







论文摘要
这篇论文提出了 DSP (DEMONSTRATE–SEARCH–PREDICT) 框架,用于在知识密集型 NLP 任务中,将检索模型 (RM) 和语言模型 (LM) 进行有效结合。DSP 框架通过在 LM 和 RM 之间传递自然语言文本,实现更复杂的交互,从而更好地利用两者的优势。DSP 框架使用一系列可组合的函数,用于实现演示、检索和预测三个阶段的任务,并通过弱监督学习的方法自动标注演示数据,从而降低标注成本。实验结果表明,DSP 框架在开放域问答、多跳问答和对话问答等任务上取得了优于传统方法的性能。
DSP 框架主要针对以下问题进行优化和改进:
1、知识密集型任务:
问题:知识密集型 NLP 任务 (例如问答、事实核查、信息检索等) 通常需要大量的知识,而预训练语言模型 (LM) 中的知识往往是不完整和不可靠的。
改进:DSP 框架通过引入检索模型 (RM),可以有效地利用外部知识库中的知识,从而提高 LM 在知识密集型任务上的性能。
2、中间步骤标注:
问题:在传统的 NLP 任务中,中间步骤 (例如多跳问答中的各个查询) 通常需要人工标注,这需要大量的时间和精力。
改进:DSP 框架使用弱监督学习的方法,可以自动标注中间步骤,从而降低标注成本,提高标注效率。
3、模型泛化能力:
问题:预训练语言模型 (LM) 的泛化能力有限,难以适应新的任务和数据集。
改进:DSP 框架通过使用零样本学习和可组合的函数,可以增强模型的泛化能力,使其能够适应不同的任务和数据集。
4、模型可解释性:
问题:预训练语言模型 (LM) 的预测结果往往缺乏可解释性,难以理解模型是如何得出预测结果的。
改进:DSP 框架通过检索到的段落作为证据,可以解释模型的预测结果,从而提高模型的可解释性。
主要贡献:
- 提出DSP架构,该架构用于上下文学习,完全依赖于在冻结的检索模型和语言模型之间做交互(传递自然语言文本或者分数)。此外,DSP还引入了一系列可组合的功能,用于实现演示、检索和预测三个阶段的任务。
- 使用弱监督学习的方法,自动标注演示数据,降低标注成本。
- 在开放域问答、多跳问答和对话问答等任务上取得了优于传统方法的性能。
DSP架构
DSP 框架的核心思想是将检索模型 (RM) 和语言模型 (LM) 协同工作,通过三个阶段的流程来实现更复杂的 NLP 任务。
DEMONSTRATE (演示阶段):
- 目标:生成演示,用于引导LM适应特定任务。
- 方法:使用弱监督学习,从标注数据中自动生成演示。
- 优点:不需要人工手动标注演示,减少标注成本;易于扩展,可以适应不同的任务和数据集。
SEARCH (检索阶段):
- 目标:使用检索模型检索与任务相关的段落。
- 方法:根据语言模型生成的问题或者查询,使用RM检索相关段 落,并将其作为上下文传递给语言模型。
- 优点:提高了语言模型的推理能力,使其能够更好地理解问题和答案之间的关系。
PREDICT (预测阶段):
- 目标:使用演示和检索到的段落,生成最终答案或者预测。
- 方法:使用语言模型生成答案或者预测,并利用检索到的段落作为证据,解释模型的预测结果。
- 优点:提高预测的可靠性和可解释性。
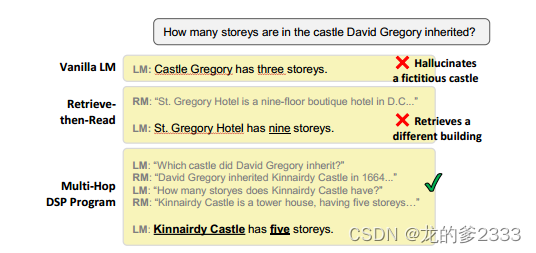
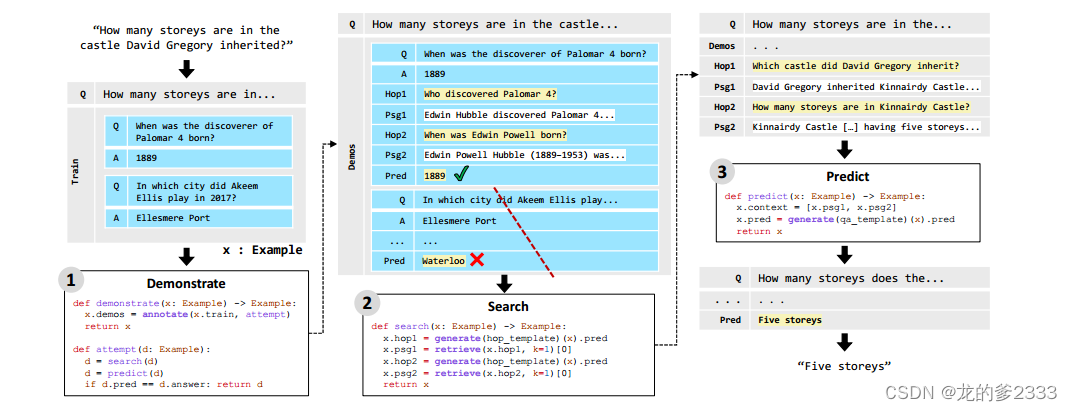
关于弱监督学习方法实现自动标注数据:
弱监督学习 是一种利用弱标签 (例如答案) 来训练模型的方法。在 DSP 中,弱标签是指任务的最终目标,例如多跳问答中的答案。
DSP自动标注数据流程如下(生成中间步骤):
1.选择训练数据: 从训练集中选择一部分数据,用于生成演示。
2.执行零样本学习: 使用 LM 对训练数据进行零样本学习,并尝试回答问题或执行其他任务。
3.缓存中间结果: 将 LM 生成的问题、查询、段落、摘要等中间结果进行缓存。
4.评估结果: 评估 LM 的预测结果是否正确。
5.生成演示: 如果预测结果正确,则将缓存的中间结果作为演示添加到训练数据中。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









