







检索增强生成 (Retrieval-Augmented Generation, RAG) 是指在利用大语言模型回答问题之前,先从外部知识库检索相关信息。
文章概述了RAG的三种模式:Naive RAG, Advanced RAG, Modular RAG。接着文章还梳理了RAG的三个主要组成部分:检索器、生成器以及增强方法。此外,文章还介绍了RAG的评估方法。最后文章从各个方面介绍了RAG的未来研究方向。
为什么需要RAG?
尽管大语言模型在NLP领域表现出色,但是在许多方面仍然存在不足。例如,它们会产生不准确的信息,不能利用最新的信息生成响应。而且在处理特定领域或者高度专业化的查询时可能会出现知识缺失的情况。以上就是纯参数化大预言模型的局限。为了解决这些问题,语言模型可以采取半参数化方法,将非参数化的语料库数据库与参数化模型相结合。这种方法被称为检索增强生成(Retrieval-Augmented Generation, RAG)。
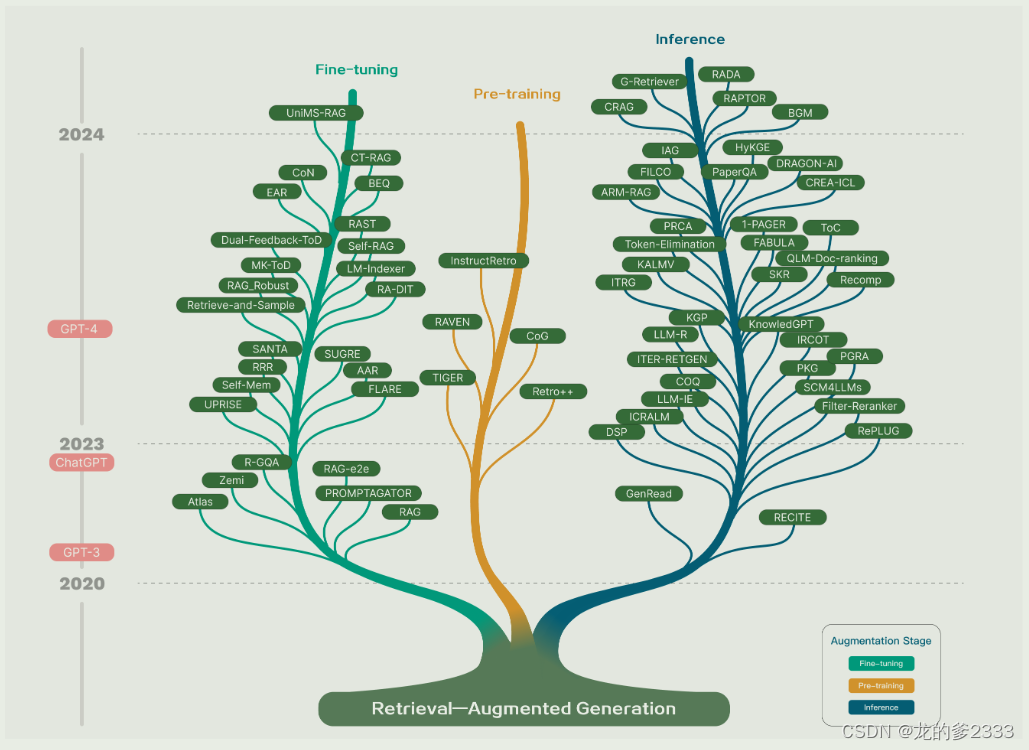
下图是RAG模型和算法的发展历程:
RAG框架
原始RAG (Naive RAG)
原始 RAG 的流程包括传统的索引、检索和生成步骤,被概括为一个“检索” - “阅读”框架。
索引 指的是在离线状态下,从数据来源处获取数据并建立索引的过程。
具体建立步骤如下:
数据索引:包括清理和提取原始数据,将PDF、HTML、Word、Markdown等不同格式的文件转换成纯文本。
分块:将加载的文本分割成更小的片段。由于语言模型处理上下文的能力有限,因此需要将文本划分为尽可能小的块。
嵌入和创建索引:这一阶段涉及通过语言模型将文本编码为向量的过程。所产生的向量将在后续的检索过程中用来计算其与问题向量之间的相似度。由于需要对大量文本进行编码,并在用户提问时实时编码问题,因此嵌入模型要求具有高速的推理能力,同时模型的参数规模不宜过大。完成嵌入之后,下一步是创建索引,将原始语料块和嵌入以键值对形式存储,以便于未来进行快速且频繁的搜索。
检索
根据用户的输入,嵌入模型将查询转化为向量。系统会计算查询与语料库中的文档块的相似度,然后根据相似度选出top-k块内容作为当前查询的补充内容。
生成
将检索到的内容与问题合并成一个新的提示词。之后,大语言模型根据新的提示词来回答问题。
原始RAG面临的挑战
①检索质量:这方面存在多种问题,但是最主要的问题还是低精度。也就是检索到的文档块与查询内容不相关,这就会导致信息错误或者不连贯。 其次是低召回率问题,即未能检索到所有相关的文档块,使得大语言模型无法获取足够的背景信息来合成答案。此外,检索到过时的信息也会对响应的质量造成影响。
②生成质量:这方面也同样面临多种问题。最突出的是制造错误信息,就是模型在缺乏足够上下文的情况下虚构答案。另一个问题是回答不相关,即模型生成的答案未能针对查询问题。进一步来说,生成有害或偏见性回应也是一个问题。
③增强过程:增强过程面临着几个重要挑战。最大的挑战是,如何将检索到的文档有效的融入当前的生成任务中。当多个文档包含相似信息时,会造成冗余和重复;当检索到的内容风格不一致时,增强过程需要处理这些差异性,以确保最终输出的一致性。最后生成模型可能会过度依赖检索到的内容从而生成与检索到的内容一样的响应。
高级RAG(Advanced RAG)
高级RAG有针对性的对原始RAG进行了改进。在检索生成质量方面,高级 RAG 引入了预检索和后检索的方法。它还通过滑动窗口、细粒度分割和元数据等手段优化了索引,以解决 Naive RAG 所遇到的索引问题。同时,高级 RAG 也提出了多种优化检索流程的方法。在具体实施上,高级 RAG 可以通过流水线方式或端到端的方式进行调整。
预检索
优化数据索引:① 提升数据颗粒度:如剔除文本中的无关信息和特殊字符;消除术语和实体歧义,剔除重复或者冗余信息;尽可能验证每项数据;更新过时文档等。②优化索引结构:调整数据块大小、改变索引路径以及加入图结构等。③添加元数据信息:将引用的元数据(例如日期和用途等)嵌入到数据块中。④对齐优化:引入“假设性问题”,即创建适合用每篇文档回答的问题,并将这些问题与文档结合起来。⑤混合检索:融合不同的检索技术,以适应不用类型的查询要求。
嵌入:①微调嵌入:微调嵌入的作用可以比作在语音生成前对“听觉”进行调整,优化检索内容对最终输出的影响。②动态嵌入:动态嵌入根据单词出现的上下文进行调整,为每个单词提供不同的向量表示。
检索后处理流程
- Rerank(重新排序):重新排序,将最相关的信息置于提示的前后边缘,是一个简单直接的方法。
- Prompt压缩:为了减轻检索文档中的噪音对RAG产生的不利影响,在处理的后期阶段需要压缩无关紧要的上下文,凸显关键段落,并缩短整体的上下文长度。
- RAG管道优化:检索过程的优化旨在提升 RAG 系统的效率和信息质量。当前的研究主要集中在智能结合不同的搜索技术,优化检索步骤,引入认知回溯概念,灵活运用多样化的查询策略,并利用嵌入式相似度。这些努力共同追求在 RAG 检索中达到效率与上下文信息丰富度的平衡。
- 混合搜索的探索:RAG 系统巧妙结合了基于关键词、语义以及向量的多种搜索技术。这种综合方法让 RAG 系统能够应对不同的查询类型和信息需求,有效地获取最相关且内容丰富的信息。
- 递归检索与查询引擎:递归检索的首要步骤是在初始阶段获取小型文档块,以便抓住关键语义。随后,该过程会提供更大的文档块,为大语言模型 (LM) 提供更丰富的上下文信息。
- StepBack-prompt 方法:集成到 RAG 流程中的 StepBack-prompt 方法使大语言模型 (LLM) 在处理具体案例时能够退一步,转而思考背后的普遍概念或原则。
- 子查询:根据不同场景,我们可以采取多种查询策略,如使用 LlamaIndex 等框架提供的查询引擎、树状查询、向量查询或基本的块序列查询。
- HyDE方法:这种方法基于一个假设:相较于直接查询,通过大语言模型 (LLM) 生成的答案在嵌入空间中可能更为接近。HyDE 首先响应查询生成一个假设性文档(答案),然后将其嵌入,并利用此嵌入去检索与假设文档类似的真实文档。这种方法强调答案之间的嵌入相似性,而非单纯依赖于查询的嵌入相似性。但在某些情况下,特别是当语言模型对话题不够熟悉时,它可能导致错误实例的增加。
模块化RAG
新模块
- 搜索模块:与简单/高级 RAG 的查询和语料间的常规相似性检索不同,这个特定场景下的搜索模块融合了直接在(附加的)语料库中进行搜索的方法。
- 记忆模块:本模块充分利用大语言模型本身的记忆功能来引导信息检索,其核心原则是寻找与当前输入最为匹配的记忆。
- 额外生成模块: 面对检索内容中的冗余和噪声问题,这个模块通过大语言模型生成必要的上下文,而非直接从数据源进行检索。通过这种方式,由大语言模型生成的内容更可能包含与检索任务相关的信息。
- 任务适应模块:该模块致力于将 RAG 调整以适应各种下游任务。
- 对齐模块:在 RAG 的应用中,查询与文本之间的对齐一直是影响效果的关键因素。在模块化 RAG 的发展中,研究者们发现,在检索器中添加一个可训练的 Adapter 模块能有效解决对齐问题。
- 验证模块:在实际应用中,我们无法确保检索结果的可靠性,检索到不相关的数据可能会导致大语言模型产生错误信息。因此,在检索文档后加入一个额外的验证模块,该模块用来评估文档与查询之间的相关性,这样可以提升RAG的鲁棒性。
新模式 Modular
RAG 的组织方法具有高度灵活性,能够根据特定问题的上下文,对 RAG 流程中的模块进行替换或重新配置。目前的研究主要围绕两种组织模式:一是增加或替换模块,二是调整模块间的工作流程。
- 增加或替换模块:在增加或替换模块的策略中,我们保留了原有的检索 - 阅读结构,同时加入新模块以增强特定功能。
- 调整模块间的工作流程:在调整模块间流程的领域,重点在于加强语言模型与检索模型之间的互动。
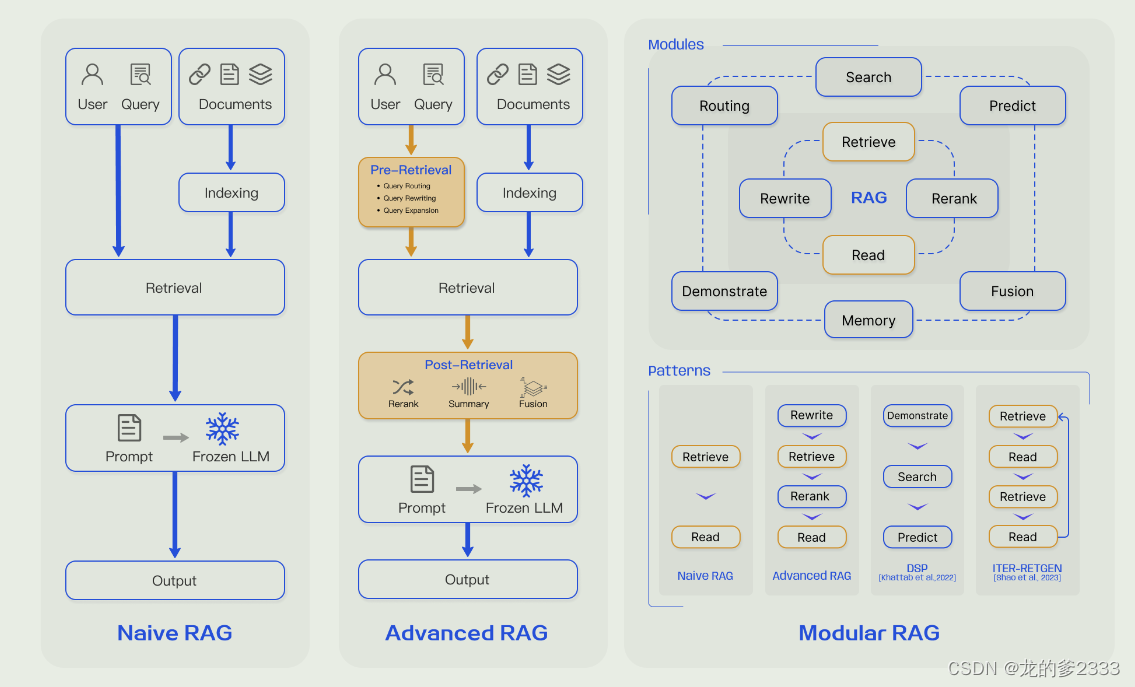
RAG三种范式之间的比较。(左) Naive RAG主要包括三个部分:索引、检索和生成。( Middle ) Advanced RAG围绕预检索和post - retrieval提出了多种优化策略,其过程类似于Naive RAG,仍然遵循链式结构。(右)模块化RAG继承和发展了之前的范式,整体上表现出更大的灵活性。这一点在多个具体功能模块的引入和现有模块的替换上体现得非常明显。整个过程不局限于顺序检索和生成;它包括迭代和自适应检索等方法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









