







文章目录
一、分库分表的概念
数据库数据量不可控,随着时间和业务发展,造成表里面数据越来越多,此时对数据库表CRUD操作,性能会有所降低。业界公认MySQL单表容量在 1千万 以下是最佳状态,因为这时它的BTREE索引树高在3~5之间。
分库分表:为了解决由于数据量过大而造成数据库性能降低问题。
分库分表有两种方式:垂直切分 和 水平切分,其中
- 垂直切分包括 垂直分库 和 垂直分表
- 水平切分包括 水平分库 和 水平分表
在实际使用场景中,随着数据库数据量增加 ,不要首先考虑做水平切分,应当首先考虑缓存处理、读写分离、优化SQL等方式,如果这些方式不能根本解决问题,再考虑做水平分库和水平分表。
1、垂直切分
垂直切分又可以分为: 垂直分库和垂直分表。
1.1、垂直分库
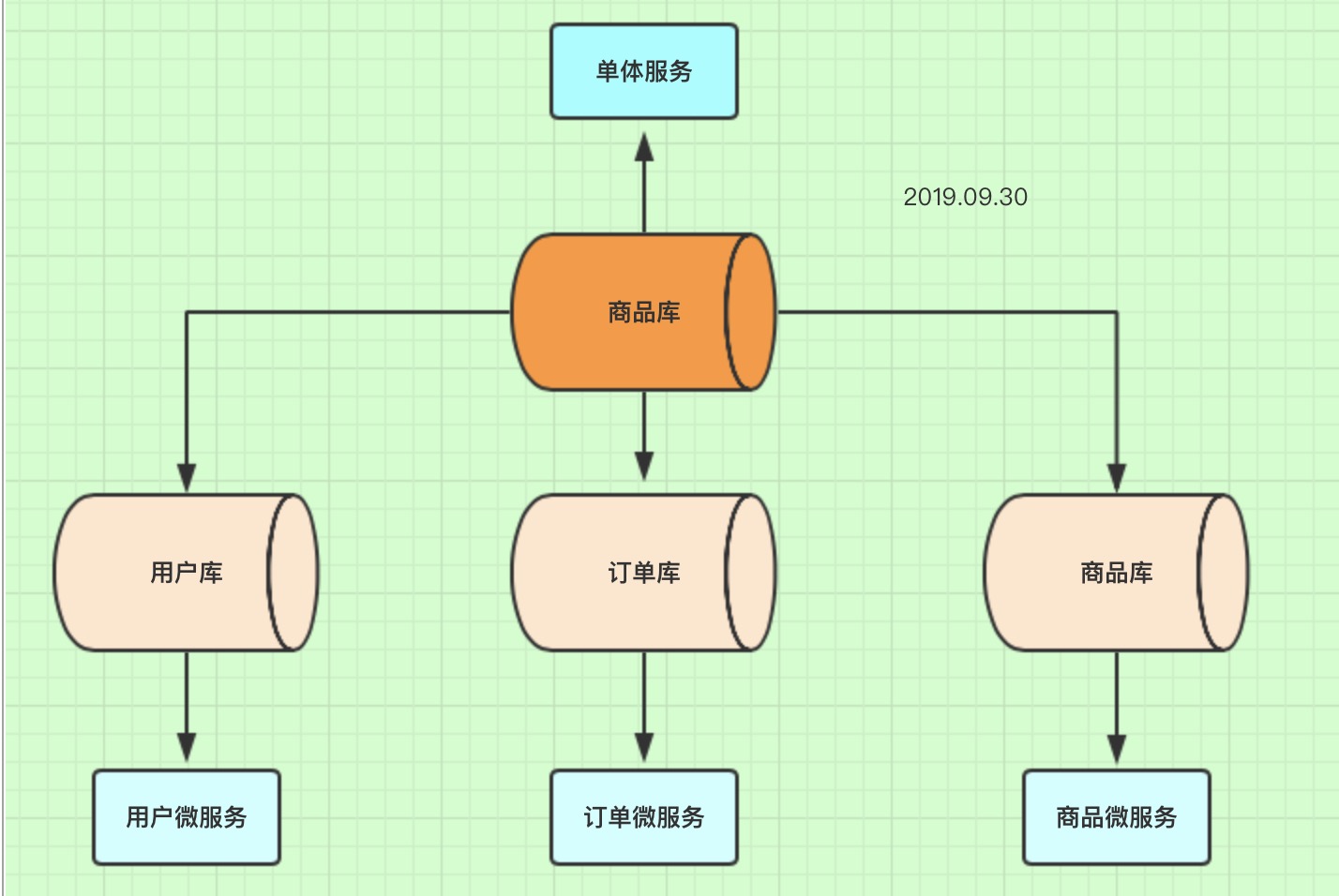
就是根据业务耦合性,将关联度低的不同表存储在不同的数据库。做法与大系统拆分为多个小系统类似,按俺也分类进行独立划分。与 “ 微服务治理” 的做法相似,每个微服务使用单独的一个数据库。
比如说:一个电商服务,拆分为用户库、订单库、商品库等。
1.2、垂直分表
把一个表的多个字段分别拆成多个表,一般按字段的冷热拆分,热字段一个表,冷字段一个表。从而提升了数据库性能。如图:
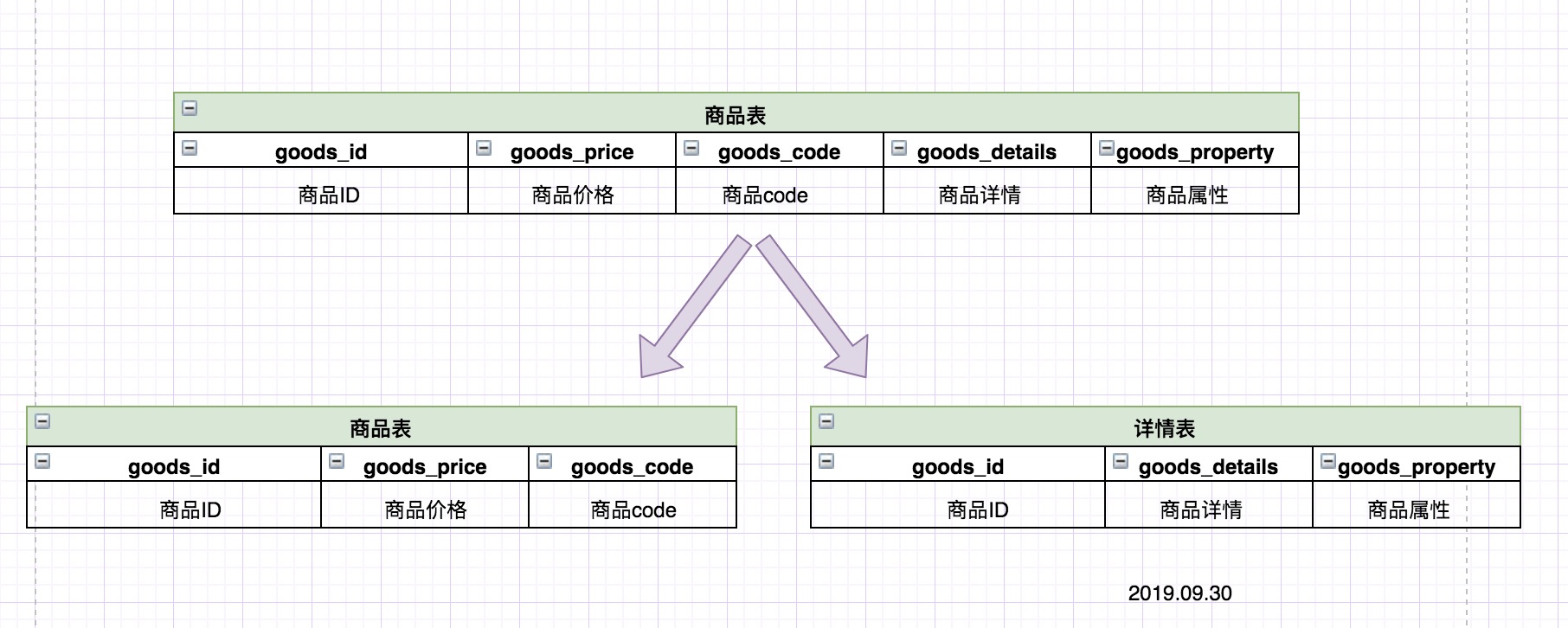
说明:一开始商品表中包含商品的所有字端,但是我们发现:在商品列表的时候我们是不需要显示商品详情和商品属性信息,只有在点击商品详情的时候才会展示商品详情信息。所以可以考虑把商品详情和商品属性单独切分成一张表,提高查询效率。
1.3、垂直切分的优缺点
- 优点
- 解决业务系统层面的耦合,业务清晰
- 与微服务的治理类似,也能对不同业务的数据进行分级管理、维护、监控、扩展等
- 高并发场景下,垂直切分一定程度的提升IO、数据库连接数、单机硬件资源的瓶颈
- 缺点
- 分库后无法Join,只能通过接口聚合方式解决,提升了开发的复杂度
- 分库后分布式事务处理复杂
- 依然存在单表数据量过大的问题(需要水平切分)
2、水平切分
当一个应用难以再细粒度的垂直切分或切分后数据量行数巨大,存在单库读写、存储性能瓶颈,这时候就需要进行水平切分了。
水平切分也可以分为:水平分库和水平分表。
2.1、水平分库
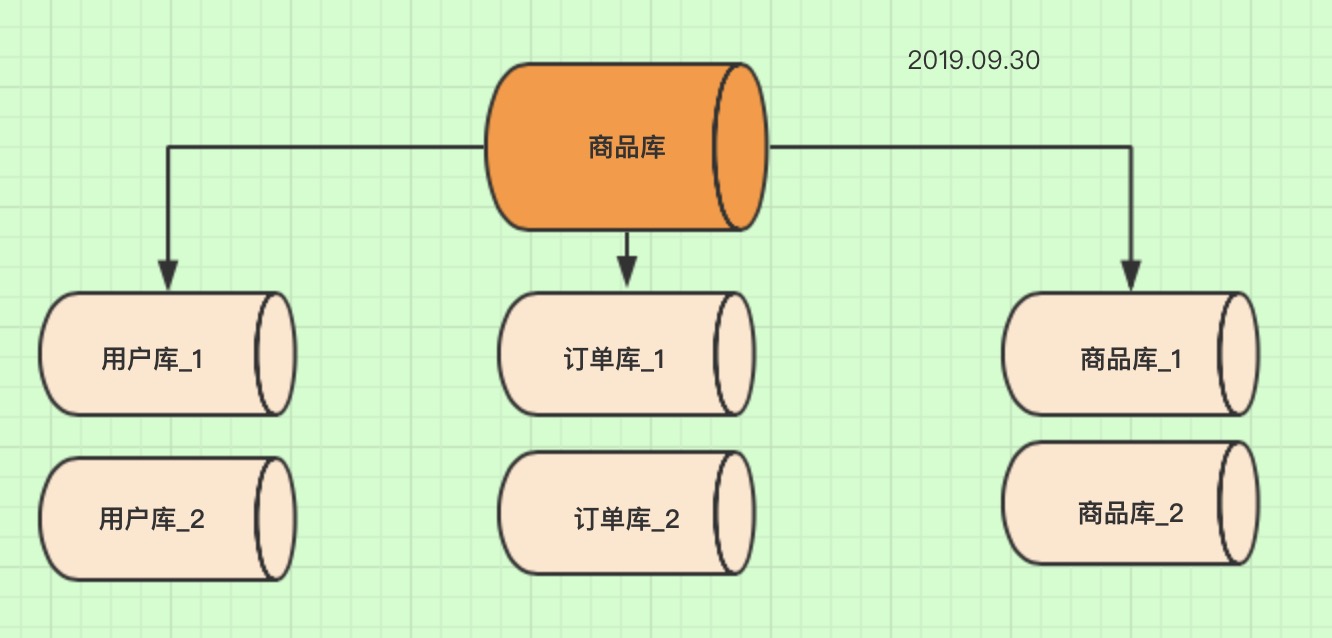
上面虽然已经把商品库分成3个库,但是随着业务的增加一个订单库也出现QPS过高,数据库响应速度来不及,一般mysql单机也就1000左右的QPS,如果超过1000就要考虑分库。
2.2、水平分表
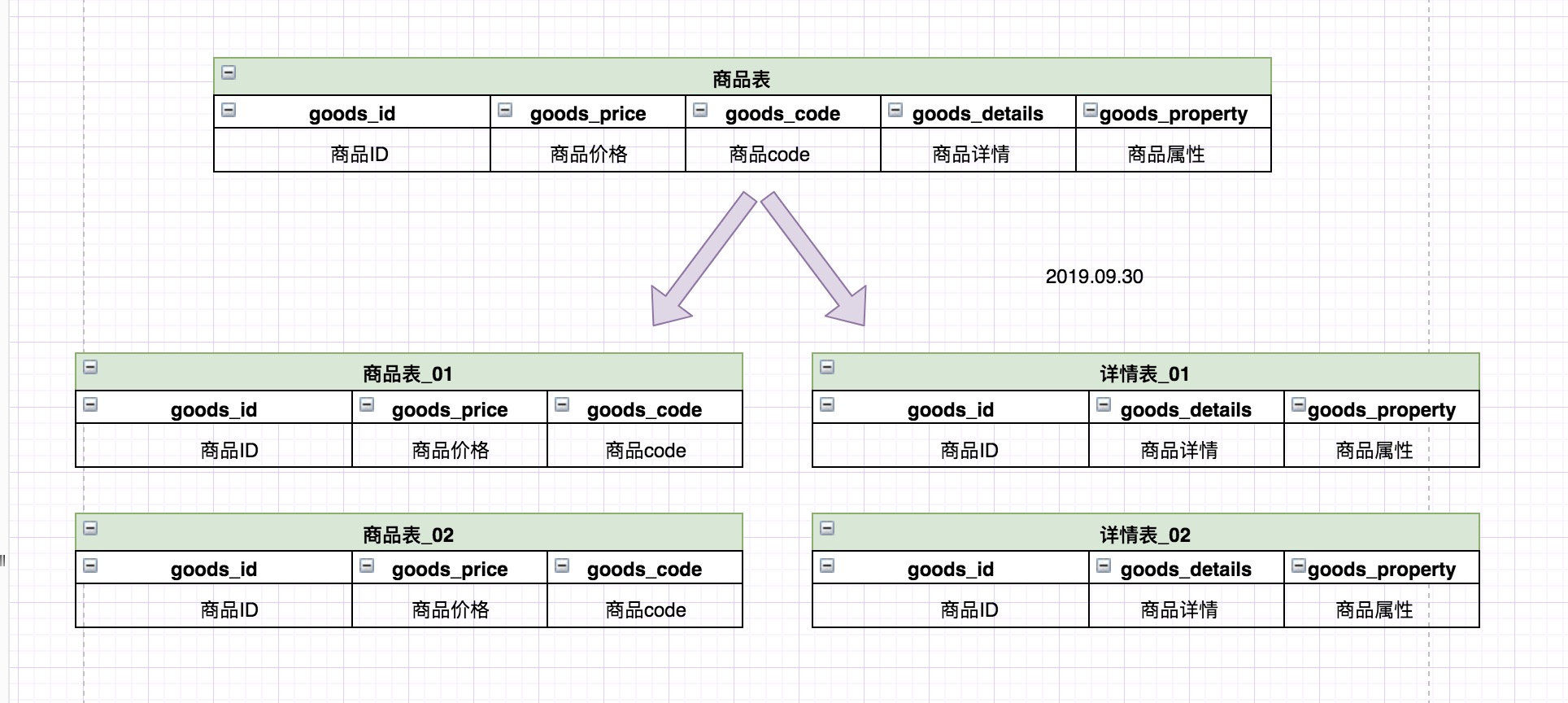
一般我们一张表的数据不要超过1千万,如果表数据超过1千万,并且还在不断增加数据,那就可以考虑分表。
2.3、水平切分的优缺点
- 优点:
- 不存在单库数据量过大、高并发的性能瓶颈,提升系统稳定性和负载能力
- 应用端改造较小,不需要拆分业务模块
- 缺点:
- 跨分片的事务一致性难以保证
- 跨库的Join关联查询性能较差
- 数据多次扩展难度和维护量极大
3、数据分片规则
我们我们考虑去水平切分表,将一张表水平切分成多张表,这就涉及到数据分片的规则,比较常见的有:Hash取模分表、数值Range分表、一致性Hash算法分表。
3.1、Hash取模分表
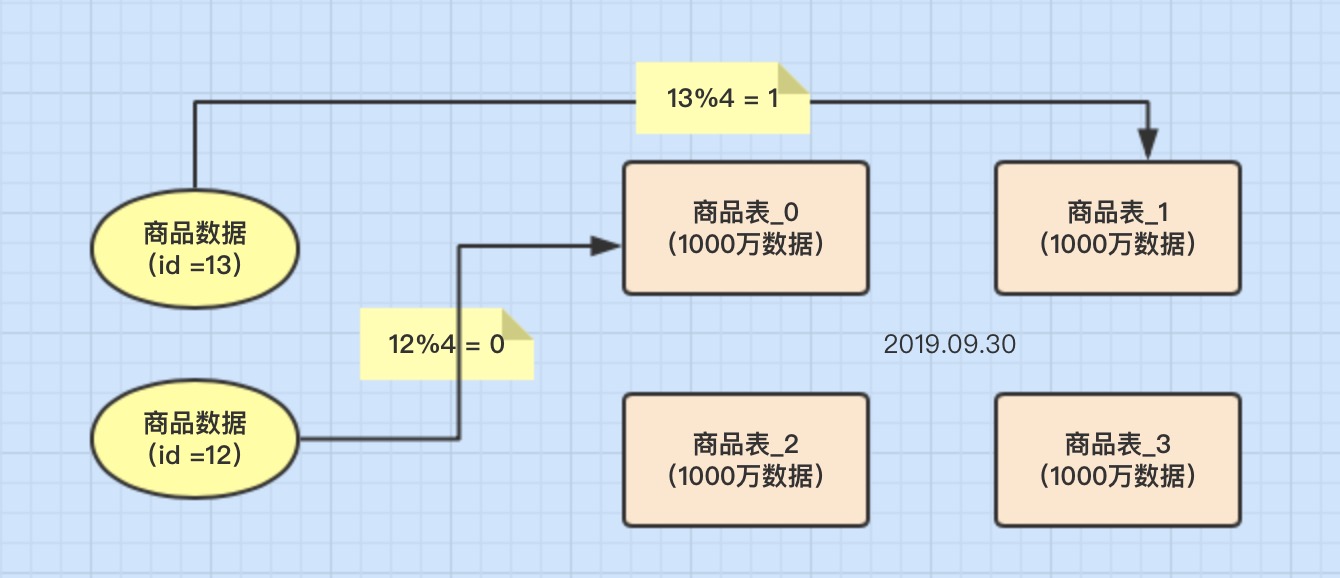
概念 一般采用Hash取模的切分方式,例如:假设按goods_id分4张表。(goods_id%4 取整确定表)
优点
- 数据分片相对比较均匀,不容易出现热点和并发访问的瓶颈。
缺点
- 后期分片集群扩容时,需要迁移旧的数据很难。
- 容易面临跨分片查询的复杂问题。比如上例中,如果频繁用到的查询条件中不带goods_id时,将会导致无法定位数据库,从而需要同时向4个库发起查询,再在内存中合并数据,取最小集返回给应用,分库反而成为拖累。
3.2、数值Range分表
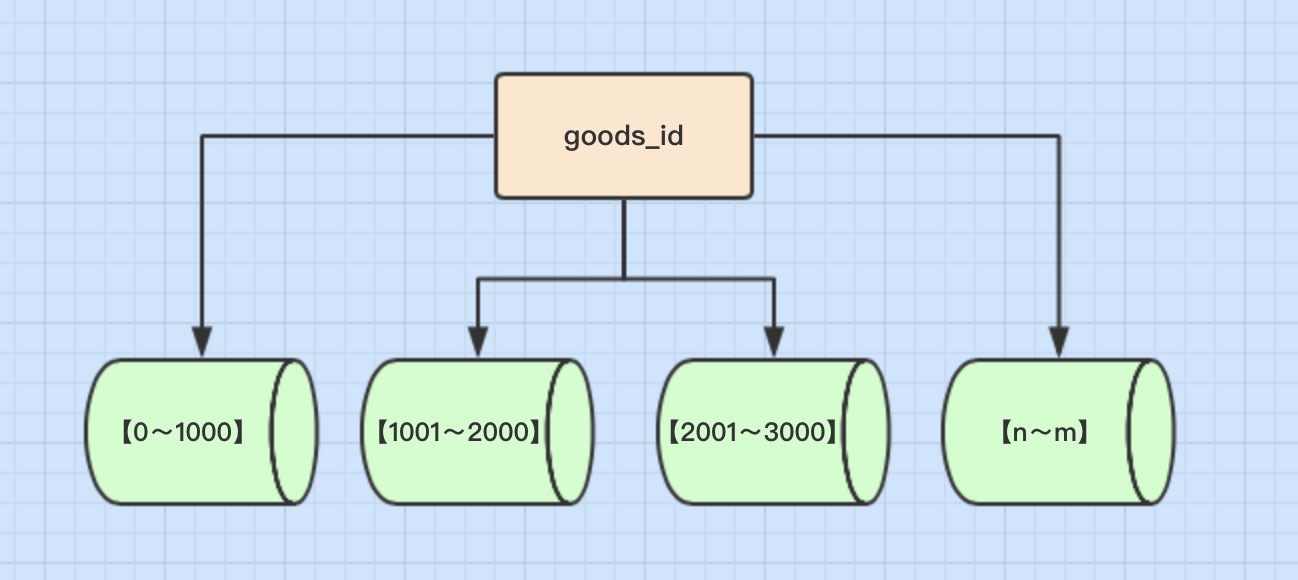
概念 按照时间区间或ID区间来切分。例如:将goods_id为11000的记录分到第一个表,10012000的分到第二个表,以此类推。
如图
优点
- 单表大小可控
- 天然便于水平扩展,后期如果想对整个分片集群扩容时,只需要添加节点即可,无需对其他分片的数据进行迁移
- 使用分片字段进行范围查找时,连续分片可快速定位分片进行快速查询,有效避免跨分片查询的问题。
缺点
- 热点数据成为性能瓶颈。例如按时间字段分片,有些分片存储最近时间段内的数据,可能会被频繁的读写,而有些分片存储的历史数据,则很少被查询
3.3、一致性Hash算法
一致性Hash算法能很好的解决因为Hash取模而产生的分片集群扩容时,需要迁移旧的数据的难题。至于具体原理这里就不详细说,
可以参考一篇博客:一致性哈希算法(分库分表,负载均衡等)
4、分库分表带来的问题
任何事情都有两面性,分库分表也不例外,如果采用分库分表,会引入新的的问题
4.1、分布式事务问题
使用分布式事务中间件解决,具体是通过最终一致性还是强一致性分布式事务,看业务需求,这里就不多说。
4.2、跨节点关联查询 Join 问题
切分之前,我们可以通过Join来完成。而切分之后,数据可能分布在不同的节点上,此时Join带来的问题就比较麻烦了,考虑到性能,尽量避免使用Join查询。
解决这个问题的一些方法:
-
全局表:也可看做是 “数据字典表”,就是系统中所有模块都可能依赖的一些表,为了避免跨库Join查询,可以将 这类表在每个数据库中都保存一份。这些数据通常很少会进行修改,所以也不担心一致性的问题。
-
字段冗余:利用空间换时间,为了性能而避免join查询。例:订单表保存userId时候,也将userName冗余保存一份,这样查询订单详情时就不需要再去查询"买家user表"了。
-
数据组装:在系统层面,分两次查询。第一次查询的结果集中找出关联数据id,然后根据id发起第二次请求得到关联数据。最后将获得到的数据进行字段拼装。
4.3、跨节点分页、排序、函数问题
跨节点多库进行查询时,会出现Limit分页、Order by排序等问题。分页需要按照指定字段进行排序,当排序字段就是分片字段时,通过分片规则就比较容易定位到指定的分片;
当排序字段非分片字段时,就变得比较复杂了。需要先在不同的分片节点中将数据进行排序并返回,然后将不同分片返回的结果集进行汇总和再次排序,最终返回给用户。
4.4、全局主键避重问题
如果都用主键自增肯定不合理,如果用UUID那么无法做到根据主键排序,所以我们可以考虑通过雪花ID来作为数据库的主键。
4.5、数据迁移问题
采用双写的方式,修改代码,所有涉及到分库分表的表的增、删、改的代码,都要对新库进行增删改。同时,再有一个数据抽取服务,不断地从老库抽数据,往新库写,边写边按时间比较数据是不是最新的。
二、Sharding-JDBC
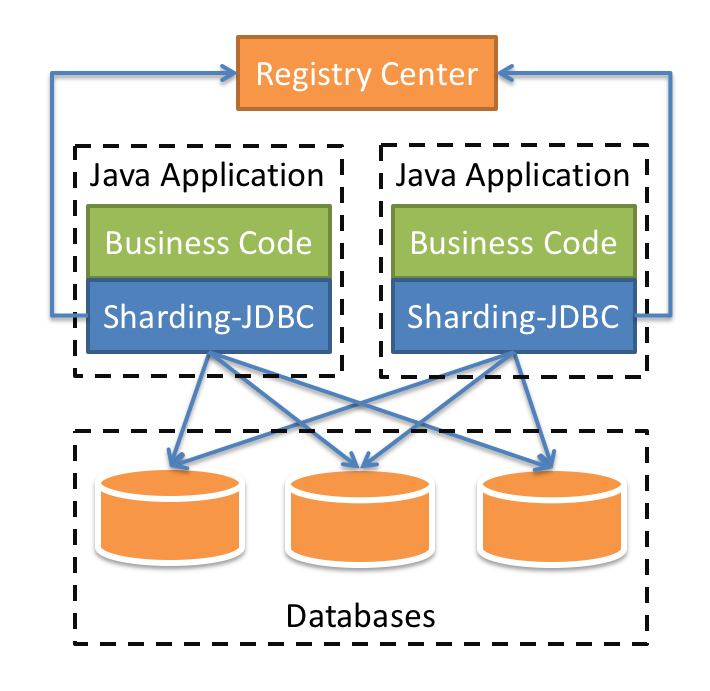
首先为大家介绍一下ShardingSphere,ShardingSphere定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、云原生等各种多样化的应用场景。
Sharding-JDBC是ShardingSphere的第一个产品,也是ShardingSphere的前身。 它定位为轻量级Java框架,在Java的JDBC层提供的额外服务。它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
优点:
- 适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。
1、水平分表演示
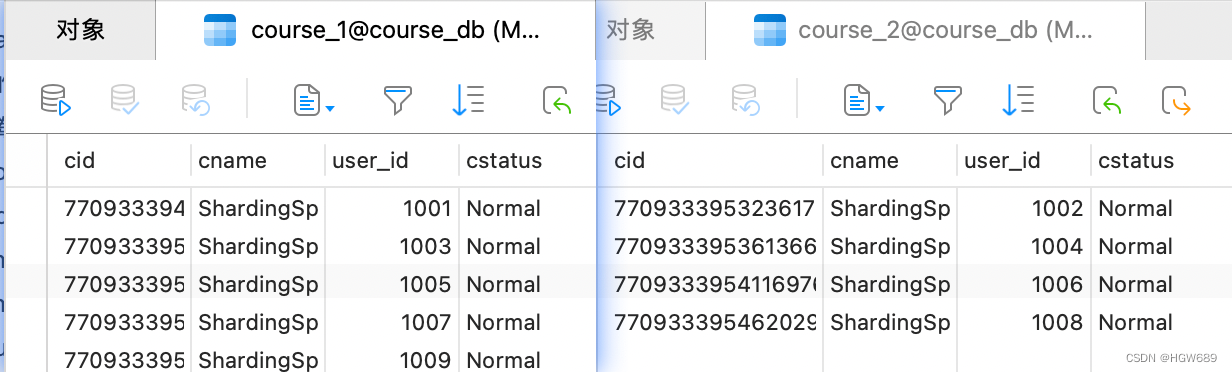
我们来模拟一个场景:插入数据时根据 cid 插入到不同的表中,当 cid 为奇数时插入到 course_1 表,反之当 cid 为偶数时插入到 course_2 表
数据库环境
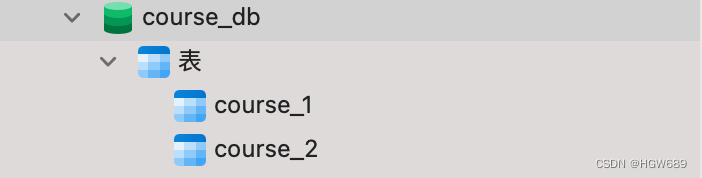
首先我们准备一个 course_db 数据库,在 course_db中 创建两个相同表结构的表,表名分别为:course_1,course_2。
脚本sql给大家放在这了:
CREATE TABLE course_1 (
cid BIGINT ( 20 ) PRIMARY KEY,
cname VARCHAR ( 50 ) NOT NULL,
user_id BIGINT ( 20 ) NOT NULL,
cstatus VARCHAR ( 10 ) NOT NULL
);
CREATE TABLE course_2 (
cid BIGINT ( 20 ) PRIMARY KEY,
cname VARCHAR ( 50 ) NOT NULL,
user_id BIGINT ( 20 ) NOT NULL,
cstatus VARCHAR ( 10 ) NOT NULL
);
第一步、导入导入相关的依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.20</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.0.5</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
第二步、编写domain和mapper
Domain:
package com.hgw.shardingjdbcdemo.domain;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Course {
private Long cid;
private String cname;
private Long userId;
private String cstatus;
}
Mapper:简单的逻辑处理着我们这里使用MyBatisPlus来完成~
package com.hgw.shardingjdbcdemo.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.hgw.shardingjdbcdemo.domain.Course;
import org.springframework.stereotype.Repository;
@Repository
public interface CourseMapper extends BaseMapper<Course> {
}
在主启动类中开启扫描:
package com.hgw.shardingjdbcdemo;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.ComponentScan;
@SpringBootApplication
@MapperScan("com.hgw.shardingjdbcdemo.mapper")
public class ShardingjdbcdemoApplication {
public static void main(String[] args) {
SpringApplication.run(ShardingjdbcdemoApplication.class, args);
}
}
第三步、编写配置文件
# shardingjdbc分片策略
# 配置数据源,给数据源起别名
spring.shardingsphere.datasource.names=m1
# 一个实体类对应多张表,覆盖
spring.main.allow-bean-definition-overriding=true
# 配置数据源具体内容,包含连接池、驱动、地址、用户名和密码
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/course_db?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=hgw6721224
# 指定 course 表分布情况,配置表在拿个数据库里面,表名称都是什么
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m1.course_$->{1..2}
# 指定 course 表里面主键生成的策略 SNOWFLAKE:雪花算法
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
# 指定 表的分片策略 约定cid值奇数添加到course_1表,如果cid是偶数添加到course_2表
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid % 2 == 0 ? 2 : 1}
# 打开sql输出的日志
spring.shardingsphere.props.sql.show=true
测试:接下来让我们演示一下吧~
/**
* 添加课程的方法
*/
@Test
public void addCourse() {
Course course = new Course();
course.setCname("ShardingSphere");
course.setCstatus("Normal");
for (int i = 1; i < 10; i++) {
course.setUserId(1000L+i);
courseMapper.insert(course);
}
}
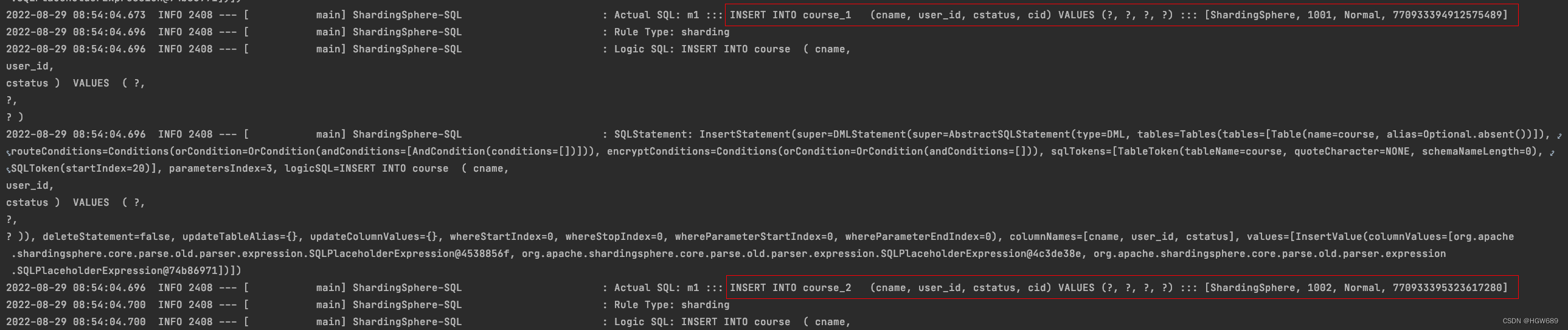
/**
* 查询课程的方法
*/
@Test
public void findCourse() {
LambdaQueryWrapper<Course> queryWrapper = new QueryWrapper<Course>()
.lambda()
.eq(Course::getCid, 770933395411697664L);
Course course = courseMapper.selectOne(queryWrapper);
System.out.println(course);
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1xfo3l32-1661761308299)(ShardingSphere.assets/image-20220829091326705.png)]](https://img-blog.csdnimg.cn/142d606a1cc145f08549fcabb497d421.png)
当我们根据 cid 查询记录时,自动分离查询到对应的数据库中~
BUG处理:

这是因为一个实体类无法对应多张表,此时通过编写配置文件开启即可:
# 一个实体类对应多张表,覆盖
spring.main.allow-bean-definition-overriding=true
2、水平分库演示
我们来模拟一个场景:
- 插入数据时根据 user_id 插入到不同的数据库中,当 user_id 为奇数时插入到 edu_db_1 数据库,反之当 user_id 为偶数时插入到 edu_db_2 数据库中。
- 根据记录的 cid 插入到不同的数据库中,当 cid 为奇数时插入到 course_1 表中,当 cid 为偶数时插入到 course_2 表中。
前期准备:
1、创建两个数据库(edu_db_1,edu_db_2),在数据库中分别创建两个表(course_1,course_2)~
CREATE DATABASE edu_db_1;
CREATE DATABASE edu_db_2;
USE edu_db_1;
CREATE TABLE course_1 (
cid BIGINT ( 20 ) PRIMARY KEY,
cname VARCHAR ( 50 ) NOT NULL,
user_id BIGINT ( 20 ) NOT NULL,
cstatus VARCHAR ( 10 ) NOT NULL
);
CREATE TABLE course_2 (
cid BIGINT ( 20 ) PRIMARY KEY,
cname VARCHAR ( 50 ) NOT NULL,
user_id BIGINT ( 20 ) NOT NULL,
cstatus VARCHAR ( 10 ) NOT NULL
);
USE edu_db_2;
CREATE TABLE course_1 (
cid BIGINT ( 20 ) PRIMARY KEY,
cname VARCHAR ( 50 ) NOT NULL,
user_id BIGINT ( 20 ) NOT NULL,
cstatus VARCHAR ( 10 ) NOT NULL
);
CREATE TABLE course_2 (
cid BIGINT ( 20 ) PRIMARY KEY,
cname VARCHAR ( 50 ) NOT NULL,
user_id BIGINT ( 20 ) NOT NULL,
cstatus VARCHAR ( 10 ) NOT NULL
);
在 SpringBoot 配置文件配置数据库分片规则
1、首先我们需要配置两个数据源
# 配置 第一个 数据源具体内容,包含连接池、驱动、地址、用户名和密码
spring.shardingsphere.datasource.e1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.e1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.e1.url=jdbc:mysql://localhost:3306/edu_db_1?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.e1.username=root
spring.shardingsphere.datasource.e1.password=hgw6721224
# 配置 第二个 数据源具体内容,包含连接池、驱动、地址、用户名和密码
spring.shardingsphere.datasource.e2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.e2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.e2.url=jdbc:mysql://localhost:3306/edu_db_2?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.e2.username=root
spring.shardingsphere.datasource.e2.password=hgw6721224
2、指定 数据库分布情况
# 指定 数据库分布情况,数据库表的分配情况
spring.shardingsphere.sharding.tables.course.actual-data-nodes=p$->{1..2}.course_$->{1..2}
3、指定 数据库的分片策略
# 指定 数据库的分片策略,约定 user_id 为奇数插入到 edu_db_1,约定 user_id 为偶数插入到 edu_db_2
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=e$->{user_id % 2 ? 2 : 1}
整体配置文件如下:
# shardingjdbc分片策略
# 配置数据源,给数据源起别名
spring.shardingsphere.datasource.names=e1,e2
# 一个实体类对应多张表,覆盖
spring.main.allow-bean-definition-overriding=true
# 配置 第一个 数据源具体内容,包含连接池、驱动、地址、用户名和密码
spring.shardingsphere.datasource.e1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.e1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.e1.url=jdbc:mysql://localhost:3306/edu_db_1?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.e1.username=root
spring.shardingsphere.datasource.e1.password=hgw6721224
# 配置 第二个 数据源具体内容,包含连接池、驱动、地址、用户名和密码
spring.shardingsphere.datasource.e2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.e2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.e2.url=jdbc:mysql://localhost:3306/edu_db_2?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.e2.username=root
spring.shardingsphere.datasource.e2.password=hgw6721224
# 指定 数据库分布情况,数据库表的分配情况
spring.shardingsphere.sharding.tables.course.actual-data-nodes=p$->{1..2}.course_$->{1..2}
# 指定 course 表里面主键生成的策略 SNOWFLAKE:雪花算法
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
# 指定 数据库的分片策略,约定 user_id 为奇数插入到 edu_db_1,约定 user_id 为偶数插入到 edu_db_2
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=e$->{user_id % 2 ? 2 : 1}
# 指定 指定表中的字段作为策略
#spring.shardingsphere.sharding.course.database-strategy.inline.sharding-column=user_id
#spring.shardingsphere.sharding.course.database-strategy.inline.algorithm-expression=e$->{user_id % 2 ? 2 : 1}
# 指定 表的分片策略 约定cid值奇数添加到course_1表,如果cid是偶数添加到course_2表
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid % 2 == 0 ? 2 : 1}
# 打开sql输出的日志
spring.shardingsphere.props.sql.show=true
编写测试类:
@Test
public void addCourse() {
Course course = new Course();
course.setCname("ShardingSphere");
course.setCstatus("Normal");
for (int i = 1; i < 100; i++) {
course.setUserId(1000L+i);
courseMapper.insert(course);
}
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TMNU7yIc-1661761495013)(ShardingSphere.assets/image-20220829103839644.png)]](https://img-blog.csdnimg.cn/d1f2ee641510419e99a6854f849dc939.png)
3、垂直分库分表演示
专库转表,模拟查询用户信息的时候查询 user_db 数据库中的 user_1 表。如果操作user对象的数据时只会操作order_db.order_1
环境准备
CREATE DATABASE user_db;
USE user_db;
CREATE TABLE `user_1` (
`user_id` bigint NOT NULL,
`user_name` varchar(100) NOT NULL,
`common_status` varchar(20) NOT NULL,
PRIMARY KEY (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;
CREATE DATABASE order_db;
USE order_db;
CREATE TABLE `order_1` (
`order_id` bigint NOT NULL,
`amount` decimal(10,2) NOT NULL,
`common_status` varchar(20) NOT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;
编写其实体类和mapper~
package com.hgw.shardingjdbcdemo03.domain;
@Data
@AllArgsConstructor
@NoArgsConstructor
@TableName(value = "t_user")
public class User {
private Long userId;
private String userName;
private String userStatus;
}
@Repository
public interface UserMapper extends BaseMapper<User> {
}
在 SpringBoot 配置文件配置数据库分片规则
mybatis-plus.configuration.map-underscore-to-camel-case=true
# shardingjdbc分片策略
# 配置数据源,给数据源起别名
spring.shardingsphere.datasource.names=u1,o1
# 一个实体类对应多张表,覆盖
spring.main.allow-bean-definition-overriding=true
# 配置 第一个 数据源具体内容,包含连接池、驱动、地址、用户名和密码
spring.shardingsphere.datasource.u1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.u1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.u1.url=jdbc:mysql://localhost:3306/user_db?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.u1.username=root
spring.shardingsphere.datasource.u1.password=hgw6721224
# 配置 第二个 数据源具体内容,包含连接池、驱动、地址、用户名和密码
spring.shardingsphere.datasource.o1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.o1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.o1.url=jdbc:mysql://localhost:3306/order_db?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.o1.username=root
spring.shardingsphere.datasource.o1.password=hgw6721224
# 指定 数据库分布情况,数据库表的分配情况
spring.shardingsphere.sharding.tables.order.actual-data-nodes=o1.order_1
# 指定 Order 表里面主键生成的策略 SNOWFLAKE:雪花算法
spring.shardingsphere.sharding.tables.order.key-generator.column=orderId
spring.shardingsphere.sharding.tables.order.key-generator.type=SNOWFLAKE
# 指定表分片策略,所有与order相关操作都只操作order_1表
spring.shardingsphere.sharding.tables.order.table-strategy.inline.sharding-column=order_id
spring.shardingsphere.sharding.tables.order.table-strategy.inline.algorithm-expression=order_1
# 指定 数据库分布情况,数据库表的分配情况
spring.shardingsphere.sharding.tables.user.actual-data-nodes=u1.user_1
# 指定 User 表里面主键生成的策略 SNOWFLAKE:雪花算法
spring.shardingsphere.sharding.tables.user.key-generator.column=userId
spring.shardingsphere.sharding.tables.user.key-generator.type=SNOWFLAKE
# 指定表分片策略,所有与user相关操作都只操作user_1表
spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=user_1
# 打开sql输出的日志
spring.shardingsphere.props.sql.show=true
4、公共表
上面我们进行了分库分表,但我们在实际项目中会设计一些字典项表,这些字典项表或许在各个数据库中都会使用,我们要如何保证该公共表的一致性呢?Sharding-JDBC帮我们封装好了~
spring.shardingsphere.sharding.broadcast-tables=公共表
spring.shardingsphere.sharding.tables.公共表.key-generator.column=公共表主键
spring.shardingsphere.sharding.tables.公共表.key-generator.type=SNOWFLAKE















 664
664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









