







前言
看了18章,函数式编程是什么东西,大概有了一个理解,但大多还是抽象的概念,接下来看第19章,函数式编程的技巧,相信会有更多的收获。
一、无处不在的函数
函数可以像任何其他值一样随意使用:可以作为参数传递,可以作为返回值,还可以存储在数据结构中。能够像普通变量一样使用的函数称为一等函数。
这点在前面学习函数式接口就知道了,Java8还有其他新东西,比如Lambda表达式和方法引用。
Function<String, Integer> strToInt = Integer::parseInt; //把方法保存为变量
1.高阶函数
让我们看看两个例子:
Comparator<Apple> c = comparing(Apple::getWeight)
Function<String, String> transformationPipeline
= addHeader.andThen(Letter::checkSpelling)
.andThen(Letter::addFooter);
函数式编程的世界里,如果函数,比如Comparator.comparing,能满足下面任一要求就可以被称为高阶函数:
1.接收至少一个函数作为参数
2.返回结果是一个函数
Comparator.comparing接收了一个函数为参数同时返回了另一个函数(一个比较器)。
andThen 接收了个函数,返回了个Function。
注意,高阶函数也有副作用,因为无法预知会接收什么样的参数,所以应该将可能产生副作用的参数记录下来。
2.柯里化
在理解柯里化是什么之前,我们先来看个例子:
static double converter(double x, double f, double b){
return x * f + b;
}
这是个宽泛的单位转化方式,x是希望转换的数量,f是转换因子,b是基线值,就像个一阶函数,比如摄氏度转为华氏度的公式是x*9/5 + 32。
当然,我们想要使用这个方法,来广泛用于所有问题,这时候就有问题了,我们每次都要输入新的f和b,一来比较繁琐,二来容易出错。
于是,我们写一个新的方法:
static DoubleUnaryOperator curriedConverter(double f, double b){
return (double x) -> x * f + b;
}
这是一个高阶函数,是一个工厂方法,接收两个参数f,b,返回一个lambda表达式方法。
现在,我们可以通过这个工厂方法,生产出我们想要的方法:
DoubleUnaryOperator convertCtoF = curriedConverter(9.0/5, 32);
DoubleUnaryOperator convertUSDtoGBP = curriedConverter(0.79, 0); // 美元转英镑
接下来,我们就可以使用生产出的方法了:
double gbq = converUSDtoGBP(1000); //1000美元是多少英镑
柯里化是一种将具备两个参数的函数转化为使用一个参数的函数,并且这个函数的返回值也是一个函数,它会作为新函数的一个参数。后者的返回值和初始函数的返回值相同,即f(x,y)=(g(x))(y)。
当一个函数使用的所有参数仅有部分(少于函数的完整参数列表)被传递时,通常我们说这个函数是部分求值的。
二.持久化数据结构
在前面说到,函数式编程希望用不变的数据结构,说的更细一点是不允许修改任何全局数据结构或者任何作为参数传入的结构。因为一旦修改,两次相同的调用就可能产生不同的结果,这违背了透明性原则。
1.破坏式更新和函数式更新
// 表示从X-Y的一个单向链
class TrainJourney {
public int price;
public TrainJourney onward;
public TrainJourney(int p, TrainJourney t){
price = p;
onward = t;
}
// 连接两个TrainJourney,表示从X-Y-Z
static TrainJourney link(TrainJourney a, TrainJourney b){
if (a==null) return b;
TrainJourney t = a;
while(t.onward != null){ // 找到末端
t = t.onward;
}
t.onward = b; // 把末端连上b
return a;
// 价格就按a的来
}
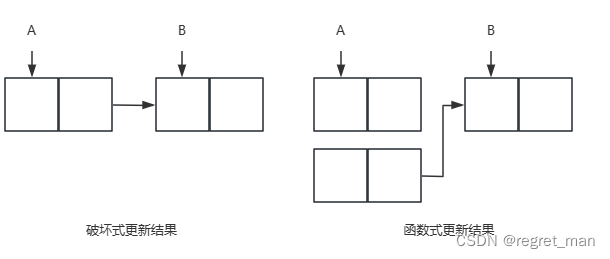
这里有个问题,就是我向link输入一个A,一个B,那么A 的原有结构就被破坏了,也就是破坏式更新。
但是,用函数式的方法如下:
static TrainJourney append(TrainJourney a, TrainJourney b){
return a==null ? b : new TrainJourney(a.price, append(a.onward, b);
}
没有改变任何数据结构,而且用递归代替了while迭代,没有创建整个新对象的副本,比如A是n个元素的序列,B是m个元素的序列,返回了一个n+m个元素的序列,这其中,前n个是新创建的,后m个是和B共享的。(请注意,不要修改append的结果,因为会破坏b)。
2.另一个例子
来看看二叉搜索树(left<root<right),还有个通过key找到val的方法:
class Tree {
private String key;
private int val;
public Tree(String k, int v, Tree 1, Tree r){
key = k;val = v;left = l;right = r;
}
}
class TreeProcessor {
// 通过key找到val值
public static int lookup(String k, int defaultval, Tree t){
if (t == null) return defaultval;
if (k.equals(t.key)) return t.val;
// 递归
return lookup(k, defaultval, k.compareTo(t.key) < 0 ? t.left : t.right);
}
}
现在想想,如何更新key对应的val?
public static void update(String k, int v, Tree t){
if (t == null) {
//创建一个新的节点
}
else if (k.equals(t.key)) t.val = v;
// 递归
else update(k, v, k.compareTo(t.key) < 0 ? t.left : t.right);
}
如果没有找到,那就会增加一个节点,但这样写会很繁琐,一个解决方法是直接返回刚遍历的树。
public static Tree update(String k, int v, Tree t){
if (t == null)
t = new Tree(k, v, null, null);
else if (k.equals(t.key))
t.val = v;
else if (k.compareTo(t.key) < 0)
t.left = update(k, v, t.left);
else
t.right = update(k, v, t.right);
return t;
}
当然,这两种写法都会改变原有的数据结构,那么怎么采取函数式的写法呢?
首先,我们来看看遍历二叉搜索树是怎么样的,如图,假设我们插入一个G,那么遍历顺序是:D — F 最后插入G 。

可以看到,我们接触了的节点是就是D和F,而函数式编程不希望我们修改已有的数据结构,所以就用构造来替代:
public static Tree fupdate(String k, int v, Tree t){
return (t == null) ?
new Tree(k, v, null, null) :
k.equals(t.key) ?
new Tree(k, v, t.left, t.right) :
k.compareTo(t.key) < 0 ?
new Tree(t.key, t.val, fupdate(k, v, t.left), t.right) :
new Tree(t.key, t.val, t.left, fupdate(k, v, t.right));
}
书上为了不用if-else,就这样写了,目的是为了告诉读者一个思想,就是函数体里只包含一条语句,没有副作用。
用if-else来写是这样的:
public static Tree fupdate(String k, int v, Tree t){
if (t == null)
new Tree(k, v, null, null);
else if(k.equals(t.key))
new Tree(k, v, t.left, t.right);
else if(k.compareTo(t.key) < 0)
new Tree(t.key, t.val, fupdate(k, v, t.left), t.right);
else
new Tree(t.key, t.val, t.left, fupdate(k, v, t.right));
}
其实就是改成构造。
用图来理解的话,结果是这样的:
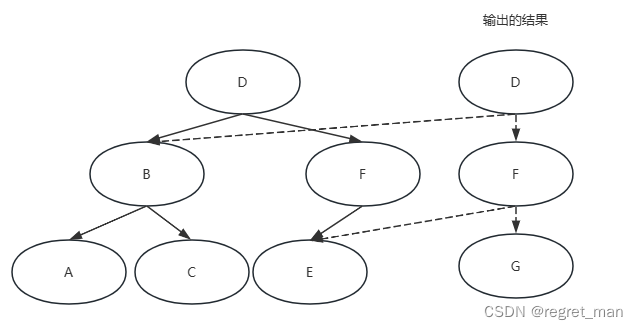
我们创建了新的D和F节点,没有改变原有的数据结构。
这种函数式的数据结构通常被成为持久化的——数据结构的值始终保持一致,不受其他部分变化的影响。
为了保证“不修改”,所有程序员都不能改,有一个人直接修改了数据都会有问题。
那我就是想让某些用户能看到变化呢?一是考虑在改变数据前保存个副本,二是用函数式的方式,因为会创建新的数据结构,然后给个正确版本的数据结构。
三.Stream的延迟计算
Stream是个很好用的东西,但它有个局限,就是无法声明一个递归的Stream,因为Stream仅能使用一次。
递归式Stream是个什么东西?先看个例子,我们想要个由质数构成的Stream:
public static Stream<Integer> primes (int n) {
return Stream.iterate(2, i -> i + 1) //从2开始的无限流
.filter(MymathUtils::isPrime) //筛选质数
.limit(n); //选n个
}
public static boolean isPrime (int candidate) { // 判断是不是质数
int candidateRoot = (int) Math.sqrt((double) candidate); // 取平方根
return IntStream.rangeClosed(2, candicateRoot) // 从2到平方根开始除
.noneMath(i -> candidate % i == 0); // 看看有没有整除, 没有就说明是质数
}
这样写的思想其实还是遍历所有的数,一个一个计算,只不过用了Stream。
理想的情况是,Stream能实时的筛选掉能被质数整除的数字,也就是拿到了质数,能被质数整除的数肯定不是质数(除了自己)。这样怎么写呢?
(1)一个Stream,在里面选择质数。
(2)从这个Stream里取出一个质数(第一个数是2).
(3)从Stream的尾部开始,筛选掉所有能被该质数整除的数。
(4)最后剩下的结果是新的Stream,继续来进行筛选,回到第一步,所以这个算法是递归的。
不过,这个算法不是很好,原有是多方面的。
额。
总之就是Stream实现不了,因为Stream用一下就没了。
而Stream有个特点,就是延迟执行,直到终止操作时才会实际地计算。
所以可以实现延迟计算,就是创建一个延迟列表的数据结构。
不过我很好奇,这个一般会用到吗?去网上找只找到用Spring Cloud Stream 整合RabbitMQ搞定时任务。
这里暂时先不写了。
四.模式匹配
Java语言中暂时并未提供这一特性。
额。
看个Scala语言的一个例子:
def simplifyExpression(expr : Expr) : Expr = expr match {
case BinOp("+", e, Number(0)) => e
case BinOp("*", e, Number(1)) => e
case BinOp("/", e, Number(1)) => e
case_ => expr
}
这个玩意的效果像是Switch,而case后面有个复杂的匹配,就是(匹配String, 匹配e,匹配Number(0))
我们可以模仿这种方式,创建一些数据结构,然后用(匹配, 匹配 …)来简化表达式。
比如:
// 对每个参数进行匹配,binopcoded等是函数,识别是否为BinOp,Number
static<T> T patternMatchRxpr(e, (op, l ,r) -> {return binopcode;},
(n) -> {return numcode;},
() -> {return defaultcode;});
// 写一个方法,输入一个东西,返回匹配结果
public static Expr simplify(Expe e) {
TriFunction<String, Expr, Expr, Expr> binopcase = (opname, left, right) -> {
// 解析操作
if ("+".equals(opname)){...}
if ("*".equals(opname)){...}
return new BinOp(opname, left, right);
};
Function<Integer, Expr> numcase = val -> mew Number(val);
Supplier<Expr> defaultcase = () -> new Number(0);
// 模式匹配
return patternMatchExpr(e, binopcase, numcase, defaultcase);
}
Expr e = new BinOp("+", new Number(5), new Number(0));
Expr match = simplify(e);
好像懂了,又好像没懂,这代码看起的我有点懵逼。
我看C#有模式匹配,反正Java是没有。
五.杂项
剩下一些说更难的,我也看不下去了,列一下:
缓存或记忆表
返回同样的对象
结合器
小结
1.什么是高阶函数
2.柯里化
3.持久化数据结构
其他
看了下20章,在介绍Scala,因为Scala从函数式编程的角度来说远超了Java,而且也是运行在JVM之上的,二者还能融合使用,估计我是用不到了。















 882
882











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









