by('name', '-id')
res = models.Book.objects.all().order_by('id', 'name')
print(res)
# < 6 > reverse(): 对查询结果反向排序,必须结合order_by使用,对结果进行反转,等同于 ('-i')
res = models.Book.objects.exclude(name='从姑获鸟开始').order_by('id')
res = models.Book.objects.exclude(name='从姑获鸟开始').order_by('id').reverse()
print(res)
# < 7 > count(): 返回数据库中匹配查询(QuerySet)的对象数量。
res = models.Book.objects.exclude(name='从姑获鸟开始').count()
res = models.Book.objects.all().count()
print(res)
# 返回的数据是——————————————》》》》》》数字
# < 8 > first(): 返回第一条记录
res = models.Book.objects.exclude(name='从姑获鸟开始').first()
print(res, type(res)) # 测试书籍 <class 'app01.models.Book'>
# 返回的数据是——————————————》》》》》》数据对象本身
# < 9 > last(): 返回最后一条记录
res = models.Book.objects.exclude(name='从姑获鸟开始').last()
print(res, type(res)) # 测试书籍 重返东京有点热197 <class 'app01.models.Book'>
# 返回的数据是——————————————》》》》》》数据对象本身
# < 10 > exists(): 如果QuerySet包含数据,就返回True,否则返回False
res = models.Book.objects.exclude(name='从姑获鸟开始').exists()
print(res, type(res)) # True <class 'bool'>
res = models.Book.objects.filter(name='从姑获鸟开始aaa').exists()
print(res, type(res)) # False <class 'bool'>
# 返回的数据是——————————————》》》》》》布尔值
# < 11 > values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列
res = models.Book.objects.all().values('name', 'publish')
print(res, type(res)) # <QuerySet [...]> <class 'django.db.models.query.QuerySet'>
res = models.Book.objects.all().values('name', 'publish').first()
print(type(res), res) # <class 'dict'> {'name': '测试书籍', 'publish': 'xx出版社'}
# < 12 > values_list(*field): 它与values()非常相似,不同的是它返回的queryset对象内部是一个元组序列,values返回的是一个字典序列
res = models.Book.objects.all().values_list('name', 'publish')
print(type(res), res) # <class 'django.db.models.query.QuerySet'>
res = models.Book.objects.all().values_list('name', 'publish').first()
print(type(res), res) # <class 'tuple'> ('测试书籍', 'xx出版社')
# < 13 > distinct(): 从返回结果中剔除重复纪录 --->>>在字段未设置唯一或联合唯一时使用
res = models.Book.objects.all().values('name', 'publish').distinct()
print(type(res), res)
(四) 基于双下划线的模糊查询
# 基于双下划线的模糊查询
# 1) 在范围内的
res = models.Book.objects.filter(id__in=[100, 120, 200])
print(1, res)
# 2) 大于、小于、大于等于、小于等于
res = models.Book.objects.filter(id__gt=100)
print(2, res)
res = models.Book.objects.filter(id__lt=100)
print(3, res)
res = models.Book.objects.filter(id__gte=100)
print(4, res)
res = models.Book.objects.filter(id__lte=100)
print(5, res)
# 3) 范围内的
res = models.Book.objects.filter(id__range=[100, 200])
print(6, res)
# 4) 包含,忽略大小写包含
res = models.Book.objects.filter(name__contains="东京")
print(7, res)
res = models.Book.objects.filter(name__icontains="东京")
print(8, res)
# 5) 以XX开头、结尾(name__endswith)
res = models.Book.objects.filter(name__startswith="神")
print(9, res)
# 6) 时间类型,年份是2019
res = models.Book.objects.filter(publish_date__year=2019)
print(10, res)
(五) 删除表记录
# 删除表记录的两种方式
# 第一种:queryset的delete方法
res = models.Book.objects.filter(name='重返东京有点热0').delete()
print(res) # (1, {'app01.Book': 1})
# 第二种:对象自己的delete方法
book = models.Book.objects.filter(name__contains='重返东京').first()
print(type(book))
res = book.delete() # <class 'app01.models.Book'>
print(res) # (1, {'app01.Book': 1})
(六) 修改表记录
# 修改表记录的两种方式
# 第一种:queryset的update方法
res = models.Book.objects.filter(publish='东京出版社', name='重返东京有点热2').update(name='TokyoHot')
print(res) # 1
# 第二种:对象自己的方法
book = models.Book.objects.filter(publish='东京出版社').last()
book.name = 'Absolutely_Perfect'
book.save()
三、在python脚本中调用Django环境
# 在脚本中调用djagno服务
import os
if __name__ == '__main__':
# 1 引入django配置文件
os.environ.setdefault('DJANGO_SETTINGS_MODULE', '项目名.settings')
# 2 让djagno启动
import django
django.setup()
# 3 使用表模型
from app01 import models
models.Book.objects.create(name='测试书籍', publish='xx出版社')
四、Django终端打印原生sql
1 配置文件粘贴
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level': 'DEBUG',
},
}
}
五、其他操作补充
(一) 时区和国际化问题
# setting.py中
1) 后台管理汉语问题
LANGUAGE_CODE = 'zh-hans' # 管理后台看到的就是中文
2) 时区问题(使用东八区)
TIME_ZONE = 'Asia/Shanghai'
USE_TZ = False
(二) blank参数作用
1) 需要把book表注册到admin中
在app下的admin.py中写
from app01 import models
# 把book表注册一些,管理后台就能看到了
admin.site.register(models.Book)
2) 可以快速的对book表进行增删查改操作
(三) django admin(管理后台的简单使用)
0) 管理后台是django提供的可以快速对表进行增删查改操作
1) 创建一个后台管理账号
python3 manage.py createsuperuser
输入用户名
输入邮箱(可以不填,敲回车)
输入密码
确认密码
# 超级用户创建出来了,可以登录管理后台了
2) 创建好之后,可以登录admin,但是看不到表,需要在app中的admin注册
from app01 import models
admin.site.register(models.Book)
3) admin中表中一行一行的数据显示我们定制的样子
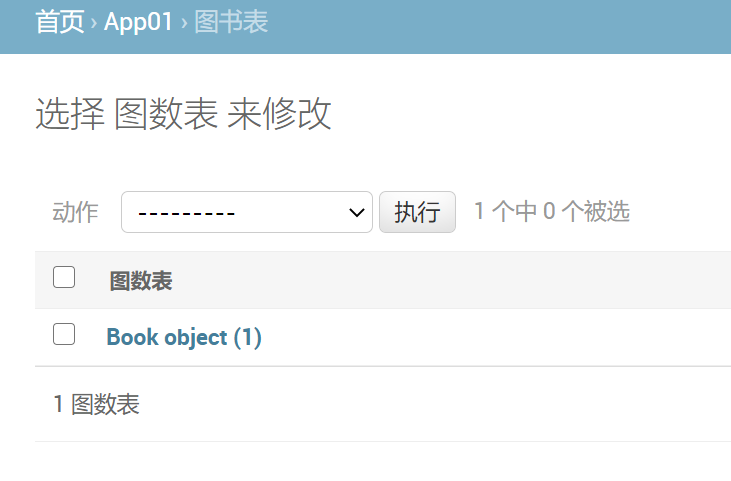
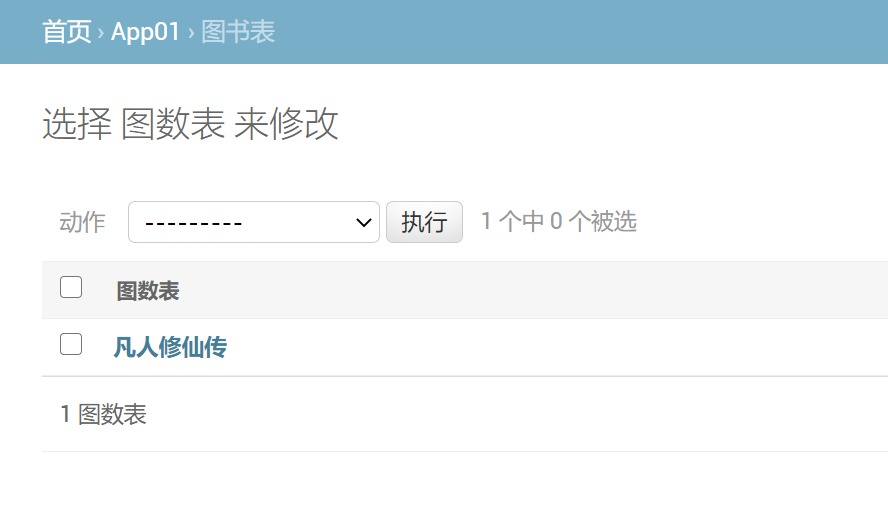
重写模型类的__str__方法【在models下的数据表类中】
def __str__(self):
return self.name
重写模型类的效果对比:















 195
195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









