







论文全称:PRCA: Fitting Black-Box Large Language Models for Retrieval Question
Answering via Pluggable Reward-Driven Contextual Adapter
核心问题:如何在检索增强式问答(ReQA)任务中,利用大型语言模型(LLMs)作为生成器,同时避免对其进行耗时的微调。
解决方案:提出了一种可训练的插件式奖励驱动上下文适配器(PRCA),它位于检索器和生成器之间,以黑盒方式工作。
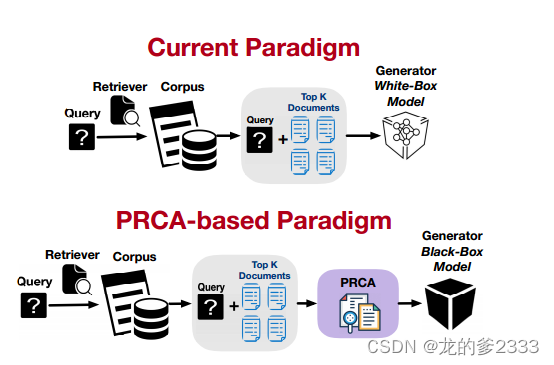
PRCA优势:
- 黑盒 LLMs 集成: PRCA 允许将 LLMs 作为黑盒集成到 ReQA 框架中,无需微调,也适用于闭源模型。
- 鲁棒性: PRCA 兼容各种检索器和生成器,因为它保持了检索器和生成器的冻结状态。
- 效率: PRCA 通过减少输入生成器的文本长度来提高框架的效率,并可以适应不同的检索语料库。
将LLM作为黑盒模型:
将 LLM 作为黑盒模型,意味着我们将其视为一个不可见的、无法直接修改的组件,只关注其输入和输出。在这种情况下,我们无法了解 LLM 内部的结构和参数,也无法对其进行直接修改或优化。
原因:
- LLM 参数规模庞大:例如 GPT-3 拥有 1750 亿参数,进行微调需要大量的计算资源和时间。
- LLM 开源情况:部分 LLM 是闭源的,无法获取其内部结构和参数。
- LLM 部署复杂性: 将 LLM 部署到生产环境中可能面临各种挑战,例如资源分配、模型更新等。
例子:
- API 调用: 通过 API 调用 LLM,只关注输入和输出,无需了解其内部结构。
- 模型集成:将 LLM 集成到其他模型中,只使用其预测功能,无需修改其参数。
利与弊:
利:降低训练成本、适用闭源模型、简化部署过程、提高模型泛化能力、提高开发效率。
弊:无法理解 LLM 的决策过程、难以进行模型优化、难以解释模型的预测结果
PRCA工作原理:
1.上下文提取阶段(相当于是精炼上下文)
- PRCA 从检索器获取查询和 Top-K 相关文档,然后通过监督学习训练,学习如何从这些文档中提取信息丰富的上下文。
- 目标是最小化提取的上下文与真实上下文之间的差异。
2.奖励驱动阶段
- 将生成器视为奖励模型,根据生成答案与真实答案之间的 ROUGE-L 分数计算奖励信号。
- 通过强化学习优化 PRCA 的参数,目标是最大化生成器的奖励,并保持与原始参数的相似性。
- 为了解决黑盒生成器带来的挑战,PRCA 使用了一种策略来估计每个时间步的奖励 Rt,从而避免频繁调用生成器 API。
- PRCA 使用近端策略优化(PPO)算法进行参数更新。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









