








摘要
我们研究了语言模型执行组合推理任务的能力,其中整体解决方案依赖于正确组合子问题的答案。我们衡量模型能够正确回答所有子问题但不能生成整体解决方案的频率,我们称之为组合性差距。
我们通过提出多跳问题来评估这一比率,这些问题的答案需要组合在预训练期间不太可能同时观察到的多个事实。在GPT-3系列模型中,随着模型大小的增加,我们发现单跳问答性能比多跳问答性能提高得更快,因此组合性差距没有减小。这个令人惊讶的结果表明,虽然更强大的模型记忆和回忆更多的事实性知识,但他们在进行这种组合推理的能力上并没有相应的提高。
然后,我们展示了如何通过明确的推理来缩小组合性差距的激发提示(如思维链)。我们提出了一种新的方法,自我询问,它进一步改善了思维链。在我们的方法中,模型在回答初始问题之前明确地问自己(并回答)后续问题。我们最后展示了self-ask的结构化提示让我们可以轻松地插入搜索引擎来回答后续问题,这进一步提高了准确性。
1 引言
组合推理让模型能够超越对直接观察到的信息的死记硬背,从而推导出以前未见过的知识。例如,一个模型应该能够回答“伊丽莎白女王的统治持续了多久?”即使这个答案在训练数据中没有明确出现,也可以通过回忆她的和她父亲的去世日期,并对这些事实进行推理来得出答案。虽然语言模型(LMs)在问答方面表现出了强大的性能,但仍然不清楚这是由于记忆大量语料库还是由于推理。
首先,我们使用多跳问答来量化LMs的推理能力。我们提出了一个新的、自动生成的数据集,Compositional Celebrities(CC),包含8.6千个两跳问题;它将频繁陈述的事实以不太可能的方式组合在一起(例如,“贾斯汀·比伯出生那年谁赢得了大师赛锦标赛?”),这使我们能够区分记忆和推理。直观地说,回答这类问题所需的推理在获得相关事实后似乎是微不足道的。
我们引入了“组合性差距”(compositionality gap)这个术语,用来描述模型在所有组合性问题中,对于子问题回答正确但整体回答错误的组合性问题的比例。不出所料,我们发现无论是单跳还是多跳问答,随着预训练模型的规模增大,性能都会单调提升。然而,有趣的是,我们发现组合性差距在大约40%左右保持恒定,不受模型大小和训练技巧的影响,并且从规模上没有明显的改进(见图1)。这个结果尤其令人惊讶,因为这类问题所需的推理步骤是直截了当的,它表明大规模的预训练在教授模型记忆事实方面非常有效,但不是在如何组合这些事实方面。我们还发现,模型对某一事实的确信度与它能否将这一事实与其他事实组合起来回答关于它的组合性问题之间存在正相关关系。
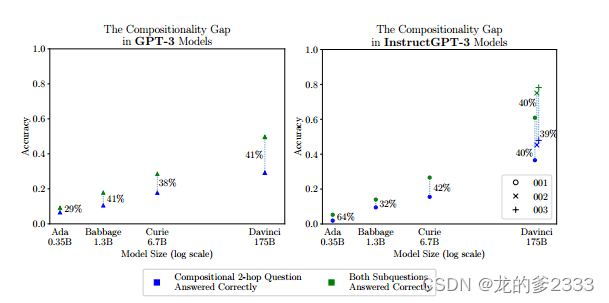
图1:组合性差距不随规模而减小。该图显示了组合名人数据集中组合问题(蓝色)和组成它们的两个子问题(绿色)的准确性。△为普通GPT型号,◦、x、+为001、002和003指令型号。百分比是相对的,表明构成差距。
接下来,我们通过使用所谓的“引导性提示”(elicitive prompts)来缩小组合性差距。组合性问题需要比单跳问题更多的计算和知识检索;然而,通过使用天真提示(即期望问题之后立即输出答案),我们总是给模型大约相同数量的步骤来回答问题。我们展示了引导性提示,如思维链(Wei et al., 2022b),允许模型在输出最终答案之前“深思熟虑”,这显著提高了性能。然后我们展示了我们的自我提问提示,其中提示让LM将复杂问题分解为更容易的子问题,它在回答主问题之前先回答这些子问题,这可以进一步提高性能。
除了CC之外,我们还对两个现有的自动生成数据集(2WikiMultiHopQA, Ho等人,2020年,和Musique, Trivedi等人,2022年)以及我们手动构建的第三个数据集Bamboogle(包含125个问题)应用了引导性提示。Bamboogle是一个由作者编写的包含两跳问题的数据集,所有问题都足够困难,以至于无法通过流行的互联网搜索引擎回答,但是所有支持性的证据都可以在维基百科中找到(因此可能包含在任何语言模型的预训练集中)。
我们构建的两个数据集——Bamboogle和之前提到的Compositional Celebrities——是互补的,并服务于不同的研究目的。Bamboogle是一个小型的、手工制作的数据集,涵盖了不同领域、以独特方式编写的多种不同类型的问题,而CC(类似于Musique和2WikiMultiHopQA)是一个大型的、自动生成的数据集,每个问题都符合我们制作的17个模板之一(即比Bamboogle的变化要小得多)。Compositional Celebrities旨在估计在大规模问题上的组合性差距,而Bamboogle旨在衡量问答系统回答各种组合性问题的能力,尽管统计功效较低。
最后,我们展示了自我提问的结构可以轻松地与互联网搜索引擎结合,以进一步提高组合性问题的结果。
总之,我们系统地揭示了一个现象:尽管语言模型有时能够组合它们在预训练期间分别观察到的事实,但在大量情况下它们无法做到这一点,即使它们单独展示了组成事实的知识。我们将这种比例称为组合性差距,并表明它并不会随着规模的增大而缩小。我们展示了引导性提示,如思维链和我们自我提问提示,可以缩小甚至有时关闭这个差距,并提高语言模型解决复杂组合性问题的能力。最后,自我提问可以轻松地与搜索引擎结合,以进一步提高性能。
2 系统地测量组合性差距
随着语言模型规模的增大,它们包含了越来越多的关于世界的知识(Brown等人,2020年;Srivastava等人,2022年)。但是它们的组合能力是如何扩展的呢?我们通过一种新的方法来研究这个问题,该方法展示了如何正式量化语言模型的组合能力。
我们的方法基于两跳问题,这些问题在语法上是正确的,但以前可能没有说过,例如,“弗里达·卡洛出生地的电话代码是什么?”我们通过抓取名人名单以及他们的出生地和时间来生成这些问题。然后我们检索关于每个出生国家(首都、货币、电话代码……)和每个出生年份(那一年大师赛锦标赛的获胜者或诺贝尔文学奖……)的事实,并通过组合事实对来生成两跳问题。附录表3展示了我们Compositional Celebrities(CC)数据集中每个17个类别的示例问题;附录A.2节详细介绍了该数据集。
我们设计的CC旨在测量组合性差距,它故意包含了直接且明确的问题,其中(1)每个事实可能已经在训练数据集中出现了多次,但(2)两个事实的组合足够不自然,以至于它可能从未出现在训练集或互联网上。
这种问题格式有许多优点:几乎所有的问题都有一个正确答案,它们可以很容易地分解为子问题(让我们可以验证LM是否知道背景事实),并且对于大多数问题,答案域非常大(不像是非/是或选择题)。因此,随机猜测正确答案的机会很低。
我们在CC上评估了GPT-3,使用2次提示(2-shot prompt),分别为2跳和1跳问题。我们对每个问题使用了一个类别特定的提示,其中包含从数据集中移除的2个随机选择的示例;见附录表4和5。GPT-3(davinci-002)正确回答了45.4%的2跳问题。在某些类别中,例如出生地/域名,准确率甚至达到了84.6%,尽管模型在训练期间很可能没有明确看到这些问题的绝大多数。该模型甚至正确回答了一些极端问题,例如“柏拉图出生地的顶级域名是什么?”在最难的类别,如出生年份/文学诺贝尔奖得主,GPT-3只正确回答了1.2%的问题。然而,它正确回答了该数据集上80%的子问题,这表明它已经看到了回答这些问题所需许多单独的事实,但缺乏足够的组合能力来正确回答问题。附录表6显示了完整的结果。
我们将模型正确回答单个子问题但不是组合问题的问题比例称为组合性差距。图1显示,令人惊讶的是,随着我们增加GPT-3模型的大小,无论是InstructGPT还是非Instruct系列的模型,组合性差距并没有缩小。这表明,随着GPT-3模型规模的增大,它对世界的了解越来越多,但其组合这些知识的能力增加的速度较慢。
我们已经展示,GPT-3偶尔能够足够好地存储一个事实,以至于在它单独出现时能够回忆起来(例如,“贾斯汀·比伯是什么时候出生的?”(1994年)和“1994年大师赛锦标赛的冠军是谁?”(何塞·玛丽亚·奥拉扎巴尔))。然而,它不能组合这两个事实(“贾斯汀·比伯出生那年大师赛锦标赛的冠军是谁?”)。
我们如何确定GPT-3将能够或不能够组合哪些事实?附录图5显示,当正确子问题答案的困惑度降低时(即,模型对正确答案变得更加自信),正确回答组合性问题的概率增加。例如,当正确子问题答案的最大困惑度(即,分配给两个子问题中模型不太自信的正确答案)在1.232和6.738之间时,模型正确回答42.6%的组合性问题。然而,当最大困惑度在1.000和1.002之间时,模型正确回答81.1%的组合性问题。我们在按平均困惑度而不是更差的困惑度对子问题对进行排序时,观察到了类似的模式。
能够在包含类似1跳问题的提示中正确回答1跳问题,并不意味着模型已经完全“学习”了给定的事实。我们的结果表明,当模型能够更自信地回忆这些事实时,即对于1跳问题的正确答案分配了较低的困惑度时,模型可以以更高的比率组合事实。这表明,除了报告正确答案的准确率之外,额外报告对正确答案分配的困惑度可能是在下游问答任务上评估语言模型的更好方法。同时期的论文(Srivastava等人,2022年;Wei等人,2022a年)最近也提倡这一点,但角度不同。他们展示了证据,表明随着模型规模的增大,即使实际任务指标(即,准确率)没有改进,交叉熵损失可以指示下游任务性能的改进。
3 启发式提示缩小组合性差距,提高答题效果
接下来,我们展示了使用我们的选择提示(selfask,图2),首先将多跳问题分解为更简单的子问题,然后回答子问题,最后回答主问题,这使得LM能够以更高的成功率回答组合问题。
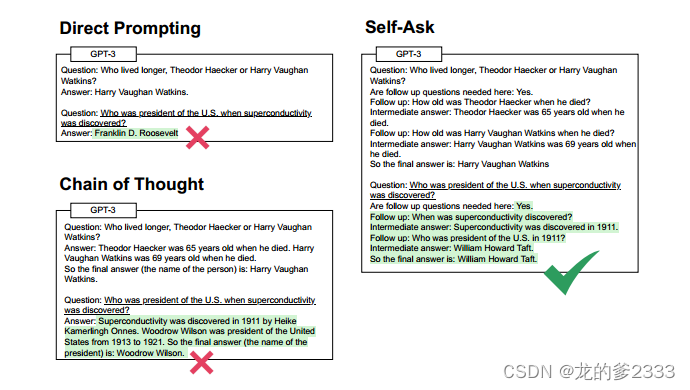
图2:直接提示(Brown et al, 2020)与思维链和我们对Bamboogle问题的自我问法进行比较。白色背景的文本是提示,绿色背景的文本是LM输出,带下划线的文本是推理时间问题。这里的提示被缩短了,我们实际上为这个数据集使用了4次提示,参见3.5节。
我们在四个数据集上展示了这一点:composition Celebrities,两个先前存在的数据集,和一个新数据集Bamboogle;我们通过手动创建组合问题来设计这个新数据集,这些问题足够简单,可以让一个流行的互联网搜索引擎给出答案,但又足够难,以至于它给出的答案是不正确的。这也提供了证据,证明这个问题以前没有出现在网络上,因此可能不会包含在LM的训练集中。此外,所有问题都是2跳,其中两个“跳”都来自Wikipedia,因此应该在任何LM的训练集中。与CC(以及类似的Musique和2WikiMultiHopQA)不同,在CC中,17类问题中的每一类都遵循相同的模板,而Bamboogle的问题几乎都是彼此独立的。因此,我们认为它是测量LM组成能力的其他数据集的合适补充。
我们选择的两个现有数据集是2WikiMultiHopQA (Ho et al, 2020)和Musique (Trivedi et al, 2022)。我们在开放域设置中使用它们(这些不是多项选择数据集),并且,像Roberts等人(2020)和Brown等人(2020)一样,我们只使用这些数据集中的问答对,而不是它们包含的任何相关文本段落。这些数据集都包含来自维基百科文章中出现的事实的2跳组合问题。
我们可以将问答的提示方法分为两大类。第一类,直接回答提示,是(Brown et al ., 2020)使用的naïve提示方法,其中每个问题后面直接跟着答案;参见附录图4和图5中的示例。第二类是启发式提示,让模型在回答问题之前“把事情说清楚”。
思维链和便签本(Nye et al, 2021)就是这类提示的例子。
如果我们期望一个问题立即得到答案,那么LM用来回答这个问题的计算量总是大致相同的,假设问题的长度相对相似,当问题更难时,计算量不一定更长。为了让模型将更多的计算应用于更难的问题,我们可以允许它“把事情说清楚”。我们发现启发式提示在作文题上的准确性要高得多。这可以在附录图6中观察到,它显示在CC上,选择性提示有时可以回答更多的组合问题,而不是单独正确回答子问题的直接提示。这可能是因为启发性提示比直接提示包含更多的信息。请注意,本节的其余部分表明,启发性提示提高了性能,但并没有表明它们缩小了组合性差距,因为我们缺乏CC以外的数据集的子问题。Kojima等人(2022)的“Let 's think step by step”也是一种启发性方法。
但在我们的实验中,它在InstructGPT-Davinci002/Davinci模型上的准确率为45.7%/1.1%,而self-ask在CC模型上的准确率为79.6%/54.2%。这与Kojima等人的结果一致,他们的方法不如思维链强,使用非指示模型进一步降低了性能。因此,我们不在这里用这种方法做更多的实验。
3.1 self-ask
我们的方法基于思维链提示,但与输出连续不间断的思维链不同,我们的提示让模型在回答之前明确声明它想要提出的下一个跟进问题。此外,我们的方法插入了如“跟进:”这样的支架,我们发现这可以提高以易于解析的方式输出正确最终答案的能力。正如我们后面所展示的,这使得将我们的方法与互联网搜索引擎集成以回答跟进问题变得容易,这进一步提高了性能。
自我提问(如图2所示)需要一个一跳或少数跳的提示,以演示如何回答问题。我们的提示从那些示例开始,之后我们追加推理时的问题。然后我们在提示的末尾插入短语“这里需要跟进问题吗:”,因为我们发现这样做可以略微提高结果。
模型然后输出一个响应。在大多数情况下,它首先输出“Yes.”,意味着需要跟进问题。然后LM输出第一个跟进问题,回答它,并继续提问和回答跟进问题,直到它认为有足够的信息;此时,它在提供最终答案之前输出“So the final answer is:”;这使得最终答案易于解析,即最后输出行的“:”之后出现的内容。在罕见的情况下,LM决定不需要提出跟进问题,并且可以立即回答问题。与思维链一样,我们的方法完全是自动的:我们只需输入提示和测试时的问题,模型就会自行执行整个过程,包括决定提出多少个跟进问题。
在较小的模型中,提示末尾加上额外的“这里需要跟进问题吗:Yes. 跟进:”可以提高性能,但对于Davinci则不必要。
我们假设,自我询问相对于思维链的优势在于,它将完整问题的分解(通过形成子问题)与这些子问题的实际答案分离开来。此外,严格的脚手架式自问使模型更容易以简洁、可解析的方式陈述最终答案。
在某些情况下,思维链不会输出简短的最终答案,而是选择完整的句子,这不是提示中展示的格式。在Bamboogle中,40%的链式思维最终答案不是简短形式,而自我提问的这一比例为17%,自我提问+搜索引擎的这一比例为3%。附录表15包含了思维链失败的例子。
3.2 Bamboogle
Musique、2WikiMultiHop和CC是自动生成的大型数据集,其中的问题符合少量模板。我们通过阅读随机的维基百科文章,并编写一个关于它们的2跳问题,手动构建了Bamboogle,这是一个包含125个问题的数据集,这导致了一个多样化的数据集,挑战了系统分解复杂问题的能力。
我们通过查询关于文章主题的两个不相关的事实,为每篇文章推导出2跳问题。例如,在阅读旅行者2号的文章时,我们了解到它是有史以来第一个接近天王星的探测器,它是由泰坦IIIE火箭发射的,这就引出了一个问题:“第一个接近天王星的航天器是由什么火箭发射的?”然后,我们通过互联网搜索引擎运行我们的问题,只有当查询引出的答案“特色片段”不正确时,才将它们添加到最终数据集中;见附录图4。我们使用搜索引擎来过滤我们的数据集,因为我们假设它无法回答这些问题表明这些问题不在网络上。附录表7给出了更多的Bamboogle问题示例。
3.3 利用搜索引擎改进自我询问
与思维链不同,自我问清楚地划分了每个子问题的开始和结束。
因此,我们可以使用搜索引擎来代替LM来回答子问题。搜索引擎具有LM所缺乏的特性,例如易于快速更新的能力(Kasai et al, 2022)。
因此,我们将一个流行的互联网搜索引擎整合到自我询问中。图3描述了Self-ask + Search Engine (SA+SE)。请注意,SA+SE使用与自我询问相同的提示。我们将提示符输入到语言模型;如果LM输出“Follow up:”,我们让它完成问题的生成,通过输出字符串“Intermediate answer:”来表示。在此响应之后,我们停止LM,而不是让它输出自己的答案,我们将模型请求的完整子问题输入到搜索引擎API,然后将搜索引擎返回的答案添加到提示中,然后要求LM继续生成其答案。
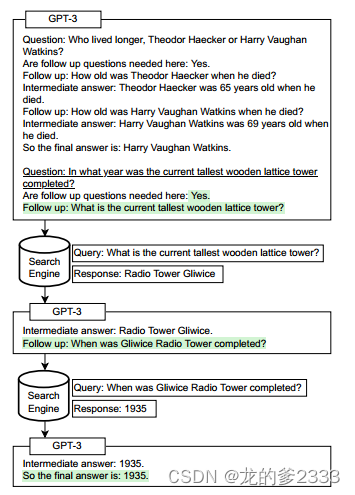
图3:自问+搜索引擎:白色背景提示,绿色lm生成文本。我们首先使用几个提示(为了节省空间,这里减少了),并将测试时间问题(下划线)附加到其中。然后,LM生成一个后续问题,我们将其输入到互联网搜索引擎中。将响应插入到提示的其余部分中,以便LM生成下一个后续问题。然后重复这个过程,直到LM决定输出最终答案。
因此,语言模型接收一个组合性问题作为输入,并通过首先输出一个初始子问题到搜索引擎来分解它;答案被反馈给语言模型,它生成另一个子问题,如此循环,直到输出最终答案(标记为最终答案)。由于我们将搜索引擎的结果插入到提示中,就像语言模型输出了那个结果一样,我们不需要用任何特殊语法微调我们的模型,也不需要修改模型的架构。此外,我们甚至不需要修改我们的提示来将搜索引擎集成到自我提问中!在所有实验中,我们用于自我提问+搜索引擎方法的提示与我们用于自我提问的提示完全相同。这种方法只需要几行代码就可以实现。它让语言模型——无需任何更改——使用一个API,而API调用对语言模型不是直接暴露的,只有它们的结果。
3.4 实验
我们将我们的结果与以下基线进行比较;请注意,对于所有提示,我们总是使用少量样本提示,即我们向模型展示演示问题及其正确答案,格式与提示相同。直接提示(Direct Prompting):这个来自Brown等人(2020年)的天真提示方法向模型呈现一个问题,然后直接输出答案。思维链(Chain of Thought):这个提示方法向模型提出一个问题,并让模型在输出最终答案之前输出一个思维链。
搜索引擎(Search Engine):在这里,我们简单地将问题输入搜索引擎。如果它返回一个特色摘要(见图4),我们就返回那个;否则,我们返回它从第一个搜索结果中提取的文本。搜索引擎+语言模型后处理(Search Engine + LM postprocessing):搜索结果可能是完整的句子,而不仅仅是最终答案,这会根据我们的指标(如精确匹配)降低性能。为了解决这个问题,我们使用Davinci-002从搜索引擎返回的结果中提取最终答案。

图4:精选片段中的错误答案。问题是“谁是阿波罗11号的NASA负责人?”阿波罗计划期间的NASA局长是托马斯·o·潘恩。从片段中可以看出,尤金·克兰兹是首席飞行指挥,从来没有当过NASA的管理员。
我们在附录表8、9、10 (Musique)和11、12、13 (2WikiMultiHopQA)中显示了每种方法使用的提示。我们的思维链实现与原始论文中的略有不同:我们在输出最终答案之前立即指定答案类型(例如,“所以最终答案(这个人的名字)是”,而不仅仅是“所以最终答案是”)。这是受到Kojima等人的答案提取步骤的启发(2022),我们在musque训练集上经验验证了这种修改提高了性能。注意,应用这个修改并没有提高自我询问的性能。
3.5 实验细节
在每个数据集中,我们总是对基线和提示使用相同的问题。我们在Musique的训练集上开发我们的方法,然后在Musique和2WikiMultiHopQA的开发集以及我们自己的数据集上测试它。
我们使用了来自2WikiMultiHopQA开发集的1.2万个问题的子集(Ho et al, 2020)。
我们的提示有4个示例,与Ho et al(2020)的表3中的示例相同,顺序相同;这表明我们没有对该数据集进行及时的工程或调优。我们只使用了Musique开发集中标记为2跳的1252个问题,因为我们发现3跳和4跳的问题太复杂了,甚至论文作者有时也无法理解。在训练集上进行了几十次实验后,我们选择了特定的提示示例和格式。我们只使用了一次开发集,即本文中给出的结果。
对于Bamboogle,我们使用与2WikiMultiHopQA相同的提示符,以表明我们没有对该数据集进行提示调优。对于附录图6中的CC实验,我们从CC中抽取了1.2万个问题,并使用第2节中提到的相同的2次提示。
3.6 结果
表1给出了使用davici -002在2WikiMultiHopQA、Musique和Bamboogle上的基线和我们的方法的结果。思维链比直接提示有显著的改进。搜索引擎很难回答大多数作文问题;然而,如果使用LM进行后处理,它得到的2WikiMultiHopQA的结果与直接提示得到的结果相当。
在2WikiMultiHopQA和musque上,自我询问在思维链上的提升幅度较小,但在Bamboogle上,提升幅度高达11%(绝对)。我们假设,Bamboogle更多样化的本质,以及大多数问题与少数几个提示中的问题不相似的事实,可能会使思维链更难分解问题,而我们的自我问模型,在回答问题之前明确分解问题,更好地处理新的推理问题。将搜索引擎集成到自我询问中进一步提高了在所有数据集上的性能,有时高达10%(绝对)。
Least-to-most (Zhou et al, 2022)是分解作文问题的提示;然而,它需要使用不同提示进行多次向前传递,而self-ask使用一个提示在一次向前传递中分解输入问题并回答子问题。表2显示,我们的方法在运行速度提高30%以上的情况下实现了类似或更好的性能。
4 相关工作
在链式思维和Scratchpad方法之前,Ling等人(2017年)已经展示了序列到序列模型在解决算术问题时,通过在输出最终答案之前生成一个推理,可以获得性能提升。允许模型使用更多的计算来解决更难的问题,之前在语言(Graves, 2016; Seo et al., 2017; Dong et al., 2019; Schwartz et al., 2020; Schwarzschild et al., 2021; Nye et al., 2021; Wei et al., 2022b; Zhou et al., 2022)和视觉(Bolukbasi et al., 2017; Huang et al., 2018; Wang et al., 2018, 2021)领域都有过探索。
之前的论文探讨了将复杂任务分解为一组更简单的子问题。Iyyer et al. (2017); Buck et al. (2018); Talmor and Berant (2018); Min et al. (2019); Qi et al. (2019); Rao and Daumé III (2019); Wolfson et al. (2020); Perez et al. (2020); Khot et al. (2021); Wang et al. (2022) 训练了监督模型以将组合性问题分解为子问题。
这些论文没有使用因果预训练的语言模型。Mishra et al. (2022) 显示,手动将指令性提示分解为更简单的子步骤可以提高性能。Shwartz et al. (2020); Betz et al. (2021); Liu et al. (2022) 使用预训练的因果语言模型生成上下文,以改善多项选择题的表现。Ye和Durrett (2022) 使用思维链来回答与上下文段落一起呈现的组合性问题。在这里,我们在向语言模型呈现问题时,不输入任何上下文。
Talmor等人(2020年)在2跳问题上测试了遮蔽语言模型(masked LMs)。CC包含带有额外约束的2跳问题,即,被组合的两个事实很可能在预训练期间分别多次观察到,但不太可能一起出现。Patel等人(2022年)展示了将复杂问题手动分解为子问题可以提高性能。我们的自我提问方法自动执行这一过程,因此更快且更具可扩展性。
Nakano等人(2021年)让GPT-3浏览网页,提高了问答性能,但他们使用他们手动构建的数据集对GPT-3进行了模仿学习目标的微调。Menick等人(2022年)使用强化学习将搜索引擎集成到一个生成支持性证据的语言模型中。Thoppilan等人(2022年)提出了一种可以与信息检索系统交互的语言模型,但这种交互需要一种特殊的查询语言,并且他们不得不在新数据上进行微调。我们的Self-ask + Search Engine方法不需要对语言模型或其预训练进行任何修改。Thoppilan等人(2022年)还通过让他们的两个语言模型相互对话来回答问题。我们的自我对话只需要一个模型。此外,他们只关注单跳问题。Thoppilan等人(2022年)的工作与先前将语言模型应用于对话建模的工作有关(Zhang等人,2018年;Dinan等人,2019年;Freitas等人,2020年;Roller等人,2021年),后者是基于以前在将神经网络应用于对话任务方面的成功(Shang等人,2015年;Sordoni等人,2015年;Vinyals和Le,2015年;Li等人,2016年;Serban等人,2021年)。
我们的自问+搜索引擎模型部分受到了先前将神经lm与检索模型相结合的工作的启发(Khandelwal等人,2020;Lewis et al, 2020;Guu et al ., 2020;伊扎卡德和格雷夫,2021;Borgeaud et al, 2022)。我们是第一个提出使用二跳题作为评估大型LMs作文能力的方法的人。Lake和Baroni(2017)以及Hupkes等人(2020)此前测试了在人工数据集上训练的序列到序列模型将已知部件整合到新组合中的能力。Keysers等人(2020)生成组合问题来测试小型编码器-解码器模型,但他们不测试预训练的lm。
与我们的工作并行,Khot等人(2023)和Yao等人(2023)提出了类似于自我询问的方法,但他们没有提出我们关于组合性差距的发现,也没有将他们的提示与网络搜索引擎集成,也没有像我们的composition Celebrities和Bamboogle那样提出新的数据集。
5 结论
我们提出了组合性差距。然后我们表明,通过让LM明确地陈述和回答后续问题,我们的自我提问在思维链上得到了改善。最后,利用搜索引擎对子问题进行了改进。
局限性
虽然我们在这里表明,对于10亿到1750亿个参数之间的模型,组合性差距保持在40%左右,但我们无法访问,因此也没有对大于1750亿个参数的模型进行实验。虽然这种模式在GPT-3的不同变体(包括vanilla和InstructGPT)中是一致的,但大于1750亿个参数的模型的行为可能会有所不同。
本文的实验集中在英语的两跳问答数据集上,因为我们相信这些数据集是探索语言模型推理能力的强大工具,因为我们相信专注于这些数据集将为Siri等面向用户的问答系统等应用程序带来更好的系统。我们在其他数据集上有限的手工实验,比如语义分析、算术问题或逻辑谜题的数据集,表明自我问也适用于那些非常不同的问题集。但对这些进行更彻底的实证评估可能会揭示出不同的结果。

















 346
346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









